Pap-smear analysis tool (pat) a méhnyakrák pap-smear images-ből történő kimutatására
képelemzés
Az ebben a cikkben bemutatott pap-smear analysis tool kifejlesztésére szolgáló képelemzési csővezeték a Pap-smear analysis tool kifejlesztésére a Pap-Smear Analysis tool a méhnyakrák pap-kenetekből történő kimutatására az ábrán látható. 1.

a méhnyakrák kimutatásának megközelítése pap-kenet képek alapján
Képgyűjtés
a megközelítést három módszerrel értékelték adathalmazok. Adatkészlet 1 áll 917 egyetlen sejt Harlev pap-kenet képek által készített Jantzen et al. . Az adatkészlet olyan pap-kenet képeket tartalmaz, amelyeket képzett citopatológusok készítettek 0,201 Ft / pixel felbontással, mikroszkóp segítségével, amely egy keretfogóhoz van csatlakoztatva. A képeket a CHAMP kereskedelmi szoftver segítségével szegmentáltuk, majd hét osztályba soroltuk, amelyek különböző jellemzőkkel rendelkeznek, a 2.táblázat szerint. Ebből 200 képet használtak edzésre, 717 képet pedig tesztelésre.
a 2. adatkészlet 497 teljes diapap-kenet képet tartalmaz, amelyeket Norup et al. . Ebből 200 képet használtak edzésre, 297 képet pedig tesztelésre. Továbbá az osztályozó teljesítményét A Mbarara Regional Referral Hospital-tól (MRRH) kapott 60 pap-kenet (30 normál és 30 rendellenes) mintájának 3.Adatkészletén értékelték. A mintákat Olympus BX51 fénymezős mikroszkóppal készítették, amely 40 db 6,95 NA objektívvel és Hamamatsu ORCA-05G 1,4 Mpx monokróm kamerával volt felszerelve, így 0,25 megapixeles képpontméretet kapott, 8 bites szürke mélységgel. Ezután minden képet 300 területre osztottak, mindegyik terület 200-400 sejtet tartalmazott. A citopatológusok véleménye alapján 10 000 tárgyat választottak ki a 60 különböző pap-kenet tárgylemezből származó képeken, amelyek közül 8000 szabadon fekvő nyaki hámsejt volt (3000 normál sejt normál kenetből és 5000 abnormális sejt abnormális kenetből), a fennmaradó 2000 pedig törmelék tárgy volt. Ezt a pap-kenet szegmentációt kiképezhető Weka szegmentációs eszköztár segítségével értük el egy pixel szintű szegmentációs osztályozó felépítéséhez.
Képjavítás
kontraszt lokális adaptív hisztogram-kiegyenlítést (CLAHE) alkalmaztak a szürkeárnyalatos képre a képjavítás érdekében . CLAHE-ban a clip-limit kiválasztása, amely meghatározza a kép hisztogramjának kívánt alakját, a legfontosabb, mivel kritikusan befolyásolja a továbbfejlesztett kép minőségét. A clip-limit optimális értékét empirikusan választottuk ki a Joseph et al. . Az optimális klip határérték 2.A 0-t úgy határozták meg, hogy megfelelő legyen a megfelelő képjavítás biztosításához, miközben megőrzi a használt adatkészletek sötét tulajdonságait. A szürkeárnyalatos konverziót az EQ használatával megvalósított szürkeárnyalatos technikával értük el. 1 meghatározása szerint .
ahol R = piros, G = zöld és B = kék szín hozzájárulások az új képhez.
a CLAHE alkalmazása a képjavításhoz észrevehető változásokat eredményezett a képekben a képintenzitás beállításával, ahol a mag sötétedése, valamint a citoplazma határai könnyen azonosíthatóvá váltak a 2,0-es kliphatár segítségével.
jelenet szegmentálás
a jelenet szegmentálásának eléréséhez egy pixel szintű osztályozót fejlesztettek ki a Trainable WEKA Szegmentation (TWS) eszközkészlet használatával. A pap-kenetben megfigyelt sejtek többsége nem meglepő módon nyaki hámsejtek . Ezenkívül a leukociták, eritrociták és baktériumok változó száma általában nyilvánvaló, míg más szennyező sejtek és mikroorganizmusok kis száma néha megfigyelhető. A pap-kenet azonban négy fő típusú laphámsejtet tartalmaz—felületes, köztes, parabasalis és bazális—, amelyek felületes és köztes sejtek képviselik a túlnyomó többséget egy hagyományos kenetben; ezért ezt a két típust általában a hagyományos pap-kenet elemzéshez használják . A tanulható WEKA szegmentációt használták a dián lévő különböző objektumok azonosítására és szegmentálására. Ebben a szakaszban egy pixel szintű osztályozót képeztek ki a sejtmagokra, a citoplazmára, a háttér-és törmelékazonosításra egy képzett citopatológus segítségével, a Trainable Weka Szegmentation (TWS) eszköztár segítségével . Ezt úgy érjük el, hogy vonalakat rajzolunk/kiválasztunk az érdeklődési területeken keresztül, és hozzárendeljük őket egy adott osztályhoz. A vonalak/szelekció alatti pixeleket a magok, a citoplazma, a háttér és a törmelék reprezentatívjának vettük.
