Reading Code Right, With Some Help From The Lexer
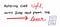
Software is all about logic. Programozás szerzett hírnevét, hogy egy olyan területen, amely nehéz a matematikai és őrült egyenletek. Úgy tűnik, hogy a számítástechnika áll ennek a tévhitnek a középpontjában.
persze, van némi matematika és vannak képletek — de egyikünknek sem kell PhD-vel rendelkeznie a kalkulusból, hogy megértsük, hogyan működnek a gépeink! Valójában sok olyan szabály és paradigma, amelyet a kódírás során megtanulunk, ugyanazok a szabályok és paradigmák, amelyek a komplex számítástechnikai fogalmakra vonatkoznak. És néha, ezek az ötletek valójában a számítástechnikából származnak, és mi csak soha nem tudtunk róla.
függetlenül attól, hogy milyen programozási nyelvet használunk, amikor a legtöbbünk írja a kódot, arra törekszünk, hogy különböző dolgokat osztályokba, objektumokba vagy módszerekbe foglaljunk, szándékosan elválasztva a kódunk különböző részeit. Más szavakkal, tudjuk, hogy általában jó dolog úgy felosztani a kódunkat, hogy egy osztály, objektum vagy módszer csak egyetlen dologgal foglalkozik és felelős. Ha ezt nem tesszük meg, a dolgok szuper rendetlenné válhatnak, és összefonódhatnak egy rendetlen hálóval. Néha ez még mindig megtörténik, még az aggodalmak szétválasztásával is.
mint kiderült, számítógépeink belső működése is nagyon hasonló tervezési paradigmákat követ. Fordítóinknak például különböző részei vannak, és mindegyik rész felelős a fordítási folyamat egy adott részének kezeléséért. Találkoztunk egy kicsit ezzel a múlt héten, amikor megtudtuk az elemzőt, amely felelős az elemzési fák létrehozásáért. De az elemzőt nem lehet mindennel megbízni.
az elemzőnek szüksége van egy kis segítségre a haverjaitól, és végre itt az ideje, hogy megtudjuk, kik ők!
amikor nemrég megtudtuk az elemzést, belemártottuk a lábujjainkat a nyelvtanba, a szintaxisba, és hogy a fordító hogyan reagál és reagál ezekre a dolgokra egy programozási nyelven belül. De soha nem emeltük ki, hogy pontosan mi a fordító! Ahogy belépünk a fordítási folyamat belső működésébe, sokat fogunk tanulni a fordítóprogram tervezéséről, ezért létfontosságú számunkra, hogy megértsük, miről is beszélünk itt pontosan.
a fordítók félelmetesnek tűnhetnek, de a munkájuk valójában nem túl bonyolult ahhoz, hogy megértsük — különösen akkor, ha a complier különböző részeit harapásméretű részekre bontjuk.
de először kezdjük a lehető legegyszerűbb meghatározással. A fordító olyan program, amely elolvassa a kódunkat (vagy bármilyen kódot, bármilyen programozási nyelven), és lefordítja egy másik nyelvre.

