Una herramienta de análisis de papanicolaou (PAT) para la detección de cáncer de cuello uterino a partir de imágenes de papanicolaou
- Análisis de imágenes
- Adquisición de imágenes
- Mejora de imagen
- Segmentación de escenas
- Eliminación de desechos
- Análisis de tamaño
- Análisis de formas
- Análisis de texturas
- Extracción de entidades
- Selección de entidades es el proceso de selección de subconjuntos de las entidades extraídas que dan los mejores resultados de clasificación. Entre esas características extraídas, algunas pueden contener ruido, mientras que el clasificador elegido puede no utilizar otras. Por lo tanto, se debe determinar un conjunto óptimo de características, posiblemente probando todas las combinaciones. Sin embargo, cuando hay muchas características, las posibles combinaciones explotan en número y esto aumenta la complejidad computacional del algoritmo. Los algoritmos de selección de características se clasifican ampliamente en los métodos de filtro, envoltura y embebido .
- La defuzzificación
- Evaluación de clasificación
- Diseño e integración de GUI
Análisis de imágenes
La tubería de análisis de imágenes para el desarrollo de una herramienta de análisis de papanicolaou para la detección de cáncer de cuello uterino a partir de papanicolaou presentada en este artículo se muestra en la Fig. 1.

El enfoque para lograr la detección del cáncer de cuello uterino a partir de imágenes de papanicolaou
Adquisición de imágenes
El enfoque se evaluó utilizando tres conjuntos de datos. El conjunto de datos 1 consta de 917 células individuales de imágenes de papanicolaou de Harlev preparadas por Jantzen et al. . El conjunto de datos contiene imágenes de frotis de papanicolaou tomadas con una resolución de 0,201 µm / píxel por citopatólogos expertos que utilizan un microscopio conectado a un capturador de fotogramas. Las imágenes se segmentaron utilizando el software comercial CHAMP y luego se clasificaron en siete clases con características distintas, como se muestra en la Tabla 2. De estas 200 imágenes se utilizaron para entrenamiento y 717 para pruebas.
El conjunto de datos 2 consta de 497 imágenes de frotis de papanicolaou de diapositivas completas preparadas por Norup et al. . De estas 200 imágenes se utilizaron para entrenamiento y 297 para pruebas. Además, el rendimiento del clasificador se evaluó en el Conjunto de datos 3 de muestras de 60 pruebas de papanicolaou (30 normales y 30 anormales) obtenidas del Hospital Regional de Referencia de Mbarara (MRRH). Se tomaron imágenes de las muestras utilizando un microscopio de campo brillante Olympus BX51 equipado con una lente de 40×, 0,95 NA y una cámara monocromática Hamamatsu ORCA-05G de 1,4 Mpx, lo que dio un tamaño de píxel de 0,25 µm con una profundidad gris de 8 bits. Cada imagen se dividió en 300 áreas con cada área que contenía entre 200 y 400 celdas. Sobre la base de las opiniones de los citopatólogos, se seleccionaron 10.000 objetos en imágenes derivadas de los 60 portaobjetos de papanicolaou diferentes, de los cuales 8.000 eran células epiteliales cervicales en posición libre (3.000 células normales de frotis normales y 5.000 células anormales de frotis anormales) y los 2.000 restantes eran objetos de desecho. Esta segmentación por frotis de pap se logró utilizando el kit de herramientas de segmentación Weka entrenable para construir un clasificador de segmentación a nivel de píxel.
Mejora de imagen
Se aplicó una ecualización de histograma adaptativo local de contraste (CLAHE) a la imagen en escala de grises para mejorar la imagen . En CLAHE, la selección del límite de clip que especifica la forma deseada del histograma de la imagen es primordial, ya que influye de manera crítica en la calidad de la imagen mejorada. El valor óptimo del límite de clip se seleccionó empíricamente utilizando el método definido por Joseph et al. . Un valor límite de clip óptimo de 2.se determinó que 0 era apropiado para proporcionar una mejora de imagen adecuada al tiempo que se preservaban las características oscuras para los conjuntos de datos utilizados. La conversión a escala de grises se logró utilizando una técnica de escala de grises implementada mediante ecualización. 1 tal como se define en .
donde R = Rojo, G = Verde y B = Azul contribuciones de color a la nueva imagen.
