et pap-smear-analyseværktøj (PAT) til påvisning af livmoderhalskræft fra pap-smear-billeder
billedanalyse
billedanalyserørledningen til udvikling af et pap-smear-analyseværktøj til påvisning af livmoderhalskræft fra pap-smears præsenteret i dette papir er afbildet i Fig. 1.

fremgangsmåden til opnåelse af påvisning af livmoderhalskræft fra pap-smear-billeder
billedoptagelse
fremgangsmåden blev vurderet ved hjælp af tre datasæt. Datasæt 1 består af 917 enkeltceller af Harlev pap-smear billeder udarbejdet af Jantsen et al. . Datasættet indeholder pap-smear-billeder taget med en opløsning på 0,201 liter af dygtige cytopatologer ved hjælp af et mikroskop forbundet til en rammegribber. Billederne blev segmenteret ved hjælp af Champ-kommercielle programmer og derefter klassificeret i syv klasser med forskellige egenskaber som vist i tabel 2. Af disse 200 billeder blev brugt til træning og 717 billeder til test.
datasæt 2 består af 497 fuld slide pap-smear billeder udarbejdet af Norup et al. . Af disse 200 billeder blev brugt til træning og 297 billeder til test. Desuden blev klassificeringens ydeevne evalueret på datasæt 3 af prøver af 60 pap-udstrygninger (30 normale og 30 unormale) opnået fra Mbarara Regional Referral Hospital (MRRH). Prøver blev afbildet ved hjælp af et Olympus Bh 51 lysfeltmikroskop udstyret med et 40 liter, 0,95 NA-objektiv og et Hamamatsu ORCA-05G 1,4 MP monokromt kamera, hvilket gav en billedstørrelse på 0,25 liter med 8-bit grå dybde. Hvert billede blev derefter opdelt i 300 områder, hvor hvert område indeholdt mellem 200 og 400 celler. Baseret på cytopatologernes meninger blev der valgt 10.000 objekter i billeder afledt af de 60 forskellige pap-smear-dias, hvoraf 8000 var frie liggende cervikale epitelceller (3000 normale celler fra normale udstrygninger og 5000 unormale celler fra unormale udstrygninger) og de resterende 2000 var affaldsgenstande. Denne Pap-smear segmentering blev opnået ved hjælp af Trainable segmentering Toolkit til at konstruere en segmentering klassifikator.
billedforbedring
en kontrast lokal adaptiv histogramudligning (CLAHE) blev anvendt på gråtonebilledet til billedforbedring . I CLAHE er valget af klipgrænse, der specificerer den ønskede form af billedets histogram, altafgørende, da det kritisk påvirker kvaliteten af det forbedrede billede. Den optimale værdi af klipgrænsen blev valgt empirisk ved hjælp af metoden defineret af Joseph et al. . En optimal clip grænseværdi på 2.0 blev bestemt til at være passende til at tilvejebringe tilstrækkelig billedforbedring, samtidig med at de mørke funktioner for de anvendte datasæt bevares. Konvertering til gråtoner blev opnået ved hjælp af en gråtoneteknik implementeret ved hjælp af EKV. 1 som defineret i .
hvor R = rød, G = grøn og B = blå farvebidrag til det nye billede.
anvendelse af CLAHE til billedforbedring resulterede i mærkbare ændringer i billederne ved at justere billedintensiteter, hvor mørkningen af kernen såvel som cytoplasmens grænser blev let identificerbar ved hjælp af en klipgrænse på 2,0.
Scenesegmentering
for at opnå scenesegmentering blev der udviklet en klassifikator for billedniveau ved hjælp af værktøjssæt, der kan trænes. Størstedelen af celler observeret i en pap-smear er ikke overraskende cervikale epitelceller . Derudover er varierende antal leukocytter, erythrocytter og bakterier normalt tydelige, mens der undertiden observeres et lille antal andre forurenende celler og mikroorganismer. Imidlertid, pap-smear indeholder fire hovedtyper af pladeformede cervikale celler-overfladisk, mellemliggende, parabasal og basal—hvoraf overfladiske og mellemliggende celler repræsenterer det overvældende flertal i en konventionel udstrygning; derfor bruges disse to typer normalt til en konventionel pap-smear-analyse . En trainable segmentering blev brugt til at identificere og segmentere de forskellige objekter på diaset. På dette stadium blev en klassifikator uddannet på cellekerner, cytoplasma, baggrunds-og affaldsidentifikation ved hjælp af en dygtig cytopatolog ved hjælp af Trainable segmentering toolkit . Dette blev opnået ved at tegne linjer/udvælgelse gennem interesseområderne og tildele dem til en bestemt klasse. Billedpunkterne under linjerne/udvælgelsen blev taget for at være repræsentant for kernerne, cytoplasma, baggrund og affald.
