seaborn.histplot¶
seaborn.histplot(data=None, *, x=None, y=None, hue=None, závaží=None, stat= „počítat“, bins=’auto‘, binwidth=None, binrange=None, diskrétní=None, pro kumulativní=False, common_bins=True, common_norm=True, více=’vrstva‘, element= „tyčí“, fill=True, zmenšit=1, kde=False, kde_kws=None, line_kws=None, thresh=0, pthresh=None, pmax=None, cbar=False, cbar_ax=None, cbar_kws=None, paleta=None, hue_order=None, hue_norm=None, color=None, log_scale=None, legenda=True, ax=None, **kwargs)¶
univariate Plot nebo bivariační histogramy ukázat distribucí sad.
histogram je klasický vizualizační nástroj, který představuje distribuci jedné nebo více proměnných počítáním počtu pozorování, které spadají do koše.
Tato funkce může normalizovat statistiky vypočtené v každém koši estimatefrequency, hustotu nebo pravděpodobnost hmoty, a to může přidat hladkou křivku obtainedusing jádrovým odhadem hustoty, podobné kdeplot().
Více informací naleznete v uživatelské příručce.
Parametry datapandas.DataFramenumpy.ndarray, mapování, nebo sekvence
Vstupní datové struktury. Buď dlouhoformátový soubor vektorů, který lze přiřadit k pojmenovaným proměnným, nebo širokoformátový dataset, který bude internalizován.
x, yvektory nebo klíče vdata
proměnné, které určují pozice na osách x a y.
huevector nebo klíč vdata
Sémantické proměnná, která je mapována určit barvu dějové prvky.
weightsvector nebo klíč vdata
Pokud za předpokladu, hmotnost příspěvku odpovídající údaje pointstowards počítat v každém bin těmito faktory.
stat {„počet“,“ frekvence“,“ hustota“,“ pravděpodobnost“}
Souhrnná statistika pro výpočet v každém bin.
-
countudává počet pozorování -
frequencyudává počet pozorování děleno šířkou -
densitynormalizuje se počítá tak, že oblast histogramu je 1 -
probabilitynormalizuje se počítá tak, že součet bar výšky je 1,
binsstr, číslo, vektor, nebo pár z těchto hodnot
Generic bin parametr, který může být název referenční pravidlo,počet přihrádek, nebo přestávky košů.Předáno numpy.histogram_bin_edges().
binwidthnumber nebo dvojice čísel
Šířka každého bin, přepíše bins, ale může být použit sbinrange.
binrangepair čísel nebo dvojice párů
nejnižší a nejvyšší hodnota pro okraje bin; lze použít buď s bins nebo binwidth. Výchozí hodnoty jsou datové extrémy.
discretebool
Pokud je to Pravda, default binwidth=1 a kreslit tyče tak, aby se arecentered na jejich odpovídající datové body. Tím se zabrání „mezerám“, které mohoujinak se objeví při použití diskrétních (celočíselných) dat.
cumulativebool
Pokud je to pravda, vykreslete kumulativní počty jako zvýšení zásobníků.
common_binsbool
Pokud je to pravda, použijte stejné koše, když sémantické proměnné produkují multipleplots. Pokud k určení zásobníků použijete referenční pravidlo, bude vypočtenas úplnou datovou sadou.
common_normbool
Pokud je pravda a používá normalizovanou statistiku, normalizace bude platit nad celou datovou sadou. Jinak normalizujte každý histogram nezávisle.
multiple {„layer“,“ dodge“,“ stack“,“ fill“}
přístup k řešení více prvků, když sémantické mapování vytvoří podmnožiny.Relevantní pouze s jednorozměrnými údaji.
element{„bars“,“ step“,“ poly“}
vizuální reprezentace statistiky histogramu.Relevantní pouze s jednorozměrnými údaji.
fillbool
Pokud je to pravda, vyplňte mezeru pod histogramem.Relevantní pouze s jednorozměrnými údaji.
