Comment faire de la segmentation sémantique à l’aide de l’apprentissage profond
Cet article est un aperçu complet, y compris un guide étape par étape pour implémenter un modèle de segmentation d’image en apprentissage profond.
Nous avons partagé ici un nouveau blog mis à jour sur la segmentation sémantique: Un guide 2021 de la segmentation sémantique
De nos jours, la segmentation sémantique est l’un des problèmes clés dans le domaine de la vision par ordinateur. En regardant la vue d’ensemble, la segmentation sémantique est l’une des tâches de haut niveau qui ouvre la voie à une compréhension complète de la scène. L’importance de la compréhension des scènes en tant que problème central de la vision par ordinateur est mise en évidence par le fait qu’un nombre croissant d’applications se nourrissent de l’inférence de connaissances à partir d’images. Certaines de ces applications incluent les véhicules autonomes, l’interaction homme-ordinateur, la réalité virtuelle, etc. Avec la popularité du deep learning ces dernières années, de nombreux problèmes de segmentation sémantique sont abordés à l’aide d’architectures profondes, le plus souvent des réseaux neuronaux convolutifs, qui surpassent largement les autres approches en termes de précision et d’efficacité.
- Qu’est-ce que la segmentation sémantique ?
- Quelles sont les approches de segmentation sémantique existantes ?
- 1 — Segmentation sémantique basée sur les régions
- 2 — Segmentation Sémantique basée sur un Réseau Entièrement convolutif
- 3 — Segmentation sémantique faiblement supervisée
- Faire de la segmentation sémantique avec un Réseau Entièrement convolutif
- Étape 1
- Étape 2
- Étape 3
- Étape 4
- Étape 5
- Vous pourriez être intéressé par nos derniers articles sur:
Qu’est-ce que la segmentation sémantique ?
La segmentation sémantique est une étape naturelle de la progression de l’inférence grossière à l’inférence fine : L’origine pourrait se situer à la classification, qui consiste à faire une prédiction pour une entrée entière.L’étape suivante est la localisation / détection, qui fournit non seulement les classes, mais également des informations supplémentaires concernant l’emplacement spatial de ces classes.Enfin, la segmentation sémantique permet une inférence fine en faisant des prédictions denses en déduisant des étiquettes pour chaque pixel, de sorte que chaque pixel est étiqueté avec la classe de sa région de minerai d’objet englobant.
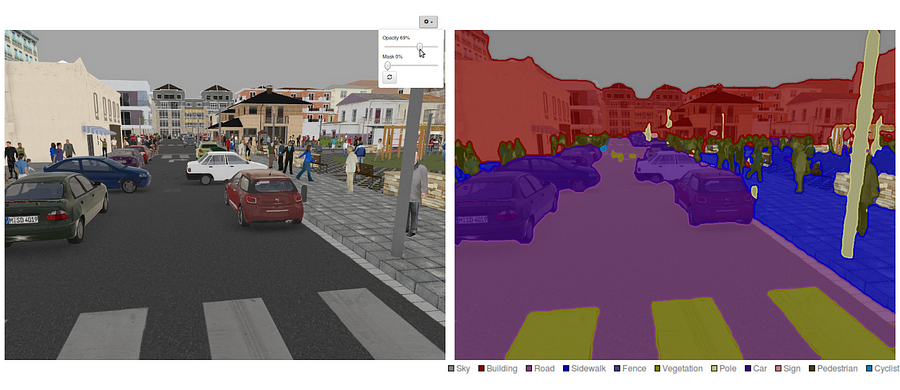
Il convient également de passer en revue certains réseaux profonds standard qui ont apporté une contribution significative au domaine de la vision par ordinateur, car ils sont souvent utilisés comme base de systèmes de segmentation sémantique:
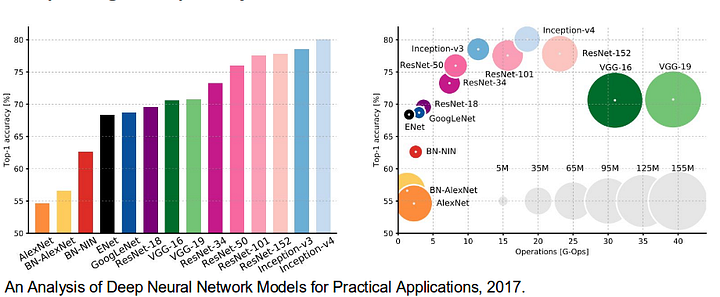
- AlexNet: le CNN profond pionnier de Toronto qui a remporté le concours ImageNet 2012 avec une précision de test de 84,6%. Il se compose de 5 couches convolutives, de couches de mise en commun maximale, de ReLUs en tant que non-linéarités, de 3 couches entièrement convolutives et d’abandon.
