seaborn.histplot¶
seaborn.histplot(data=None, *, x=None, y=None, hue=None, weights=None, stat=’count’, bins=’auto’, binwidth=None, binrange=None, discrete=None, cumulative=False, common_bins=True, common_norm=True, multiple=’ calque’, element=’barres’, fill= True, shrink=1, kde=False, kde_kws=None, line_kws=None, thresh=0, pthresh=None, pmax= None, cbar_ax= None, cbar_kws=None, palette=None, hue_order=None, hue_norm=None, color=None, log_scale= None, legend= True, ax=None, **kwargs)¶
Tracé histogrammes univariés ou bivariés pour montrer les distributions de jeux de données.
Un histogramme est un outil de visualisation classique qui représente la distribution d’une ou de plusieurs variables en comptant le nombre d’observations qui tombent dans des bins distincts.
Cette fonction peut normaliser la statistique calculée dans chaque bac pour estimer la fréquence, la densité ou la masse de probabilité, et elle peut ajouter une courbe lisse obtenue en utilisant une estimation de la densité du noyau, similaire à kdeplot().
Plus d’informations sont fournies dans le guide de l’utilisateur.
Données de paramètrespandas.DataFramenumpy.ndarray, mappage ou séquence
Structure de données d’entrée. Soit une collection de vecteurs de forme longue pouvant être assignée à des variables nommées, soit un ensemble de données de forme large qui sera mis en forme en interne.
x, yvectors ou clés dansdata
Variables qui spécifient des positions sur les axes x et y.
huevector ou clé dansdata
Variable sémantique mappée pour déterminer la couleur des éléments de tracé.
weightsvector ou clé dansdata
Si elle est fournie, pondérez la contribution des points de données correspondants en fonction de ces facteurs.
stat {« count », »frequency », « density », « probability »}
Agréger la statistique à calculer dans chaque bac.
-
countmontre le nombre d’observations -
frequencymontre le nombre d’observations divisé par la largeur du bac -
densitynormalise compte de telle sorte que l’aire de l’histogramme soit 1 -
probabilitynormalise le compte de telle sorte que la somme des hauteurs de barre soit 1
binsstr, nombre, vecteur ou une paire de telles valeurs
Paramètre bin générique qui peut être le nom d’une règle de référence, le nombre de bacs ou les ruptures des bacs.Passé à numpy.histogram_bin_edges().
binwidthnumber ou paire de nombres
Largeur de chaque bin, remplace bins mais peut être utilisé avec binrange.
binrangepair de nombres ou une paire de paires
Valeur la plus basse et la plus élevée pour les bords du bac; peut être utilisé soit avec bins ou binwidth. Par défaut, les extrêmes de données.
discretebool
Si True, la valeur par défaut est binwidth=1 et dessine les barres de sorte qu’elles soient centrées sur leurs points de données correspondants. Cela évite les « lacunes » qui peuvent également apparaître lors de l’utilisation de données discrètes (entières).
cumulativebool
Si la valeur est True, tracez le nombre cumulé au fur et à mesure que les bacs augmentent.
common_binsbool
Si True, utilisez les mêmes bacs lorsque les variables sémantiques produisent des multiplots. Si vous utilisez une règle de référence pour déterminer les bins, elle sera computéeavec l’ensemble de données complet.
common_normbool
Si True et en utilisant une statistique normalisée, la normalisation s’appliquera sur l’ensemble de données complet. Sinon, normalisez chaque histogramme indépendamment.
multiple {« layer », « dodge », « stack », « fill »}
Approche pour résoudre plusieurs éléments lorsque le mappage sémantique crée des sous-ensembles.Uniquement pertinent avec des données univariées.
element {« bars », « step », « poly »}
Représentation visuelle de la statistique de l’histogramme.Uniquement pertinent avec des données univariées.
fillbool
Si True, remplissez l’espace sous l’histogramme.Uniquement pertinent avec des données univariées.
