Jak zrobić segmentację semantyczną za pomocą głębokiego uczenia
Ten artykuł jest kompleksowym przeglądem, w tym przewodnikiem krok po kroku, aby wdrożyć model segmentacji obrazów głębokiego uczenia.
udostępniliśmy nowy zaktualizowany blog na temat segmentacji semantycznej tutaj: Przewodnik 2021 do segmentacji semantycznej
obecnie segmentacja semantyczna jest jednym z kluczowych problemów w dziedzinie widzenia komputerowego. Patrząc na szerszy obraz, segmentacja semantyczna jest jednym z zadań wysokiego poziomu, które toruje drogę do pełnego zrozumienia sceny. Znaczenie rozumienia scen jako podstawowego problemu widzenia komputerowego podkreśla fakt, że coraz większa liczba zastosowań opiera się na wnioskowaniu wiedzy z obrazów. Niektóre z tych aplikacji obejmują Pojazdy samojezdne, interakcję człowiek-komputer, rzeczywistość wirtualną itp. Wraz z popularnością uczenia głębokiego w ostatnich latach wiele problemów z segmentacją semantyczną jest rozwiązywanych za pomocą głębokich architektur, najczęściej splotowych sieci neuronowych, które przewyższają inne podejścia dużym marginesem pod względem dokładności i wydajności.
- czym jest segmentacja semantyczna?
- jakie są istniejące podejścia do segmentacji semantycznej?
- 1 — segmentacja semantyczna oparta na regionie
- 2 — Fully Convolutional Network-Based Semantic Segmentation
- 3 — słabo nadzorowana segmentacja semantyczna
- Dokonywanie segmentacji semantycznej za pomocą sieci Fully-Convolutional
- krok 1
- Krok 2
- Krok 3
- Krok 4
- Krok 5
- możesz być zainteresowany naszymi ostatnimi postami na:
czym jest segmentacja semantyczna?
segmentacja semantyczna jest naturalnym krokiem w postępie od zgrubnego do drobnego wnioskowania:początek może być zlokalizowany w klasyfikacji, która polega na dokonaniu prognozy dla całego wejścia.Kolejnym krokiem jest lokalizacja / Detekcja, która dostarcza nie tylko klas, ale także dodatkowych informacji dotyczących lokalizacji przestrzennej tych klas.Wreszcie, segmentacja semantyczna osiąga drobnoziarnisty wnioskowanie poprzez tworzenie gęstych przewidywań wnioskujących etykiet dla każdego piksela, tak że każdy piksel jest oznaczony klasą otaczającego go obszaru rudy obiektu.
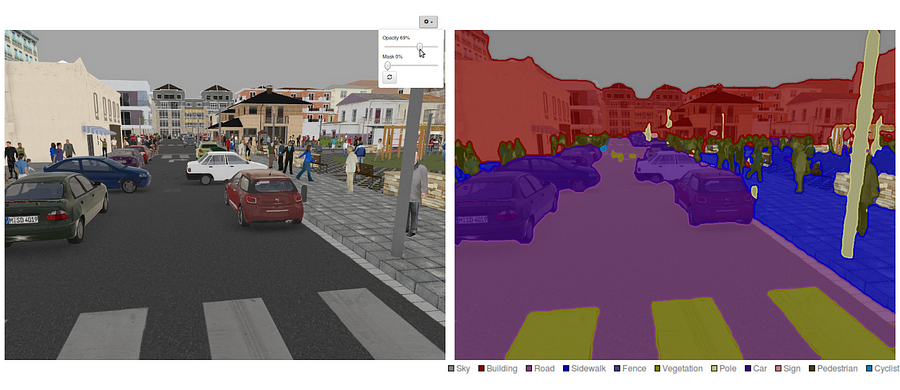
warto również przejrzeć niektóre standardowe sieci Deep, które wniosły znaczący wkład w pole widzenia komputerowego, ponieważ są one często używane jako podstawa systemów segmentacji semantycznej:
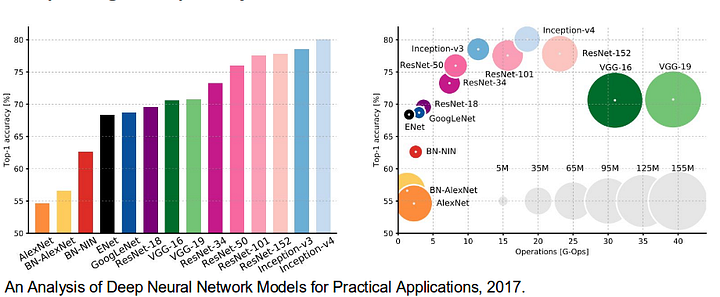
- alexnet: pionierski CNN z Toronto, który wygrał konkurs ImageNet 2012 z dokładnością testu 84,6%. Składa się z 5 warstw splotowych, max-poolingowych, Reluzyjnych jako nieliniowości, 3 w pełni splotowych warstw i dropout.
