seaborn.histplot 2
seaborn.histplot(data=None, *, x=None, y=None, hue=None, vikter=None, stat=’count’, soptunnor=’auto’, binwidth=None, binrange=None, discrete=None, kumulativ=False, common_bins=True, common_norm=True, multiple=’layer’, element=’bars’, fill=true, Shrink=1, KDE=False, kde_kws=None, line_kws=None, Thresh=0, pthresh=none, Pmax=none, cbar=false, cbar_ax=none, cbar_kws=none, palette=None, hue_order=none, hue_norm=None, color=None, Log_scale=None, Legend=True, AX=None, **kwargs) univariat eller bivariat histogram för att visa fördelningar av datauppsättning.
ett histogram är ett klassiskt visualiseringsverktyg som representerar fördelningenav en eller flera variabler genom att räkna antalet observationer som faller inomdisreta fack.
denna funktion kan normalisera statistiken beräknad inom varje fack för att estimatefrequency, densitet eller sannolikhetsmassa, och den kan lägga till en jämn kurva erhållenmed hjälp av en kärndensitetsuppskattning, liknande kdeplot().
Mer information finns i användarhandboken.
parameterdatapandas.DataFramenumpy.ndarray, kartläggning eller sekvens
Indatastruktur. Antingen en långformad samling av vektorer som kan tilldelas namngivna variabler eller en bredformad dataset som kommer att internallyreshaped.
x, yvektorer eller nycklar idata
variabler som anger positioner på X-och y-axlarna.
huevector eller nyckel idata
semantisk variabel som är mappad för att bestämma färgen på plotelement.
weightsvector eller nyckel idata
om det tillhandahålls, vikt bidraget från motsvarande datapunktermot räkningen i varje fack av dessa faktorer.
stat {”count”, ”frequency”, ”density”, ”probability”}
Aggregate statistik för att beräkna i varje fack.
-
countvisar antalet observationer -
frequencyvisar antalet observationer dividerat med bin bredd -
densitynormaliserar räkningar så att histogrammets område är 1 -
probabilitynormaliserar räknas så att summan av stapelhöjderna är 1
binsstr, tal, vektor eller ett par sådana värden
Generisk bin-parameter som kan vara namnet på en referensregel, antalet fack eller rasterna i facken.Skickas till numpy.histogram_bin_edges().
binwidthnumber eller par av siffror
bredden på varje fack, åsidosätter bins men kan användas medbinrange.
binrangepair av siffror eller ett par par
lägsta och högsta värde för bin kanter; kan användas antingenmedbins ellerbinwidth. Standardvärden för data ytterligheter.
discretebool
Om True, standard till binwidth=1 och rita staplarna så att de är centrerade på motsvarande datapunkter. Detta undviker” luckor ” som kanannars visas när du använder diskreta (heltal) data.
kumulativebool
om sant, Rita de kumulativa räkningarna som lagerplatser ökar.
common_binsbool
om sant, använd samma fack när semantiska variabler producerar multipleplots. Om du använder en referensregel för att bestämma facken, kommer den att beräknasmed hela datauppsättningen.
common_normbool
Om True och använder en normaliserad statistik kommer normaliseringen att gälla över hela datauppsättningen. Annars normalisera varje histogram oberoende.
multiple {”layer”, ”dodge”, ”stack”, ”fill”}
tillvägagångssätt för att lösa flera element när semantisk kartläggning skapar delmängder.Endast relevant med univariata data.
element {”staplar”, ”steg”, ”poly”}
visuell representation av histogramstatistiken.Endast relevant med univariata data.
fillbool
om sant, fyll i utrymmet under histogrammet.Endast relevant med univariata data.
krympnummer
skala bredden på varje stapel i förhållande till binbredden med denna faktor.Endast relevant med univariata data.
kdebool
om sant, beräkna en uppskattning av kärndensiteten för att jämna ut fördelningen och visa på diagrammet som(en eller flera) rader.Endast relevant med univariata data.
Kde_kwsdict
parametrar som styr KDE-beräkningen, som i kdeplot().
