papスミア画像から子宮頸がんを検出するためのpapスミア解析ツール(PAT)
- 画像解析
- 画像取得
- 画像強調
- シーンセグメンテーション
- デブリ除去
- サイズ分析は、粒子のサイズ測定の範囲を決定するための手順 この領域は、細胞を破片から分離するために自動化された細胞診の分野で使用される最も基本的な特徴の一つです。 Pap塗抹標本の分析は細胞の特性に関する多くの予備知識のよく調査された分野である。 しかし、核領域評価における重要な変化の1つは、癌細胞が核サイズの大幅な増加を受けることである。 したがって、診断細胞を体系的に排除しない上限サイズ閾値を決定することは、はるかに困難であるが、探索空間を減少させる利点を有する。 本稿で提示された方法は、子宮頸部細胞の低いサイズと上部サイズしきい値に基づいています。 この手法の擬似コードをEqに示します。 3.ここで、Are area_{min}\le area_{roi}\le area_{max}\;then\;\left\langle{foreground}\right\rangle\;else\;\left\langle{background}\right\rangle、else else p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p表2から得られた\(area_{min}=625\,{\upmu\Text{M}}^{2}\)と\(area_{min}=625\,{\upmu\Text{M}}.{2}\)から得られた。
- 形状分析
- テクスチャ解析
- 特徴抽出
- 特徴選択
- defuzzification
- 分類評価
- GUI設計と統合
画像解析
ここで紹介したpapスミア画像から子宮頸がんを検出するためのpapスミア解析ツールの開発のための画像解析パイプラインを図1に示します。 1.

pap-スミア画像から子宮頸癌検出を達成するためのアプローチ
画像取得
アプローチは、三つのデータセットを用いて評価した。 データセット1は、Jantzenらによって調製されたHarlev pap-スミア画像の917個の単一細胞で構成されています。 . データセットには、フレームグラバーに接続された顕微鏡を使用して熟練した細胞病理学者によって0.201μ m/ピクセルの解像度で撮影されたpap-スミア画像が含 画像は、CHAMP商用ソフトウェアを使用してセグメント化され、表2に示すように異なる特性を有する七つのクラスに分類された。 これらの200の画像のトレーニングとテストのための717の画像に使用されました。
データセット2は、Norupらによって調製された497のフルスライドpap-スミア画像で構成されている。 . これらの200の画像のトレーニングとテストのための297の画像に使用されました。 さらに、分類器の性能は、Mbarara地域紹介病院(MRRH)から得られた60pap-スミア(30正常および30異常)のサンプルのデータセット3で評価された。 標本は、40×、0.95NAレンズと浜松ORCA-05G1.4Mpxモノクロカメラを装備したオリンパスBX51明視野顕微鏡を使用して撮像し、0.25μ mのピクセルサイズを8ビットグレーの深さで与えた。 次に、各画像を300の領域に分割し、各領域には200から400の細胞が含まれていました。 細胞病理学者の意見に基づいて、10,000の異なるpap-スミアスライドから派生した画像内のオブジェクトが選択され、そのうち8000は自由に横たわっている子宮頸部上皮細胞(正常なスミアから3000の正常な細胞と異常なスミアから5000の異常な細胞)であり、残りの2000は破片の物体であった。 このpap-semaセグメンテーションは,学習可能なWekaセグメンテーション-ツールキットを用いて画素レベルセグメンテーション分類器を構築した。
画像強調
コントラスト局所適応ヒストグラム等化(CLAHE)は、画像強調のためのグレースケール画像に適用されました。 CLAHEでは、画像のヒストグラムの所望の形状を指定するclip-limitの選択は、強化された画像の品質に重大な影響を与えるため、最も重要です。 クリップ限界の最適値は、Josephらによって定義された方法を使用して経験的に選択された。 . 最適なクリップ制限値は2です。0は、使用されるデータセットの暗い特徴を維持しながら、適切な画像強調を提供するために適切であると決定された。 グレースケールへの変換は、Eqを使用して実装されたグレースケール技術を使用して達成された。 1に定義される。画像=\左({\左({0.3*R}\右)+\左({0.59*G}\右)+\左({0.11*B}\右)}\右)、new