ordító: definíció.
Általánosságban elmondható, hogy a fordító valójában csak egy magas szintű nyelvről fordít le kódot egy alacsonyabb szintű nyelvre. Az alacsonyabb szintű nyelveket, amelyekre a fordító lefordítja a kódot, gyakran összeszerelési kódnak, gépi kódnak vagy tárgykódnak nevezik. Érdemes megemlíteni, hogy a legtöbb programozó nem igazán foglalkozik gépi kóddal vagy írással; inkább a fordítótól függünk, hogy a programjainkat gépi kódra fordítsuk, ami a számítógépünk futtatható programként fog futni.
a fordítókra úgy gondolhatunk, mint a közvetítőre köztünk, a programozók és a számítógépeink között, amelyek csak futtatható programokat futtathatnak alacsonyabb szintű nyelveken.
a fordító a gépeink által érthető és végrehajtható módon fordítja le azt, amit meg akarunk valósítani.
a fordító nélkül gépi kód írásával kénytelenek lennénk kommunikálni a számítógépeinkkel, ami hihetetlenül olvashatatlan és nehezen megfejthető. A gépi kód gyakran csak úgy néz ki, mint egy csomó 0 és 1 az emberi szem számára — ez mind bináris, emlékszel? – ami miatt nagyon nehéz olvasni, írni és hibakeresni. A fordító elvonta a gépi kódot számunkra, mint programozóknak, mert nagyon megkönnyítette számunkra, hogy ne gondoljunk a gépi kódra, és sokkal elegánsabb, tisztább és könnyen olvasható nyelveken írjunk programokat.
a következő hetekben egyre többet fogunk kicsomagolni a titokzatos fordítóról, ami remélhetőleg kevésbé lesz enigma a folyamatban. De most térjünk vissza a kérdésre: melyek a fordító lehető legegyszerűbb részei?
minden fordító, függetlenül attól, hogy hogyan lehet megtervezni, különböző fázisokkal rendelkezik. Ezek a fázisok különböztetik meg a fordító egyedi részeit.

a fordítási kalandok egyik fázisával már találkoztunk, amikor nemrég megismertük az elemző és elemző fákat. Tudjuk, hogy az elemzés az a folyamat, amely valamilyen bemenetet vesz fel, és egy elemzési fát épít ki belőle, amelyet néha az elemzés aktusának neveznek. Mint kiderült, az elemzés munkája a fordítási folyamat szintaxis-elemzésnek nevezett szakaszára jellemző.
az elemző azonban nem csak a semmiből épít elemzési fát. Van némi segítség! Emlékeztetünk arra, hogy az elemző kap néhány tokent (más néven terminálokat), és ezekből a Tokenekből elemzési fát épít. De honnan szerzi ezeket a tokeneket? Az elemző szerencséjére nem kell vákuumban működnie; ehelyett van némi segítség.
ezzel eljutunk a fordítási folyamat egy másik szakaszához, amely a szintaxis elemzési szakasz előtt áll: a lexikális elemzési szakasz.

a”lexikális “kifejezés egy szó jelentésére utal, elkülönítve az azt tartalmazó mondattól, függetlenül annak nyelvtani kontextusától. Ha kizárólag ezen definíció alapján próbáljuk kitalálni saját jelentésünket, akkor feltételezhetjük, hogy a lexikális elemzési szakasznak köze van a program egyes szavaihoz/kifejezéseihez, és semmi köze a szavakat tartalmazó mondat nyelvtanához vagy jelentéséhez.
a lexikális elemzési szakasz a fordítási folyamat első lépése. Nem ismeri vagy érdekli egy mondat nyelvtanát, vagy egy szöveg vagy program jelentését; csak maguknak a szavaknak a jelentését ismeri.
lexikális elemzésnek kell történnie, mielőtt a forrásprogram bármely kódját elemezni lehet. Mielőtt az elemző elolvashatja, a programot először be kell szkennelni, fel kell osztani és bizonyos módon csoportosítani.
amikor a múlt héten elkezdtük vizsgálni a szintaxis elemzési fázist, megtudtuk, hogy az elemzési fa úgy épül fel, hogy a mondat egyes részeit megvizsgáljuk, és a kifejezéseket egyszerűbb részekre bontjuk. De a lexikai elemzés szakaszában a fordító nem ismeri vagy nem fér hozzá ezekhez az “egyes részekhez”. Inkább először be kell azonosítania és meg kell találnia őket, majd el kell végeznie azt a munkát, hogy a szöveget külön-külön darabokra bontsa.
amikor például Shakespeare-től olvasunk egy olyan mondatot, mint a To sleep, perchance to dream., akkor tudjuk, hogy a szóközök és az írásjelek elválasztják a mondat “szavait”. Ez természetesen azért van, mert arra képeztek ki minket, hogy olvassunk egy mondatot, “lex”, és elemezzük a nyelvtan szempontjából.
de egy fordító számára ugyanaz a mondat így nézhet ki, amikor először olvassa: Tosleepperhachancetodream. Amikor elolvassuk ezt a mondatot, egy kicsit nehezebb számunkra meghatározni, hogy mi a tényleges “szavak”! Biztos vagyok benne, hogy a fordítónk is így érez.
tehát hogyan kezeli a gépünk ezt a problémát? Nos, a fordítási folyamat lexikális elemzési szakaszában mindig két fontos dolgot csinál: beolvassa a kódot, majd kiértékeli.