shrinknumber
Redimensionne la largeur de chaque barre par rapport à la largeur du bac par ce facteur.Uniquement pertinent avec des données univariées.
kdebool
Si True, calculez une estimation de la densité du noyau pour lisser la distribution et afficher sur le graphique une (ou plusieurs) ligne(s).Uniquement pertinent avec des données univariées.
kde_kwsdict
Paramètres qui contrôlent le calcul de KDE, comme dans kdeplot().
line_kwsdict
Paramètres qui contrôlent la visualisation KDE, transmis à matplotlib.axes.Axes.plot().
nombre de battage ou Aucun
Les cellules avec une statistique inférieure ou égale à cette valeur seront transparentes.Uniquement pertinent avec des données bivariées.
pthreshnumber ou None
Comme thresh, mais une valeur telle que les cellules avec des nombres agrégés (ou d’autres statistiques, lorsqu’elles sont utilisées) jusqu’à cette proportion du total seront transparentes.
pmaxnumber or None
Une valeur qui définit ce point de saturation de la palette de couleurs à une valeur telle que les cellules ci-dessous constituent cette proportion du nombre total (ou une autre statistique, lorsqu’elle est utilisée).
cbarbool
Si True, ajoutez une barre de couleurs pour annoter le mappage de couleurs dans un tracé bivarié.Remarque : Ne prend actuellement pas en charge les tracés avec un puits de variable hue.
cbar_axmatplotlib.axes.Axes
Axes préexistants pour la barre de couleurs.
cbar_kwsdict
Paramètres supplémentaires transmis à matplotlib.figure.Figure.colorbar().
palettestring, list, dict oumatplotlib.colors.Colormap
Méthode pour choisir les couleurs à utiliser lors du mappage de la sémantique hue.Les valeurs de chaîne sont transmises à color_palette(). Les valeurs List ou dict sont simplement un mappage catégoriel, tandis qu’un objet colormap implique un mappage numérique.
hue_ordervector of strings
Spécifiez l’ordre de traitement et de traçage des niveaux catégoriels de la sémantique hue.
hue_normtuple oumatplotlib.colors.Normalize
Soit une paire de valeurs qui définissent la plage de normalisation dans les unités de donnéesou un objet qui mappera des unités de données dans un intervalle. L’Utilisationimplique la cartographie numérique.
couleurmatplotlib color
Spécification de couleur unique lorsque le mappage de teinte n’est pas utilisé. Sinon, theplot essaiera de se connecter au cycle de propriétés matplotlib.
log_scalebool ou nombre, ou paire de bools ou nombres
Définissez une échelle de journal sur l’axe de données (ou les axes, avec des données bivariées) avec la base donnée (par défaut 10), et évaluez le KDE dans l’espace journal.
legendbool
Si False, supprimez la légende des variables sémantiques.
axmatplotlib.axes.Axes
Axes préexistants pour le tracé. Sinon, appelez matplotlib.pyplot.gca() en interne.
kwargs
D’autres arguments de mots clés sont passés à l’une des fonctions matplotlib suivantes:
-
matplotlib.axes.Axes.bar()(univariate, element= »bars ») -
matplotlib.axes.Axes.fill_between()(univariate, other element, fill=True) -
matplotlib.axes.Axes.plot()(univariate, other element, fill=False) -
matplotlib.axes.Axes.pcolormesh()(bivariate)
Returnsmatplotlib.axes.Axes
The matplotlib axes containing the plot.
See also
displot
Figure-level interface to distribution plot functions.
kdeplot
Tracer des distributions univariées ou bivariées en utilisant l’estimation de la densité du noyau.
rugplot
Tracez une coche à chaque valeur d’observation le long des axes x et/ou y.
ecdfplot
Tracer les fonctions de distribution cumulatives empiriques.
jointplot
Tracez un graphique bivarié avec des distributions marginales univariées.