shrinknumber
měřítko šířky každého pruhu vzhledem k binwidth tímto faktorem.Relevantní pouze s jednorozměrnými údaji.
kdebool
Pokud je to pravda, Vypočítejte odhad hustoty jádra pro vyhlazení distribucea zobrazit na grafu jako (jeden nebo více) řádek (y).Relevantní pouze s jednorozměrnými údaji.
kde_kwsdict
parametry, které řídí výpočet KDE, jako v kdeplot().
line_kwsdict
parametry, které řídí vizualizaci KDE, předánymatplotlib.axes.Axes.plot().
threshnumber nebo None
buňky se statistikou menší nebo rovnou této hodnotě budou transparentní.Relevantní pouze u bivariátních údajů.
pthreshnumber nebo Žádný
Jako thresh, ale hodnotu v tak, že buňky s agregátní počítá(nebo další statistiky, pokud je použit) se na tento podíl na celkových bude betransparent.
pmaxnumber nebo None
hodnota, která nastaví bod nasycení pro barevnou mapu na hodnotu, kterou buňky níže představují, tento podíl celkového počtu (nebo jiná statistika, pokud je použita).
cbarbool
Pokud je to Pravda, přidejte colorbar komentovat mapování barev v bivariační pozemku.Poznámka: v současné době nepodporuje grafy s proměnnou hue.
cbar_axmatplotlib.axes.Axes
již existující osy pro barevný panel.
cbar_kwsdict
další parametry předané matplotlib.figure.Figure.colorbar().
palettestring, list, dict, nebomatplotlib.colors.Colormap
Metoda pro výběr barvy použít při mapování hue sémantické.Hodnoty řetězců jsou předány color_palette(). Hodnoty seznamu nebo dictjednoduše kategorické mapování, zatímco objekt colormap znamená numerické mapování.
hue_ordervector řetězců
Určete pořadí zpracování a vykreslování pro kategorické úrovněhue sémantické.
hue_normtuple nebomatplotlib.colors.Normalize
buď dvojice hodnot, které nastavují normalizační rozsah v datových jednotkách, nebo objekt, který bude mapovat z datových jednotek do intervalu. Usageimplikuje numerické mapování.
barvymatplotlib color
jednobarevné specifikaci, když odstín mapování není používán. V opačném případě se theplot pokusí připojit do cyklu vlastností matplotlib.
log_scalebool nebo číslo, nebo pár knih nebo čísla
Nastavit log měřítko na datové ose (nebo osách, s bivariate dat) s thegiven základny (výchozí 10), a zhodnotit, KDE v protokolu prostor.
legendbool
Pokud je nepravdivý, potlačte legendu pro sémantické proměnné.
axmatplotlib.axes.Axes
již existující osy pro graf. V opačném případě volejte matplotlib.pyplot.gca() interně.
kwargs
další argumenty klíčových slov jsou předány jedné z následujících matplotlibfunctions:
-
matplotlib.axes.Axes.bar()(univariate, element=“bars“) -
matplotlib.axes.Axes.fill_between()(univariate, other element, fill=True) -
matplotlib.axes.Axes.plot()(univariate, other element, fill=False) -
matplotlib.axes.Axes.pcolormesh()(bivariate)
Returnsmatplotlib.axes.Axes
The matplotlib axes containing the plot.