konturerne tegnet inden for hver klasse blev brugt til at generere en funktionsvektor, \(\mathop F\limits^{ \to}\), som blev afledt af antallet af billedpunkter, der tilhører hver kontur. Funktionsvektoren fra hvert billede (200 fra datasæt 1 og 200 fra datasæt 2) blev defineret af Ek. 2.
hvor Ni, Ci, Bi og Di er antallet af billedpunkter fra kernen, cytoplasma, baggrund og snavs af billedet \(i\) som vist i Fig. 2.

generering af funktionsvektoren fra træningsbillederne
hvert billede, der er ekstraheret fra billedet, repræsenterer ikke kun dens intensitet, men også et sæt billedfunktioner, der indeholder en masse information, herunder tekstur, grænser og farve inden for et billedområde på 0,201 liter 2. At vælge en passende funktionsvektor til træning af klassifikatoren var en stor udfordring og en ny opgave i den foreslåede tilgang. Klassificeringsenheden blev trænet ved hjælp af i alt 226 træningsfunktioner. I) støjreduktion: de bilaterale filtre i værktøjssættet blev brugt til at træne klassifikatoren i støjfjernelse. Disse er rapporteret at være fremragende filtre til fjernelse af støj, samtidig med at kanterne bevares, (ii) kantdetektion: et Sobel-filter, hessisk Matrice og Gabor-filter blev brugt til at træne klassifikatoren i grænsedetektion i et billede og (iii) teksturfiltrering: Middel -, varians -, median -, maksimum -, minimum-og entropifiltrene blev brugt til teksturfiltrering.
fjernelse af affald
hovedårsagen til de nuværende begrænsninger i mange af de eksisterende automatiserede pap-smear-analysesystemer er, at de kæmper for at overvinde kompleksiteten af pap-smear-strukturer ved at forsøge at analysere diaset som helhed, som ofte indeholder flere celler og snavs. Dette har potentialet til at forårsage algoritmens fiasko og kræver højere beregningskraft . Prøver er dækket af artefakter—såsom blodlegemer, overlappende og foldede celler og bakterier—der hæmmer segmenteringsprocesserne og genererer et stort antal mistænkelige genstande. Det har vist sig, at klassifikatorer designet til at skelne mellem normale celler og prækræftceller normalt producerer uforudsigelige resultater, når der findes artefakter i pap-smear . I dette værktøj er en teknik til at identificere livmoderhalsceller ved hjælp af et trefaset sekventielt eliminationsskema (afbildet i Fig. 3) anvendes.

trefaset sekventiel eliminationsmetode til afvisning af affald
det foreslåede trefasede eliminationsskema fjerner sekventielt affald fra pap-smear, hvis det skønnes at være usandsynligt at være en livmoderhalscelle. Denne tilgang er gavnlig, da den gør det muligt at træffe en lavere dimensionel beslutning på hvert trin.
Størrelsesanalyse
Størrelsesanalyse er et sæt procedurer til bestemmelse af en række størrelsesmålinger af partikler . Området er en af de mest basale funktioner, der anvendes inden for automatiseret cytologi til at adskille celler fra affald. Pap-smear-analysen er et velundersøgt felt med meget forudgående viden om celleegenskaber . En af de vigtigste ændringer med vurdering af kerneområdet er imidlertid, at kræftceller gennemgår en betydelig stigning i nuklear størrelse . Derfor er det meget sværere at bestemme en øvre størrelsestærskel, der ikke systematisk udelukker diagnostiske celler, men har fordelen ved at reducere søgepladsen. Metoden præsenteret i dette papir er baseret på en lavere størrelse og øvre størrelse tærskel for de cervikale celler. Pseudokoden for fremgangsmåden er vist i Ek. 3.
hvor \(Area_{maks} = 85.267\,{\upmu \tekst{m}}^{2}\) og \(Area_{min} = 625\,{\upmu \tekst{m}}^{2}\) afledt af tabel 2.
objekterne i baggrunden betragtes som affald og kasseres således fra billedet. Partikler, der falder mellem \(Area_{min}\) og \(Area_{maks}\) analyseres yderligere i de næste faser af struktur-og formanalyse.
