pap-stěr analysis tool (PAT) pro detekci rakoviny děložního hrdla od pap-rozmazání snímků
analýza Obrazu
analýza obrazu potrubí pro rozvoj pap-rozmazání nástroj pro analýzu souborů pro detekci rakoviny děložního hrdla od pap stěry prezentovány v této knize je zobrazen na Obr. 1.

přístup k dosažení děložního čípku detekce od pap-rozmazání snímků
snímání Obrazu
přístup byla hodnocena pomocí tří datových souborů. Dataset 1 se skládá z 917 jednotlivých buněk harlev pap-stěr obrazů připravených Jantzen et al. . Dataset obsahuje pap-rozmazání snímků pořízených s rozlišením 0.201 µm/pixel po kvalifikovaných cytopathologists pomocí mikroskopu připojeného k rámu grabber. Obrázky byly segmentovány pomocí komerčního softwaru CHAMP a poté rozděleny do sedmi tříd s odlišnými charakteristikami, jak je uvedeno v tabulce 2. Z těchto 200 obrázků bylo použito pro školení a 717 obrázků pro testování.
Dataset 2 se skládá z 497 full slide pap-rozmazání snímků připravil Norup et al. . Z těchto 200 obrázků bylo použito pro školení a 297 obrázků pro testování. Dále byl výkon klasifikátoru hodnocen na datovém souboru 3 vzorků 60 pap-nátěrů (30 normálních a 30 abnormálních) získaných z Mbarara Regional Referral Hospital (MRRH). Vzorky byly naskenovány pomocí Olympus BX51 světlé poli mikroskopu je vybaven 40×, 0.95 NA objektiv a Hamamatsu ORCA-05G 1.4 Mpx fotoaparát, monochromatický, což je velikost pixelu 0,25 µm s 8-bit šedá hloubky. Každý obrázek byl poté rozdělen na 300 oblastí, přičemž každá oblast obsahovala mezi 200 a 400 buňkami. Na základě stanoviska cytopathologists, 10 000 objektů v obrazech získaných z 60 různých pap-rozmazání snímků byly vybrány z nichž 8000 byly zdarma ležící cervikálních epiteliálních buněk (3000 normální buňky od normálních šmouhy a 5000 abnormální buňky s abnormální cytologií) a zbývající 2000 byly trosky. Tato segmentace Pap-stěru byla dosažena pomocí Trainable Weka Segmentation toolkit k vytvoření klasifikátoru segmentace na úrovni pixelů.
vylepšení obrazu
pro vylepšení obrazu byla použita kontrastní lokální adaptivní ekvalizace histogramu (CLAHE). V CLAHE, výběr clip-hranice, která určuje požadovaný tvar histogramu obrazu je rozhodující, jak je kriticky ovlivňuje kvalitu vylepšený obrázek. Optimální hodnota klipového limitu byla vybrána empiricky pomocí metody definované Josephem et al. . Optimální mezní hodnota klipu 2.0 bylo stanoveno jako vhodné pro zajištění adekvátního vylepšení obrazu při zachování tmavých funkcí pro použité datové sady. Konverze na stupně šedi byla dosažena technikou ve stupních šedi implementovanou pomocí Eq. 1, Jak je definováno v .
, kde R = Červená, G = Zelená a B = Modrá barva, příspěvky na nové image.
Aplikace CLAHE pro vylepšení obrazu za následek viditelné změny na obrázky úpravou obrazu intenzit, kde ztmavnutí jádro, stejně jako cytoplazma hranice, se stal snadno identifikovatelné pomocí clip limit 2.0.
