Raccomandazione Utilizzando la fattorizzazione a matrice
Nell’era del mondo digitale, vediamo raccomandazione in ogni area meteo è sito di e-commerce o sito web di intrattenimento o siti di social network. Raccomandazione non solo dà all’utente la sua scelta consigliata (in base alle attività passate), ma racconta anche il comportamento degli utenti (analisi sentimentale o emozione AI).
Quindi, per prima cosa, capiamo cos’è la raccomandazione. È fondamentalmente raccomandando l’elemento all’utente in base alla sua ricerca/attività passata.

La figura 1 indica la raccomandazione di Amazon in base alla cronologia di navigazione passata e alle ricerche passate. Quindi, possiamo dire che la raccomandazione è fondamentalmente predire il comportamento futuro basato sul comportamento passato. Ci sono due tipi di approcci che è utilizzato nel sistema di raccomandazione
1 – Content Based Filtering
2 – Collaborazione a base di filtraggio
Content Based Filtering-
è basato sull’idea di proporre la voce per l’utente K, che è simile alla precedente voce altamente valutato da K. concetto di Base nel contenuto a base di filtraggio TF-IDF (Termine di frequenza — inverse document frequency), che viene utilizzato per determinare l’importanza del documento/parola/film etc. Content based filtering mostra la trasparenza nella raccomandazione, ma a differenza di filtraggio collaborativo non può in grado di lavorare in modo efficiente di dati di grandi dimensioni
Collaborativo basato filtraggio
si basa sull’idea che le persone che condividono lo stesso interesse in certi tipi di prodotti anche condividere lo stesso interesse di un altro tipo di elementi, a differenza di contenuto di base che fondamentalmente si basano su metadati, mentre si tratta con la vita reale attività. Questo tipo di filtraggio è flessibile per la maggior parte del dominio (o possiamo dire che è privo di dominio) ma a causa del problema di avvio a freddo, la sparsità dei dati (che è stata gestita dalla fattorizzazione della matrice) questo tipo di algoritmo affronta qualche battuta d’arresto in alcuni scenari.
Matrix factorization
Matrix factorization arriva alla ribalta dopo Netflix competition (2006) quando Netflix ha annunciato un premio in denaro di $1 milione a coloro che miglioreranno le sue prestazioni root mean square del 10%. Netflix ha fornito un set di dati di formazione di 100.480.507 valutazioni che 480.189 utenti hanno dato a 17.770 film.
La fattorizzazione della matrice è il metodo di filtraggio basato sulla collaborazione in cui la matrice m*n viene scomposta in m*k e k*n . Viene fondamentalmente utilizzato per il calcolo di operazioni a matrice complessa. La divisione della matrice è tale che se moltiplichiamo la matrice fattorizzata otterremo la matrice originale come mostrato in Figura 2. Esso è utilizzato per scoprire latente tra due entità (può essere utilizzato per più di due entità ma questo avverrà sotto il tensore di fattorizzazione)

la decomposizione della Matrice possono essere classificati in tre tipi-
1 – decomposizione LU — Decomposizione della matrice L e U matrice, dove L è la matrice triangolare bassa e U matrice triangolare superiore, generalmente usato per trovare il coefficiente di regressione lineare. Questa decomposizione non è riuscita se la matrice non può essere facilmente decomposta
2 – Decomposizione della matrice QR-Decomposizione della matrice in Q e R dove Q è matrice quadrata e R è matrice triangolare superiore (quadrato non necessario). Utilizzato per l’analisi del sistema eigen
Decomposizione 3 – Cholesky – Questa è la decomposizione più utilizzata nell’apprendimento automatico. Utilizzato per il calcolo del minimo quadrato lineare per la regressione lineare
La fattorizzazione della matrice può essere utilizzata in vari domini come il riconoscimento delle immagini, la raccomandazione. Le matrici utilizzate in questo tipo di problema sono generalmente sparse perché c’è la possibilità che un utente possa valutare solo alcuni film. Esistono varie applicazioni per la fattorizzazione della matrice come la riduzione della dimensionalità (per saperne di più sulla riduzione della dimensionalità fare riferimento a Curse Of Dimensionality), la decomposizione del valore latente
Dichiarazione del problema
Nella Tabella 1 abbiamo 5 utenti e 6 film in cui ogni utente può valutare qualsiasi film. Come possiamo vedere che Henry non ha valutato per Thor e Rocky allo stesso modo Jerry non ha valutato per Avatar. Nel mondo reale lo scenario di questi tipi di matrice può essere altamente matrice sparsa
il problema economico è che dobbiamo trovare valutazioni per la classificazione dei film, come mostrato in Tabella 1