See also
displot
Figure-level interface to distribution plot functions.
kdeplot
vykreslete jednorozměrné nebo bivariátní distribuce pomocí odhadu hustoty jádra.
rugplot
vykreslete klíště na každé pozorovací hodnotě podél OS x a/nebo y.
ecdfplot
Plot empirické kumulativní distribuční funkce.
jointplot
nakreslete bivariátní graf s jednorozměrnými okrajovými distribucemi.
poznámky
výběr zásobníků pro výpočet a Vykreslování histogramu může mít podstatný vliv na poznatky, které je možné čerpat z vizualizace. Pokud jsou koše příliš velké, mohou vymazat důležité funkce.Na druhou stranu, koše, které jsou příliš malé, mohou být ovládány náhodnou variabilitou, zakrývající tvar skutečné základní distribuce. Výchozí bin velikost je určena pomocí referenčního pravidlo, že záleží na vzorek velikosti a rozptylu. V mnoha případech to funguje dobře (tj. s“dobře vychovanými“ daty), ale v jiných selhává. Vždy je dobré to zkusitrůzné velikosti koše, abyste se ujistili, že vám něco důležitého nechybí.Tato funkce umožňuje zadat přihrádek v několika různých způsoby, jako je asby nastavení celkový počet košů k použití, šířka každého koše, nebo na specifická místa, kde popelnic by měly pauzu.
