A pap-smear analysis tool (PAT) for detection of cervical cancer from pap-smear images
Image analysis
Die Bildanalyse-Pipeline für die Entwicklung eines Pap-Smear-Analysetools zum Nachweis von Gebärmutterhalskrebs aus Pap-Abstrichen, die in diesem Beitrag vorgestellt wird, ist in Abb. 1.

Der Ansatz zur Erkennung von Gebärmutterhalskrebs aus Pap-Abstrichbildern
Bilderfassung
Der Ansatz wurde anhand von drei Datensätzen bewertet. Datensatz 1 besteht aus 917 Einzelzellen von Harlev-Pap-Abstrichbildern, die von Jantzen et al. . Der Datensatz enthält Pap-Abstrichbilder, die von erfahrenen Zytopathologen mit einem an einen Framegrabber angeschlossenen Mikroskop mit einer Auflösung von 0,201 µm / Pixel aufgenommen wurden. Die Bilder wurden unter Verwendung der kommerziellen CHAMP-Software segmentiert und dann in sieben Klassen mit unterschiedlichen Merkmalen klassifiziert, wie in Tabelle 2 gezeigt. Davon wurden 200 Bilder zum Training und 717 Bilder zum Testen verwendet.
Datensatz 2 besteht aus 497 Pap-Abstrichbildern, die von Norup et al. . Davon wurden 200 Bilder zum Training und 297 Bilder zum Testen verwendet. Darüber hinaus wurde die Leistung des Klassifikators bewertet auf Datensatz 3 von Proben von 60 Pap-Abstrichen (30 normal und 30 abnormal), die vom Mbarara Regional Referral Hospital (MRRH) erhalten wurden. Die Proben wurden mit einem Olympus BX51-Hellfeldmikroskop aufgenommen, das mit einem 40 ×, 0,95 NA-Objektiv und einer Hamamatsu ORCA-05G 1,4 Mpx-Monochromkamera ausgestattet war und eine Pixelgröße von 0,25 µm mit 8-Bit-Grautiefe ergab. Jedes Bild wurde dann in 300 Bereiche unterteilt, wobei jeder Bereich zwischen 200 und 400 Zellen enthielt. Basierend auf den Meinungen der Zytopathologen wurden 10.000 Objekte in Bildern ausgewählt, die von den 60 verschiedenen Pap-Abstrichobjekten abgeleitet wurden, von denen 8000 frei liegende Zervixepithelzellen waren (3000 normale Zellen aus normalen Abstrichen und 5000 abnormale Zellen aus abnormalen Abstrichen) und die restlichen 2000 waren Trümmerobjekte. Diese Pap-Abstrich-Segmentierung wurde mit dem trainierbaren Weka-Segmentierungs-Toolkit erreicht, um einen Segmentierungsklassifikator auf Pixelebene zu konstruieren.
Bildverbesserung
Zur Bildverbesserung wurde auf das Graustufenbild ein lokaler adaptiver Histogrammausgleich (Contrast local Adaptive Histogram Equalization, CLAHE) angewendet. In CLAHE ist die Auswahl der Clip-Grenze, die die gewünschte Form des Histogramms des Bildes angibt, von größter Bedeutung, da sie die Qualität des verbesserten Bildes entscheidend beeinflusst. Der optimale Wert der Clip-Grenze wurde empirisch mit der von Joseph et al. . Ein optimaler Clip-Grenzwert von 2.Es wurde festgestellt, dass 0 geeignet ist, um eine angemessene Bildverbesserung bereitzustellen und gleichzeitig die dunklen Merkmale für die verwendeten Datensätze beizubehalten. Die Umwandlung in Graustufen wurde unter Verwendung einer Graustufentechnik erreicht, die unter Verwendung von Eq implementiert wurde. 1 wie in.
wobei R = Rot, G = Grün und B = Blau Farbbeiträge zum neuen Bild.
Die Anwendung von CLAHE zur Bildverbesserung führte zu spürbaren Änderungen der Bilder durch Anpassung der Bildintensitäten, wobei die Verdunkelung des Kerns sowie die Zytoplasmabegrenzungen mit einer Clip-Grenze von 2,0 leicht erkennbar wurden.