- VGG-16: Ce modèle d’Oxford a remporté le concours ImageNet 2013 avec une précision de 92,7%. Il utilise une pile de couches de convolution avec de petits champs réceptifs dans les premières couches au lieu de quelques couches avec de grands champs réceptifs.
- GoogLeNet: Ce réseau de Google a remporté le concours ImageNet 2014 avec une précision de 93,3%. Il est composé de 22 couches et d’un bloc de construction nouvellement introduit appelé module inception. Le module se compose d’une couche réseau-dans-réseau, d’une opération de mise en commun, d’une couche de convolution de grande taille et d’une couche de convolution de petite taille.
- ResNet: Ce modèle de Microsoft a remporté le concours ImageNet 2016 avec une précision de 96,4%. Il est bien connu en raison de sa profondeur (152 couches) et de l’introduction de blocs résiduels. Les blocs résiduels résolvent le problème de la formation d’une architecture vraiment profonde en introduisant des connexions de saut d’identité afin que les couches puissent copier leurs entrées dans la couche suivante.
Quelles sont les approches de segmentation sémantique existantes ?
Une architecture de segmentation sémantique générale peut être globalement considérée comme un réseau de codeurs suivi d’un réseau de décodeurs :
- Le codeur est généralement un réseau de classification pré-formé comme VGG/ResNet suivi d’un réseau de décodeurs.
- La tâche du décodeur est de projeter sémantiquement les caractéristiques discriminantes (résolution inférieure) apprises par le codeur sur l’espace des pixels (résolution supérieure) pour obtenir une classification dense.
Contrairement à la classification où le résultat final du réseau très profond est la seule chose importante, la segmentation sémantique nécessite non seulement une discrimination au niveau des pixels, mais également un mécanisme permettant de projeter les caractéristiques discriminantes apprises à différentes étapes du codeur sur l’espace des pixels. Différentes approches utilisent différents mécanismes dans le cadre du mécanisme de décodage. Explorons les 3 approches principales:
1 — Segmentation sémantique basée sur les régions
Les méthodes basées sur les régions suivent généralement le pipeline « segmentation à l’aide de la reconnaissance », qui extrait d’abord les régions de forme libre d’une image et les décrit, puis la classification basée sur les régions. Au moment du test, les prédictions basées sur la région sont transformées en prédictions de pixels, généralement en étiquetant un pixel en fonction de la région de notation la plus élevée qui le contient.
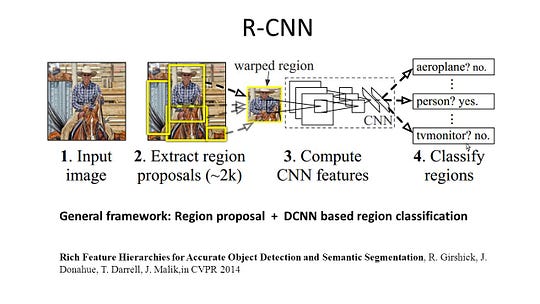
R-CNN (Régions avec fonction CNN) est un travail représentatif pour les méthodes basées sur les régions. Il effectue la segmentation sémantique en fonction des résultats de détection d’objets. Pour être précis, R-CNN utilise d’abord la recherche sélective pour extraire une grande quantité de propositions d’objets, puis calcule les fonctionnalités CNN pour chacune d’elles. Enfin, il classe chaque région en utilisant les SVM linéaires spécifiques à la classe. Comparé aux structures CNN traditionnelles qui sont principalement destinées à la classification des images, R-CNN peut traiter des tâches plus compliquées, telles que la détection d’objets et la segmentation d’images, et il devient même une base importante pour les deux champs. De plus, R-CNN peut être construit au-dessus de toutes les structures de référence CNN, telles que AlexNet, VGG, GoogLeNet et ResNet.
