Blog
In einem früheren Blogbeitrag haben wir diskutiert, wie Supermärkte Daten verwenden, um die Bedürfnisse der Verbraucher besser zu verstehen und letztendlich ihre Gesamtausgaben zu erhöhen. Eine der Schlüsseltechniken, die von den großen Einzelhändlern verwendet wird, heißt Market Basket Analysis (MBA), die Assoziationen zwischen Produkten aufdeckt, indem sie nach Kombinationen von Produkten sucht, die häufig in Transaktionen auftreten. Mit anderen Worten, es ermöglicht den Supermärkten, Beziehungen zwischen den Produkten zu identifizieren, die Menschen kaufen. Zum Beispiel kaufen Kunden, die einen Bleistift und Papier kaufen, wahrscheinlich einen Gummi oder ein Lineal.
„Die Warenkorbanalyse ermöglicht es Einzelhändlern, Beziehungen zwischen den Produkten zu identifizieren, die Menschen kaufen.“
Einzelhändler können die aus MBA gewonnenen Erkenntnisse auf verschiedene Arten nutzen, darunter:
- Gruppierung von Produkten, die bei der Gestaltung des Ladenlayouts mitspielen, um die Chance auf Cross-Selling zu erhöhen;
- Online-Empfehlungsmaschinen („Kunden, die dieses Produkt gekauft haben, haben sich dieses Produkt auch angesehen“); und
- Targeting von Marketingkampagnen durch Versenden von Werbegutscheinen an Kunden für Produkte, die sich auf kürzlich gekaufte Artikel beziehen.
Angesichts der Beliebtheit und des Wertes von MBA dachten wir, wir würden die folgende Schritt-für-Schritt-Anleitung erstellen, in der beschrieben wird, wie es funktioniert und wie Sie Ihre eigene Warenkorbanalyse durchführen können.
Wie funktioniert die Warenkorbanalyse?
Um einen MBA durchzuführen, benötigen Sie zunächst einen Datensatz mit Transaktionen. Jede Transaktion stellt eine Gruppe von Artikeln oder Produkten dar, die zusammen gekauft wurden und oft als „Itemset“ bezeichnet werden. Zum Beispiel könnte ein Itemset sein: {Bleistift, Papier, Heftklammern, Gummi} in diesem Fall wurden alle diese Artikel in einer einzigen Transaktion gekauft.
In einem MBA werden die Transaktionen analysiert, um Assoziationsregeln zu identifizieren. Eine Regel könnte beispielsweise lauten: {Bleistift, Papier} => {Gummi} . Dies bedeutet, dass ein Kunde, der eine Transaktion hat, die einen Bleistift und Papier enthält, wahrscheinlich daran interessiert ist, auch einen Gummi zu kaufen.
Bevor ein Einzelhändler nach einer Regel handelt, muss er wissen, ob ausreichende Beweise dafür vorliegen, dass dies zu einem positiven Ergebnis führt. Wir messen daher die Stärke einer Regel, indem wir die folgenden drei Metriken berechnen (beachten Sie, dass andere Metriken verfügbar sind, aber dies sind die drei am häufigsten verwendeten):
Unterstützung: Der Prozentsatz der Transaktionen, die alle Elemente in einem Itemset enthalten (z. B. Bleistift, Papier und Gummi). Je höher der Support, desto häufiger tritt das Itemset auf. Regeln mit einer hohen Unterstützung werden bevorzugt, da sie wahrscheinlich auf eine große Anzahl zukünftiger Transaktionen anwendbar sind.
Konfidenz: Die Wahrscheinlichkeit, dass eine Transaktion, die die Elemente auf der linken Seite der Regel (in unserem Beispiel Bleistift und Papier) enthält, auch das Element auf der rechten Seite (ein Gummi) enthält. Je höher das Vertrauen, desto größer ist die Wahrscheinlichkeit, dass der Artikel auf der rechten Seite gekauft wird, oder, mit anderen Worten, desto größer ist die Rücklaufquote, die Sie für eine bestimmte Regel erwarten können.
