Blog
V předchozím blogu, jsme diskutovali o tom, jak supermarkety využívat data pro lepší pochopení potřeb spotřebitelů, a nakonec, zvýšit své celkové strávit. Jednou z klíčových technik používaných velkými maloobchodníky se nazývá analýza tržního koše (MBA), která odhaluje asociace mezi produkty hledáním kombinací produktů, které se často vyskytují v transakcích. Jinými slovy, umožňuje supermarketům identifikovat vztahy mezi produkty, které lidé kupují. Například zákazníci, kteří si koupí tužku a papír, si pravděpodobně koupí gumu nebo pravítko.
“ analýza tržního koše umožňuje maloobchodníkům identifikovat vztahy mezi produkty, které lidé kupují.“
Maloobchodníci mohou použít poznatky získané z MBA v mnoha způsoby, včetně:
- Seskupení produktů, které co-nastat v designu obchodu, rozložení zvýšit šance na cross-selling;
- Řízení on-line doporučení, motory („zákazníci, kteří zakoupili tento produkt, si také prohlíželi tento produkt“); a
- cílení marketingových kampaní zasláním propagačních kuponů zákazníkům na produkty související s položkami, které nedávno zakoupili.
Vzhledem k tomu, jak populární a cenné MBA je, že bychom produkovat následující krok-za-krokem průvodce, který popisuje, jak to funguje a jak můžete jít o podnik vlastní Analýza nákupního Košíku.
jak funguje analýza tržního koše?
k provedení MBA budete nejprve potřebovat datovou sadu transakcí. Každá transakce představuje skupinu položek nebo produktů, které byly zakoupeny společně a často označovány jako „sada položek“. Například jedna sada položek může být: {tužka, papír, sponky, guma} v takovém případě byly všechny tyto položky zakoupeny v jedné transakci.
v MBA jsou transakce analyzovány za účelem identifikace pravidel sdružování. Například jedno pravidlo může být: {pencil, paper} => {rubber}. To znamená, že pokud má zákazník transakci, která obsahuje tužku a papír, bude pravděpodobně mít zájem také o koupi gumy.
před jednáním podle pravidla musí prodejce vědět, zda existují dostatečné důkazy, které by naznačovaly, že to bude mít za následek příznivý výsledek. Proto jsme se změřit sílu pravidlo o výpočtu následující tři metriky (poznámka: ostatní metriky jsou k dispozici, ale to jsou tři nejčastěji používané):
Podpora: procento transakcí, které obsahují všechny položky v itemset (např. tužka, papír a pryž). Čím vyšší je podpora, tím častěji dochází k položce. Pravidla s vysokou podporou jsou upřednostňována, protože je pravděpodobné, že budou použitelná pro velký počet budoucích transakcí.
Důvěra: pravděpodobnost, že transakce, která obsahuje položky na levé straně pravidla (v našem příkladu, tužka a papír) obsahuje také položku na pravé straně (gumové). Čím vyšší sebevědomí, tím větší je pravděpodobnost, že položka na pravé straně bude možné zakoupit, nebo, jinými slovy, čím větší návratnost můžete očekávat, že pro dané pravidlo.
výtah: pravděpodobnost, že všechny položky v pravidle vyskytující se společně (jinak známý jako podporu) dělený součinem pravděpodobnosti položky na levé a pravé straně, které se vyskytují jako kdyby tam byl žádná souvislost mezi nimi. Například, pokud tužka, papír a guma došlo spolu v 2,5% všech transakcí, tužka a papír, v 10% z transakce a gumy v 8% z transakce, pak výtah by: 0.025/(0.1*0.08) = 3.125. Zdvih více než 1 naznačuje, že přítomnost tužky a papíru zvyšuje pravděpodobnost, že v transakci dojde také k gumě. Celkově, výtah shrnuje sílu asociace mezi produkty na levé a pravé straně pravidlo; čím větší zdvih, tím větší souvislost mezi dva produkty.
provést Analýza nákupního Košíku a identifikovat potenciální pravidla, dolování dat algoritmus nazývá ‚Apriori algoritmus se běžně používá, který pracuje ve dvou krocích:
- Systematicky identifikovat položky, které se vyskytují často v datové sadě s podporou větší než zadaná prahová hodnota.
