a pap-smear analysis tool (PAT) for detection of cervical cancer from pap-smear images
Image analysis
the image analysis pipeline for the development of a pap-smear analysis tool for the detection of cervical cancer from pap-smear prezentowany w niniejszym artykule jest przedstawiony na Fig. 1.

podejście do wykrywania raka szyjki macicy z rozmazów pap
pozyskiwanie obrazu
podejście oceniono za pomocą trzech metod: zbiory danych. Zestaw danych 1 składa się z 917 pojedynczych komórek obrazów rozmazów pap Harlev przygotowanych przez Jantzen et al. . Zbiór danych zawiera obrazy rozmazów pap wykonane z rozdzielczością 0,201 µm / piksel przez wykwalifikowanych cytopatologów przy użyciu mikroskopu połączonego z chwytakiem ramki. Obrazy zostały podzielone przy użyciu komercyjnego oprogramowania CHAMP, a następnie podzielone na siedem klas o odrębnych cechach, jak pokazano w tabeli 2. Z tych 200 obrazów wykorzystano do treningu, a 717 do testów.
zestaw danych 2 składa się z 497 pełnych obrazów rozmazów pap przygotowanych przez Norup et al. . Z tych 200 obrazów wykorzystano do treningu i 297 obrazów do testów. Ponadto skuteczność klasyfikatora oceniono na podstawie zbioru danych 3 próbek 60 rozmazów pap (30 prawidłowych i 30 nieprawidłowych) uzyskanych z Mbarara Regional Referral Hospital (MRRH). Próbki zostały sfotografowane przy użyciu mikroskopu Olympus BX51 z obiektywem 40×, 0,95 NA i monochromatycznym aparatem Hamamatsu ORCA-05G 1,4 Mpx, co daje rozmiar piksela 0,25 µm z 8-bitową głębią szarości. Każdy obraz został następnie podzielony na 300 obszarów, a każdy obszar zawierał od 200 do 400 komórek. Na podstawie opinii cytopatologów wybrano 10 000 obiektów w obrazach pochodzących z 60 różnych slajdów rozmazów pap, z których 8000 to wolne leżące komórki nabłonka szyjki macicy (3000 normalnych komórek z normalnych rozmazów i 5000 nieprawidłowych komórek z nieprawidłowych rozmazów), a pozostałe 2000 to obiekty szczątkowe. Ta segmentacja pap-smear została osiągnięta przy użyciu Trainable Weka Segmentation toolkit do skonstruowania klasyfikatora segmentacji na poziomie pikseli.
image enhancement
do obrazu w skali szarości zastosowano lokalną adaptacyjną korektę histogramu (CLAHE) w celu poprawy obrazu . W CLAHE wybór clip-limit, który określa pożądany kształt histogramu obrazu, jest najważniejszy, ponieważ wpływa krytycznie na jakość ulepszonego obrazu. Optymalną wartość clip-limit wybrano empirycznie za pomocą metody zdefiniowanej przez Josepha i wsp. . Optymalna wartość graniczna klipu 2.0 uznano za odpowiednie do zapewnienia odpowiedniej poprawy obrazu przy jednoczesnym zachowaniu ciemnych funkcji używanych zestawów danych. Konwersja do skali szarości została osiągnięta przy użyciu techniki skali szarości zaimplementowanej przy użyciu korektora. 1 zgodnie z definicją w .
gdzie R = czerwony, G = zielony i B = niebieski kolor przyczynia się do nowego obrazu.
zastosowanie CLAHE do poprawy obrazu spowodowało zauważalne zmiany w obrazach poprzez dostosowanie intensywności obrazu, gdzie zaciemnienie jądra, jak również granice cytoplazmy, stało się łatwe do zidentyfikowania za pomocą granicy klipu 2,0.