Notes
Le choix des bacs pour calculer et tracer un histogramme peut exercer une influence substantielle sur les informations que l’on est capable de tirer de la visualisation. Si les bacs sont trop grands, ils peuvent effacer des caractéristiques importantes.D’autre part, les bacs trop petits peuvent être dominés par la variabilité aléatoire, obscurcissant la forme de la vraie distribution sous-jacente. La taille du bac par défaut est déterminée à l’aide d’une règle de référence qui dépend de la taille et de la variance de l’échantillon. Cela fonctionne bien dans de nombreux cas (c’est-à-dire avec des données « bien comportées »), mais cela échoue dans d’autres. C’est toujours bon d’essayerdifférentes tailles de bacs pour être sûr de ne pas manquer quelque chose d’important.Cette fonction vous permet de spécifier des bacs de plusieurs manières différentes, par exemple en définissant le nombre total de bacs à utiliser, la largeur de chaque bac ou les emplacements spécifiques où les bacs doivent se casser.
Exemples
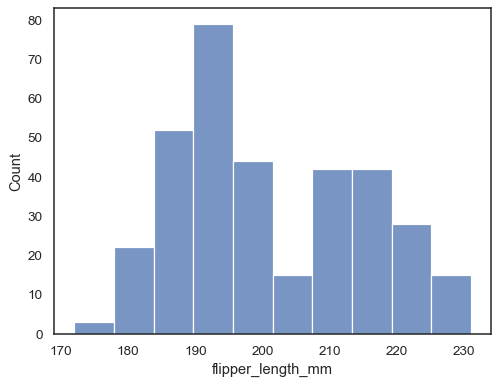
Attribuez une variable à x pour tracer une distribution univariée le long de l’axe des x :
penguins = sns.load_dataset("penguins")sns.histplot(data=penguins, x="flipper_length_mm")