Příklady
Přiřadit proměnné na x k vykreslení jednorozměrné rozložení podél osy x:
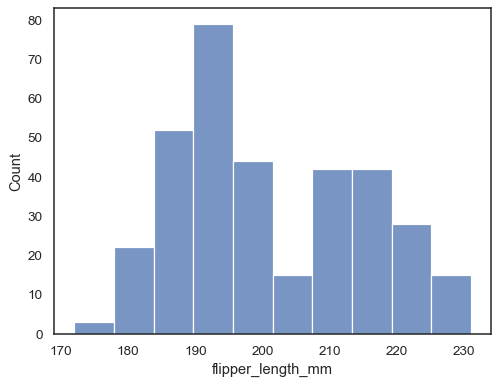
penguins = sns.load_dataset("penguins")sns.histplot(data=penguins, x="flipper_length_mm")
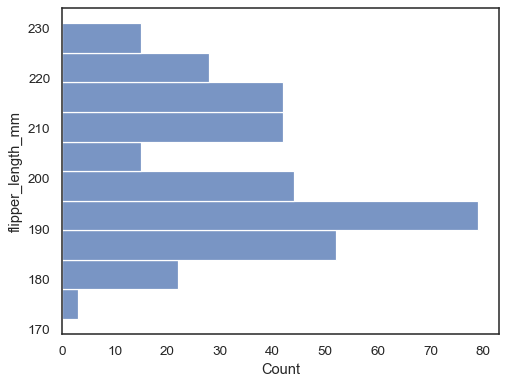
Flip děj přiřazením dat proměnné na ose y,
sns.histplot(data=penguins, y="flipper_length_mm")
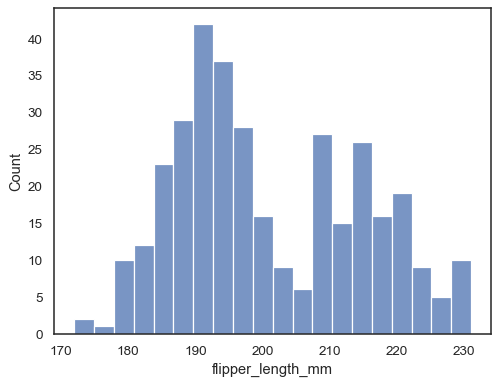
Zkontrolovat, jak dobře histogram představuje data zadáním jiné bin šířka:
sns.histplot(data=penguins, x="flipper_length_mm", binwidth=3)
můžete také definovat celkový počet košů k použití:
sns.histplot(data=penguins, x="flipper_length_mm", bins=30)
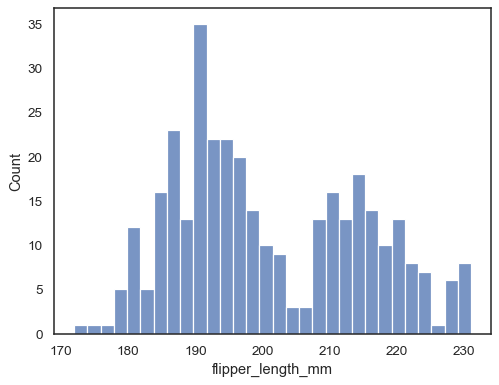
Přidat jádrovým odhadem hustoty k vyhlazení histogramu, providingcomplementary informace o tvaru rozdělení:
sns.histplot(data=penguins, x="flipper_length_mm", kde=True)
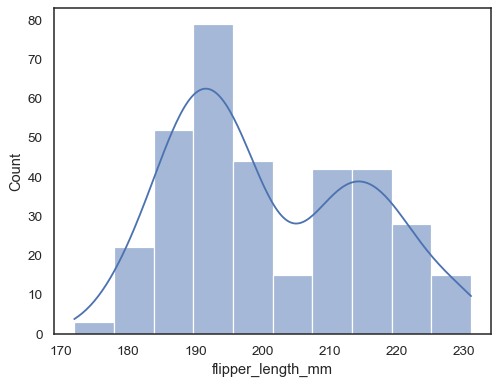
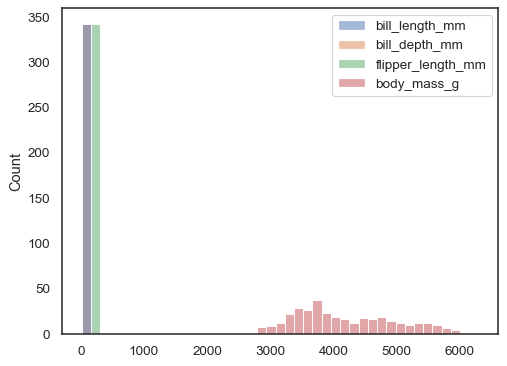
Pokud ani jeden x ani y je přiřazen datový soubor je zacházeno aswide-formě, a histogram je vypracován pro každý číselný sloupec:
sns.histplot(data=penguins)