Formanalyse
formen på objekterne i en pap-udstrygning er en nøglefunktion i differentieringen mellem celler og affald . Der er en række metoder til detektion af formbeskrivelse, og disse inkluderer regionsbaserede og konturbaserede tilgange . Regionsbaserede metoder er mindre følsomme over for støj, men mere beregningsintensive, mens konturbaserede metoder er relativt effektive til at beregne, men mere følsomme over for støj . I dette papir er der anvendt en regionbaseret metode (perimeter2/område (P2A)). P2A-deskriptoren blev valgt på den fortjeneste, at den beskriver ligheden mellem et objekt og en cirkel. Dette gør det velegnet som en cellekernebeskrivelse, da kerner generelt er cirkulære i deres udseende. P2A kaldes også formkompaktitet og er defineret af EKV. 4.
hvor c er værdien af formkompaktitet, A er området og p er omkredsen af kernen. Affald blev antaget at være objekter med en P2A-værdi større end 0,97 eller mindre end 0,15 i henhold til træningsfunktionerne (afbildet i tabel 2).
Teksturanalyse
tekstur er et meget vigtigt karakteristisk træk, der kan skelne mellem kerner og affald. Billedtekstur er et sæt metrics designet til at kvantificere den opfattede tekstur af et billede . Inden for en pap-udstrygning er fordelingen af den gennemsnitlige nukleare pletintensitet meget snævrere end variationen i pletintensiteten blandt affaldsgenstande . Denne kendsgerning blev brugt som grundlag for at fjerne snavs baseret på deres billedintensiteter og farveinformation ved hjælp af Nulmomenter . Moderne øjeblikke bruges til en række applikationer til mønstergenkendelse og er kendt for at være robuste med hensyn til støj og have en god genopbygningskraft. I dette arbejde, mm som præsenteret af Malm et al. af rækkefølge n med gentagelse i af funktion \(f\left ({r, \ theta }\ right)\), i polære koordinater inde i en disk centreret i firkantet billede\(i \left( {h,y}\ right)\) af størrelse \(m\ gange m\) givet af Ek. 5 blev brugt.
\(v_ {nl} ^ { * }\left ({r, \Theta}\right)\) betegner det komplekse konjugat af det nuværende polynom\(V_ {nl } \Left ({r,\ Theta} \right)\). For at producere et teksturmål beregnes størrelsen fra \(a_{nl}\) centreret ved hvert punkt i teksturbilledet i gennemsnit .
funktionsekstraktion
succesen med en klassificeringsalgoritme afhænger i høj grad af rigtigheden af de funktioner, der udvindes fra billedet. Cellerne i pap-smears i det anvendte datasæt er opdelt i syv klasser baseret på egenskaber som størrelse, areal, form og lysstyrke af kernen og cytoplasma. Funktionerne ekstraheret fra billederne inkluderede morfologifunktioner, der tidligere blev brugt af andre . I dette papir blev der også ekstraheret tre geometriske træk (soliditet, kompaktitet og ekscentricitet) og seks tekstfunktioner (gennemsnit, standardafvigelse, varians, glathed, energi og entropi) fra kernen, hvilket resulterede i 29 funktioner i alt som vist i tabel 3.
