Se familiariser avec l’Apprentissage par renforcement via le Processus de Décision de Markov
Cet article a été publié dans le cadre du Blogathon de la Science des données.
Introduction
L’apprentissage par renforcement (RL) est une méthodologie d’apprentissage par laquelle l’apprenant apprend à se comporter dans un environnement interactif en utilisant ses propres actions et en récompensant ses actions. L’apprenant, souvent appelé agent, découvre quelles actions donnent le maximum de récompenses en les exploitant et en les explorant.

Une question clé est – en quoi le RL est-il différent de l’apprentissage supervisé et non supervisé?
La différence vient de la perspective de l’interaction. L’apprentissage supervisé indique directement à l’utilisateur / agent quelle action il doit effectuer pour maximiser la récompense à l’aide d’un ensemble de données d’entraînement d’exemples étiquetés. D’autre part, RL permet directement à l’agent d’utiliser les récompenses (positives et négatives) qu’il obtient pour sélectionner son action. Il est donc également différent de l’apprentissage non supervisé car l’apprentissage non supervisé consiste à trouver une structure cachée dans des collections de données non étiquetées.
Formulation de l’apprentissage par renforcement via le Processus de décision de Markov (MDP)
Les éléments de base d’un problème d’apprentissage par renforcement sont:
- Environnement: Le monde extérieur avec lequel l’agent interagit
- État: Situation actuelle de l’agent
- Récompense: Signal de rétroaction numérique de l’environnement
- Politique: Méthode pour mapper l’état de l’agent aux actions. Une stratégie est utilisée pour sélectionner une action à un état donné
- Valeur: Récompense future (récompense différée) qu’un agent recevrait en prenant une action dans un état donné
Le processus de décision de Markov (MDP) est un cadre mathématique pour décrire un environnement d’apprentissage par renforcement. La figure suivante montre l’interaction agent-environnement dans MDP:
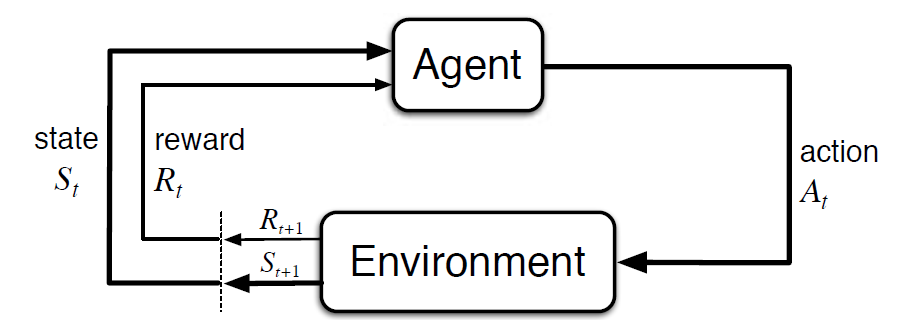
Plus précisément, l’agent et l’environnement interagissent à chaque pas de temps discret, t = 0, 1, 2, 3…At à chaque pas de temps, l’agent obtient des informations sur l’état d’environnement St. Sur la base de l’état d’environnement à l’instant t, l’agent choisit une action At. L’instant suivant, l’agent reçoit également un signal de récompense numérique Rt+1. Cela donne donc lieu à une séquence comme S0, A0, R1, S1, A1, R2…
Les variables aléatoires Rt et St ont des distributions de probabilité discrètes bien définies. Ces distributions de probabilité ne dépendent que de l’état et de l’action précédents en vertu de la propriété de Markov. Soit S, A et R les ensembles d’états, d’actions et de récompenses. Ensuite, la probabilité que les valeurs de St, Rt et At prennent les valeurs s ‘, r et a avec l’état précédent s est donnée par,
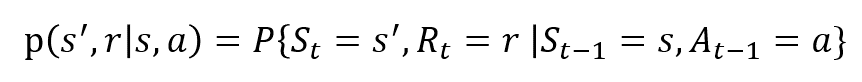
La fonction p contrôle la dynamique du processus .
