Cómo realizar la segmentación semántica mediante aprendizaje profundo
Este artículo es una descripción general completa que incluye una guía paso a paso para implementar un modelo de segmentación de imágenes de aprendizaje profundo.
Compartimos un nuevo blog actualizado sobre Segmentación Semántica aquí: Una guía de Segmentación Semántica de 2021
Hoy en día, la segmentación semántica es uno de los problemas clave en el campo de la visión por computadora. Mirando el panorama general, la segmentación semántica es una de las tareas de alto nivel que allana el camino hacia la comprensión completa de la escena. La importancia de la comprensión de la escena como un problema central de visión por computadora se destaca por el hecho de que un número creciente de aplicaciones se nutren de la inferencia de conocimientos a partir de imágenes. Algunas de esas aplicaciones incluyen vehículos autónomos, interacción persona-ordenador, realidad virtual, etc. Con la popularidad del aprendizaje profundo en los últimos años, muchos problemas de segmentación semántica se están abordando utilizando arquitecturas profundas, la mayoría de las veces Redes Neuronales convolucionales, que superan a otros enfoques por un gran margen en términos de precisión y eficiencia.
- ¿Qué es la Segmentación Semántica?
- ¿Cuáles son los enfoques de Segmentación semántica existentes?
- 1-Segmentación Semántica Basada en regiones
- 2-Segmentación Semántica Basada en Red Completamente Convolucional
- 3-Segmentación semántica Débilmente supervisada
- Haciendo Segmentación Semántica con Red Completamente Convolucional
- Paso 1
- Paso 2
- Paso 3
- Paso 4
- Paso 5
- Puede estar interesado en nuestras últimas publicaciones en:
¿Qué es la Segmentación Semántica?
La segmentación semántica es un paso natural en la progresión de inferencia gruesa a fina:El origen podría ubicarse en la clasificación, que consiste en hacer una predicción para una entrada completa.El siguiente paso es la localización / detección, que proporciona no solo las clases, sino también información adicional sobre la ubicación espacial de esas clases.Finalmente, la segmentación semántica logra una inferencia de grano fino al hacer predicciones densas que infieren etiquetas para cada píxel, de modo que cada píxel se etiqueta con la clase de su región de mineral de objeto envolvente.
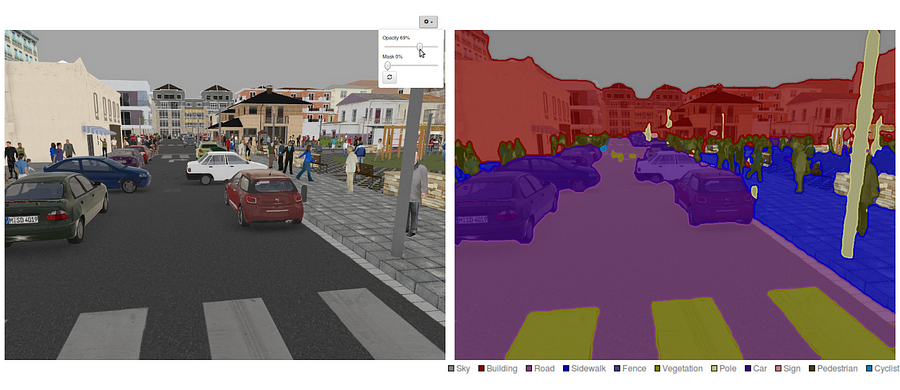
También es digno de revisar algunas redes profundas estándar que han hecho contribuciones significativas al campo de la visión por computadora, ya que a menudo se utilizan como base de sistemas de segmentación semántica:
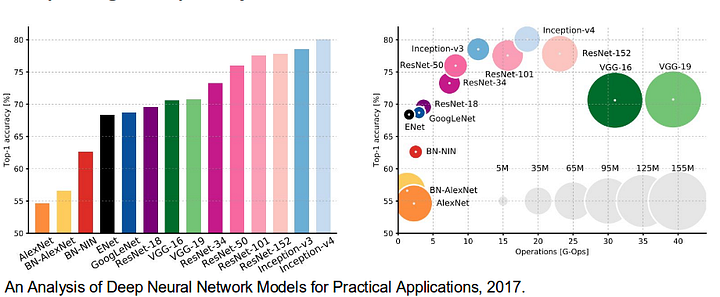
- AlexNet: la pionera deep CNN de Toronto que ganó el concurso ImageNet de 2012 con una precisión de prueba del 84,6%. Consta de 5 capas convolucionales, capas de máximo agrupamiento, ReLUs como no linealidades, 3 capas completamente convolucionales y abandono.