segmentacja sceny
aby uzyskać segmentację sceny, opracowano klasyfikator poziomu pikseli przy użyciu zestawu narzędzi Trainable WEKA Segmentation (TWS). Większość komórek obserwowanych w rozmazie pap nie jest zaskakująco komórki nabłonka szyjki macicy . Ponadto zwykle obserwuje się różną liczbę leukocytów, erytrocytów i bakterii, podczas gdy czasami obserwuje się niewielką liczbę innych zanieczyszczających komórek i mikroorganizmów. Jednak pap-wymaz zawiera cztery główne typy komórek płaskonabłonkowych szyjki macicy-powierzchowne, pośrednie, parabasal i basal – z których powierzchowne i pośrednie komórki stanowią przeważającą większość w konwencjonalnym wymazu; stąd te dwa typy są zwykle używane do konwencjonalnej analizy wymazu pap . Do identyfikacji i segmentacji różnych obiektów na szkiełku użyto wytrenowanej segmentacji Weka. Na tym etapie klasyfikator poziomu pikseli został przeszkolony w zakresie jąder komórkowych, cytoplazmy, tła i identyfikacji zanieczyszczeń przy pomocy wykwalifikowanego cytopatologa przy użyciu Zestawu Narzędzi Do Trainable Weka Segmentation (TWS). Osiągnięto to poprzez rysowanie linii / selekcji poprzez obszary zainteresowania i przypisywanie ich do konkretnej klasy. Piksele pod liniami / selekcją uznano za reprezentatywne dla jąder, cytoplazmy, tła i gruzu.
kontury narysowane w każdej klasie zostały użyte do wygenerowania wektora funkcji, \(\mathop f\limits^{ \to}\), który został wyprowadzony z liczby pikseli należących do każdego konturu. Wektor funkcji z każdego obrazu (200 z Dataset 1 i 200 z Dataset 2) został zdefiniowany przez Eq. 2.
gdzie Ni, Ci, Bi i Di to liczba pikseli z jądra, cytoplazmy, tła i resztek obrazu \(i\), jak pokazano na Fig. 2.

generowanie wektora funkcji z obrazów treningowych
każdy piksel wyodrębniony z obrazu reprezentuje nie tylko jego intensywność, ale także zestaw funkcji obrazu, które zawierają wiele informacji, w tym tekstury, obramowania i kolor w pikselu o powierzchni 0,201 µm2. Wybór odpowiedniego wektora funkcji do szkolenia klasyfikatora był wielkim wyzwaniem i nowatorskim zadaniem w proponowanym podejściu. Klasyfikator poziomu pikseli został przeszkolony przy użyciu łącznie 226 funkcji szkoleniowych TWS. Klasyfikator został przeszkolony przy użyciu zestawu funkcji szkoleniowych TWS, które obejmowały: (i) redukcję szumów: Kuwahara i dwustronne filtry w zestawie narzędzi TWS zostały użyte do szkolenia klasyfikatora w zakresie usuwania hałasu. Stwierdzono, że są to doskonałe filtry do usuwania szumów przy jednoczesnym zachowaniu krawędzi, (ii) wykrywanie krawędzi: Filtr Sobel, Matryca Hessian i filtr Gabor zostały użyte do szkolenia klasyfikatora w zakresie wykrywania granic na obrazie oraz (iii) filtrowanie tekstur: Do filtrowania tekstur użyto filtrów średniej, wariancji, mediany, maksimum, minimum i entropii.
usuwanie gruzu
głównym powodem obecnych ograniczeń wielu istniejących zautomatyzowanych systemów analizy rozmazu pap jest to, że walczą one o przezwyciężenie złożoności struktur rozmazu pap, próbując przeanalizować slajd jako całość, które często zawierają wiele komórek i zanieczyszczeń. Może to spowodować awarię algorytmu i wymaga większej mocy obliczeniowej . Próbki są pokryte artefaktami-takimi jak komórki krwi, nakładające się i złożone komórki i bakterie—które utrudniają procesy segmentacji i generują dużą liczbę podejrzanych obiektów. Wykazano, że klasyfikatory zaprojektowane w celu rozróżnienia między normalnymi komórkami a komórkami przedrakowymi zwykle dają nieprzewidywalne wyniki, gdy artefakty istnieją w rozmazie pap . W tym narzędziu technika identyfikacji komórek szyjki macicy za pomocą trójfazowego sekwencyjnego schematu eliminacji (przedstawionego na Fig. 3) jest używany.