az egyes osztályokon belül rajzolt körvonalakat egy jellemző vektor, \(\mathop F\limits^{ \to }\) generálására használták, amelyet az egyes körvonalakhoz tartozó pixelek számából származtattak. Az egyes képek jellemző vektorát (200 az 1. adatkészletből és 200 a 2.adatkészletből) az Eq határozta meg. 2.
ahol Ni, Ci, Bi és Di a kép magjából, citoplazmájából, hátteréből és törmelékéből származó pixelek száma \(i\) Az ábrán látható módon. 2.

a funkcióvektor generálása a képzési képekből
a képből kivont minden pixel nem csak az intenzitását képviseli, hanem egy olyan képjellemzőt is, amely sok információ, beleértve a textúrát, a szegélyeket és a színt egy 0,201 6m2 pixelterületen belül. Az osztályozó képzéséhez megfelelő jellemzővektor kiválasztása nagy kihívás és új feladat volt a javasolt megközelítésben. A pixel szintű osztályozót a TWS összesen 226 képzési funkciójának felhasználásával képezték ki. Az osztályozót egy sor TWS képzési funkcióval képezték ki, amelyek a következőket tartalmazták: I. zajcsökkentés: a TWS eszköztár Kuwahara és bilaterális szűrőit használták az osztályozó zajeltávolításra való kiképzéséhez. Ezek a jelentések szerint kiváló szűrők a zaj eltávolítására, miközben megőrzik az éleket , (ii) Élérzékelés: egy Sobel szűrőt, Hessian matrix és Gábor szűrőt használtak az osztályozó képzésére a képen a határérzékelésről, valamint (iii) textúra szűrés: A textúraszűréshez az átlag, a variancia, a medián, a maximum, a minimum és az entrópia szűrőket használtuk.
törmelék eltávolítása
a meglévő automatizált pap-kenet elemző rendszerek jelenlegi korlátainak fő oka az, hogy küzdenek a pap-kenet struktúrák összetettségének leküzdésével, megpróbálva elemezni a diát egészében, amelyek gyakran több sejtet és törmeléket tartalmaznak. Ez az algoritmus meghibásodását okozhatja, és nagyobb számítási teljesítményt igényel . A mintákat olyan tárgyak borítják—mint a vérsejtek, az átfedő és hajtogatott sejtek, valamint a baktériumok, amelyek akadályozzák a szegmentációs folyamatokat és nagyszámú gyanús tárgyat generálnak. Kimutatták, hogy a normál sejtek és a rák előtti sejtek megkülönböztetésére tervezett osztályozók általában kiszámíthatatlan eredményeket hoznak, amikor a pap-kenetben műtárgyak vannak . Ebben az eszközben egy technika a méhnyak sejtek azonosítására háromfázisú szekvenciális eliminációs séma alkalmazásával (ábrán látható. 3) használják.

háromfázisú szekvenciális eliminációs megközelítés a törmelék elutasításához
a javasolt háromfázisú eliminációs séma egymás után eltávolítja a törmeléket a pap-kenetből, ha figyelembe vesszük nem valószínű, hogy méhnyaksejt. Ez a megközelítés előnyös, mivel lehetővé teszi egy alacsonyabb dimenziós döntés meghozatalát minden szakaszban.
