Semantische Segmentierung mit Deep Learning
Dieser Artikel bietet einen umfassenden Überblick und eine Schritt-für-Schritt-Anleitung zur Implementierung eines Deep Learning-Bildsegmentierungsmodells.
Wir haben hier einen neuen aktualisierten Blog zur semantischen Segmentierung veröffentlicht: A 2021 guide to Semantic Segmentation
Heutzutage ist die semantische Segmentierung eines der Hauptprobleme im Bereich der Computer Vision. Mit Blick auf das Gesamtbild ist die semantische Segmentierung eine der wichtigsten Aufgaben, die den Weg zum vollständigen Verständnis der Szene ebnet. Die Bedeutung des Szenenverständnisses als zentrales Computer-Vision-Problem wird durch die Tatsache unterstrichen, dass eine zunehmende Anzahl von Anwendungen davon profitiert, Wissen aus Bildern abzuleiten. Einige dieser Anwendungen umfassen selbstfahrende Fahrzeuge, Mensch-Computer-Interaktion, virtuelle Realität usw. Mit der Popularität von Deep Learning in den letzten Jahren werden viele semantische Segmentierungsprobleme mit tiefen Architekturen, meist faltungsneuralen Netzen, angegangen, die andere Ansätze in Bezug auf Genauigkeit und Effizienz weit übertreffen.
- Was ist semantische Segmentierung?
- Welche semantischen Segmentierungsansätze gibt es?
- 1 — Regionsbasierte semantische Segmentierung
- 2 — Fully Convolutional Network-Based Semantic Segmentation
- 3 — Schwach überwachte semantische Segmentierung
- Semantische Segmentierung mit Vollfaltungsnetzwerk durchführen
- Schritt 1
- Schritt 2
- Schritt 3
- Schritt 4
- Schritt 5
- Sie könnten an unseren neuesten Beiträgen interessiert sein:
Was ist semantische Segmentierung?
Die semantische Segmentierung ist ein natürlicher Schritt in der Progression von der groben zur feinen Inferenz: Der Ursprung könnte bei der Klassifikation liegen, die darin besteht, eine Vorhersage für eine ganze Eingabe zu treffen.Der nächste Schritt ist die Lokalisierung / Erkennung, die nicht nur die Klassen, sondern auch zusätzliche Informationen zur räumlichen Lage dieser Klassen liefert.Schließlich erreicht die semantische Segmentierung eine feinkörnige Inferenz, indem dichte Vorhersagen getroffen werden, die Beschriftungen für jedes Pixel ableiten, sodass jedes Pixel mit der Klasse seines umschließenden Objekts oder seiner Region beschriftet wird.
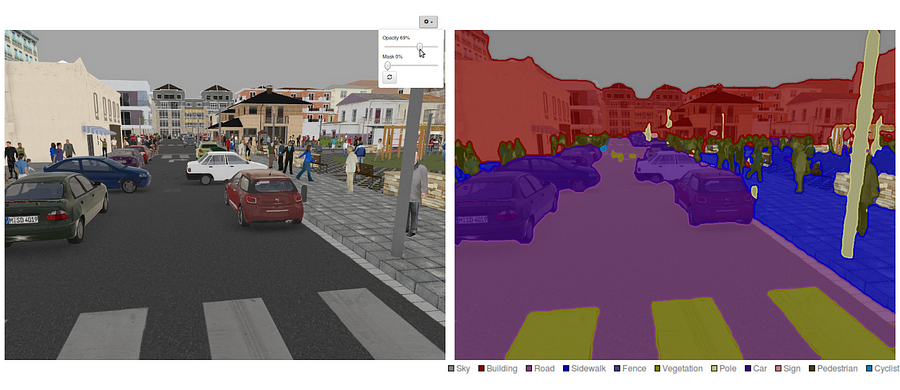
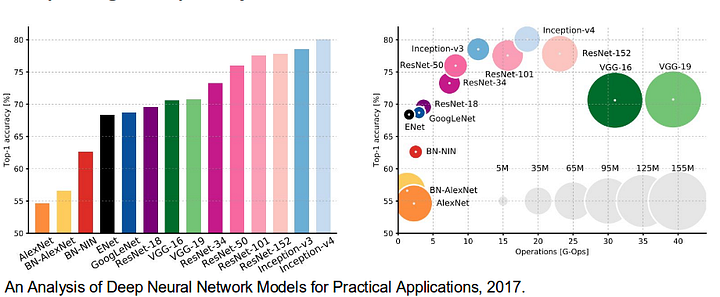
Es lohnt sich auch, einige standard-Deep-Netzwerke, die wesentliche Beiträge zum Bereich der Computer Vision geleistet haben, da sie häufig als Grundlage für semantische Segmentierungssysteme verwendet werden:
- AlexNet: Torontos wegweisendes Deep-Netzwerk, das den ImageNet-Wettbewerb 2012 mit einer Testgenauigkeit von 84,6% gewann. Es besteht aus 5 Faltungsschichten, Max-Pooling-Schichten, ReLUs als Nichtlinearitäten, 3 vollständig Faltungsschichten und Dropout.