trójfazowe sekwencyjne podejście do usuwania zanieczyszczeń
proponowany trójfazowy schemat eliminacji kolejno usuwa zanieczyszczenia z rozmazu pap, Jeśli prawdopodobnie jest to komórka szyjki macicy. Takie podejście jest korzystne, ponieważ pozwala na podjęcie decyzji o niższym wymiarze na każdym etapie.
analiza wielkości
Analiza wielkości jest zbiorem procedur do wyznaczania zakresu pomiarów wielkości cząstek . Obszar ten jest jedną z najbardziej podstawowych cech stosowanych w dziedzinie cytologii automatycznej do oddzielania komórek od zanieczyszczeń. Analiza pap-rozmaz jest dobrze zbadaną dziedziną z dużą wiedzą na temat właściwości komórek . Jednak jedną z kluczowych zmian w ocenie obszaru jądra jest to, że komórki nowotworowe ulegają znacznemu zwiększeniu wielkości jądra . Dlatego określenie górnego progu wielkości, który nie wyklucza systematycznie komórek diagnostycznych, jest znacznie trudniejsze, ale ma tę zaletę, że zmniejsza przestrzeń wyszukiwania. Metoda przedstawiona w niniejszej pracy opiera się na Dolnym i górnym progu wielkości komórek szyjki macicy. Pseudo kod dla tego podejścia jest pokazany w Eq. 3.
where \(Area_{max} = 85,267\,{\upmu \text{m}}^{2}\) i \(Area_{min} = 625\,{\upmu \text{m}}^{2}\) pochodzące z tabeli 2.
obiekty w tle są uważane za gruzy, a tym samym odrzucane z obrazu. Cząstki, które mieszczą się pomiędzy \(Area_{min}\) i \(Area_ {max}\) są dalej analizowane podczas kolejnych etapów analizy tekstury i kształtu.
Analiza kształtu
kształt obiektów w rozmazie pap jest kluczową cechą w różnicowaniu między komórkami a szczątkami . Istnieje wiele metod wykrywania opisu kształtu, które obejmują podejścia oparte na regionie i konturze . Metody oparte na regionach są mniej wrażliwe na hałas, ale bardziej intensywne obliczeniowo, podczas gdy metody oparte na konturach są stosunkowo wydajne do obliczania, ale bardziej wrażliwe na hałas . W artykule wykorzystano metodę regionalną (perymetr2 / obszar (P2A)). Deskryptor P2A został wybrany ze względu na to, że opisuje podobieństwo obiektu do okręgu. To sprawia, że dobrze nadaje się jako deskryptor jądra komórkowego, ponieważ jądra są na ogół okrągłe w swoim wyglądzie. P2A jest również określany jako zwartość kształtu i jest zdefiniowany przez Eq. 4.
gdzie C jest wartością zwartości kształtu, a jest obszarem, a p jest obwodem jądra. Przyjęto, że gruz to obiekty o wartości P2A większej niż 0,97 lub mniejszej niż 0,15 zgodnie z cechami treningowymi (przedstawionymi w tabeli 2).