segmentace scény
pro dosažení segmentace scény byl vyvinut klasifikátor úrovně pixelů pomocí Trainable Weka Segmentation (TWS) toolkit. Většina buněk pozorovaných v pap-nátěru nejsou překvapivě cervikální epiteliální buňky . Kromě toho jsou obvykle patrné různé počty leukocytů, erytrocytů a bakterií, zatímco někdy jsou pozorovány malé počty jiných kontaminujících buněk a mikroorganismů. Nicméně, pap-stěr obsahuje čtyři hlavní typy karcinomu z dlaždicových buněk děložního čípku—povrchní, střední, parabazálních a bazálních—z nichž povrchní a přechodné buňky představují naprostou většinu v konvenčním nátěru; proto tyto dva typy jsou obvykle používány pro konvenční pap-stěr pro analýzu . K identifikaci a segmentaci různých objektů na snímku byla použita trénovatelná segmentace Weka. V této fázi byl klasifikátor úrovně Pixelů vyškolen na identifikaci buněčných jader, cytoplazmy, pozadí a trosek pomocí kvalifikovaného cytopatologa pomocí Trainable Weka Segmentation (TWS) toolkit . Toho bylo dosaženo nakreslením čar / výběru prostřednictvím oblastí zájmu a jejich přiřazením k určité třídě. Pixely pod liniemi / výběrem byly považovány za zástupce jader, cytoplazmy, pozadí a zbytků.
obrysy nakreslené v každé třídě byly použity ke generování vektoru znaků \(\mathop F\limits^{ \to}\), který byl odvozen z počtu pixelů patřících ke každému obrysu. Vektor vlastností z každého obrázku (200 z datové sady 1 a 200 z datové sady 2) byl definován Eq. 2.
, kde Ni, Ci, Bi a Di jsou počet pixelů z jádra, cytoplasmy, pozadí a nečistoty z obrázku \(i\), jak je znázorněno na Obr. 2.

Generace příznakový vektor z trénovací obrázky
Každý pixel extrahované z obrázku představuje nejen jeho intenzita, ale také sadu obrazových funkcí, které obsahují mnoho informací včetně textury, ohraničení a barvy v pixelu prostor 0.201 µm2. Výběr vhodného vektoru funkcí pro výcvik klasifikátoru byl velkou výzvou a novým úkolem v navrhovaném přístupu. Klasifikátor úrovně Pixelů byl vyškolen pomocí celkem 226 tréninkových funkcí od TWS. V klasifikátor byl trénován pomocí sady TWS tréninkové funkce, které zahrnovaly: (i) Redukce Šumu: Kuwahara a Bilaterální filtry v TWS toolkit byly použity na trénovat klasifikátor na odstranění šumu. Tyto byly hlášeny vynikající filtry pro odstranění šumu, při zachování okrajů , (ii) Detekce Hran: Sobel filtr , Hessian matice a Gabor filtru byly použity pro výcvik třídění na hranici detekce v obraze, a (iii) filtrování Textury: Pro filtrování textur byly použity filtry průměr, rozptyl, medián, maximum, minimum a entropie.
odstranění Nečistot
hlavním důvodem pro aktuální omezení mnoha stávajících automatizovaných pap-stěr analýza systémů je, že se snaží překonat složitost pap-stěr struktur, tím, že se snaží analyzovat snímku jako celku, které často obsahují více buněk a nečistot. To má potenciál způsobit selhání algoritmu a vyžaduje vyšší výpočetní výkon . Vzorky jsou pokryty artefakty-jako jsou krevní buňky, překrývající se a složené buňky a bakterie-které brání segmentačním procesům a vytvářejí velké množství podezřelých objektů. Bylo prokázáno, že klasifikátory určené k rozlišení mezi normálními buňkami a prekancerózními buňkami obvykle produkují nepředvídatelné výsledky, pokud existují artefakty v pap-nátěru . V tomto nástroji je technika identifikace buněk děložního čípku pomocí třífázového sekvenčního eliminačního schématu(znázorněného na obr. 3) se používá.

Tři-fáze sekvenční přístup pro odstranění nečistot odmítnutí
navrhované tři-fáze eliminace režimu postupně odstraňuje nečistoty z pap stěru, pokud to považují za nepravděpodobné, že by čípku buněk. Tento přístup je prospěšný, protože umožňuje v každé fázi učinit rozhodnutí o nižším rozměru.
analýza velikosti
analýza velikosti je soubor postupů pro stanovení rozsahu měření velikosti částic . Oblast je jedním z nejzákladnějších rysů používaných v oblasti automatizované cytologie k oddělení buněk od zbytků. Analýza pap-stěru je dobře studovaným oborem s mnohem předchozími znalostmi týkajícími se vlastností buněk . Jednou z klíčových změn při hodnocení oblasti jádra je však to, že rakovinné buňky procházejí podstatným zvýšením velikosti jádra . Proto je stanovení horní prahové hodnoty velikosti, která systematicky nevylučuje diagnostické buňky, mnohem těžší, ale má tu výhodu, že snižuje vyhledávací prostor. Metoda uvedená v tomto článku je založena na nižší velikosti a horním prahu velikosti cervikálních buněk. Pseudokód pro přístup je uveden v Eq. 3.
