Blog
以前のブログ記事では、スーパーマーケットが消費者のニーズをよりよく理解し、最終的には全体的な支出を増やすためにデータをどのように使用するかについて議論しました。 大規模小売業者によって使用される重要な技術の一つは、頻繁に取引で共起する製品の組み合わせを探して、製品間の関連付けを明らかにする市場バ 言い換えれば、それはスーパーマーケットが人々が買う製品間の関係を識別することを可能にする。 たとえば、鉛筆と紙を購入する顧客は、ゴムや定規を購入する可能性があります。
“マーケットバスケット分析は、小売業者が人々が購入する製品間の関係を識別することができます。”
小売業者は、MBAから得られた洞察をさまざまな方法で使用することができます。
- 店舗のレイアウトの設計で同時発生する; そして、
- 彼らが最近購入したアイテムに関連する製品のための顧客にプロモーションクーポンを送信することにより、マーケティングキャンペー
MBAがどのように人気があり、貴重なMBAであるかを考えると、私たちはそれがどのように機能し、どのようにあなた自身の市場バスケット分析を行
マーケットバスケット分析はどのように機能しますか?MBAを実行するには、最初にトランザクションのデータセットが必要です。
MBAを実行するには、最初にトランザクションのデータセットが必要です。トランザクションは、一緒に購入され、しばしば”アイテムセット”と呼ばれるアイテムまたは製品のグループを表します。 たとえば、{pencil,paper,staples,rubber}のように、これらのすべてのアイテムが単一のトランザクションで購入されている場合があります。
MBAでは、取引は関連のルールを識別するために分析されます。 たとえば、1つのルールは{pencil,paper}=>{rubber}です。 これは、顧客が鉛筆と紙を含む取引をしている場合、ゴムを購入することにも興味がある可能性が高いことを意味します。ルールに基づいて行動する前に、小売業者はそれが有益な結果をもたらすことを示唆するのに十分な証拠があるかどうかを知る必要があります。
したがって、ルールの強さを測定するには、次の三つのメトリックを計算します(他のメトリックもありますが、これらは最も一般的に使用される三つです)。
サポート:アイテムセット内のすべてのアイテムを含むトランザクションの割合(鉛筆、紙、ゴムなど)。 サポートが高いほど、アイテムセットが頻繁に発生します。 将来の多数のトランザクションに適用される可能性が高いため、高いサポートを持つルールが好まれます。
Confidence:ルールの左側にあるアイテム(この例では鉛筆と紙)を含むトランザクションに、右側にあるアイテム(ゴム)も含まれる確率。 信頼度が高いほど、右側のアイテムが購入される可能性が高くなり、言い換えれば、特定のルールに対して期待できる返品率が高くなります。リフト
リフト
リフト: ルール内のすべてのアイテムが一緒に発生する確率(サポートとも呼ばれます)を、それらの間に関連性がないかのように発生する左側と右側のアイテムの確率の積で割ったものです。 たとえば、鉛筆、紙、ゴムがすべての取引の2.5%で一緒に発生し、取引の10%で鉛筆と紙、取引の8%でゴムが発生した場合、リフトは次のようになります: 0.025/(0.1*0.08) = 3.125. 1を超えるリフトは、鉛筆と紙の存在が取引にゴムも発生する確率を高めることを示唆しています。 全体的に、リフトは、ルールの左側と右側の製品間の関連付けの強さを要約します。
マーケットバスケット分析を実行し、潜在的なルールを特定するには、”Apriori algorithm”と呼ばれるデータマイニングアルゴリズムが一般的に使用されます。
- 事前に指定されたしきい値を超えるサポートを持つデータセット内で頻繁に発生するアイテムセットを体系的に識別します。