Méretelemzés
A Méretelemzés a részecskék méretmérési tartományának meghatározására szolgáló eljárások összessége . A terület az egyik legalapvetőbb jellemző, amelyet az automatizált citológia területén használnak a sejtek törmeléktől való elválasztására. A pap-kenet elemzés jól tanulmányozott terület, sok előzetes ismerettel a sejtek tulajdonságairól . A magterület értékelésének egyik legfontosabb változása azonban az, hogy a rákos sejtek jelentősen megnövelik a nukleáris méretet . Ezért egy olyan felső méretküszöb meghatározása, amely nem zárja ki szisztematikusan a diagnosztikai sejteket, sokkal nehezebb, de előnye, hogy csökkenti a keresési helyet. Az ebben a tanulmányban bemutatott módszer a nyaki sejtek alsó és felső méretküszöbén alapul. A megközelítés álkódját az Eq mutatja. 3.
hol \(area_{max} = 85,267\,{\upmu \text{m}}^{2}\) és \(Area_{min} = 625\,{\upmu \text{m}}^{2}\) a 2.táblázatból származik.
a háttérben lévő tárgyak törmeléknek tekintendők, így a képről eldobhatók. A \(area_{min}\) és \(Area_{max}\) közé eső részecskéket tovább elemezzük a textúra és az alakelemzés következő szakaszaiban.
Alakelemzés
a pap-kenetben lévő tárgyak alakja kulcsfontosságú a sejtek és a törmelék megkülönböztetésében . Számos módszer létezik az alak leírására, és ezek közé tartoznak a régió alapú és a kontúr alapú megközelítések . A régióalapú módszerek kevésbé érzékenyek a zajra, de számítási szempontból intenzívebbek, míg a kontúralapú módszerek viszonylag hatékonyan kiszámíthatók, de érzékenyebbek a zajra . Ebben a cikkben egy régióalapú módszert (perimeter2/area (P2A)) alkalmaztak . A P2A leírót az érdeme alapján választották ki, hogy leírja az objektum hasonlóságát egy körhöz. Ez jól alkalmazható sejtmag-leíróként, mivel a magok megjelenése általában kör alakú. A P2A-t alakkompaktságnak is nevezik, és az Eq határozza meg. 4.
ahol c az alak tömörségének értéke, A A terület, p pedig a mag kerülete. A törmeléket feltételezték, hogy olyan tárgyak, amelyek P2A értéke nagyobb, mint 0,97 vagy kevesebb, mint 0,15 a képzési jellemzők szerint (a 2.táblázatban ábrázolva).
Textúraelemzés
a textúra egy nagyon fontos jellemző tulajdonság, amely különbséget tud tenni a magok és a törmelék között. A kép textúrája olyan mérőszámok halmaza, amelyek célja a kép észlelt textúrájának számszerűsítése . A pap-keneten belül az átlagos nukleáris folt intenzitásának eloszlása sokkal szűkebb, mint a folt intenzitásának változása a törmelék tárgyak között . Ezt a tényt használták alapul a törmelék eltávolításához a képintenzitás és a színinformáció alapján a Zernike moments (ZM) segítségével . Zernike moments használják a különböző mintafelismerő alkalmazások és ismert, hogy robusztus tekintetében a zaj és a jó rekonstrukciós teljesítmény. Ebben a munkában, a ZM által bemutatott Malm et al. rend n ismétléssel I függvény \(F\bal ({r, \theta}\ jobb)\), polárkoordinátákban egy lemezen belül, négyzet alakú kép közepén\(i \bal( {x, y}\ jobb)\) méretű \(m\ szor m\) által megadott EQ. 5 használták.
\(v_{nl }^{*} \left( {r,\Theta } \right)\) a Zernike polinom komplex konjugátumát jelöli \(V_{NL} \left( {r,\Theta } \right)\). A textúramérés előállításához a textúrakép minden pixelére központosított \(a_{nl}\) nagyságát átlagoljuk .
Funkciókivonás
egy osztályozási algoritmus sikere nagyban függ a képből kinyert funkciók helyességétől. A felhasznált adatkészletben lévő pap-kenetek sejtjeit hét osztályba sorolják olyan jellemzők alapján, mint a mag és a citoplazma mérete, területe, alakja és fényessége. A képekből kivont funkciók közé tartoztak a mások által korábban használt morfológiai jellemzők . Ebben a tanulmányban három geometriai jellemzőt (szilárdság, tömörség és excentricitás) és hat szöveges jellemzőt (átlag, szórás, variancia, simaság, energia és entrópia) is kivontunk a magból, ami összesen 29 jellemzőt eredményezett, amint azt a 3.táblázat mutatja.