, kde \(Area_{max} = 85,267\,{\upmu \text{m}}^{2}\) a \(Area_{min} = 625\,{\upmu \text{m}}^{2}\) odvozená z Tabulky 2.
objekty na pozadí jsou považovány za trosky, a proto jsou z obrázku vyřazeny. Částice, které spadají mezi \(Area_{min}\) a \(Area_{max}\), jsou dále analyzovány během dalších fází analýzy textury a tvaru.
analýza tvaru
tvar objektů v pap-nátěru je klíčovým rysem diferenciace mezi buňkami a zbytky . Existuje řada metod pro detekci popisu tvaru a zahrnují přístupy založené na regionech a obrysech . Region-based metody jsou méně citlivé na šum, ale více výpočetně náročné, vzhledem k tomu, že obrys-based metody jsou poměrně účinné pro výpočet, ale více citlivé na hluk . V tomto článku byla použita metoda založená na regionech (perimeter2 / area (P2A)). Deskriptor P2A byl vybrán na základě toho, že popisuje podobnost objektu s kruhem. Díky tomu je dobře vhodný jako deskriptor buněčného jádra, protože jádra mají obecně kruhový vzhled. P2A je také označována jako tvarová kompaktnost a je definována Eq. 4.
kde c je hodnota tvar, kompaktnost, je plocha a p je obvod jádra. Předpokládalo se, že trosky jsou objekty s hodnotou P2A větší než 0,97 nebo menší než 0,15 podle výcvikových prvků (znázorněných v tabulce 2).
analýza textur
textura je velmi důležitou charakteristickou vlastností, která může rozlišovat mezi jádry a zbytky. Textura obrazu je sada metrik navržených pro kvantifikaci vnímané textury obrazu . V rámci pap-nátěru je distribuce průměrné intenzity jaderných skvrn mnohem užší než variace intenzity skvrn mezi objekty trosek . Tato skutečnost byla použita jako základ pro odstranění zbytků na základě jejich intenzity obrazu a barevné informace pomocí Zernike moments (ZM). Zernikovy momenty jsou použita pro různé aplikace rozpoznávání vzorů a je známo, že být robustní s ohledem na hluk a mají dobrý rekonstrukce napájení. V této práci, ZM, jak je uvedeno Malm et al. řádu n s opakováním I funkce \(f\left( {r,\theta } \right)\), v polárních souřadnicích uvnitř disku na střed v čtvercový obraz \(\left( {x,y} \right)\), velikost \(m \times m\) je dána Rovnicí. Byl použit 5.
\(v_{nl }^{*} \left( {r,\theta } \right)\) značí komplexně sdružené číslo z Zernikovy polynom \(v_{nl} \left( {r,\theta } \right)\). Pro vytvoření míry textury jsou zprůměrovány veličiny z \(A_{nl}\) vystředěné na každý pixel v obrázku textury .
extrakce vlastností
úspěch klasifikačního algoritmu do značné míry závisí na správnosti funkcí extrahovaných z obrázku. Buňky v pap stěry v souboru údajů jsou rozděleny do sedmi tříd na základě charakteristik, jako je velikost, plocha, tvar a jas jádra a cytoplazmy. Funkce extrahované z obrázků zahrnovaly morfologické rysy dříve používané ostatními . V této knize tři geometrické vlastnosti (pevnost, kompaktnost a excentricity) a šest textových funkcí (průměr, směrodatná odchylka, rozptyl, plynulost, energie a entropie), byly také získané z jádra, což vede k 29 funkce v celkem jak je uvedeno v Tabulce 3.