a két lépés a lexikai elemzési folyamatról!
a szkennelés és az értékelés munkája néha egyetlen programba tömöríthető, vagy lehet két különálló program, amelyek egymástól függenek; valójában csak az a kérdés, hogy miként tervezték meg bármelyik complier-t. A program a fordító, amely felelős a munkát a szkennelés és értékelése gyakran nevezik a lexer vagy a tokenizer, és a teljes lexikális elemzés fázis néha a folyamat lexing vagy tokenizing.
beolvasni, esetleg olvasni
a lexikai elemzés két alapvető lépése közül az első a szkennelés. Úgy gondolhatunk a szkennelésre, mint valamilyen bemeneti szöveg “olvasására”. Ne feledje, hogy ez a beviteli szöveg lehet karakterlánc, mondat, kifejezés vagy akár egy teljes program! Nem igazán számít, mert a folyamat ezen szakaszában ez csak egy hatalmas karakterfolt, amely még nem jelent semmit, és egy összefüggő darab.
nézzünk meg egy példát, hogy pontosan hogyan történik ez. Az eredeti mondatunkat fogjuk használni, To sleep, perchance to dream., amely a forrásszövegünk vagy forráskódunk. A fordítónk számára ez a forrásszöveg bemeneti szövegként lesz olvasható, amely úgy néz ki, mint Tosleep,perchancetodream., amely csak egy karakterlánc, amelyet még meg kell fejteni.

az első dolog, amit a fordítónknak meg kell tennie, valójában fel kell osztania a szövegfoltot a lehető legkisebb darabokra, ami sokkal könnyebbé teszi annak azonosítását, hogy a szövegfoltban lévő szavak valójában hol vannak.
a legegyszerűbb módja annak, hogy egy hatalmas szövegdarabot fel lehessen meríteni, ha lassan és szisztematikusan olvassuk, egyszerre egy karaktert. Pontosan ezt teszi a fordító.
a szkennelési folyamatot gyakran egy külön program, a szkenner kezeli, amelynek egyetlen feladata egy forrásfájl/szöveg olvasása, egyszerre egy karakter. Szkennerünk számára nem igazán számít, mekkora a szövegünk; csak akkor fog látni, amikor “elolvassa” a fájlunkat, egyszerre egy karakter.
itt van, amit a Shakespeare mondat lenne olvasni, mint a mi szkenner:

olyamat, 2.lépés.
észre fogjuk venni, hogy a To sleep, perchance to dream. szkennerünk egyedi karakterekre osztotta. Ezenkívül még a szavak közötti szóközöket is karakterként kezelik, csakúgy, mint a mondatunkban szereplő írásjeleket. Van egy karakter is a sorozat végén, ami különösen érdekes: eof. Ez a “fájl vége” karakter, és hasonló a tabspace és newlinekarakterhez. Mivel a forrásszövegünk csak egyetlen mondat, amikor a szkennerünk a fájl végére ér (ebben az esetben a mondat végére), beolvassa a fájl végét, és karakterként kezeli.
tehát valójában, amikor a szkenner elolvasta a bemeneti szöveget, egyedi karakterekként értelmezte, ami ezt eredményezte: .