- VGG-16: Das diesjährige Modell gewann den ImageNet-Wettbewerb 2013 mit einer Genauigkeit von 92,7%. Es verwendet einen Stapel von Faltungsschichten mit kleinen rezeptiven Feldern in den ersten Schichten anstelle von wenigen Schichten mit großen rezeptiven Feldern.
- GoogLeNet: Dieses Google-Netzwerk gewann den ImageNet-Wettbewerb 2014 mit einer Genauigkeit von 93,3%. Es besteht aus 22 Schichten und einem neu eingeführten Baustein namens Inception Module. Das Modul besteht aus einer Netzwerk-in-Netzwerk-Schicht, einer Pooling-Operation, einer großen Faltungsschicht und einer kleinen Faltungsschicht.
- ResNet: Dieses Microsoft-Modell gewann den ImageNet-Wettbewerb 2016 mit einer Genauigkeit von 96,4 %. Es ist bekannt für seine Tiefe (152 Schichten) und die Einführung von Restblöcken. Die verbleibenden Blöcke adressieren das Problem des Trainings einer wirklich tiefen Architektur, indem Identity Skip-Verbindungen eingeführt werden, damit Layer ihre Eingaben in die nächste Ebene kopieren können.
Welche semantischen Segmentierungsansätze gibt es?
Eine allgemeine semantische Segmentierungsarchitektur kann allgemein als Encoder-Netzwerk gefolgt von einem Decoder-Netzwerk betrachtet werden:
- Der Encoder ist normalerweise ein vortrainiertes Klassifizierungsnetzwerk wie VGG/ResNet gefolgt von einem Decoder-Netzwerk.
- Die Aufgabe des Decoders besteht darin, die vom Encoder gelernten diskriminativen Merkmale (niedrigere Auflösung) semantisch auf den Pixelraum (höhere Auflösung) zu projizieren, um eine dichte Klassifizierung zu erhalten.
Im Gegensatz zur Klassifizierung, bei der das Endergebnis des sehr tiefen Netzwerks das einzig Wichtige ist, erfordert die semantische Segmentierung nicht nur eine Diskriminierung auf Pixelebene, sondern auch einen Mechanismus, um die diskriminierenden Merkmale, die in verschiedenen Phasen des Encoders gelernt wurden, auf den Pixelraum zu projizieren. Verschiedene Ansätze verwenden unterschiedliche Mechanismen als Teil des Decodierungsmechanismus. Lassen Sie uns die 3 Hauptansätze untersuchen:
1 — Regionsbasierte semantische Segmentierung
Die regionsbasierten Methoden folgen im Allgemeinen der Pipeline „Segmentierung mit Erkennung“, die zuerst Freiformregionen aus einem Bild extrahiert und beschreibt, gefolgt von einer regionsbasierten Klassifizierung. Zur Testzeit werden die regionsbasierten Vorhersagen in Pixelvorhersagen umgewandelt, normalerweise durch Beschriften eines Pixels gemäß der Region mit der höchsten Punktzahl, die es enthält.
