Hogyan lehet szemantikai szegmentálást végezni a mély tanulás használatával
Ez a cikk átfogó áttekintést nyújt, amely lépésről lépésre bemutatja a mély tanulási képszegmentációs modell megvalósítását.
itt megosztottunk egy új, frissített blogot a szemantikai Szegmentálásról: 2021-es útmutató a szemantikai Szegmentáláshoz
manapság a szemantikai szegmentálás az egyik legfontosabb probléma a számítógépes látás területén. A nagy képet tekintve a szemantikus szegmentálás az egyik magas szintű feladat, amely előkészíti az utat a jelenet teljes megértése felé. A jelenet megértésének fontosságát, mint alapvető számítógépes látásproblémát, kiemeli az a tény, hogy egyre több alkalmazás táplálja a képekből származó ismeretek következtetését. Néhány ilyen alkalmazás magában foglalja az önvezető járműveket, az ember-számítógép interakciót, a virtuális valóságot stb. A mély tanulás népszerűségével az elmúlt években számos szemantikai szegmentációs problémát kezelnek mély architektúrák, leggyakrabban konvolúciós neurális hálók, amelyek pontosság és hatékonyság szempontjából nagy különbséggel felülmúlják a többi megközelítést.
- mi a szemantikai szegmentálás?
- mi a meglévő szemantikai szegmentációs megközelítések?
- 1-Régióalapú szemantikai szegmentálás
- 2 — teljesen konvolúciós hálózat alapú szemantikai szegmentálás
- 3 — gyengén felügyelt szemantikai szegmentálás
- szemantikai szegmentálás elvégzése teljesen konvolúciós hálózattal
- 1.lépés
- 2.lépés
- 3.lépés
- 4.lépés
- 5. lépés
- lehet, hogy érdekel a legújabb hozzászólás:
mi a szemantikai szegmentálás?
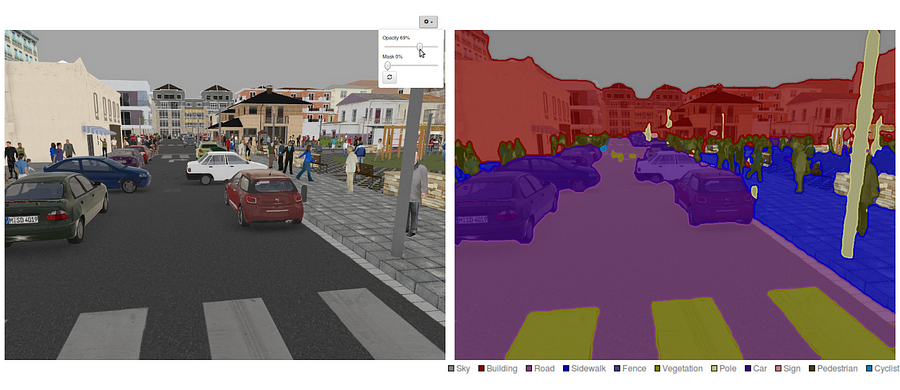
a szemantikai szegmentálás természetes lépés a durva következtetéstől a finom következtetésig: az eredet a osztályozásnál helyezkedhet el, amely egy egész bemenet előrejelzéséből áll.A következő lépés a lokalizáció / detektálás, amely nemcsak az osztályokat, hanem az osztályok térbeli elhelyezkedésével kapcsolatos további információkat is szolgáltat.Végül a szemantikai szegmentálás finomszemcsés következtetést ér el azáltal, hogy sűrű előrejelzéseket készít minden pixel címkéjére, így minden pixelt a körülzáró objektumérc régió osztályával jelölnek.