- Vypočítejte důvěru všech možných pravidel vzhledem k častým položkám a udržujte pouze ty, které mají jistotu větší než předem stanovený práh.
prahové hodnoty pro nastavení podpory a důvěry jsou určeny uživatelem a pravděpodobně se budou lišit mezi sadami transakčních dat. R má výchozí hodnoty, ale doporučujeme s nimi experimentovat, abyste zjistili, jak ovlivňují počet vrácených pravidel (více o tom níže). Konečně, ačkoli algoritmus Apriori nepoužívá lift ke stanovení pravidel, uvidíte v následujícím textu, že používáme lift při zkoumání pravidel, která algoritmus vrací.
provádění analýzy tržního koše v R
abychom ukázali, jak provést MBA, rozhodli jsme se použít R a zejména balíček arules. Pro ty, kteří mají zájem, jsme zahrnuli R kód, který jsme použili na konci tohoto blogu.
Tady budeme sledovat stejný příklad použit v arulesViz dálniční Známku a použít soubor dat, z prodeje potravin, který obsahuje 9,835 jednotlivých transakcí s 169 položek. První věc, kterou uděláme, je podívat se na položky v transakcích a zejména vykreslit relativní frekvenci 25 nejčastějších položek na obrázku 1. To odpovídá podpoře těchto položek, kde každá sada položek obsahuje pouze jednu položku. Tento bar děj znázorňuje potraviny, které jsou často koupil v tomto obchodě, a to je pozoruhodné, že podpora i těch častých položek je relativně nízká (například, nejčastější položka se vyskytuje pouze kolem 2,5% z transakce). Tyto poznatky používáme k informování minimální prahové hodnoty při spuštění algoritmu Apriori; například víme, že k tomu, aby algoritmus vrátil přiměřený počet pravidel, budeme muset nastavit prahovou hodnotu podpory hluboko pod 0,025.
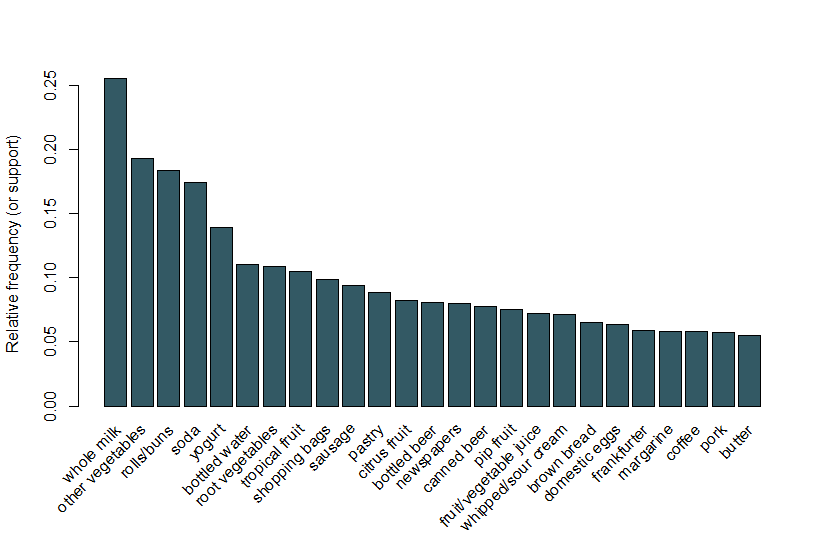
Obrázek 1 bar graf podpory 25 nejčastějších zakoupených položek.
nastavením prahové hodnoty podpory 0, 001 a spolehlivosti 0, 5 můžeme spustit algoritmus Apriori a získat sadu 5 668 výsledků. Tyto prahové hodnoty jsou voleny tak, aby počet vrácených pravidel byl vysoký, ale toto číslo by se snížilo, kdybychom zvýšili některou prahovou hodnotu. Doporučujeme experimentovat s těmito prahovými hodnotami, abychom získali nejvhodnější hodnoty. I když existuje příliš mnoho pravidel musí být schopen podívat se na ně individuálně, můžeme se podívat na pět pravidel, s největší výtah:
| Pravidlo | Podpora | Důvěra | Výtah |
| {instantní potravinářské výrobky,soda}=>{hamburger maso} | 0.001 | 0.632 | 19.00 |
| {soda, popcorn}=>{slané občerstvení} | 0.001 | 0.632 | 16.70 |
| {flour, baking powder}=>{sugar} | 0.001 | 0.556 | 16.41 |
| {ham, processed cheese}=>{white bread} | 0.002 | 0.633 | 15.05 |
| {whole milk, instant food products}=>{hamburger meat} | 0.002 | 0.500 | 15.04 |
Table 1: The five rules with the largest lift.
