Sådan gør du semantisk segmentering ved hjælp af dyb læring
Denne artikel er en omfattende oversigt, herunder en trinvis vejledning til implementering af en dyb læringsbilledsegmenteringsmodel.
Vi delte en ny opdateret blog om semantisk segmentering her: en 2021-guide til semantisk segmentering
i dag er semantisk segmentering et af de vigtigste problemer inden for computersyn. Når man ser på det store billede, er semantisk segmentering en af de opgaver på højt niveau, der baner vejen mod fuldstændig sceneforståelse. Betydningen af sceneforståelse som et centralt computersynsproblem fremhæves af det faktum, at et stigende antal applikationer nærer fra at udlede viden fra billeder. Nogle af disse applikationer inkluderer selvkørende køretøjer, interaktion mellem mennesker og Computere, virtual reality osv. Med populariteten af dyb læring i de senere år håndteres mange semantiske segmenteringsproblemer ved hjælp af dybe arkitekturer, oftest indviklede neurale net, der overgår andre tilgange med stor margin med hensyn til nøjagtighed og effektivitet.
- Hvad er semantisk segmentering?
- hvad er de eksisterende semantiske segmenteringsmetoder?
- 1-Regionbaseret semantisk segmentering
- 2 — fuldt Konvolutionær netværksbaseret semantisk segmentering
- 3 — svagt Overvåget semantisk segmentering
- gør semantisk segmentering med fuldt Konvolutionært netværk
- trin 1
- Trin 2
- Trin 3
- Trin 4
- Trin 5
- du er måske interesseret i vores seneste indlæg på:
Hvad er semantisk segmentering?
semantisk segmentering er et naturligt trin i progressionen fra grov til fin slutning:oprindelsen kunne være placeret ved klassificering, som består i at forudsige et helt input.Det næste trin er lokalisering / detektion, som ikke kun giver klasserne, men også yderligere oplysninger om den rumlige placering af disse klasser.Endelig opnår semantisk segmentering finkornet slutning ved at lave tætte forudsigelser, der udleder etiketter for hvert punkt, så hvert punkt er mærket med klassen af dets omsluttende objektmalm region.
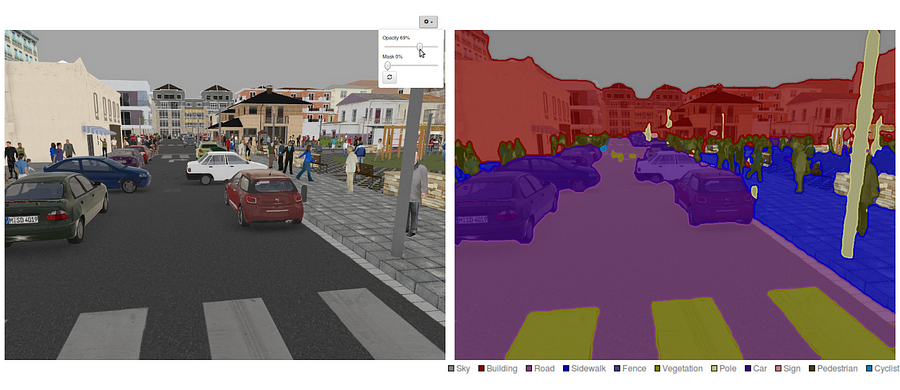
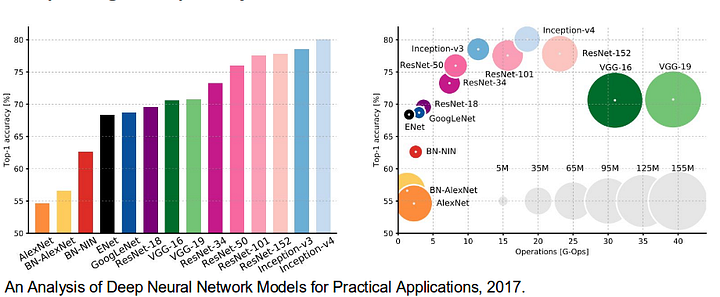
det er også værd at gennemgå nogle standard dybe netværk, der har ydet betydelige bidrag til området for computersyn, da de ofte bruges som grundlag for semantiske segmenteringssystemer:
- aleksnet: Torontos banebrydende dybe CNN, der vandt ImageNet-konkurrencen i 2012 med en Testnøjagtighed på 84,6%. Den består af 5 sammenfaldende lag, maks.pooling, ReLUs som ikke-linearitet, 3 fuldt udfoldede lag og frafald.
