Deep learningを使用してセマンティックセグメンテーションを実行する方法
この記事では、deep learningの画像セグメンテーションモデルを実装するためのステップバイステップガイドを含む包括的な概要を説明します。
セマンティックセグメンテーションに関する新しい更新されたブログをここで共有しました:セマンティックセグメンテーションへの2021ガイド
今日、セマンティックセグメンテーションは、コンピュータビジョンの分野における重要な問題の一つです。 全体像を見ると、セマンティックセグメンテーションは、完全なシーン理解への道を開く高レベルのタスクの一つです。 コアコンピュータビジョンの問題としてのシーン理解の重要性は、アプリケーションの増加は、画像からの知識を推論から栄養を与えるという事実によっ それらの適用のいくつかは自動運転車、人間コンピュータ相互作用、バーチャルリアリティ等を含んでいます。 近年のディープラーニングの人気に伴い、多くの意味セグメンテーション問題がディープアーキテクチャ、最も頻繁に畳み込みニューラルネットを使用して取り組まれており、精度と効率の点で他のアプローチを大きく凌駕しています。
- セマンティックセグメンテーションとは何ですか?
- 既存のセマンティックセグメンテーションアプローチは何ですか?
- 1—領域ベースのセマンティックセグメンテーション
- 2—完全畳み込みネットワークベースのセマンティックセグメンテーション
- 3—弱教師セマンティックセグメンテーション
- 完全畳み込みネットワークを使用したセマンティックセグメンテーションの実行
- ステップ1h4最初に、事前に訓練されたVGG-16モデルをtensorflowにロードします。 TensorFlowセッションとVGGフォルダへのパス(ここでダウンロード可能です)を取得して、画像入力、keep_prob(ドロップアウトレートを制御するため)、レイヤー3、レイヤー4、およ def load_vgg(sess, vgg_path): # load the model and weights model = tf.saved_model.loader.load(sess, , vgg_path) # Get Tensors to be returned from graph graph = tf.get_default_graph() image_input = graph.get_tensor_by_name('image_input:0') keep_prob = graph.get_tensor_by_name('keep_prob:0') layer3 = graph.get_tensor_by_name('layer3_out:0') layer4 = graph.get_tensor_by_name('layer4_out:0') layer7 = graph.get_tensor_by_name('layer7_out:0') return image_input, keep_prob, layer3, layer4, layer7
- ステップ2
- ステップ3
- Step4
- ステップ5
セマンティックセグメンテーションとは何ですか?
セマンティックセグメンテーションは、粗い推論から細かい推論への進行における自然なステップです。次のステップは、クラスだけでなく、それらのクラスの空間的位置に関する追加情報も提供するローカリゼーション/検出です。最後に、セマンティックセグメンテーションは、各ピクセルのラベルを推論する密な予測を行うことによって、きめ細かな推論を達成し、各ピクセルは、その囲むオブジェクト鉱石領域のクラスでラベル付けされるようにします。
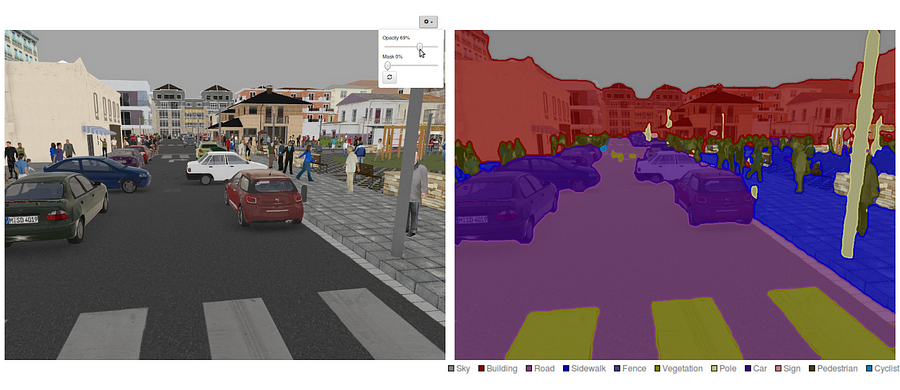
コンピュータビジョンの分野に大きく貢献したネットワークは、セマンティックセグメンテーションシステムの基礎としてよく使用されています。
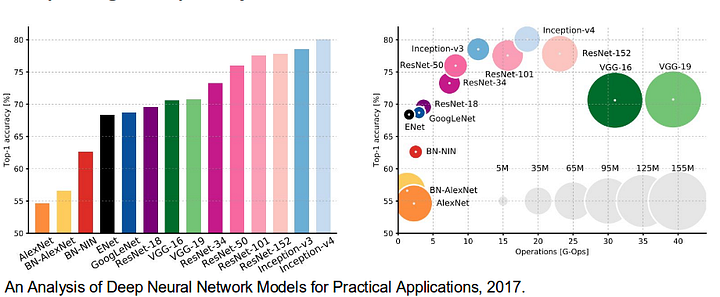
- alexnet:2012年のimagenetコンペティションで84.6%のテスト精度で優勝したトロントの先駆的なdeep cnn。 これは、5つの畳み込み層、最大プーリング層、非線形性としてのReLUs、3つの完全畳み込み層、およびドロップアウトで構成されています。
- VGG-16:このオックスフォードのモデルは、2013年のImageNet competitionで92.7%の精度で優勝しました。 これは、大きな受容野を持ついくつかの層の代わりに、最初の層に小さな受容野を持つ畳み込み層のスタックを使用します。