Line_kwsdict
parametrar som styr KDE visualisering, skickas tillmatplotlib.axes.Axes.plot().
threshnumber eller ingen
celler med en statistik mindre än eller lika med detta värde kommer att vara transparent.Endast relevant med bivariata data.
pthreshnumber eller ingen
som thresh, men ett värde i sådant att celler med aggregat räknas(eller annan statistik, när den används) upp till denna andel av den totala kommer att varagenomskinlig.
pmaxnumber eller ingen
ett värde i det sätter den mättnadspunkten för färgkartan till ett värdeså att cellerna nedan är förstoppar denna andel av det totala antalet (ellerAndra statistik, när de används).
cbarbool
om sant, Lägg till en färgfält för att kommentera färgmappningen i en bivariat plot.Obs: stöder för närvarande inte tomter med en hue variabel brunn.
cbar_axmatplotlib.axes.Axes
befintliga axlar för färgfältet.
cbar_kwsdict
ytterligare parametrar skickas till matplotlib.figure.Figure.colorbar().
palettestring, list, dict ellermatplotlib.colors.Colormap
metod för att välja färger som ska användas vid mappning av hue semantisk.Strängvärden skickas till color_palette(). Lista eller dict valueshelt enkelt kategorisk kartläggning, medan ett colormap-objekt innebär numerisk kartläggning.
hue_ordervector av strängar
ange ordningen för bearbetning och plottning för kategoriska nivåer avhue semantisk.
hue_normtuple ellermatplotlib.colors.Normalize
antingen ett par värden som ställer in normaliseringsområdet i dataenhetereller ett objekt som kommer att mappas från dataenheter till ett intervall. Användninginnebär numerisk kartläggning.
färgmatplotlib color
enfärgspecifikation för när färgtonskartläggning inte används. Annars kommer theplot att försöka ansluta sig till matplotlib-egenskapscykeln.
log_scalebool eller number, eller par bools eller numbers
Ställ in en loggskala på dataaxeln (eller axlarna, med bivariata data) med den givna basen (Standard 10) och utvärdera KDE i loggutrymme.
legendbool
om falskt, undertrycka legenden för semantiska variabler.
axmatplotlib.axes.Axes
befintliga axlar för diagrammet. Annars Ring matplotlib.pyplot.gca()internt.
kwargs
andra sökordsargument skickas till en av följande matplotlibfunktioner:
-
matplotlib.axes.Axes.bar()(univariate, element=”bars”) -
matplotlib.axes.Axes.fill_between()(univariate, other element, fill=True) -
matplotlib.axes.Axes.plot()(univariate, other element, fill=False) -
matplotlib.axes.Axes.pcolormesh()(bivariate)
Returnsmatplotlib.axes.Axes
The matplotlib axes containing the plot.
See also
displot
Figure-level interface to distribution plot functions.
kdeplot
plotta univariata eller bivariata fördelningar med kärndensitetsuppskattning.
rugplot
rita ett fält vid varje observationsvärde längs X-och/eller y-axlarna.
ecdfplot
plotta empiriska kumulativa fördelningsfunktioner.
jointplot
rita en bivariat plot med univariata marginalfördelningar.
anteckningar
valet av fack för beräkning och plottning av ett histogram kan utöva ett väsentligt inflytande på de insikter som man kan dra från visualisering. Om facken är för stora kan de radera viktiga funktioner.Å andra sidan kan soptunnor som är för små domineras av slumpvariabilitet, vilket döljer formen på den verkliga underliggande fördelningen. Standardfackstorleken bestäms med hjälp av en referensregel som beror på samplingsstorlek och varians. Detta fungerar bra i många fall (dvs. med”välskötta” data) men det misslyckas i andra. Det är alltid bra att försökaolika binstorlekar för att vara säker på att du inte saknar något viktigt.Med den här funktionen kan du ange fack på flera olika sätt, t.ex. genom att ställa in det totala antalet fack som ska användas, bredden på varje fack eller specifika platser där facken ska gå sönder.
