seaborn.histplot Lars
seaborn.histplot(data=Ingen,*,=Ingen, y=ingen, hue=ingen, vægte=ingen, stat=’count’, bins=’auto’, binbredde=ingen, binrange=ingen, diskret=ingen, kumulativ=falsk, common_bins=True, common_norm=True, flere=’layer’, element=’bars’, fyld=true, Shrink=1, KDE=false, kde_kv=none, line_kv=None, Thresh=0, pthresh=None, pmaks=None, cbar=false, cbar_akse=None, palette=None, hue_order=none, hue_norm=none, color=None, log_scale=None, Legend=true, økse=none, **kvargs) p>plot univariate eller bivariate histogrammer for at vise distributioner af datasæt.
et histogram er et klassisk visualiseringsværktøj, der repræsenterer distributionen af en eller flere variabler ved at tælle antallet af observationer, der falder medindisrete skraldespande.
Denne funktion kan normalisere statistikken beregnet inden for hver bin til estimatefrekvens, densitet eller sandsynlighedsmasse, og den kan tilføje en glat kurve opnået ved hjælp af et kernetæthedsestimat svarende til kdeplot().
flere oplysninger findes i brugervejledningen.
parametre datapandas.DataFramenumpy.ndarray, kortlægning eller sekvens
Input datastruktur. Enten en langformet samling af vektorer, der kan tildeles navngivne variabler, eller et datasæt i bred form, der vil blive internalt omformet.i data
variabler, der angiver positioner på H-og y-akserne.
huevector eller nøgle idata
semantisk variabel, der er kortlagt for at bestemme farven på plotelementer.
vægtvektor eller nøgle idata
Hvis angivet, vægt bidraget fra de tilsvarende datapunktermod tællingen i hver bin af disse faktorer.
stat {“count”, “frekvens”, “densitet”, “Sandsynlighed”}
aggregeret statistik til beregning i hver bin.
-
countviser antallet af observationer -
frequencyviser antallet af observationer divideret med binbredden -
densitynormaliserer tæller, så histogrammets område er 1 -
probabilitynormaliserer tællinger, så summen af bjælkehøjderne er 1
binsstr, nummer,vektor eller et par af sådanne værdier
generisk bin-parameter, der kan være navnet på en referenceregel, antallet af skraldespande eller pauserne i skraldespandene.Sendt til numpy.histogram_bin_edges().
binbredden eller par af tal
bredden af hver bin tilsidesætterbins men kan bruges medbinrange.
binrangepair af tal eller et par par
laveste og højeste værdi for bin kanter; kan bruges entenmedbins ellerbinwidth. Standard til data ekstremer.
discretebool
Hvis det er sandt, standard tilbinwidth=1 og tegne søjlerne, så de ercentreret på deres tilsvarende datapunkter. Dette undgår “huller”, der kanellers vises, når du bruger diskrete (heltal) data.
kumulativebool
Hvis det er sandt, plot de kumulative tæller som skraldespande stigning.
common_binsbool
Hvis det er sandt, skal du bruge de samme placeringer, når semantiske variabler producerer multiplots. Hvis du bruger en referenceregel til at bestemme beholderne, vil den blive beregnetmed det fulde datasæt.
common_normbool
Hvis det er sandt og bruger en normaliseret statistik, vil normaliseringen gælde over det fulde datasæt. Ellers normaliser hvert histogram uafhængigt.
multiple {“layer”, “dodge”, “stack”, “fill”}
tilgang til at løse flere elementer, når semantisk kortlægning skaber delmængder.Kun relevant med univariate data.
element {“bars”, “step”, “poly”}
visuel repræsentation af histogramstatistikken.Kun relevant med univariate data.
fillbool
Hvis det er sandt, skal du udfylde pladsen under histogrammet.Kun relevant med univariate data.
shrinknumber
skala bredden af hver stang i forhold til binbredden med denne faktor.Kun relevant med univariate data.
kdebool
Hvis det er sandt, skal du beregne et kernetæthedsestimat for at udjævne distributionen og vise på plottet som (en eller flere) linjer.Kun relevant med univariate data.parametre, der styrer KDE-beregningen, som i kdeplot().parametre, der styrer KDE-visualiseringen, overføres tilmatplotlib.axes.Axes.plot().
threshnumber eller ingen
celler med en statistik mindre end eller lig med denne værdi vil være gennemsigtig.Kun relevant med bivariate data.