- VGG-16: Ten model Oxford wygrał konkurs ImageNet 2013 z dokładnością 92,7%. Używa stosu warstw splotu z małymi polami odbiorczymi w pierwszych warstwach zamiast kilku warstw z dużymi polami odbiorczymi.
- GoogLeNet: ta sieć Google wygrała konkurs ImageNet 2014 z dokładnością 93,3%. Składa się z 22 warstw i nowo wprowadzonego bloku o nazwie moduł Incepcji. Moduł składa się z warstwy Sieci w sieci, operacji łączenia, warstwy splotu dużych rozmiarów i warstwy splotu małych rozmiarów.
- ResNet: ten model Microsoftu wygrał konkurs ImageNet 2016 z dokładnością 96,4%. Jest dobrze znany ze względu na głębokość (152 warstwy) i wprowadzenie resztkowych bloków. Pozostałe bloki rozwiązują problem szkolenia naprawdę głębokiej architektury poprzez wprowadzenie połączeń pomijania tożsamości, dzięki czemu warstwy mogą kopiować swoje dane wejściowe do następnej warstwy.
jakie są istniejące podejścia do segmentacji semantycznej?
ogólna Architektura segmentacji semantycznej może być ogólnie postrzegana jako sieć kodera, po której następuje sieć dekodera:
- enkoder jest zwykle wstępnie przeszkoloną siecią klasyfikacyjną, taką jak VGG / ResNet, po której następuje sieć dekodera.
- zadaniem dekodera jest semantyczne rzutowanie cech rozróżniających (niższa rozdzielczość) poznanych przez koder na przestrzeń pikseli (wyższa rozdzielczość) w celu uzyskania gęstej klasyfikacji.
w przeciwieństwie do klasyfikacji, gdzie końcowy wynik bardzo głębokiej sieci jest jedyną ważną rzeczą, segmentacja semantyczna wymaga nie tylko dyskryminacji na poziomie pikseli, ale także mechanizmu rzutowania cech rozróżniających poznanych na różnych etapach kodera na przestrzeń pikseli. Różne podejścia wykorzystują różne mechanizmy jako część mechanizmu dekodującego. Przyjrzyjmy się 3 głównym podejściom:
1 — segmentacja semantyczna oparta na regionie
metody oparte na regionie generalnie podążają za potokiem „segmentacja przy użyciu rozpoznawania”, który najpierw wyodrębnia regiony wolnej formy z obrazu i opisuje je, a następnie klasyfikuje je na podstawie regionu. W czasie testu przewidywania oparte na regionach są przekształcane w przewidywania Pikselowe, zwykle poprzez etykietowanie piksela zgodnie z najwyższym regionem punktacji, który go zawiera.
