Un outil d’analyse de frottis (PAT) pour la détection du cancer du col utérin à partir d’images de frottis
- Analyse d’images
- Acquisition d’images
- Amélioration de l’image
- Segmentation de scène
- Enlèvement des débris
- Analyse de taille
- Analyse de la forme
- Analyse de texture
- Extraction d’entités
- Sélection des caractéristiques
- La défuzzification
- Évaluation de la classification
- Conception et intégration de l’interface graphique
Analyse d’images
Le pipeline d’analyse d’images pour le développement d’un outil d’analyse de frottis pour la détection du cancer du col utérin à partir de frottis présentés dans cet article est représenté à la Fig. 1.

L’approche pour détecter le cancer du col utérin à partir d’images de frottis
Acquisition d’images
L’approche a été évaluée à l’aide de trois méthodes : jeux de données. L’ensemble de données 1 est constitué de 917 cellules uniques d’images de frottis de Harlev préparées par Jantzen et al. . L’ensemble de données contient des images de frottis de pap prises avec une résolution de 0,201 µm/pixel par des cytopathologistes qualifiés à l’aide d’un microscope connecté à une pince d’acquisition d’images. Les images ont été segmentées à l’aide du logiciel commercial CHAMP, puis classées en sept classes avec des caractéristiques distinctes, comme le montre le tableau 2. De ces 200 images ont été utilisées pour l’entraînement et 717 images pour les tests.
L’ensemble de données 2 se compose de 497 images de frottis de diapositives complètes préparées par Norup et al. . De ces 200 images ont été utilisées pour la formation et 297 images pour les tests. De plus, la performance du classificateur a été évaluée sur le jeu de données 3 d’échantillons de 60 frottis pap (30 normaux et 30 anormaux) obtenus à l’Hôpital régional de référence de Mbarara (MRRH). Les spécimens ont été imagés à l’aide d’un microscope à champ lumineux Olympus BX51 équipé d’une lentille de 40 × 0,95 NA et d’une caméra monochrome Hamamatsu ORCA-05G de 1,4 Mpx, donnant une taille de pixel de 0,25 µm avec une profondeur de gris de 8 bits. Chaque image a ensuite été divisée en 300 zones, chaque zone contenant entre 200 et 400 cellules. Sur la base des opinions des cytopathologistes, 10 000 objets dans des images dérivées des 60 lames de frottis différentes ont été sélectionnés, dont 8 000 étaient des cellules épithéliales cervicales libres (3 000 cellules normales provenant de frottis normaux et 5 000 cellules anormales provenant de frottis anormaux) et les 2 000 autres étaient des objets débris. Cette segmentation par frottis a été réalisée à l’aide de la boîte à outils de segmentation Weka entraînable pour construire un classificateur de segmentation au niveau des pixels.
Amélioration de l’image
Une égalisation adaptative locale de l’histogramme de contraste (CLAHE) a été appliquée à l’image en niveaux de gris pour l’amélioration de l’image. Dans CLAHE, la sélection de clip-limit qui spécifie la forme souhaitée de l’histogramme de l’image est primordiale, car elle influence de manière critique la qualité de l’image améliorée. La valeur optimale de la limite de clip a été choisie empiriquement en utilisant la méthode définie par Joseph et al. . Une valeur limite optimale du clip de 2.0 a été jugé approprié pour fournir une amélioration adéquate de l’image tout en préservant les caractéristiques sombres des ensembles de données utilisés. La conversion en niveaux de gris a été réalisée à l’aide d’une technique en niveaux de gris implémentée à l’aide de l’égaliseur. 1 tel que défini dans.
où R = Rouge, G= Vert et B= contributions de couleur bleue à la nouvelle image.
L’application de CLAHE pour l’amélioration de l’image a entraîné des modifications notables des images en ajustant les intensités de l’image où l’assombrissement du noyau, ainsi que les limites du cytoplasme, sont devenus facilement identifiables à l’aide d’une limite de clip de 2.0.