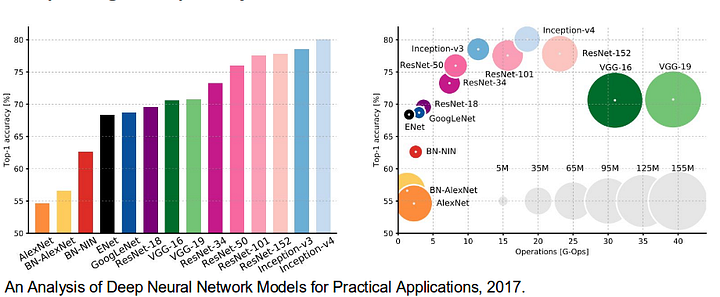
érdemes áttekinteni néhány olyan szabványos mélyhálózatot is, amelyek jelentősen hozzájárultak a számítógépes látás területéhez, mivel ezeket gyakran használják a szemantikai szegmentációs rendszerek alapjaként:
- alexnet: Toronto úttörő mély CNN, amely megnyerte a 2012-es IMAGEnet versenyt 84,6% – os tesztpontossággal. 5 konvolúciós rétegből áll, max-pooling rétegekből, ReLUs mint nem-linearitásokból, 3 teljesen konvolúciós rétegből és lemorzsolódásból.
- VGG-16: Ez az Oxfordi modell 92,7% – os pontossággal nyerte meg a 2013-as ImageNet versenyt. Ez használ egy halom konvolúciós rétegek kis befogadó mezők az első rétegek helyett néhány réteg nagy befogadó mezők.
- GoogLeNet: ez a Google hálózata nyerte meg a 2014-es ImageNet versenyt 93, 3% – os pontossággal. 22 rétegből áll, és egy újonnan bevezetett építőelem, az inception module. A modul egy hálózat a hálózatban rétegből, egy pooling műveletből, egy nagy méretű konvolúciós rétegből és egy kis méretű konvolúciós rétegből áll.
- ResNet: ez a Microsoft modellje 96,4% – os pontossággal nyerte meg a 2016-os ImageNet versenyt. Jól ismert a mélysége (152 réteg) és a maradék blokkok bevezetése miatt. A maradék blokkok egy igazán mély architektúra képzésének problémájával foglalkoznak az identity skip connections bevezetésével, hogy a rétegek átmásolhassák bemeneteiket a következő rétegre.
mi a meglévő szemantikai szegmentációs megközelítések?
egy általános szemantikai szegmentációs architektúra nagyjából úgy tekinthető, mint egy kódoló hálózat, amelyet egy dekóder hálózat követ:
- a kódoló általában egy előre kiképzett osztályozási hálózat, mint például a VGG/ResNet, amelyet egy dekóder hálózat követ.
- a dekóder feladata, hogy szemantikailag kivetítse a kódoló által megtanult diszkriminatív jellemzőket (alacsonyabb felbontás) a pixeltérre (nagyobb felbontás), hogy sűrű osztályozást kapjon.
ellentétben az osztályozással, ahol a nagyon mély hálózat végeredménye az egyetlen fontos dolog, a szemantikai szegmentálás nemcsak pixelszintű megkülönböztetést igényel, hanem egy mechanizmust is, amely a kódoló különböző szakaszaiban megtanult diszkriminatív jellemzőket a pixeltér. A különböző megközelítések különböző mechanizmusokat alkalmaznak a dekódolási mechanizmus részeként. Vizsgáljuk meg a 3 fő megközelítést:
1-Régióalapú szemantikai szegmentálás
a régióalapú módszerek általában a “szegmentálás felismeréssel” folyamatot követik, amely először kivonja a szabad formájú régiókat egy képből, és leírja azokat, majd régióalapú osztályozás következik. A teszt idején a régióalapú előrejelzések pixel előrejelzésekké alakulnak át, általában úgy, hogy egy pixelt az azt tartalmazó legmagasabb pontszámú régió szerint címkéznek.
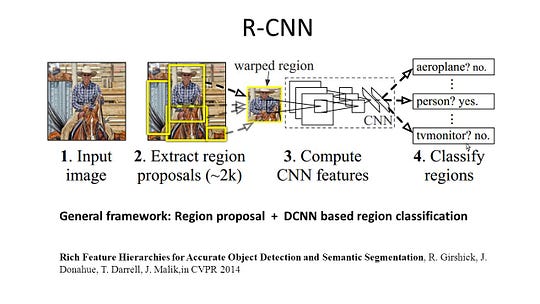
az R-CNN (CNN funkcióval rendelkező régiók) a régióalapú módszerek egyik reprezentatív munkája. A szemantikai szegmentálást az objektumfelismerési eredmények alapján hajtja végre. Pontosabban, az R-CNN először szelektív keresést használ nagy mennyiségű objektumjavaslat kinyerésére, majd kiszámítja mindegyik CNN funkcióját. Végül osztályozza az egyes régiókat az osztályspecifikus lineáris SVMs segítségével. A hagyományos, főleg képosztályozásra szánt CNN struktúrákkal összehasonlítva az R-CNN bonyolultabb feladatokat képes megoldani, mint például az objektumfelismerés és a képszegmentálás, sőt mindkét terület egyik fontos alapjává válik. Sőt, az R-CNN bármilyen CNN benchmark struktúrára építhető, mint például az AlexNet, a VGG, a GoogLeNet és a ResNet.