most, hogy a szkenner elolvasta és felosztotta a forrásszöveget a lehető legkisebb részekre, sokkal könnyebb lesz kitalálni a mondatban szereplő “szavakat”.
ezután a szkennernek meg kell vizsgálnia a felosztott karaktereket sorrendben, és meg kell határoznia, hogy mely karakterek részei egy szónak, és melyek nem. A szkenner által olvasott minden karakternél megjelöli azt a vonalat és helyet, ahol a karakter megtalálható a forrásszövegben.
az itt látható kép illusztrálja ezt a folyamatot Shakespeare-mondatunkhoz. Láthatjuk, hogy a szkennerünk a mondat minden egyes karakterének vonalát és oszlopát jelöli. A vonal – és oszlopábrázolást úgy tekinthetjük, mint egy mátrixot vagy karaktertömböt.
emlékezzünk arra, hogy mivel a fájlunkban csak egyetlen sor van, minden a0sorban él. Azonban, ahogy végigjárjuk a mondatot, az egyes karakterek oszlopa növekszik. Érdemes megemlíteni azt is, hogy mivel a szkennerünk beolvassa a spacesnewlineseof, valamint az összes írásjelet karakterként, ezek is megjelennek a karaktertáblánkban!

a forrásszöveg beolvasása és megjelölése után fordítónk készen áll arra, hogy ezeket a karaktereket szavakká alakítsa. Mivel a szkenner nem csak azt tudja, hogy a fájlban lévő spacesnewlines és eof hol vannak, hanem azt is, hogy hol élnek az őket körülvevő többi karakterhez képest, át tudja szkennelni a karaktereket, és szükség szerint külön karakterláncokra oszthatja őket.
példánkban a szkenner a T karaktereket, majd a o karaktereket, majd a spacekaraktereket vizsgálja meg. Amikor szóközt talál, a To — t a saját szavára osztja-a lehető legegyszerűbb karakterkombinációt, mielőtt a szkenner szóközzel találkozna.
hasonló történet a következő szóhoz, amelyet megtalál, ami sleep. Ebben a forgatókönyvben azonban a s-l-e-e-p, majd a , írásjelet olvassa. Mivel ezt a vesszőt egy karakter (p) és egy space mindkét oldalon, a vesszőt magát “szónak”tekintik.
mind a sleepszót, mind a , írásjelet lexémáknak nevezzük, amelyek a forrásszöveg alszövegei. A lexéma a forráskódunkban a lehető legkisebb karaktersorozatok csoportosítása. A forrásfájl lexémáit magának a fájlnak az egyes “szavainak” tekintik. Miután a szkenner befejezte a fájlunk egyes karaktereinek olvasását, visszaad egy sor lexémát, amelyek így néznek ki: .

olyamat, 5.lépés.
figyeljük meg, hogy a szkenner vett egy folt a szöveg, mint a bemenet, amely nem tudott kezdetben olvasni, és folytatta, hogy átvizsgálja egyszer karaktert egy időben, egyszerre olvasás és jelölés azt a tartalmat. Ezután a karakterláncot a lehető legkisebb lexémákra osztotta, a karakterek közötti szóközöket és írásjeleket elválasztóként használva.
mindezek ellenére azonban a lexikális elemzési szakasz ezen a pontján a szkennerünk semmit sem tud ezekről a szavakról. Persze, a szöveget különböző formájú és méretű szavakra osztja, de amennyire ezek a szavak, a szkennernek fogalma sincs! A szavak lehetnek szó szerinti karakterláncok, vagy lehetnek írásjelek, vagy lehet valami egészen más!
a szkenner nem tud semmit magukról a szavakról, vagy arról, hogy milyen “típusú” szavak. Csak azt tudja, hogy a szavak hol végződnek és kezdődnek magában a szövegben.
Ez beállítja a lexikai elemzés második szakaszát: az értékelést. Miután beszkenneltük a szöveget, és a forráskódot külön lexémaegységekre bontottuk, ki kell értékelnünk azokat a szavakat, amelyeket a szkenner visszaadott nekünk, és ki kell derítenünk, hogy milyen típusú szavakkal van dolgunk — különösen fontos szavakat kell keresnünk, amelyek valami különlegeset jelentenek azon a nyelven, amelyet megpróbálunk lefordítani.
A fontos részek kiértékelése
miután befejeztük a forrásszöveg beolvasását és azonosítottuk a lexémáinkat, tennünk kell valamit a lexémánk “szavaival”. Ez a lexikai elemzés értékelési lépése, amelyet a complier tervezésben gyakran a bemenetünk lexing vagy tokenizálásának folyamataként emlegetnek.