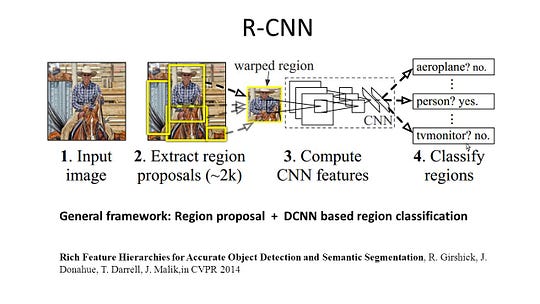
R-CNN (Regionen mit CNN-Funktion) ist eine repräsentative Arbeit für die regionsbasierten Methoden. Es führt die semantische Segmentierung basierend auf den Objekterkennungsergebnissen durch. Um genau zu sein, verwendet R-CNN zuerst die selektive Suche, um eine große Menge von Objektvorschlägen zu extrahieren, und berechnet dann CNN-Features für jedes von ihnen. Schließlich klassifiziert es jede Region unter Verwendung der klassenspezifischen linearen SVMs. Im Vergleich zu herkömmlichen CNN-Strukturen, die hauptsächlich der Bildklassifizierung dienen, kann R-CNN kompliziertere Aufgaben wie Objekterkennung und Bildsegmentierung lösen und wird sogar zu einer wichtigen Grundlage für beide Bereiche. Darüber hinaus kann R-CNN auf beliebigen CNN-Benchmarkstrukturen wie AlexNet, VGG, GoogLeNet und ResNet aufgebaut werden.
Für die Bildsegmentierungsaufgabe extrahierte R-CNN 2 Arten von Features für jede Region: Vollregionsmerkmal und Vordergrundmerkmal, und stellte fest, dass dies zu einer besseren Leistung führen kann, wenn sie als Regionsmerkmal verkettet werden. R-CNN erzielte durch die Verwendung der hochdiskriminierenden CNN-Funktionen signifikante Leistungsverbesserungen. Es hat jedoch auch einige Nachteile für die Segmentierungsaufgabe:
- Die Funktion ist nicht mit der Segmentierungsaufgabe kompatibel.
- Das Feature enthält nicht genügend räumliche Informationen für eine präzise Grenzgenerierung.
- Das Generieren von segmentbasierten Vorschlägen nimmt Zeit in Anspruch und würde die endgültige Leistung stark beeinflussen.
Aufgrund dieser Engpässe wurden neuere Forschungen vorgeschlagen, um die Probleme anzugehen, einschließlich SDS, Hyperspalten und R-CNN.
2 — Fully Convolutional Network-Based Semantic Segmentation
Das ursprüngliche Fully Convolutional Network (FCN) lernt eine Abbildung von Pixel zu Pixel, ohne die Region selbst zu extrahieren. Die FCN-Netzwerkpipeline ist eine Erweiterung des klassischen CNN. Die Hauptidee besteht darin, das klassische CNN dazu zu bringen, Bilder beliebiger Größe als Eingabe zu verwenden. Die Einschränkung von CNNs, Etiketten nur für Eingaben bestimmter Größe zu akzeptieren und zu produzieren, ergibt sich aus den vollständig verbundenen Schichten, die fest sind. Im Gegensatz zu ihnen haben FCNs nur Falt- und Pooling-Schichten, die ihnen die Möglichkeit geben, Vorhersagen über Eingaben beliebiger Größe zu treffen.
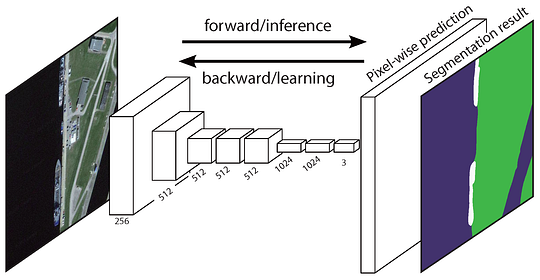
Ein Problem bei diesem speziellen FCN besteht darin, dass durch die Ausbreitung durch mehrere alternierende Falt- und Pooling-Layer die Auflösung der Ausgabe-Feature-Maps verringert wird abgetastet. Daher sind die direkten Vorhersagen von FCN typischerweise in niedriger Auflösung, was zu relativ unscharfen Objektgrenzen führt. Eine Vielzahl fortschrittlicherer FCN-basierter Ansätze wurde vorgeschlagen, um dieses Problem anzugehen, einschließlich SegNet, DeepLab-CRF und erweiterte Windungen.
3 — Schwach überwachte semantische Segmentierung
Die meisten relevanten Methoden der semantischen Segmentierung beruhen auf einer großen Anzahl von Bildern mit pixelweisen Segmentierungsmasken. Das manuelle Kommentieren dieser Masken ist jedoch recht zeitaufwändig, frustrierend und kommerziell teuer. Daher wurden kürzlich einige schwach überwachte Methoden vorgeschlagen, die sich der Erfüllung der semantischen Segmentierung durch Verwendung annotierter Begrenzungsrahmen widmen.