Funkce výběr
Funkce výběr je proces výběru podmnožiny extrahované vlastnosti, které dávají nejlepší výsledky klasifikace. Mezi těmito extrahovanými funkcemi mohou některé obsahovat šum, zatímco vybraný klasifikátor nemusí využívat jiné. Proto musí být stanovena optimální sada funkcí, případně vyzkoušením všech kombinací. Pokud však existuje mnoho funkcí, možné kombinace explodují v počtu, což zvyšuje výpočetní složitost algoritmu. Algoritmy pro výběr funkcí jsou široce rozděleny do metod filtru, obalu a vložených metod .
metoda používaná nástrojem kombinuje simulované žíhání s přístupem obalu. Tento přístup byl navržen v but, v tomto článku, výkon výběru funkcí je hodnocen pomocí algoritmu náhodného lesa s dvojitou strategií . Simulované žíhání je pravděpodobnostní technika pro aproximaci globálního Optima dané funkce. Tento přístup je vhodný pro zajištění výběru optimální sady funkcí. Hledání optimální sady se řídí hodnotou fitness . Po dokončení simulovaného žíhání se porovnají všechny různé podmnožiny vlastností a vybere se nejvhodnější (tj. Hledání fitness hodnoty bylo získáno pomocí obalu, kde byla k-fold křížová validace použita k výpočtu chyby na klasifikačním algoritmu. Různé kombinace z extrahovaných prvků jsou připraveny, vyhodnoceny a porovnány s jinými kombinacemi. Prediktivní model se pak používá k vyhodnocení kombinace funkcí a přiřazení skóre na základě přesnosti modelu. Fitness chyba daná obalem se používá jako fitness chyba simulovaným algoritmem žíhání. Algoritmus fuzzy C-means byl zabalen do černé skříňky, ze které byla získána odhadovaná chyba pro různé kombinace funkcí, jak je znázorněno na obr. 4.

fuzzy C-means je zabaleno do černé krabice, z nichž odhadem chyba je získal
Fuzzy C-znamená, že umožňuje data bodů v souboru dat patří všechny klastry, se členství v intervalu (0-1), jak je znázorněno v Rovnici. 6.
, kde \(m_{ik}\) je členství pro datový bod, k do clusteru center jsem, \(d_{jk}\) je vzdálenost od clusteru centrum j údajů písm. k a q € je exponent, který rozhodne, jak silný členství by mělo být. Algoritmus fuzzy C-means byl implementován pomocí fuzzy Toolboxu v Matlabu.
defuzzifikace
algoritmus fuzzy C-means nám neříká, jaké informace klastry obsahují a jak mají být tyto informace použity pro klasifikaci. Definuje však, jak jsou datovým bodům přiřazena členství v různých klastrech, a toto fuzzy členství se používá k předpovědi třídy datového bodu . To je překonáno defuzzifikací. Existuje řada metod defuzzifikace . V tomto nástroji má však každý cluster fuzzy členství (0-1) všech tříd v obrázku. Tréninková data jsou přiřazena nejbližšímu klastru. Procento tréninkových dat každé třídy patřící do clusteru a dává členství clusteru, cluster a = různým třídám, kde i je kontejnment v clusteru a A j v druhém clusteru. Míra intenzity je přidána do funkce členství pro každý cluster pomocí algoritmu fuzzy clustering defuzzification. Populární přístup pro defuzzifikaci fuzzy oddílu je použití principu maximálního stupně členství, kde je datový bod k přiřazen třídě M, pokud je jeho stupeň členství \(m_{ik}\) do clusteru i největší. Chuang et al. navrhovaná úprava stavu členství každého datového bodu pomocí stavu členství jeho sousedů.
V navrhovaném přístupu, defuzzification metoda založená na Bayesovské pravděpodobnosti se používá k vytvořit pravděpodobnostní model funkce členství pro každý datový bod a použít model k obrazu produkovat klasifikace informací. Pravděpodobnostní model je vypočítán níže:
-
převést distribuce možností v matici oddílů (clustery) na distribuce pravděpodobnosti.
-
Vytvořte pravděpodobnostní model datových distribucí jako v .
-
použijte model k vytvoření klasifikačních informací pro každý datový bod pomocí Eq. 7.