- GoogLeNet:このGoogleのネットワークは、2014年のImageNet競争で93.3%の精度で優勝しました。 それは22の層および開始モジュールと呼ばれる最近導入されたブロックによって構成される。 このモジュールは,ネットワーク-イン-ネットワーク層,プーリング動作,大型畳み込み層,および小型畳み込み層からなる。
- ResNet:このMicrosoftのモデルは、96.4%の精度で2016ImageNet competitionで優勝しました。 それは、その深さ(152層)および残留ブロックの導入のためによく知られている。 残差ブロックは、層が入力を次の層にコピーできるように、idスキップ接続を導入することによって、本当に深いアーキテクチャを訓練する問題に対
既存のセマンティックセグメンテーションアプローチは何ですか?
一般的なセマンティックセグメンテーションアーキテクチャは、エンコーダネットワークの後にデコーダネットワークが続くと広く考えることができます。
- エンコーダは、通常、vgg/ResNetのような事前訓練された分類ネットワークであり、その後にデコーダネットワークが続く。
- 復号器のタスクは、符号器によって学習された識別的特徴(低解像度)を意味的にピクセル空間(高解像度)に投影して、密な分類を得ることです。
非常に深いネットワークの最終結果が唯一の重要なものである分類とは異なり、意味的セグメンテーションは、ピクセルレベルでの差別だけでなく、エンコーダーの異なる段階で学習された差別的特徴をピクセル空間に投影するメカニズムも必要とする。 異なる手法は、復号機構の一部として異なる機構を採用する。 3つの主なアプローチを見てみましょう:
1—領域ベースのセマンティックセグメンテーション
領域ベースの方法は、一般的に、最初に画像から自由形 テスト時に、領域ベースの予測は、通常、それを含む最高得点の領域に従ってピクセルにラベル付けすることによって、ピクセル予測に変換されます。
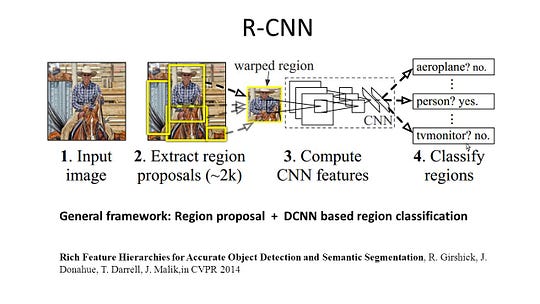
R-CNN(Cnn機能を持つ地域)は、地域ベースのメソッドの代表的な作品の一つです。 オブジェクト検出結果に基づいて意味分割を行う。 具体的には、R-CNNは最初に選択的検索を利用して大量のオブジェクト提案を抽出し、次にそれぞれのCNN特徴を計算します。 最後に、クラス固有の線形Svmを使用して各領域を分類します。 主に画像分類を目的とした従来のCNN構造と比較して、R-CNNは、物体検出や画像セグメンテーションなどのより複雑なタスクに対処することができ、両分野の重要な基礎となっている。 さらに、R-CNNは、AlexNet、VGG、GoogLeNet、ResNetなどのCNNベンチマーク構造の上に構築することができます。
画像セグメンテーションタスクでは、r-CNNは、全領域特徴と前景特徴の2種類の特徴を抽出し、それらを領域特徴として連結すると、より良いパフォーマ R-CNNは、非常に差別的なCNN機能を使用することにより、大幅なパフォーマンスの向上を達成しました。 ただし、セグメンテーションタスクにはいくつかの欠点もあります。
- この機能はセグメンテーションタスクと互換性がありません。
- フィーチャには、境界を正確に生成するのに十分な空間情報が含まれていません。
- セグメントベースの提案を生成するには時間がかかり、最終的なパフォーマンスに大きく影響します。これらのボトルネックのために、SDS、Hypercolumns、Mask R-CNNなどの問題に対処するための最近の研究が提案されています。
2—完全畳み込みネットワークベースのセマンティックセグメンテーション
元の完全畳み込みネットワーク(FCN)は、領域提案を抽出することなく、ピクセ FCNネットワークパイプラインは、古典的なCNNの拡張です。 主なアイデアは、古典的なCNNが入力として任意のサイズの画像を取るようにすることです。 特定の大きさで分類された入力のためのだけラベルを受け入れ、作り出すCnnの制限は固定である完全接続された層から来る。 それらとは対照的に、Fcnは畳み込み層とプーリング層のみを持ち、任意のサイズの入力で予測を行う能力を与えます。
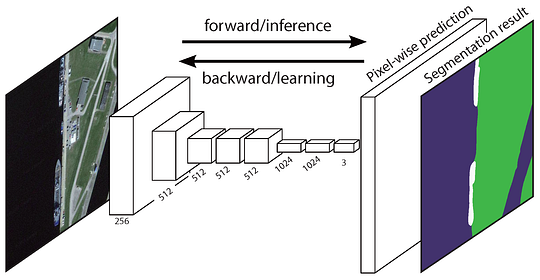
FCNアーキテクチャ この特定のFCNの問題の一つは、いくつかの交互の畳み込み層とプーリング層を介して伝播することによって、出力フィーチャマップの解像度が次のようになることです。ダウンサンプリング。 したがって、FCNの直接予測は、典型的には低解像度であり、その結果、比較的ファジィな物体境界を生じる。 この問題に対処するために、SegNet、DeepLab-CRF、および拡張畳み込みを含む、より高度なFCNベースのさまざまなアプローチが提案されています。
3—弱教師セマンティックセグメンテーション