Anheben: die Wahrscheinlichkeit, dass alle Elemente in einer Regel zusammen auftreten (auch als Unterstützung bezeichnet), dividiert durch das Produkt der Wahrscheinlichkeiten der Elemente auf der linken und rechten Seite, die auftreten, als gäbe es keine Assoziation zwischen ihnen. Zum Beispiel, wenn Bleistift, Papier und Gummi zusammen in 2,5% aller Transaktionen, Bleistift und Papier in 10% der Transaktionen und Gummi in 8% der Transaktionen auftraten, dann wäre der Lift: 0.025/(0.1*0.08) = 3.125. Ein Lift von mehr als 1 deutet darauf hin, dass das Vorhandensein von Bleistift und Papier die Wahrscheinlichkeit erhöht, dass auch ein Gummi in der Transaktion auftritt. Insgesamt fasst lift die Stärke der Assoziation zwischen den Produkten auf der linken und rechten Seite der Regel zusammen; Je größer der Lift, desto größer die Verbindung zwischen den beiden Produkten.
Um eine Warenkorbanalyse durchzuführen und potenzielle Regeln zu identifizieren, wird üblicherweise ein Data-Mining-Algorithmus namens ‚Apriori-Algorithmus‘ verwendet, der in zwei Schritten arbeitet:
- Identifizieren Sie systematisch Itemsets, die häufig im Datensatz mit einer Unterstützung auftreten, die größer als ein vorgegebener Schwellenwert ist.
- Berechnen Sie die Konfidenz aller möglichen Regeln angesichts der häufigen Itemsets und behalten Sie nur diejenigen bei, deren Konfidenz größer als ein vorgegebener Schwellenwert ist.
Die Schwellenwerte, bei denen die Unterstützung und das Vertrauen festgelegt werden, sind benutzerdefiniert und variieren wahrscheinlich zwischen Transaktionsdatensätzen. R hat zwar Standardwerte, aber wir empfehlen Ihnen, mit diesen zu experimentieren, um zu sehen, wie sie sich auf die Anzahl der zurückgegebenen Regeln auswirken (mehr dazu weiter unten). Obwohl der Apriori-Algorithmus Lift nicht zum Festlegen von Regeln verwendet, sehen Sie im Folgenden, dass wir Lift verwenden, wenn wir die vom Algorithmus zurückgegebenen Regeln untersuchen.
Durchführen einer Warenkorbanalyse in R
Um zu demonstrieren, wie ein MBA durchgeführt werden kann, haben wir uns für R und insbesondere für das arules-Paket entschieden. Für Interessierte haben wir den R-Code eingefügt, den wir am Ende dieses Blogs verwendet haben.
Hier folgen wir dem gleichen Beispiel wie in der arulesViz-Vignette und verwenden einen Datensatz von Lebensmittelverkäufen, der 9.835 Einzeltransaktionen mit 169 Artikeln enthält. Als erstes werfen wir einen Blick auf die Positionen in den Transaktionen und zeichnen insbesondere die relative Häufigkeit der 25 häufigsten Elemente in Abbildung 1 auf. Dies entspricht der Unterstützung dieser Elemente, bei denen jedes Itemset nur das einzelne Element enthält. Dieses Balkendiagramm veranschaulicht die Lebensmittel, die häufig in diesem Geschäft gekauft werden, und es ist bemerkenswert, dass die Unterstützung selbst der häufigsten Artikel relativ gering ist (z. B. tritt der häufigste Artikel nur bei etwa 2,5% der Transaktionen auf). Wir verwenden diese Erkenntnisse, um den Mindestschwellenwert bei der Ausführung des Apriori-Algorithmus zu ermitteln; wir wissen zum Beispiel, dass wir den Unterstützungsschwellenwert deutlich unter 0,025 setzen müssen, damit der Algorithmus eine angemessene Anzahl von Regeln zurückgibt.
