Regression Trees
alla regressionstekniker innehåller en enda utdata (svar) variabel och en eller flera indata (prediktor) variabler. Utmatningsvariabeln är numerisk. Den allmänna regressionsträdbyggnadsmetoden tillåter inmatningsvariabler att vara en blandning av kontinuerliga och kategoriska variabler. Ett beslutsträd genereras när varje beslutskod i trädet innehåller ett test på någon inmatningsvariabels värde. Terminalnoderna i trädet innehåller de förutsagda utgångsvariabelvärdena.
ett Regressionsträd kan betraktas som en variant av beslutsträd, utformad för att approximera verkliga värderade funktioner, istället för att användas för klassificeringsmetoder.
metodik
ett regressionsträd byggs genom en process som kallas binär rekursiv partitionering, vilket är en iterativ process som delar upp data i partitioner eller grenar och fortsätter sedan att dela upp varje partition i mindre grupper när metoden flyttar upp varje gren.
ursprungligen grupperas alla poster i träningsuppsättningen (förklassificerade poster som används för att bestämma trädets struktur) i samma partition. Algoritmen börjar sedan allokera data till de två första partitionerna eller grenarna, med alla möjliga binära splittringar på varje fält. Algoritmen väljer delningen som minimerar summan av de kvadrerade avvikelserna från medelvärdet i de två separata partitionerna. Denna delningsregel tillämpas sedan på var och en av de nya filialerna. Denna process fortsätter tills varje nod når en användarspecificerad minsta nodstorlek och blir en terminalnod. (Om summan av kvadratiska avvikelser från medelvärdet i en nod är noll, anses den noden vara en terminalnod även om den inte har nått minsta storlek.)
beskärning av trädet
eftersom trädet odlas från träningsuppsättningen lider ett fullt utvecklat träd vanligtvis av övermontering (dvs. det förklarar slumpmässiga delar av träningsuppsättningen som sannolikt inte kommer att vara funktioner hos den större befolkningen). Denna övermontering resulterar i dålig prestanda på verkliga data. Därför måste trädet beskäras med hjälp av Valideringsuppsättningen. XLMiner beräknar kostnadskomplexitetsfaktorn vid varje steg under trädets tillväxt och bestämmer antalet beslutsnoder i det beskurna trädet. Kostnadskomplexitetsfaktorn är den multiplikativa faktorn som appliceras på trädets storlek (mätt med antalet terminalnoder).
trädet beskärs för att minimera summan av: 1) utmatningsvariabelvariansen i valideringsdata, taget en terminalnod i taget; och 2) produkten av kostnadskomplexitetsfaktorn och antalet terminalnoder. Om kostnadskomplexitetsfaktorn anges som noll, är beskärning helt enkelt att hitta det träd som fungerar bäst på valideringsdata när det gäller total terminalnodvarians. Större värden på kostnadskomplexitetsfaktorn resulterar i mindre träd. Beskärning utförs på en sista-In-först-ut-basis, vilket innebär att den senast odlade noden är den första som är föremål för eliminering.
Ensemblemetoder
XLMiner V2015 erbjuder tre kraftfulla ensemblemetoder för användning med Regressionsträd: bagging (bootstrap aggregating), boosting och random trees. Regressionsträdsalgoritmen kan användas för att hitta en modell som resulterar i goda förutsägelser för de nya data. Vi kan se statistiken och förvirringsmatriserna för den aktuella prediktorn för att se om vår modell passar bra till data; men hur skulle vi veta om det finns en bättre prediktor som bara väntar på att hittas? Svaret är att vi inte vet om det finns en bättre prediktor. Ensemblemetoder tillåter oss dock att kombinera flera svaga regressionsträdmodeller, som när de tas tillsammans bildar en ny, exakt, stark regressionsträdmodell. Dessa metoder fungerar genom att skapa flera olika regressionsmodeller, genom att ta olika prover av den ursprungliga datamängden och sedan kombinera sina utgångar. (Utgångar kan kombineras med flera tekniker, till exempel majoritetsröstning för klassificering och medelvärde för regression) denna kombination av modeller minskar effektivt variansen i den starka modellen. De tre typerna av ensemblemetoder som erbjuds i XLMiner (bagging, boosting och random trees) skiljer sig åt på tre punkter: 1) valet av träningsuppsättning för varje prediktor eller svag modell; 2) Hur de svaga modellerna genereras; och 3) Hur utgångarna kombineras. I alla tre metoderna utbildas varje svag modell på hela träningsuppsättningen för att bli skicklig i någon del av datamängden.
