seaborn.histplot¶
seaborn.histplot(data=None,*,x=None,y=None,hue=None,weights=None,stat=’count’,bins=’auto’,binwidth=None,binrange=None,discrete=None,cumulative=False,common_bins=True,common_norm=True,multiple=’layer’,element=’bars’,fill=true,shrink=1,kde=false,kde_kws=none,line_kws=none,thresh=0,pthresh=none,pmax=none,cbar=false,cbar_Ax=none,Cbar_Kws=none,Palette=none,hue_order=none,hue_norm=None,color=none,Log_scale=None,legend=True,ax=none,**kwargs)¶
一変量プロットまたは一変量プロットまたは一変量プロットまたは一変量プロットまたは一変量プロットまたは一変量プロットまたは一変量プロットまたは一変量プロットまたは一変量プロットまたは一変量プロットまたは一変量プロットまたは一変量プロットまたは一変量プロットまたは一変量プロットまたは一変量プロットまたは一変量プロットまたは一変量プロットまたは一変量プロットまたは一変量プロットまたは一変量プロットまたは一変量プロットまたは一変量プロットまたは一変量プロットまたは一変量プロットまたは一変量プロットまたは一変量プロットまたは一変量プロットまたは一変量プロットまたは一変量プロットまたは一変量プロットまたは一変量プロットまたは一変量プロットの分布を示す二変量ヒストグラム ——-
ヒストグラムは、独立したビン内にある観測値の数を数えることによって、一つ以上の変数の分布を表す古典的な可視化ツールです。
この関数は、各ビン内で計算された統計量をestimatefrequency、密度、または確率質量に正規化し、kdeplot()と同様に、カーネル密度推定値を使用して得られた滑らかな曲線を追加することができます。
詳細については、ユーザーガイドに記載されています。
パラメータデータpandas.DataFramenumpy.ndarray、マッピング、またはシーケンス
入力データ構造。 名前付き変数に割り当てることができるベクトルの長い形式のコレクション、または内部的に再整形されるワイド形式のデータセットのいずれか。
x、yvectorsまたはキーdata
x軸とy軸上の位置を指定する変数。
huevectorまたはキーdata
プロット要素の色を決定するためにマップされたセマンティック変数。
weightsvectorまたはkey indata
指定されている場合、対応するデータポイントの寄与をこれらの要因で各ビンのカウントに重み付けします。
stat{“count”,”frequency”,”density”,”probability”}
各ビンで計算する統計量を集計します。
-
count観測値の数を示しています -
frequencyビン幅で割った観測値の数を示しています -
densityhistogram is1 -
probabilityバーの高さの合計が1になるようにカウントを正規化します
binsstr、number、vector、またはそのような値のペア
参照ルールの名前、ビンの数、numpy.histogram_bin_edges()に渡されます。
binwidthnumberまたは数字のペア
各ビンの幅は、binsbinrangeで使用できます。
数字のbinrangepairまたはペアのペア
ビンエッジの最低値と最高値;どちらかを使用することができますbinsbinwidth。 デフォルトはdata extremesです。
discretebool
Trueの場合、デフォルトはbinwidth=1になり、バーを描画して、対応するデータポイントに反映されるようにします。 これにより、離散(整数)データを使用するときに別の方法で現れる”ギャップ”が回避されます。
cumulativebool
trueの場合、ビンの増加に応じて累積カウントをプロットします。
common_binsbool
trueの場合、セマンティック変数が多重プロットを生成するときに同じビンを使用します。 参照ルールを使用してビンを決定する場合は、完全なデータセットで計算されます。
common_normbool
trueの場合、正規化された統計量を使用すると、正規化は完全なデータセットに適用されます。 それ以外の場合は、各ヒストグラムを個別に正規化します。