- VGG-16: Este modelo de Oxford ganó el concurso ImageNet 2013 con una precisión del 92,7%. Utiliza una pila de capas de convolución con campos receptivos pequeños en las primeras capas en lugar de pocas capas con campos receptivos grandes.
- GoogLeNet: Esta red de Google ganó el concurso ImageNet 2014 con una precisión del 93,3%. Está compuesto por 22 capas y un bloque de construcción recién introducido llamado módulo de inicio. El módulo consta de una capa de red en red, una operación de agrupación, una capa de convolución de gran tamaño y una capa de convolución de pequeño tamaño.
- ResNet: Este modelo de Microsoft ganó el concurso ImageNet 2016 con una precisión del 96,4%. Es muy conocido por su profundidad (152 capas) y la introducción de bloques residuales. Los bloques residuales abordan el problema de entrenar una arquitectura realmente profunda al introducir conexiones de salto de identidad para que las capas puedan copiar sus entradas a la siguiente capa.
¿Cuáles son los enfoques de Segmentación semántica existentes?
Una arquitectura de segmentación semántica general se puede considerar ampliamente como una red de codificadores seguida de una red de decodificadores:
- El codificador suele ser una red de clasificación preentrenada como VGG/ResNet seguida de una red de decodificadores.
- La tarea del decodificador es proyectar semánticamente las características discriminativas (menor resolución) aprendidas por el codificador en el espacio de píxeles (mayor resolución) para obtener una clasificación densa.
A diferencia de la clasificación, donde el resultado final de la red muy profunda es lo único importante, la segmentación semántica no solo requiere discriminación a nivel de píxel, sino también un mecanismo para proyectar las características discriminatorias aprendidas en diferentes etapas del codificador en el espacio de píxeles. Diferentes enfoques emplean diferentes mecanismos como parte del mecanismo de decodificación. Exploremos los 3 enfoques principales:
1-Segmentación Semántica Basada en regiones
Los métodos basados en regiones generalmente siguen la canalización de «segmentación mediante reconocimiento», que primero extrae regiones de forma libre de una imagen y las describe, seguido de una clasificación basada en regiones. En el momento de la prueba, las predicciones basadas en regiones se transforman en predicciones de píxeles, generalmente etiquetando un píxel de acuerdo con la región de puntuación más alta que lo contiene.
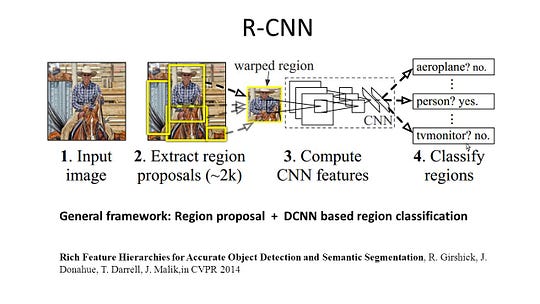
R-CNN (Regiones con función de CNN) es un trabajo representativo para los métodos basados en regiones. Realiza la segmentación semántica en función de los resultados de detección de objetos. Para ser específicos, R-CNN primero utiliza la búsqueda selectiva para extraer una gran cantidad de propuestas de objetos y luego calcula las características de CNN para cada una de ellas. Finalmente, clasifica cada región utilizando los SVM lineales específicos de clase. En comparación con las estructuras tradicionales de CNN, que están destinadas principalmente a la clasificación de imágenes, R-CNN puede abordar tareas más complicadas, como la detección de objetos y la segmentación de imágenes, e incluso se convierte en una base importante para ambos campos. Además, R-CNN se puede construir sobre cualquier estructura de referencia de CNN, como AlexNet, VGG, GoogLeNet y ResNet.
Para la tarea de segmentación de imágenes, R-CNN extrajo 2 tipos de características para cada región: la característica de región completa y la característica de primer plano, y descubrió que podría mejorar el rendimiento al concatenarlas juntas como la característica de región. R-CNN logró mejoras significativas en el rendimiento debido al uso de las características altamente discriminatorias de CNN. Sin embargo, también tiene un par de inconvenientes para la tarea de segmentación:
- La función no es compatible con la tarea de segmentación.
- La entidad no contiene suficiente información espacial para generar límites precisos.
- Generar propuestas basadas en segmentos lleva tiempo y afectaría en gran medida el rendimiento final.
Debido a estos cuellos de botella, se han propuesto investigaciones recientes para abordar los problemas, incluidos SDS, Hipercolumnos, Máscara R-CNN.
