T検定
t検定は、2つのグループの平均が互いに統計的に異なるかどうかを評価します。 この分析は、2つのグループの平均を比較したいときに適しており、特にテスト後のみの2グループ無作為化実験計画の分析として適しています。
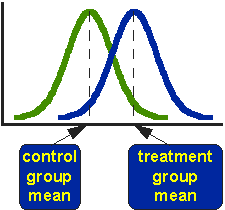
図1。 処理されたグループと比較グループのテスト後の値の理想化された分布。
図1は、研究における処理された(青)グループと対照(緑)グループの分布を示しています。 実際には、図は理想化された分布を示しています–実際の分布は、通常、ヒストグラムまたは棒グラフで描かれます。 この図は、対照群および治療群の平均がどこにあるかを示す。 T検定が対応する問題は、平均が統計的に異なるかどうかです。2つのグループの平均値が統計的に異なると言うのはどういう意味ですか?
図2に示す3つの状況を考えてみましょう。 3つの状況について最初に気づくことは、平均の違いが3つすべてで同じであるということです。 しかし、あなたはまた、3つの状況が同じように見えないことに気づくべきです–彼らは非常に異なる物語を伝えます。 上の例は、各グループ内のスコアの中程度の変動を持つケースを示しています。 第二の状況は、高い変動性のケースを示しています。 第三は、変動性が低い場合を示しています。 明らかに、我々は、2つのグループが底部または低変動性の場合に最も異なっているか、または区別されると結論付けるであろう。 どうして? なぜなら、2つの鐘形の曲線の間には比較的重なり合いが少ないからである。 高い変動性の場合,二つのベル形状の分布が非常に重なるため,群差は最も顕著ではない。
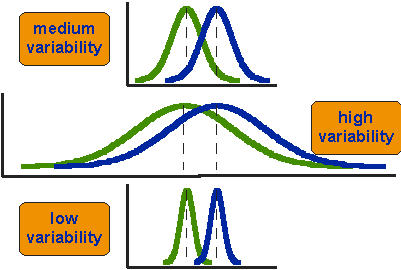
図2。 平均間の違いのための三つのシナリオ。
これは非常に重要な結論に私達を導く:私達が2つのグループのためのスコア間の相違を見ているとき、私達はスコアの広がりか可変性に関連して T検定はこれだけを行います。
t検定の統計分析
t検定の式は比です。 比率の上部は、2つの平均または平均の差にすぎません。 下の部分は、スコアの変動性または分散の尺度です。 この式は本質的に研究における信号対雑音のメタファーの別の例です:平均の違いは、この場合、私たちのプログラムまたは治療法がデータに導入された 図3は、t検定の式と、分子と分母が分布にどのように関連しているかを示しています。
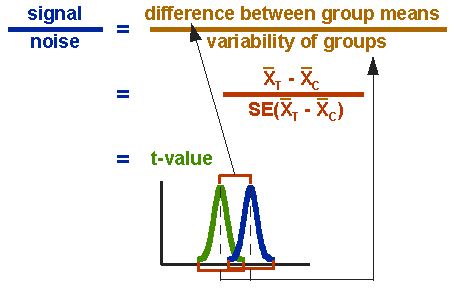
図3。 T検定の式。式の上部は簡単に計算できます–平均の差を見つけるだけです。
式の上部は簡単に計算できます。
式の上部は簡単に計算できます-平均の差 下の部分は差の標準誤差と呼ばれます。 それを計算するために、各グループの分散を取り、それをそのグループの人数で除算します。 これらの2つの値を追加し、それらの平方根を取ります。 平均間の差の標準誤差の具体的な式は次のとおりです:variance\bar{x}_T-\bar{x}_C)=\sqrt{\frac{\textrm{var}_T}{n_t}+\frac{\textrm{var}_C}{n_c}}variance
分散は単純に標準偏差の二乗であることを覚えておいてください。t t=\frac{\bar{x}_T-\bar{x}_C}{\sqrt{\frac{\textrm{var}_T}{n_t}+\frac{\textrm{var}_c}{n_c}}}$ $
tt-valueあなたは比率がグループ間の差が偶然発見されていない可能性が高いと言うのに十分な大きさであるかどうかをテストするために有意性のテーブルでそれを調べなければなりません。 有意性をテストするには、リスクレベル(アルファレベルと呼ばれる)を設定する必要があります。 ほとんどの社会調査では、”経験則”はアルファレベルを.05に設定することです。 これは、たとえ何もなかったとしても(つまり、「偶然」によって)、平均の間に統計的に有意な差を見つけることができることを意味します。 また、テストの自由度(df)を決定する必要があります。 t-test2を引いたものです。 アルファレベル、df、およびttt-値が有意であるのに十分な大きさである。 そうであれば、2つのグループの平均間の差が異なると結論付けることができます(変動性が与えられていても)。 幸いなことに、統計的なコンピュータプログラムは、日常的に有意性テスト結果を印刷し、あなたのテーブルでそれらを検索する手間を省きます。
t検定、一方向分散分析(ANOVA)、回帰分析の形式は数学的に同等であり(テスト後のみのランダム化実験計画の統計分析を参照)、同じ結果が得られます。