multiple{“layer”,”dodge”,”stack”,”fill”}
セマンティックマッピングがサブセットを作成するときに複数の要素を解決するアプローチ。単変量データにのみ関連します。
要素{“bars”,”step”,”poly”}
ヒストグラム統計量を視覚的に表現します。単変量データにのみ関連します。
fillbool
Trueの場合、ヒストグラムの下のスペースを入力します。単変量データにのみ関連します。
shrinknumber
各バーの幅をbinwidthに対してこの係数でスケーリングします。単変量データにのみ関連します。
kdebool
Trueの場合、分布を滑らかにするためにカーネル密度推定値を計算し、プロット上に(1つ以上の)線として表示します。単変量データにのみ関連します。
kde_kwsdict
kdeplot()のように、KDEの計算を制御するパラメータ。
line_kwsdict
KDE視覚化を制御するパラメータ。matplotlib.axes.Axes.plot()に渡されます。
threshnumberまたはNone
この値以下の統計量を持つセルは透明になります。二変量データにのみ関連します。pthreshnumberまたはNone
Likethreshですが、集計数(または使用されている場合は他の統計)を持つセルが合計のこの割合まで一致するような値は、一致しません。
pmaxnumberまたはNone
カラーマップの飽和点を、以下のセルが合計カウント(または他の統計を使用する場合)のこの割合をconstistuteとする値に設定する値。
cbarbool
Trueの場合、二変量プロットのカラーマッピングに注釈を付けるためにcolorbarを追加します。注:現在、hue変数wellを持つプロットはサポートされていません。
cbar_axmatplotlib.axes.Axes
カラーバーの既存の軸。p>cbar_kwsdict
matplotlib.figure.Figure.colorbar()に渡される追加のパラメータ。
palettestring、list、dict、またはmatplotlib.colors.Colormap
マッピングするときに使用する色を選択する方法huecolor_palette()に渡されます。 リストまたはdict値は単純なカテゴリカルマッピングですが、colormapオブジェクトは数値マッピングを意味します。
文字列のhue_ordervector
のカテゴリレベルの処理とプロットの順序を指定しますhueセマンティック。
hue_normtupleまたはmatplotlib.colors.Normalize
データ単位の正規化範囲を設定する値のペアまたはデータ単位から間隔にマップするオブジェクト。 Usageimplies数値マッピング。
カラーmatplotlib color
色相マッピングが使用されていない場合の単一の色の指定。 それ以外の場合、theplotはmatplotlibプロパティcycleにフックしようとします。
log_scaleboolまたはnumber、またはboolまたはnumbersのペア
givenベース(デフォルトは10)でデータ軸(または二変量データを持つ軸)にログスケールを設定し、ログ空間でKDEを評価します。
legendbool
Falseの場合、セマンティック変数の凡例を抑制します。
axmatplotlib.axes.Axes
プロットの既存の軸。 それ以外の場合は、matplotlib.pyplot.gca()を内部的に呼び出します。
kwargs
その他のキーワード引数は、次のいずれかのmatplotlibfunctionsに渡されます:
-
matplotlib.axes.Axes.bar()(univariate, element=”bars”) -
matplotlib.axes.Axes.fill_between()(univariate, other element, fill=True) -
matplotlib.axes.Axes.plot()(univariate, other element, fill=False) -
matplotlib.axes.Axes.pcolormesh()(bivariate)
Returnsmatplotlib.axes.Axes
The matplotlib axes containing the plot.
See also
displot
Figure-level interface to distribution plot functions.