Szenensegmentierung
Um eine Szenensegmentierung zu erreichen, wurde ein Klassifikator auf Pixelebene mit dem trainierbaren Weka Segmentation (TWS) Toolkit entwickelt. Die Mehrheit der in einem Pap-Abstrich beobachteten Zellen sind nicht überraschend zervikale Epithelzellen . Darüber hinaus sind in der Regel eine unterschiedliche Anzahl von Leukozyten, Erythrozyten und Bakterien erkennbar, während manchmal eine geringe Anzahl anderer kontaminierender Zellen und Mikroorganismen beobachtet wird. Der Pap-Abstrich enthält jedoch vier Haupttypen von Plattenepithelkarzinomzellen – oberflächlich, intermediär, parabasal und basal —, von denen oberflächliche und intermediäre Zellen die überwiegende Mehrheit in einem herkömmlichen Abstrich darstellen. Eine trainierbare Weka-Segmentierung wurde verwendet, um die verschiedenen Objekte auf der Folie zu identifizieren und zu segmentieren. In diesem Stadium wurde ein Klassifikator auf Pixelebene mit Hilfe eines erfahrenen Zytopathologen unter Verwendung des trainierbaren Weka-Segmentierungs-Toolkits (TWS) auf Zellkernen, Zytoplasma, Hintergrund und Trümmeridentifikation trainiert . Dies wurde erreicht, indem Linien / Auswahl durch die interessierenden Bereiche gezogen und einer bestimmten Klasse zugeordnet wurden. Die Pixel unter den Linien / der Auswahl wurden als Repräsentativ für die Kerne, das Zytoplasma, den Hintergrund und die Trümmer angesehen.
Die in jeder Klasse gezeichneten Umrisse wurden verwendet, um einen Merkmalsvektor \(\math F\limits^{ \to }\) zu erzeugen, der aus der Anzahl der zu jeder Umrisslinie gehörenden Pixel abgeleitet wurde. Der Merkmalsvektor aus jedem Bild (200 aus Datensatz 1 und 200 aus Datensatz 2) wurde durch Gl. 2.
wobei Ni, Ci, Bi und Di die Anzahl der Pixel vom Kern, Zytoplasma, Hintergrund und Trümmern des Bildes \(i\) sind, wie in Abb. 2.

Erzeugung des Merkmalsvektors aus den Trainingsbildern
Jedes aus dem Bild extrahierte Pixel repräsentiert nicht nur seine Intensität, sondern auch eine Reihe von Bildmerkmalen, die viele Informationen enthalten, einschließlich Textur, Ränder und Farbe innerhalb des Bildes eine Pixelfläche von 0,201 µm2. Die Auswahl eines geeigneten Merkmalsvektors für das Training des Klassifikators war eine große Herausforderung und eine neuartige Aufgabe im vorgeschlagenen Ansatz. Der Pixel-Level-Klassifikator wurde mit insgesamt 226 Trainingsfunktionen von TWS trainiert. Der Klassifikator wurde mit einer Reihe von TWS-Trainingsfunktionen trainiert, darunter: (i) Rauschunterdrückung: Die Kuwahara- und bilateralen Filter im TWS-Toolkit wurden verwendet, um den Klassifikator in Bezug auf die Rauschentfernung zu trainieren. Es wurde berichtet, dass dies ausgezeichnete Filter zum Entfernen von Rauschen unter Beibehaltung der Kanten sind, (ii) Kantenerkennung: Ein Sobel-Filter, eine Hessische Matrix und ein Gabor-Filter wurden verwendet, um den Klassifikator bei der Grenzdetektion in einem Bild zu trainieren, und (iii) Texturfilterung: Die Mittelwert-, Varianz-, Median-, Maximum-, Minimum- und Entropiefilter wurden für die Texturfilterung verwendet.
Debris removal
Der Hauptgrund für die aktuellen Einschränkungen vieler der bestehenden automatisierten Pap-Abstrich-Analysesysteme ist, dass sie kämpfen, um die Komplexität der Pap-Abstrich Strukturen zu überwinden, indem sie versuchen, den Objektträger als Ganzes zu analysieren, die oft mehrere Zellen und Trümmer enthalten. Dies kann zum Ausfall des Algorithmus führen und erfordert eine höhere Rechenleistung . Die Proben sind mit Artefakten wie Blutzellen, überlappenden und gefalteten Zellen und Bakterien bedeckt, die die Segmentierungsprozesse behindern und eine große Anzahl verdächtiger Objekte erzeugen. Es wurde gezeigt, dass Klassifikatoren, die zur Unterscheidung zwischen normalen Zellen und präkanzerösen Zellen entwickelt wurden, normalerweise unvorhersehbare Ergebnisse liefern, wenn Artefakte im Pap-Abstrich vorhanden sind . In diesem Tool wird eine Technik zur Identifizierung von Gebärmutterhalszellen unter Verwendung eines dreiphasigen sequentiellen Eliminierungsschemas (in Abb. 3) verwendet wird.