pthreshnumber or None
Like thresh, men en værdi i sådan, at celler med aggregattællinger(eller anden statistik, når de bruges) op til denne andel af det samlede antal vil væregennemsigtig.en værdi i det indstiller mætningspunktet for farvekortet til en værdi, således at cellerne nedenfor er forstoppet denne andel af det samlede antal (elleranden statistik, når den bruges).
cbarbool
Hvis det er sandt, skal du tilføje en farvebjælke for at kommentere farvekortlægningen i et bivariat-plot.Bemærk: understøtter i øjeblikket ikke plots med enhue variabel godt.
cbar_aksmatplotlib.axes.Axes
eksisterende akser til farvebjælken.yderligere parametre overført til matplotlib.figure.Figure.colorbar().
palettestring, list, dict ellermatplotlib.colors.Colormap
metode til valg af farver, der skal bruges, når du kortlæggerhue semantisk.Strengværdier sendes til color_palette(). Liste eller dict værdisimpelthen kategorisk kortlægning, mens et colormap-objekt indebærer numerisk kortlægning.
hue_ordervector af strenge
Angiv rækkefølgen af behandling og plotning for kategoriske niveauer afhue semantisk.
hue_normtuple ellermatplotlib.colors.Normalize
enten et par værdier, der indstiller normaliseringsområdet i dataenhedereller et objekt, der vil kortlægge fra dataenheder til et interval. Usageimplies numerisk kortlægning.
colormatplotlib color
enkelt farve specifikation for når hue kortlægning ikke anvendes. Ellers, theplot vil forsøge at tilslutte sig matplotlib ejendomscyklus.
log_scalebool eller nummer eller par bools eller tal
Indstil en logskala på dataaksen (eller akserne med bivariate data) med den givne base (standard 10), og evaluer KDE i logrummet.
legendbool
Hvis falsk, undertrykke legenden for semantiske variabler.
øksematplotlib.axes.Axes
eksisterende akser til plottet. Ellers skal du ringe matplotlib.pyplot.gca() internt.andre søgeord argumenter overføres til en af følgende matplotlibfunctions:
-
matplotlib.axes.Axes.bar()(univariate, element=”bars”) -
matplotlib.axes.Axes.fill_between()(univariate, other element, fill=True) -
matplotlib.axes.Axes.plot()(univariate, other element, fill=False) -
matplotlib.axes.Axes.pcolormesh()(bivariate)
Returnsmatplotlib.axes.Axes
The matplotlib axes containing the plot.
See also
displot
Figure-level interface to distribution plot functions.
kdeplot
Plot univariate eller bivariate distributioner ved hjælp af kernetæthedsestimering.
rugplot
Tegn et kryds ved hver observationsværdi langs akserne h og/eller y.
ecdfplot
Plot empiriske kumulative fordelingsfunktioner.
jointplot
Tegn et bivariat plot med univariate marginale fordelinger.
noter
valget af skraldespande til beregning og planlægning af et histogram kan udøve væsentlig indflydelse på den indsigt, man er i stand til at trække fravisualisering. Hvis beholderne er for store, kan de slette vigtige funktioner.På den anden side kan skraldespande, der er for små, domineres af randomvariabilitet, der tilslører formen på den sande underliggende fordeling. Default bin størrelse bestemmes ved hjælp af en referenceregel, der afhænger afprøvestørrelse og varians. Dette fungerer godt i mange tilfælde (dvs.med”velopdragen” data), men det mislykkes i andre. Det er altid en god at prøveforskellige bin størrelser for at være sikker på, at du ikke mangler noget vigtigt.Denne funktion giver dig mulighed for at specificere skraldespande på flere forskellige måder, f.eksved at indstille det samlede antal skraldespande, der skal bruges, bredden på hver skraldespand eller de specifikke placeringer, hvor skraldespandene skal gå i stykker.
