seaborn.histplot¶
seaborn.histplot(data=None, *, x=None, y=None, hue=None, weights=None, stat=’count’, bins=’auto’, binwidth=None, binrange=None, discrete=None, cumulative=False, common_bins=True, common_norm=True, multiple=’layer’, element=’bars’, fill=True, shrink=1, kde=False, kde_kws=None, line_kws=None, thresh=0, pthresh=None, pmax=None, cbar=False, cbar_ax=None, cbar_kws=None, palette=None, hue_order=None, hue_norm=None, color=None, log_scale=None, legend=True, ax=None, **kwargs)¶
Plot histogramas univariados o bivariados para mostrar distribuciones de DataSet.
Un histograma es una herramienta de visualización clásica que representa la distribución de una o más variables contando el número de observaciones que caen con contenedores aislados.
Esta función puede normalizar la estadística calculada dentro de cada bin para estimar la frecuencia, densidad o masa de probabilidad, y puede agregar una curva suave obtenida utilizando una estimación de densidad del núcleo, similar a kdeplot().
Se proporciona más información en la guía del usuario.
Datos de parámetrospandas.DataFramenumpy.ndarray, mapeo o secuencia
Estructura de datos de entrada. Una colección de vectores de formato largo que se puede asignar a variables con nombre o un conjunto de datos de formato ancho que se configurará internamente.
x, yvectores o claves endata
Variables que especifican posiciones en los ejes x e y.
huevector o key indata
Variable semántica que se asigna para determinar el color de los elementos de la gráfica.
weightsvector o key indata
Si se proporciona, pondere la contribución de los puntos de datos correspondientes al recuento en cada bin por estos factores.
stat {«conteo», «frecuencia», «densidad», «probabilidad»}
Estadística agregada para calcular en cada bin.
-
countmuestra el número de observaciones -
frequencymuestra el número de observaciones dividido por el ancho de la bandeja -
densitynormaliza recuentos para que el área del histograma sea 1 -
probabilitynormaliza los recuentos para que la suma de las alturas de barra sea 1
binsstr, número, vector o un par de dichos valores
Parámetro genérico de bin que puede ser el nombre de una regla de referencia, el número de contenedores o los saltos de los contenedores.Pasado a numpy.histogram_bin_edges().
binwidthnumber o par de números
Ancho de cada bin, anula binspero se puede usar conbinrange.
binrangepair de números o un par de pares
Valor más bajo y más alto para bordes de bin; se puede usar con binso binwidth. Los valores predeterminados son extremos de datos.
discretebool
Si es True, el valor predeterminado esbinwidth=1 y dibuja las barras para que se centren en sus puntos de datos correspondientes. Esto evita «huecos» que pueden aparecer de otro modo cuando se utilizan datos discretos (enteros).
herramienta acumulativa
Si es verdadera, trace los recuentos acumulativos a medida que aumentan los contenedores.
common_binsbool
Si es True, utilice los mismos contenedores cuando las variables semánticas produzcan multipleplots. Si se utiliza una regla de referencia para determinar los contenedores, se calculará con el conjunto de datos completo.
common_normbool
Si es True y utiliza una estadística normalizada, la normalización se aplicará sobre el conjunto de datos completo. De lo contrario, normalice cada histograma de forma independiente.
{«capa», «esquivar», «apilar», «rellenar»}
Enfoque para resolver varios elementos cuando la asignación semántica crea subconjuntos.Solo relevante con datos univariados.
elemento {«barras», «paso», «poli»}
Representación visual de la estadística del histograma.Solo relevante con datos univariados.
fillbool
Si es verdadero, rellene el espacio debajo del histograma.Solo relevante con datos univariados.
número de contracción
Escala el ancho de cada barra en relación con el ancho de la bandeja por este factor.Solo relevante con datos univariados.
kdebool
Si es True, calcule una estimación de densidad del núcleo para suavizar la distribución y se muestre en la gráfica como (una o más) línea(s).Solo relevante con datos univariados.
kde_kwsdict
Parámetros que controlan el cálculo de KDE, como en kdeplot().
line_kwsdict
Parámetros que controlan la visualización de KDE, pasados amatplotlib.axes.Axes.plot().las celdas
número de trilla o Ninguno
con una estadística menor o igual a este valor serán transparentes.Solo relevante con datos bivariados.
