Jak na Sémantické Segmentace pomocí Hluboké učení
Tento článek je komplexní přehled, včetně krok-za-krokem průvodce k provedení hluboké učení segmentace obrazu modelu.
zde jsme sdíleli nový aktualizovaný blog o sémantické segmentaci: průvodce sémantickou segmentací 2021
v současné době je sémantická segmentace jedním z klíčových problémů v oblasti počítačového vidění. Při pohledu na celkový obraz je sémantická segmentace jedním z úkolů na vysoké úrovni, který připravuje cestu k úplnému pochopení scény. Důležitost porozumění scéně jako hlavního problému počítačového vidění je zdůrazněna skutečností, že rostoucí počet aplikací vyživuje odvozování znalostí ze snímků. Některé z těchto aplikací zahrnují samořiditelná vozidla, interakce člověk-počítač, virtuální realita atd. S popularitou hluboké učení v posledních letech, mnoho sémantické segmentace problémy jsou řešeny pomocí hlubokých architektur, nejčastěji Konvoluční Neuronové Sítě, které předčí jiné přístupy, s velkým náskokem, pokud jde o přesnost a efektivitu.
- co je sémantická segmentace?
- Jaké jsou existující Sémantické Segmentace přístupy?
- 1 — Region-na Základě Sémantické Segmentace
- 2 — Plně Konvoluční Sítě na Bázi Sémantické Segmentace
- 3 — Slabě pod Dohledem Sémantické Segmentace
- Sémantické Segmentace s Plně-Konvoluční Sítě
- Krok 1
- Krok 2
- Krok 3
- Krok 4
- Krok 5
- by Vás mohl zajímat náš nejnovější příspěvky na:
co je sémantická segmentace?
sémantická segmentace je přirozeným krokem v progresi od hrubého k jemnému závěru:Počátek může být umístěn při klasifikaci, která spočívá v predikci celého vstupu.Dalším krokem je lokalizace / detekce, která poskytuje nejen třídy, ale také další informace týkající se prostorového umístění těchto tříd.Konečně, sémantické segmentace dosahuje jemnozrnné závěr tím, že husté předpovědi dovodit, etikety pro každý pixel, takže každý pixel je označen třídy jeho obklopující objekt rudy regionu.
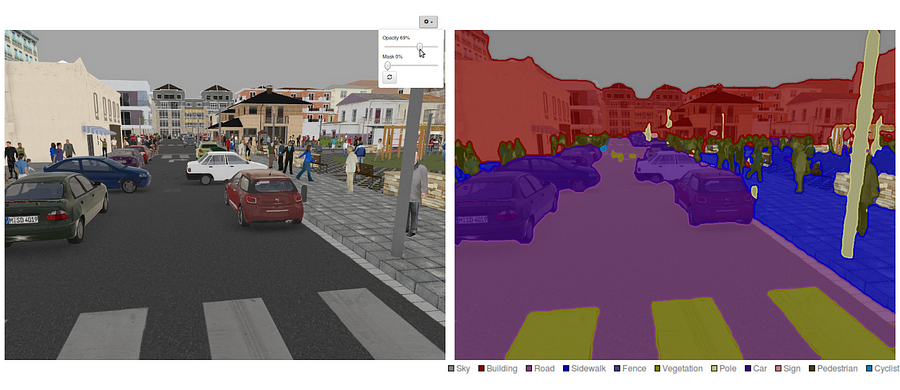
To je také hoden, aby přezkoumala některé standardní hlubokých sítí, které významně přispěli k oblasti počítačového vidění, jak oni jsou často používány jako základ pro sémantické segmentace systémy:
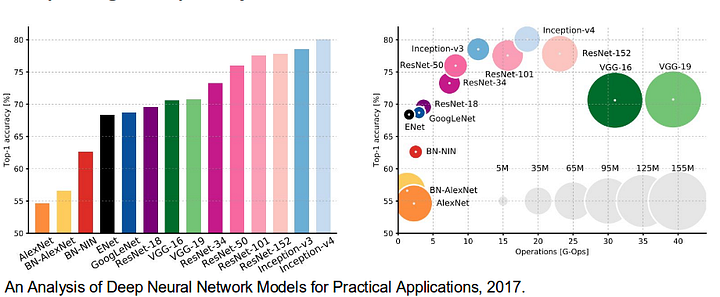
- AlexNet: Toronto průkopnickou hluboké CNN, který vyhrál v roce 2012 ImageNet soutěže s testem přesnosti 84.6%. Skládá se z 5 konvoluční vrstvy, max-pooling ty, ReLUs jako nelinearity, 3 plně konvoluční vrstvy, a odpadlík.