Comprenons cela En utilisant un Exemple
Discutons maintenant d’un exemple simple où RL peut être utilisé pour implémenter une stratégie de contrôle pour un processus de chauffage.
L’idée est de contrôler la température d’une pièce dans les limites de température spécifiées. La température à l’intérieur de la pièce est influencée par des facteurs externes tels que la température extérieure, la chaleur interne générée, etc.
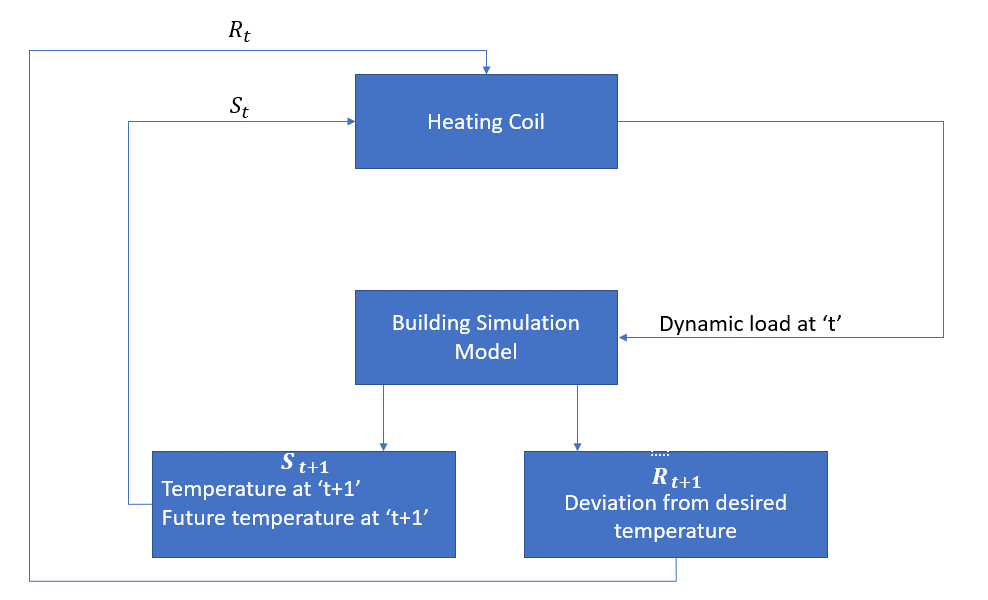
L’agent, dans ce cas, est le serpentin de chauffage qui doit décider de la quantité de chaleur nécessaire pour contrôler la température à l’intérieur de la pièce en interagissant avec l’environnement et s’assurer que la température à l’intérieur de la pièce se situe dans la plage spécifiée. La récompense, dans ce cas, est essentiellement le coût payé pour s’écarter des limites de température optimales.
L’action de l’agent est la charge dynamique. Cette charge dynamique est ensuite envoyée au simulateur de pièce qui est essentiellement un modèle de transfert de chaleur qui calcule la température en fonction de la charge dynamique. Donc, dans ce cas, l’environnement est le modèle de simulation. La variable d’état St contient les récompenses présentes et futures.
Le schéma fonctionnel suivant explique comment le MDP peut être utilisé pour contrôler la température à l’intérieur d’une pièce :
Limites de cette méthode
Apprentissage par renforcement apprend de l’État. L’État est la contribution à l’élaboration des politiques. Par conséquent, les entrées d’état doivent être correctement données. De plus, comme nous l’avons vu, il y a plusieurs variables et la dimensionnalité est énorme. Il serait donc difficile de l’utiliser pour de vrais systèmes physiques!
Lectures supplémentaires
Pour en savoir plus sur le RL, les matériaux suivants pourraient être utiles:
- Apprentissage par renforcement: Une introduction par Richard.S.Sutton et Andrew.G.Barto: http://incompleteideas.net/book/the-book-2nd.html
- Conférences vidéo de David Silver disponibles sur YouTube
- https://gym.openai.com/est une boîte à outils pour une exploration plus approfondie
Vous pouvez également lire cet article sur notre APPLICATION mobile ![]()