2-Segmentación Semántica Basada en Red Completamente Convolucional
La Red Completamente Convolucional original (FCN) aprende un mapeo de píxeles a píxeles, sin extraer las propuestas de región. El canal de la red FCN es una extensión de la clásica CNN. La idea principal es hacer que la CNN clásica tome como entrada imágenes de tamaño arbitrario. La restricción de los CNN para aceptar y producir etiquetas solo para entradas de tamaño específico proviene de las capas completamente conectadas que son fijas. Contrariamente a ellos, los FCN solo tienen capas convolucionales y de agrupación que les dan la capacidad de hacer predicciones sobre entradas de tamaño arbitrario.
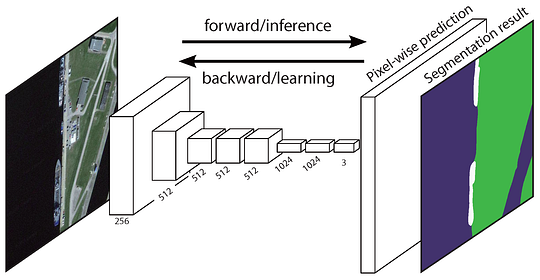
Un problema en esta FCN específica es que al propagarse a través de varias capas convolucionales y de agrupación alternadas, la resolución de la salida los mapas de características están muestreados. Por lo tanto, las predicciones directas de FCN son típicamente de baja resolución, lo que resulta en límites de objetos relativamente difusos. Se han propuesto una variedad de enfoques más avanzados basados en la NFC para abordar este problema, incluidos SegNet, DeepLab-CRF y Convoluciones dilatadas.
3-Segmentación semántica Débilmente supervisada
La mayoría de los métodos relevantes en la segmentación semántica se basan en un gran número de imágenes con máscaras de segmentación en píxeles. Sin embargo, anotar manualmente estas máscaras es bastante lento, frustrante y costoso comercialmente. Por lo tanto, recientemente se han propuesto algunos métodos débilmente supervisados, que están dedicados a cumplir con la segmentación semántica mediante la utilización de cuadros delimitadores anotados.

Por ejemplo, Boxsup empleó las anotaciones de caja delimitadora como supervisión para entrenar la red y mejorar iterativamente las máscaras estimadas para semántica segmentación. Simple Does trató la débil limitación de la supervisión como un problema de ruido de la etiqueta de entrada y exploró el entrenamiento recursivo como una estrategia para eliminar el ruido. El etiquetado a nivel de píxel interpretó la tarea de segmentación dentro del marco de aprendizaje de múltiples instancias y agregó una capa adicional para restringir el modelo para asignar más peso a los píxeles importantes para la clasificación a nivel de imagen.
Haciendo Segmentación Semántica con Red Completamente Convolucional
En esta sección, pasemos por una implementación paso a paso de la arquitectura más popular para la segmentación semántica: la Red Completamente Convolucional (FCN). Lo implementaremos usando la biblioteca TensorFlow en Python 3, junto con otras dependencias como Numpy y Scipy.In en este ejercicio etiquetaremos los píxeles de una carretera en imágenes utilizando FCN. Trabajaremos con el conjunto de datos de carreteras Kitti para la detección de carreteras/carriles. Este es un ejercicio simple del programa de Nano-grado de Auto-Conducción de Udacity, que puedes aprender más sobre la configuración en este repositorio de GitHub.

Estas son las características clave de la arquitectura FCN:
- FCN transfiere el conocimiento de VGG16 para realizar la segmentación semántica.
- Las capas completamente conectadas de VGG16 se convierten en capas completamente convolucionales, utilizando la convolución 1×1. Este proceso produce un mapa de calor de presencia de clase en baja resolución.
- El muestreo de estos mapas de características semánticas de baja resolución se realiza utilizando convoluciones transpuestas (inicializadas con filtros de interpolación bilineal).
- En cada etapa, el proceso de muestreo adicional se perfecciona aún más mediante la adición de características de mapas de características más gruesos pero de mayor resolución de capas inferiores en VGG16.
- La conexión de salto se introduce después de cada bloque de convolución para permitir que el bloque posterior extraiga características más abstractas y sobresalientes de clase de las entidades agrupadas previamente.