exempel
tilldela en variabel till x för att plotta en univariat fördelning längs X-axeln:
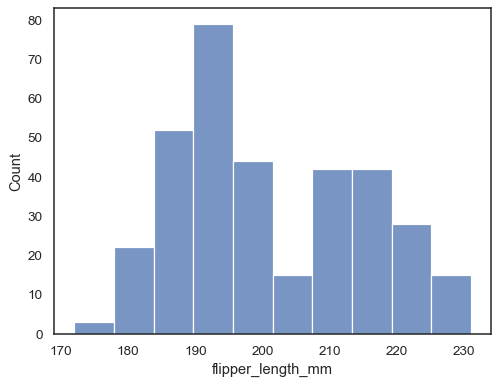
penguins = sns.load_dataset("penguins")sns.histplot(data=penguins, x="flipper_length_mm")
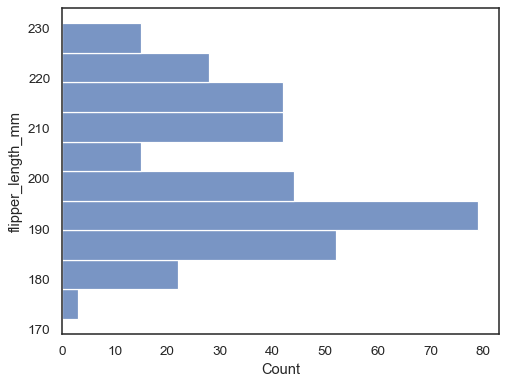
vänd tomten genom att tilldela datavariabeln till y-axeln:
sns.histplot(data=penguins, y="flipper_length_mm")
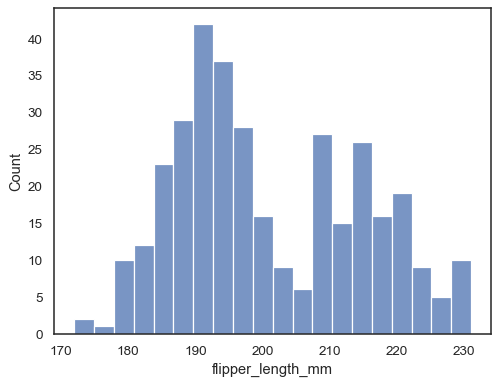
kontrollera hur väl histogrammet representerar data genom att ange endifferent bin bredd:
sns.histplot(data=penguins, x="flipper_length_mm", binwidth=3)
Du kan också definiera det totala antalet fack som ska användas:
sns.histplot(data=penguins, x="flipper_length_mm", bins=30)
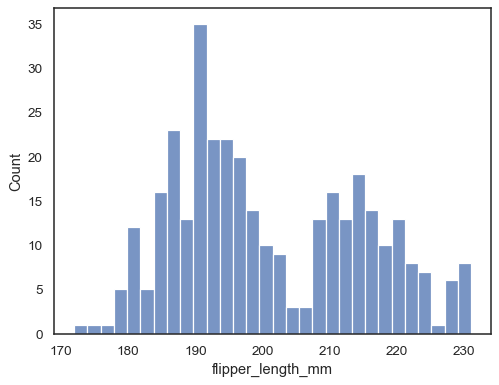
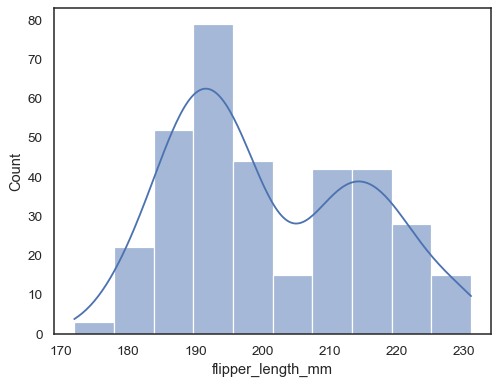
Lägg till en kärndensitetsuppskattning för att släta histogrammet, vilket gerkompletterande information om fördelningens form:
sns.histplot(data=penguins, x="flipper_length_mm", kde=True)
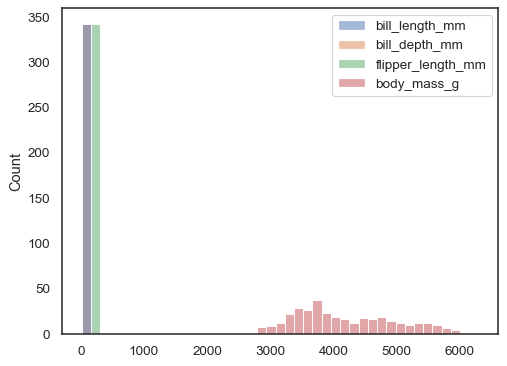
om varken x eller y tilldelas, behandlas datasetet sombred form och ett histogram ritas för varje numerisk kolumn:
sns.histplot(data=penguins)
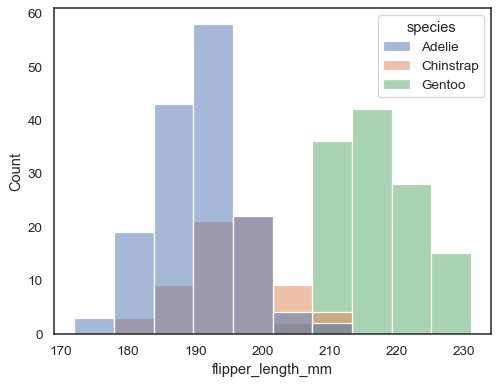