Analiza Tekstury
tekstura jest bardzo ważną cechą charakterystyczną, która może odróżniać jądra od gruzu. Tekstura obrazu to zestaw wskaźników służących do kwantyfikacji postrzeganej tekstury obrazu . W rozmazie pap rozkład średniej intensywności plam jądrowych jest znacznie węższy niż zmienność intensywności plam wśród obiektów gruzu . Fakt ten posłużył jako podstawa do usuwania szczątków na podstawie ich intensywności obrazu i informacji o kolorze za pomocą momentów Zernike ’ a (ZM) . Momenty Zernike są używane do różnych zastosowań rozpoznawania wzorców i są znane jako wytrzymałe w odniesieniu do hałasu i mają dobrą moc rekonstrukcji. W tej pracy ZM przedstawiony przez Malm et al. rzędu n z powtórzeniem I funkcji \(f\left ({r, \ theta} \right)\), we współrzędnych biegunowych wewnątrz dysku wyśrodkowanego kwadratowym obrazem \(i\left( {x,y} \right)\) O rozmiarze \(M \razy m\) podanym przez Eq. Użyto 5.
\(v_{nl }^{*} \left( {r,\Theta } \right)\) oznacza sprzężenie zespolone wielomianu zernikego \(V_{NL} \Left( {r,\Theta } \right)\). Aby utworzyć miarę tekstury, uśredniane są wielkości od \(a_{nl}\) wyśrodkowane na każdym pikselu obrazu tekstury .
wyodrębnianie cech
powodzenie algorytmu klasyfikacji w dużym stopniu zależy od poprawności cech wyodrębnionych z obrazu. Komórki w rozmazach pap w stosowanym zbiorze danych są podzielone na siedem klas w oparciu o cechy, takie jak rozmiar, Powierzchnia, kształt i jasność jądra i cytoplazmy. Cechy wyekstrahowane ze zdjęć obejmowały cechy morfologiczne używane wcześniej przez innych . W pracy wyodrębniono również z jądra trzy cechy geometryczne (solidność, zwartość i mimośrodowość) oraz sześć cech tekstualnych (średnia, odchylenie standardowe, wariancja, gładkość, energia i Entropia), w wyniku czego uzyskano łącznie 29 cech, jak pokazano w tabeli 3.
wybór funkcji
wybór funkcji jest procesem wyboru podzbiorów wyodrębnionych funkcji, które dają najlepsze wyniki klasyfikacji. Wśród wyodrębnionych funkcji niektóre mogą zawierać szum, podczas gdy wybrany klasyfikator może nie wykorzystywać innych. W związku z tym należy określić optymalny zestaw funkcji, ewentualnie wypróbowując wszystkie kombinacje. Jednak, gdy istnieje wiele funkcji, możliwe kombinacje eksplodują w liczbie, co zwiększa złożoność obliczeniową algorytmu. Algorytmy wyboru funkcji są szeroko klasyfikowane do metod filtrowania ,owijania i osadzania.
metoda stosowana przez narzędzie łączy symulowane wyżarzanie z podejściem owijania. Podejście to zostało zaproponowane w niniejszym artykule, ale wydajność wyboru funkcji jest oceniana przy użyciu algorytmu losowego lasu o podwójnej strategii . Symulowane wyżarzanie jest probabilistyczną techniką przybliżania globalnego optimum danej funkcji. Podejście to doskonale nadaje się do zapewnienia optymalnego zestawu funkcji. Poszukiwanie optymalnego zestawu kieruje się wartością kondycyjną . Po zakończeniu symulowanego wyżarzania porównywane są wszystkie różne podzbiory funkcji i wybierane są najsprawniejsze (czyli takie, które wykonuje najlepsze). Wyszukiwanie wartości sprawności uzyskano za pomocą owijarki, w której do obliczenia błędu w algorytmie klasyfikacji wykorzystano walidację krzyżową K-fold. Różne kombinacje z wyodrębnionych cech są przygotowywane, oceniane i porównywane z innymi kombinacjami. Model predykcyjny jest następnie używany do oceny kombinacji funkcji i przypisania wyniku na podstawie dokładności modelu. Błąd sprawności podany przez owijarkę jest używany jako błąd sprawności przez symulowany algorytm wyżarzania. Niewyraźny algorytm C-means został zawinięty w czarną skrzynkę, z której uzyskano szacunkowy błąd dla różnych kombinacji funkcji, jak pokazano na Fig. 4.