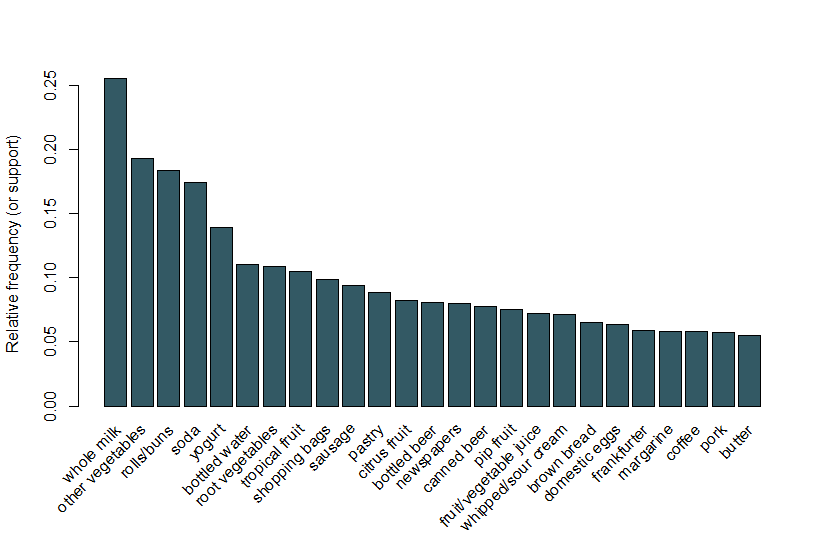
Abbildung 1 Ein Balkendiagramm der Unterstützung der 25 am häufigsten gekauften Artikel.
Wenn wir einen Unterstützungsschwellenwert von 0,001 und eine Konfidenz von 0,5 festlegen, können wir den Apriori-Algorithmus ausführen und einen Satz von 5.668 Ergebnissen erhalten. Diese Schwellenwerte werden so gewählt, dass die Anzahl der zurückgegebenen Regeln hoch ist, aber diese Anzahl würde sich verringern, wenn wir einen der beiden Schwellenwerte erhöhen würden. Wir empfehlen, mit diesen Schwellenwerten zu experimentieren, um die am besten geeigneten Werte zu erhalten. Während es zu viele Regeln gibt, um sie alle einzeln betrachten zu können, können wir uns die fünf Regeln mit dem größten Lift ansehen:
| Regel | Unterstützung | Vertrauen | Lift |
| {instant food products,soda}= >{Hamburgerfleisch} | 0,001 | 0,632 | 19,00 |
| {Soda, Popcorn}=>{salzige Snacks} | 0,001 | 0.632 | 16.70 |
| {flour, baking powder}=>{sugar} | 0.001 | 0.556 | 16.41 |
| {ham, processed cheese}=>{white bread} | 0.002 | 0.633 | 15.05 |
| {whole milk, instant food products}=>{hamburger meat} | 0.002 | 0.500 | 15.04 |
Table 1: The five rules with the largest lift.
These rules seem to make intuitive sense. Zum Beispiel könnte die erste Regel die Art von Gegenständen darstellen, die für einen Grill gekauft wurden, die zweite für einen Filmabend und die dritte zum Backen.
Anstatt die Schwellenwerte zu verwenden, um die Regeln auf einen kleineren Satz zu reduzieren, ist es üblich, dass ein größerer Satz von Regeln zurückgegeben wird, so dass eine größere Chance besteht, relevante Regeln zu generieren. Alternativ können wir Visualisierungstechniken verwenden, um die zurückgegebenen Regeln zu überprüfen und diejenigen zu identifizieren, die wahrscheinlich nützlich sind.