Segmentation de scène
Pour obtenir une segmentation de scène, un classificateur de niveau de pixels a été développé à l’aide de la boîte à outils de segmentation Weka (TWS) entraînable. La majorité des cellules observées dans un frottis sont sans surprise des cellules épithéliales cervicales. De plus, un nombre variable de leucocytes, d’érythrocytes et de bactéries est généralement évident, tandis qu’un petit nombre d’autres cellules et micro-organismes contaminants sont parfois observés. Cependant, le frottis contient quatre principaux types de cellules cervicales squameuses — superficielles, intermédiaires, parabasales et basales — dont les cellules superficielles et intermédiaires représentent l’écrasante majorité dans un frottis conventionnel; ces deux types sont donc généralement utilisés pour une analyse de frottis classique. Une segmentation Weka entraînable a été utilisée pour identifier et segmenter les différents objets de la diapositive. À ce stade, un classificateur de niveau de pixels a été formé sur l’identification des noyaux cellulaires, du cytoplasme, du fond et des débris avec l’aide d’un cytopathologiste qualifié utilisant une boîte à outils de segmentation Weka (TWS) entraînable. Cela a été réalisé en dessinant des lignes / sélection à travers les domaines d’intérêt et en les attribuant à une classe particulière. Les pixels sous les lignes / sélection ont été considérés comme représentatifs des noyaux, du cytoplasme, du fond et des débris.
Les contours dessinés dans chaque classe ont été utilisés pour générer un vecteur d’entités, \(\mathop F\limits^{\to}\) qui a été dérivé du nombre de pixels appartenant à chaque contour. Le vecteur caractéristique de chaque image (200 de l’ensemble de données 1 et 200 de l’ensemble de données 2) a été défini par Eq. 2.
où Ni, Ci, Bi et Di sont le nombre de pixels du noyau, du cytoplasme, de l’arrière-plan et des débris de l’image \(i\) comme le montre la Fig. 2.

Génération du vecteur d’entités à partir des images d’entraînement
Chaque pixel extrait de l’image représente non seulement son intensité, mais également un ensemble de caractéristiques d’image qui contiennent beaucoup d’informations, y compris la texture, les bordures et la couleur dans une zone de pixels de 0,201 µm2. Le choix d’un vecteur de caractéristiques approprié pour la formation du classificateur a été un grand défi et une tâche nouvelle dans l’approche proposée. Le classificateur de niveau de pixels a été formé à l’aide d’un total de 226 fonctionnalités d’entraînement de TWS. Le classificateur a été formé à l’aide d’un ensemble de fonctionnalités de formation TWS comprenant: (i) Réduction du bruit: Les filtres Kuwahara et bilatéraux de la boîte à outils TWS ont été utilisés pour former le classificateur à l’élimination du bruit. Ceux-ci se sont révélés être d’excellents filtres pour éliminer le bruit tout en préservant les bords, (ii) Détection des bords: Un filtre de Sobel, une matrice de Hesse et un filtre de Gabor ont été utilisés pour entraîner le classificateur à la détection des limites dans une image, et (iii) Filtrage de texture: Les filtres moyenne, variance, médiane, maximum, minimum et entropie ont été utilisés pour le filtrage des textures.
Enlèvement des débris
La principale raison des limitations actuelles de nombreux systèmes d’analyse de frottis automatisés existants est qu’ils ont du mal à surmonter la complexité des structures de frottis, en essayant d’analyser la lame dans son ensemble, qui contient souvent plusieurs cellules et débris. Cela a le potentiel de provoquer l’échec de l’algorithme et nécessite une puissance de calcul plus élevée. Les échantillons sont recouverts d’artefacts — tels que des cellules sanguines, des cellules qui se chevauchent et se replient et des bactéries — qui entravent les processus de segmentation et génèrent un grand nombre d’objets suspects. Il a été démontré que les classificateurs conçus pour différencier les cellules normales des cellules précancéreuses produisent généralement des résultats imprévisibles lorsque des artefacts existent dans le frottis. Dans cet outil, une technique d’identification des cellules du col de l’utérus utilisant un schéma d’élimination séquentielle triphasé (représenté à la Fig. 3) est utilisé.

Approche d’élimination séquentielle triphasée pour le rejet des débris
Le schéma d’élimination triphasée proposé élimine séquentiellement les débris du frottis si il est peu probable qu’il s’agisse d’une cellule du col de l’utérus. Cette approche est bénéfique car elle permet de prendre une décision de dimension inférieure à chaque étape.