eksempler
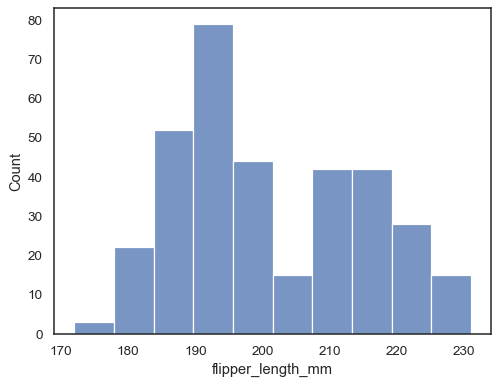
Tildel en variabel tilx for at plotte en univariat fordeling langs aksen:
penguins = sns.load_dataset("penguins")sns.histplot(data=penguins, x="flipper_length_mm")
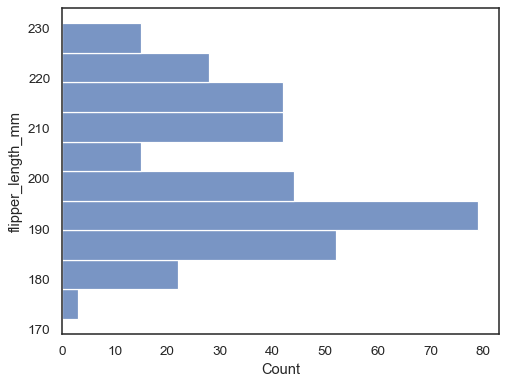
vend plottet ved at tildele datavariablen til Y-aksen:
sns.histplot(data=penguins, y="flipper_length_mm")
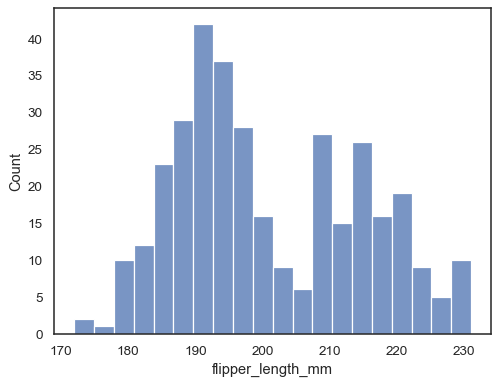
Kontroller, hvor godt histogrammet repræsenterer dataene ved at specificere adifferent bin bredde:
sns.histplot(data=penguins, x="flipper_length_mm", binwidth=3)
Du kan også definere det samlede antal placeringer, der skal bruges:
sns.histplot(data=penguins, x="flipper_length_mm", bins=30)
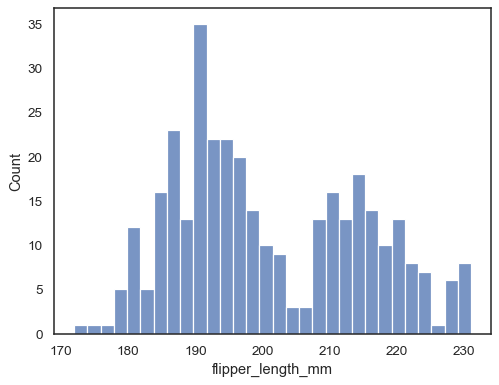
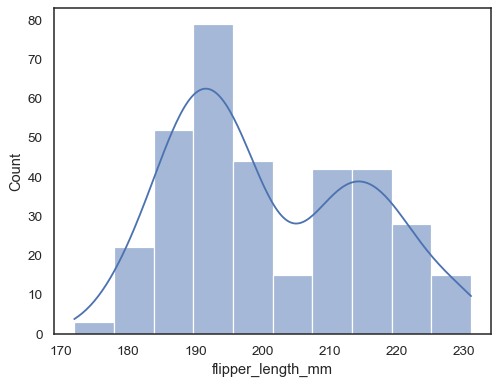
Tilføj et kernetæthedsestimat for at glatte histogrammet, giverkomplementær information om fordelingens form:
sns.histplot(data=penguins, x="flipper_length_mm", kde=True)
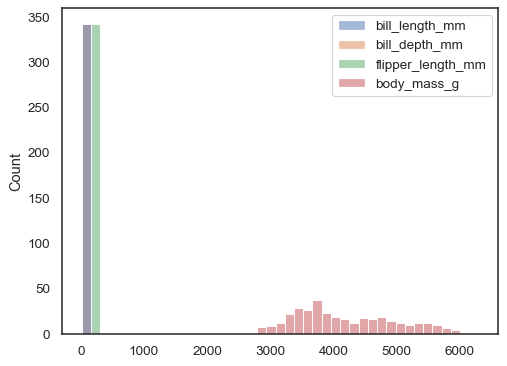
hvis hverken x eller y er tildelt, behandles datasættet sombred-form, og der tegnes et histogram for hver numerisk kolonne:
sns.histplot(data=penguins)