セマンティックセグメンテーションにおける関連する方法のほとんどは、ピクセル単位のセグメンテーションマスクを持つ多数の画像に依存しています。 しかし、手動でこれらのマスクに注釈を付けることは非常に時間がかかり、イライラし、商業的に高価です。 そこで,注釈付き境界ボックスを利用して意味的セグメンテーションを実現することに専念するいくつかの弱い監督法が最近提案されている。

Boxsupトレーニング 例えば、Boxsupは、ネットワークを訓練し、セマンティックセグメンテーションの推定マスクを反復的に改善するための監督として境界ボックス注釈を採用した。 Simple Does Itは、弱い監督制限を入力ラベルノイズの問題として扱い、ノイズ除去戦略として再帰的なトレーニングを検討しました。 ピクセルレベルのラベリングは、複数インスタンス学習フレームワーク内のセグメンテーションタスクを解釈し、イメージレベルの分類のために重要なピク
完全畳み込みネットワークを使用したセマンティックセグメンテーションの実行
このセクションでは、セマンティックセグメンテーションのための最も一般的なアーキテクチャである完全畳み込みネット(FCN)の段階的な実装について説明します。 Python3のTensorFlowライブラリを使用して、NumpyやNumpyなどの他の依存関係と一緒に実装します。Scipy.In この演習では、FCNを使用して画像内の道路のピクセルにラベルを付けます。 道路/車線検出のためにKitti Roadデータセットを使用します。 これは、UdacityのSelf-Driving Car Nano-degreeプログラムの簡単な演習です。

Kitti道路データセットトレーニングサンプル(出典:http://www.cvlibs.net/datasets/kitti/eval_road_detail.php?result=3748e213cf8e0100b7a26198114b3cdc7caa3aff) fcnアーキテクチャ:
- fcnは意味分割を実行するためにvgg16から知識を転送します。
- VGG16の完全に接続された層は、1×1畳み込みを使用して完全畳み込み層に変換されます。 このプロセスでは、クラスプレゼンスのヒートマップが低解像度で生成されます。
- これらの低解像度セマンティックフィーチャマップのアップサンプリングは、転置畳み込み(双一次補間フィルタで初期化)を使用して行われます。
- 各段階で、アップサンプリングプロセスは、vgg16の下位レイヤーから粗いが高解像度のフィーチャマップからフィーチャを追加することによって、さら
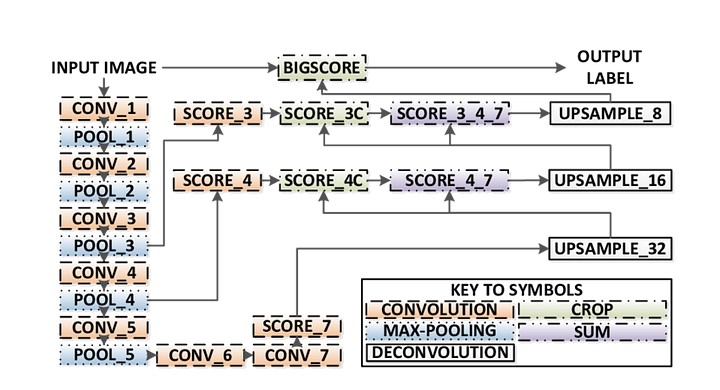
- Skip connectionは、各convolutionブロックの後に導入され、後続のブロックが以前にプールされたフィーチャからより抽象的でクラス顕著なフィーチャを抽出できるようにFCNには3つのバージョン(FCN-32、FCN-16、FCN-8)があります。 以下の詳細な手順に従って、FCN-8を実装します。
- エンコーダ:事前に訓練されたVGG16がエンコーダとして使用されます。 デコーダはVGG16のレイヤ7から開始されます。FCN層-8:VGG16の最後の完全に接続された層は1×1畳み込みに置き換えられます。
- FCN層-9: FCNレイヤ8は、パラメータ(kernel=(4,4)、stride=(2,2)、paddding=’same’)で転置された畳み込みを使用して、VGG16のレイヤ4と次元を一致させるために2回アップサンプリングされます。 その後、VGG1 6のレイヤ4とFCNレイヤ9との間にスキップ接続を追加した。FCN Layer-10:FCN Layer-9は、パラメータ(kernel=(4,4),stride=(2,2),paddding=’same’)を持つ転置畳み込みを使用して、VGG16のレイヤ3と次元を一致させるために2回アップサンプリングされます。 その後、VGG1 6のレイヤ3とFCNレイヤ1 0との間にスキップ接続を追加した。
- FCN層-11: FCN Layer-10は、入力画像サイズと寸法を一致させるために4回アップサンプリングされるため、実際の画像が返され、深さはクラスの数に等しくなります。(kernel=(16,16),stride=(8,8),paddding=’same’)。
FCN-8アーキテクチャ(ソース:https://www.researchgate.net/figure/Illustration-of-the-FCN-8s-network-architecture-as-proposed-in-20-In-our-method-the_fig1_305770331) ステップ1h4最初に、事前に訓練されたVGG-16モデルをtensorflowにロードします。 TensorFlowセッションとVGGフォルダへのパス(ここでダウンロード可能です)を取得して、画像入力、keep_prob(ドロップアウトレートを制御するため)、レイヤー3、レイヤー4、およ