pthreshnumber o None
Como thresh, pero un valor tal que las celdas con recuentos agregados (u otras estadísticas, cuando se utilicen) hasta esta proporción del total serán transparentes.
pmáxnúmero o Ninguno
Un valor que establece el punto de saturación para el mapa de colores en un valor tal que las celdas de abajo constituyen esta proporción del recuento total (u otra estadística, cuando se usa).
cbarbool
Si es True, agregue una barra de color para anotar la asignación de colores en una gráfica bivariada.Nota: Actualmente no admite gráficas con un pozo variable hue.
cbar_axmatplotlib.axes.Axes
Ejes preexistentes para la barra de color.
cbar_kwsdict
Parámetros adicionales pasados a matplotlib.figure.Figure.colorbar().
palettring, list, dict omatplotlib.colors.Colormap
Método para elegir los colores que se utilizarán al asignar el hue semántico.Los valores de cadena se pasan a color_palette(). Los valores de lista o dicto simplifican la asignación categórica, mientras que un objeto de mapa de colores implica una asignación numérica.
hue_ordervector de cadenas
Especifique el orden de procesamiento y trazado para los niveles categóricos delhue semántico.
hue_normtuple omatplotlib.colors.Normalize
Un par de valores que establecen el rango de normalización en unidades de datos o un objeto que se asignará desde unidades de datos a un intervalo. Usaimplia el mapeo numérico.
colormatplotlib color
Especificación de color único para cuando no se utiliza la asignación de tonos. De lo contrario, theplot intentará engancharse al ciclo de propiedad matplotlib.
log_scalebool o number, o par de bools o numbers
Establezca una escala de registro en el eje de datos (o ejes, con datos bivariados) con la base dada (por defecto 10), y evalúe el KDE en el espacio de registro.
legendbool
Si es falso, suprima la leyenda para las variables semánticas.
axmatplotlib.axes.Axes
Ejes preexistentes para la gráfica. De lo contrario, llame internamente a matplotlib.pyplot.gca().
kwargs
Otros argumentos de palabra clave se pasan a una de las siguientes funciones matplotlib:
-
matplotlib.axes.Axes.bar()(univariate, element=»bars») -
matplotlib.axes.Axes.fill_between()(univariate, other element, fill=True) -
matplotlib.axes.Axes.plot()(univariate, other element, fill=False) -
matplotlib.axes.Axes.pcolormesh()(bivariate)
Returnsmatplotlib.axes.Axes
The matplotlib axes containing the plot.
See also
displot
Figure-level interface to distribution plot functions.
kdeplot
Trace distribuciones univariadas o bivariadas utilizando la estimación de densidad del núcleo.
rugplot
Trace una marca en cada valor de observación a lo largo de los ejes x y / o y.
ecdfplot
Trazar funciones de distribución acumulativas empíricas.
jointplot
Dibuja una gráfica bivariada con distribuciones marginales univariadas.
Notas
La elección de contenedores para calcular y trazar un histograma puede ejercer una influencia sustancial en las percepciones que uno es capaz de extraer de la visualización. Si los contenedores son demasiado grandes, pueden borrar características importantes.Por otro lado, los contenedores que son demasiado pequeños pueden estar dominados por la aleatoriedad, oscureciendo la forma de la verdadera distribución subyacente. El tamaño predeterminado de la bandeja se determina mediante una regla de referencia que depende del tamaño de la muestra y la varianza. Esto funciona bien en muchos casos (es decir, con datos»de buen comportamiento»), pero falla en otros. Siempre es bueno probar diferentes tamaños de contenedores para asegurarse de que no le falta algo importante.Esta función le permite especificar contenedores de varias maneras diferentes, por ejemplo, estableciendo el número total de contenedores a usar, el ancho de cada contenedor o las ubicaciones específicas donde los contenedores deben romperse.