a képszegmentálási feladathoz az R-CNN 2 típusú funkciót vont ki minden régióhoz: teljes régió funkció és előtér funkció, és úgy találta, hogy jobb teljesítményhez vezethet, ha összekapcsolja őket régió funkcióként. Az R-CNN jelentős teljesítménynövekedést ért el az erősen diszkriminatív CNN funkciók használata miatt. A szegmentálási feladatnak azonban néhány hátránya is van:
- a szolgáltatás nem kompatibilis a szegmentálási feladattal.
- a funkció nem tartalmaz elegendő térinformációt a határ pontos létrehozásához.
- a szegmens alapú javaslatok generálása időt vesz igénybe, és nagyban befolyásolja a végső teljesítményt.
Ezen szűk keresztmetszetek miatt a legújabb kutatásokat javasolták a problémák kezelésére, beleértve az SDS – t, a Hiperoszlopokat, az R-CNN maszkot.
2 — teljesen konvolúciós hálózat alapú szemantikai szegmentálás
az eredeti teljesen konvolúciós hálózat (FCN) megtanulja a leképezést pixelekről pixelekre, a régiójavaslatok kibontása nélkül. Az FCN hálózati csővezeték a klasszikus CNN kiterjesztése. A fő ötlet az, hogy a klasszikus CNN tetszőleges méretű képeket vegyen be bemenetként. A CNN-ek korlátozása, hogy csak meghatározott méretű bemenetekre fogadjanak el és gyártsanak címkéket, a teljesen összekapcsolt, rögzített rétegekből származik. Ellentétben velük, az FCN – ek csak konvolúciós és pooling rétegekkel rendelkeznek, amelyek lehetővé teszik számukra, hogy előrejelzéseket készítsenek tetszőleges méretű bemenetekről.
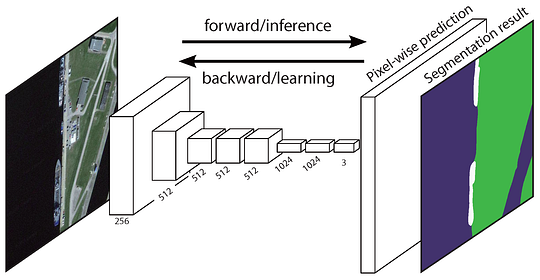
az egyik probléma ebben a konkrét FCN-ben az, hogy több váltakozó konvolúciós és pooling rétegen keresztül történő terjesztéssel a felbontást az FCN a kimeneti funkció térképek le mintavételezett. Ezért az FCN közvetlen előrejelzései általában alacsony felbontásúak, ami viszonylag fuzzy objektumhatárokat eredményez. Számos fejlettebb FCN-alapú megközelítést javasoltak ennek a kérdésnek a kezelésére, beleértve a SegNet-et, a DeepLab-CRF-et és a Dilated Convolutions-t.
3 — gyengén felügyelt szemantikai szegmentálás
a szemantikai szegmentálás releváns módszereinek többsége nagyszámú képre támaszkodik pixel-alapú szegmentációs maszkokkal. Ezeknek a maszkoknak a kézi megjegyzése azonban meglehetősen időigényes, frusztráló és kereskedelmi szempontból drága. Ezért nemrégiben javasoltak néhány gyengén felügyelt módszert, amelyek a szemantikai szegmentáció teljesítésére szolgálnak jegyzetekkel ellátott határoló dobozok felhasználásával.