Analyse de taille
L’analyse de taille est un ensemble de procédures permettant de déterminer une gamme de mesures de taille de particules. La zone est l’une des caractéristiques les plus élémentaires utilisées dans le domaine de la cytologie automatisée pour séparer les cellules des débris. L’analyse de frottis est un domaine bien étudié avec beaucoup de connaissances préalables sur les propriétés cellulaires. Cependant, l’un des changements clés avec l’évaluation de la surface du noyau est que les cellules cancéreuses subissent une augmentation substantielle de la taille du noyau. Par conséquent, la détermination d’un seuil de taille supérieure qui n’exclut pas systématiquement les cellules de diagnostic est beaucoup plus difficile, mais présente l’avantage de réduire l’espace de recherche. La méthode présentée dans cet article est basée sur un seuil de taille inférieure et de taille supérieure des cellules cervicales. Le pseudo-code de l’approche est affiché dans Eq. 3.
où \(Area_{max}= 85,267\, {\upmu\text {m}}^{2}\) et \(Area_{min}= 625\, {\upmu\text{m}}^{2}\) dérivées du tableau 2.
Les objets en arrière-plan sont considérés comme des débris et donc rejetés de l’image. Les particules qui se situent entre \(Area_{min}\) et \(Area_{max}\) sont analysées plus avant lors des étapes suivantes de l’analyse de la texture et de la forme.
Analyse de la forme
La forme des objets d’un frottis est une caractéristique clé de la différenciation entre les cellules et les débris. Il existe un certain nombre de méthodes de détection de description de forme, notamment des approches basées sur les régions et les contours. Les méthodes basées sur les régions sont moins sensibles au bruit mais plus gourmandes en calculs, tandis que les méthodes basées sur les contours sont relativement efficaces à calculer mais plus sensibles au bruit. Dans cet article, une méthode basée sur la région (perimeter2/area (P2A)) a été utilisée. Le descripteur P2A a été choisi pour le mérite qu’il décrit la similitude d’un objet avec un cercle. Cela le rend bien adapté comme descripteur de noyau cellulaire puisque les noyaux sont généralement circulaires dans leur aspect. Le P2A est également appelé compacité de forme et est défini par Eq. 4.
où c est la valeur de la compacité de la forme, A est l’aire et p est le périmètre du noyau. On a supposé que les débris étaient des objets ayant une valeur de P2A supérieure à 0,97 ou inférieure à 0,15 selon les caractéristiques d’entraînement (représentées dans le tableau 2).
Analyse de texture
La texture est une caractéristique très importante qui peut différencier les noyaux des débris. La texture de l’image est un ensemble de mesures conçues pour quantifier la texture perçue d’une image. Au sein d’un frottis, la distribution de l’intensité moyenne des taches nucléaires est beaucoup plus étroite que la variation de l’intensité des taches entre les débris. Ce fait a été utilisé comme base pour éliminer les débris en fonction de leurs intensités d’image et des informations de couleur à l’aide des moments de Zernike (ZM). Les moments Zernike sont utilisés pour diverses applications de reconnaissance de formes et sont connus pour être robustes en ce qui concerne le bruit et pour avoir un bon pouvoir de reconstruction. Dans ce travail, le ZM tel que présenté par Malm et al. d’ordre n avec répétition I de la fonction \(f\left({r,\theta}\right)\), en coordonnées polaires à l’intérieur d’un disque centré en image carrée \(I\left({x,y}\right)\) de taille \(m\times m\) donnée par Eq. 5 a été utilisé.
\(v_{nl}^{* }\left({r, \theta}\right)\) désigne le conjugué complexe du polynôme de Zernike \(v_{nl}\left({r, \theta}\right)\). Pour produire une mesure de texture, les grandeurs de \(A_{nl}\) centrées sur chaque pixel de l’image de texture sont moyennées.
Extraction d’entités
Le succès d’un algorithme de classification dépend grandement de l’exactitude des entités extraites de l’image. Les cellules des frottis dans l’ensemble de données utilisé sont divisées en sept classes en fonction de caractéristiques telles que la taille, la surface, la forme et la luminosité du noyau et du cytoplasme. Les caractéristiques extraites des images comprenaient des caractéristiques morphologiques précédemment utilisées par d’autres. Dans cet article, trois caractéristiques géométriques (solidité, compacité et excentricité) et six caractéristiques textuelles (moyenne, écart-type, variance, douceur, énergie et entropie) ont également été extraites du noyau, ce qui donne 29 caractéristiques au total, comme indiqué dans le tableau 3.
Sélection des caractéristiques
La sélection des caractéristiques consiste à sélectionner des sous-ensembles des caractéristiques extraites qui donnent les meilleurs résultats de classification. Parmi les caractéristiques extraites, certaines peuvent contenir du bruit tandis que le classificateur choisi peut ne pas en utiliser d’autres. Par conséquent, un ensemble optimal de caractéristiques doit être déterminé, éventuellement en essayant toutes les combinaisons. Cependant, lorsqu’il existe de nombreuses fonctionnalités, les combinaisons possibles explosent en nombre, ce qui augmente la complexité de calcul de l’algorithme. Les algorithmes de sélection d’entités sont généralement classés dans les méthodes filtre, wrapper et embedded.