kdeplot
カーネル密度推定を使用して一変量または二変量分布をプロットします。
rugplot
x軸および/またはy軸に沿って各観測値に目盛りをプロットします。
ecdfplot
経験的累積分布関数をプロットします。p>jointplot
一変量周辺分布を持つ二変量プロットを描画します。
ノート
ヒストグラムを計算してプロットするためのビンの選択は、可視化から引き出すことができる洞察に実質的な影響を及ぼす可能性が ビンが大きすぎると、重要なフィーチャが消去される可能性があります。一方、小さすぎるビンはrandomvariabilityによって支配され、真の基礎となる分布の形状を不明瞭にする可能性があります。 デフォルトのビンサイズは、サンプルサイズと分散に依存する参照ルールを使用して決定されます。 これは多くの場合(つまり、「行儀の良い」データで)うまく機能しますが、他の場合は失敗します。 あなたが重要な何かを見逃していないことを確認するために、異なるビンのサイズを試すことは常に良いことです。この関数を使用すると、使用するビンの総数、各ビンの幅、またはビンが壊れる特定の場所を設定するなど、さまざまな方法でビンを指定できます。p>
例
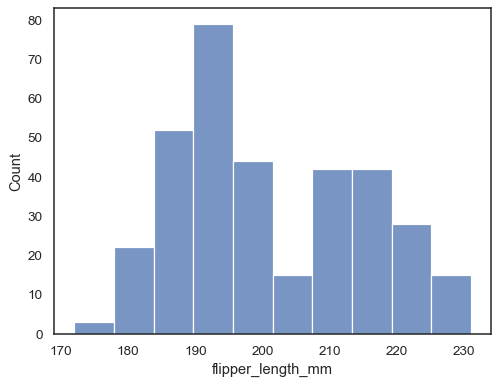
変数をxに代入して、x軸に沿った一変量分布をプロットします。
penguins = sns.load_dataset("penguins")sns.histplot(data=penguins, x="flipper_length_mm")
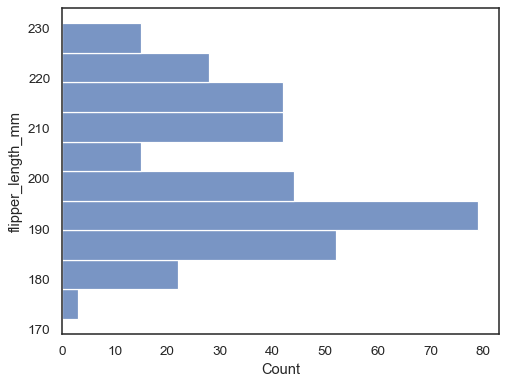
sns.histplot(data=penguins, y="flipper_length_mm")
ヒストグラムがデータをどのように表しているかを確認するには、異なるビン幅を指定します。
sns.histplot(data=penguins, x="flipper_length_mm", binwidth=3)
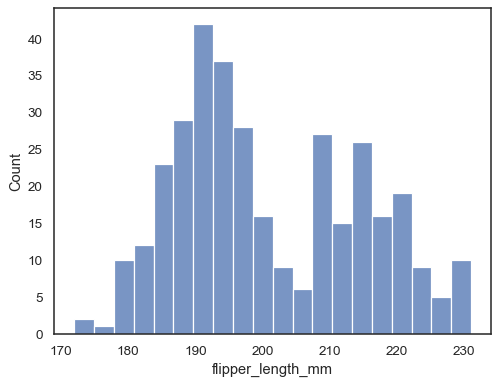
sns.histplot(data=penguins, x="flipper_length_mm", bins=30)