- 頻繁なアイテムセットが与えられたすべての可能なルールの信頼度を計算し、事前に指定されたしきい値よりも大きい信頼度を持つものだけを保
サポートと信頼度を設定するしきい値はユーザー指定であり、トランザクションデータセット間で変化する可能性があります。 Rにはデフォルト値がありますが、これらを試して、返されるルールの数にどのように影響するかを確認することをお勧めします(詳細は以下を参照)。 最後に、Aprioriアルゴリズムはliftを使用してルールを確立しませんが、アルゴリズムが返すルールを調べるときにliftを使用することが次のようにわかります。
Rでマーケットバスケット分析を実行する
MBAを実行する方法を実証するために、R、特にarulesパッケージを使用することを選択しました。 興味のある人のために、私たちはこのブログの最後に使用したRコードを含めました。
ここでは、arulesViz Vignetteで使用されているのと同じ例に従い、9,835個の個別取引を含む食料品販売のデータセットを使用し、169個のアイテムを使用します。 最初に行うことは、トランザクション内の項目を見て、特に、図1の25の最も頻繁な項目の相対的な頻度をプロットすることです。 これは、各アイテムセットに単一のアイテムのみが含まれているこれらのアイテムのサポートと同等です。 この棒グラフは、この店で頻繁に購入される食料品を示しており、最も頻繁なアイテムでさえもサポートが比較的低いことが注目に値します(たとえば、最 これらの洞察を使用して、Aprioriアルゴリズムを実行するときの最小しきい値を通知します; たとえば、アルゴリズムが妥当な数のルールを返すためには、サポートしきい値を0.025よりもはるかに低い値に設定する必要があることがわかります。
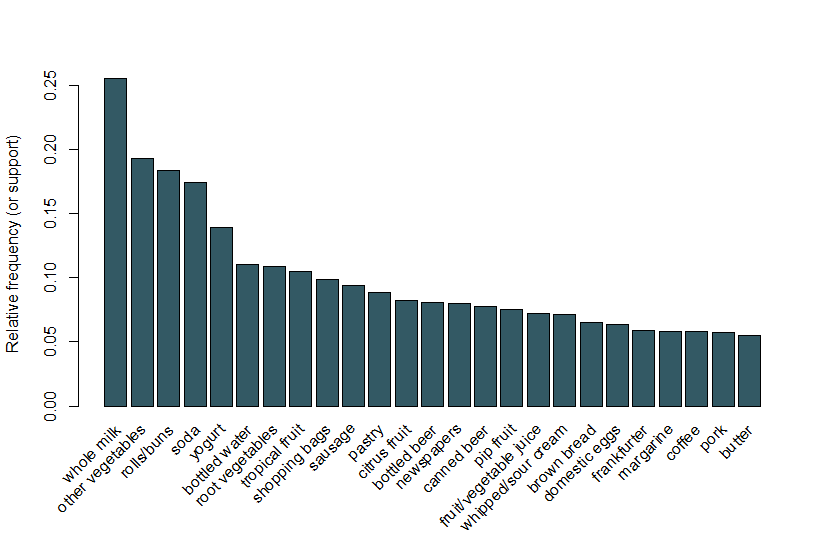
図1買った25最も頻繁なアイテムのサポートの棒グラフ。
サポートしきい値を0.001、信頼度を0.5に設定することで、Aprioriアルゴリズムを実行して5,668個の結果を得ることができます。 これらのしきい値は、返されるルールの数が多くなるように選択されますが、いずれかのしきい値を増加させると、この数は減少します。 最も適切な値を得るために、これらのしきい値を試してみることをお勧めします。 それらをすべて個別に見るにはあまりにも多くのルールがありますが、最大のリフトを持つ五つのルールを見ることができます。
| ルール | サポート | 信頼 | リフト | ||||||||
| {インスタント食品、ソーダ}= | 0.001 | 0.632 | 19.00 | ||||||||
| {ソーダ、ポップコーン}=>{ハンバーガー肉} | 0.001 | 0.632 | 19.00 | ||||||||
| {ソーダ、ポップコーン}= | 0.001 | 0.001 | 0.001 | 0.001 | 0.001 | 0.001 | 0.001 | 0.001 | 0.001 | 0632 | 16.70 |
| {flour, baking powder}=>{sugar} | 0.001 | 0.556 | 16.41 | ||||||||
| {ham, processed cheese}=>{white bread} | 0.002 | 0.633 | 15.05 | ||||||||
| {whole milk, instant food products}=>{hamburger meat} | 0.002 | 0.500 | 15.04 |
Table 1: The five rules with the largest lift.
These rules seem to make intuitive sense. たとえば、最初のルールは、バーベキューのために購入されたアイテムの種類、映画の夜のための第二、ベーキングのための第三を表すことができます。