ここで、r=赤、G=緑、B=青の色は新しい画像に寄与します。
画像強調のためのCLAHEの適用は、核の黒ずみだけでなく、細胞質の境界が、2.0のクリップ制限を使用して容易に識別できるようになった画像強度を調整することにより、画像に顕著な変化をもたらした。
シーンセグメンテーション
シーンセグメンテーションを達成するために、ピクセルレベル分類器は、Trainable Wekaセグメンテーション(TWS)ツールキットを使用し Pap塗抹標本で観察される細胞の大部分は、驚くべきことに子宮頸部上皮細胞ではない。 さらに、白血球、赤血球および細菌の数の変化は、通常、明らかであるが、他の汚染細胞および微生物の数が少ないことが時々観察される。 しかし、pap-スミアは、表在性、中間性、傍基底性および基底性の四つの主要なタイプの扁平上皮頸部細胞を含み、そのうちの表在性および中間細胞は、従来のスメア 学習可能なWekaセグメンテーションを使用して、スライド上のさまざまなオブジェクトを識別し、セグ この段階では、ピクセルレベルの分類器は、Trainable Wekaセグメンテーション(TWS)ツールキットを使用して熟練した細胞病理学者の助けを借りて、細胞核、細胞質、背景およ これは、関心のある領域を通る線/選択を描画し、それらを特定のクラスに割り当てることによって達成されました。 線/選択の下のピクセルは、核、細胞質、背景および破片の代表であると取られた。
各クラス内で描画された輪郭は、各輪郭に属するピクセル数から派生した特徴ベクトル\(\mathop F\limits^{\to}\)を生成するために使用されました。\(\mathop F\limits^{\to}\)。\(\mathop F\limits^{\to}\)。\(\mathop F\limits^ 各画像からの特徴ベクトル(データセット1からの200およびデータセット2からの200)は、式によって定義された。 2.ここで、ni、Ci、BiおよびDiは、図に示すように、画像\(i\)の核、細胞質、背景および破片からのピクセル数である。 2.

トレーニング画像からの特徴ベクトルの生成
画像から抽出された各ピクセルは、その強度だけでなく、ピクセ0.201µ m2の区域。 分類器を訓練するための適切な特徴ベクトルを選択することは大きな課題であり,提案したアプローチにおける新しい課題であった。 ピクセルレベル分類器は、TWSからの合計226のトレーニング機能を使用してトレーニングされました。 分類器は、以下を含む一連のTWS訓練機能を使用して訓練された:(i)ノイズ低減:TWSツールキットの桑原と両側フィルタを使用して、ノイズ除去に関する分類器を訓練した。 これらは、エッジを維持しながらノイズを除去するための優れたフィルタであることが報告されている,(ii)エッジ検出:Sobelフィルタ,ヘッセ行列とGaborフィ: 平均,分散,中央値,最大値,最小値およびエントロピーフィルタをテクスチャフィルタリングに使用した。
デブリ除去
既存の自動化されたpapスミア分析システムの多くの現在の制限の主な理由は、多くの場合、複数の細胞やデブリを含むスラ これは、アルゴリズムの失敗を引き起こす可能性があり、より高い計算能力を必要とする。 サンプルは、血液細胞、重複して折り畳まれた細胞、細菌などの人工物で覆われており、細分化プロセスを妨げ、多数の疑わしい物体を生成します。 正常細胞と前癌性細胞とを区別するように設計された分類器は、通常、パップ塗抹標本に人工物が存在する場合に予測不可能な結果を生じることが示されている。 このツールでは、三相逐次排除スキームを使用して子宮頸部細胞を同定するための技術(図に示す)が提供されている。 3)が使用される。

デブリ除去のための三相シーケンシャル除去アプローチ
提案された三相除去スキームは、子宮頸部細胞である可能性が低いと判断された場合、pap-スミアからデブリを順次除去する。 このアプローチは、各段階でより低い次元の決定を可能にするので有益である。サイズ分析は、粒子のサイズ測定の範囲を決定するための一連の手順です。