Dreiphasiger sequentieller Eliminationsansatz zur Abstoßung von Debris
Das vorgeschlagene dreiphasige Eliminationsschema entfernt sequentiell Debris aus dem Pap-Abstrich, wenn es als unwahrscheinlich erachtet wird, dass es sich um eine Zervixzelle handelt. Dieser Ansatz ist vorteilhaft, da er es ermöglicht, in jeder Phase eine niederdimensionale Entscheidung zu treffen.
Größenanalyse
Die Größenanalyse ist eine Reihe von Verfahren zur Bestimmung eines Bereichs von Größenmessungen von Partikeln . Der Bereich ist eines der grundlegendsten Merkmale, die auf dem Gebiet der automatisierten Zytologie verwendet werden, um Zellen von Trümmern zu trennen. Die Pap-Abstrichanalyse ist ein gut untersuchtes Gebiet mit viel Vorwissen über Zelleigenschaften . Eine der wichtigsten Veränderungen bei der Beurteilung der Kernfläche besteht jedoch darin, dass Krebszellen eine erhebliche Zunahme der Kerngröße erfahren . Daher ist die Bestimmung einer oberen Größenschwelle, die diagnostische Zellen nicht systematisch ausschließt, viel schwieriger, hat aber den Vorteil, dass der Suchraum reduziert wird. Die in dieser Arbeit vorgestellte Methode basiert auf einer unteren und oberen Größenschwelle der Zervixzellen. Der Pseudocode für den Ansatz ist in Gl. 3.
where \(Area_{max} = 85.267\,{\upmu \text{m}} ^{2}\) und \(Area_{min} = 625\,{\upmu \text{m}}^{2}\) aus Tabelle 2 abgeleitet.
Die Objekte im Hintergrund werden als Trümmer betrachtet und somit aus dem Bild verworfen. Partikel, die zwischen \(Area_{min}\) und \(Area_{max}\) fallen, werden in den nächsten Schritten der Textur- und Formanalyse weiter analysiert.
Formanalyse
Die Form der Objekte in einem Pap-Abstrich ist ein Schlüsselmerkmal bei der Unterscheidung zwischen Zellen und Trümmern . Es gibt eine Reihe von Methoden zur Erkennung von Formbeschreibungen, darunter bereichsbasierte und konturbasierte Ansätze . Regionsbasierte Methoden sind weniger rauschempfindlich, aber rechenintensiver, während konturbasierte Methoden relativ effizient zu berechnen, aber rauschempfindlicher sind . In diesem Papier wurde eine regionsbasierte Methode (perimeter2 / area (P2A)) verwendet . Der P2A-Deskriptor wurde ausgewählt, weil er die Ähnlichkeit eines Objekts mit einem Kreis beschreibt. Dies macht es gut geeignet als Zellkerndeskriptor, da Kerne in ihrem Aussehen im Allgemeinen kreisförmig sind. Die P2A wird auch als Formkompaktheit bezeichnet und wird durch Gl. 4.
wobei c der Wert der Formkompaktheit ist, A die Fläche und p der Umfang des Kerns ist. Es wurde angenommen, dass es sich bei Trümmern um Objekte mit einem P2A-Wert von mehr als 0,97 oder weniger als 0,15 gemäß den Trainingsmerkmalen handelte (in Tabelle 2 dargestellt).