しきい値を使用してルールを小さなセットに減らすのではなく、関連するルールを生成する可能性が高くなるように、より大きなルールセットを返 あるいは、視覚化技術を使用して、返された一連のルールを検査し、有用である可能性が高いルールを特定することもできます。
arulesVizパッケージを使用して、図2の信頼度、サポート、リフトによってルールをプロットします。 このプロットは、異なる指標間の関係を示しています。 最適なルールは、「サポート信頼境界」として知られているものにあるルールであることが示されています。 基本的に、これらは、支持、信頼、またはその両方が最大化されるプロットの右側の境界にあるルールです。 ArulesVizパッケージのplot関数には、(関連するデータポイントをクリックして)個々のルールを選択できる便利な対話型関数があり、境界線のルールを簡単に識別できます。
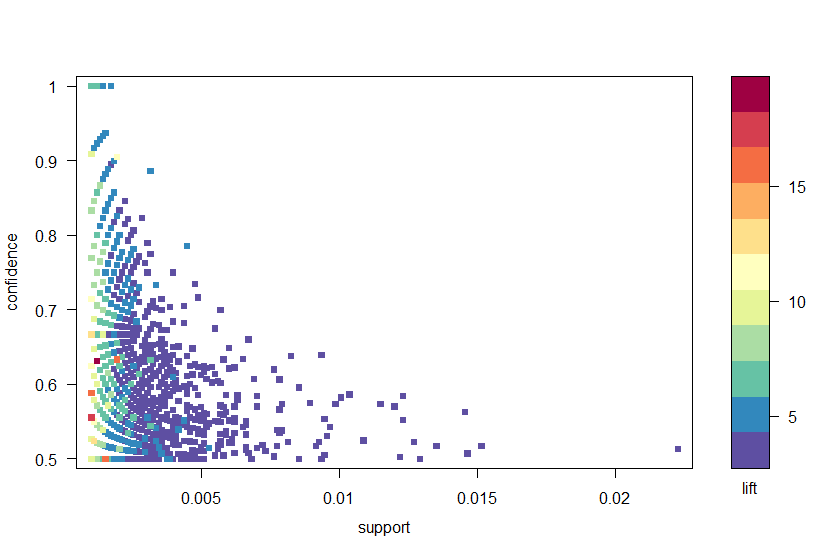
図2:信頼度、支持度、および上昇度の指標の散布図。
ルールを視覚化するために利用可能な他のプロットがたくさんありますが、探索することをお勧めするもう一つの図は、リフトの面でトップテンのルールのグラフベースの視覚化(図3を参照)です(十以上を含めることができますが、これらのタイプのグラフは簡単に乱雑になる可能性があります)。 このグラフでは、円の周りにグループ化されたアイテムはアイテムセットを表し、矢印はルール内の関係を示します。 例えば、一つのルールは、砂糖の購入は小麦粉とベーキングパウダーの購入に関連しているということです。 円のサイズは、ルールに関連付けられている信頼度を表し、色はリフトのレベルを表します(円が大きく、灰色が濃いほど良い)。
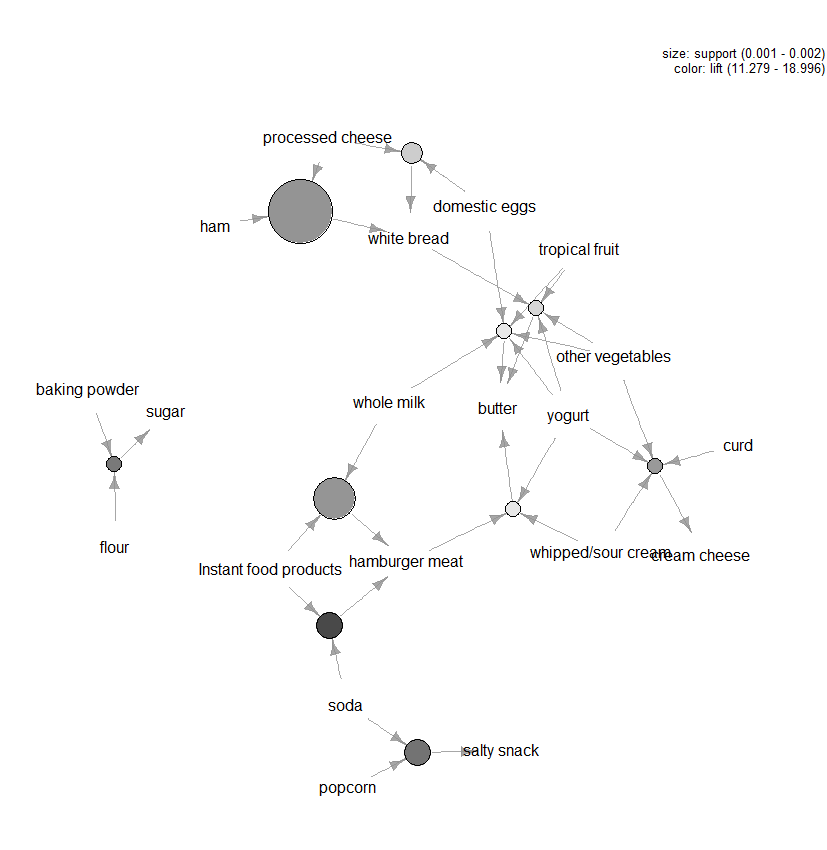
図3:リフトの観点からトップテンのルールのグラフベースの視覚化。
マーケットバスケット分析は、人々が購入する製品間の関係をよりよく理解したい小売業者にとって便利なツールです。 MBAを実行するときに適用できるツールはたくさんあり、分析の最も難しい側面は、Aprioriアルゴリズムの信頼度とサポートのしきい値を設定し、どのルールを追 典型的には、後者は、視覚化技術とより正式な多変量統計を使用して、それらがどれほど興味深いかを要約する指標の観点からルールを測定することに 最終的にMBAの鍵は、消費者のニーズを理解することによって、取引データから価値を抽出することです。 このタイプの情報は交差販売または目標とされたキャンペーンのようなマーケティングの活動に興味があれば非常に貴重である。
あなたの取引データを分析する方法についての詳細を知りたい場合は、私達に連絡してください、私たちは喜んで助けてくれるでしょう。
R Code
library("arules")
library("arulesViz")
#Load data set:
data("Groceries")
summary(Groceries)
#Look at data:
inspect(Groceries)
LIST(Groceries)
#Calculate rules using apriori algorithm and specifying support and confidence thresholds:
rules = apriori(Groceries, parameter=list(support=0.001, confidence=0.5))
#Inspect the top 5 rules in terms of lift:
inspect(head(sort(rules, by ="lift"),5))
#Plot a frequency plot:
itemFrequencyPlot(Groceries, topN = 25)
#Scatter plot of rules:
library("RColorBrewer")
iv