Pour la tâche de segmentation d’image, R-CNN a extrait 2 types de fonctionnalités pour chaque région : la fonctionnalité de région complète et la fonctionnalité de premier plan, et a constaté que cela pouvait améliorer les performances lors de leur concaténation en tant que fonctionnalité de région. R-CNN a obtenu des améliorations significatives des performances grâce à l’utilisation des fonctionnalités CNN hautement discriminantes. Cependant, elle présente également quelques inconvénients pour la tâche de segmentation :
- La fonctionnalité n’est pas compatible avec la tâche de segmentation.
- La fonction ne contient pas suffisamment d’informations spatiales pour générer des limites précises.
- La génération de propositions basées sur des segments prend du temps et affecterait grandement les performances finales.
En raison de ces goulots d’étranglement, des recherches récentes ont été proposées pour résoudre les problèmes, y compris les FDS, les Hypercolumnes, le masque R-CNN.
2 — Segmentation Sémantique basée sur un Réseau Entièrement convolutif
Le Réseau entièrement convolutif d’origine (FCN) apprend un mappage de pixels en pixels, sans extraire les propositions de région. Le pipeline du réseau FCN est une extension du CNN classique. L’idée principale est de faire en sorte que le CNN classique prenne en entrée des images de taille arbitraire. La restriction des CNN d’accepter et de produire des étiquettes uniquement pour des entrées de taille spécifique provient des couches entièrement connectées qui sont fixes. Contrairement à eux, les FCN n’ont que des couches convolutives et de mise en commun qui leur donnent la possibilité de faire des prédictions sur des entrées de taille arbitraire.
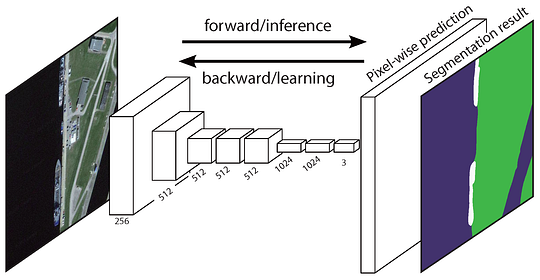
Un problème dans ce FCN spécifique est qu’en se propageant à travers plusieurs couches convolutives et de mise en commun alternées, la résolution des cartes d’entités de sortie sont échantillonnées en baisse. Par conséquent, les prédictions directes de FCN sont généralement de faible résolution, ce qui entraîne des limites d’objets relativement floues. Diverses approches plus avancées basées sur le FCN ont été proposées pour résoudre ce problème, notamment SegNet, DeepLab-CRF et Convolutions dilatées.
3 — Segmentation sémantique faiblement supervisée
La plupart des méthodes pertinentes de segmentation sémantique reposent sur un grand nombre d’images avec des masques de segmentation en pixels. Cependant, annoter manuellement ces masques prend beaucoup de temps, est frustrant et coûte cher sur le plan commercial. Par conséquent, certaines méthodes faiblement supervisées ont récemment été proposées, qui sont dédiées à la réalisation de la segmentation sémantique en utilisant des boîtes de délimitation annotées.

Par exemple, Boxsup a utilisé les annotations de la boîte englobante comme supervision pour entraîner le réseau et améliorer de manière itérative les masques estimés pour la segmentation sémantique. Simple A-t-il traité la faible limitation de la supervision comme un problème de bruit d’étiquette d’entrée et exploré la formation récursive comme stratégie de réduction du bruit. L’étiquetage au niveau des pixels a interprété la tâche de segmentation dans le cadre d’apprentissage à plusieurs instances et a ajouté une couche supplémentaire pour contraindre le modèle à attribuer plus de poids aux pixels importants pour la classification au niveau de l’image.