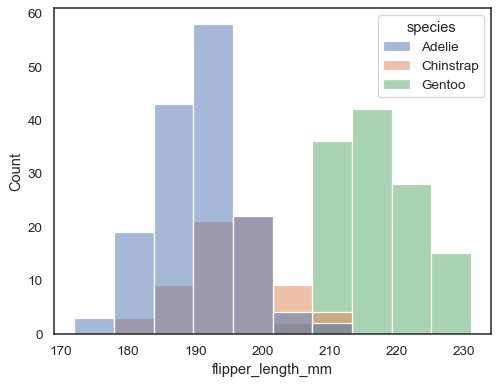
Du kan ellers tegne flere histogrammer fra et langformet datasæt medhue mapping:
sns.histplot(data=penguins, x="flipper_length_mm", hue="species")
standardmetoden til at plotte flere distributioner er at ” lag ” dem, men du kan også “stable” dem:
sns.histplot(data=penguins, x="flipper_length_mm", hue="species", multiple="stack")
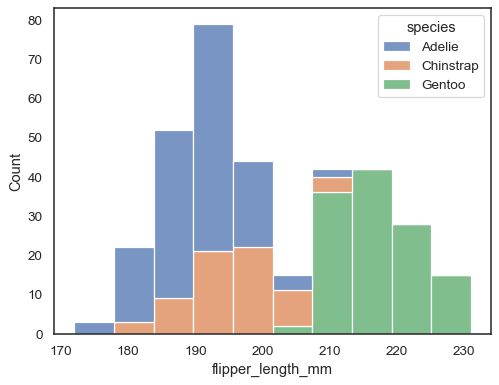
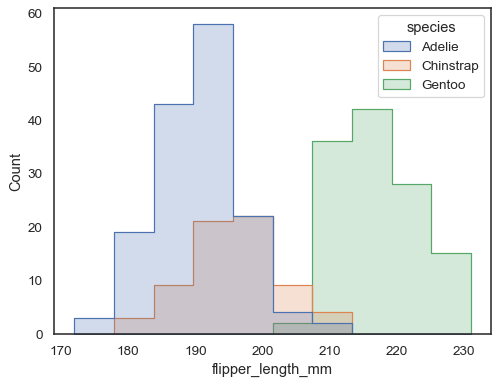
overlappende søjler kan være svære at visuelt løse. En anden tilgangville være at tegne en trinfunktion:
sns.histplot(penguins, x="flipper_length_mm", hue="species", element="step")
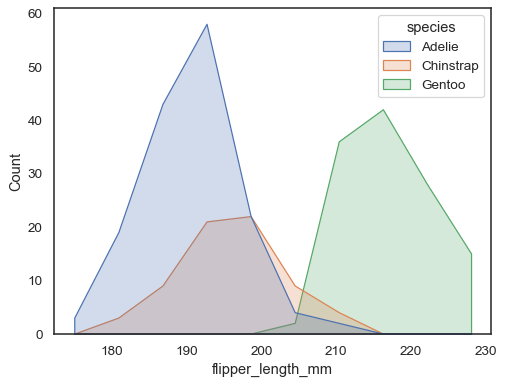
Du kan flytte endnu længere væk fra søjler ved at tegne en polygon medvertices i midten af hver bin. Dette kan gøre det lettere at seform af distributionen, men brug med forsigtighed: det vil være mindre indlysendetil dit publikum, at de ser på et histogram:
sns.histplot(penguins, x="flipper_length_mm", hue="species", element="poly")
for at sammenligne fordelingen af undergrupper, der adskiller sig væsentligt i størrelse, skal du bruge indepdendent density normalisering:
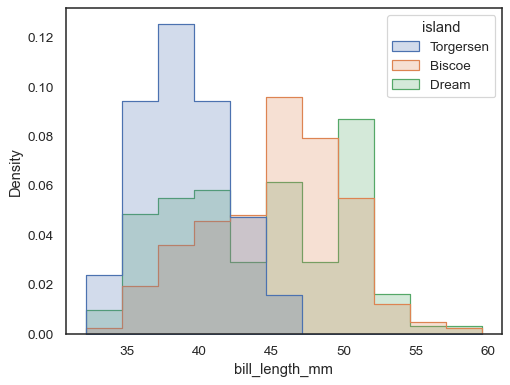
det er også muligt at normalisere, så hver bars højde viser aprobabilitet, hvilket giver mere mening for diskrete variabler:
tips = sns.load_dataset("tips")sns.histplot(data=tips, x="size", stat="probability", discrete=True)
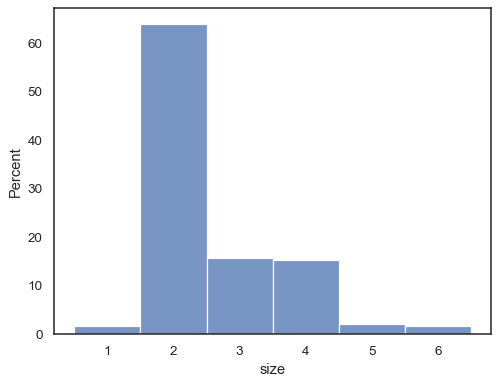
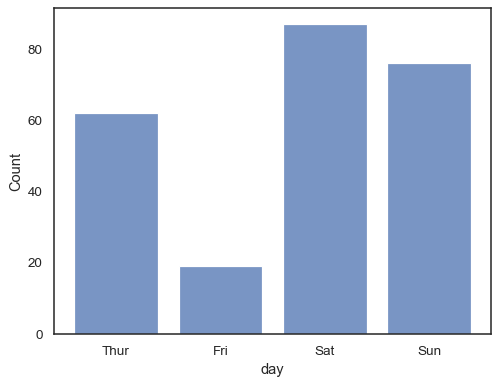
Du kan endda tegne et histogram over kategoriske variabler (selvom detteer en eksperimentel funktion):
sns.histplot(data=tips, x="day", shrink=.8)
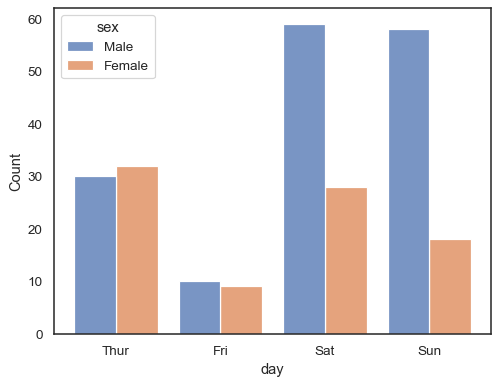
Når du bruger enhue semantisk med diskrete data, kan det være fornuftigt at”undvige” niveauerne:
sns.histplot(data=tips, x="day", hue="sex", multiple="dodge", shrink=.8)
virkelige data er ofte skævt. For stærkt skæve fordelinger er det bedre at definere bakkerne i logrummet. Sammenligne:
planets = sns.load_dataset("planets")sns.histplot(data=planets, x="distance")
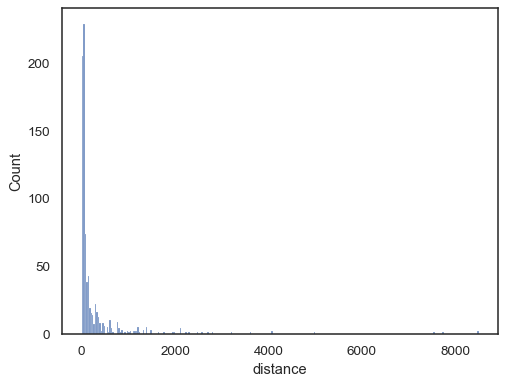
To the log-scale version:
sns.histplot(data=planets, x="distance", log_scale=True)
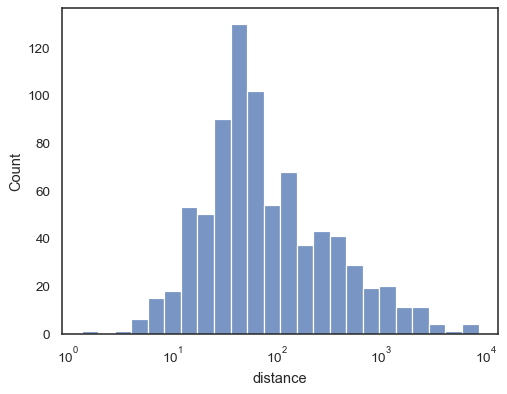