Du kan annars rita flera histogram från en långformad dataset medhue-mappning:
sns.histplot(data=penguins, x="flipper_length_mm", hue="species")
standardmetoden för att plotta flera distributioner är att ”layer” dem, men du kan också ”stack” dem:
sns.histplot(data=penguins, x="flipper_length_mm", hue="species", multiple="stack")
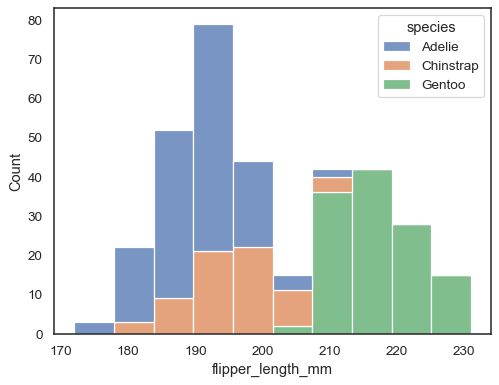
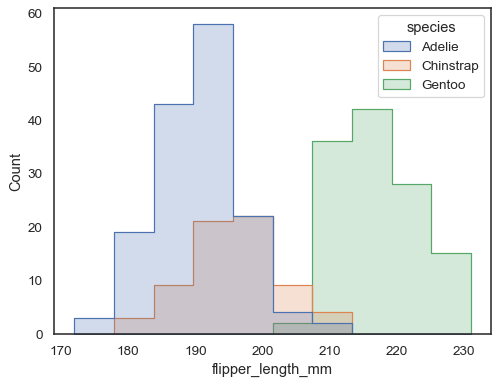
överlappande staplar kan vara svåra att visuellt lösa. Ett annat tillvägagångssätt skulle vara att rita en stegfunktion:
sns.histplot(penguins, x="flipper_length_mm", hue="species", element="step")
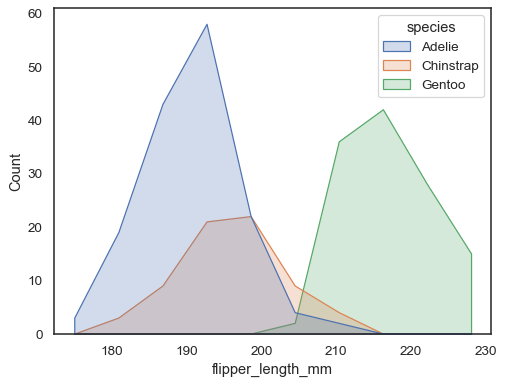
Du kan flytta ännu längre bort från staplar genom att rita en polygon medvinklar i mitten av varje fack. Detta kan göra det lättare att seform av distributionen, men använd med försiktighet: det blir mindre uppenbart för din publik att de tittar på ett histogram:
sns.histplot(penguins, x="flipper_length_mm", hue="species", element="poly")
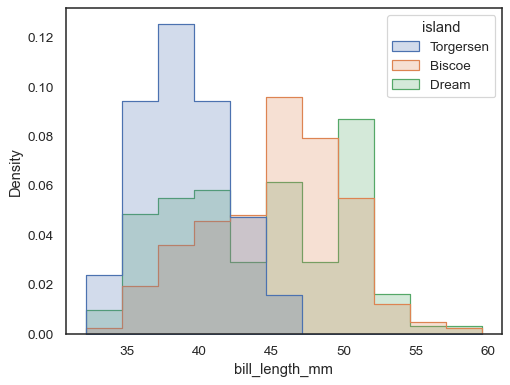
för att jämföra fördelningen av delmängder som skiljer sig väsentligt istorlek, använd indepdendent density normalization:
sns.histplot( penguins, x="bill_length_mm", hue="island", element="step", stat="density", common_norm=False,)
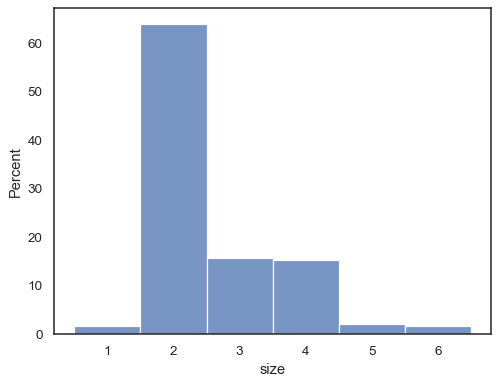
det är också möjligt att normalisera så att varje stapels höjd visar aprobability, vilket är mer meningsfullt för diskreta variabler:
tips = sns.load_dataset("tips")sns.histplot(data=tips, x="size", stat="probability", discrete=True)
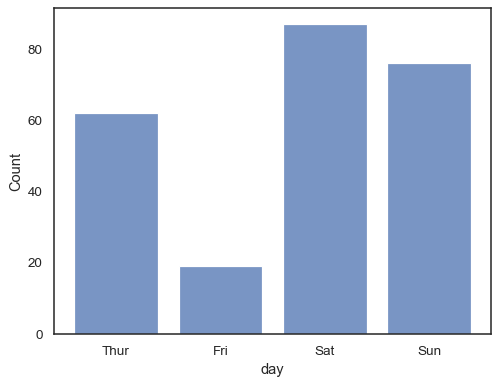
Du kan till och med rita ett histogram över kategoriska variabler (även om dettaär en experimentell funktion):
sns.histplot(data=tips, x="day", shrink=.8)
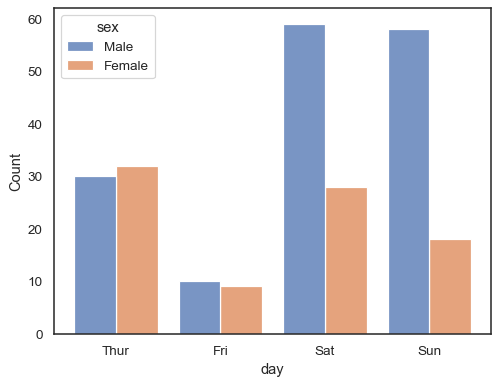
När du använder enhue semantisk med diskreta data kan det vara meningsfullt att”undvika” nivåerna:
sns.histplot(data=tips, x="day", hue="sex", multiple="dodge", shrink=.8)
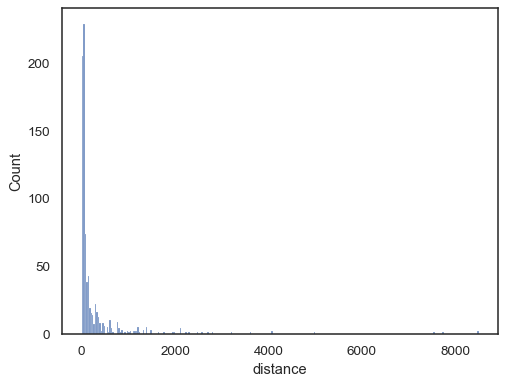
verkliga data är ofta skev. För kraftigt snedställda fördelningar är det bättre att definiera facken i loggutrymme. Jämföra:
planets = sns.load_dataset("planets")sns.histplot(data=planets, x="distance")
To the log-scale version:
sns.histplot(data=planets, x="distance", log_scale=True)
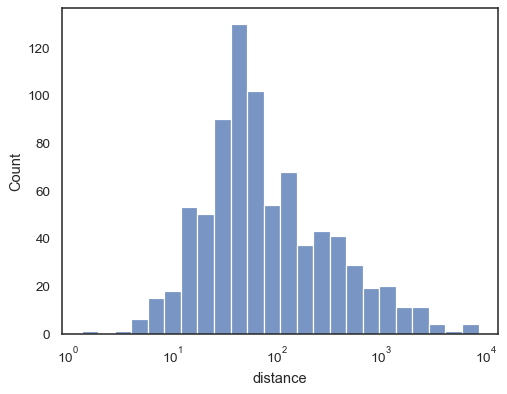