a Boxsup például a határolódoboz-kommentárokat alkalmazta felügyeletként a hálózat kiképzéséhez és a szemantikai szegmentáláshoz használt becsült maszkok iteratív javításához. A Simple a gyenge felügyeleti korlátozást a bemeneti címke zajának problémájaként kezelte, a rekurzív képzést pedig noising stratégiának tekintette. A pixelszintű címkézés értelmezte a szegmentálási feladatot a többpéldányos tanulási keretrendszeren belül, és hozzáadott egy további réteget, hogy korlátozza a modellt, hogy nagyobb súlyt rendeljen a fontos képpontokhoz a képszintű osztályozáshoz.
szemantikai szegmentálás elvégzése teljesen konvolúciós hálózattal
ebben a szakaszban lépjünk át a szemantikai szegmentálás legnépszerűbb architektúrájának-a teljesen konvolúciós hálónak (FCN)-lépésről lépésre történő megvalósításán. A TensorFlow könyvtár használatával valósítjuk meg a Python 3-ban, más függőségekkel együtt, mint például a Numpy Scipy.In ez a gyakorlat az út képpontjait az FCN használatával jelöljük meg. A Kitti Road adatkészlettel fogunk dolgozni az út / sáv észleléséhez. Ez egy egyszerű gyakorlat az Udacity önvezető autó Nano-szak, amely akkor többet megtudni a beállítás ebben GitHub repo.

itt vannak az FCN architektúra legfontosabb jellemzői:
- az FCN átadja a tudást a vgg16-ból a szemantikai szegmentálás elvégzéséhez.
- a vgg16 teljesen összekapcsolt rétegei teljesen konvolúciós rétegekké alakulnak át, 1×1 konvolúcióval. Ez a folyamat alacsony felbontású osztály jelenlét hőtérképet eredményez.
- ezeknek az alacsony felbontású szemantikai jellemzőtérképeknek a mintavételezése transzponált konvolúciókkal történik (inicializálva bilineáris interpolációs szűrők).
- minden szakaszban a mintavételi folyamat tovább finomodik a durvább, de nagyobb felbontású funkciótérképek hozzáadásával a vgg16 alsó rétegeiből.
- Skip connection kerül bevezetésre minden konvolúciós blokk után, hogy a következő blokk absztraktabb, osztálykiemelkedőbb jellemzőket vonhasson ki a korábban összevont funkciókból.
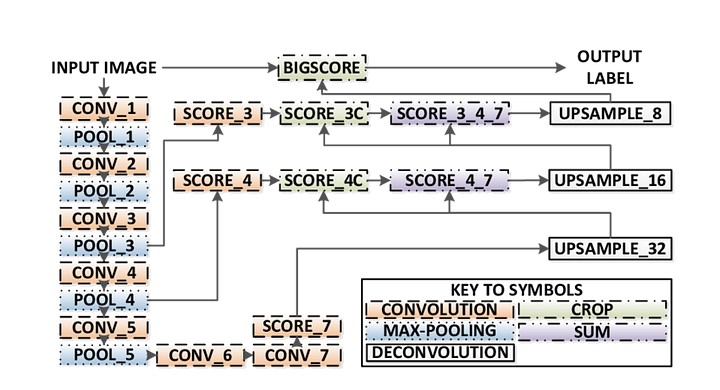
az FCN 3 változata létezik (FCN-32, FCN-16, FCN-8). Az FCN-8-at az alábbiakban részletesen ismertetjük:
- kódoló: egy előre kiképzett VGG16-ot használnak kódolóként. A dekóder a Vgg16 7. rétegéből indul.
- FCN Layer-8: a vgg16 utolsó teljesen összekapcsolt rétegét egy 1×1 konvolúció váltja fel.
- FCN Layer-9: FCN Layer-8 van upsampled 2 alkalommal, hogy megfeleljen méretek réteg 4 A VGG 16, a transzponált konvolúció paraméterekkel: (kernel=(4,4), lépés=(2,2), paddding=’ugyanaz’). Ezt követően a vgg16 4.rétege és az FCN 9. réteg között egy skip kapcsolat jött létre.