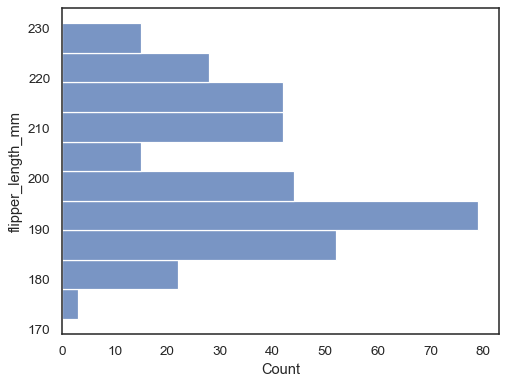
Retournez le tracé en affectant la variable de données à l’axe y :
sns.histplot(data=penguins, y="flipper_length_mm")
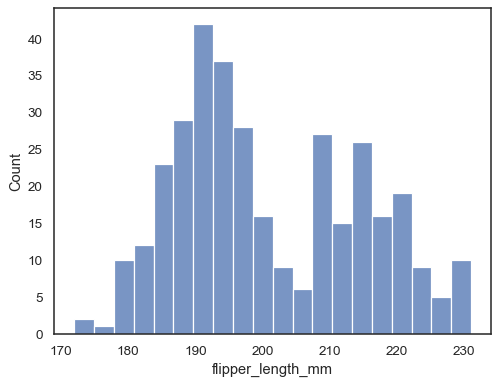
Vérifiez dans quelle mesure l’histogramme représente les données en spécifiant une largeur de bac différente :
sns.histplot(data=penguins, x="flipper_length_mm", binwidth=3)
Vous pouvez également définir le nombre total de bacs à utiliser :
sns.histplot(data=penguins, x="flipper_length_mm", bins=30)
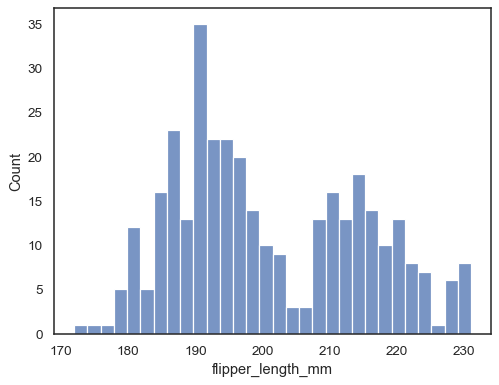
Ajoutez une estimation de la densité du noyau pour lisser l’histogramme, en fournissant des informations complémentaires sur la forme de la distribution :
sns.histplot(data=penguins, x="flipper_length_mm", kde=True)
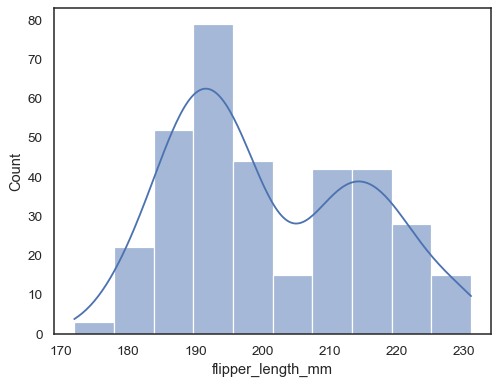
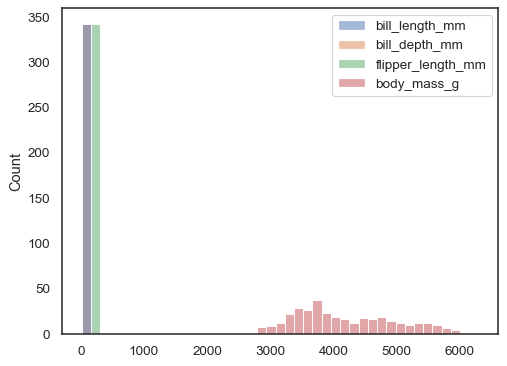
Si ni x ni y n’est attribué, l’ensemble de données est traité sous forme large et un histogramme est dessiné pour chaque colonne numérique :
sns.histplot(data=penguins)
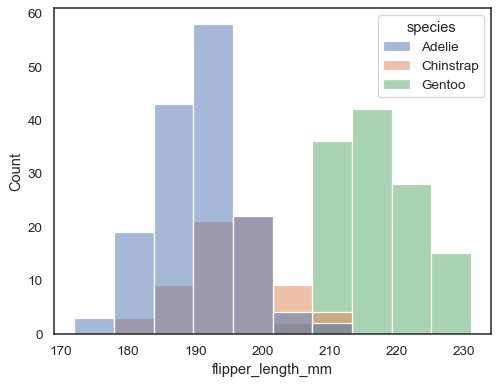
Vous pouvez sinon dessiner plusieurs histogrammes à partir d’un ensemble de données de forme longue avec un mappage de fichiers :