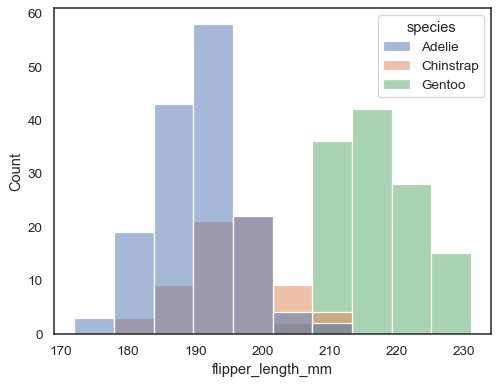
můžete jinak nakreslit více histogramy z dlouhé-formu dataset withhue mapování:
sns.histplot(data=penguins, x="flipper_length_mm", hue="species")
výchozí přístup k vykreslování více distribucí je „vrstva“ je, ale můžete také „stack“ je:
sns.histplot(data=penguins, x="flipper_length_mm", hue="species", multiple="stack")
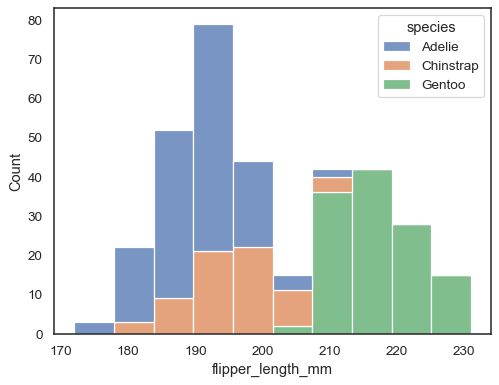
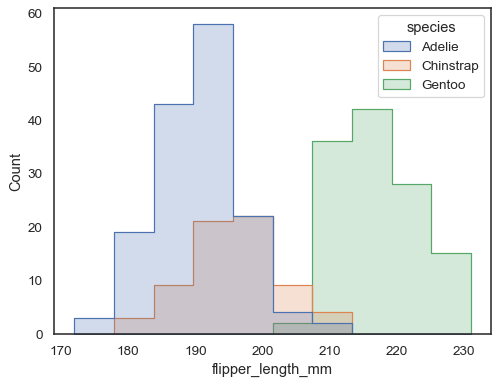
překrývající se pruhy lze těžko vizuálně vyřešit. Jiný approachwould být kreslit krok funkce:
sns.histplot(penguins, x="flipper_length_mm", hue="species", element="step")
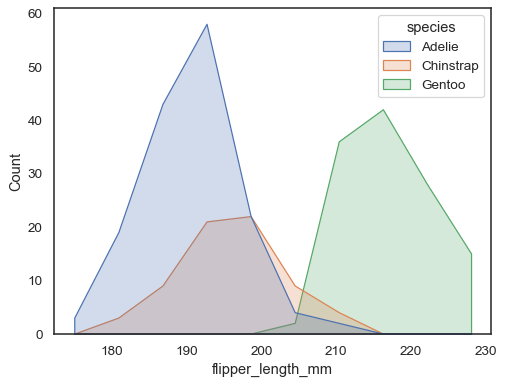
můžete se pohybovat ještě dále od tyčí nakreslením mnohoúhelníku svertice ve středu každého koše. To může usnadnit viděttvar distribuce, ale používejte s opatrností: pro vaše publikum bude méně zřejmé, že se dívají na histogram:
sns.histplot(penguins, x="flipper_length_mm", hue="species", element="poly")
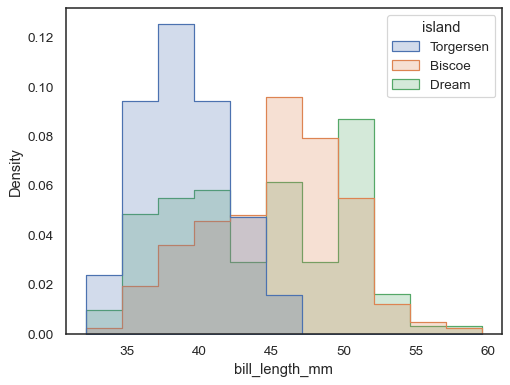
porovnat rozdělení podskupin, které se liší podstatně insize, použijte indepdendent hustota normalizace:
sns.histplot( penguins, x="bill_length_mm", hue="island", element="step", stat="density", common_norm=False,)
je také možné, aby normalizovat tak, že každý panel je výška ukazuje aprobability, které tvoří větší smysl pro diskrétní proměnné:
tips = sns.load_dataset("tips")sns.histplot(data=tips, x="size", stat="probability", discrete=True)
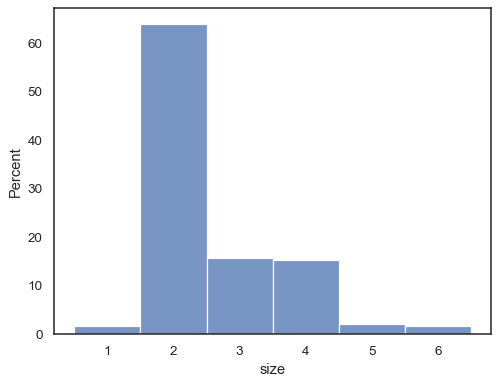
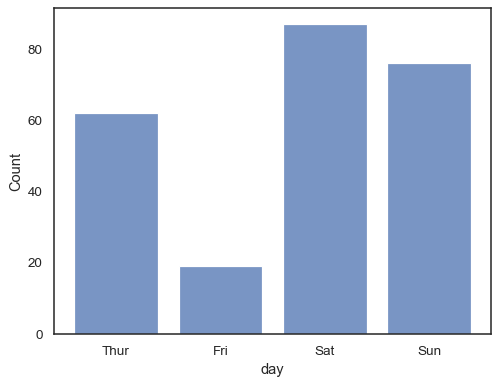
můžete Si dokonce nakreslit histogram přes kategorické proměnné (i když je to experimentální funkce):
sns.histplot(data=tips, x="day", shrink=.8)
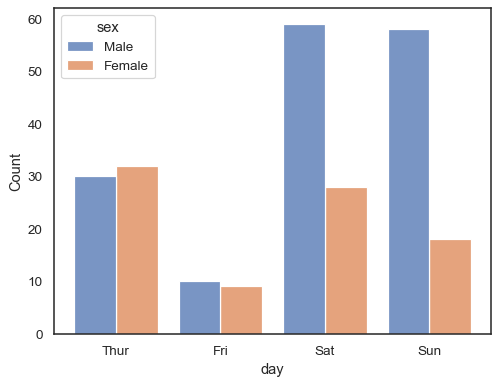
Při použití hue sémantické s diskrétní údaje, může to mít smysl, aby se“vyhnout“ úrovních:
sns.histplot(data=tips, x="day", hue="sex", multiple="dodge", shrink=.8)
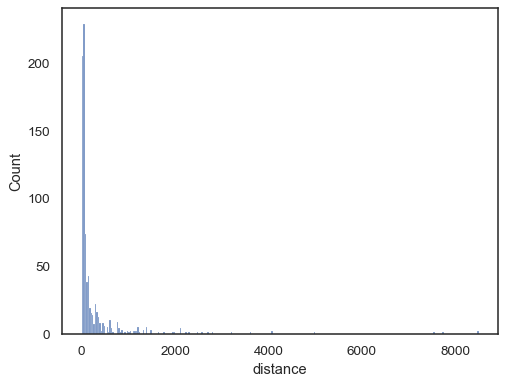
reálná data jsou často zkreslená. U silně zkosených distribucí je lepší definovat koše v prostoru protokolu. Porovnat:
planets = sns.load_dataset("planets")sns.histplot(data=planets, x="distance")
To the log-scale version:
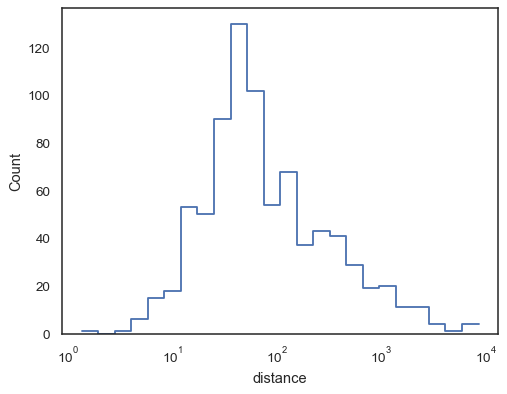
sns.histplot(data=planets, x="distance", log_scale=True)