These rules seem to make intuitive sense. Například první pravidlo může představovat druh položek zakoupených pro BBQ, druhý pro filmovou noc a třetí pro pečení.
namísto použití prahových hodnot ke snížení pravidel na menší množinu je obvyklé, že větší soubor pravidel bude vrácen, takže existuje větší šance na vytvoření příslušných pravidel. Alternativně můžeme pomocí vizualizačních technik zkontrolovat soubor vrácených pravidel a identifikovat ta, která budou pravděpodobně užitečná.
pomocí balíčku arulesViz zakreslíme pravidla důvěrou, podporou a zvednutím na obrázku 2. Tento graf ilustruje vztah mezi různými metrikami. Ukázalo se, že optimální pravidla jsou ta, která leží na takzvané „hranici podpory a důvěry“. V podstatě, toto jsou pravidla, která leží na pravém okraji spiknutí, kde je maximalizována podpora, důvěra nebo obojí. Funkce grafu v balíčku arulesViz má užitečnou interaktivní funkci, která umožňuje vybrat jednotlivá pravidla (kliknutím na přidružený datový bod), což znamená, že pravidla na hranici lze snadno identifikovat.
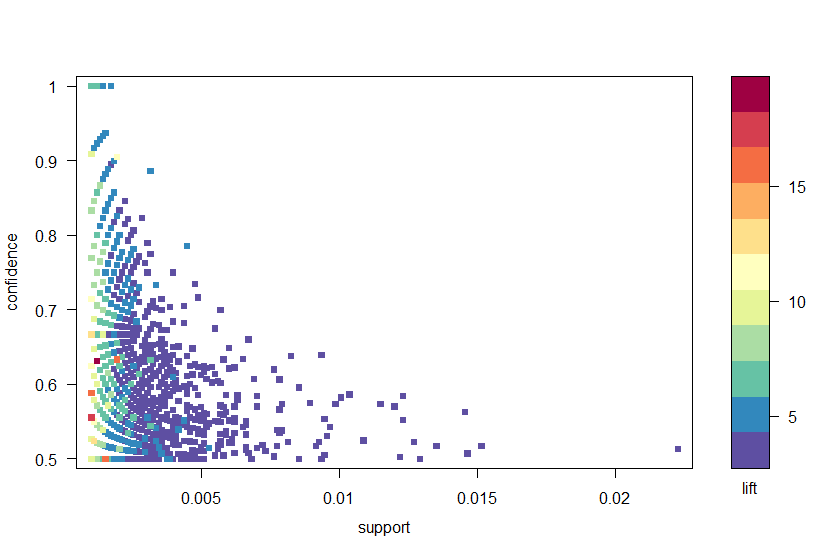
Obrázek 2: bodový graf metrik spolehlivosti, podpory a zvedání.
Existuje spousta dalších pozemků k dispozici, vizualizovat pravidla, ale jedna postava, která doporučujeme zkoumání je graf-založené na vizualizaci (viz Obrázek 3) z deseti pravidel, pokud jde o výtah (můžete zahrnout více než deset, ale tyto typy grafů můžete snadno dostat přeplněná). V tomto grafu položky seskupené kolem kruhu představují sadu položek a šipky označují vztah v pravidlech. Jedním pravidlem je například to, že nákup cukru je spojen s nákupy mouky a prášku do pečiva. Velikost kruhu představuje úroveň spolehlivosti spojenou s pravidlem a barvu úrovně zdvihu (čím větší kruh a tmavší šedá, tím lépe).