def load_vgg(sess, vgg_path): # load the model and weights model = tf.saved_model.loader.load(sess, , vgg_path) # Get Tensors to be returned from graph graph = tf.get_default_graph() image_input = graph.get_tensor_by_name('image_input:0') keep_prob = graph.get_tensor_by_name('keep_prob:0') layer3 = graph.get_tensor_by_name('layer3_out:0') layer4 = graph.get_tensor_by_name('layer4_out:0') layer7 = graph.get_tensor_by_name('layer7_out:0') return image_input, keep_prob, layer3, layer4, layer7VGG16function
ステップ2
ここでは、VGGモデルのテンソルを使用して、FCNのレイヤーを作成することに焦点を当てま VGG層の出力のテンソルと分類するクラスの数が与えられた場合、その出力の最後の層のテンソルを返します。 特に、エンコーダ層に1×1畳み込みを適用し、スキップコネクションとアップサンプリングを使用してデコーダ層をネットワークに追加します。
def layers(vgg_layer3_out, vgg_layer4_out, vgg_layer7_out, num_classes): # Use a shorter variable name for simplicity layer3, layer4, layer7 = vgg_layer3_out, vgg_layer4_out, vgg_layer7_out # Apply 1x1 convolution in place of fully connected layer fcn8 = tf.layers.conv2d(layer7, filters=num_classes, kernel_size=1, name="fcn8") # Upsample fcn8 with size depth=(4096?) to match size of layer 4 so that we can add skip connection with 4th layer fcn9 = tf.layers.conv2d_transpose(fcn8, filters=layer4.get_shape().as_list(), kernel_size=4, strides=(2, 2), padding='SAME', name="fcn9") # Add a skip connection between current final layer fcn8 and 4th layer fcn9_skip_connected = tf.add(fcn9, layer4, name="fcn9_plus_vgg_layer4") # Upsample again fcn10 = tf.layers.conv2d_transpose(fcn9_skip_connected, filters=layer3.get_shape().as_list(), kernel_size=4, strides=(2, 2), padding='SAME', name="fcn10_conv2d") # Add skip connection fcn10_skip_connected = tf.add(fcn10, layer3, name="fcn10_plus_vgg_layer3") # Upsample again fcn11 = tf.layers.conv2d_transpose(fcn10_skip_connected, filters=num_classes, kernel_size=16, strides=(8, 8), padding='SAME', name="fcn11") return fcn11レイヤー関数
ステップ3
次のステップは、tensorflow損失関数とオプティマイザ操作を構築する別名ニューラルネットワークを最適化 ここでは、損失関数としてクロスエントロピーを使用し、最適化アルゴリズムとしてAdamを使用します。