- FCN Layer-10: FCN Layer-9 van upsampled 2 alkalommal, hogy megfeleljen méretek réteg 3 Vgg16, a transzponált konvolúció paraméterekkel: (kernel=(4,4), stride=(2,2), paddding=’ugyanaz’). Ezt követően egy skip kapcsolat került hozzáadásra a VGG 3.rétege 16 és az FCN 10. réteg között.
- FCN réteg-11: Az FCN Layer-10-et 4-szer emeljük fel, hogy a méretek illeszkedjenek a bemeneti képmérethez, így megkapjuk a tényleges képet, és a mélység megegyezik az osztályok számával, az átültetett konvolúciót használva a következő paraméterekkel:(kernel=(16,16), stride=(8,8), paddding=’same’).
1.lépés
először az előre betanított VGG-16 modellt töltjük be a TensorFlow-ba. Figyelembe véve a TensorFlow munkamenetet és a VGG mappa elérési útját (amely itt letölthető), visszaadjuk a tenzorok dupláját a VGG modellből, beleértve a képbemenetet, a keep_prob-ot (a lemorzsolódás sebességének szabályozására), a 3.réteget, a 4. réteget és a 7. réteget.
def load_vgg(sess, vgg_path): # load the model and weights model = tf.saved_model.loader.load(sess, , vgg_path) # Get Tensors to be returned from graph graph = tf.get_default_graph() image_input = graph.get_tensor_by_name('image_input:0') keep_prob = graph.get_tensor_by_name('keep_prob:0') layer3 = graph.get_tensor_by_name('layer3_out:0') layer4 = graph.get_tensor_by_name('layer4_out:0') layer7 = graph.get_tensor_by_name('layer7_out:0') return image_input, keep_prob, layer3, layer4, layer7VGG16 funkció
2.lépés
most arra összpontosítunk, hogy létrehozzuk a rétegeket egy FCN számára, a VGG modell tenzorainak felhasználásával. Figyelembe véve a VGG réteg kimenetének tenzorait és az osztályozandó osztályok számát, visszaadjuk a kimenet utolsó rétegének tenzorát. Különösen 1×1-es konvolúciót alkalmazunk a kódoló rétegekre, majd dekóder rétegeket adunk a hálózathoz a kapcsolatok kihagyásával és a mintavételezéssel.
def layers(vgg_layer3_out, vgg_layer4_out, vgg_layer7_out, num_classes): # Use a shorter variable name for simplicity layer3, layer4, layer7 = vgg_layer3_out, vgg_layer4_out, vgg_layer7_out # Apply 1x1 convolution in place of fully connected layer fcn8 = tf.layers.conv2d(layer7, filters=num_classes, kernel_size=1, name="fcn8") # Upsample fcn8 with size depth=(4096?) to match size of layer 4 so that we can add skip connection with 4th layer fcn9 = tf.layers.conv2d_transpose(fcn8, filters=layer4.get_shape().as_list(), kernel_size=4, strides=(2, 2), padding='SAME', name="fcn9") # Add a skip connection between current final layer fcn8 and 4th layer fcn9_skip_connected = tf.add(fcn9, layer4, name="fcn9_plus_vgg_layer4") # Upsample again fcn10 = tf.layers.conv2d_transpose(fcn9_skip_connected, filters=layer3.get_shape().as_list(), kernel_size=4, strides=(2, 2), padding='SAME', name="fcn10_conv2d") # Add skip connection fcn10_skip_connected = tf.add(fcn10, layer3, name="fcn10_plus_vgg_layer3") # Upsample again fcn11 = tf.layers.conv2d_transpose(fcn10_skip_connected, filters=num_classes, kernel_size=16, strides=(8, 8), padding='SAME', name="fcn11") return fcn11rétegek funkció
3.lépés
a következő lépés a neurális hálózat optimalizálása, más néven a TensorFlow veszteségfüggvények és az optimalizáló műveletek kiépítése. Itt a kereszt-entrópiát használjuk veszteségfüggvényként, az Adam-et pedig optimalizálási algoritmusként.