sns.histplot(data=penguins, x="flipper_length_mm", hue="species")
L’approche par défaut pour tracer plusieurs distributions consiste à les » superposer », mais vous pouvez également les « empiler »:
sns.histplot(data=penguins, x="flipper_length_mm", hue="species", multiple="stack")
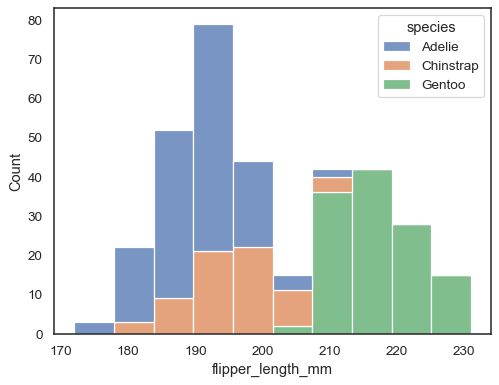
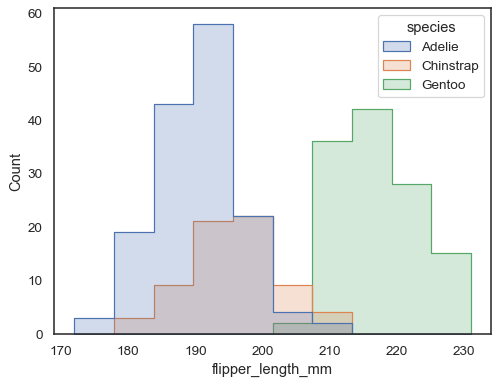
Les barres qui se chevauchent peuvent être difficiles à résoudre visuellement. Une approche différente consisterait à dessiner une fonction d’étape:
sns.histplot(penguins, x="flipper_length_mm", hue="species", element="step")
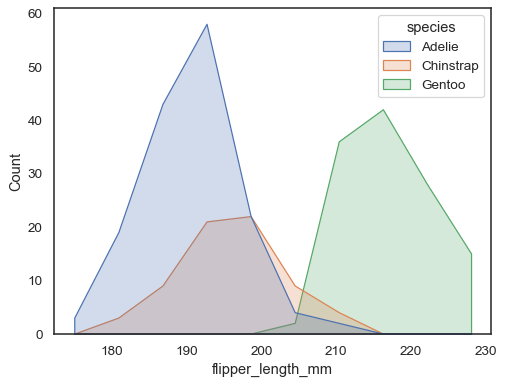
Vous pouvez vous éloigner encore plus des barres en dessinant un polygone avec des sommets au centre de chaque bac. Cela peut faciliter la visualisation de la forme de la distribution, mais utilisez-la avec prudence: il sera moins évident pour votre public qu’il regarde un histogramme:
sns.histplot(penguins, x="flipper_length_mm", hue="species", element="poly")
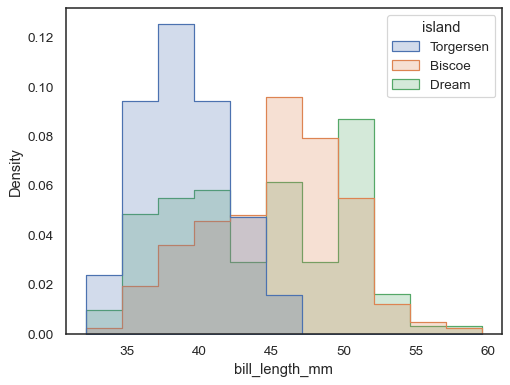
Pour comparer la distribution de sous-ensembles qui diffèrent sensiblement en taille, utilisez la normalisation de densité indépendante :
sns.histplot( penguins, x="bill_length_mm", hue="island", element="step", stat="density", common_norm=False,)