サイズ分析は、粒子のサイズ測定の範囲を決定するための手順 この領域は、細胞を破片から分離するために自動化された細胞診の分野で使用される最も基本的な特徴の一つです。 Pap塗抹標本の分析は細胞の特性に関する多くの予備知識のよく調査された分野である。 しかし、核領域評価における重要な変化の1つは、癌細胞が核サイズの大幅な増加を受けることである。 したがって、診断細胞を体系的に排除しない上限サイズ閾値を決定することは、はるかに困難であるが、探索空間を減少させる利点を有する。 本稿で提示された方法は、子宮頸部細胞の低いサイズと上部サイズしきい値に基づいています。 この手法の擬似コードをEqに示します。 3.ここで、Are area_{min}\le area_{roi}\le area_{max}\;then\;\left\langle{foreground}\right\rangle\;else\;\left\langle{background}\right\rangle、else else p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p p表2から得られた\(area_{min}=625\,{\upmu\Text{M}}^{2}\)と\(area_{min}=625\,{\upmu\Text{M}}.{2}\)から得られた。
背景にあるオブジェクトは破片とみなされ、画像から破棄されます。 \(Area_{min}\)と\(area_{max}\)の間にあるパーティクルは、テクスチャと形状の分析の次の段階でさらに分析されます。
形状分析
パップ塗抹標本における物体の形状は、細胞と破片との間の分化における重要な特徴である。 形状記述検出のための多くの方法があり、これらには領域ベースおよび輪郭ベースのアプローチが含まれる。 領域ベースの方法はノイズには敏感ではありませんが、計算には集中的ですが、コンターベースの方法は計算には比較的効率的ですが、ノイズには敏感です。 本稿では、領域ベースの方法(perimeter2/area(P2A))が使用されています。 P2A記述子は、オブジェクトと円の類似性を記述するというメリットに基づいて選択されました。 これは、核が一般的にその外観が円形であるため、細胞核記述子としてよく適している。 P2Aは形状コンパクト性とも呼ばれ、Eqによって定義されます。 4.$ $C=\frac{{p^{2}}}{a}、$ $
ここで、Cは形状のコンパクトさの値であり、aは面積であり、pは核の周囲である。 破片は、訓練特徴(表2に示す)に従って、P2A値が0.97より大きいまたは0.15未満の物体であると仮定した。
テクスチャ解析
テクスチャは、核とデブリを区別することができる非常に重要な特徴です。 画像テクスチャは、画像の知覚されるテクスチャを定量化するために設計された一連のメトリックです。 Pap塗抹標本内では,平均核染色強度の分布はデブリ物体間の染色強度の変化よりもはるかに狭い。 この事実は、Zernikeモーメント(ZM)を使用して画像強度と色情報に基づいて破片を除去するための基礎として使用されました。 Zernikeモーメントは種々のパターン認識アプリケーションに使用され,ノイズに関してロバストであり,良好な再構成パワーを有することが知られている。 この研究では、Malmらによって提示されたZM。 関数\(f\left({r,\theta}\right)\)の繰り返しIを使って、サイズ\(m\times m\)の正方形画像\(I\left({x,y}\right)\)を中心とするディスク内の極座標で、次式で与えられる。 5が使用された。v a_{nl}=\frac{n+1}{\pi}\mathop\sum\limits_{x}\mathop\sum\limits_{y}v_{nl}v{*}\left({r、\theta}\right)、i私はleft a_{nl}v{*}\left({r、\theta}\right)、p私は5a_{nl}v{*}\left({r、\theta}\right)、p私はv a_{nl}v{*}\left({r、\theta}\right)、p私はa a_{nl}v{*}\left({r、\theta}\right)、p私はa a_{nl}v{*}\left({r、\theta}\right)、p私はa a_{nl}v{*}\left({r、\theta}\right)、p私はa a_{nl}v{*}\left({r、\theta}\right)、v_{nl}\left({r,\theta}\right)\)は、ゼルニケ多項式の複素共役を表します。 テクスチャ測度を生成するために、テクスチャ画像内の各ピクセルを中心とする\(A_{nl}\)からの大きさが平均化されます。
特徴抽出
分類アルゴリズムの成功は、画像から抽出された特徴の正確さに大きく依存する。 使用されたデータセット内のpap-スミアの細胞は、核と細胞質の大きさ、面積、形状、明るさなどの特性に基づいて七つのクラスに分割されます。 画像から抽出された特徴は、以前に他の人が使用した形態学的特徴を含んでいた。 この論文では、三つの幾何学的特徴(固体性、コンパクト性、偏心)と六つのテキスト特徴(平均、標準偏差、分散、滑らかさ、エネルギー、エントロピー)も核から抽出され、合計29の特徴が表3に示すように3つの特徴が得られた。