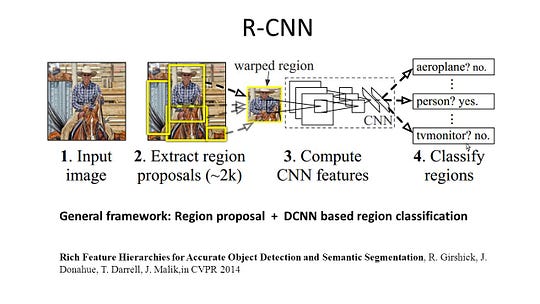
R-CNN (regiony z funkcją CNN) jest jedną z reprezentatywnych prac dla metod opartych na regionach. Wykonuje segmentację semantyczną w oparciu o wyniki wykrywania obiektów. Aby być konkretnym, R-CNN najpierw wykorzystuje selektywne wyszukiwanie, aby wyodrębnić dużą ilość propozycji obiektów, a następnie oblicza funkcje CNN dla każdego z nich. Wreszcie klasyfikuje Każdy region za pomocą liniowych maszyn SVM specyficznych dla danej klasy. W porównaniu z tradycyjnymi strukturami CNN, które są przeznaczone głównie do klasyfikacji obrazów, R-CNN może zająć się bardziej skomplikowanymi zadaniami, takimi jak wykrywanie obiektów i segmentacja obrazu, a nawet staje się ważną podstawą dla obu pól. Co więcej, R-CNN może być zbudowany na bazie dowolnych struktur benchmarkowych CNN, takich jak AlexNet, VGG, GoogLeNet i ResNet.
dla zadania segmentacji obrazu, R-CNN wyodrębnił 2 typy funkcji dla każdego regionu: funkcję pełnego regionu i funkcję pierwszego planu, i stwierdził, że może to prowadzić do lepszej wydajności podczas łączenia ich razem jako funkcji regionu. R-CNN osiągnął znaczną poprawę wydajności dzięki zastosowaniu wysoce dyskryminujących funkcji CNN. Jednak ma również kilka wad zadania segmentacji:
- funkcja nie jest kompatybilna z zadaniem segmentacji.
- funkcja nie zawiera wystarczającej ilości informacji przestrzennych do precyzyjnego generowania granic.
- generowanie propozycji opartych na segmentach wymaga czasu i znacznie wpłynie na końcową wydajność.
z powodu tych wąskich gardeł zaproponowano najnowsze badania mające na celu rozwiązanie problemów, w tym SDS, Hypercolumns, Mask R-CNN.
2 — Fully Convolutional Network-Based Semantic Segmentation
oryginalna sieć Fully Convolutional Network (FCN) uczy się mapowania z pikseli na piksele, bez wyodrębniania propozycji regionu. Rurociąg sieciowy FCN jest rozszerzeniem klasycznego CNN. Główną ideą jest, aby klasyczna CNN wziąć jako wejściowe obrazy o dowolnej wielkości. Ograniczenie CNN do przyjmowania i wytwarzania etykiet tylko dla wejść o określonej wielkości pochodzi z całkowicie połączonych warstw, które są stałe. W przeciwieństwie do nich, FCN mają tylko warstwy splotowe i poolingowe, które dają im możliwość przewidywania na wejściach o dowolnej wielkości.
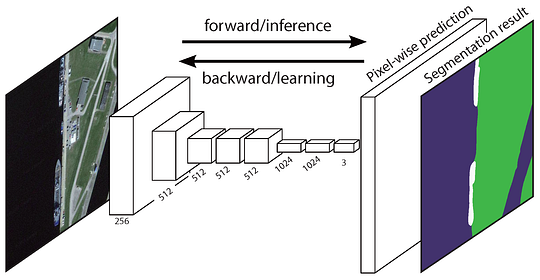
jednym z problemów w tym konkretnym FCN jest to, że poprzez propagację przez kilka naprzemiennych warstw splotowych i poolingowych, rozdzielczość wyjściowych map funkcji jest próbkowana w dół. W związku z tym przewidywania bezpośrednie FCN są zwykle w niskiej rozdzielczości, co powoduje stosunkowo rozmyte granice obiektów. W celu rozwiązania tego problemu zaproponowano szereg bardziej zaawansowanych podejść opartych na FCN, w tym SegNet, DeepLab-CRF i rozszerzone sploty.
3 — słabo nadzorowana segmentacja semantyczna
Większość odpowiednich metod segmentacji semantycznej opiera się na dużej liczbie obrazów z maskami segmentacji w pikselach. Jednak ręczne opisywanie tych masek jest dość czasochłonne, frustrujące i kosztowne komercyjnie. Dlatego niedawno zaproponowano kilka słabo nadzorowanych metod, które są dedykowane do wypełniania segmentacji semantycznej poprzez wykorzystanie przypisanych ramek obwiedniowych.