Texturanalyse
Textur ist ein sehr wichtiges charakteristisches Merkmal, das zwischen Kernen und Trümmern unterscheiden kann. Bildtextur ist eine Reihe von Metriken, mit denen die wahrgenommene Textur eines Bildes quantifiziert werden kann . Innerhalb eines Pap-Abstrichs ist die Verteilung der durchschnittlichen Kernfleckenintensität viel enger als die Variation der Fleckenintensität zwischen Trümmerobjekten . Diese Tatsache wurde als Grundlage verwendet, um Trümmer basierend auf ihren Bildintensitäten und Farbinformationen mit Zernike-Momenten (ZM) zu entfernen . Zernike-Momente werden für eine Vielzahl von Mustererkennungsanwendungen verwendet und sind dafür bekannt, robust in Bezug auf Rauschen zu sein und eine gute Rekonstruktionsleistung zu haben. In dieser Arbeit wird das ZM, wie von Malm et al. der Ordnung n mit Wiederholung I der Funktion \(f \ left ( {r, \ theta } \ right) \), in Polarkoordinaten innerhalb einer Scheibe zentriert in quadratischem Bild \(I\ left ( {x,y} \right) \) der Größe \ (m \ times m\) gegeben durch Gl. 5 verwendet wurde.
\(v_{nl }^{*} {r,\theta } \right)\) bezeichnet das komplexe Konjugat des Zernike-Polynoms \(v_{nl} \left( {r,\theta } \right)\). Um ein Texturmaß zu erzeugen, werden Größen von \(A_ {nl}\), die an jedem Pixel im Texturbild zentriert sind, gemittelt .
Merkmalsextraktion
Der Erfolg eines Klassifizierungsalgorithmus hängt stark von der Korrektheit der aus dem Bild extrahierten Merkmale ab. Die Zellen in den Pap-Abstrichen im verwendeten Datensatz werden anhand von Merkmalen wie Größe, Fläche, Form und Helligkeit des Zellkerns und des Zytoplasmas in sieben Klassen unterteilt. Die aus den Bildern extrahierten Merkmale enthielten Morphologiefunktionen, die zuvor von anderen verwendet wurden . In diesem Papier wurden auch drei geometrische Merkmale (Festigkeit, Kompaktheit und Exzentrizität) und sechs Textmerkmale (Mittelwert, Standardabweichung, Varianz, Glätte, Energie und Entropie) aus dem Kern extrahiert, was zu insgesamt 29 Merkmalen führte, wie in Tabelle 3 gezeigt.
Merkmalsauswahl
Bei der Merkmalsauswahl werden Teilmengen der extrahierten Merkmale ausgewählt, die die besten Klassifizierungsergebnisse liefern. Unter den extrahierten Merkmalen können einige Rauschen enthalten, während der ausgewählte Klassifikator andere möglicherweise nicht verwendet. Daher muss ein optimaler Satz von Merkmalen ermittelt werden, möglicherweise durch Ausprobieren aller Kombinationen. Wenn es jedoch viele Merkmale gibt, explodieren die möglichen Kombinationen in der Anzahl und dies erhöht die Rechenkomplexität des Algorithmus. Feature-Auswahlalgorithmen werden grob in die Filter-, Wrapper- und Embedded-Methoden eingeteilt .
Die vom Werkzeug verwendete Methode kombiniert simuliertes Glühen mit einem Wrapper-Ansatz. Dieser Ansatz wurde in aber vorgeschlagen, in diesem Papier, Die Leistung der Merkmalsauswahl wird unter Verwendung eines Random-Forest-Algorithmus mit Doppelstrategie bewertet . Simuliertes Glühen ist eine probabilistische Technik zur Approximation des globalen Optimums einer gegebenen Funktion. Der Ansatz eignet sich gut, um sicherzustellen, dass der optimale Satz von Merkmalen ausgewählt wird. Die Suche nach dem optimalen Set wird von einem Fitnesswert geleitet . Wenn das simulierte Glühen abgeschlossen ist, werden alle verschiedenen Teilmengen von Merkmalen verglichen und die am besten geeignete (dh diejenige, die die beste Leistung erbringt) ausgewählt. Die Fitnesswertsuche wurde mit einem Wrapper erhalten, bei dem die k-fache Kreuzvalidierung verwendet wurde, um den Fehler des Klassifizierungsalgorithmus zu berechnen. Verschiedene Kombinationen aus den extrahierten Merkmalen werden aufbereitet, bewertet und mit anderen Kombinationen verglichen. Ein Vorhersagemodell wird dann verwendet, um eine Kombination von Merkmalen zu bewerten und eine Punktzahl basierend auf der Modellgenauigkeit zuzuweisen. Der vom Wrapper angegebene Fitnessfehler wird vom simulierten Glühalgorithmus als Fitnessfehler verwendet. Ein Fuzzy-C-Means-Algorithmus wurde in eine Blackbox eingeschlossen, aus der ein geschätzter Fehler für die verschiedenen Merkmalskombinationen erhalten wurde, wie in Fig. 4.