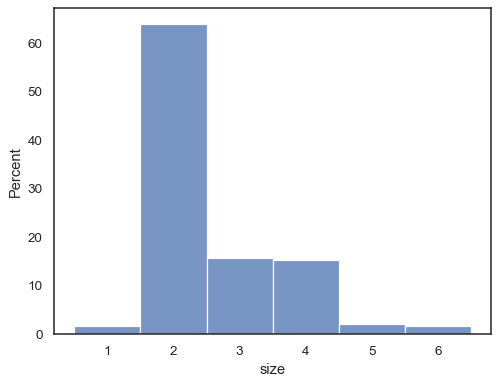
Il est également possible de normaliser pour que la hauteur de chaque barre montre une approbabilité, ce qui est plus logique pour les variables discrètes:
tips = sns.load_dataset("tips")sns.histplot(data=tips, x="size", stat="probability", discrete=True)
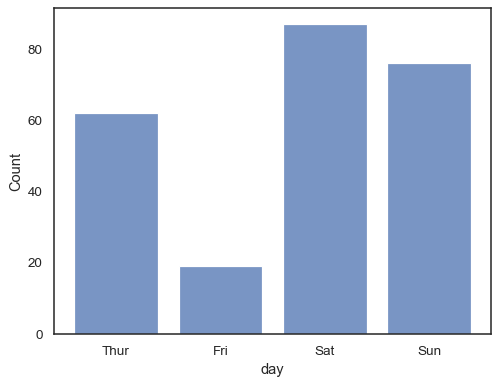
Vous pouvez même dessiner un histogramme sur des variables catégorielles (bien que ce soit une fonctionnalité expérimentale):
sns.histplot(data=tips, x="day", shrink=.8)
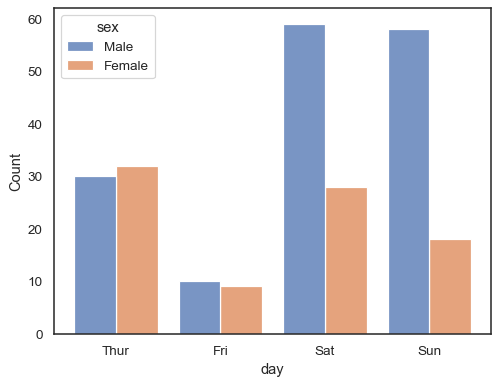
Lorsque vous utilisez une sémantique hue avec des données discrètes, il peut être logique d' »esquiver » les niveaux:
sns.histplot(data=tips, x="day", hue="sex", multiple="dodge", shrink=.8)
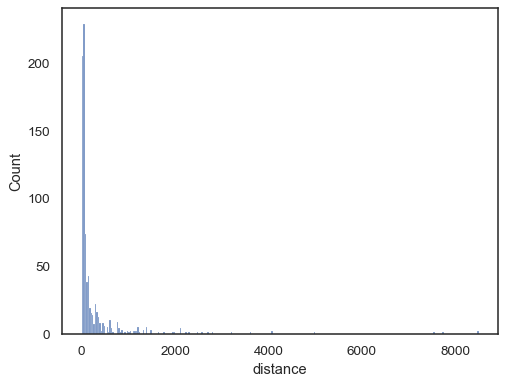
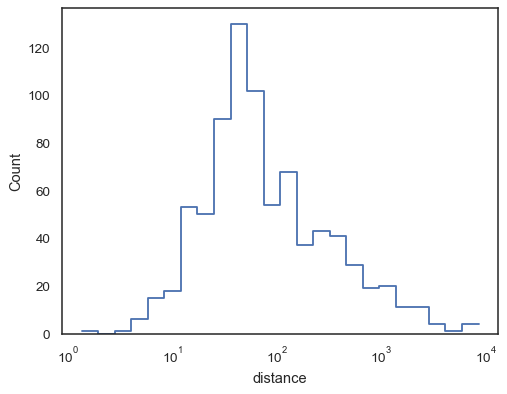
Les données réelles sont souvent biaisées. Pour les distributions fortement asymétriques, il est préférable de définir les bacs dans l’espace journal. Comparer:
planets = sns.load_dataset("planets")sns.histplot(data=planets, x="distance")
To the log-scale version:
sns.histplot(data=planets, x="distance", log_scale=True)
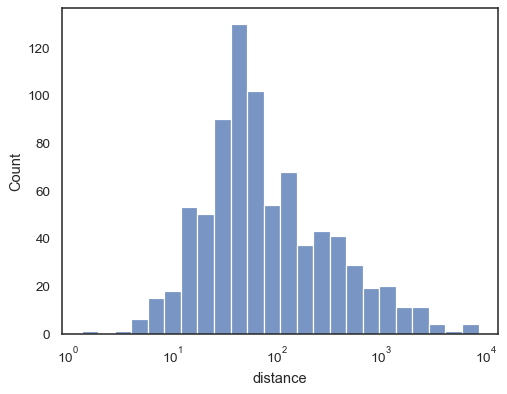