Faire de la segmentation sémantique avec un Réseau Entièrement convolutif
Dans cette section, passons en revue une implémentation étape par étape de l’architecture la plus populaire pour la segmentation sémantique – le Réseau Entièrement convolutif (FCN). Nous allons l’implémenter en utilisant la bibliothèque TensorFlow en Python 3, avec d’autres dépendances telles que Numpy et Scipy.In cet exercice nous allons étiqueter les pixels d’une route dans des images en utilisant FCN. Nous travaillerons avec le jeu de données Kitti Road pour la détection de route/voie. Il s’agit d’un exercice simple du programme de Nano-degré de voiture autonome d’Udacity, dont vous pouvez en savoir plus sur la configuration dans ce dépôt GitHub.

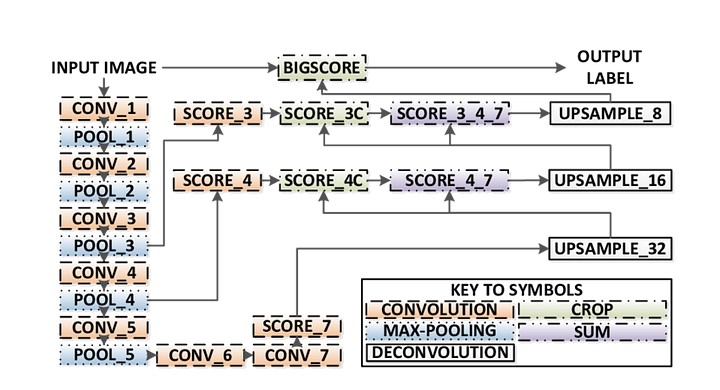
Voici les principales caractéristiques de l’architecture FCN :
- FCN transfère les connaissances de VGG16 pour effectuer une segmentation sémantique.
- Les couches entièrement connectées de VGG16 sont converties en couches entièrement convolutives, en utilisant la convolution 1×1. Ce processus produit une carte thermique de présence de classe en basse résolution.
- Le suréchantillonnage de ces cartes d’entités sémantiques à basse résolution se fait à l’aide de circonvolutions transposées (initialisées avec des filtres d’interpolation bilinéaires).
- À chaque étape, le processus de suréchantillonnage est affiné en ajoutant des entités à partir de cartes d’entités plus grossières mais de résolution plus élevée provenant de couches inférieures dans VGG16.
- La connexion Skip est introduite après chaque bloc de convolution pour permettre au bloc suivant d’extraire des fonctionnalités plus abstraites et plus saillantes des fonctionnalités précédemment regroupées.
Il existe 3 versions de FCN (FCN-32, FCN-16, FCN-8). Nous allons implémenter FCN-8, comme détaillé étape par étape ci-dessous:
- Encodeur: Un VGG16 pré-formé est utilisé comme encodeur. Le décodeur démarre à partir de la couche 7 de VGG16.
- Couche FCN-8 : La dernière couche entièrement connectée de VGG16 est remplacée par une convolution 1×1.
- Couche FCN-9: La couche FCN-8 est suréchantillonnée 2 fois pour correspondre aux dimensions de la couche 4 de VGG 16, en utilisant une convolution transposée avec des paramètres : (kernel=(4,4), stride=(2,2), paddding= ‘same’). Après cela, une connexion de saut a été ajoutée entre la couche 4 de VGG16 et la couche FCN-9.
- Couche FCN-10: La couche FCN-9 est suréchantillonnée 2 fois pour correspondre aux dimensions de la couche 3 de VGG16, en utilisant une convolution transposée avec des paramètres : (kernel=(4,4), stride=(2,2), paddding= ‘same’). Après cela, une connexion de saut a été ajoutée entre la couche 3 de VGG 16 et la couche FCN-10.