Feature selection
Feature selection er processen med at vælge undergrupper af de ekstraherede funktioner, der giver de bedste klassificeringsresultater. Blandt de funktioner, der udvindes, kan nogle indeholde støj, mens den valgte klassifikator muligvis ikke bruger andre. Derfor skal et optimalt sæt funktioner bestemmes, muligvis ved at prøve alle kombinationer. Men når der er mange funktioner, eksploderer de mulige kombinationer i antal, og dette øger algoritmens beregningskompleksitet. Feature udvælgelse algoritmer er bredt klassificeret i filteret, indpakning og indlejrede metoder .
metoden, der anvendes af værktøjet, kombinerer simuleret udglødning med en indpakningsmetode. Denne tilgang er blevet foreslået i men, i dette papir, udførelsen af funktionsvalget evalueres ved hjælp af en tilfældig skovalgoritme med dobbelt strategi . Simuleret udglødning er en probabilistisk teknik til tilnærmelse af det globale optimale for en given funktion. Fremgangsmåden er velegnet til at sikre, at det optimale sæt funktioner vælges. Søgningen efter det optimale sæt styres af en fitnessværdi . Når simuleret udglødning er færdig, sammenlignes alle de forskellige undergrupper af funktioner, og den stærkeste (det vil sige den, der udfører bedst) vælges. Fitnessværdisøgningen blev opnået med en indpakning, hvor k-fold krydsvalidering blev brugt til at beregne fejlen på klassificeringsalgoritmen. Forskellige kombinationer fra de ekstraherede funktioner fremstilles, evalueres og sammenlignes med andre kombinationer. En forudsigelig model bruges derefter til at evaluere en kombination af funktioner og tildele en score baseret på modelnøjagtighed. Den fitnessfejl, der gives af indpakningen, bruges som fitnessfejl af den simulerede udglødningsalgoritme. En uklar C-middelalgoritme blev pakket ind i en sort boks, hvorfra der blev opnået en estimeret fejl for de forskellige funktionskombinationer som vist i Fig. 4.

det uklare C-middel er pakket ind i en sort boks, hvorfra der opnås en estimeret fejl
uklar C-midler tillader data punkter i datasættet skal tilhøre alle klyngerne med medlemskaber i intervallet (0-1) som vist i EKV. 6.
hvor \(m_{ik}\) er medlemskabet for datapunkt k til klyngecenter i, \(d_{jk}\) er afstanden fra klyngecenter j til datapunkt k, og K er en eksponent, der bestemmer, hvor stærk medlemskabet skal være. Den uklare C-betyder algoritme blev implementeret ved hjælp af den uklare værktøjskasse i Matlab.
defusion
en uklar C-betyder algoritme fortæller os ikke, hvilke oplysninger klyngerne indeholder, og hvordan disse oplysninger skal bruges til klassificering. Det definerer dog, hvordan datapunkter tildeles medlemskab af de forskellige klynger, og dette uklare medlemskab bruges til at forudsige klassen for et datapunkt . Dette overvindes gennem forvirring. Der findes en række defusionsmetoder . I dette værktøj har hver klynge imidlertid et uklar medlemskab (0-1) af alle klasser i billedet. Træningsdata tildeles den klynge, der er tættest på den. Procentdelen af træningsdata for hver klasse, der tilhører klynge a, giver klyngens medlemskab, klynge A = til de forskellige klasser, hvor I er indeslutningen i klynge A og j i den anden klynge. Intensitetsforanstaltningen føjes til medlemsfunktionen for hver klynge ved hjælp af en uklar klyngedefusionsalgoritme. En populær tilgang til defusion af uklar partition er anvendelsen af princippet om maksimal medlemsgrad, hvor datapunkt k er tildelt klasse m, hvis og kun hvis dens medlemsgrad \(m_{ik}\) til klynge i, er den største. Chuang et al. foreslået at justere medlemskabsstatus for hvert datapunkt ved hjælp af naboernes medlemsstatus.
i den foreslåede tilgang bruges en defusionsmetode baseret på bayesisk Sandsynlighed til at generere en probabilistisk model af medlemsfunktionen for hvert datapunkt og anvende modellen på billedet for at producere klassificeringsoplysningerne. Den probabilistiske model beregnes som nedenfor:
-
konverter mulighedsfordelingerne i partitionsmatricen (klynger) til sandsynlighedsfordelinger.
-
Konstruer en probabilistisk model af datafordelingerne som i .