il nostro obiettivo è trovare valutazione dell’utente attraverso la fattorizzazione della matrice, ma prima dobbiamo passare attraverso la Decomposizione a valori Singolari (SVD) perché fattorizzazione della matrice e SVD sono correlate tra di loro
SVD e fattorizzazione della matrice
Prima di andare alla profondità di SVD consente prima di capire che cosa è K e trasporre(K). Se eseguiamo PCA sulla matrice K(Tabella 1) otteniamo tutto il vettore utente. Più tardi possiamo mettere questi vettori nella colonna della matrice U e se eseguiamo PCA su transpose(K) otteniamo tutto il vettore del film che diventa colonna per matrix M.
Quindi invece di eseguire PCA su K e transpose(K) separatamente, possiamo usare SVD che può eseguire PCA su K e transpose(K) in un solo colpo. SVD è fondamentalmente fattorizzato matrice K in matrice U, matrice M e matrice diagonale:

dove K è la Matrice Originale, U è utente matrice,M è il film matrix e quella di mezzo è la matrice diagonale
Per semplicità, possiamo rimuovere matrice diagonale per un po ‘ così nuova equazione diventa:

Lasciate che r è la valutazione definito per l’utente u e la voce che ho, p è la riga di M per un utente e q è la colonna di recepimento(U) per un elemento specifico io. Quindi l’equazione diventerà:

Note — Se K è densa matrice valore di M sarà autovettore di K*transpose(K), allo stesso modo il valore di U sarà autovettore di recepimento(K)*K, ma la nostra matrice è la matrice sparsa di noi può calcolare U e M da questo approccio
Quindi, ecco il nostro compito è quello di trovare una matrice M e U . Un modo è inizializzare il valore casuale su M e U e confrontarlo con la matrice originale K se il valore è vicino a K piuttosto che interrompere la procedura altrimenti minimizzare il valore di U e M fino a quando non sono vicini a K . Il processo di questi tipo di ottimizzazione è chiamato gradiente di discesa

il nostro compito fondamentale è quello di minimizzare l’errore quadratico medio della funzione che può essere rappresentata come :

As our main task is to minimize the error i.e. dobbiamo trovare la direzione in cui dobbiamo andare per questo che dobbiamo differenziare, quindi i nuovi equazione diventerà


Quindi il valore aggiornato per p e u sarà ormai diventato:


Where alpha is learning rate generally its value is very small as higher alpha can overshoot the minimum value.
Regularization in Recommendation
When we fit the model to the training data it returns some decision line . Basata su tale decisione, siamo in grado di in grado di distinguere la distribuzione dei dati
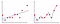
In Figura 2 primi trama è dove il modello è montato in modo lineare, mentre nel secondo lotto è dotato di polinomio di grado. A prima vista sembra che la seconda trama sia molto meglio della prima trama in quanto fornisce una precisione del 99% sui dati di allenamento, ma cosa succede se introduciamo i dati di test e danno una precisione del 50% sui dati di test . Questo tipo di problema è chiamato overfitting e per superare questo problema introduciamo un concetto chiamato regolarizzazione.
Poiché il problema dell’overfitting è comune nell’apprendimento automatico, ci sono due tipi di approccio di regolarizzazione che possono essere utilizzati per rimuovere l’overfitting
1 – L1 regolarizzazione
2 – L2 regolarizzazione
La regolarizzazione L1 aggiunge la grandezza lineare del coefficiente come termine di penalità mentre in L2 aggiunge la grandezza quadrata del coefficiente alla funzione L1 restituisce matrici sparse mentre L2 no. La regolarizzazione L1 funziona bene nella selezione delle funzionalità nella matrice sparsa.
Anche nel set di dati di raccomandazione, ci sono alte probabilità di overfitting dei dati. Quindi, per rimuovere il problema di overfitting possiamo aggiungere la regolarizzazione L2 (poiché la matrice è già scarsa, non abbiamo bisogno della regolarizzazione L1 qui) nella funzione di perdita, quindi la nuova equazione della funzione di perdita sarà:

Di nuovo si può trovare pendenza aggiornato MSE e aggiornata punti, seguendo lo stesso approccio, come discusso sopra,
Una cosa importante da considerare nello scenario di cui sopra, la matrice P e Q non sono negativi, quindi, questi tipi di fattorizzazione è chiamato anche non-negativo di fattorizzazione. Poiché la fattorizzazione non negativa estrae automaticamente le informazioni per l’insieme non negativo del vettore. NMF è ampiamente usato in elaborazione delle immagini, text mining, analisi di dati ad alta dimensionale