def optimize(nn_last_layer, correct_label, learning_rate, num_classes): # Reshape 4D tensors to 2D, each row represents a pixel, each column a class logits = tf.reshape(nn_last_layer, (-1, num_classes), name="fcn_logits") correct_label_reshaped = tf.reshape(correct_label, (-1, num_classes)) # Calculate distance from actual labels using cross entropy cross_entropy = tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=correct_label_reshaped) # Take mean for total loss loss_op = tf.reduce_mean(cross_entropy, name="fcn_loss") # The model implements this operation to find the weights/parameters that would yield correct pixel labels train_op = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(loss_op, name="fcn_train_op") return logits, train_op, loss_opoptimalizálja a funkciót
4.lépés
itt definiáljuk a train_nn függvényt, amely fontos paramétereket vesz fel, beleértve a korszakok számát, A köteg méretét, a veszteségfüggvényt, az optimalizáló műveletet és a bemeneti képek helyőrzőit, a címkeképeket, a tanulási arányt. A képzési folyamathoz a keep_probability értéket 0,5-re, a learning_rate értéket pedig 0,001-re állítjuk. Az előrehaladás nyomon követése érdekében az edzés során kinyomtatjuk a veszteséget is.
def train_nn(sess, epochs, batch_size, get_batches_fn, train_op, cross_entropy_loss, input_image, correct_label, keep_prob, learning_rate): keep_prob_value = 0.5 learning_rate_value = 0.001 for epoch in range(epochs): # Create function to get batches total_loss = 0 for X_batch, gt_batch in get_batches_fn(batch_size): loss, _ = sess.run(, feed_dict={input_image: X_batch, correct_label: gt_batch, keep_prob: keep_prob_value, learning_rate:learning_rate_value}) total_loss += loss; print("EPOCH {} ...".format(epoch + 1)) print("Loss = {:.3f}".format(total_loss)) print()5. lépés
Végül itt az ideje, hogy kiképezzük a hálónkat! Ebben a run függvényben először a load_vgg, layers, and optimize függvényt használjuk. Ezután a train_nn függvény segítségével kiképezzük a hálót, és elmentjük a következtetési adatokat a rekordokhoz.
def run(): # Download pretrained vgg model helper.maybe_download_pretrained_vgg(data_dir) # A function to get batches get_batches_fn = helper.gen_batch_function(training_dir, image_shape) with tf.Session() as session: # Returns the three layers, keep probability and input layer from the vgg architecture image_input, keep_prob, layer3, layer4, layer7 = load_vgg(session, vgg_path) # The resulting network architecture from adding a decoder on top of the given vgg model model_output = layers(layer3, layer4, layer7, num_classes) # Returns the output logits, training operation and cost operation to be used # - logits: each row represents a pixel, each column a class # - train_op: function used to get the right parameters to the model to correctly label the pixels # - cross_entropy_loss: function outputting the cost which we are minimizing, lower cost should yield higher accuracy logits, train_op, cross_entropy_loss = optimize(model_output, correct_label, learning_rate, num_classes) # Initialize all variables session.run(tf.global_variables_initializer()) session.run(tf.local_variables_initializer()) print("Model build successful, starting training") # Train the neural network train_nn(session, EPOCHS, BATCH_SIZE, get_batches_fn, train_op, cross_entropy_loss, image_input, correct_label, keep_prob, learning_rate) # Run the model with the test images and save each painted output image (roads painted green) helper.save_inference_samples(runs_dir, data_dir, session, image_shape, logits, keep_prob, image_input)függvény futtatása
paramétereink közül az epochs = 40, batch_size = 16, num_classes = 2 és image_shape = (160, 576) lehetőséget választjuk. Miután 2 próbát végzett a dropout = 0,5 és a dropout = 0,75 értékkel, azt találtuk, hogy a 2.próba jobb eredményeket eredményez jobb átlagos veszteségekkel.

a teljes kód megtekintéséhez nézze meg ezt a linket: https://gist.github.com/khanhnamle1994/e2ff59ddca93c0205ac4e566d40b5e88
Ha tetszett ez a darab, szeretném megosztani és terjeszteni a tudást.
lehet, hogy érdekel a legújabb hozzászólás:
- AWS Textract
- adatok kinyerése
kezdje el használni Nanonetek automatizálási
próbálja ki a modellt, vagy kérjen demo még ma!
próbálja ki most