Funkcióválasztás
a Funkcióválasztás a kibontott funkciók részhalmazainak kiválasztásának folyamata, amelyek a legjobb osztályozási eredményeket adják. A kinyert funkciók közül egyesek zajt tartalmazhatnak, míg a kiválasztott osztályozó nem használhat másokat. Ezért meg kell határozni a funkciók optimális készletét, esetleg az összes kombináció kipróbálásával. Ha azonban sok jellemző van, a lehetséges kombinációk száma felrobban, ami növeli az algoritmus számítási összetettségét. A funkcióválasztó algoritmusokat széles körben a szűrő, a wrapper és a beágyazott módszerek közé sorolják .
az eszköz által alkalmazott módszer kombinálja a szimulált lágyítást egy burkoló megközelítéssel. Ezt a megközelítést a but-ban javasolták, ezen a papíron, a funkcióválasztás teljesítményét kettős stratégiai véletlenszerű erdő algoritmus segítségével értékelik . A szimulált lágyítás egy valószínűségi technika egy adott funkció globális optimumának közelítésére. A megközelítés alkalmas annak biztosítására, hogy az optimális funkciókészlet legyen kiválasztva. Az optimális készlet keresését egy fitnesz érték vezérli . Amikor a szimulált lágyítás befejeződött, a funkciók összes különböző részhalmazát összehasonlítják, és kiválasztják a legmegfelelőbbet (vagyis azt, amelyik a legjobban teljesít). A fitneszérték-keresést egy burkolóval kaptuk, ahol k-szeres keresztellenőrzést használtunk az osztályozási algoritmus hibájának kiszámításához. A kivont tulajdonságokból különböző kombinációkat készítenek, értékelnek és összehasonlítanak más kombinációkkal. A prediktív modellt ezután a funkciók kombinációjának értékelésére és a modell pontosságán alapuló pontszám hozzárendelésére használják. A wrapper által megadott fitnesz hibát a szimulált lágyítási algoritmus használja fitnesz hibaként. Egy fuzzy C-means algoritmust csomagoltunk egy fekete dobozba, amelyből becsült hibát kaptunk a különféle funkciókombinációkhoz, az ábrán látható módon. 4.

a fuzzy C-means egy fekete dobozba van csomagolva, amelyből becsült hiba keletkezik
a Fuzzy C-means lehetővé teszi az adatpontokat a az adatkészlet az összes klaszterhez tartozik, tagságokkal az intervallumban (0-1), az EQ szerint. 6.
ahol \(m_{ik}\) a K adatpont tagsága az i klaszterközponthoz, \(d_{jk}\) a J klaszterközponttól a k adatpontig terjedő távolság, q pedig egy kitevő, amely eldönti, hogy milyen erősnek kell lennie a tagságnak. A fuzzy C-means algoritmust a MATLAB fuzzy eszköztárával valósítottuk meg.
A defuzzifikáció
a fuzzy C-means algoritmus nem mondja meg nekünk, hogy a klaszterek milyen információkat tartalmaznak, és hogyan kell ezeket az információkat felhasználni az osztályozáshoz. Meghatározza azonban, hogy az adatpontok hogyan vannak hozzárendelve a különböző klaszterek tagságához, és ezt a fuzzy tagságot használják az adatpontok osztályának előrejelzésére . Ezt a defuzzifikáció révén lehet legyőzni. Számos defuzzifikációs módszer létezik . Ebben az eszközben azonban minden fürt fuzzy tagsággal rendelkezik (0-1) a kép összes osztályából. A képzési adatokat a legközelebbi klaszterhez rendelik. Az a klaszterhez tartozó egyes osztályok képzési adatainak százalékos aránya adja meg a klaszter tagságát, az a klaszter = a különböző osztályokhoz, ahol i az A és j klaszter elszigetelése a másik klaszterben. Az intenzitás mértéke hozzáadódik az egyes klaszterek tagsági függvényéhez egy fuzzy fürtözési defuzzifikációs algoritmus segítségével. A fuzzy partíció defuzzifikációjának népszerű megközelítése a maximális tagsági fok elve ahol az adatpont k osztályhoz van rendelve m csak akkor, ha a tagsági foka \(m_{IK}\) az I klaszterhez, a legnagyobb. Chuang et al. javasolt minden adatpont tagsági állapotának módosítása a szomszédok tagsági állapotának felhasználásával.
a javasolt megközelítésben a bayesi valószínűségen alapuló defuzzifikációs módszert használják a tagsági függvény valószínűségi modelljének létrehozására minden adatponthoz, és a modellt a képre alkalmazzák az osztályozási információ előállításához. A valószínűségi modell kiszámítása az alábbiak szerint történik:
-
konvertálja a partíciós mátrix (klaszterek) valószínűségi eloszlásokká.
-
az adateloszlások valószínűségi modelljének felépítése, mint a .