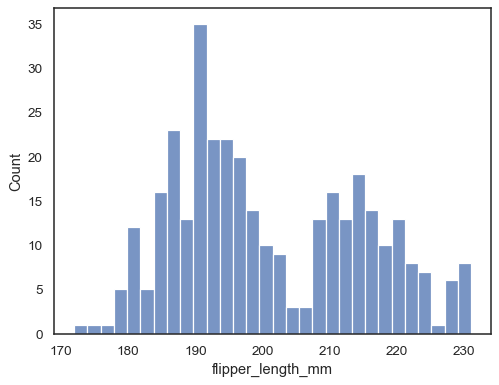
ヒストグラムを滑らかにするためにカーネル密度推定値を追加し、分布の形状に関する補完的な情報を提供します。
sns.histplot(data=penguins, x="flipper_length_mm", kde=True)
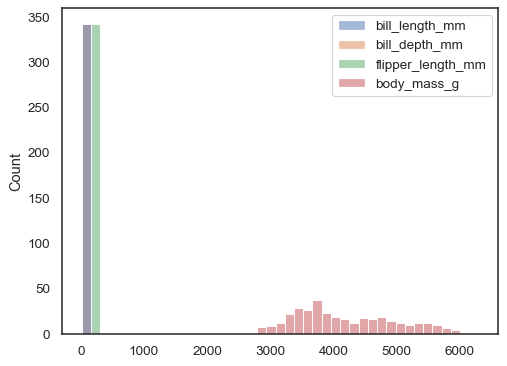
xyも割り当てられていない場合、データセットはワイド形式として扱われ、各数値列に対してヒストグラムが描画されます。
sns.histplot(data=penguins)
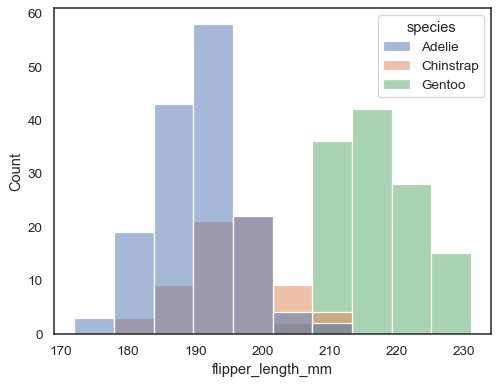
それ以外の場合は、長い形式のデータセットから複数のヒストグラムを描画することができます。
sns.histplot(data=penguins, x="flipper_length_mm", hue="species")
複数の分布をプロットするデフォルトのアプローチは、それらを”レイヤー”することですが、それらを”スタック”することもできます:
sns.histplot(data=penguins, x="flipper_length_mm", hue="species", multiple="stack")
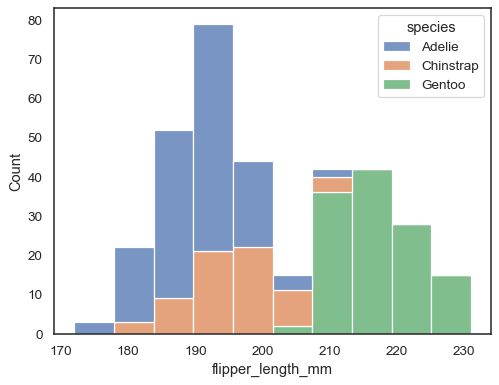
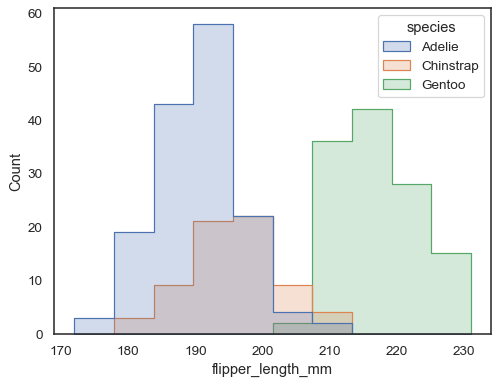
重なり合うバーは視覚的に解決するのが難しい場合があります。 別のアプローチは、ステップ関数を描画することです:
sns.histplot(penguins, x="flipper_length_mm", hue="species", element="step")
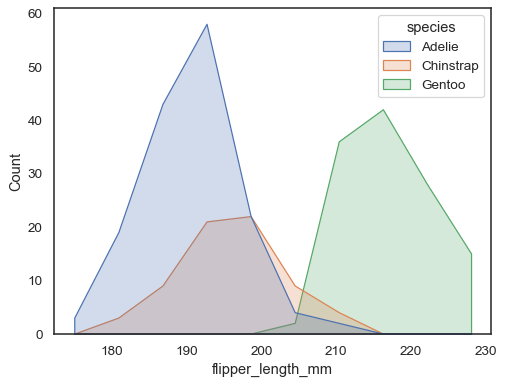
多角形を描画することで、棒からさらに遠くに移動することができます各ビンの中央に垂直。 これにより、分布の形状を簡単に見ることができますが、注意して使用してください:ヒストグラムを見ている視聴者はあまり目立たなくなります:
sns.histplot(penguins, x="flipper_length_mm", hue="species", element="poly")