Mit dem arulesViz-Paket zeichnen wir die Regeln nach Vertrauen, Unterstützung und Lift in Abbildung 2. Dieses Diagramm veranschaulicht die Beziehung zwischen den verschiedenen Metriken. Es hat sich gezeigt, dass die optimalen Regeln diejenigen sind, die auf der sogenannten „Support-Confidence-Grenze“ liegen. Im Wesentlichen sind dies die Regeln, die am rechten Rand des Diagramms liegen, wo entweder Unterstützung, Vertrauen oder beides maximiert werden. Die Plot-Funktion im arulesViz-Paket verfügt über eine nützliche interaktive Funktion, mit der Sie einzelne Regeln auswählen können (indem Sie auf den zugehörigen Datenpunkt klicken), sodass die Regeln an der Grenze leicht identifiziert werden können.
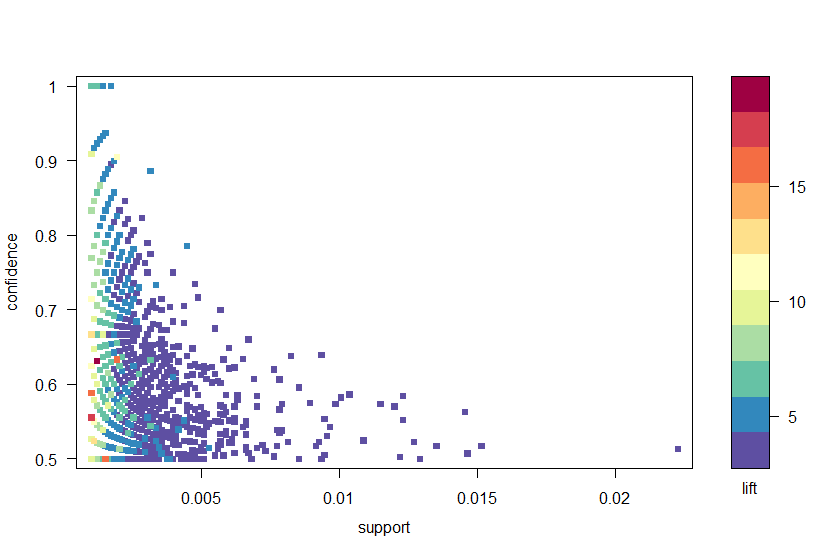
Abbildung 2: Ein Streudiagramm der Konfidenz-, Unterstützungs- und Auftriebsmetriken.
Es gibt viele andere Diagramme, um die Regeln zu visualisieren, aber eine andere Abbildung, die wir empfehlen würden, ist die diagrammbasierte Visualisierung (siehe Abbildung 3) der zehn wichtigsten Regeln in Bezug auf den Lift (Sie können mehr als zehn einbeziehen, aber diese Arten von Diagrammen können leicht überladen werden). In diesem Diagramm stellen die um einen Kreis gruppierten Elemente ein Itemset dar, und die Pfeile geben die Beziehung in Regeln an. Zum Beispiel ist eine Regel, dass der Kauf von Zucker mit dem Kauf von Mehl und Backpulver verbunden ist. Die Größe des Kreises stellt den Vertrauensgrad dar, der mit der Regel verbunden ist, und die Farbe den Liftgrad (je größer der Kreis und je dunkler das Grau, desto besser).