Ejemplos
Asignar una variable a x para trazar un univariante distribución a lo largo del eje x:
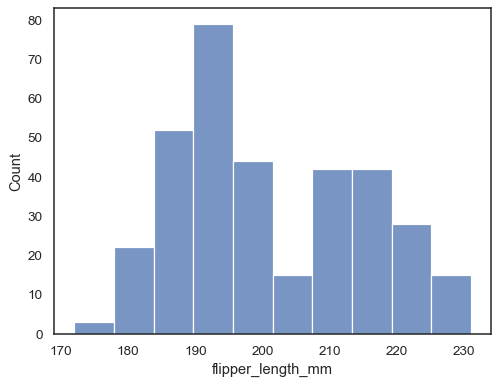
penguins = sns.load_dataset("penguins")sns.histplot(data=penguins, x="flipper_length_mm")
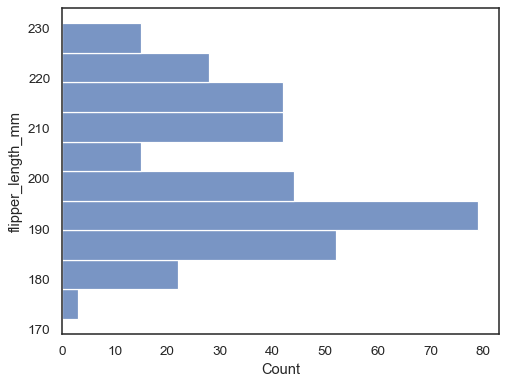
Voltear la parcela mediante la asignación de la variable de datos para el eje y:
sns.histplot(data=penguins, y="flipper_length_mm")
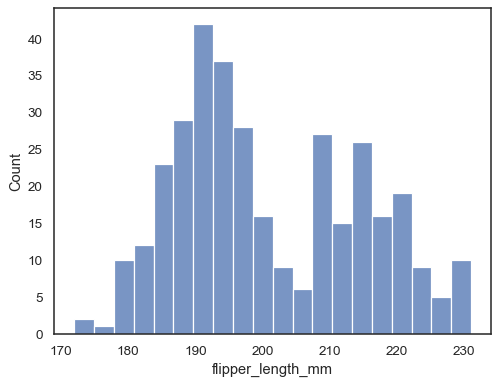
Compruebe qué tan bien representa el histograma los datos especificando un ancho de bin diferente:
sns.histplot(data=penguins, x="flipper_length_mm", binwidth=3)
también puede definir el número total de contenedores de uso:
sns.histplot(data=penguins, x="flipper_length_mm", bins=30)
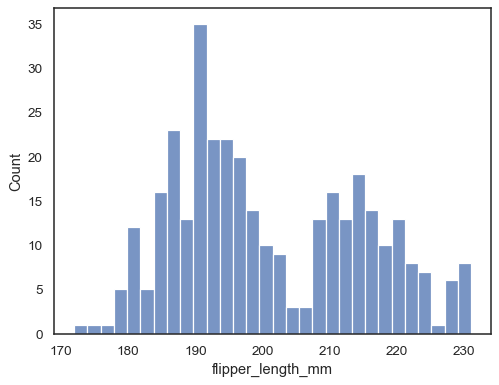
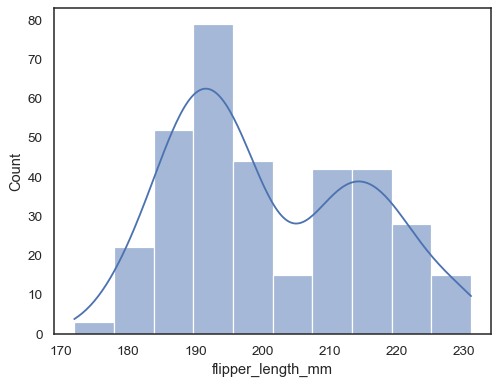
Agregue una estimación de densidad del núcleo para suavizar el histograma, proporcionando información complementaria sobre la forma de la distribución:
sns.histplot(data=penguins, x="flipper_length_mm", kde=True)
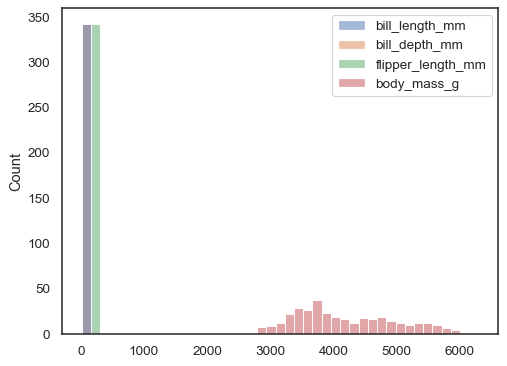
Si no x ni y es asignado, el conjunto de datos es tratado aswide-forma, y un histograma se dibuja para cada columna numérica:
sns.histplot(data=penguins)