- VGG-16: Denne model vandt ImageNet-konkurrencen i 2013 med 92,7% nøjagtighed. Det bruger en stak foldningslag med små modtagelige felter i de første lag i stedet for få lag med store modtagelige felter.
- GoogLeNet: dette Googles netværk vandt ImageNet-konkurrencen i 2014 med en nøjagtighed på 93, 3%. Det er sammensat af 22 lag og en nyligt introduceret byggesten kaldet inception module. Modulet består af et netværk-i-netværk lag, en pooling operation, en stor størrelse foldning lag, og lille størrelse foldning lag.
- ResNet: denne Microsofts model vandt ImageNet-konkurrencen i 2016 med 96, 4% nøjagtighed. Det er velkendt på grund af dets dybde (152 lag) og indførelsen af resterende blokke. De resterende blokke løser problemet med at træne en virkelig dyb arkitektur ved at introducere identity skip-forbindelser, så lag kan kopiere deres input til det næste lag.
hvad er de eksisterende semantiske segmenteringsmetoder?
en generel semantisk segmenteringsarkitektur kan bredt betragtes som et kodernetværk efterfulgt af et dekodernetværk:
- koderen er normalt et forududdannet klassificeringsnetværk som VGG/ResNet efterfulgt af et dekodernetværk.dekoderens opgave er semantisk at projicere de diskriminerende funktioner (lavere opløsning), som koderen lærer på billedrummet (højere opløsning) for at få en tæt klassificering.
i modsætning til klassificering, hvor slutresultatet af det meget dybe netværk er det eneste vigtige, kræver semantisk segmentering ikke kun diskrimination på billedniveau, men også en mekanisme til at projicere de diskriminerende funktioner, der læres på forskellige stadier af koderen, på billedrummet. Forskellige tilgange anvender forskellige mekanismer som en del af afkodningsmekanismen. Lad os undersøge de 3 vigtigste tilgange:
1-Regionbaseret semantisk segmentering
de regionbaserede metoder følger generelt pipelinen “segmentering ved hjælp af genkendelse”, som først udtrækker friformede regioner fra et billede og beskriver dem efterfulgt af regionbaseret klassificering. På testtidspunktet omdannes de regionsbaserede forudsigelser til billedforudsigelser, normalt ved at mærke et billedpunkt i henhold til det område, der indeholder det med den højeste score.
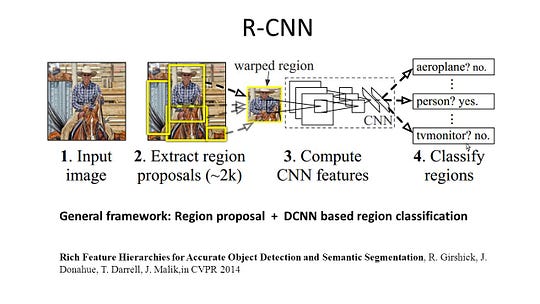
R-CNN (regioner med CNN-funktion) er et repræsentativt arbejde for de regionbaserede metoder. Det udfører den semantiske segmentering baseret på objektdetekteringsresultaterne. For at være specifik bruger R-CNN først selektiv søgning til at udtrække en stor mængde objektforslag og beregner derefter CNN-funktioner for hver af dem. Endelig klassificerer den hver region ved hjælp af de klassespecifikke lineære SVM ‘ er. Sammenlignet med traditionelle CNN-strukturer, der hovedsageligt er beregnet til billedklassificering, kan R-CNN adressere mere komplicerede opgaver, såsom objektdetektering og billedsegmentering, og det bliver endda et vigtigt grundlag for begge felter. Desuden kan R-CNN bygges oven på nogen CNN benchmark strukturer, såsom Aleksnet, VGG, GoogLeNet og ResNet.
til billedsegmenteringsopgaven udpakkede R-CNN 2 typer funktioner for hver region: fuld regionsfunktion og forgrundsfunktion og fandt ud af, at det kunne føre til bedre ydeevne, når de sammenkædes som regionfunktionen. R-CNN opnåede betydelige præstationsforbedringer på grund af brugen af de meget diskriminerende CNN-funktioner. Det lider dog også af et par ulemper ved segmenteringsopgaven:
- funktionen er ikke kompatibel med segmenteringsopgaven.
- funktionen indeholder ikke nok geografisk information til præcis grænsegenerering.
- generering af segmentbaserede forslag tager tid og vil i høj grad påvirke den endelige præstation.
på grund af disse flaskehalse er nyere forskning blevet foreslået for at løse problemerne, herunder SDS, Hypercolumns, Mask R-CNN.