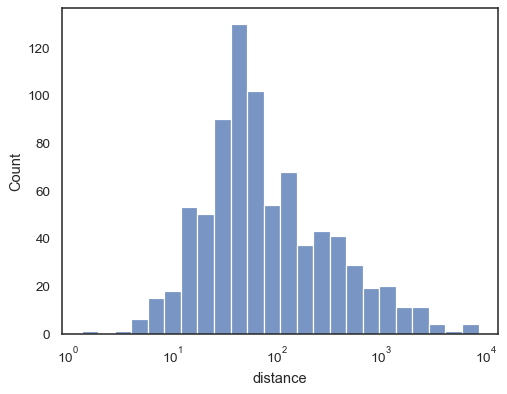
There are also a number of options for how the histogram appears. Youcan show unfilled bars:
sns.histplot(data=planets, x="distance", log_scale=True, fill=False)
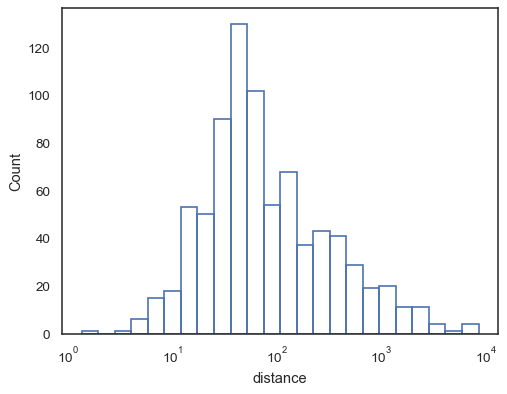
Or an unfilled step function:
sns.histplot(data=planets, x="distance", log_scale=True, element="step", fill=False)
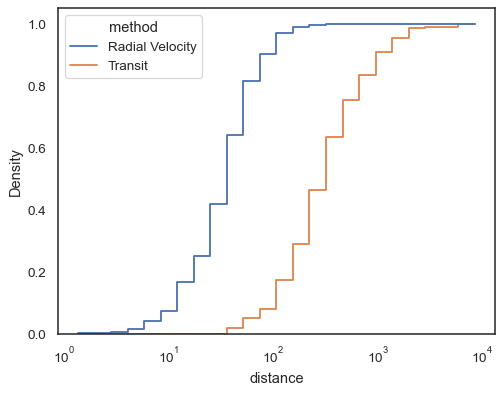
Krok funkce, esepcially když nevyplněné, aby bylo snadné comparecumulative histogramy:
sns.histplot( data=planets, x="distance", hue="method", hue_order=, log_scale=True, element="step", fill=False, cumulative=True, stat="density", common_norm=False,)
Když xy jsou přiřazeny, a dvě histogram iscomputed a zobrazuje jako heatmap:
sns.histplot(penguins, x="bill_depth_mm", y="body_mass_g")
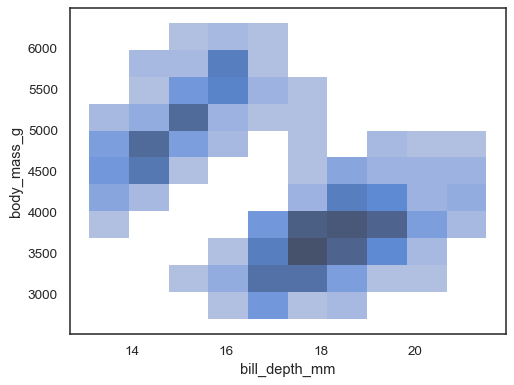
je možné přiřadit hue variabilní taky, i když to bude nepráce no, pokud data z různých úrovní mají značné překrývání:
sns.histplot(penguins, x="bill_depth_mm", y="body_mass_g", hue="species")
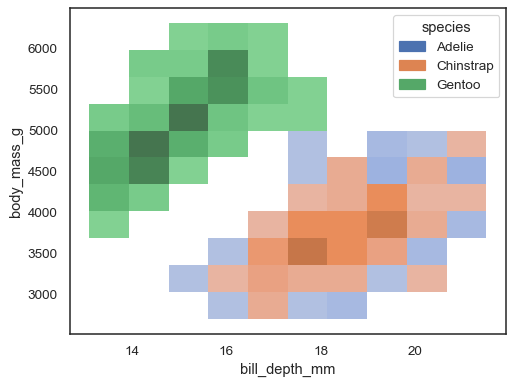
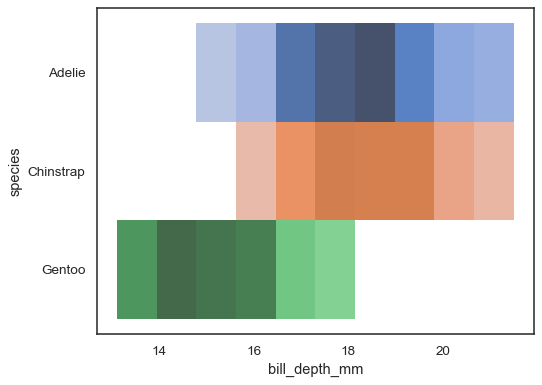
Více barevné mapy mohou smysl, když jedna z proměnných isdiscrete:
sns.histplot( penguins, x="bill_depth_mm", y="species", hue="species", legend=False)
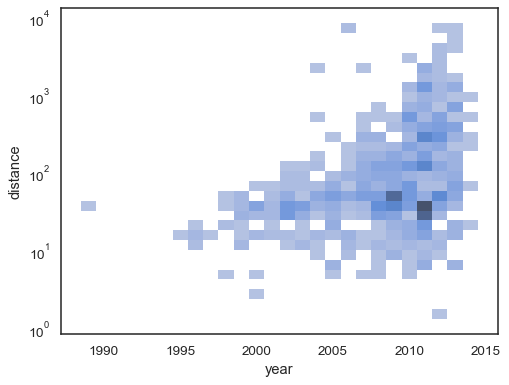
bivariační histogram přijímá všechny stejné možnosti pro computationas jeho jednorozměrných protějšek, pomocí n-tic pro parametrizovat xy nezávisle
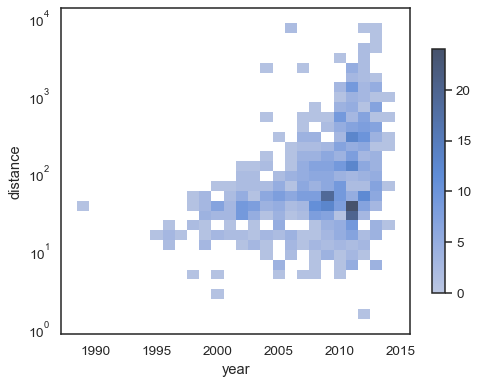
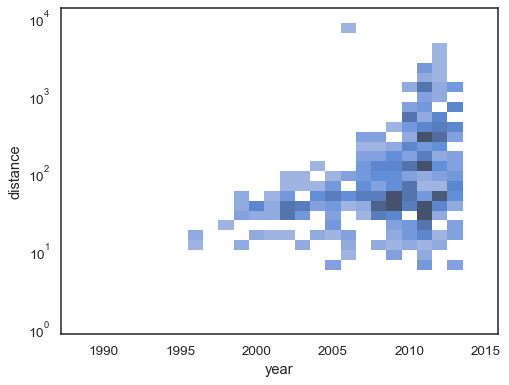
sns.histplot( planets, x="year", y="distance", bins=30, discrete=(True, False), log_scale=(False, True),)
výchozí chování činí buňky s žádné připomínky transparentní,i když to může být vypnuto:
sns.histplot( planets, x="year", y="distance", bins=30, discrete=(True, False), log_scale=(False, True), thresh=None,)
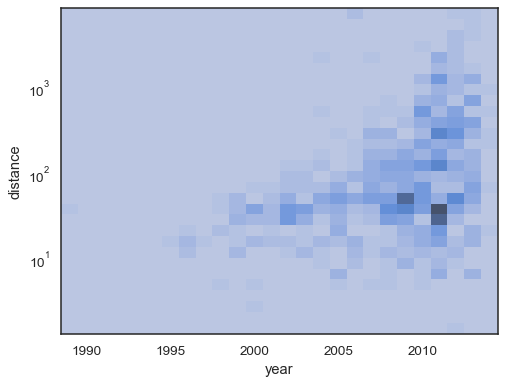
je také možné nastavit práh a colormap bodu nasycení, má podíl kumulativní počty:
sns.histplot( planets, x="year", y="distance", bins=30, discrete=(True, False), log_scale=(False, True), pthresh=.05, pmax=.9,)
anotovat do mapy, přidat colorbar:
sns.histplot( planets, x="year", y="distance", bins=30, discrete=(True, False), log_scale=(False, True), cbar=True, cbar_kws=dict(shrink=.75),)