Das Fuzzy-C-Mittel wird in eine Blackbox eingeschlossen, aus der ein geschätzter Fehler erhalten wird
Das Fuzzy-C-Mittel ermöglicht es, dass Datenpunkte im Datensatz zu allen Clustern gehören, mit Mitgliedschaften im Intervall (0-1) wie in Gl. 6.
wobei \(m_{ik}\) die Zugehörigkeit von Datenpunkt k zum Clusterzentrum i ist, \(d_{jk}\) der Abstand von Clusterzentrum j zum Datenpunkt k ist und q € ein Exponent ist, der entscheidet, wie stark die Mitgliedschaften sein sollen. Der Fuzzy C-means Algorithmus wurde mit der fuzzy Toolbox in Matlab implementiert.
Die Defuzzifizierung
Ein Fuzzy-C-Means-Algorithmus sagt uns nicht, welche Informationen die Cluster enthalten und wie diese Informationen für die Klassifizierung verwendet werden sollen. Sie definiert jedoch, wie Datenpunkten die Zugehörigkeit zu den verschiedenen Clustern zugewiesen wird, und diese unscharfe Zugehörigkeit wird verwendet, um die Klasse eines Datenpunkts vorherzusagen . Dies wird durch Defuzzifizierung überwunden. Es gibt eine Reihe von Defuzzifizierungsmethoden . In diesem Tool hat jeder Cluster jedoch eine Fuzzy-Mitgliedschaft (0-1) aller Klassen im Image. Trainingsdaten werden dem nächstgelegenen Cluster zugewiesen. Der Prozentsatz der Trainingsdaten jeder Klasse, die zu Cluster A gehört, gibt die Zugehörigkeit des Clusters an, Cluster A = zu den verschiedenen Klassen, wobei i die Eindämmung in Cluster A und j im anderen Cluster ist. Das Intensitätsmaß wird der Mitgliedschaftsfunktion für jeden Cluster mithilfe eines Fuzzy-Clustering-Defuzzifizierungsalgorithmus hinzugefügt. Ein populärer Ansatz zur Defuzzifizierung von Fuzzy-Partitionen ist die Anwendung des Prinzips des maximalen Mitgliedschaftsgrads, wobei der Datenpunkt k der Klasse m zugewiesen wird, wenn und nur wenn sein Mitgliedschaftsgrad \ (m_ {ik}\) zum Cluster i der größte ist. In: Chuang et al. vorgeschlagen, den Mitgliedschaftsstatus jedes Datenpunkts anhand des Mitgliedschaftsstatus seiner Nachbarn anzupassen.
Bei dem vorgeschlagenen Ansatz wird eine auf Bayes’scher Wahrscheinlichkeit basierende Defuzzifizierungsmethode verwendet, um ein probabilistisches Modell der Zugehörigkeitsfunktion für jeden Datenpunkt zu erzeugen und das Modell auf das Bild anzuwenden, um die Klassifizierungsinformation zu erzeugen. Das probabilistische Modell wird wie folgt berechnet:
-
Konvertieren Sie die Möglichkeitsverteilungen in der Partitionsmatrix (Cluster) in Wahrscheinlichkeitsverteilungen.
-
Konstruieren Sie ein probabilistisches Modell der Datenverteilungen wie in .
-
Wenden Sie das Modell an, um die Klassifizierungsinformationen für jeden Datenpunkt mit Gl. 7.
wobei \(P \left( {A_{i} } \right),i = 0 \ldots .c\) ist die Vorwahrscheinlichkeit von \(A_ {i}\), die mit der Methode berechnet werden kann, bei der die Vorwahrscheinlichkeit immer proportional zur Masse jeder Klasse ist.