Bagging (bootstrap aggregating) var en av de första ensemblealgoritmerna som någonsin skrivits. Det är en enkel algoritm, men ändå mycket effektiv. Bagging genererar flera träningsuppsättningar genom att använda slumpmässig provtagning med ersättning (bootstrap sampling), tillämpar regressionsträdsalgoritmen på varje datamängd och tar sedan genomsnittet bland modellerna för att beräkna förutsägelserna för de nya data. Den största fördelen med bagging är den relativa lättheten att algoritmen kan parallelliseras, vilket gör det till ett bättre val för mycket stora datamängder.
Boosting bygger en stark modell genom att successivt träna modeller för att koncentrera sig på poster som får felaktiga förutsagda värden i tidigare modeller. När de är färdiga kombineras alla prediktorer med en viktad majoritetsröst. XLMiner erbjuder tre varianter av boosting som implementerats av AdaBoost-algoritmen (en av de mest populära ensemblealgoritmerna som används idag): M1 (Freund), M1 (Breiman) och SAMME (Stagewise additiv modellering med användning av en multi-klass exponentiell).
Adaboost.M1 tilldelar först en vikt(wb (i)) till varje post eller observation. Denna vikt är ursprungligen inställd på 1 / n, och kommer att uppdateras på varje iteration av algoritmen. Ett ursprungligt regressionsträd skapas med denna första träningsuppsättning (Tb) och ett fel beräknas som
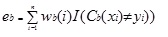
där i () – funktionen returnerar 1 om sant och 0 om inte.
felet i regressionsträdet i BTH-iterationen används för att beräkna konstanten ?b. Denna konstant används för att uppdatera vikten (wb (i). I AdaBoost.M1 (Freund), konstanten beräknas som
ab= ln ((1-eb)/eb)
i AdaBoost.M1 (Breiman), konstanten beräknas som
ab= 1/2LN ((1-eb)/eb)
i SAMME beräknas konstanten som
ab= 1/2LN ((1-eb)/eb + ln (k-1) där k är antalet klasser
där antalet kategorier är lika med 2, samme beter sig på samma sätt som AdaBoost Breiman.
i någon av de tre implementeringarna (Freund, Breiman eller SAMME) kommer den nya vikten för (b + 1)th-iterationen att vara

efteråt justeras vikterna till summan av 1. Som ett resultat ökas vikterna som tilldelats observationerna som tilldelades felaktiga förutsagda värden och vikterna som tilldelats observationerna som tilldelades exakta förutsagda värden minskas. Denna justering tvingar nästa regressionsmodell att lägga större vikt vid de poster som tilldelades felaktiga förutsägelser. (Detta ? konstant används också i den slutliga beräkningen, vilket ger regressionsmodellen med det lägsta felet mer inflytande.) Denna process upprepas tills b = antal svaga elever. Algoritmen beräknar sedan det vägda genomsnittet bland alla svaga elever och tilldelar det värdet till posten. Boosting ger i allmänhet bättre modeller än bagging; det har dock en nackdel eftersom det inte är parallelliserbart. Som ett resultat, om antalet svaga elever är stort, skulle det inte vara lämpligt att öka.
metoden för slumpmässiga träd (slumpmässiga skogar) är en variation av säckar. Denna metod fungerar genom att träna flera svaga regressionsträd med ett fast antal slumpmässigt utvalda funktioner (sqrt för klassificering och antal funktioner/3 för förutsägelse), tar sedan medelvärdet för de svaga eleverna och tilldelar det värdet till den starka prediktorn. Vanligtvis kan antalet svaga träd som genereras sträcka sig från flera hundra till flera tusen beroende på träningssatsens storlek och svårighet. Slumpmässiga träd är parallelliserbara, eftersom de är en variant av bagging. Men eftersom tandomträd väljer en begränsad mängd funktioner i varje iteration är prestandan för slumpmässiga träd snabbare än säckar.
Regression Tree Ensemble-metoder är mycket kraftfulla metoder och resulterar vanligtvis i bättre prestanda än ett enda träd. Denna funktion tillägg i XLMiner V2015 ger mer exakta förutsägelse modeller, och bör övervägas över enda träd metoden.