La aplicación de CLAHE para la mejora de la imagen dio lugar a cambios notables en las imágenes ajustando las intensidades de la imagen, donde el oscurecimiento del núcleo, así como los límites del citoplasma, se hicieron fácilmente identificables utilizando un límite de clip de 2,0.
Segmentación de escenas
Para lograr la segmentación de escenas, se desarrolló un clasificador de nivel de píxeles utilizando el kit de herramientas de segmentación Weka (TWS) entrenable. La mayoría de las células observadas en una prueba de papanicolaou no son sorprendentemente células epiteliales cervicales . Además, el número variable de leucocitos, eritrocitos y bacterias suele ser evidente, mientras que a veces se observan pequeños números de otras células y microorganismos contaminantes. Sin embargo, el frotis de papanicolaou contiene cuatro tipos principales de células escamosas cervicales-superficiales, intermedias, parabasales y basales—de las cuales las células superficiales e intermedias representan la abrumadora mayoría en un frotis convencional; por lo tanto, estos dos tipos se usan generalmente para un análisis de frotis de papanicolaou convencional . Se utilizó una segmentación Weka entrenable para identificar y segmentar los diferentes objetos en la diapositiva. En esta etapa, se entrenó a un clasificador a nivel de píxel en núcleos celulares, citoplasma, fondo e identificación de desechos con la ayuda de un citopatólogo experto que utiliza un kit de herramientas de segmentación Weka (TWS) entrenable . Esto se logró dibujando líneas / selección a través de las áreas de interés y asignándolas a una clase en particular. Los píxeles debajo de las líneas/selección se consideraron representativos de los núcleos, el citoplasma, el fondo y los desechos.
Los contornos dibujados dentro de cada clase se usaron para generar un vector de entidad, \(\mathop F\limits^{ \to }\) que se derivó del número de píxeles pertenecientes a cada contorno. El vector de entidad de cada imagen (200 del Conjunto de datos 1 y 200 del Conjunto de datos 2) se definió mediante Ecualización. 2.
donde Ni, Ci, Bi y Di son el número de píxeles del núcleo, citoplasma, fondo y restos de la imagen \(i\) como se muestra en la Fig. 2.

Generación del vector de entidades a partir de las imágenes de entrenamiento
Cada píxel extraído de la imagen representa no solo su intensidad, sino también un conjunto de características de imagen que contienen mucha información, incluyendo textura, bordes y color dentro de un área de píxeles de 0,201 µm2. Elegir un vector de características apropiado para entrenar al clasificador fue un gran desafío y una tarea novedosa en el enfoque propuesto. El clasificador de nivel de píxel se entrenó utilizando un total de 226 funciones de capacitación de TWS. El clasificador fue entrenado usando un conjunto de características de entrenamiento TWS que incluyeron: (i) Reducción de ruido: Los filtros Kuwahara y bilaterales en el kit de herramientas TWS se utilizaron para entrenar al clasificador en la eliminación de ruido. Se ha informado que estos son excelentes filtros para eliminar el ruido y preservar los bordes, (ii) Detección de bordes: Se utilizaron un filtro Sobel , una matriz de arpillera y un filtro Gabor para entrenar al clasificador en la detección de bordes en una imagen, y (iii) Filtrado de texturas: Para el filtrado de texturas se utilizaron los filtros de media, varianza, mediana, máximo, mínimo y entropía.
Eliminación de desechos
La razón principal de las limitaciones actuales de muchos de los sistemas automatizados de análisis de frotis de papanicolaou existentes es que luchan por superar la complejidad de las estructuras de frotis de papanicolaou, tratando de analizar el portaobjetos en su conjunto, que a menudo contienen múltiples células y desechos. Esto tiene el potencial de causar el fallo del algoritmo y requiere una mayor potencia computacional . Las muestras están cubiertas de artefactos, como células sanguíneas, células superpuestas y plegadas y bacterias, que obstaculizan los procesos de segmentación y generan un gran número de objetos sospechosos. Se ha demostrado que los clasificadores diseñados para diferenciar entre células normales y células precancerosas generalmente producen resultados impredecibles cuando existen artefactos en la prueba de papanicolaou . En esta herramienta, una técnica para identificar las células del cuello uterino utilizando un esquema de eliminación secuencial de tres fases (representado en la Fig. 3) se utiliza.

Enfoque de eliminación secuencial trifásica para el rechazo de desechos
El esquema de eliminación trifásica propuesto elimina secuencialmente los desechos de la prueba de papanicolaou si se considera poco probable que sea una célula del cuello uterino. Este enfoque es beneficioso, ya que permite tomar una decisión de dimensiones inferiores en cada etapa.