- VGG-16: tento model Oxfordu vyhrál soutěž ImageNet 2013 s přesností 92,7%. Používá hromadu konvolučních vrstev s malými vnímavými poli v prvních vrstvách místo několika vrstev s velkými vnímavými poli.
- GoogLeNet: tato síť Google zvítězila v soutěži ImageNet 2014 s přesností 93,3%. Skládá se z 22 vrstev a nově představeného stavebního bloku nazvaného inception module. Modul se skládá z vrstvy sítě v síti, operace sdružování, velké konvoluční vrstvy a malé konvoluční vrstvy.
- ResNet: tento model společnosti Microsoft vyhrál soutěž ImageNet 2016 s přesností 96,4%. Je dobře známý díky své hloubce (152 vrstev) a zavedení zbytkových bloků. Zbytkové bloky řeší problém trénování opravdu hluboké architektury zavedením spojení pro přeskočení identity, aby vrstvy mohly kopírovat své vstupy do další vrstvy.
Jaké jsou existující Sémantické Segmentace přístupy?
obecné sémantické segmentace architektura může být obecně myšlenka jako kodér sítě následuje dekodér síť:
- snímače je obvykle pre-vyškoleni klasifikace sítě, jako VGG/ResNet následuje dekodér sítě.
- úkolem dekodéru je sémanticky projektu diskriminační funkce (nižší rozlišení) naučil encoder na pixel prostoru (vyšší rozlišení), aby se hustou klasifikace.
na Rozdíl od klasifikace, kde konečný výsledek velmi hluboké sítě je jediná důležitá věc, sémantické segmentace vyžaduje nejen diskriminace na úrovni pixelů, ale také mechanismus pro projekt diskriminační funkce se naučil v různých fázích encoder na pixel prostoru. Různé přístupy používají různé mechanismy jako součást dekódovacího mechanismu. Podíváme se na 3 hlavní přístupy:
1 — Region-na Základě Sémantické Segmentace
region-based metody obvykle následují „segmentace pomocí rozpoznávání“ potrubí, které první výtažky free-form regionů z obrazu a popisuje jim, následuje region-based klasifikace. V době testu jsou předpovědi založené na regionu transformovány na předpovědi Pixelů, obvykle označením pixelu podle oblasti s nejvyšším hodnocením, která jej obsahuje.
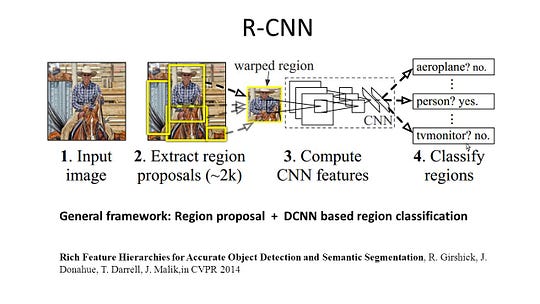
R-CNN (Regiony s CNN funkce) je jeden zástupce práce pro region-based metody. Provádí sémantickou segmentaci na základě výsledků detekce objektů. Konkrétně, R-CNN nejprve využívá selektivní vyhledávání k extrahování velkého množství návrhů objektů a poté vypočítá funkce CNN pro každý z nich. Nakonec klasifikuje každou oblast pomocí lineárního SVM specifického pro třídu. Ve srovnání s tradičními strukturami CNN, které jsou určeny především pro klasifikaci obrazu, může R-CNN řešit složitější úkoly, jako je detekce objektů a segmentace obrazu, a dokonce se stává jedním důležitým základem pro obě pole. Kromě toho může být R-CNN postavena na všech srovnávacích strukturách CNN, jako jsou AlexNet, VGG, GoogLeNet a ResNet.
Pro segmentaci obrazu úkol, R-CNN extrahovány 2 typy funkcí pro každý region: celý region, funkce a popředí funkce, a zjistil, že by to mohlo vést k lepší výkon při zřetězení je společně jako region funkci. R-CNN dosáhla významného zlepšení výkonu díky použití vysoce diskriminačních funkcí CNN. Nicméně, to také trpí několika nevýhodami pro segmentační úkol:
- funkce není kompatibilní s úlohou segmentace.
- funkce neobsahuje dostatek prostorových informací pro přesné generování hranic.
- generování segmentových návrhů vyžaduje čas a výrazně by ovlivnilo konečný výkon.
v Důsledku těchto překážek, nedávný výzkum bylo navrženo k řešení problémů, včetně SDS, Hypercolumns, Maska R-CNN.