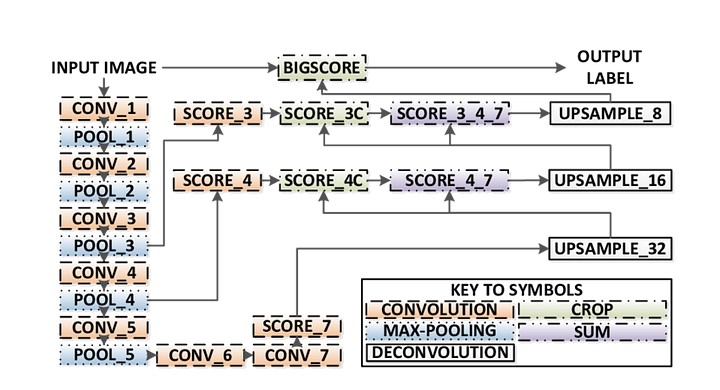
Hay 3 versiones de FCN (FCN-32, FCN-16, FCN-8). Implementaremos FCN-8, como se detalla paso a paso a continuación: Codificador
- : Se utiliza un codificador VGG16 preentrenado. El decodificador comienza en la capa 7 de VGG16.
- Capa FCN-8: La última capa completamente conectada de VGG16 se reemplaza por una convolución 1×1.
- Capa FCN-9: La capa-8 de FCN se muestrea 2 veces para que coincida con las dimensiones de la Capa 4 de VGG 16, utilizando convolución transpuesta con parámetros: (kernel=(4,4), stride=(2,2), paddding=’same’). Después de eso, se agregó una conexión de salto entre la capa 4 de VGG16 y la Capa FCN-9.
- Capa FCN-10: La capa FCN-9 se muestrea 2 veces para que coincida con las dimensiones de la capa 3 de VGG16, utilizando convolución transpuesta con parámetros: (kernel=(4,4), stride=(2,2), paddding=’same’). Después de eso, se agregó una conexión de salto entre la capa 3 de VGG 16 y la Capa FCN-10.
- Capa FCN-11: FCN Layer-10 se muestrea 4 veces para que coincida con las dimensiones con el tamaño de la imagen de entrada, de modo que obtenemos la imagen real y la profundidad es igual al número de clases, utilizando convolución transpuesta con parámetros:(kernel=(16,16), stride=(8,8), paddding=’same’).
Paso 1
Estamos en la primera carga del pre-entrenados VGG-16 modelo en TensorFlow. Tomando la sesión TensorFlow y la ruta a la carpeta VGG (que se puede descargar aquí), devolvemos la tupla de tensores del modelo VGG, incluida la entrada de imagen, keep_prob (para controlar la tasa de abandono), capa 3, capa 4 y capa 7.
def load_vgg(sess, vgg_path): # load the model and weights model = tf.saved_model.loader.load(sess, , vgg_path) # Get Tensors to be returned from graph graph = tf.get_default_graph() image_input = graph.get_tensor_by_name('image_input:0') keep_prob = graph.get_tensor_by_name('keep_prob:0') layer3 = graph.get_tensor_by_name('layer3_out:0') layer4 = graph.get_tensor_by_name('layer4_out:0') layer7 = graph.get_tensor_by_name('layer7_out:0') return image_input, keep_prob, layer3, layer4, layer7Función VGG16
Paso 2
Ahora nos centramos en crear las capas para un FCN, utilizando los tensores del modelo VGG. Dados los tensores para la salida de capa VGG y el número de clases a clasificar, devolvemos el tensor para la última capa de esa salida. En particular, aplicamos una convolución 1×1 a las capas de codificador y, a continuación, agregamos capas de decodificador a la red con conexiones de salto y muestreo ascendente.
def layers(vgg_layer3_out, vgg_layer4_out, vgg_layer7_out, num_classes): # Use a shorter variable name for simplicity layer3, layer4, layer7 = vgg_layer3_out, vgg_layer4_out, vgg_layer7_out # Apply 1x1 convolution in place of fully connected layer fcn8 = tf.layers.conv2d(layer7, filters=num_classes, kernel_size=1, name="fcn8") # Upsample fcn8 with size depth=(4096?) to match size of layer 4 so that we can add skip connection with 4th layer fcn9 = tf.layers.conv2d_transpose(fcn8, filters=layer4.get_shape().as_list(), kernel_size=4, strides=(2, 2), padding='SAME', name="fcn9") # Add a skip connection between current final layer fcn8 and 4th layer fcn9_skip_connected = tf.add(fcn9, layer4, name="fcn9_plus_vgg_layer4") # Upsample again fcn10 = tf.layers.conv2d_transpose(fcn9_skip_connected, filters=layer3.get_shape().as_list(), kernel_size=4, strides=(2, 2), padding='SAME', name="fcn10_conv2d") # Add skip connection fcn10_skip_connected = tf.add(fcn10, layer3, name="fcn10_plus_vgg_layer3") # Upsample again fcn11 = tf.layers.conv2d_transpose(fcn10_skip_connected, filters=num_classes, kernel_size=16, strides=(8, 8), padding='SAME', name="fcn11") return fcn11Función de capas
Paso 3
El siguiente paso es optimizar nuestra red neuronal, también conocida como crear funciones de pérdida de TensorFlow y operaciones de optimizador. Aquí usamos entropía cruzada como nuestra función de pérdida y Adam como nuestro algoritmo de optimización.