rozmyte C-means jest zawinięte w czarną skrzynkę, z której uzyskuje się szacowany błąd
rozmyte C-means pozwala na punkty danych w zbiór danych, który ma należeć do wszystkich klastrów, z członkostwem w przedziale (0-1), jak pokazano w EQ. 6.
gdzie \(M_{ik}\) jest członkostwem dla punktu danych k do centrum klastra i, \(d_{jk}\) jest odległością od centrum klastra j do punktu danych k, A q € jest wykładnikiem, który decyduje o sile członkostwa. Algorytm fuzzy C-means został zaimplementowany przy użyciu fuzzy toolbox w Matlab.
defuzifikacja
algorytm rozmyty C-oznacza nie mówi nam, jakie informacje zawierają klastry i jak te informacje mają być wykorzystane do klasyfikacji. Jednak określa, w jaki sposób punkty danych są przypisane członkostwa różnych klastrów i to rozmyte członkostwa jest używany do przewidywania klasy punktu danych . Jest to przezwyciężone przez defuzzification. Istnieje wiele metod defuzzyfikacji . Jednak w tym narzędziu każdy klaster ma rozmyte członkostwo (0-1) wszystkich klas na obrazie. Dane treningowe są przypisywane do najbliższego klastra. Procent danych szkoleniowych każdej klasy należącej do klastra a daje przynależność klastra, klaster a = do różnych klas, gdzie i jest przechowywaniem w klastrze a i j w innym klastrze. Miara intensywności jest dodawana do funkcji członkostwa dla każdego klastra przy użyciu algorytmu defuzzyfikacji rozmytego klastra. Popularnym podejściem do defuzzifikacji rozmytej partycji jest zastosowanie zasady maksymalnego stopnia członkostwa, gdzie punkt danych k jest przypisany do klasy M wtedy i tylko wtedy, gdy jej stopień członkostwa \(M_{IK}\) do klastra i, jest największy. Chuang et al. zaproponowano dostosowanie statusu członkostwa każdego punktu danych za pomocą statusu członkostwa sąsiadów.
w proponowanym podejściu metoda defuzzyfikacji oparta na prawdopodobieństwie Bayesa jest używana do wygenerowania probabilistycznego modelu funkcji członkostwa dla każdego punktu danych i zastosowania modelu do obrazu w celu wytworzenia informacji klasyfikacji. Model probabilistyczny jest obliczany w następujący sposób:
-
Konwertuj rozkłady możliwości w macierzy partycji (klastrach) na rozkłady prawdopodobieństwa.
-
skonstruuj probabilistyczny model rozkładów danych jak w
-
Zastosuj model, aby uzyskać informacje o klasyfikacji dla każdego punktu danych za pomocą korektora. 7.
gdzie \(p\left( {a_{i} } \Right),i = 0 \ldots .c\) jest prawdopodobieństwem poprzedzającym \(a_{i}\), które można obliczyć za pomocą metody, w której prawdopodobieństwo poprzedzające jest zawsze proporcjonalne do masy każdej klasy.
liczba klastrów do wykorzystania została określona w celu zapewnienia, że zbudowany model może opisać dane w najlepszy możliwy sposób. Jeśli wybrano zbyt wiele klastrów, istnieje ryzyko przepełnienia szumu w danych. Jeśli wybrano zbyt małą liczbę klastrów, rezultatem może być słaby klasyfikator. W związku z tym przeprowadzono analizę liczby klastrów w odniesieniu do błędu testu weryfikacji krzyżowej. Osiągnięto optymalną liczbę 25 klastrów i doszło do przetrenowania powyżej tej liczby klastrów. Wykładnik defuzyfikacji równy 1.0930 został uzyskany z 25 klastrów, dziesięciokrotnej weryfikacji krzyżowej i 60 powtórek i został wykorzystany do obliczenia błędu sprawności dla wyboru funkcji, gdzie w sumie wybrano 18 cech z 29 cech do budowy klasyfikatora. Wybrane cechy to: obszar jądra; poziom szarości jądra; Najkrótsza średnica jądra; najdłuższe jądro; Obwód jądra; maksimum w jądrze; minima w jądrze; obszar cytoplazmy; poziom szarości cytoplazmy; Obwód cytoplazmy; stosunek jądra do cytoplazmy; ekscentryczność jądra, odchylenie standardowe jądra, wariancja poziomu szarości jądra; Entropia poziomu szarości jądra; położenie względne jądra; Średnia poziom szarości jądra i energia wartości szarości jądra.