na przykład, Boxsup zastosował adnotacje obwiedniowe jako Nadzór do szkolenia sieci i iteracyjnej poprawy szacowanych masek semantycznych segmentacja. Simple Does it traktował słabe ograniczenie nadzoru jako kwestię szumu etykiety wejściowej i badał trening rekurencyjny jako strategię usuwania hałasu. Etykietowanie na poziomie pikseli zinterpretowało zadanie segmentacji w ramach uczenia się wielu instancji i dodało dodatkową warstwę, aby ograniczyć model, aby przypisać większą wagę ważnym pikselom do klasyfikacji na poziomie obrazu.
Dokonywanie segmentacji semantycznej za pomocą sieci Fully-Convolutional
w tej sekcji przejdźmy krok po kroku przez implementację najpopularniejszej architektury segmentacji semantycznej-sieci Fully-Convolutional Net (FCN). Zaimplementujemy go za pomocą biblioteki TensorFlow w Pythonie 3, wraz z innymi zależnościami, takimi jak Numpy i Scipy.In to ćwiczenie będziemy oznaczać piksele drogi na obrazach za pomocą FCN. Będziemy współpracować z zestawem danych drogowych Kitti do wykrywania dróg/pasów ruchu. Jest to proste ćwiczenie z programu Nano-stopniowego samodzielnego prowadzenia samochodu Udacity, którego możesz dowiedzieć się więcej o konfiguracji w tym repo GitHub.

oto kluczowe cechy architektury FCN:
- FCN przekazuje wiedzę z vgg16 w celu przeprowadzenia segmentacji semantycznej.
- w pełni połączone warstwy VGG16 są konwertowane na w pełni splotowe warstwy, przy użyciu splotu 1×1. W procesie tym powstaje mapa cieplna obecności klasy w niskiej rozdzielczości.
- upsampling tych map cech semantycznych o niskiej rozdzielczości odbywa się przy użyciu transponowanych splotów (inicjowanych za pomocą dwuliniowych filtrów interpolacji).
- na każdym etapie proces upsamplingu jest jeszcze bardziej udoskonalany przez dodawanie funkcji z grubszych, ale wyższych map funkcji z niższych warstw w VGG16.
- pominięcie połączenia jest wprowadzane po każdym bloku splotu, aby umożliwić kolejnemu blokowi wyodrębnienie bardziej abstrakcyjnych, istotnych dla klasy cech z wcześniej zebranych cech.
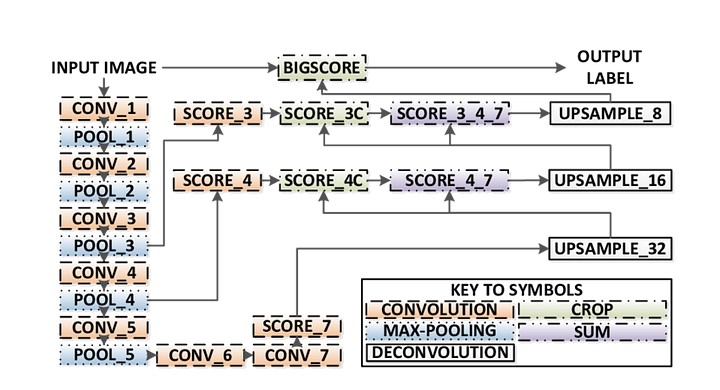
Istnieją 3 wersje FCN (FCN-32, FCN-16, FCN-8). Zaimplementujemy FCN-8, jak opisano krok po kroku poniżej:
- Encoder: wstępnie przeszkolony VGG16 jest używany jako koder. Dekoder zaczyna się od warstwy 7 vgg16.
- FCN Layer-8: ostatnia w pełni połączona warstwa VGG16 zostaje zastąpiona splotem 1×1.
- FCN Layer-9: FCN Layer-8 jest upsamplowany 2 razy, aby dopasować wymiary do warstwy 4 VGG 16, używając transponowanego splotu z parametrami: (kernel=(4,4), stride=(2,2), paddding=’same’). Następnie dodano połączenie pominięte między warstwą 4 VGG16 i FCN Layer-9.