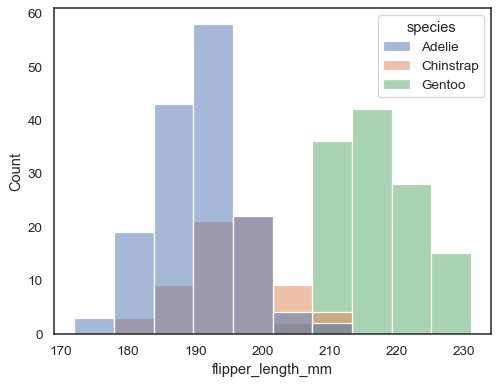
De lo contrario, puede dibujar varios histogramas de un conjunto de datos de formato largo con asignación de valor:
sns.histplot(data=penguins, x="flipper_length_mm", hue="species")
El enfoque predeterminado para trazar distribuciones múltiples es «superponerlas» , pero también puede «apilarlas»:
sns.histplot(data=penguins, x="flipper_length_mm", hue="species", multiple="stack")
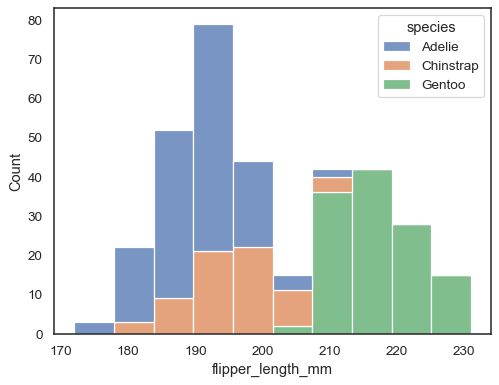
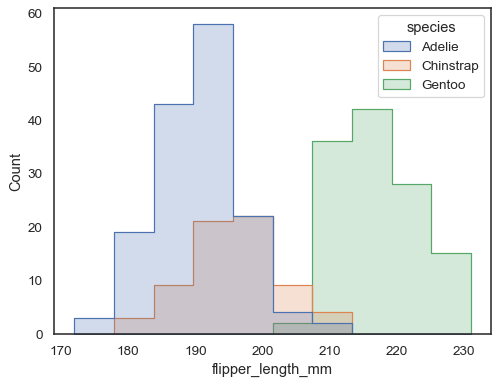
Las barras superpuestas pueden ser difíciles de resolver visualmente. Diferentes approachwould ser para dibujar una función de paso:
sns.histplot(penguins, x="flipper_length_mm", hue="species", element="step")
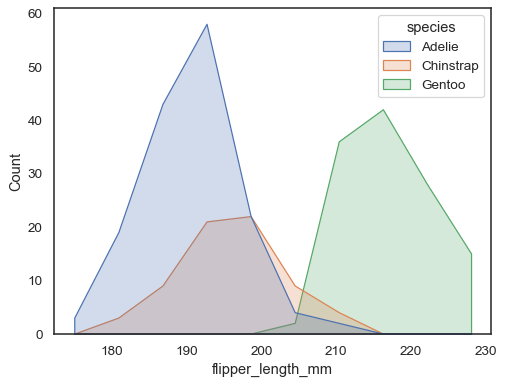
Puede alejarse aún más de las barras dibujando un polígono con vértices en el centro de cada bandeja. Esto puede hacer que sea más fácil ver la forma de la distribución, pero úselo con precaución: será menos obvio para su audiencia que esté mirando un histograma:
sns.histplot(penguins, x="flipper_length_mm", hue="species", element="poly")
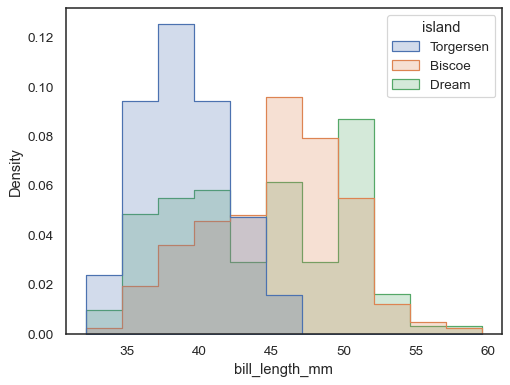
Para comparar la distribución de subconjuntos que difieren sustancialmente en el interior, utilice normalización de densidad independiente:
sns.histplot( penguins, x="bill_length_mm", hue="island", element="step", stat="density", common_norm=False,)
también Es posible normalizar de manera que cada altura de la barra muestra aprobability, que tiene más sentido para variables discretas:
tips = sns.load_dataset("tips")sns.histplot(data=tips, x="size", stat="probability", discrete=True)
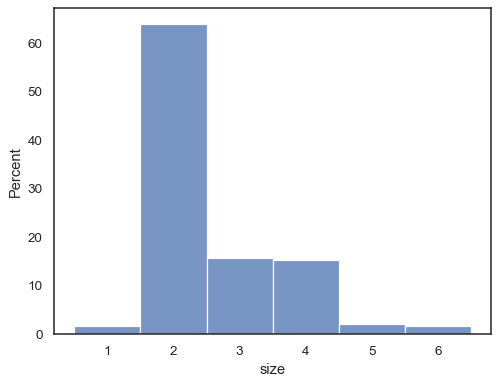
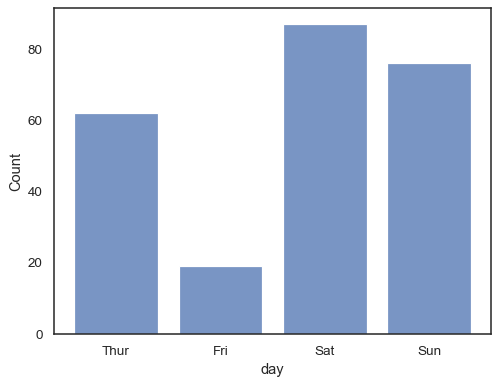
Usted puede incluso dibujar un histograma sobre las variables categóricas (aunque estoes una característica experimental):
sns.histplot(data=tips, x="day", shrink=.8)
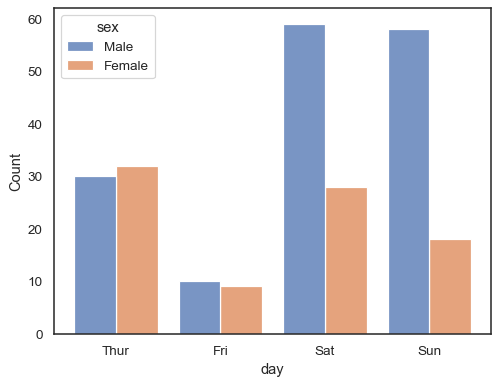
Cuando se utiliza un hue semántica con datos discretos, que pueda dar sentido a»dodge» los niveles:
sns.histplot(data=tips, x="day", hue="sex", multiple="dodge", shrink=.8)
Los datos del mundo real a menudo están sesgados. Para distribuciones muy sesgadas, es mejor definir los contenedores en el espacio de registro. Comparar:
planets = sns.load_dataset("planets")sns.histplot(data=planets, x="distance")
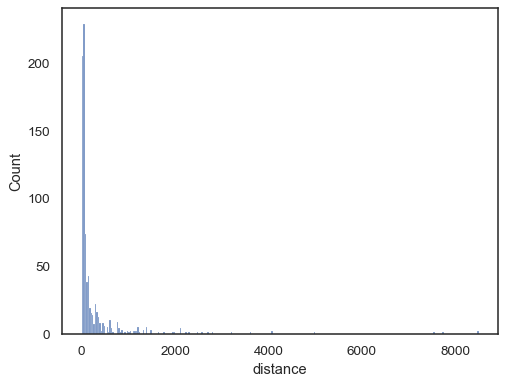
To the log-scale version:
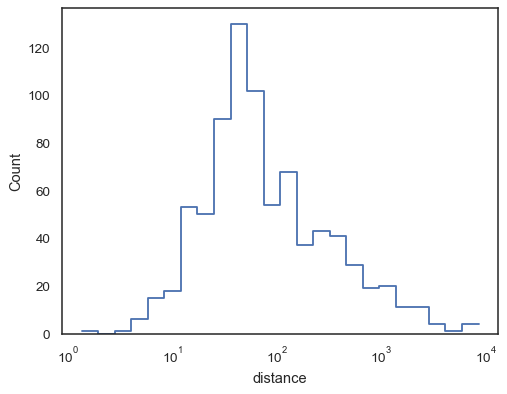
sns.histplot(data=planets, x="distance", log_scale=True)
