T-testen
T-testen vurderer, om midlerne til to grupper er statistisk forskellige fra hinanden. Denne analyse er passende, når du vil sammenligne midlerne til to grupper, og især passende som analysen for posttest-kun to-Gruppe randomiseret eksperimentelt design.
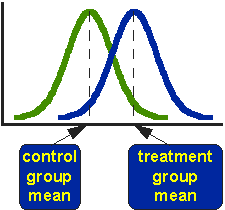
Figur 1. Idealiserede distributioner for behandlede og sammenligning gruppe posttest værdier.
Figur 1 viser fordelingen for de behandlede (blå) og kontrol (grønne) grupper i en undersøgelse. Faktisk viser figuren den idealiserede fordeling – den faktiske fordeling vil normalt blive afbildet med et histogram eller søjlediagram. Figuren angiver, hvor kontrol-og behandlingsgruppens midler er placeret. Spørgsmålet, som T-test adresserer, er, om midlerne er statistisk forskellige.
hvad betyder det at sige, at gennemsnittet for to grupper er statistisk forskellige? Overvej de tre situationer, der er vist i figur 2. Den første ting at bemærke om de tre situationer er, at forskellen mellem midlerne er den samme i alle tre. Men du skal også bemærke, at de tre situationer ikke ser ens ud – de fortæller meget forskellige historier. Det øverste eksempel viser en sag med moderat variation i score inden for hver gruppe. Den anden situation viser den høje variabilitetssag. den tredje viser sagen med lav variabilitet. Det er klart, at vi vil konkludere, at de to grupper forekommer mest forskellige eller adskilte i bunden eller lavvariationssagen. Hvorfor? Fordi der er relativt lidt overlapning mellem de to klokkeformede kurver. I tilfælde af høj variabilitet forekommer gruppeforskellen mindst slående, fordi de to klokkeformede fordelinger overlapper så meget.
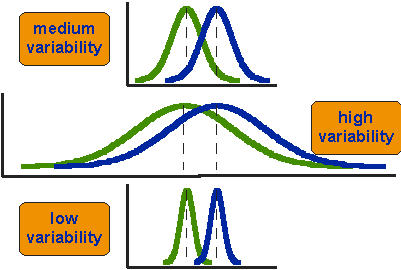
figur 2. Tre scenarier for forskelle mellem midler.
dette fører os til en meget vigtig konklusion: når vi ser på forskellene mellem scoringer for to grupper, er vi nødt til at bedømme forskellen mellem deres midler i forhold til spredningen eller variabiliteten af deres score. T-testen gør netop dette.
statistisk analyse af T-testen
formlen for T-testen er et forhold. Den øverste del af forholdet er kun forskellen mellem de to midler eller gennemsnit. Den nederste del er et mål for variabiliteten eller spredningen af scorerne. Denne formel er i det væsentlige et andet eksempel på signal-til-støj-metaforen i forskning: forskellen mellem midlerne er signalet om, at vi i dette tilfælde tror, at vores program eller behandling introduceres i dataene; den nederste del af formlen er et mål for variabilitet, der i det væsentlige er støj, der kan gøre det sværere at se gruppeforskellen. Figur 3 viser formlen for T-testen, og hvordan tælleren og nævneren er relateret til fordelingerne.
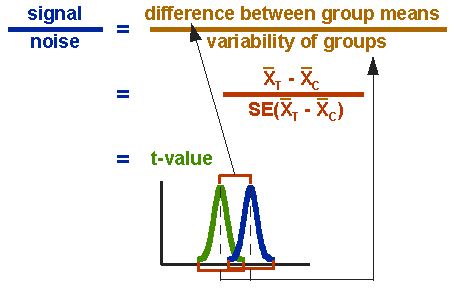
figur 3. Formel til T-testen.
den øverste del af formlen er let at beregne – find bare forskellen mellem midlerne. Den nederste del kaldes standardfejlen for forskellen. For at beregne det tager vi variansen for hver gruppe og deler den med antallet af personer i den gruppe. Vi tilføjer disse to værdier og tager derefter deres kvadratrod. Den specifikke formel for standardfejlen for forskellen mellem midlerne er:
$ $ \ tekstrm{SE} (\bar{H}_T-\bar{H}_C) = \frat {\frac {\tekstrm{var}_T}{n_T}+\frac {\tekstrm{var}_C}{n_C}}$$
Husk, at variansen simpelthen er kvadratet af standardafvigelsen.
den endelige formel for T-testen er:
$$t = \frac{\bar {} _T-\bar {{\frac{\tekstrm {var}_T} {n_T}+\frac {\tekstrm {var} _C} {n_c}}$$
t-værdien vil være positiv, hvis det første gennemsnit er større end det andet og negativt, hvis det er mindre. Når du har beregnet t -værdien, skal du slå den op i en tabel med betydning for at teste, om forholdet er stort nok til at sige, at forskellen mellem grupperne sandsynligvis ikke har været en chance for at finde. For at teste betydningen skal du indstille et risikoniveau (kaldet alfa-niveauet). I de fleste sociale undersøgelser er “tommelfingerreglen” at indstille alfa-niveauet til .05. Det betyder, at fem gange ud af hundrede vil du finde en statistisk signifikant forskel mellem midlerne, selvom der ikke var nogen (dvs.ved “chance”). Du skal også bestemme frihedsgraderne (df) til testen. I t-tester frihedsgraderne summen af personerne i begge grupper minus 2. I betragtning af alfa-niveauet, df og t-værdien kan du set-værdien op i en standardtabel af betydning (tilgængelig som et tillæg på bagsiden af de fleste statistiktekster) for at afgøre, omt -værdien er stor nok til at være signifikant. Hvis det er, kan du konkludere, at forskellen mellem midlerne til de to grupper er forskellig (selv i betragtning af variabiliteten). Heldigvis udskriver statistiske computerprogrammer rutinemæssigt signifikanstestresultaterne og sparer dig besværet med at slå dem op i en tabel.
t-testen, envejsanalyse af varians (ANOVA) og en form for regressionsanalyse er matematisk ækvivalente (se den statistiske analyse af det posttest-kun randomiserede eksperimentelle design) og ville give identiske resultater.