Boxsup verwendete beispielsweise die Bounding-Box-Annotationen als Supervision, um das Netzwerk zu trainieren und die geschätzten Masken für die semantische Segmentierung iterativ zu verbessern. Simple Does It behandelte die schwache Überwachungsbegrenzung als ein Problem des Input-Label-Rauschens und untersuchte das rekursive Training als eine De-Noising-Strategie. Die Beschriftung auf Pixelebene interpretierte die Segmentierungsaufgabe innerhalb des Lernrahmens für mehrere Instanzen und fügte eine zusätzliche Ebene hinzu, um das Modell so einzuschränken, dass wichtigen Pixeln für die Klassifizierung auf Bildebene mehr Gewicht zugewiesen wird.
Semantische Segmentierung mit Vollfaltungsnetzwerk durchführen
In diesem Abschnitt gehen wir Schritt für Schritt durch die Implementierung der beliebtesten Architektur für die semantische Segmentierung – des Vollfaltungsnetzes (FCN). Wir implementieren es mit der TensorFlow-Bibliothek in Python 3 zusammen mit anderen Abhängigkeiten wie Numpy und Scipy.In in dieser Übung beschriften wir die Pixel einer Straße in Bildern mit FCN. Wir arbeiten mit dem Kitti-Straßendatensatz für die Straßen- / Spurerkennung. Dies ist eine einfache Übung aus dem Udacity Self-Driving Car Nano-Degree-Programm, die Sie in diesem GitHub-Repo mehr über das Setup erfahren können.

Hier sind die wichtigsten Funktionen des FCN-Architektur:
- FCN überträgt Wissen aus VGG16, um eine semantische Segmentierung durchzuführen.
- Die vollständig verbundenen Schichten von VGG16 werden mithilfe der 1×1-Faltung in vollständig Faltungsschichten umgewandelt. Dieser Prozess erzeugt eine Class Presence Heatmap in niedriger Auflösung.
- Das Upsampling dieser semantischen Merkmalskarten mit niedriger Auflösung erfolgt unter Verwendung transponierter Faltungen (initialisiert mit bilinearen Interpolationsfiltern).
- In jeder Phase wird der Upsampling-Prozess weiter verfeinert, indem Features aus gröberen, aber höher aufgelösten Feature-Maps aus niedrigeren Layern in VGG16 hinzugefügt werden.
- Skip connection wird nach jedem Faltungsblock eingeführt, damit der nachfolgende Block abstraktere, klassenspezifische Features aus den zuvor gepoolten Features extrahieren kann.
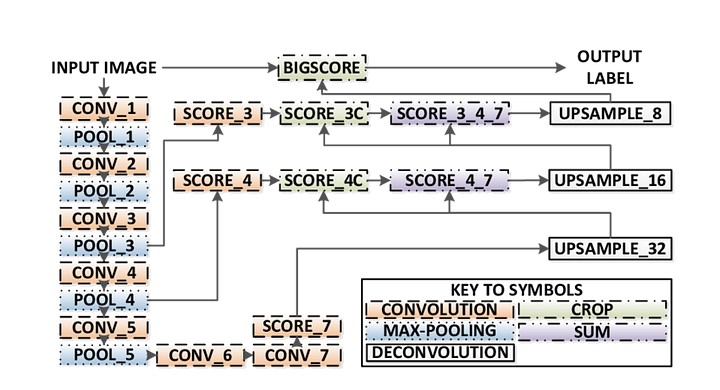
Es gibt 3 Versionen von FCN (FCN-32, FCN-16, FCN-8). Wir implementieren FCN-8, wie unten Schritt für Schritt beschrieben:
- Encoder: Als Encoder wird ein vortrainierter VGG16 verwendet. Der Decoder beginnt mit Schicht 7 von VGG16.
- FCN Layer-8: Die letzte vollständig verbundene Schicht von VGG16 wird durch eine 1×1-Faltung ersetzt.
- FCN-Schicht-9: FCN Layer-8 wird 2 mal hochgesampelt, um die Abmessungen mit Layer 4 von VGG 16 abzugleichen, wobei die transponierte Faltung mit folgenden Parametern verwendet wird: (kernel = (4,4), stride = (2,2), paddding=’same‘). Danach wurde eine Skip-Verbindung zwischen Schicht 4 von VGG16 und FCN-Schicht-9 hinzugefügt.