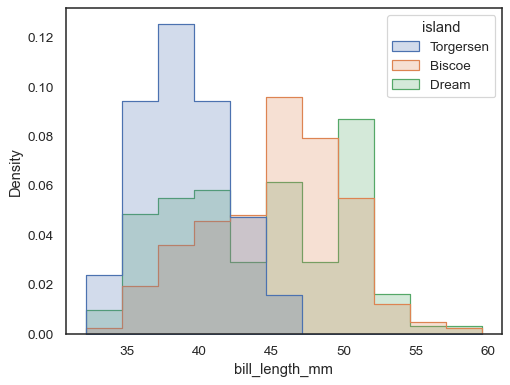
サイズが大きく異なるサブセットの分布を比較するには、独立した密度正規化を使用します。
sns.histplot( penguins, x="bill_length_mm", hue="island", element="step", stat="density", common_norm=False,)
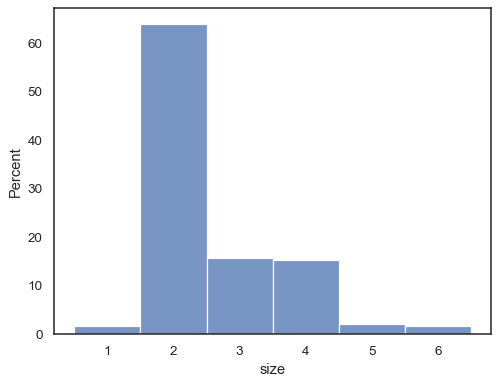
tips = sns.load_dataset("tips")sns.histplot(data=tips, x="size", stat="probability", discrete=True)
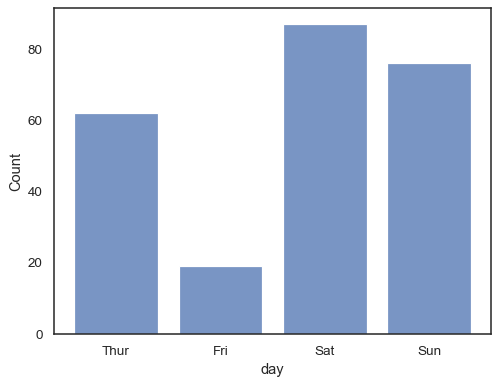
sns.histplot(data=tips, x="day", shrink=.8)
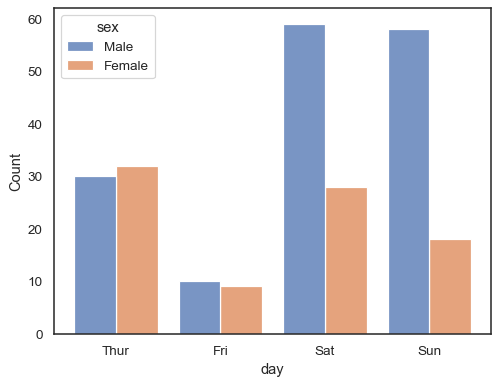
離散データでhueセマンティックを使用する場合、レベルを”ダッジ”することは意味があります。
sns.histplot(data=tips, x="day", hue="sex", multiple="dodge", shrink=.8)
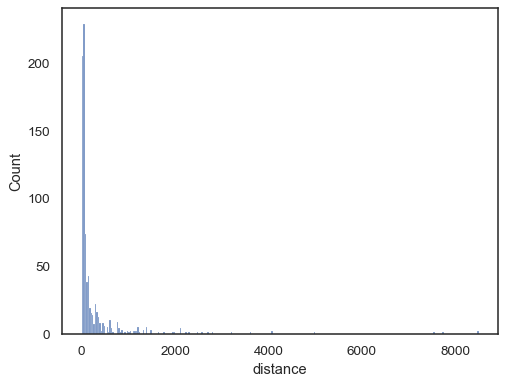
実世界のデータは、多くの場合、歪んでいます。 大きく歪んだ分布の場合は、ログ空間でビンを定義することをお勧めします。 比較:
planets = sns.load_dataset("planets")sns.histplot(data=planets, x="distance")
To the log-scale version:
sns.histplot(data=planets, x="distance", log_scale=True)
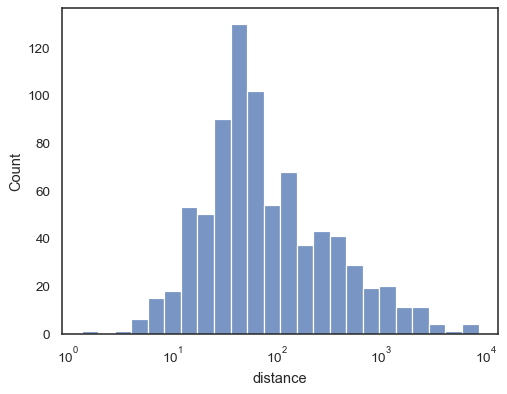
There are also a number of options for how the histogram appears. Youcan show unfilled bars:
sns.histplot(data=planets, x="distance", log_scale=True, fill=False)
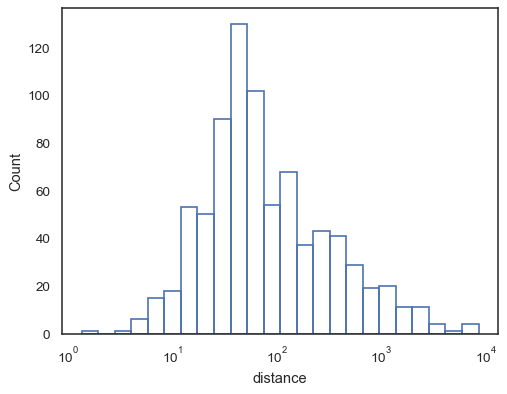
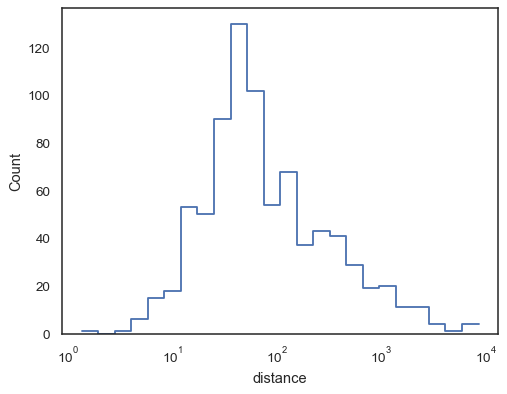
Or an unfilled step function:
sns.histplot(data=planets, x="distance", log_scale=True, element="step", fill=False)
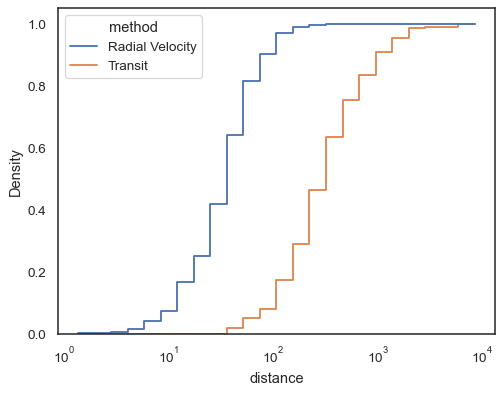
sns.histplot( data=planets, x="distance", hue="method", hue_order=, log_scale=True, element="step", fill=False, cumulative=True, stat="density", common_norm=False,)
xyの両方が割り当てられている場合、二変量ヒストグラムが計算され、ヒートマップとして表示されます。
sns.histplot(penguins, x="bill_depth_mm", y="body_mass_g")
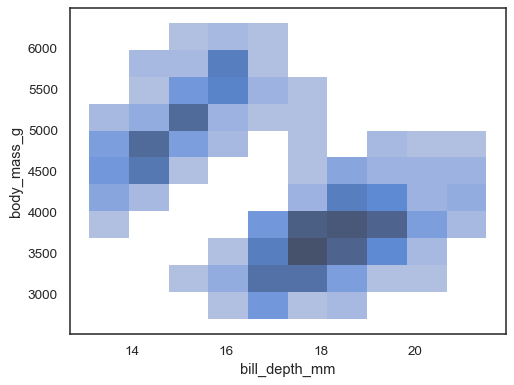 変数も割り当てることができます。
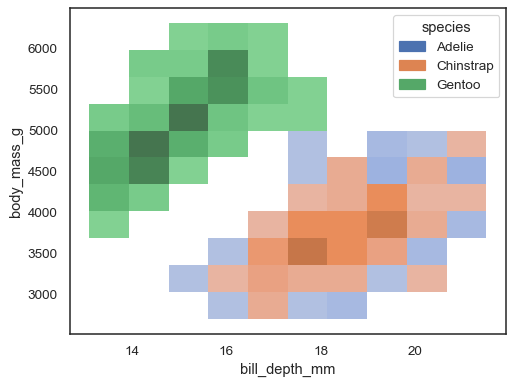
変数も割り当てることができます。
sns.histplot(penguins, x="bill_depth_mm", y="body_mass_g", hue="species")
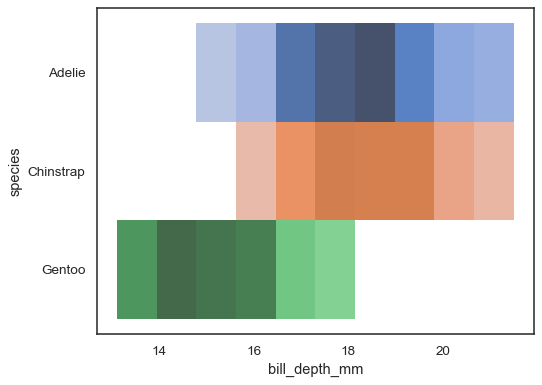
複数のカラーマップは、変数のいずれかがisdiscrete:
sns.histplot( penguins, x="bill_depth_mm", y="species", hue="species", legend=False)
二変量ヒストグラムは、タプルを使用してパラメータ化する、その一変量対応として計算のための同じオプションのすべてを受け入れますxy独立して:
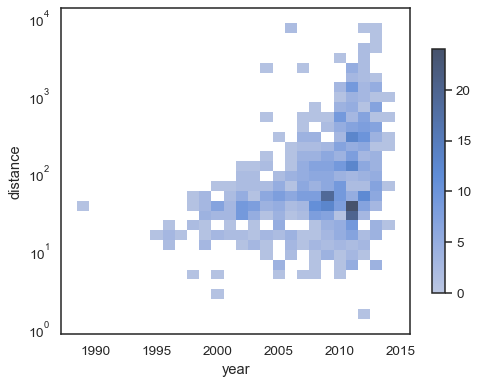