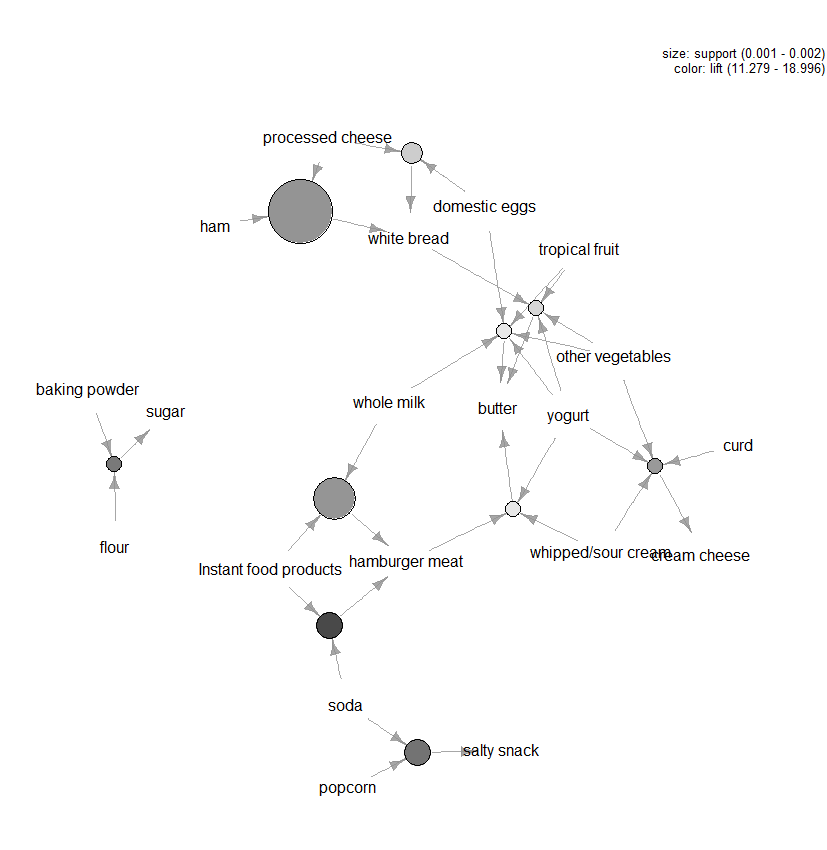
Abbildung 3: Graph-basierte Visualisierung der Top Ten Regeln in Bezug auf Lift.
Die Warenkorbanalyse ist ein nützliches Werkzeug für Einzelhändler, die die Beziehungen zwischen den Produkten, die Menschen kaufen, besser verstehen möchten. Die schwierigsten Aspekte der Analyse sind das Festlegen der Vertrauens- und Unterstützungsschwellenwerte im Apriori-Algorithmus und das Ermitteln, welche Regeln es wert sind, verfolgt zu werden. In der Regel erfolgt letzteres durch Messen der Regeln in Form von Metriken, die zusammenfassen, wie interessant sie sind, mithilfe von Visualisierungstechniken und auch formelleren multivariaten Statistiken. Letztendlich besteht der Schlüssel zum Erfolg darin, einen Mehrwert aus Ihren Transaktionsdaten zu ziehen, indem Sie ein Verständnis für die Bedürfnisse Ihrer Verbraucher aufbauen. Diese Art von Informationen ist von unschätzbarem Wert, wenn Sie an Marketingaktivitäten wie Cross-Selling oder gezielten Kampagnen interessiert sind.
Wenn Sie mehr darüber erfahren möchten, wie Sie Ihre Transaktionsdaten analysieren können, kontaktieren Sie uns bitte und wir helfen Ihnen gerne weiter.
R Code
library("arules")
library("arulesViz")
#Load data set:
data("Groceries")
summary(Groceries)
#Look at data:
inspect(Groceries)
LIST(Groceries)
#Calculate rules using apriori algorithm and specifying support and confidence thresholds:
rules = apriori(Groceries, parameter=list(support=0.001, confidence=0.5))
#Inspect the top 5 rules in terms of lift:
inspect(head(sort(rules, by ="lift"),5))
#Plot a frequency plot:
itemFrequencyPlot(Groceries, topN = 25)
#Scatter plot of rules:
library("RColorBrewer")
plot(rules,control=list(col=brewer.pal(11,"Spectral")),main="")
#Rules with high lift typically have low support.
#The most interesting rules reside on the support/confidence border which can be clearly seen in this plot.