- FCN Layer-10: FCN Layer-9 wird 2 mal hochgesampelt, um die Abmessungen mit Schicht 3 von VGG16 abzugleichen, wobei die transponierte Faltung mit folgenden Parametern verwendet wird: (kernel =(4,4), stride=(2,2), paddding=’same‘). Danach wurde eine Skip-Verbindung zwischen Schicht 3 von VGG 16 und FCN-Schicht-10 hinzugefügt.
- FCN-Schicht-11: FCN Layer-10 wird 4 Mal hochgesampelt, um die Abmessungen an die Eingabebildgröße anzupassen, sodass wir das tatsächliche Bild zurückerhalten und die Tiefe der Anzahl der Klassen entspricht, wobei die transponierte Faltung mit den Parametern verwendet wird: (kernel = (16,16), stride = (8,8), paddding=’same‘).
Schritt 1
Wir laden zuerst das vortrainierte VGG-16-Modell in TensorFlow. Unter Berücksichtigung der TensorFlow-Sitzung und des Pfads zum VGG-Ordner (der hier heruntergeladen werden kann) geben wir das Tupel der Tensoren aus dem VGG-Modell zurück, einschließlich der Bildeingabe, keep_prob (zur Steuerung der Dropout-Rate), Layer 3, Layer 4 und Layer 7.
def load_vgg(sess, vgg_path): # load the model and weights model = tf.saved_model.loader.load(sess, , vgg_path) # Get Tensors to be returned from graph graph = tf.get_default_graph() image_input = graph.get_tensor_by_name('image_input:0') keep_prob = graph.get_tensor_by_name('keep_prob:0') layer3 = graph.get_tensor_by_name('layer3_out:0') layer4 = graph.get_tensor_by_name('layer4_out:0') layer7 = graph.get_tensor_by_name('layer7_out:0') return image_input, keep_prob, layer3, layer4, layer7VGG16-Funktion
Schritt 2
Jetzt konzentrieren wir uns darauf, die Ebenen für einen FCN mit den Tensoren aus dem VGG-Modell zu erstellen. Angesichts der Tensoren für die Ausgabe der VGG-Ebene und der Anzahl der zu klassifizierenden Klassen geben wir den Tensor für die letzte Ebene dieser Ausgabe zurück. Insbesondere wenden wir eine 1×1-Faltung auf die Encoderschichten an und fügen dem Netzwerk dann Decoderschichten mit Skip-Verbindungen und Upsampling hinzu.
def layers(vgg_layer3_out, vgg_layer4_out, vgg_layer7_out, num_classes): # Use a shorter variable name for simplicity layer3, layer4, layer7 = vgg_layer3_out, vgg_layer4_out, vgg_layer7_out # Apply 1x1 convolution in place of fully connected layer fcn8 = tf.layers.conv2d(layer7, filters=num_classes, kernel_size=1, name="fcn8") # Upsample fcn8 with size depth=(4096?) to match size of layer 4 so that we can add skip connection with 4th layer fcn9 = tf.layers.conv2d_transpose(fcn8, filters=layer4.get_shape().as_list(), kernel_size=4, strides=(2, 2), padding='SAME', name="fcn9") # Add a skip connection between current final layer fcn8 and 4th layer fcn9_skip_connected = tf.add(fcn9, layer4, name="fcn9_plus_vgg_layer4") # Upsample again fcn10 = tf.layers.conv2d_transpose(fcn9_skip_connected, filters=layer3.get_shape().as_list(), kernel_size=4, strides=(2, 2), padding='SAME', name="fcn10_conv2d") # Add skip connection fcn10_skip_connected = tf.add(fcn10, layer3, name="fcn10_plus_vgg_layer3") # Upsample again fcn11 = tf.layers.conv2d_transpose(fcn10_skip_connected, filters=num_classes, kernel_size=16, strides=(8, 8), padding='SAME', name="fcn11") return fcn11Layer-Funktion
Schritt 3
Der nächste Schritt besteht darin, unser neuronales Netzwerk zu optimieren, auch bekannt als TensorFlow-Verlustfunktionen und Optimierungsoperationen. Hier verwenden wir die Kreuzentropie als Verlustfunktion und Adam als Optimierungsalgorithmus.