- FCN Layer-10: FCN Layer-9 jest upsamplowany 2 razy, aby dopasować wymiary do warstwy 3 vgg16, używając transponowanego splotu z parametrami: (kernel=(4,4), stride=(2,2), paddding=’same’). Następnie dodano połączenie pominięte między warstwą 3 VGG 16 A warstwą FCN-10.
- FCN Layer-11: FCN Layer-10 jest upsamplowany 4 razy, aby dopasować wymiary do rozmiaru obrazu wejściowego, więc otrzymujemy rzeczywisty obraz z powrotem, a głębokość jest równa liczbie klas, używając transponowanego splotu z parametrami: (kernel=(16,16), stride=(8,8), paddding=’same’).
krok 1
najpierw ładujemy wstępnie przeszkolony model VGG-16 do TensorFlow. Biorąc sesję TensorFlow i ścieżkę do folderu VGG (który można pobrać tutaj), zwracamy krotkę tensorów z modelu VGG, w tym wejście obrazu, keep_prob (do kontroli szybkości porzucania), warstwę 3, warstwę 4 i warstwę 7.
def load_vgg(sess, vgg_path): # load the model and weights model = tf.saved_model.loader.load(sess, , vgg_path) # Get Tensors to be returned from graph graph = tf.get_default_graph() image_input = graph.get_tensor_by_name('image_input:0') keep_prob = graph.get_tensor_by_name('keep_prob:0') layer3 = graph.get_tensor_by_name('layer3_out:0') layer4 = graph.get_tensor_by_name('layer4_out:0') layer7 = graph.get_tensor_by_name('layer7_out:0') return image_input, keep_prob, layer3, layer4, layer7funkcja VGG16
Krok 2
teraz skupiamy się na tworzeniu warstw dla FCN, używając tensorów z modelu VGG. Biorąc pod uwagę tensory dla wyjścia warstwy VGG i liczbę klas do sklasyfikowania, zwracamy tensor dla ostatniej warstwy tego wyjścia. W szczególności stosujemy splot 1×1 do warstw enkodera, a następnie dodajemy warstwy dekodera do sieci z pominięciem połączeń i upsamplingiem.
def layers(vgg_layer3_out, vgg_layer4_out, vgg_layer7_out, num_classes): # Use a shorter variable name for simplicity layer3, layer4, layer7 = vgg_layer3_out, vgg_layer4_out, vgg_layer7_out # Apply 1x1 convolution in place of fully connected layer fcn8 = tf.layers.conv2d(layer7, filters=num_classes, kernel_size=1, name="fcn8") # Upsample fcn8 with size depth=(4096?) to match size of layer 4 so that we can add skip connection with 4th layer fcn9 = tf.layers.conv2d_transpose(fcn8, filters=layer4.get_shape().as_list(), kernel_size=4, strides=(2, 2), padding='SAME', name="fcn9") # Add a skip connection between current final layer fcn8 and 4th layer fcn9_skip_connected = tf.add(fcn9, layer4, name="fcn9_plus_vgg_layer4") # Upsample again fcn10 = tf.layers.conv2d_transpose(fcn9_skip_connected, filters=layer3.get_shape().as_list(), kernel_size=4, strides=(2, 2), padding='SAME', name="fcn10_conv2d") # Add skip connection fcn10_skip_connected = tf.add(fcn10, layer3, name="fcn10_plus_vgg_layer3") # Upsample again fcn11 = tf.layers.conv2d_transpose(fcn10_skip_connected, filters=num_classes, kernel_size=16, strides=(8, 8), padding='SAME', name="fcn11") return fcn11funkcja warstw
Krok 3
następnym krokiem jest optymalizacja naszej sieci neuronowej, czyli budowanie funkcji utraty TensorFlow i operacji optymalizujących. Tutaj używamy entropii Krzyżowej jako funkcji straty i Adam jako naszego algorytmu optymalizacji.