def optimize(nn_last_layer, correct_label, learning_rate, num_classes): # Reshape 4D tensors to 2D, each row represents a pixel, each column a class logits = tf.reshape(nn_last_layer, (-1, num_classes), name="fcn_logits") correct_label_reshaped = tf.reshape(correct_label, (-1, num_classes)) # Calculate distance from actual labels using cross entropy cross_entropy = tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=correct_label_reshaped) # Take mean for total loss loss_op = tf.reduce_mean(cross_entropy, name="fcn_loss") # The model implements this operation to find the weights/parameters that would yield correct pixel labels train_op = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(loss_op, name="fcn_train_op") return logits, train_op, loss_opFunción de optimización
Paso 4
Aquí definimos la función train_nn, que incluye parámetros importantes, como el número de épocas, el tamaño del lote, la función de pérdida, la operación del optimizador y marcadores de posición para imágenes de entrada, imágenes de etiquetas, velocidad de aprendizaje. Para el proceso de entrenamiento, también establecemos keep_probability en 0.5 y learning_rate en 0.001. Para hacer un seguimiento del progreso, también imprimimos la pérdida durante el entrenamiento.
def train_nn(sess, epochs, batch_size, get_batches_fn, train_op, cross_entropy_loss, input_image, correct_label, keep_prob, learning_rate): keep_prob_value = 0.5 learning_rate_value = 0.001 for epoch in range(epochs): # Create function to get batches total_loss = 0 for X_batch, gt_batch in get_batches_fn(batch_size): loss, _ = sess.run(, feed_dict={input_image: X_batch, correct_label: gt_batch, keep_prob: keep_prob_value, learning_rate:learning_rate_value}) total_loss += loss; print("EPOCH {} ...".format(epoch + 1)) print("Loss = {:.3f}".format(total_loss)) print()Paso 5
¡Finalmente, es hora de entrenar nuestra red! En esta función ejecutar, primero construimos nuestra red usando la función load_vgg, layers y optimize. Luego entrenamos la red usando la función train_nn y guardamos los datos de inferencia para registros.
def run(): # Download pretrained vgg model helper.maybe_download_pretrained_vgg(data_dir) # A function to get batches get_batches_fn = helper.gen_batch_function(training_dir, image_shape) with tf.Session() as session: # Returns the three layers, keep probability and input layer from the vgg architecture image_input, keep_prob, layer3, layer4, layer7 = load_vgg(session, vgg_path) # The resulting network architecture from adding a decoder on top of the given vgg model model_output = layers(layer3, layer4, layer7, num_classes) # Returns the output logits, training operation and cost operation to be used # - logits: each row represents a pixel, each column a class # - train_op: function used to get the right parameters to the model to correctly label the pixels # - cross_entropy_loss: function outputting the cost which we are minimizing, lower cost should yield higher accuracy logits, train_op, cross_entropy_loss = optimize(model_output, correct_label, learning_rate, num_classes) # Initialize all variables session.run(tf.global_variables_initializer()) session.run(tf.local_variables_initializer()) print("Model build successful, starting training") # Train the neural network train_nn(session, EPOCHS, BATCH_SIZE, get_batches_fn, train_op, cross_entropy_loss, image_input, correct_label, keep_prob, learning_rate) # Run the model with the test images and save each painted output image (roads painted green) helper.save_inference_samples(runs_dir, data_dir, session, image_shape, logits, keep_prob, image_input)Función de ejecución
Sobre nuestros parámetros, elegimos epochs = 40, batch_size = 16, num_classes = 2 e image_shape = (160, 576). Después de hacer 2 pases de prueba con abandono = 0.5 y abandono = 0.75, encontramos que el 2do ensayo produce mejores resultados con mejores pérdidas promedio.

Para ver el código completo, consulte este enlace: https://gist.github.com/khanhnamle1994/e2ff59ddca93c0205ac4e566d40b5e88
Si disfrutaras de esta pieza, me encantaría compartirla 👏 y difundir el conocimiento.
Puede estar interesado en nuestras últimas publicaciones en:
- AWS Textract
- Extracción de datos
Comience a usar Nanonets para la automatización
Pruebe el modelo o solicite una demostración hoy mismo!
intento