Análisis de tamaño
El análisis de tamaño es un conjunto de procedimientos para determinar un rango de medidas de tamaño de partículas . El área es una de las características más básicas utilizadas en el campo de la citología automatizada para separar las células de los desechos. El análisis de papanicolaou es un campo bien estudiado con mucho conocimiento previo sobre las propiedades celulares . Sin embargo, uno de los cambios clave con la evaluación del área del núcleo es que las células cancerosas experimentan un aumento sustancial en el tamaño nuclear . Por lo tanto, determinar un umbral de tamaño superior que no excluya sistemáticamente las células de diagnóstico es mucho más difícil, pero tiene la ventaja de reducir el espacio de búsqueda. El método presentado en este trabajo se basa en un umbral de tamaño inferior y superior de las células cervicales. El pseudo código para el enfoque se muestra en la Ec. 3.
donde \(Area_{max} = 85,267\,{\upmu \text{m}}^{2}\) y \(Area_{min} = 625\,{\upmu \text{m}}^{2}\) que se derivan de la Tabla 2.
Los objetos del fondo se consideran escombros y, por lo tanto, se descartan de la imagen. Las partículas que se encuentran entre \(Area_{min}\) y \(Area_{max}\) se analizan más a fondo durante las siguientes etapas del análisis de textura y forma.
Análisis de formas
La forma de los objetos en un frotis de papanicolaou es una característica clave en la diferenciación entre células y desechos . Existen varios métodos para la detección de la descripción de formas, que incluyen enfoques basados en regiones y contornos . Los métodos basados en regiones son menos sensibles al ruido pero más intensivos computacionalmente, mientras que los métodos basados en contornos son relativamente eficientes para calcular pero más sensibles al ruido . En este trabajo, se ha utilizado un método basado en la región (perimetro 2/área (P2A)). El descriptor P2A se eligió por el mérito de describir la similitud de un objeto con un círculo. Esto lo hace muy adecuado como descriptor de núcleos celulares, ya que los núcleos son generalmente circulares en su apariencia. El P2A también se conoce como forma compacta y se define por Ec. 4.
donde c es el valor de la figura de compacidad, a es el área y p es el perímetro del núcleo. Se suponía que los desechos eran objetos con un valor de P2A superior a 0,97 o inferior a 0,15 según las características de entrenamiento (descritas en el cuadro 2).
Análisis de texturas
La textura es una característica muy importante que puede diferenciar entre núcleos y desechos. Textura de imagen es un conjunto de métricas diseñadas para cuantificar la textura percibida de una imagen . Dentro de un frotis de papanicolaou, la distribución de la intensidad media de la mancha nuclear es mucho más estrecha que la variación de la intensidad de la mancha entre los desechos . Este hecho se utilizó como base para eliminar los residuos en función de sus intensidades de imagen e información de color utilizando momentos Zernike (ZM) . Los momentos Zernike se utilizan para una variedad de aplicaciones de reconocimiento de patrones y se sabe que son robustos con respecto al ruido y tienen una buena potencia de reconstrucción. En este trabajo, el ZM presentado por Malm et al. de orden n con repetición I de función \(f\left ({r, \ theta } \ right)\), en coordenadas polares dentro de un disco centrado en una imagen cuadrada \(I\left( {x, y} \right)\) de tamaño \(m \times m\) dada por la Ec. se utilizó el 5.
\(v_{nl }^{*} \left( {r,\theta } \right)\) denota el complejo conjugado de la Zernike polinomio \(v_{nl} \left( {r,\theta } \right)\). Para producir una medida de textura, se promedian las magnitudes de \(A_{nl}\) centradas en cada píxel de la imagen de textura .
Extracción de entidades
El éxito de un algoritmo de clasificación depende en gran medida de la corrección de las entidades extraídas de la imagen. Las células de las pruebas de papanicolaou en el conjunto de datos utilizado se dividen en siete clases basadas en características como el tamaño, el área, la forma y el brillo del núcleo y el citoplasma. Las características extraídas de las imágenes incluían características morfológicas utilizadas anteriormente por otros . En este trabajo también se extrajeron del núcleo tres características geométricas (solidez, compacidad y excentricidad) y seis características textuales (media, desviación estándar, varianza, suavidad, energía y entropía), resultando en un total de 29 características, como se muestra en la Tabla 3.