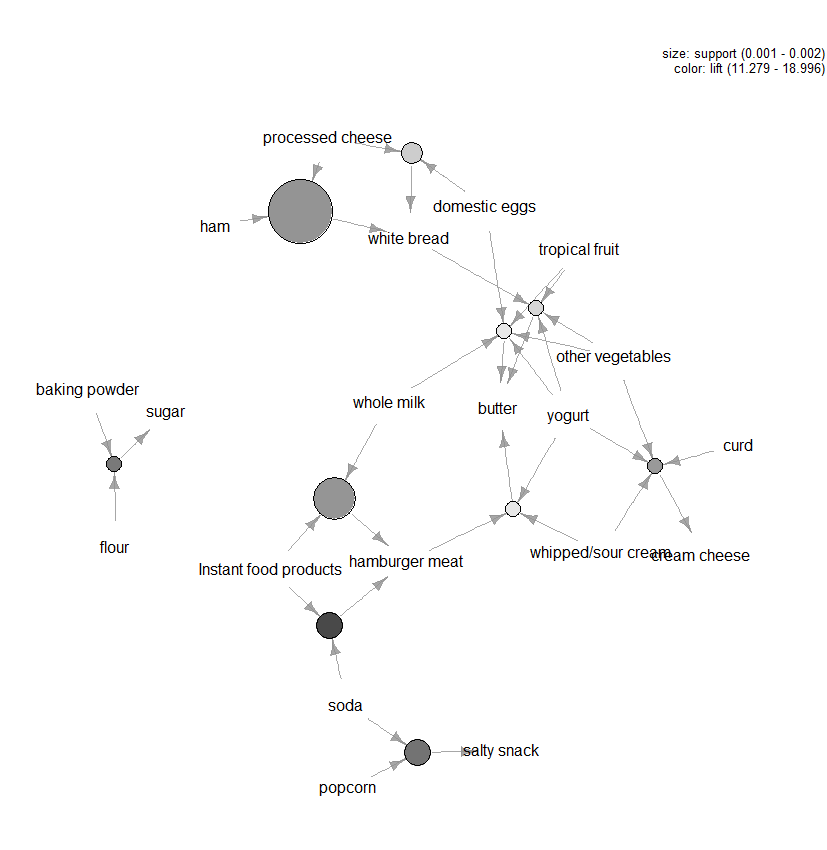
obrázek 3: Grafová vizualizace prvních deseti pravidel z hlediska zdvihu.
analýza tržního koše je užitečným nástrojem pro maloobchodníky, kteří chtějí lépe porozumět vztahům mezi produkty, které lidé kupují. Existuje mnoho nástrojů, které mohou být použity při provádění MBA a nejsložitější aspekty analýzy jsou nastavení důvěru a podporu prahy v Apriori algoritmus a určit pravidla, která jsou stojí za to pokračovat. Obvykle se provádí měřením pravidel z hlediska metrik, které shrnují, jak zajímavé jsou, pomocí vizualizačních technik a také formálnějších vícerozměrných statistik. V konečném důsledku klíčem k MBA je získat hodnotu z vašich transakčních dat tím, že vybuduje pochopení potřeb vašich spotřebitelů. Tento typ informací je neocenitelný, pokud máte zájem o marketingové aktivity, jako je křížový prodej nebo cílené kampaně.
Pokud se chcete dozvědět více o analýze údajů o vašich transakcích, kontaktujte nás a my vám rádi pomůžeme.
R Code
library("arules")
library("arulesViz")
#Load data set:
data("Groceries")
summary(Groceries)
#Look at data:
inspect(Groceries)
LIST(Groceries)
#Calculate rules using apriori algorithm and specifying support and confidence thresholds:
rules = apriori(Groceries, parameter=list(support=0.001, confidence=0.5))
#Inspect the top 5 rules in terms of lift:
inspect(head(sort(rules, by ="lift"),5))
#Plot a frequency plot:
itemFrequencyPlot(Groceries, topN = 25)
#Scatter plot of rules:
library("RColorBrewer")
plot(rules,control=list(col=brewer.pal(11,"Spectral")),main="")
#Rules with high lift typically have low support.
#The most interesting rules reside on the support/confidence border which can be clearly seen in this plot.