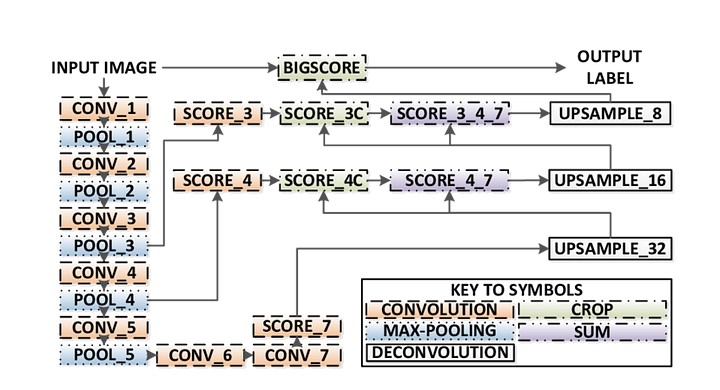
2 — Plně Konvoluční Sítě na Bázi Sémantické Segmentace
původní Plně Konvoluční Network (FCN) učí mapování z pixelů pixelů, bez extrakce oblasti návrhů. FCN network pipeline je rozšíření klasické CNN. Hlavní myšlenkou je, aby klasická CNN brala jako vstupní obrázky libovolné velikosti. Omezení CNN přijímat a vyrábět štítky pouze pro vstupy určité velikosti pochází z pevně propojených vrstev. Na rozdíl od nich mají FCN pouze konvoluční a sdružující vrstvy, které jim umožňují předpovídat vstupy libovolné velikosti.
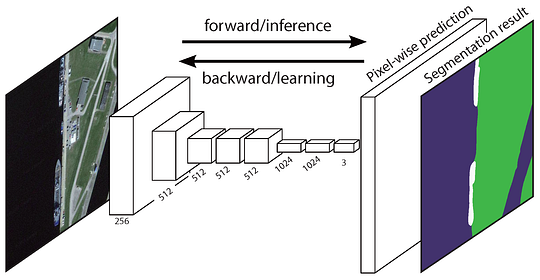
Jeden problém, v tomto konkrétním FCN je, že šíření prostřednictvím několika střídal konvoluční a sdružování vrstev, rozlišení výstupní funkce mapy je dole ve vzorku. Proto, přímé předpovědi FCN jsou obvykle v nízkém rozlišení, což má za následek relativně fuzzy hranice objektů. K řešení tohoto problému byla navržena řada pokročilejších přístupů založených na FCN, včetně SegNet,DeepLab-CRF, a rozšířené konvoluce.
3 — Slabě pod Dohledem Sémantické Segmentace
Většina relevantních metod v sémantické segmentace spoléhat na velké množství obrázků s pixel-moudrý segmentační masky. Ruční anotace těchto masek je však poměrně časově náročná, frustrující a komerčně nákladná. Proto byly nedávno navrženy některé slabě kontrolované metody, které se věnují naplňování sémantické segmentace pomocí anotovaných ohraničujících políček.

například, Boxsup zaměstnán vymezovací rámeček popisy jako dohled na vlak v síti a iterativně zlepšovat odhaduje masky pro sémantické segmentace. Jednoduché považuje omezení slabého dohledu za problém šumu vstupního štítku a prozkoumal rekurzivní trénink jako de-noising strategii. Pixel-úroveň Značení interpretovat segmentace úkol v rámci více-instance rámce učení a přidal další vrstvu omezit modelu přiřadit větší váhu důležité pixelů pro obraz-úroveň klasifikace.
Sémantické Segmentace s Plně-Konvoluční Sítě
V této části, pojďme se projít, krok-za-krokem provedení z nejpopulárnějších architektury pro sémantické segmentace — Plně-Konvoluční Sítě (FCN). Implementujeme ji pomocí knihovny TensorFlow v Pythonu 3, spolu s dalšími závislostmi, jako jsou Numpy a Scipy.In toto cvičení označíme pixely silnice v obrázcích pomocí FCN. Budeme pracovat s Datasetem Kitti Road pro detekci silnic/jízdních pruhů. To je jednoduché cvičení z Udacity je Self-Řídit Auto Nano-studijní program, který se můžete dozvědět více o nastavení v tomto GitHub repo.

Zde jsou klíčové funkce FCN architektury:
- FCN transfery znalostí od VGG16 provést sémantickou segmentaci.
- plně Spojené vrstvy VGG16 se převádějí na plně konvoluční vrstvy pomocí konvoluce 1×1. Tento proces vytváří tepelnou mapu přítomnosti třídy v nízkém rozlišení.
- převzorkování tyto nízké rozlišení sémantické funkce mapy je provedena pomocí je provedena konvoluce (inicializován s bilineární interpolace filtry).