ocena klasyfikacji
w niniejszej pracy przyjęto hierarchiczny model skuteczności systemów obrazowania diagnostycznego zaproponowany przez Frybacka i Thornbury ’ ego jako zasadę przewodnią oceny narzędzia, jak przedstawiono w tabeli 4.
czułość mierzy odsetek rzeczywistych pozytywów, które są prawidłowo zidentyfikowane jako takie, podczas gdy swoistość mierzy odsetek rzeczywistych negatywów, które są prawidłowo zidentyfikowane jako takie. Czułość i swoistość są opisane przez Eq. 8.
gdzie TP = True positives, FN = False negatives, TN = True negatives i FP = False positives.
projektowanie i integracja GUI
opisane powyżej metody przetwarzania obrazu zostały zaimplementowane w programie Matlab i są wykonywane za pomocą graficznego interfejsu użytkownika (GUI) w języku Java pokazanego na Rys. 5. Narzędzie ma panel, w którym ładowany jest obraz rozmazu pap, a cytotechnik wybiera odpowiednią metodę segmentacji sceny (w oparciu o klasyfikator TWS), usuwania gruzu (w oparciu o podejście trzech sekwencyjnych eliminacji) i wykrywania granic (jeśli uzna to za konieczne, przy użyciu metody wykrywania krawędzi Canny), po czym funkcje są wyodrębniane za pomocą przycisku funkcji wyodrębniania.
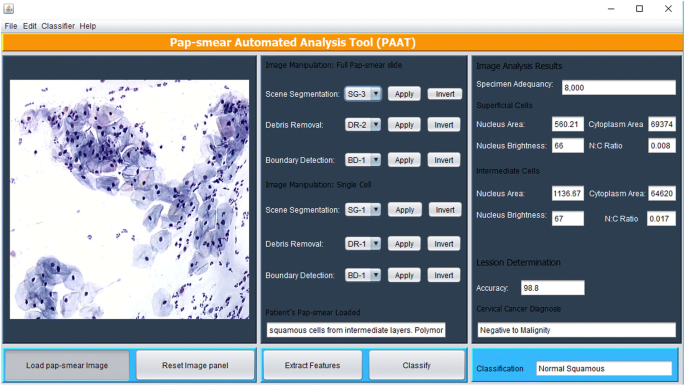
PAT graficzny interfejs użytkownika
narzędzie skanuje rozmaz pap, aby przeanalizować wszystkie obiekty, które pozostały po usunięciu gruzu. 18 cech opisanych w selekcji cech wyodrębnia się z każdego obiektu i wykorzystuje do klasyfikacji każdej komórki przy użyciu algorytmu rozmytego C-means opisanego w metodzie klasyfikacji. Losowo wyodrębnione cechy jednej komórki powierzchownej i jednej komórki pośredniej są wyświetlane w panelu wyników analizy obrazu. Po wyodrębnieniu funkcji cytotechnik (użytkownik) naciska przycisk klasyfikacji, a narzędzie wyświetla diagnozę (pozytywną do złośliwości lub negatywną do złośliwości) i klasyfikuje diagnozę do jednej z 7 klas/etapów raka szyjki macicy zgodnie z zestawem danych szkoleniowych.