2 — fuldt Konvolutionær netværksbaseret semantisk segmentering
det oprindelige fuldt Konvolutionære netværk (FCN) lærer en kortlægning fra billedpunkter til billedpunkter uden at udtrække regionforslagene. FCN-netværksledningen er en udvidelse af den klassiske CNN. Hovedideen er at få den klassiske CNN til at tage billeder i vilkårlig størrelse. Begrænsningen af CNN ‘ er til kun at acceptere og producere etiketter til input i specifik størrelse kommer fra de fuldt tilsluttede lag, der er faste. I modsætning til dem har FCN ‘ er kun konvolutionære og pooling lag, som giver dem mulighed for at lave forudsigelser om vilkårlig størrelse input.
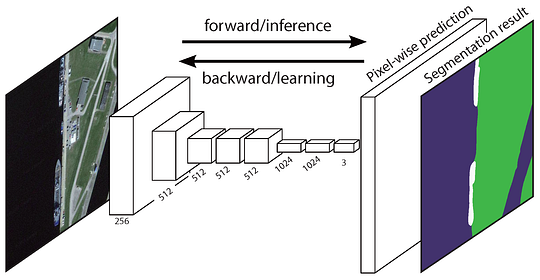
et problem i denne specifikke FCN er, at ved at forplante sig gennem flere vekslede convolutional og pooling lag, er opløsning af output funktion kort er ned samplet. Derfor er de direkte forudsigelser af FCN typisk i lav opløsning, hvilket resulterer i relativt uklare objektgrænser. En række mere avancerede FCN-baserede tilgange er blevet foreslået for at løse dette problem, herunder SegNet, DeepLab-CRF og udvidede svingninger.
3 — svagt Overvåget semantisk segmentering
de fleste af de relevante metoder i semantisk segmentering er afhængige af et stort antal billeder med billedvis segmenteringsmasker. Men manuelt at kommentere disse masker er ret tidskrævende, frustrerende og kommercielt dyrt. Derfor er nogle svagt overvågede metoder for nylig blevet foreslået, som er dedikeret til at opfylde den semantiske segmentering ved at anvende annoterede afgrænsningsbokse.

for eksempel anvendte Boksup afgrænsningsboksens annoteringer som et tilsyn til at træne netværket og iterativt forbedre de estimerede masker til semantisk segmentering. Enkel behandlede den den svage overvågningsbegrænsning som et spørgsmål om inputmærkestøj og udforskede rekursiv træning som en de-noising-strategi. Mærkning på billedniveau fortolkede segmenteringsopgaven inden for læringsrammen med flere forekomster og tilføjede et ekstra lag for at begrænse modellen til at tildele større vægt til vigtige billedpunkter til klassificering af billedniveau.
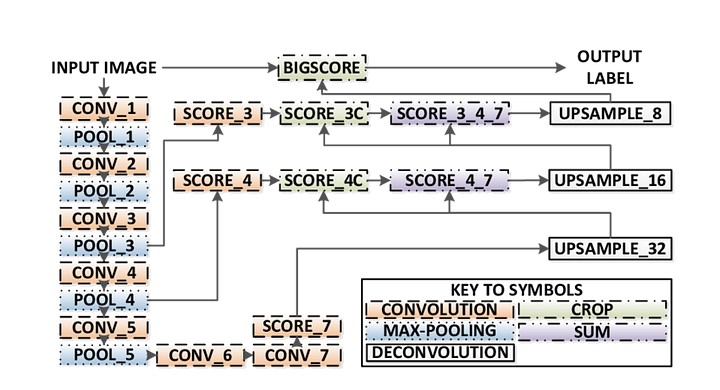
gør semantisk segmentering med fuldt Konvolutionært netværk
i dette afsnit, lad os gå gennem en trinvis implementering af den mest populære arkitektur til semantisk segmentering-Fully-Convolutional Net (FCN). Vi implementerer det ved hjælp af tensorstrømsbiblioteket i Python 3 sammen med andre afhængigheder som Numpy og Scipy.In denne øvelse vil vi mærke billedpunkterne på en vej i billeder ved hjælp af FCN. Vi arbejder med Kitti Road datasæt til vej – /banedetektering. Dette er en simpel øvelse fra Udacity ‘ s selvkørende bil Nano-uddannelsen, som du kan lære mere om opsætningen i denne GitHub repo.

Her er nøglefunktionerne i FCN-arkitekturen:
- FCN overfører viden fra vgg16 til at udføre semantisk segmentering.
- de fuldt tilsluttede lag af VGG16 konverteres til fuldt konvolutionære lag ved hjælp af 1H1-konvolution. Denne proces producerer en klasse tilstedeværelse varme kort i lav opløsning.