- Couche FCN-11: La couche FCN-10 est suréchantillonnée 4 fois pour faire correspondre les dimensions avec la taille de l’image d’entrée afin que nous récupérions l’image réelle et que la profondeur soit égale au nombre de classes, en utilisant une convolution transposée avec des paramètres: (kernel =(16,16), stride =(8,8), paddding = ‘same’).
Étape 1
Nous chargeons d’abord le modèle VGG-16 pré-entraîné dans TensorFlow. En prenant la session TensorFlow et le chemin d’accès au dossier VGG (téléchargeable ici), nous renvoyons le tuple de tenseurs du modèle VGG, y compris l’entrée d’image, keep_prob (pour contrôler le taux d’abandon), la couche 3, la couche 4 et la couche 7.
def load_vgg(sess, vgg_path): # load the model and weights model = tf.saved_model.loader.load(sess, , vgg_path) # Get Tensors to be returned from graph graph = tf.get_default_graph() image_input = graph.get_tensor_by_name('image_input:0') keep_prob = graph.get_tensor_by_name('keep_prob:0') layer3 = graph.get_tensor_by_name('layer3_out:0') layer4 = graph.get_tensor_by_name('layer4_out:0') layer7 = graph.get_tensor_by_name('layer7_out:0') return image_input, keep_prob, layer3, layer4, layer7Fonction VGG16
Étape 2
Maintenant, nous nous concentrons sur la création des couches pour un FCN, en utilisant les tenseurs du modèle VGG. Étant donné les tenseurs pour la sortie de la couche VGG et le nombre de classes à classer, nous renvoyons le tenseur pour la dernière couche de cette sortie. En particulier, nous appliquons une convolution 1×1 aux couches d’encodeur, puis ajoutons des couches de décodeur au réseau avec des connexions de saut et un suréchantillonnage.
def layers(vgg_layer3_out, vgg_layer4_out, vgg_layer7_out, num_classes): # Use a shorter variable name for simplicity layer3, layer4, layer7 = vgg_layer3_out, vgg_layer4_out, vgg_layer7_out # Apply 1x1 convolution in place of fully connected layer fcn8 = tf.layers.conv2d(layer7, filters=num_classes, kernel_size=1, name="fcn8") # Upsample fcn8 with size depth=(4096?) to match size of layer 4 so that we can add skip connection with 4th layer fcn9 = tf.layers.conv2d_transpose(fcn8, filters=layer4.get_shape().as_list(), kernel_size=4, strides=(2, 2), padding='SAME', name="fcn9") # Add a skip connection between current final layer fcn8 and 4th layer fcn9_skip_connected = tf.add(fcn9, layer4, name="fcn9_plus_vgg_layer4") # Upsample again fcn10 = tf.layers.conv2d_transpose(fcn9_skip_connected, filters=layer3.get_shape().as_list(), kernel_size=4, strides=(2, 2), padding='SAME', name="fcn10_conv2d") # Add skip connection fcn10_skip_connected = tf.add(fcn10, layer3, name="fcn10_plus_vgg_layer3") # Upsample again fcn11 = tf.layers.conv2d_transpose(fcn10_skip_connected, filters=num_classes, kernel_size=16, strides=(8, 8), padding='SAME', name="fcn11") return fcn11Fonction des couches
Étape 3
L’étape suivante consiste à optimiser notre réseau de neurones, c’est-à-dire à créer des fonctions de perte de flux tensor et des opérations d’optimiseur. Ici, nous utilisons l’entropie croisée comme fonction de perte et Adam comme algorithme d’optimisation.