-
Anvend modellen til at fremstille klassificeringsoplysningerne for hvert datapunkt ved hjælp af EKV. 7.
hvor \(p\venstre( {a_{i} } \højre),i = 0 \ldots .c\) er den forudgående Sandsynlighed for \(a_{i}\), som kan beregnes ved hjælp af metoden, hvor den forudgående sandsynlighed altid er proportional med massen af hver klasse.
antallet af klynger, der skal bruges, blev bestemt for at sikre, at den byggede model kan beskrive dataene på den bedst mulige måde. Hvis der vælges for mange klynger, er der risiko for overfitting af støj i dataene. Hvis der vælges for få klynger, kan en dårlig klassifikator være resultatet. Derfor blev der udført en analyse af antallet af klynger mod krydsvalideringstestfejlen. Et optimalt antal på 25 klynger blev opnået, og overtræning fandt sted over dette antal klynger. En deficification eksponent af 1.0930 blev opnået med 25 klynger, ti gange krydsvalidering og 60 genudsendelser og blev brugt til at beregne fitnessfejlen til valg af funktion, hvor i alt 18 funktioner ud af de 29 funktioner blev valgt til konstruktion af klassifikatoren. De valgte funktioner var: kerneområde; nucleus grå niveau; nucleus korteste diameter; nucleus længste; nucleus perimeter; Maksima i nucleus; minima i nucleus; cytoplasma område; cytoplasma grå niveau; cytoplasma perimeter; nucleus til cytoplasma ratio; nucleus ekscentricitet, nucleus standardafvigelse, nucleus grå niveau varians; nucleus grå niveau entropi; nucleus relativ position; nucleus grå niveau middelværdi og nucleus grå værdier energi.
Klassificeringsevaluering
i dette papir blev den hierarkiske model for effektiviteten af diagnostiske billeddannelsessystemer foreslået af Fryback og Thornbury vedtaget som et vejledende princip for evalueringen af værktøjet som vist i tabel 4.
følsomhed måler andelen af faktiske positive, der er korrekt identificeret som sådan, mens specificitet måler andelen af faktiske negativer, der er korrekt identificeret som sådan. Følsomhed og specificitet er beskrevet af MK. 8.
hvor TP = sande positiver, FN = falske negativer, TN = sande negativer og FP = falske positiver.
GUI design og integration
billedbehandlingsmetoderne beskrevet ovenfor blev implementeret i Matlab og udføres via en Java graphical user interface (GUI) vist i Fig. 5. Værktøjet har et panel, hvor et pap-smear-billede er indlæst, og cytoteknikeren vælger en passende metode til scenesegmentering (baseret på to-klassifikator), fjernelse af affald (baseret på de tre sekventielle eliminationsmetoder) og grænsedetektion (hvis det skønnes nødvendigt ved hjælp af Canny edge-detektionsmetode), hvorefter funktioner ekstraheres ved hjælp af knappen ekstraktfunktioner.
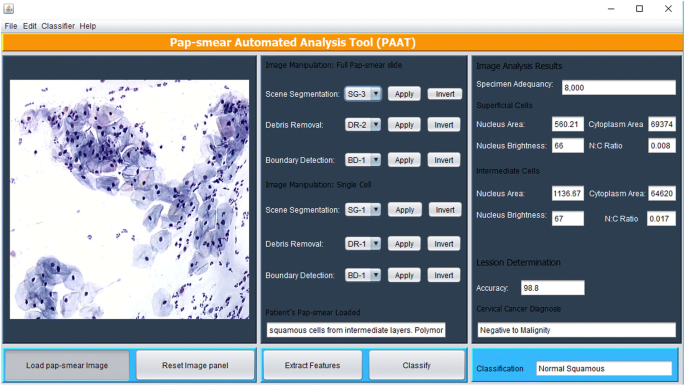
PAT grafisk brugergrænseflade
værktøjet scanner gennem pap-smear for at analysere alle de objekter, der blev tilbage efter fjernelse af affald. De 18 funktioner, der er beskrevet i funktionsvalg, ekstraheres fra hvert objekt og bruges til at klassificere hver celle ved hjælp af den uklare C-middelalgoritme, der er beskrevet i klassificeringsmetoden. Tilfældigt vises ekstraherede funktioner i en overfladisk celle og en mellemcelle i billedanalyseresultatpanelet. Når funktionerne er blevet ekstraheret, trykker cytoteknikeren (brugeren) på klassificeringsknappen, og værktøjet udsender en diagnose (positiv til malignitet eller negativ til malignitet) og klassificerer diagnosen til en af de 7 klasser/stadier af livmoderhalskræft i henhold til træningsdatasættet.