Selección de entidades es el proceso de selección de subconjuntos de las entidades extraídas que dan los mejores resultados de clasificación. Entre esas características extraídas, algunas pueden contener ruido, mientras que el clasificador elegido puede no utilizar otras. Por lo tanto, se debe determinar un conjunto óptimo de características, posiblemente probando todas las combinaciones. Sin embargo, cuando hay muchas características, las posibles combinaciones explotan en número y esto aumenta la complejidad computacional del algoritmo. Los algoritmos de selección de características se clasifican ampliamente en los métodos de filtro, envoltura y embebido .
El método utilizado por la herramienta combina el recocido simulado con un enfoque de envoltura. Este enfoque se ha propuesto en pero, en este documento, el rendimiento de la selección de características se evalúa utilizando un algoritmo de bosque aleatorio de doble estrategia . El recocido simulado es una técnica probabilística para aproximar el óptimo global de una función dada. El enfoque es adecuado para garantizar que se selecciona el conjunto óptimo de características. La búsqueda del conjunto óptimo se guía por un valor de aptitud física . Cuando se termina el recocido simulado, se comparan todos los diferentes subconjuntos de características y se selecciona el más apto (es decir, el que tiene el mejor rendimiento). La búsqueda de valor de aptitud se obtuvo con un envoltorio donde se utilizó validación cruzada k-fold para calcular el error en el algoritmo de clasificación. Se preparan, evalúan y comparan diferentes combinaciones de las características extraídas con otras combinaciones. A continuación, se utiliza un modelo predictivo para evaluar una combinación de características y asignar una puntuación basada en la precisión del modelo. El error de aptitud dado por la envoltura se utiliza como error de aptitud por el algoritmo de recocido simulado. Un algoritmo de medias C difusas se envolvió en una caja negra, de la cual se obtuvo un error estimado para las diversas combinaciones de características, como se muestra en la Fig. 4.

La media C difusa se envuelve en una caja negra de la que se obtiene un error estimado
La media C difusa permite puntos de datos en el conjunto de datos para pertenecer a todos los clústeres, con membresías en el intervalo (0-1) como se muestra en la Ec. 6.
donde \(m_{ik}\) es la pertenencia del punto de datos k al centro del clúster i, \(d_{jk}\) es la distancia del centro del clúster j al punto de datos k y q € es un exponente que decide qué tan fuertes deben ser las membresías. El algoritmo de medias C difusas se implementó utilizando fuzzy toolbox en Matlab.
La defuzzificación
Un algoritmo de medias C difusas no nos dice qué información contienen los clústeres y cómo se utilizará esa información para la clasificación. Sin embargo, define cómo se asigna la pertenencia a los puntos de datos de los diferentes clústeres y esta pertenencia difusa se usa para predecir la clase de un punto de datos . Esto se supera a través de la defuzzificación. Existen varios métodos de defuzzificación . Sin embargo, en esta herramienta, cada clúster tiene una pertenencia difusa (0-1) de todas las clases de la imagen. Los datos de entrenamiento se asignan al clúster más cercano. El porcentaje de datos de entrenamiento de cada clase que pertenece al clúster A da la pertenencia al clúster, clúster A = a las diferentes clases, donde i es la contención en el clúster A y j en el otro clúster. La medida de intensidad se agrega a la función de pertenencia para cada clúster mediante un algoritmo de defuzzificación de agrupamiento difuso. Un enfoque popular para la defuzzificación de particiones difusas es la aplicación del principio de grado de pertenencia máximo donde el punto de datos k se asigna a la clase m si, y solo si, su grado de pertenencia \(m_{ik}\) al clúster i, es el mayor. Chuang et al. propuso ajustar el estado de membresía de cada punto de datos utilizando el estado de membresía de sus vecinos.
En el enfoque propuesto, se utiliza un método de defuzzificación basado en la probabilidad bayesiana para generar un modelo probabilístico de la función de pertenencia para cada punto de datos y aplicar el modelo a la imagen para producir la información de clasificación. El modelo probabilístico se calcula de la siguiente manera:
-
Convertir las distribuciones de posibilidades en la matriz de particiones (clústeres) en distribuciones de probabilidad.
-
Construir un modelo probabilístico de las distribuciones de datos como en .
-
Aplique el modelo para producir la información de clasificación para cada punto de datos utilizando la Ec. 7.
donde \(P\left( {A_{i} } \derecho),i = 0 \ldots .c\) es la probabilidad previa de \(A_{i}\) que se puede calcular utilizando el método en el que la probabilidad previa es siempre proporcional a la masa de cada clase.