- opsamplingen af disse semantiske funktionskort med lav opløsning udføres ved hjælp af transponerede konvolutter (initialiseret med bilinære interpolationsfiltre).
- på hvert trin forbedres upsampling-processen yderligere ved at tilføje funktioner fra grovere, men højere opløsningskort fra lavere lag i VGG16.
- Skip-forbindelse introduceres efter hver konvolutionsblok for at gøre det muligt for den efterfølgende blok at udtrække mere abstrakte, klasse-fremtrædende funktioner fra de tidligere poolede funktioner.
der er 3 versioner af FCN (FCN-32, FCN-16, FCN-8). Vi implementerer FCN-8, som detaljeret trin for trin nedenfor:
- Encoder: en forududdannet VGG16 bruges som en encoder. Dekoderen starter fra Lag 7 i VGG16.
- FCN Layer-8: det sidste fuldt tilsluttede lag af VGG16 erstattes af en 1H1-foldning.
- FCN Layer-9: FCN Layer-8 er upsampled 2 gange for at matche dimensioner med lag 4 af VGG 16, ved hjælp af transponeret foldning med parametre: (kernel=(4,4), stride=(2,2), paddding=’samme’). Derefter blev der tilføjet en springforbindelse mellem lag 4 af VGG16 og FCN Layer-9.
- FCN Layer-10: FCN Layer-9 er upsampled 2 gange for at matche dimensioner med lag 3 af VGG16 ved hjælp af transponeret foldning med parametre: (kernel=(4,4), stride=(2,2), paddding=’samme’). Derefter blev der tilføjet en springforbindelse mellem lag 3 af VGG 16 og FCN Layer-10.
- FCN Layer-11: FCN Layer-10 er upsampled 4 gange for at matche dimensioner med input billedstørrelse, så vi får det faktiske billede tilbage og dybden er lig med antallet af klasser, ved hjælp af transponeret foldning med parametre:(kernel=(16,16), stride=(8,8), paddding=’samme’).
trin 1
vi indlæser først den forududdannede VGG-16-model i tensorstrøm. Når vi tager Tensorløbssessionen og stien til VGG-mappen (som kan hentes her), returnerer vi tuplen af tensorer fra VGG-modellen, inklusive billedindgangen, keep_prob (for at kontrollere frafaldshastighed), lag 3, lag 4 og lag 7.
def load_vgg(sess, vgg_path): # load the model and weights model = tf.saved_model.loader.load(sess, , vgg_path) # Get Tensors to be returned from graph graph = tf.get_default_graph() image_input = graph.get_tensor_by_name('image_input:0') keep_prob = graph.get_tensor_by_name('keep_prob:0') layer3 = graph.get_tensor_by_name('layer3_out:0') layer4 = graph.get_tensor_by_name('layer4_out:0') layer7 = graph.get_tensor_by_name('layer7_out:0') return image_input, keep_prob, layer3, layer4, layer7vgg16 funktion
Trin 2
nu fokuserer vi på at oprette lagene til en FCN ved hjælp af tensorerne fra VGG-modellen. I betragtning af tensorerne for VGG-lagoutput og antallet af klasser, der skal klassificeres, returnerer vi tensoren til det sidste lag af denne output. Især anvender vi en 1H1-foldning på koderlagene og tilføjer derefter dekoderlag til netværket med springforbindelser og upsampling.
def layers(vgg_layer3_out, vgg_layer4_out, vgg_layer7_out, num_classes): # Use a shorter variable name for simplicity layer3, layer4, layer7 = vgg_layer3_out, vgg_layer4_out, vgg_layer7_out # Apply 1x1 convolution in place of fully connected layer fcn8 = tf.layers.conv2d(layer7, filters=num_classes, kernel_size=1, name="fcn8") # Upsample fcn8 with size depth=(4096?) to match size of layer 4 so that we can add skip connection with 4th layer fcn9 = tf.layers.conv2d_transpose(fcn8, filters=layer4.get_shape().as_list(), kernel_size=4, strides=(2, 2), padding='SAME', name="fcn9") # Add a skip connection between current final layer fcn8 and 4th layer fcn9_skip_connected = tf.add(fcn9, layer4, name="fcn9_plus_vgg_layer4") # Upsample again fcn10 = tf.layers.conv2d_transpose(fcn9_skip_connected, filters=layer3.get_shape().as_list(), kernel_size=4, strides=(2, 2), padding='SAME', name="fcn10_conv2d") # Add skip connection fcn10_skip_connected = tf.add(fcn10, layer3, name="fcn10_plus_vgg_layer3") # Upsample again fcn11 = tf.layers.conv2d_transpose(fcn10_skip_connected, filters=num_classes, kernel_size=16, strides=(8, 8), padding='SAME', name="fcn11") return fcn11Lagfunktion
Trin 3
det næste trin er at optimere vores neurale netværk, også kaldet opbygning af Tensorstrømstabsfunktioner og optimeringsoperationer. Her bruger vi cross entropi som vores tabsfunktion og Adam som vores optimeringsalgoritme.