特徴選択
特徴選択は、最良の分類結果を与える抽出された特徴のサブセッ 抽出されたこれらの特徴の中には、ノイズを含むものもあれば、選択された分類器が他のものを利用しないものもあります。 したがって、機能の最適なセットは、おそらくすべての組み合わせを試して、決定する必要があります。 しかし、多くの特徴がある場合、可能な組み合わせは数が爆発し、これはアルゴリズムの計算の複雑さを増加させる。 特徴選択アルゴリズムは,フィルタ法,ラッパー法,埋め込み法に大別される。
このツールで使用される方法は、シミュレーテッドアニーリングとラッパーアプローチを組み合 このアプローチは提案されているが,ここでは,二重戦略ランダムフォレストアルゴリズムを用いて特徴選択の性能を評価した。 シミュレーテッドアニーリングは,与えられた関数の大域的最適を近似するための確率的手法である。 このアプローチは、機能の最適なセットが選択されることを確実にするのに適しています。 最適なセットの検索は、適応度の値によって導かれます。 シミュレートされたアニーリングが終了すると、フィーチャのすべての異なるサブセットが比較され、適者生存(つまり、最高のパフォーマンスを行うもの)が選 適応度値探索は,分類アルゴリズムの誤差を計算するためにk分割交差検証を使用したラッパーを用いて得た。 抽出された特徴からの異なる組み合わせが準備され、評価され、他の組み合わせと比較される。 次に、予測モデルを使用して、特徴の組み合わせを評価し、モデルの精度に基づいてスコアを割り当てます。 ラッパーによって与えられた適応度誤差は,シミュレーテッドアニーリングアルゴリズムによる適応度誤差として使用される。 ファジィC平均アルゴリズムをブラックボックスにラップし,そこから図に示すような様々な特徴の組み合わせに対する推定誤差を得た。 4.

fuzzy C-meansは、推定誤差が得られるブラックボックスにラップされます
Fuzzy C-meansは、データセット内のデータポイント区間(0-1)では、式に示すように。 6.$ $M_{ik}=\frac{1}{{\mathop\sum\nolimits_{j=1}c{c}\left({\frac{{d_{ik}}}{{d_{jk}}}}\right)){2|\left({q-1}\right)/{2}\left({q-1}\right)q{2}\left({q-1}\right)m{2}\left({q-1}\right)m{2}\left({q-1}\right)m{2}\left({q-1}\right)m{2}\left({q-1}\right)m{2}\)}} }} ,$$ここで、\(m_{ik}\)はデータ点kからクラスター中心iまでのメンバーシップ、\(d_{jk}\)はクラスター中心jからデータ点kまでの距離、q€はメンバーシップの強さを決定する指数です。 Fuzzy c-meansアルゴリズムは、Matlabのfuzzy toolboxを使用して実装されました。
defuzzification
ファジィC-meansアルゴリズムは、クラスターに含まれる情報と、その情報が分類にどのように使用されるかを教えてくれません。 ただし、データポイントに異なるクラスターのメンバシップがどのように割り当てられるかを定義し、このファジィメンバシップを使用してデータポイ これはdefuzzificationによって克服されます。 いくつかのdefuzzificationメソッドが存在します。 ただし、このツールでは、各クラスターにはイメージ内のすべてのクラスのファジーメンバーシップ(0-1)があります。 学習データは、それに最も近いクラスターに割り当てられます。 クラスター Aに属する各クラスのトレーニングデータの割合は、クラスターのメンバシップ、クラスター A=をさまざまなクラスに与えます。iはクラスター Aの封じ込め、jは他のクラスターの封じ込めです。 ファジィクラスターデファジフィケーションアルゴリズムを使用して、各クラスターのメンバシップ関数に強度測定を追加します。 ファジィ分割の非ファジィ化のための一般的なアプローチは,データ点kがクラスmに割り当てられているとき,そのメンバーシップ度\(m_{ik}\)がクラスタiに最大である場合に限り,最大メンバーシップ度原理の適用である。 Chuang et al. 近隣の会員状況を利用して各データポイントの会員状況を調整することを提案した。