mit jelent ez a beolvasott kód kiértékelése?
amikor kiértékeljük a beolvasott kódot, csak annyit teszünk, hogy közelebbről megvizsgáljuk a szkennerünk által létrehozott lexémákat. Fordítónknak meg kell vizsgálnia az egyes lexémaszavakat, és el kell döntenie, hogy milyen szó. Annak meghatározása, hogy a szövegünkben szereplő egyes “szavak” milyen lexémát tartalmaznak, az, hogy fordítónk hogyan alakítja az egyes lexémákat tokenré, ezáltal tokenizálva a bemeneti karakterláncunkat.
először akkor találkoztunk tokenekkel, amikor az elemzési fákról tanultunk. A tokenek olyan speciális szimbólumok, amelyek az egyes programozási nyelvek középpontjában állnak. A tokenek, mint például a (, ), +, -, if, else, then segítenek a fordítónak megérteni, hogy egy kifejezés különböző részei és különböző elemek hogyan kapcsolódnak egymáshoz. Az elemző, amely központi szerepet játszik a szintaxis-elemzési szakaszban, attól függ, hogy valahonnan fogad-e tokeneket, majd ezeket a tokeneket elemzési fává alakítja.

Nos, tudod mit? Végre kitaláltuk a “valahol”! Mint kiderült, az elemzőnek küldött Tokeneket a lexikális elemzési szakaszban generálja a tokenizer, más néven lexer.

tehát pontosan hogyan néz ki egy token? A token meglehetősen egyszerű, és általában párként jelenik meg, amely egy token névből és valamilyen értékből áll (ami opcionális).
például, ha Tokenizáljuk a shakespeare-i karakterláncunkat, akkor olyan tokeneket kapunk, amelyek többnyire string literálok és elválasztók. Képviselhetjük a "dream” tokent, mint így: <string literal, "dream">. Hasonló módon reprezentálhatjuk a . tokent, <separator, .>tokent.
észre fogjuk venni, hogy ezek a tokenek egyáltalán nem módosítják a lexémát — egyszerűen további információkat adnak hozzájuk. A token az lexéma vagy lexikai egység részletesebb; pontosabban, a hozzáadott részlet megmondja, hogy a token milyen kategóriájával (milyen típusú “szó”) van dolgunk.
most, hogy már tokenized a Shakespeare mondat, láthatjuk, hogy nincs minden, hogy sok fajta tokenek a forrás fájlt. A mondatunkban csak húrok és írásjelek voltak — de ez csak a jelképes jéghegy csúcsa! Rengeteg más típusú “szó” létezik, amelyekbe egy lexémát be lehet sorolni.

okenek belül található a forráskód.
az itt bemutatott táblázat bemutatja a leggyakoribb tokeneket, amelyeket fordítónk látna, amikor egy forrásfájlt nagyjából bármilyen programozási nyelven olvas. Láttunk példákat literals, amely lehet bármilyen karakterlánc, szám vagy logikai/logikai érték, valamint separators, amelyek bármilyen típusú írásjelek, beleértve a zárójeleket ({}) és zárójeleket (()).
However, there are also keywords, which are terms that are reserved in the language (such as ifvarwhilereturn), as well as operators, which operate on arguments and return some value ( +-x/). Találkozhatunk olyan lexémákkal is, amelyek tokenizálhatók identifiers, amelyek általában változónevek vagy dolgok, amelyeket a felhasználó/programozó írt valami másra hivatkozva, valamint , amelyek lehetnek a felhasználó által írt sor-vagy blokkmegjegyzések.
eredeti mondatunk csak két példát mutatott a tokenekre. Írjuk át a mondatunkat, hogy inkább olvassuk: var toSleep = "to dream";. Hogyan lehet a fordító lex ez a változat Shakespeare?