There are also a number of options for how the histogram appears. Youcan show unfilled bars:
sns.histplot(data=planets, x="distance", log_scale=True, fill=False)
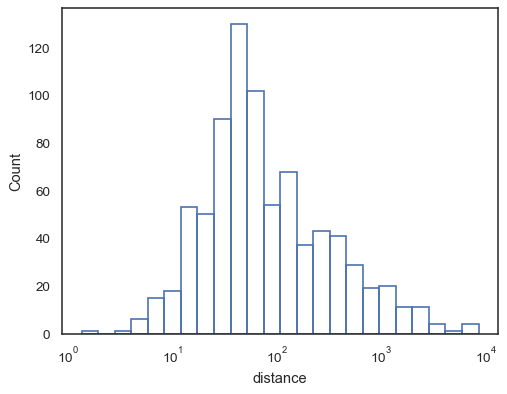
Or an unfilled step function:
sns.histplot(data=planets, x="distance", log_scale=True, element="step", fill=False)
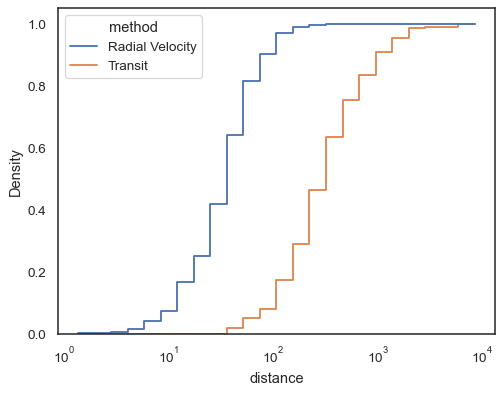
, en particulier lorsqu’elles ne sont pas remplies, facilitent la comparaison des histogrammes cumulatifs :
sns.histplot( data=planets, x="distance", hue="method", hue_order=, log_scale=True, element="step", fill=False, cumulative=True, stat="density", common_norm=False,)
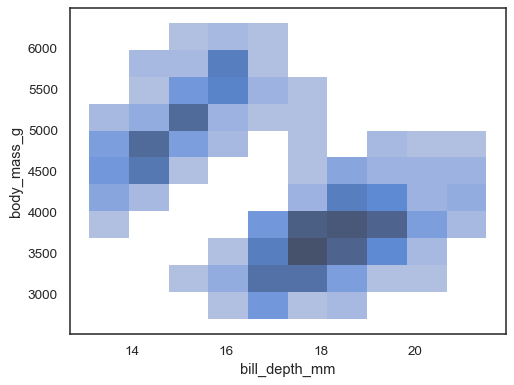
Lorsque les x et y sont assignées, un histogramme bivarié est calculé et affiché sous forme de carte thermique :
sns.histplot(penguins, x="bill_depth_mm", y="body_mass_g")
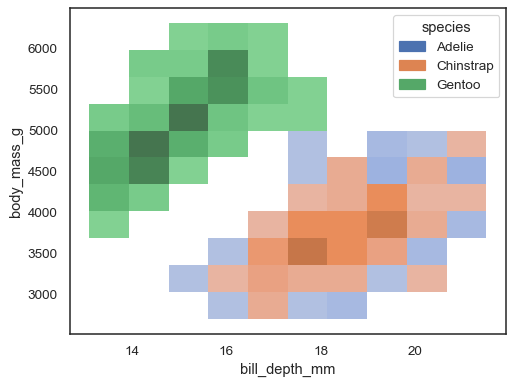
Il est également possible d’attribuer une variable hue, bien que cela ne fonctionne pas bien si les données des différents niveaux se chevauchent considérablement :
sns.histplot(penguins, x="bill_depth_mm", y="body_mass_g", hue="species")
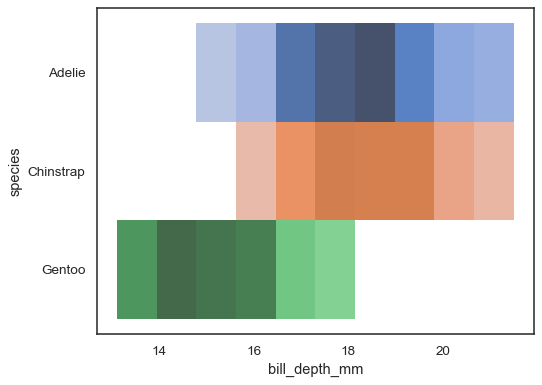
Plusieurs cartes de couleurs peuvent avoir un sens lorsque l’une des variables estdécret :