Die Anzahl der zu verwendenden Cluster wurde festgelegt, um sicherzustellen, dass das erstellte Modell die Daten bestmöglich beschreiben kann. Wenn zu viele Cluster ausgewählt werden, besteht die Gefahr einer Überanpassung des Rauschens in den Daten. Wenn zu wenige Cluster ausgewählt werden, kann ein schlechter Klassifikator die Folge sein. Daher wurde eine Analyse der Anzahl der Cluster gegen den Kreuzvalidierungstestfehler durchgeführt. Eine optimale Anzahl von 25 Clustern wurde erreicht und Übertraining trat oberhalb dieser Anzahl von Clustern auf. Ein Defuzzifizierungsexponent von 1.0930 wurde mit 25 Clustern, zehnfacher Kreuzvalidierung und 60 Wiederholungen erhalten und wurde verwendet, um den Fitnessfehler für die Merkmalsauswahl zu berechnen, wobei insgesamt 18 Merkmale aus den 29 Merkmalen für die Konstruktion des Klassifikators ausgewählt wurden. Die ausgewählten Merkmale waren: Kernbereich; Kerngraustufe; Kern kürzester Durchmesser; Kern am längsten; Kernumfang; Maxima im Kern; Minima im Kern; Zytoplasma-Bereich; Zytoplasma-Graustufe; Zytoplasma-Umfang; Verhältnis von Kern zu Zytoplasma; Kernexzentrizität, Kernstandardabweichung, Kerngraustufenvarianz; Kerngraustufenentropie; kern relative Position; Kern Grauwert Mittelwert und Kern Grauwerte Energie.
Klassifikationsbewertung
In diesem Beitrag wurde das von Fryback und Thornbury vorgeschlagene hierarchische Modell der Wirksamkeit diagnostischer Bildgebungssysteme als Leitprinzip für die Bewertung des Werkzeugs übernommen, wie in Tabelle 4 gezeigt.
Sensitivität misst den Anteil der tatsächlichen Positiven, die korrekt als solche identifiziert werden, während Spezifität den Anteil der tatsächlichen Negativen misst, die korrekt als solche identifiziert werden. Sensitivität und Spezifität werden durch Gl. 8.
wobei TP = True positive, FN = False negative, TN = True negative und FP = False Positive sind.
GUI Design und Integration
Die oben beschriebenen Bildverarbeitungsmethoden wurden in Matlab implementiert und werden über eine Java Graphical User Interface (GUI) ausgeführt, die in Abb. 5. Das Tool verfügt über ein Bedienfeld, in dem ein Pap-Abstrichbild geladen wird und der Zytotechniker eine geeignete Methode für die Szenensegmentierung (basierend auf TWS Classifier), die Trümmerentfernung (basierend auf dem Three Sequential Elimination-Ansatz) und die Grenzerfassung auswählt (falls erforderlich, mit der Canny Edge Detection-Methode).
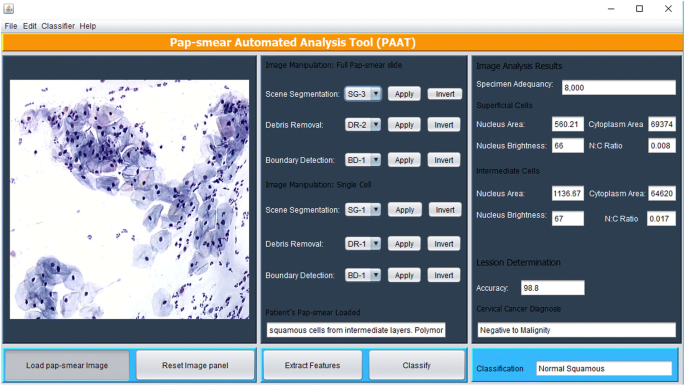
PAT grafische Benutzeroberfläche
Das Tool durchsucht den Pap-Abstrich, um alle Objekte zu analysieren, die nach der Trümmerentfernung zurückgeblieben sind. Die 18 in Merkmalsauswahl beschriebenen Merkmale werden aus jedem Objekt extrahiert und verwendet, um jede Zelle unter Verwendung des in der Klassifizierungsmethode beschriebenen Fuzzy-C-Means-Algorithmus zu klassifizieren. Zufällig extrahierte Merkmale einer Oberflächenzelle und einer Zwischenzelle werden im Bildanalyseergebnisfenster angezeigt. Sobald die Merkmale extrahiert wurden, drückt der Zytotechniker (Benutzer) die Klassifizierungstaste, und das Tool gibt eine Diagnose aus (positiv auf Malignität oder negativ auf Malignität) und klassifiziert die Diagnose gemäß dem Trainingsdatensatz in eine der 7 Klassen / Stadien von Gebärmutterhalskrebs.