def optimize(nn_last_layer, correct_label, learning_rate, num_classes): # Reshape 4D tensors to 2D, each row represents a pixel, each column a class logits = tf.reshape(nn_last_layer, (-1, num_classes), name="fcn_logits") correct_label_reshaped = tf.reshape(correct_label, (-1, num_classes)) # Calculate distance from actual labels using cross entropy cross_entropy = tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=correct_label_reshaped) # Take mean for total loss loss_op = tf.reduce_mean(cross_entropy, name="fcn_loss") # The model implements this operation to find the weights/parameters that would yield correct pixel labels train_op = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(loss_op, name="fcn_train_op") return logits, train_op, loss_opOptimer funktion
Trin 4
Her definerer vi train_nn-funktionen, som tager vigtige parametre, herunder antal epoker, batchstørrelse, tabsfunktion, optimeringsdrift og pladsholdere til inputbilleder, etiketbilleder, læringshastighed. Til træningsprocessen sætter vi også keep_probability til 0,5 og learning_rate til 0,001. For at holde styr på fremskridtene udskriver vi også tabet under træning.
def train_nn(sess, epochs, batch_size, get_batches_fn, train_op, cross_entropy_loss, input_image, correct_label, keep_prob, learning_rate): keep_prob_value = 0.5 learning_rate_value = 0.001 for epoch in range(epochs): # Create function to get batches total_loss = 0 for X_batch, gt_batch in get_batches_fn(batch_size): loss, _ = sess.run(, feed_dict={input_image: X_batch, correct_label: gt_batch, keep_prob: keep_prob_value, learning_rate:learning_rate_value}) total_loss += loss; print("EPOCH {} ...".format(epoch + 1)) print("Loss = {:.3f}".format(total_loss)) print()Trin 5
endelig er det tid til at træne vores net! I denne kørefunktion bygger vi først vores net ved hjælp af funktionen load_vgg, layers og optimer. Derefter træner vi nettet ved hjælp af train_nn-funktionen og gemmer inferensdataene til poster.
def run(): # Download pretrained vgg model helper.maybe_download_pretrained_vgg(data_dir) # A function to get batches get_batches_fn = helper.gen_batch_function(training_dir, image_shape) with tf.Session() as session: # Returns the three layers, keep probability and input layer from the vgg architecture image_input, keep_prob, layer3, layer4, layer7 = load_vgg(session, vgg_path) # The resulting network architecture from adding a decoder on top of the given vgg model model_output = layers(layer3, layer4, layer7, num_classes) # Returns the output logits, training operation and cost operation to be used # - logits: each row represents a pixel, each column a class # - train_op: function used to get the right parameters to the model to correctly label the pixels # - cross_entropy_loss: function outputting the cost which we are minimizing, lower cost should yield higher accuracy logits, train_op, cross_entropy_loss = optimize(model_output, correct_label, learning_rate, num_classes) # Initialize all variables session.run(tf.global_variables_initializer()) session.run(tf.local_variables_initializer()) print("Model build successful, starting training") # Train the neural network train_nn(session, EPOCHS, BATCH_SIZE, get_batches_fn, train_op, cross_entropy_loss, image_input, correct_label, keep_prob, learning_rate) # Run the model with the test images and save each painted output image (roads painted green) helper.save_inference_samples(runs_dir, data_dir, session, image_shape, logits, keep_prob, image_input)Kør funktion
om vores parametre vælger vi epoker = 40, batch_størrelse = 16, num_classes = 2 og image_shape = (160, 576). Efter at have lavet 2 Forsøg passerer med dropout = 0.5 og dropout = 0.75, fandt vi, at 2.Forsøg giver bedre resultater med bedre gennemsnitlige tab.

for at se den fulde kode, tjek dette link: https://gist.github.com/khanhnamle1994/e2ff59ddca93c0205ac4e566d40b5e88
Hvis du nød dette stykke, ville jeg elske det dele det og sprede viden.
du er måske interesseret i vores seneste indlæg på:
- DATAEKSTRAKTION
begynd at bruge Nanonets til automatisering
prøv modellen eller anmod om en demo i dag!
prøv nu