sns.histplot( planets, x="year", y="distance", bins=30, discrete=(True, False), log_scale=(False, True),)
sns.histplot( planets, x="year", y="distance", bins=30, discrete=(True, False), log_scale=(False, True),)
sns.histplot( planets, x="year", y="distance", bins=30, discrete=(True, False), log_scale=(False, True),)
sns.histplot( planets, x="year", y="distance", bins=30, discrete=(True, False), log_scale=(False, True),)
sns.histplot( planets, x="year", y="distance", bins=30, discrete=(True, False), log_scale=(False, True),)
sns.histplot( planets, x="year", y="distance", bins=30, discrete=(True, False), log_scale=(False, True), thresh=None,)
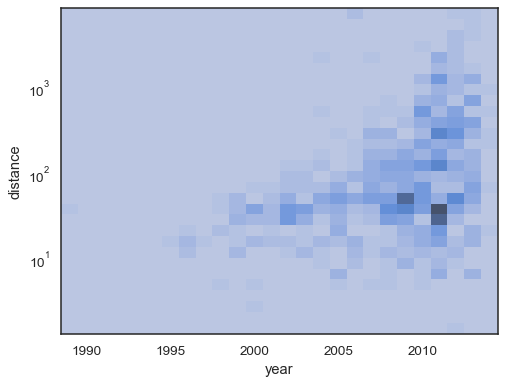
sns.histplot( planets, x="year", y="distance", bins=30, discrete=(True, False), log_scale=(False, True), pthresh=.05, pmax=.9,)
カラーマップに注釈を付けるには、カラーバーを追加します。
sns.histplot( planets, x="year", y="distance", bins=30, discrete=(True, False), log_scale=(False, True), cbar=True, cbar_kws=dict(shrink=.75),)