exer tokenizálja ezt a mondatot?
itt látni fogjuk, hogy van egy nagyobb különböző tokenek. Van egy keyworda varalatt, ahol deklarálunk egy változót, és egy identifiertoSleep, így nevezzük el a változónkat, vagy hivatkozunk a következő értékre. A következő a =, amely egy operator token, amelyet a "to dream"karakterlánc követ. Az utasításunk egy ; elválasztóval végződik, amely egy sor végét jelzi, és elválasztja a szóközöket.
fontos megjegyezni a tokenizációs folyamatot, hogy nem jelölünk semmilyen szóközt (szóközök, újsorok, fülek, sor vége stb.), sem továbbítja azt az elemzőnek. Ne feledje, hogy csak a tokenek kapnak az elemző, és a végén a parse fa.
azt is érdemes megemlíteni, hogy a különböző nyelvek különböző karakterekkel rendelkeznek, amelyek szóközként szolgálnak. Például bizonyos helyzetekben a Python programozási nyelv behúzást használ — beleértve a füleket és a szóközöket is — annak jelzésére, hogy a függvény hatóköre hogyan változik. Tehát a Python fordító tokenizerének tisztában kell lennie azzal a ténnyel, hogy bizonyos helyzetekben egy tab vagy space valójában szóként kell tokenizálni, mert valójában át kell adni az elemzőnek!

a tokenizer ezen aspektusa jó módja annak, hogy szembeállítsa a lexer/tokenizer eltérését a szkennertől. Míg a szkenner tudatlan, és csak azt tudja, hogyan bontsa fel a szöveget annak kisebb lehetséges részeire (“szavaira”), a lexer/tokenizer sokkal tudatosabb és pontosabb összehasonlítva.
a tokenizernek ismernie kell a fordítandó nyelv bonyolultságait és specifikációit. Ha a tabsfontosak, akkor ezt tudnia kell; ha anewlines bizonyos jelentéssel bírhat a lefordított nyelven, akkor a tokenizernek tisztában kell lennie ezekkel a részletekkel. Másrészt a szkenner még azt sem tudja, hogy mik azok a szavak, amelyeket oszt, még kevésbé, hogy mit jelentenek.
a complier szkennere sokkal inkább nyelv-agnosztikus, míg a tokenizernek definíció szerint nyelvspecifikusnak kell lennie.
a lexikai elemzési folyamatnak ez a két része kéz a kézben jár, és központi szerepet játszanak a fordítási folyamat első fázisában. Természetesen a különböző megfelelők saját egyedi módon vannak kialakítva. Néhány fordító a szkennelés és a tokenizálás lépését egyetlen folyamatban és egyetlen programként végzi, míg mások különböző osztályokra osztják fel őket, ebben az esetben a tokenizer a scanner osztályt hívja, amikor fut.

lemzés: gyors vizuális összefoglaló!
mindkét esetben a lexikális elemzés lépése rendkívül fontos a fordításhoz, mert a szintaxis elemzési fázis közvetlenül attól függ. És annak ellenére, hogy a fordító minden részének megvan a maga sajátos szerepe, egymásra támaszkodnak és függenek egymástól — mint mindig a jó barátok.
források
mivel sokféle módon lehet írni és megtervezni egy fordítót, sokféle módon lehet tanítani őket. Ha elegendő kutatást végez az összeállítás alapjairól, világossá válik, hogy egyes magyarázatok sokkal részletesebbek, mint mások, ami hasznos lehet vagy nem. Ha úgy találja, hogy többet szeretne megtudni, az alábbiakban különféle források találhatók a fordítókról — a lexikai elemzési szakaszra összpontosítva.
- 4. fejezet-Crafting Interpreters, Robert Nystrom
- Compiler Construction, Allan Gottlieb professzor
- Compiler alapjai, James Alan Farrell professzor
- programozási nyelv írása — a Lexer, Andy Balaam
- Megjegyzések Az elemzők és a fordítók munkájáról, Stephen Raymond Ferg
- mi a különbség a token és a lexéma között?, StackOverflow