sns.histplot( penguins, x="bill_depth_mm", y="species", hue="species", legend=False)
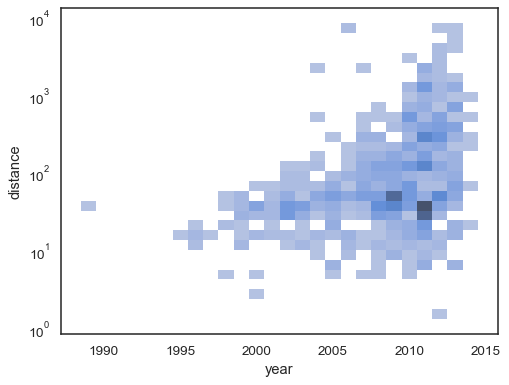
L’histogramme bivarié accepte toutes les mêmes options de calcul comme son homologue univarié, en utilisant des tuples pour paramétrer x et y indépendamment :
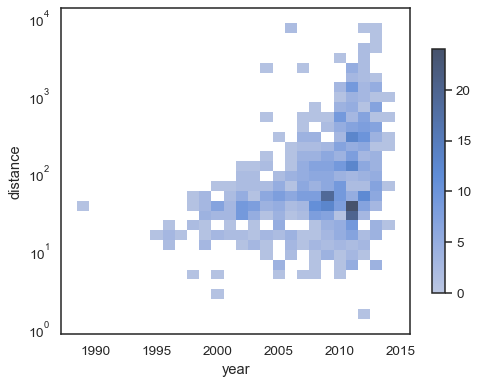
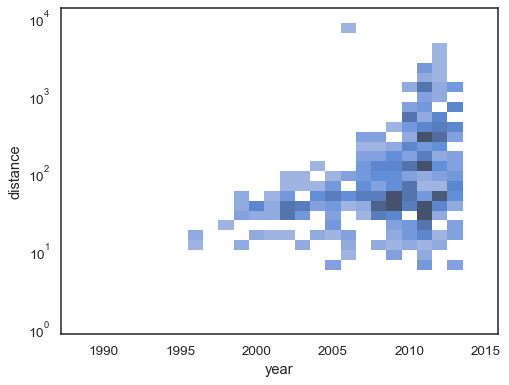
sns.histplot( planets, x="year", y="distance", bins=30, discrete=(True, False), log_scale=(False, True),)
div>
Le comportement par défaut rend les cellules sans observations transparentes, bien que cela puisse être désactivé :
sns.histplot( planets, x="year", y="distance", bins=30, discrete=(True, False), log_scale=(False, True), thresh=None,)
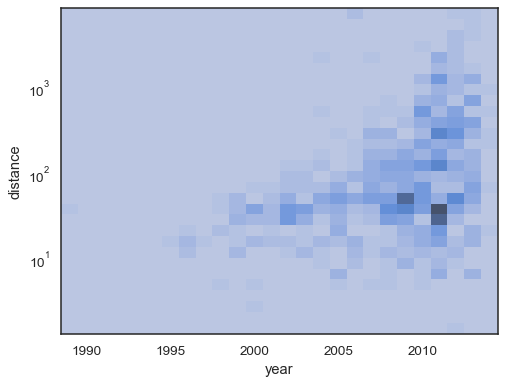
Il est également possible de définir le seuil et le point de saturation de la palette de couleurs de la proportion de comptes cumulés:
sns.histplot( planets, x="year", y="distance", bins=30, discrete=(True, False), log_scale=(False, True), pthresh=.05, pmax=.9,)
Pour annoter la carte de couleurs, ajoutez une barre de couleurs :
sns.histplot( planets, x="year", y="distance", bins=30, discrete=(True, False), log_scale=(False, True), cbar=True, cbar_kws=dict(shrink=.75),)