def optimize(nn_last_layer, correct_label, learning_rate, num_classes): # Reshape 4D tensors to 2D, each row represents a pixel, each column a class logits = tf.reshape(nn_last_layer, (-1, num_classes), name="fcn_logits") correct_label_reshaped = tf.reshape(correct_label, (-1, num_classes)) # Calculate distance from actual labels using cross entropy cross_entropy = tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=correct_label_reshaped) # Take mean for total loss loss_op = tf.reduce_mean(cross_entropy, name="fcn_loss") # The model implements this operation to find the weights/parameters that would yield correct pixel labels train_op = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(loss_op, name="fcn_train_op") return logits, train_op, loss_opFonction d’optimisation
Étape 4
Ici, nous définissons la fonction train_nn, qui prend des paramètres importants, notamment le nombre d’époques, la taille du lot, la fonction de perte, le fonctionnement de l’optimiseur et les espaces réservés pour les images d’entrée, les images d’étiquettes, le taux d’apprentissage. Pour le processus de formation, nous avons également défini keep_probability à 0,5 et learning_rate à 0,001. Pour suivre les progrès, nous imprimons également la perte pendant l’entraînement.
def train_nn(sess, epochs, batch_size, get_batches_fn, train_op, cross_entropy_loss, input_image, correct_label, keep_prob, learning_rate): keep_prob_value = 0.5 learning_rate_value = 0.001 for epoch in range(epochs): # Create function to get batches total_loss = 0 for X_batch, gt_batch in get_batches_fn(batch_size): loss, _ = sess.run(, feed_dict={input_image: X_batch, correct_label: gt_batch, keep_prob: keep_prob_value, learning_rate:learning_rate_value}) total_loss += loss; print("EPOCH {} ...".format(epoch + 1)) print("Loss = {:.3f}".format(total_loss)) print()Étape 5
Enfin, il est temps de former notre filet! Dans cette fonction d’exécution, nous construisons d’abord notre réseau à l’aide de la fonction load_vgg, layers et optimize. Ensuite, nous entraînons le réseau à l’aide de la fonction train_nn et enregistrons les données d’inférence pour les enregistrements.
def run(): # Download pretrained vgg model helper.maybe_download_pretrained_vgg(data_dir) # A function to get batches get_batches_fn = helper.gen_batch_function(training_dir, image_shape) with tf.Session() as session: # Returns the three layers, keep probability and input layer from the vgg architecture image_input, keep_prob, layer3, layer4, layer7 = load_vgg(session, vgg_path) # The resulting network architecture from adding a decoder on top of the given vgg model model_output = layers(layer3, layer4, layer7, num_classes) # Returns the output logits, training operation and cost operation to be used # - logits: each row represents a pixel, each column a class # - train_op: function used to get the right parameters to the model to correctly label the pixels # - cross_entropy_loss: function outputting the cost which we are minimizing, lower cost should yield higher accuracy logits, train_op, cross_entropy_loss = optimize(model_output, correct_label, learning_rate, num_classes) # Initialize all variables session.run(tf.global_variables_initializer()) session.run(tf.local_variables_initializer()) print("Model build successful, starting training") # Train the neural network train_nn(session, EPOCHS, BATCH_SIZE, get_batches_fn, train_op, cross_entropy_loss, image_input, correct_label, keep_prob, learning_rate) # Run the model with the test images and save each painted output image (roads painted green) helper.save_inference_samples(runs_dir, data_dir, session, image_shape, logits, keep_prob, image_input)Fonction d’exécution
À propos de nos paramètres, nous choisissons epochs=40, batch_size=16, num_classes=2 et image_shape=(160, 576). Après avoir fait 2 passes d’essai avec abandon = 0,5 et abandon = 0,75, nous avons constaté que le 2ème essai donne de meilleurs résultats avec de meilleures pertes moyennes.

Pour voir le code complet, consultez ce lien: https://gist.github.com/khanhnamle1994/e2ff59ddca93c0205ac4e566d40b5e88
Si vous avez aimé cette pièce, j’adorerais la partager 👏 et diffuser les connaissances.
Vous pourriez être intéressé par nos derniers articles sur:
- AWS Textract
- Extraction de données
Commencez à utiliser des Nanonets pour l’automatisation
Essayez le modèle ou demandez une démo aujourd’hui!
ESSAYEZ MAINTENANT