La méthode utilisée par l’outil combine un recuit simulé avec une approche enveloppante. Cette approche a été proposée dans mais, dans cet article, la performance de la sélection de caractéristiques est évaluée à l’aide d’un algorithme de forêt aléatoire à double stratégie. Le recuit simulé est une technique probabiliste permettant d’approximer l’optimum global d’une fonction donnée. L’approche est bien adaptée pour s’assurer que l’ensemble optimal de fonctionnalités est sélectionné. La recherche de l’ensemble optimal est guidée par une valeur de forme physique. Une fois le recuit simulé terminé, tous les différents sous-ensembles de caractéristiques sont comparés et le plus apte (c’est-à-dire celui qui fonctionne le mieux) est sélectionné. La recherche de valeur d’aptitude a été obtenue avec un wrapper où la validation croisée du pli k a été utilisée pour calculer l’erreur sur l’algorithme de classification. Différentes combinaisons des caractéristiques extraites sont préparées, évaluées et comparées à d’autres combinaisons. Un modèle prédictif est ensuite utilisé pour évaluer une combinaison de fonctionnalités et attribuer un score basé sur la précision du modèle. L’erreur de remise en forme donnée par l’emballage est utilisée comme erreur de remise en forme par l’algorithme de recuit simulé. Un algorithme flou de C-means a été enveloppé dans une boîte noire, à partir de laquelle une erreur estimée a été obtenue pour les différentes combinaisons de caractéristiques comme illustré à la Fig. 4.

La moyenne C floue est enveloppée dans une boîte noire à partir de laquelle une erreur estimée est obtenue
La moyenne C floue permet des points de données dans l’ensemble de données pour appartenir à tous les clusters, avec des adhésions dans l’intervalle (0-1) comme indiqué dans Eq. 6.
où \(m_{ik} \) est l’appartenance du point de données k au centre de cluster i, \(d_{jk} \) est la distance du centre de cluster j au point de données k et q € est un exposant qui décide de la force des adhésions. L’algorithme fuzzy C-means a été implémenté à l’aide de la boîte à outils fuzzy de Matlab.
La défuzzification
Un algorithme C-means flou ne nous dit pas quelles informations les clusters contiennent et comment ces informations doivent être utilisées pour la classification. Cependant, il définit comment les points de données sont attribués à l’appartenance aux différents clusters et cette appartenance floue est utilisée pour prédire la classe d’un point de données. Ceci est surmonté par la défuzzification. Il existe un certain nombre de méthodes de défuzzification. Cependant, dans cet outil, chaque cluster a une appartenance floue (0-1) à toutes les classes de l’image. Les données de formation sont affectées au cluster le plus proche. Le pourcentage de données d’apprentissage de chaque classe appartenant au cluster A donne l’appartenance du cluster, cluster A = aux différentes classes, où i est le confinement dans le cluster A et j dans l’autre cluster. La mesure d’intensité est ajoutée à la fonction d’appartenance pour chaque cluster à l’aide d’un algorithme de défuzzification de clusters flous. Une approche populaire pour la défuzzification d’une partition floue est l’application du principe du degré d’appartenance maximal où le point de données k est affecté à la classe m si, et seulement si, son degré d’appartenance \(m_{ik}\) au cluster i est le plus grand. Chuang et coll. proposition d’ajuster le statut d’adhésion de chaque point de données en utilisant le statut d’adhésion de ses voisins.
Dans l’approche proposée, une méthode de défuzzification basée sur la probabilité bayésienne est utilisée pour générer un modèle probabiliste de la fonction d’appartenance pour chaque point de données et appliquer le modèle à l’image pour produire les informations de classification. Le modèle probabiliste est calculé comme suit :
-
Convertissez les distributions de possibilités dans la matrice de partition (clusters) en distributions de probabilités.
-
Construire un modèle probabiliste des distributions de données comme dans.
-
Appliquez le modèle pour produire les informations de classification pour chaque point de données en utilisant Eq. 7.
où \(P\left({A_{i}}\right), i = 0\ldots.c \) est la probabilité antérieure de \(A_{i} \) qui peut être calculée en utilisant la méthode dans laquelle la probabilité antérieure est toujours proportionnelle à la masse de chaque classe.