There are also a number of options for how the histogram appears. Youcan show unfilled bars:
sns.histplot(data=planets, x="distance", log_scale=True, fill=False)
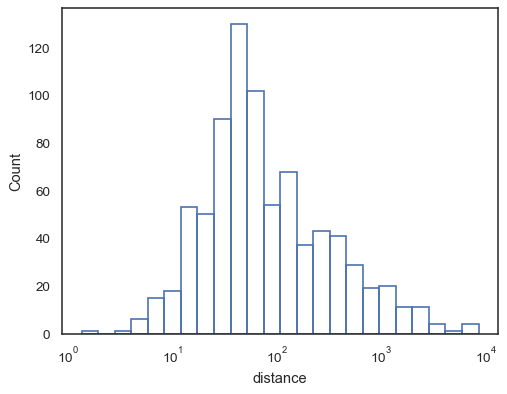
Or an unfilled step function:
sns.histplot(data=planets, x="distance", log_scale=True, element="step", fill=False)
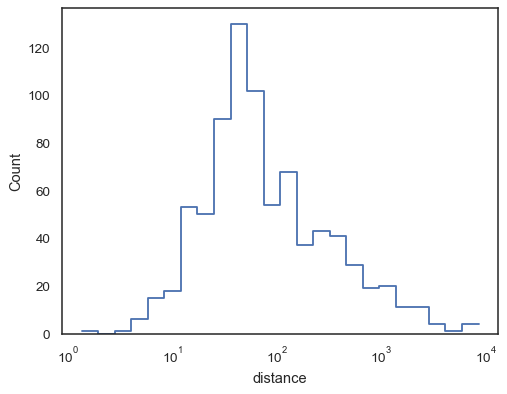
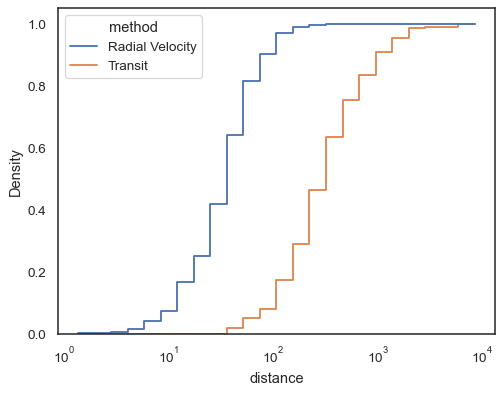
Stegfunktioner, esepcially när ofyllda, gör det enkelt att comparecumulative histogram:
sns.histplot( data=planets, x="distance", hue="method", hue_order=, log_scale=True, element="step", fill=False, cumulative=True, stat="density", common_norm=False,)
När både x och y tilldelas, beräknas ett bivariat histogram och visas som en värmekarta:
sns.histplot(penguins, x="bill_depth_mm", y="body_mass_g")
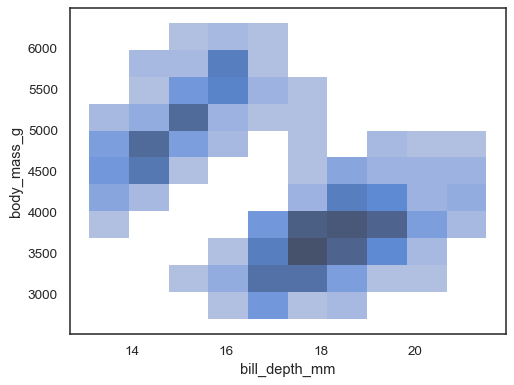
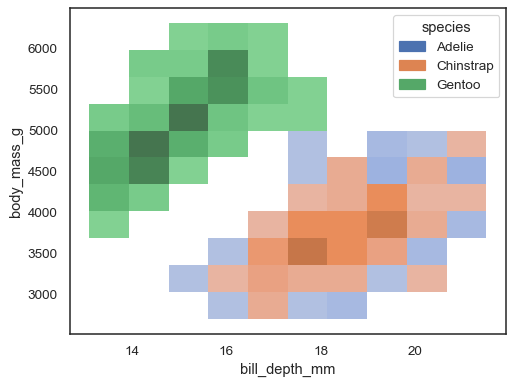
det är möjligt att tilldela enhue variabel också, även om detta inte kommer att fungera bra om data från de olika nivåerna har betydande överlappning:
sns.histplot(penguins, x="bill_depth_mm", y="body_mass_g", hue="species")
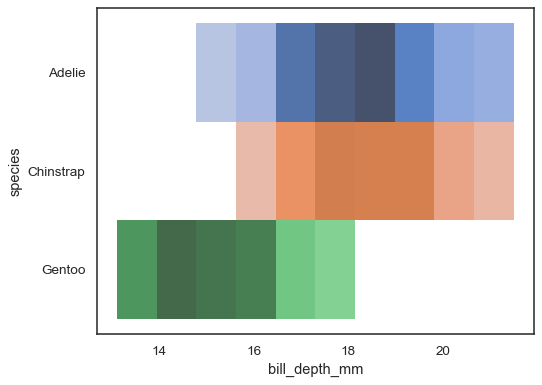
flera färgkartor kan vara meningsfulla när en av variablerna ärdiscrete:
sns.histplot( penguins, x="bill_depth_mm", y="species", hue="species", legend=False)
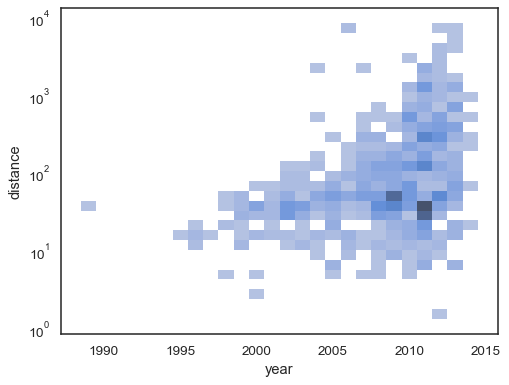
det bivariata histogrammet accepterar alla samma alternativ för beräkningsom dess univariata motsvarighet, med hjälp av tuples för att parametrisera x ochy oberoende:
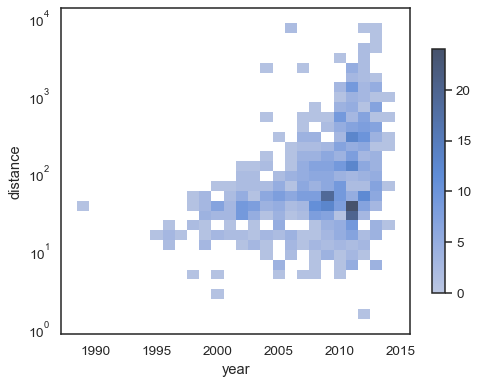
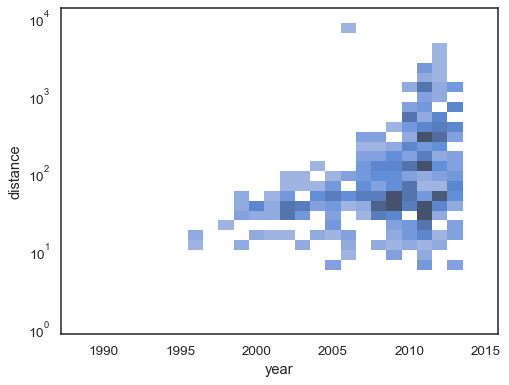
sns.histplot( planets, x="year", y="distance", bins=30, discrete=(True, False), log_scale=(False, True),)
standardbeteendet gör celler utan observationer transparenta,även om detta kan inaktiveras:
sns.histplot( planets, x="year", y="distance", bins=30, discrete=(True, False), log_scale=(False, True), thresh=None,)
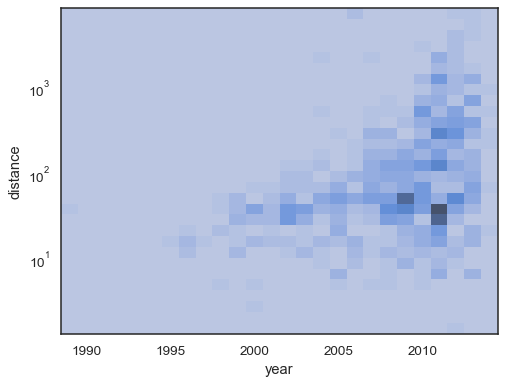
det är också möjligt att ställa in tröskelvärdet och färgmättnadspunkten interms för andelen kumulativa räkningar:
sns.histplot( planets, x="year", y="distance", bins=30, discrete=(True, False), log_scale=(False, True), pthresh=.05, pmax=.9,)
för att kommentera färgkartan, Lägg till en färgfält:
sns.histplot( planets, x="year", y="distance", bins=30, discrete=(True, False), log_scale=(False, True), cbar=True, cbar_kws=dict(shrink=.75),)