- v každé fázi je proces převzorkování dále vylepšen přidáním funkcí z hrubších, ale vyšších map funkcí z nižších vrstev ve VGG16.
- Přeskočit připojení je zavedena po každém konvoluce blok umožní následné blok, aby extrahovat více abstraktní, třída-charakteristické rysy z dříve sdružené funkce.
existují 3 verze FCN (FCN-32, FCN-16, FCN-8). Implementujeme FCN-8, Jak je podrobně popsáno níže:
- Encoder: jako kodér se používá předem vyškolený Vgg16. Dekodér začíná od vrstvy 7 vgg16.
- FCN Layer-8: poslední plně připojená vrstva VGG16 je nahrazena konvolucí 1×1.
- FCN vrstva-9: FCN Layer-8 je převzorkována 2 krát tak, aby odpovídala rozměrům s vrstvou 4 VGG 16, pomocí transponované konvoluce s parametry: (kernel=(4,4), stride=(2,2), paddding=’same‘). Poté bylo přidáno spojení skip mezi vrstvou 4 vgg16 a FCN Layer-9.
- FCN Layer-10: FCN Layer-9 je převzorkována 2x tak, aby odpovídala rozměrům s vrstvou 3 vgg16, pomocí transponované konvoluce s parametry: (kernel=(4,4), stride=(2,2), paddding=’same‘). Poté bylo mezi vrstvu 3 VGG 16 a vrstvu FCN-10 přidáno přeskočení.
- FCN vrstva-11: FCN Vrstva-10 je upsampled 4 krát na zápas s rozměry vstupního obrazu velikosti, takže jsme získat skutečný obraz zpět a hloubka je roven počtu tříd, pomocí provedena konvoluce s parametry:(jádro=(16,16), krok=(8,8), paddding= „stejné“).
Krok 1
Jsme první zatížení pre-vyškoleni VGG-16 model do TensorFlow. Přičemž v TensorFlow zasedání a cestu k VGG Složky (který je ke stažení zde), můžeme vrátit n-tice tenzory z VGG model, včetně obrazu vstup, keep_prob (ovládání dropout rate), vrstva 3, vrstva 4, a vrstva 7.
def load_vgg(sess, vgg_path): # load the model and weights model = tf.saved_model.loader.load(sess, , vgg_path) # Get Tensors to be returned from graph graph = tf.get_default_graph() image_input = graph.get_tensor_by_name('image_input:0') keep_prob = graph.get_tensor_by_name('keep_prob:0') layer3 = graph.get_tensor_by_name('layer3_out:0') layer4 = graph.get_tensor_by_name('layer4_out:0') layer7 = graph.get_tensor_by_name('layer7_out:0') return image_input, keep_prob, layer3, layer4, layer7VGG16 funkce
Krok 2
Nyní se zaměříme na vytvoření vrstev pro FCN, pomocí tenzory z VGG model. Vzhledem k tenzorům pro výstup vrstvy VGG a počtu tříd, které se mají klasifikovat, vrátíme tenzor pro poslední vrstvu tohoto výstupu. Zejména použijeme konvoluci 1×1 na vrstvy kodéru a poté přidáme vrstvy dekodéru do sítě s přeskočením připojení a převzorkováním.
def layers(vgg_layer3_out, vgg_layer4_out, vgg_layer7_out, num_classes): # Use a shorter variable name for simplicity layer3, layer4, layer7 = vgg_layer3_out, vgg_layer4_out, vgg_layer7_out # Apply 1x1 convolution in place of fully connected layer fcn8 = tf.layers.conv2d(layer7, filters=num_classes, kernel_size=1, name="fcn8") # Upsample fcn8 with size depth=(4096?) to match size of layer 4 so that we can add skip connection with 4th layer fcn9 = tf.layers.conv2d_transpose(fcn8, filters=layer4.get_shape().as_list(), kernel_size=4, strides=(2, 2), padding='SAME', name="fcn9") # Add a skip connection between current final layer fcn8 and 4th layer fcn9_skip_connected = tf.add(fcn9, layer4, name="fcn9_plus_vgg_layer4") # Upsample again fcn10 = tf.layers.conv2d_transpose(fcn9_skip_connected, filters=layer3.get_shape().as_list(), kernel_size=4, strides=(2, 2), padding='SAME', name="fcn10_conv2d") # Add skip connection fcn10_skip_connected = tf.add(fcn10, layer3, name="fcn10_plus_vgg_layer3") # Upsample again fcn11 = tf.layers.conv2d_transpose(fcn10_skip_connected, filters=num_classes, kernel_size=16, strides=(8, 8), padding='SAME', name="fcn11") return fcn11Vrstvy funkce
Krok 3
další krok je, aby optimalizovat naše neuronové sítě, aka budování TensorFlow ztráta funkce a optimalizaci provozu. Zde používáme křížovou entropii jako naši ztrátovou funkci a Adam jako náš optimalizační algoritmus.