def optimize(nn_last_layer, correct_label, learning_rate, num_classes): # Reshape 4D tensors to 2D, each row represents a pixel, each column a class logits = tf.reshape(nn_last_layer, (-1, num_classes), name="fcn_logits") correct_label_reshaped = tf.reshape(correct_label, (-1, num_classes)) # Calculate distance from actual labels using cross entropy cross_entropy = tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=correct_label_reshaped) # Take mean for total loss loss_op = tf.reduce_mean(cross_entropy, name="fcn_loss") # The model implements this operation to find the weights/parameters that would yield correct pixel labels train_op = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(loss_op, name="fcn_train_op") return logits, train_op, loss_opoptymalizacja funkcji
Krok 4
tutaj definiujemy funkcję train_nn, która przyjmuje ważne parametry, w tym liczbę epok, rozmiar partii, funkcję utraty, działanie optymalizatora i symbole zastępcze dla obrazów wejściowych, obrazów etykiet, szybkości uczenia się. Dla procesu szkolenia ustawiliśmy również keep_probability na 0.5, A learning_rate na 0.001. Aby śledzić postępy, drukujemy również straty podczas treningu.
def train_nn(sess, epochs, batch_size, get_batches_fn, train_op, cross_entropy_loss, input_image, correct_label, keep_prob, learning_rate): keep_prob_value = 0.5 learning_rate_value = 0.001 for epoch in range(epochs): # Create function to get batches total_loss = 0 for X_batch, gt_batch in get_batches_fn(batch_size): loss, _ = sess.run(, feed_dict={input_image: X_batch, correct_label: gt_batch, keep_prob: keep_prob_value, learning_rate:learning_rate_value}) total_loss += loss; print("EPOCH {} ...".format(epoch + 1)) print("Loss = {:.3f}".format(total_loss)) print()Krok 5
wreszcie nadszedł czas, aby wyszkolić naszą sieć! W tej funkcji run, najpierw budujemy naszą sieć używając load_vgg, layers i optimize function. Następnie trenujemy sieć za pomocą funkcji train_nn i zapisujemy dane wnioskowania dla rekordów.
def run(): # Download pretrained vgg model helper.maybe_download_pretrained_vgg(data_dir) # A function to get batches get_batches_fn = helper.gen_batch_function(training_dir, image_shape) with tf.Session() as session: # Returns the three layers, keep probability and input layer from the vgg architecture image_input, keep_prob, layer3, layer4, layer7 = load_vgg(session, vgg_path) # The resulting network architecture from adding a decoder on top of the given vgg model model_output = layers(layer3, layer4, layer7, num_classes) # Returns the output logits, training operation and cost operation to be used # - logits: each row represents a pixel, each column a class # - train_op: function used to get the right parameters to the model to correctly label the pixels # - cross_entropy_loss: function outputting the cost which we are minimizing, lower cost should yield higher accuracy logits, train_op, cross_entropy_loss = optimize(model_output, correct_label, learning_rate, num_classes) # Initialize all variables session.run(tf.global_variables_initializer()) session.run(tf.local_variables_initializer()) print("Model build successful, starting training") # Train the neural network train_nn(session, EPOCHS, BATCH_SIZE, get_batches_fn, train_op, cross_entropy_loss, image_input, correct_label, keep_prob, learning_rate) # Run the model with the test images and save each painted output image (roads painted green) helper.save_inference_samples(runs_dir, data_dir, session, image_shape, logits, keep_prob, image_input)Uruchom funkcję
o naszych parametrach wybieramy epochs = 40, batch_size = 16, num_classes = 2 oraz image_shape = (160, 576). Po wykonaniu 2 próbnych przejść z pominięciem = 0,5 i pominięciem = 0,75, stwierdziliśmy, że druga próba daje lepsze wyniki przy lepszych średnich stratach.

aby zobaczyć pełny kod, Sprawdź ten link: https://gist.github.com/khanhnamle1994/e2ff59ddca93c0205ac4e566d40b5e88
Jeśli podobał Ci się ten kawałek, to chętnie się nim podzielę i rozpowszechnię wiedzę.
możesz być zainteresowany naszymi ostatnimi postami na:
- AWS Textract
- Ekstrakcja danych
zacznij używać Nanonetów do automatyzacji
Wypróbuj model lub poproś o demo już dziś!
spróbuj teraz