提案したアプローチでは、ベイズ確率に基づくdefuzzification法を使用して、各データポイントのメンバシップ関数の確率モデルを生成し、モデルを画像に適用して分類情報を生成する。 確率モデルは、以下のように計算されます。
-
分割行列(クラスター)内の可能性分布を確率分布に変換します。
-
のようにデータ分布の確率モデルを構築します。
-
モデルを適用して、Eqを使用してすべてのデータポイントの分類情報を生成します。 7.$ $a_{i}=a_{i}*と$ $b_{j}=a_{i}*と$ $b_{j}=a_{j}*と$ $b_{j}=a_{j}*と$ $b_{j}=a_{j}*と$ $b_{j}=a_{j}*と$ $b_{j}=a_{j}*と$ $b_{j}=a_{j}*と$ $b_{j}=a_{j}*と$ $b_{j}=a_{j}*と$ $b_{j}=a_{j}*と=b_{j}=a_{j}*と=b_{j}=a_{j}=a_{j}=a_{j}=a_{j}=a_{j}=a_{j}=a_{j}=a_{j}=a_{j{a_{i}}\right)、i=0\ldots。c\)は\(A_{i}\)の事前確率であり、事前確率は常に各クラスの質量に比例する方法を使用して計算できます。
使用するクラスターの数は、構築されたモデルが可能な限り最良の方法でデータを記述できるようにするために決定されました。 選択したクラスター数が多すぎると、データ内のノイズが過剰に適合する危険性があります。 選択されたクラスターが少なすぎる場合、分類子が不十分な結果になる可能性があります。 そこで,交差検証テスト誤差に対するクラスタ数の解析を行った。 25クラスターの最適な数が達成され、オーバートレーニングは、クラスターのこれらの数の上に発生しました。 1のデファジー化指数。0930は、25個のクラスター、十倍の交差検証、および60回の再実行で得られ、分類器の構築のために18個の特徴のうち29個の特徴の合計が選択された特徴選択の適合度誤差を計算するために使用された。 選択された特徴は、核面積、核グレーレベル、核最短直径、核最長、核周囲、核内の最大値、核内の最小値、細胞質面積、細胞質グレーレベル、細胞質周囲、核対細胞質比、核偏心、核標準偏差、核グレーレベル分散、核グレーレベルエントロピーであった。; 核の相対的な位置;核の灰色レベルの平均および核の灰色の価値エネルギー。
分類評価
本稿では、FrybackとThornburyによって提案された画像診断システムの有効性の階層モデルを、表4に示すように、ツールの評価の指針として採
表4ツール評価基準 感度は、正しく識別された実際の陽性の割合を測定し、特異性は正しく識別された実際の陰性の割合を測定します。 感度および特異性は、Eq.2.2によって記述される。 8.sensitivity Sensitivity\;\left({TPR}\right)=\frac{TP}{TP+FN}、\;特異性\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\; tp left({TNR}\right)=\frac{TN}{TN+FP},tp
(8)ここで、tp=真陽性、fn=偽陰性、tn=真陰性、fp=偽陽性である。
GUI設計と統合
上記の画像処理方法はMatlabで実装され、図に示すJavaグラフィカルユーザーインターフェイス(GUI)を介して実行されます。 5. このツールには、パップスミア画像がロードされるパネルがあり、cytotechnicianは、シーンセグメンテーション(TWS分類器に基づく)、デブリ除去(三つの順次除去アプローチに基づく)、境界検出(必要に応じて、キャニーエッジ検出法を使用する)に適切な方法を選択し、その後、特徴の抽出ボタンを使用して特徴を抽出する。
図。 5 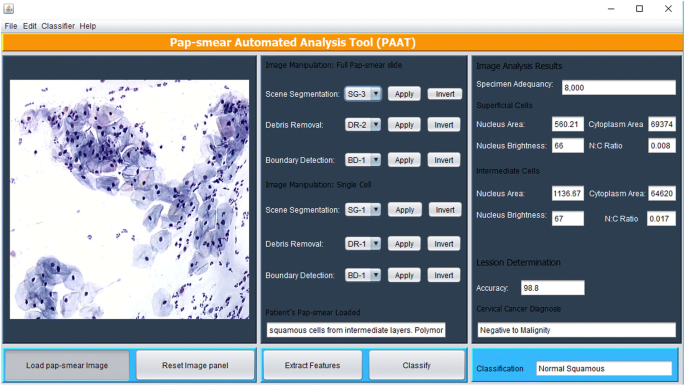
PATグラフィカルユーザインタフェース
このツールは、デブリ除去後に残ったすべてのオブジェク 特徴選択に記載されている18の特徴は、各オブジェクトから抽出され、分類方法に記載されているファジィC手段アルゴリズムを使用して各セルを分類するために使用される。 ランダムに抽出された表在細胞と中間細胞の特徴が画像解析結果パネルに表示されます。 特徴が抽出されると、cytotechnician(ユーザー)は分類ボタンを押すと、ツールは診断(悪性腫瘍に陽性または悪性腫瘍に陰性)を発し、トレーニングデータセットに従って子宮頸癌の7つのクラス/段階のいずれかに診断を分類します。