-
alkalmazza a modellt az osztályozási információk előállításához minden adatponthoz az Eq használatával. 7.
ahol \(p\bal( {a_{i} } \jobb),i = 0 \ldots .c\) a \(a_{i}\) előzetes valószínűsége, amely kiszámítható a módszerrel, ahol az előzetes valószínűség mindig arányos az egyes osztályok tömegével.
a használandó klaszterek számát úgy határoztuk meg, hogy a beépített modell a lehető legjobb módon tudja leírni az adatokat. Ha túl sok klasztert választanak, akkor fennáll annak a veszélye, hogy az adatokban a zaj túlcsordul. Ha túl kevés klasztert választanak, akkor rossz osztályozó lehet az eredmény. Ezért elvégeztük a klaszterek számának elemzését a keresztellenőrzési teszt hibájával szemben. Az optimális 25 klaszterszámot sikerült elérni, és a túlképzés ezen klaszterek száma felett történt. A defuzzifikáció kitevője 1.A 0930-at 25 klaszterrel, tízszeres keresztellenőrzéssel és 60 ismétléssel szereztük be, és a funkcióválasztás alkalmassági hibájának kiszámításához használták, ahol az osztályozó felépítéséhez összesen 18 jellemzőt választottak ki a 29 jellemzőből. A kiválasztott jellemzők a következők voltak: magterület; magszürke szint; mag legrövidebb átmérője; mag leghosszabb; mag kerülete; maximák a magban; minimumok a magban; citoplazma területe; citoplazma szürke szintje; citoplazma kerülete; mag-citoplazma arány; mag excentricitása, mag szórása, magszürke szint variancia; magszürke szintű entrópia; nucleus relatív pozíció; nucleus gray szint átlag és nucleus gray értékek energia.
osztályozás értékelése
ebben a tanulmányban a fryback és Thornbury által javasolt diagnosztikai képalkotó rendszerek hatékonyságának hierarchikus modelljét fogadták el vezérelvként az eszköz értékeléséhez, amint azt a 4.táblázat mutatja.
az érzékenység a tényleges pozitívumok arányát méri, amelyeket helyesen azonosítottak, míg a specifitás a tényleges negatívok arányát méri, amelyeket helyesen azonosítottak. Az érzékenységet és a specifitást az Eq írja le. 8.
ahol TP = igaz pozitív, FN = hamis negatív, TN = igaz negatív és FP = hamis pozitív.
GUI tervezés és integráció
a fent leírt képfeldolgozási módszerek a Matlab-ban valósultak meg, és az ábrán látható Java grafikus felhasználói felületen (GUI) keresztül kerülnek végrehajtásra. 5. Az eszköz rendelkezik egy panellel, ahol egy pap-kenet kép van betöltve, és a citotechnikus kiválasztja a megfelelő módszert a jelenet szegmentálásához (a TWS osztályozó alapján), a törmelék eltávolításához (a három egymást követő eliminációs megközelítés alapján) és a határérzékeléshez (ha szükséges, a Canny edge detection módszerrel), amely után a funkciók kivonása a extract features gomb segítségével történik.
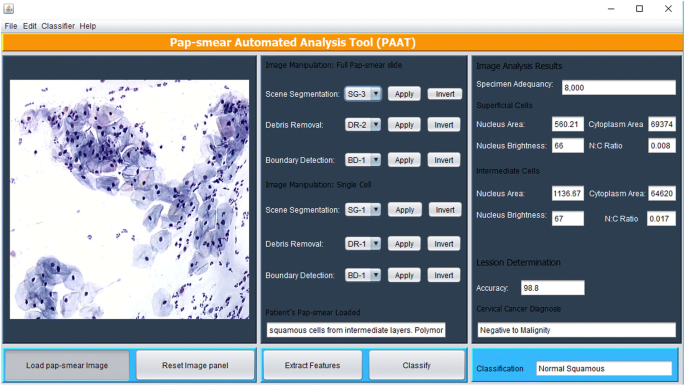
PAT grafikus felhasználói felület
az eszköz a pap-kenet segítségével elemzi a törmelék eltávolítása után megmaradt összes objektumot. A funkcióválasztásban leírt 18 tulajdonságot minden objektumból kivonjuk, és az egyes cellák osztályozására használjuk az osztályozási módszerben leírt fuzzy C-means algoritmus segítségével. Véletlenszerűen egy felületes cella és egy köztes cella extrahált jellemzői jelennek meg a képelemzési eredmények panelen. A funkciók kinyerése után a citotechnikus (felhasználó) megnyomja az osztályozás gombot, és az eszköz diagnózist bocsát ki (pozitív vagy negatív rosszindulatú), és a diagnózist a méhnyakrák 7 osztályának/szakaszának egyikébe sorolja a képzési adatkészlet szerint.