def optimize(nn_last_layer, correct_label, learning_rate, num_classes): # Reshape 4D tensors to 2D, each row represents a pixel, each column a class logits = tf.reshape(nn_last_layer, (-1, num_classes), name="fcn_logits") correct_label_reshaped = tf.reshape(correct_label, (-1, num_classes)) # Calculate distance from actual labels using cross entropy cross_entropy = tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=correct_label_reshaped) # Take mean for total loss loss_op = tf.reduce_mean(cross_entropy, name="fcn_loss") # The model implements this operation to find the weights/parameters that would yield correct pixel labels train_op = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(loss_op, name="fcn_train_op") return logits, train_op, loss_opOptimize function
Step4
ここでは、エポック数、バッチサイズ、損失関数、オプティマイザ操作、入力画像、ラベル画像、学習率のプレースホルダなどの重要なパラメータを取り込むtrain_nn関数を定義します。 トレーニングプロセスでは、keep_probabilityを0.5に、learning_rateを0.001に設定します。 進歩を把握するためには、私達はまた訓練の間に損失を印刷します。P>
def train_nn(sess, epochs, batch_size, get_batches_fn, train_op, cross_entropy_loss, input_image, correct_label, keep_prob, learning_rate): keep_prob_value = 0.5 learning_rate_value = 0.001 for epoch in range(epochs): # Create function to get batches total_loss = 0 for X_batch, gt_batch in get_batches_fn(batch_size): loss, _ = sess.run(, feed_dict={input_image: X_batch, correct_label: gt_batch, keep_prob: keep_prob_value, learning_rate:learning_rate_value}) total_loss += loss; print("EPOCH {} ...".format(epoch + 1)) print("Loss = {:.3f}".format(total_loss)) print()ステップ5
最後に、それは私たちのネットを訓練する時間です! このrun関数では、最初にload_vgg、layers、optimize関数を使用してネットを構築します。 次に、train_nn関数を使用してネットを訓練し、レコードの推論データを保存します。パラメータについては、epochs=40、batch_size=16、num_classes=2、image_shape=(160,576)を選択します。 ドロップアウト=0.5とドロップアウト=0.75で2回の試行パスを実行した後、2回目の試行では、より良い平均損失でより良い結果が得られることがわか

トレーニングサンプル結果 完全なコードを見るには、このリンクをチェックしてください。https://gist.github.com/khanhnamle1994/e2ff59ddca93c0205ac4e566d40b5e88
この作品を楽しんで、私はそれがそれを共有し、知識を広めるのが大好きです。あなたは上の私たちの最新の記事に興味があるかもしれません:
- AWS Textract
- データ抽出
自動化のためのNanonetsの使用を開始
モデルを試 p>今すぐ試してみてください