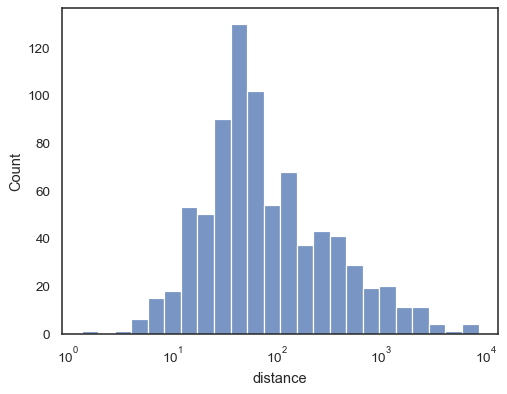
There are also a number of options for how the histogram appears. Youcan show unfilled bars:
sns.histplot(data=planets, x="distance", log_scale=True, fill=False)
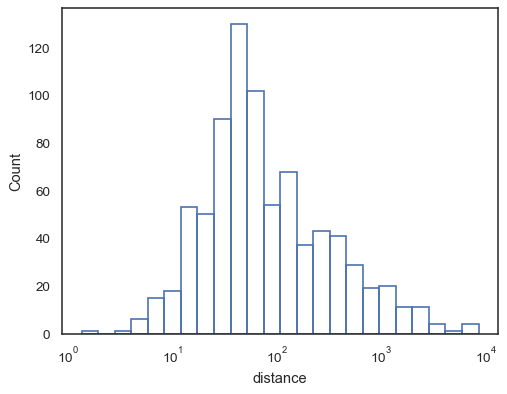
Or an unfilled step function:
sns.histplot(data=planets, x="distance", log_scale=True, element="step", fill=False)
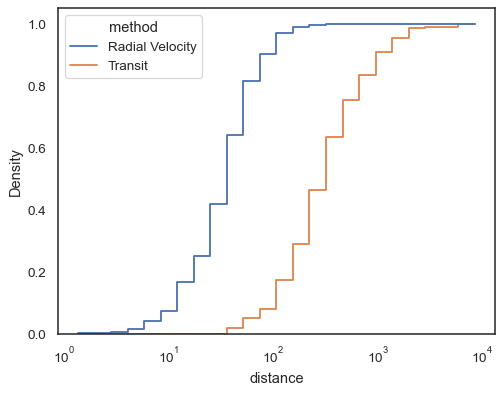
, esencialmente cuando no están llenas, facilitan la comparación de histogramas acumulativos:
sns.histplot( data=planets, x="distance", hue="method", hue_order=, log_scale=True, element="step", fill=False, cumulative=True, stat="density", common_norm=False,)
ambos x y y son asignados, un bivariante histograma iscomputed y se muestra como un mapa de calor:
sns.histplot(penguins, x="bill_depth_mm", y="body_mass_g")
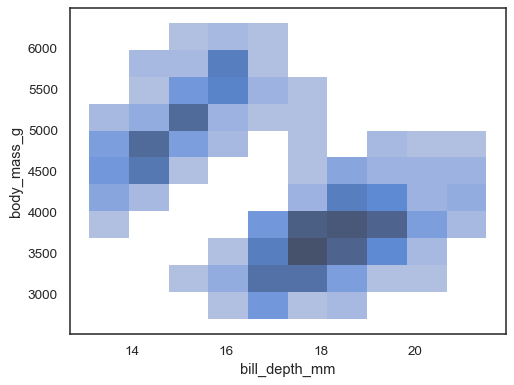
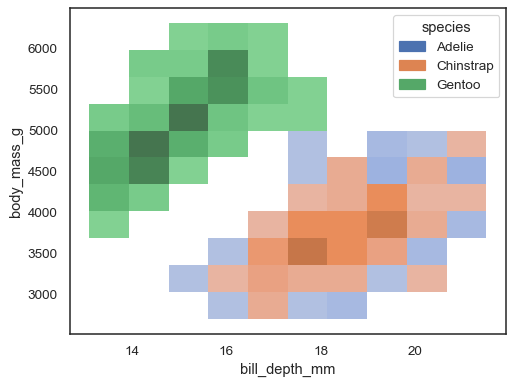
Es posible asignar un hue variable también, aunque esto notwork bien si los datos de los diferentes niveles tienen solapamiento sustancial:
sns.histplot(penguins, x="bill_depth_mm", y="body_mass_g", hue="species")
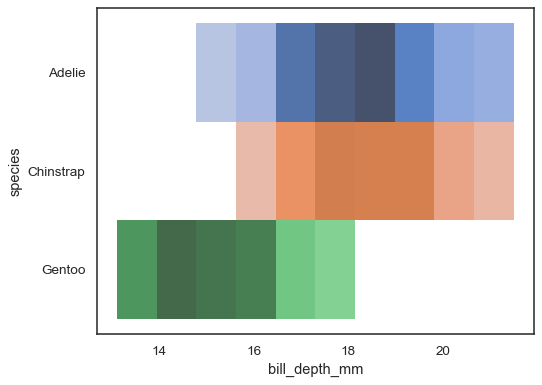
Varios mapas a color puede tener sentido cuando una de las variables isdiscrete:
sns.histplot( penguins, x="bill_depth_mm", y="species", hue="species", legend=False)
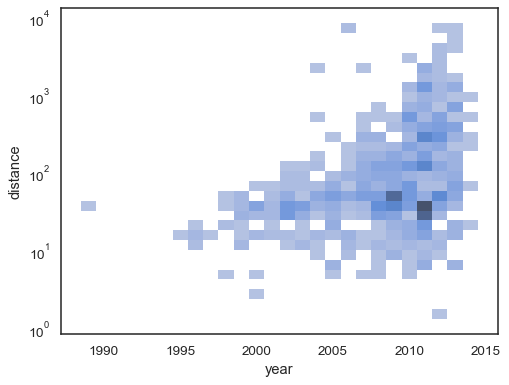
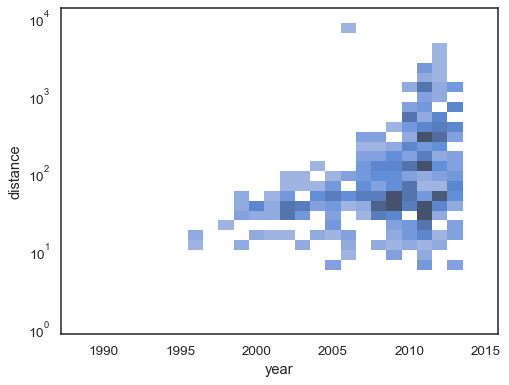
El histograma bivariado acepta todas las mismas opciones de cálculo como su contraparte univariante, utilizando tuplas para parametrizar x yy independientemente:
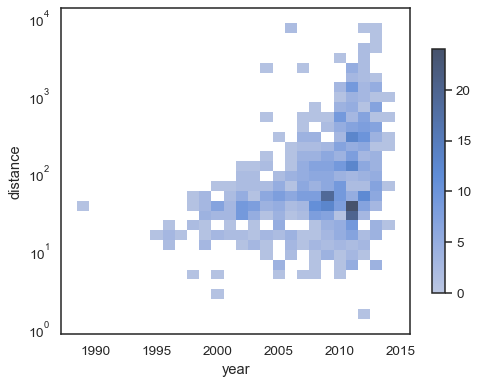
sns.histplot( planets, x="year", y="distance", bins=30, discrete=(True, False), log_scale=(False, True),)
El comportamiento predeterminado hace que las células sin observaciones transparente,aunque esto puede ser desactivado:
sns.histplot( planets, x="year", y="distance", bins=30, discrete=(True, False), log_scale=(False, True), thresh=None,)
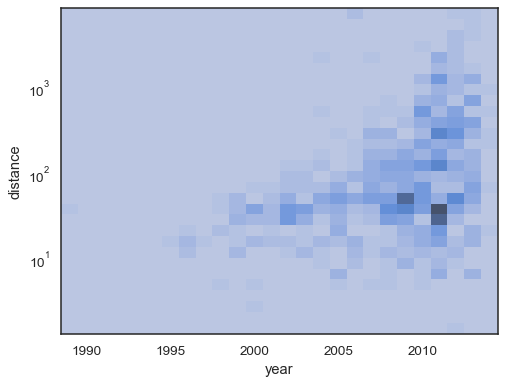
También es posible establecer el umbral y el punto de saturación del mapa de colores de la proporción de recuentos acumulativos:
sns.histplot( planets, x="year", y="distance", bins=30, discrete=(True, False), log_scale=(False, True), pthresh=.05, pmax=.9,)
Para anotar en el mapa de color, agregar un colorbar:
sns.histplot( planets, x="year", y="distance", bins=30, discrete=(True, False), log_scale=(False, True), cbar=True, cbar_kws=dict(shrink=.75),)