def optimize(nn_last_layer, correct_label, learning_rate, num_classes): # Reshape 4D tensors to 2D, each row represents a pixel, each column a class logits = tf.reshape(nn_last_layer, (-1, num_classes), name="fcn_logits") correct_label_reshaped = tf.reshape(correct_label, (-1, num_classes)) # Calculate distance from actual labels using cross entropy cross_entropy = tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=correct_label_reshaped) # Take mean for total loss loss_op = tf.reduce_mean(cross_entropy, name="fcn_loss") # The model implements this operation to find the weights/parameters that would yield correct pixel labels train_op = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(loss_op, name="fcn_train_op") return logits, train_op, loss_opOptimalizovat funkci,
Krok 4
Zde definujeme train_nn funkce, která bere v důležitých parametrů včetně počtu epoch, velikost dávky, ztráta funkce, optimalizaci provozu, a zástupné symboly pro vkládání obrázků, označení snímků, rychlost učení. Pro tréninkový proces jsme také nastavili keep_probability na 0.5 A learning_rate na 0.001. Chcete-li sledovat pokrok, vytiskneme také ztrátu během tréninku.
def train_nn(sess, epochs, batch_size, get_batches_fn, train_op, cross_entropy_loss, input_image, correct_label, keep_prob, learning_rate): keep_prob_value = 0.5 learning_rate_value = 0.001 for epoch in range(epochs): # Create function to get batches total_loss = 0 for X_batch, gt_batch in get_batches_fn(batch_size): loss, _ = sess.run(, feed_dict={input_image: X_batch, correct_label: gt_batch, keep_prob: keep_prob_value, learning_rate:learning_rate_value}) total_loss += loss; print("EPOCH {} ...".format(epoch + 1)) print("Loss = {:.3f}".format(total_loss)) print()Krok 5
konečně je čas trénovat naši síť! V této funkci spuštění nejprve sestavíme naši síť pomocí funkce load_vgg, layers a optimize. Poté trénujeme síť pomocí funkce train_nn a ukládáme data inference pro záznamy.
def run(): # Download pretrained vgg model helper.maybe_download_pretrained_vgg(data_dir) # A function to get batches get_batches_fn = helper.gen_batch_function(training_dir, image_shape) with tf.Session() as session: # Returns the three layers, keep probability and input layer from the vgg architecture image_input, keep_prob, layer3, layer4, layer7 = load_vgg(session, vgg_path) # The resulting network architecture from adding a decoder on top of the given vgg model model_output = layers(layer3, layer4, layer7, num_classes) # Returns the output logits, training operation and cost operation to be used # - logits: each row represents a pixel, each column a class # - train_op: function used to get the right parameters to the model to correctly label the pixels # - cross_entropy_loss: function outputting the cost which we are minimizing, lower cost should yield higher accuracy logits, train_op, cross_entropy_loss = optimize(model_output, correct_label, learning_rate, num_classes) # Initialize all variables session.run(tf.global_variables_initializer()) session.run(tf.local_variables_initializer()) print("Model build successful, starting training") # Train the neural network train_nn(session, EPOCHS, BATCH_SIZE, get_batches_fn, train_op, cross_entropy_loss, image_input, correct_label, keep_prob, learning_rate) # Run the model with the test images and save each painted output image (roads painted green) helper.save_inference_samples(runs_dir, data_dir, session, image_shape, logits, keep_prob, image_input)Spustit funkci,
O našich parametrů, můžeme si vybrat epoch = 40, batch_size = 16, num_classes = 2, a image_shape = (160, 576). Po provedení 2 zkušebních průchodů s dropout = 0.5 a dropout = 0.75 jsme zjistili, že 2. Pokus přináší lepší výsledky s lepšími průměrnými ztrátami.

vidět celý kód, podívejte se na tento odkaz: https://gist.github.com/khanhnamle1994/e2ff59ddca93c0205ac4e566d40b5e88
Pokud se vám to líbilo tento kus, Byl bych rád, sdílet je 👏 a šíření znalostí.
by Vás mohl zajímat náš nejnovější příspěvky na:
- AWS Textract
- Extrakce Dat
Začít používat Nanonets pro Automatizaci
Vyzkoušet model, nebo požádat o demo dnes!
zkuste nyní