def optimize(nn_last_layer, correct_label, learning_rate, num_classes): # Reshape 4D tensors to 2D, each row represents a pixel, each column a class logits = tf.reshape(nn_last_layer, (-1, num_classes), name="fcn_logits") correct_label_reshaped = tf.reshape(correct_label, (-1, num_classes)) # Calculate distance from actual labels using cross entropy cross_entropy = tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=correct_label_reshaped) # Take mean for total loss loss_op = tf.reduce_mean(cross_entropy, name="fcn_loss") # The model implements this operation to find the weights/parameters that would yield correct pixel labels train_op = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(loss_op, name="fcn_train_op") return logits, train_op, loss_opFunktion optimieren
Schritt 4
Hier definieren wir die Funktion train_nn, die wichtige Parameter wie Anzahl der Epochen, Stapelgröße, Verlustfunktion, Optimierungsoperation und Platzhalter für Eingabebilder, Etikettenbilder und Lernrate enthält. Für den Trainingsprozess setzen wir außerdem keep_probability auf 0,5 und learning_rate auf 0,001. Um den Fortschritt zu verfolgen, drucken wir auch den Verlust während des Trainings aus.
def train_nn(sess, epochs, batch_size, get_batches_fn, train_op, cross_entropy_loss, input_image, correct_label, keep_prob, learning_rate): keep_prob_value = 0.5 learning_rate_value = 0.001 for epoch in range(epochs): # Create function to get batches total_loss = 0 for X_batch, gt_batch in get_batches_fn(batch_size): loss, _ = sess.run(, feed_dict={input_image: X_batch, correct_label: gt_batch, keep_prob: keep_prob_value, learning_rate:learning_rate_value}) total_loss += loss; print("EPOCH {} ...".format(epoch + 1)) print("Loss = {:.3f}".format(total_loss)) print()Schritt 5
Endlich ist es Zeit, unser Netz zu trainieren! In dieser Run-Funktion erstellen wir zuerst unser Netz mit den Funktionen load_vgg, layers und optimize . Dann trainieren wir das Netz mit der Funktion train_nn und speichern die Inferenzdaten für Datensätze.
def run(): # Download pretrained vgg model helper.maybe_download_pretrained_vgg(data_dir) # A function to get batches get_batches_fn = helper.gen_batch_function(training_dir, image_shape) with tf.Session() as session: # Returns the three layers, keep probability and input layer from the vgg architecture image_input, keep_prob, layer3, layer4, layer7 = load_vgg(session, vgg_path) # The resulting network architecture from adding a decoder on top of the given vgg model model_output = layers(layer3, layer4, layer7, num_classes) # Returns the output logits, training operation and cost operation to be used # - logits: each row represents a pixel, each column a class # - train_op: function used to get the right parameters to the model to correctly label the pixels # - cross_entropy_loss: function outputting the cost which we are minimizing, lower cost should yield higher accuracy logits, train_op, cross_entropy_loss = optimize(model_output, correct_label, learning_rate, num_classes) # Initialize all variables session.run(tf.global_variables_initializer()) session.run(tf.local_variables_initializer()) print("Model build successful, starting training") # Train the neural network train_nn(session, EPOCHS, BATCH_SIZE, get_batches_fn, train_op, cross_entropy_loss, image_input, correct_label, keep_prob, learning_rate) # Run the model with the test images and save each painted output image (roads painted green) helper.save_inference_samples(runs_dir, data_dir, session, image_shape, logits, keep_prob, image_input)Funktion ausführen
Über unsere Parameter wählen wir Epochen = 40, batch_size = 16, num_classes = 2 und image_shape = (160, 576). Nach 2 Testdurchgängen mit Dropout = 0,5 und Dropout = 0,75 stellten wir fest, dass die 2. Studie bessere Ergebnisse mit besseren durchschnittlichen Verlusten liefert.

Den vollständigen Code finden Sie unter diesem Link: https://gist.github.com/khanhnamle1994/e2ff59ddca93c0205ac4e566d40b5e88
Wenn Ihnen dieses Stück gefallen hat, würde ich es gerne teilen 👏 und das Wissen verbreiten.
Sie könnten an unseren neuesten Beiträgen interessiert sein:
- AWS Textract
- Datenextraktion
Verwenden Sie Nanonets für die Automatisierung
Probieren Sie das Modell aus oder fordern Sie noch heute eine Demo an!
JETZT AUSPROBIEREN