, kde \(P\left( {A_{i} } \right),i = 0 \ldots .c\) je předchozí pravděpodobnost \(a_{i}\), kterou lze vypočítat pomocí metody, kde předchozí pravděpodobnost je vždy úměrná hmotnosti každé třídy.
počet clusterů, které mají být použity, byl stanoven, aby bylo zajištěno, že postavený model dokáže popsat data co nejlépe. Pokud je vybráno příliš mnoho klastrů, existuje riziko nadměrného přizpůsobení šumu v datech. Pokud je vybráno příliš málo klastrů, může být výsledkem špatný klasifikátor. Proto byla provedena analýza počtu klastrů proti chybě testu křížové validace. Bylo dosaženo optimálního počtu 25 shluků a došlo k přetrénování nad tento počet shluků. Exponent defuzzifikace 1.0930 byl získán s 25 klastrů, desetinásobné křížové validace a 60 repríz a byla použita pro výpočet fitness chyba pro výběr funkcí, kde celkem 18 funkcí z 29 funkce, bylo vybráno pro výstavbu třídění. Vybrané funkce jsou: jádro oblasti; jádro šedá úrovni; jádro nejkratší průměru; jádro nejdelší; jádro obvodu; maxima v jádře; minima v jádře; cytoplazma oblasti; cytoplazma šedá úrovni; cytoplazma obvodu; jádra do cytoplazmy poměr, excentricita jádro, jádro, směrodatná odchylka, jádro šedé úroveň rozptylu; jádra šedé úroveň entropie; relativní poloha jádra; průměr úrovně jádra šedé a jádro šedé hodnoty energie.
Klasifikace hodnocení
V této knize, hierarchický model účinnosti diagnostické zobrazovací systémy navržené Fryback a Thornbury byla přijata jako vůdčí princip pro hodnocení nástroj, jak je znázorněno v Tabulce 4.
Citlivost měří podíl skutečných poplachů, které jsou správně označeny jako takové vzhledem k tomu, specifičnost opatření podíl skutečné negativy, které jsou správně označeny jako takové. Citlivost a specificita jsou popsány Eq. 8.
kde TP = správný pozitivní, FN = Falešně negativní, TN = správný negativní a FP = Falešně pozitivní.
výše popsané metody zpracování obrazu byly implementovány v Matlabu a jsou prováděny pomocí grafického uživatelského rozhraní Java (GUI) znázorněného na obr. 5. Nástroj má panel, kde pap-rozmazání obrazu je načten a cytotechnician vybere vhodnou metodu pro scénu segmentace (na základě TWS klasifikátor), suti (založené na třech sekvenční eliminace přístupu) a hranici detekce (je-li to považováno za nezbytné, použití Canny detekce hran metoda), po které funkce jsou extrahovány pomocí extraktu funkce tlačítka.
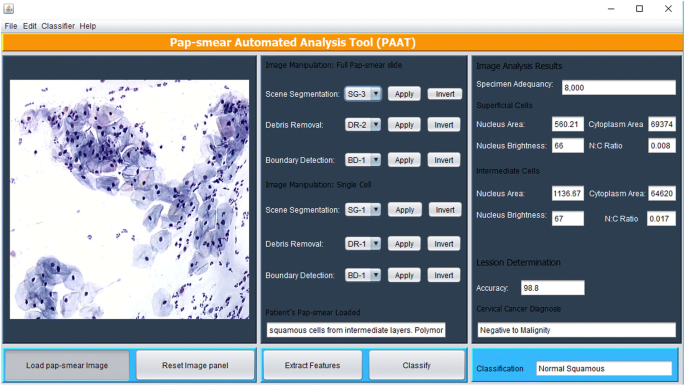
PAT grafické uživatelské rozhraní,
nástroj prohledá prostřednictvím pap-stěr analyzovat všechny objekty, které zůstaly po odstranění nečistot. 18 funkcí popsaných ve výběru funkcí je extrahováno z každého objektu a použito ke klasifikaci každé buňky pomocí algoritmu fuzzy C-means popsaného v klasifikační metodě. Náhodně extrahované vlastnosti jedné povrchové buňky a jedné mezilehlé buňky jsou zobrazeny na panelu výsledků analýzy obrazu. Jakmile funkce byly extrahovány, cytotechnician (uživatel) stiskne tlačítko klasifikovat a nástroj vydává diagnózy (pozitivní pro malignitu nebo negativní malignity) a klasifikuje se diagnóza do jedné ze 7 tříd/stádiích rakoviny děložního čípku, jako na školení dataset.