Le nombre de clusters à utiliser a été déterminé pour garantir que le modèle construit puisse décrire les données de la meilleure façon possible. Si trop de clusters sont choisis, il y a un risque de surajustement du bruit dans les données. Si trop peu de clusters sont choisis, un mauvais classificateur pourrait en être le résultat. Par conséquent, une analyse du nombre de grappes par rapport à l’erreur de test de validation croisée a été effectuée. Un nombre optimal de 25 grappes a été atteint et le surentraînement s’est produit au-dessus de ce nombre de grappes. Un exposant de défuzzification de 1.0930 a été obtenu avec 25 grappes, une validation croisée décuplée et 60 rediffusions et a été utilisé pour calculer l’erreur d’adéquation pour la sélection des entités où un total de 18 entités sur les 29 entités ont été sélectionnées pour la construction du classificateur. Les caractéristiques sélectionnées étaient: zone du noyau; niveau de gris du noyau; diamètre du noyau le plus court; noyau le plus long; périmètre du noyau; maxima dans le noyau; minima dans le noyau; zone du cytoplasme; niveau de gris du cytoplasme; périmètre du cytoplasme; rapport noyau sur cytoplasme; excentricité du noyau, écart-type du noyau, variance du niveau de gris du noyau; entropie du niveau de gris du noyau; position relative du noyau; moyenne du niveau de gris du noyau et valeurs du gris du noyau énergie.
Évaluation de la classification
Dans cet article, le modèle hiérarchique de l’efficacité des systèmes d’imagerie diagnostique proposé par Fryback et Thornbury a été adopté comme principe directeur pour l’évaluation de l’outil, comme le montre le tableau 4.
La sensibilité mesure la proportion de positifs réels correctement identifiés comme tels, tandis que la spécificité mesure la proportion de négatifs réels correctement identifiés comme tels. La sensibilité et la spécificité sont décrites par Eq. 8.
où TP = Vrais positifs, FN= Faux négatifs, TN = Vrais négatifs et FP = Faux positifs.
Conception et intégration de l’interface graphique
Les procédés de traitement d’images décrits ci-dessus ont été implémentés dans Matlab et sont exécutés via une interface utilisateur graphique Java (GUI) représentée à la Fig. 5. L’outil comporte un panneau dans lequel une image de frottis est chargée et le cytotechnicien sélectionne une méthode appropriée pour la segmentation de scène (basée sur le classificateur TWS), l’élimination des débris (basée sur l’approche d’élimination séquentielle à trois) et la détection des limites (si cela est jugé nécessaire, à l’aide de la méthode de détection des bords Canny), après quoi les caractéristiques sont extraites à l’aide du bouton Extraire les caractéristiques.
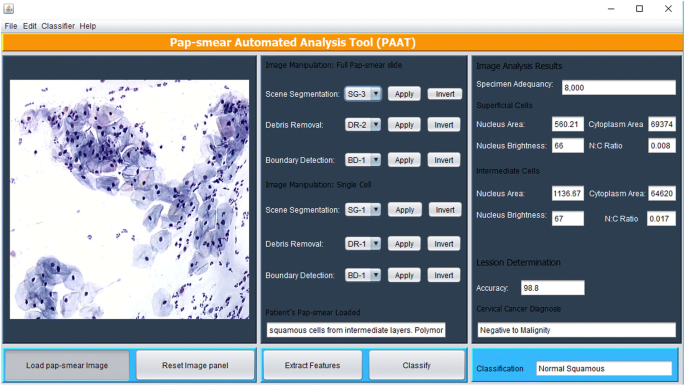
Interface utilisateur graphique PAT
L’outil parcourt le frottis pour analyser tous les objets qui sont restés après l’enlèvement des débris. Les 18 caractéristiques décrites dans la sélection des caractéristiques sont extraites de chaque objet et utilisées pour classer chaque cellule en utilisant l’algorithme floue de C-means décrit dans la méthode de classification. Des caractéristiques extraites aléatoirement d’une cellule superficielle et d’une cellule intermédiaire sont affichées dans le panneau des résultats d’analyse d’image. Une fois les caractéristiques extraites, le cytotechnicien (utilisateur) appuie sur le bouton classer et l’outil émet un diagnostic (positif à la malignité ou négatif à la malignité) et classe le diagnostic à l’une des 7 classes / stades du cancer du col de l’utérus selon l’ensemble de données de formation.