T-testet
t-testet bedömer om medlen för två grupper skiljer sig statistiskt från varandra. Denna analys är lämplig när du vill jämföra medel för två grupper, och särskilt lämplig som analys för posttest-endast två-grupp randomiserad experimentell design.
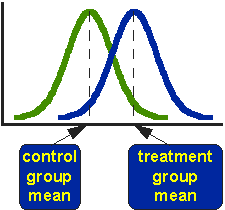
Figur 1. Idealiserade fördelningar för behandlade och jämförelse grupp posttest värden.
Figur 1 visar fördelningarna för de behandlade (blå) och kontroll (gröna) grupperna i en studie. I själva verket visar figuren den idealiserade fördelningen – den faktiska fördelningen skulle vanligtvis avbildas med ett histogram eller stapeldiagram. Figuren indikerar var kontroll-och behandlingsgruppsmedlen finns. Frågan som t-test adresserar är om medlen är statistiskt olika.
vad betyder det att medelvärdena för två grupper är statistiskt olika? Tänk på de tre situationer som visas i Figur 2. Det första att märka om de tre situationerna är att skillnaden mellan medlen är densamma i alla tre. Men du bör också märka att de tre situationerna inte ser likadana ut – de berättar mycket olika historier. Det översta exemplet visar ett fall med måttlig variation av poäng inom varje grupp. Den andra situationen visar fallet med hög variabilitet. den tredje visar fallet med låg variation. Det är uppenbart att vi skulle dra slutsatsen att de två grupperna verkar mest olika eller distinkta i botten-eller lågvariabilitetsfallet. Varför? Eftersom det finns relativt liten överlappning mellan de två klockformade kurvorna. I fallet med hög variabilitet verkar gruppskillnaden minst slående eftersom de två klockformade fördelningarna överlappar så mycket.
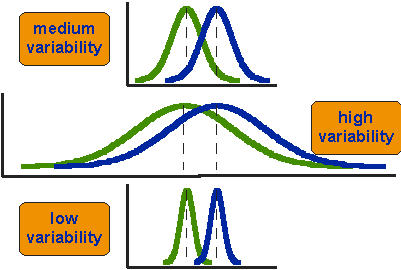
Figur 2. Tre scenarier för skillnader mellan medel.
detta leder oss till en mycket viktig slutsats: när vi tittar på skillnaderna mellan poäng för två grupper måste vi bedöma skillnaden mellan deras medel i förhållande till spridningen eller variationen i deras poäng. T-testet gör just detta.
statistisk analys av T-testet
formeln för T-testet är ett förhållande. Den övre delen av förhållandet är bara skillnaden mellan de två medlen eller medelvärdena. Den nedre delen är ett mått på variationen eller spridningen av poängen. Denna formel är i huvudsak ett annat exempel på signal-till-brus-metaforen i forskning: skillnaden mellan medlen är signalen att vi i detta fall tror att vårt program eller behandling införs i data; den nedre delen av formeln är ett mått på variabilitet som i huvudsak är brus som kan göra det svårare att se gruppskillnaden. Figur 3 visar formeln för T-testet och hur täljaren och nämnaren är relaterade till fördelningarna.
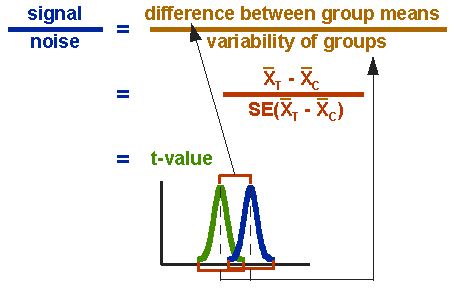
Figur 3. Formel för T-testet.
den övre delen av formeln är lätt att beräkna – bara hitta skillnaden mellan medlen. Den nedre delen kallas standardfelet för skillnaden. För att beräkna det tar vi variansen för varje grupp och delar den med antalet personer i den gruppen. Vi lägger till dessa två värden och tar sedan deras kvadratrot. Den specifika formeln för standardfelet för skillnaden mellan medlen är:
$$\textrm{se}(\bar{X}_T-\bar{X}_C) = \sqrt{\frac{\textrm{var}_T}{n_t}+\frac{\textrm{var}_c}{n_c}}$$
Kom ihåg att variansen helt enkelt är kvadraten för standardavvikelsen.
den slutliga formeln för T-testet är:
$$t = \frac{\bar{X}_T-\bar{X}_C}{\sqrt{\frac{\textrm{var}_T}{n_t}+\frac{\textrm{var}_C}{n_C}}}$$
t-värdet kommer att vara positivt om det första medelvärdet är större än det andra och negativt om det är mindre. När du har beräknatt-värdet måste du slå upp det i en tabell med betydelse för att testa om förhållandet är tillräckligt stort för att säga att skillnaden mellan grupperna inte sannolikt har varit en chans att hitta. För att testa betydelsen måste du ställa in en risknivå (kallad alfa-nivån). I de flesta sociala undersökningar är ”tumregeln” att ställa in alfa-nivån på .05. Det betyder att fem gånger av hundra skulle du hitta en statistiskt signifikant skillnad mellan medlen även om det inte fanns någon (dvs med ”chans”). Du måste också bestämma graden av frihet (df) för testet. I t-test är frihetsgraderna summan av personerna i båda grupperna minus 2. Med tanke på alfa-nivån, df ocht-värdet kan du set-värdet upp i en standardtabell med betydelse (tillgänglig som bilaga på baksidan av de flesta statistiktexter) för att avgöra omt-värdet är tillräckligt stort för att vara betydande. Om det är kan du dra slutsatsen att skillnaden mellan medel för de två grupperna är annorlunda (även med tanke på variationen). Lyckligtvis skriver statistiska datorprogram rutinmässigt ut signifikansprovresultaten och sparar dig besväret med att leta upp dem i en tabell.
t-testet, envägsanalys av varians (ANOVA) och en form av regressionsanalys är matematiskt ekvivalenta (se den statistiska analysen av den posttest-bara randomiserade experimentella designen) och skulle ge identiska resultat.