Se determinó el número de clústeres a utilizar para garantizar que el modelo construido pueda describir los datos de la mejor manera posible. Si se eligen demasiados clústeres, existe el riesgo de sobreajustar el ruido en los datos. Si se eligen muy pocos clústeres, el resultado podría ser un clasificador pobre. Por lo tanto, se realizó un análisis del número de clústeres contra el error de la prueba de validación cruzada. Se alcanzó un número óptimo de 25 grupos y se produjo un sobreentrenamiento por encima de este número de grupos. Un exponente de defuzzificación de 1.0930 se obtuvo con 25 clústeres, diez veces la validación cruzada y 60 repeticiones y se utilizó para calcular el error de aptitud para la selección de características, donde se seleccionaron un total de 18 características de las 29 características para la construcción del clasificador. Las características seleccionadas fueron: área del núcleo; nivel de gris del núcleo; diámetro más corto del núcleo; núcleo más largo; perímetro del núcleo; máximos en el núcleo; mínimos en el núcleo; área del citoplasma; nivel de gris del citoplasma; perímetro del citoplasma; relación núcleo a citoplasma; excentricidad del núcleo, desviación estándar del núcleo, varianza del nivel de gris del núcleo; entropía del nivel de gris del núcleo; posición relativa del núcleo; media del nivel de gris del núcleo y valores de energía del núcleo gris.
Evaluación de clasificación
En este trabajo, el modelo jerárquico de la eficacia de los sistemas de diagnóstico por imagen propuesto por Fryback y Thornbury fue adoptado como principio rector para la evaluación de la herramienta, como se muestra en la Tabla 4.
La sensibilidad mide la proporción de positivos reales que se identifican correctamente como tales, mientras que la especificidad mide la proporción de negativos reales que se identifican correctamente como tales. La sensibilidad y la especificidad se describen mediante la Ec. 8.
donde TP = Verdaderos positivos, FN = Falsos negativos, TN = Verdaderos negativos y FP = Falsos positivos.
Diseño e integración de GUI
Los métodos de procesamiento de imágenes descritos anteriormente se implementaron en Matlab y se ejecutan a través de una interfaz gráfica de usuario (GUI) Java que se muestra en la Fig. 5. La herramienta tiene un panel donde se carga una imagen de frotis de papanicolaou y el citotécnico selecciona un método apropiado para la segmentación de la escena (basado en el clasificador TWS), la eliminación de escombros (basado en el enfoque de eliminación secuencial de tres) y la detección de límites (si se considera necesario, utilizando el método de detección de bordes Canny), después de lo cual las características se extraen utilizando el botón extraer características.
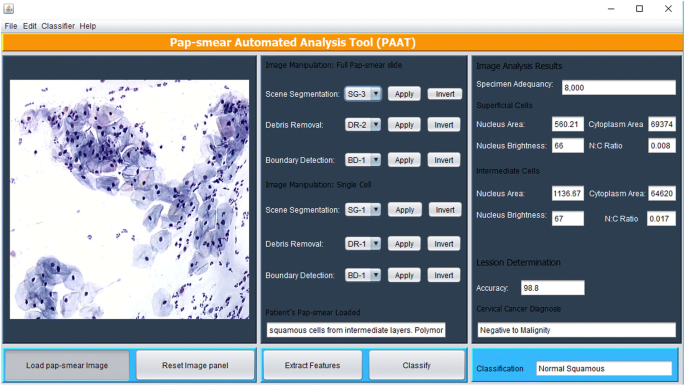
Interfaz gráfica de usuario PAT
La herramienta escanea a través de la prueba de papanicolaou para analizar todos los objetos que quedaron después de la eliminación de escombros. Las 18 características descritas en selección de características se extraen de cada objeto y se utilizan para clasificar cada celda utilizando el algoritmo de medias C difusas descrito en el método de clasificación. Las características extraídas aleatoriamente de una celda superficial y una celda intermedia se muestran en el panel de resultados del análisis de imágenes. Una vez que se han extraído las características, el citotécnico (usuario) presiona el botón clasificar y la herramienta emite un diagnóstico (positivo a malignidad o negativo a malignidad) y clasifica el diagnóstico en una de las 7 clases/etapas del cáncer de cuello uterino según el conjunto de datos de capacitación.