There are also a number of options for how the histogram appears. Youcan show unfilled bars:
sns.histplot(data=planets, x="distance", log_scale=True, fill=False)
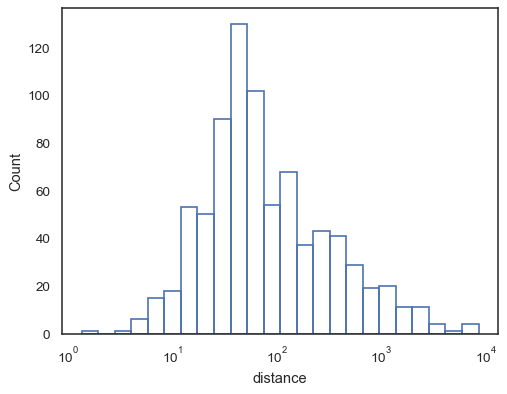
Or an unfilled step function:
sns.histplot(data=planets, x="distance", log_scale=True, element="step", fill=False)
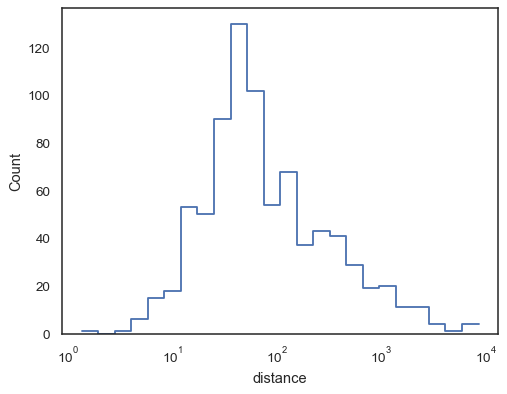
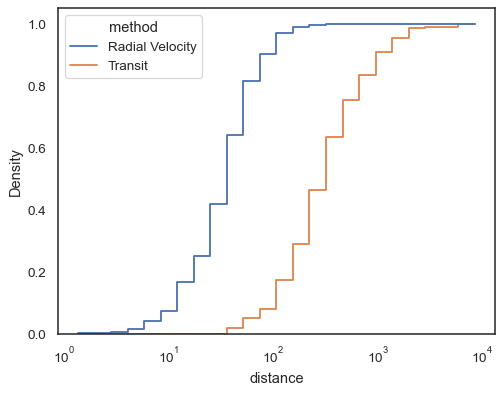
Trinfunktioner, især når de ikke er udfyldt, gør det nemt at sammenligne kumulative histogrammer:
sns.histplot( data=planets, x="distance", hue="method", hue_order=, log_scale=True, element="step", fill=False, cumulative=True, stat="density", common_norm=False,)
når begge x og y er tildelt, beregnes et bivariathistogram og vises som et varmekort:
sns.histplot(penguins, x="bill_depth_mm", y="body_mass_g")
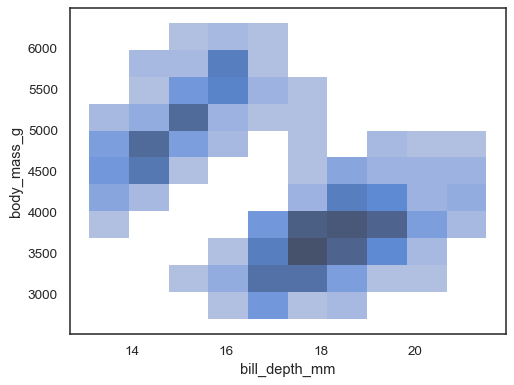
det er muligt at tildele enhue variabel også, selvom dette ikke fungerer godt, hvis data fra de forskellige niveauer har betydelig overlapning:
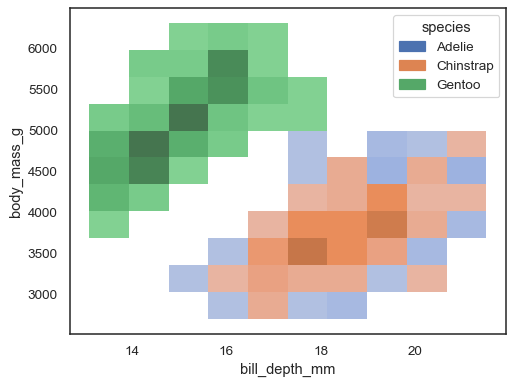
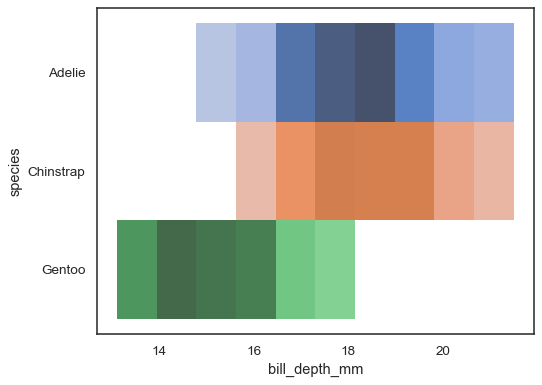
flere farvekort kan give mening, når en af variablerne isdiscrete:
sns.histplot( penguins, x="bill_depth_mm", y="species", hue="species", legend=False)
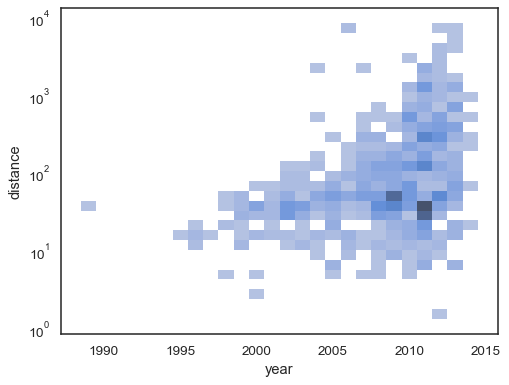
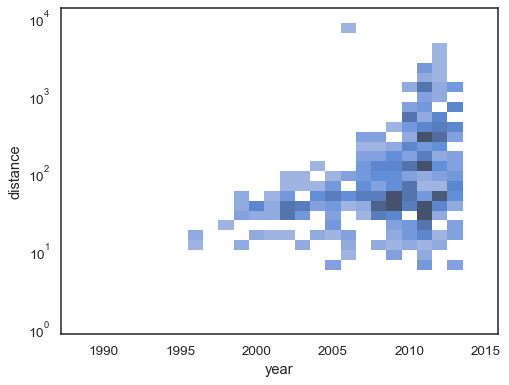
Bivariathistogrammet accepterer alle de samme muligheder for beregningsom sin univariate modstykke, ved hjælp af tupler til parametrisering x ogy uafhængigt:
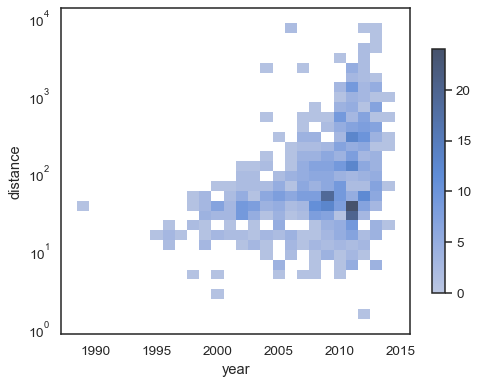
sns.histplot( planets, x="year", y="distance", bins=30, discrete=(True, False), log_scale=(False, True),)
standardadfærden gør celler uden observationer gennemsigtige,selvom dette kan deaktiveres:
sns.histplot( planets, x="year", y="distance", bins=30, discrete=(True, False), log_scale=(False, True), thresh=None,)
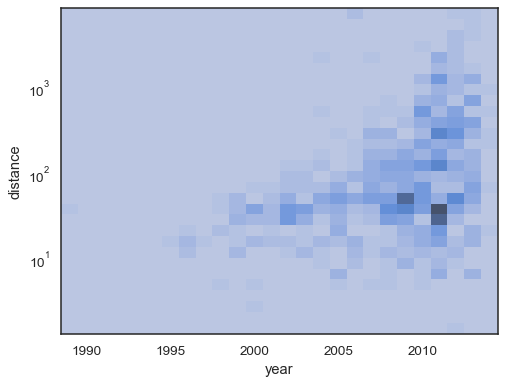
det er også muligt at indstille tærskelværdien og farvemætningspunktet for andelen af kumulative tællinger:
sns.histplot( planets, x="year", y="distance", bins=30, discrete=(True, False), log_scale=(False, True), pthresh=.05, pmax=.9,)
for at kommentere farvekortet skal du tilføje en colorbar:
sns.histplot( planets, x="year", y="distance", bins=30, discrete=(True, False), log_scale=(False, True), cbar=True, cbar_kws=dict(shrink=.75),)