seaborn .histplot¶
seaborn.histplot(data=None, *, x=None, y=None, hue=None, weights=None, stat=’count’, bins=’auto’, binwidth=None, binrange=None, discrete=None, cumulative=False, common_bins=True, common_norm=True, multiple=’layer’, element=’bars’, fill=true, shrink=1, KDE=false, kde_kws=None, line_kws=none, thresh=0, pthresh=none, Pmax=None, cbar=false, cbar_ax=none, cbar_kws=None, palette=none, hue_order=None, hue_norm=none, color=None, Log_scale=none, Legend=true, AX=None, **kwargs)¶
wykreślić jedno-lub dwuwymiarowe histogramy, aby pokazać rozkład zbiory danych.
histogram to klasyczne narzędzie do wizualizacji, które przedstawia rozkład jednej lub więcej zmiennych poprzez zliczanie liczby obserwacji, które mieszczą się w pojemnikach.
Ta funkcja może normalizować statystykę obliczoną w każdym binie w celu oszacowania częstotliwości, gęstości lub masy prawdopodobieństwa, i może dodać gładką krzywą uzyskaną przy użyciu estymacji gęstości jądra, podobną dokdeplot().
Więcej informacji znajduje się w Podręczniku użytkownika.
Dane parametrówpandas.DataFramenumpy.ndarray, mapowanie lub Sekwencja
Struktura danych wejściowych. Albo długi zbiór wektorów, który można przypisać do nazwanych zmiennych, albo szeroki zbiór danych, który będzie wewnętrznie przekształcony.
x, yvektory lub klucze w zmiennychdata
określających pozycje na osiach x i Y.
huevector lub klucz wdata
zmienna semantyczna, która jest mapowana w celu określenia koloru elementów wykresu.
ważeniesektor lub klucz wdata
jeśli jest dostępny, ważenie wkładu odpowiednich punktów danychzawiera liczbę w każdym pojemniku za pomocą tych czynników.
stat{„count”, „frequency”, „density”, „probability”}
Zbiorcza statystyka do obliczenia w każdym bin.
-
countpokazuje liczbę obserwacji -
frequencypokazuje liczbę obserwacji podzieloną przez szerokość kosza -
densitynormalizuje liczniki tak, że powierzchnia histogramu wynosi 1 -
probabilitynormalizuje liczniki tak, że suma wysokości słupka wynosi 1
binsstr, liczba,wektor lub para takich wartości
ogólny parametr BIN, który może być nazwą reguły odniesienia, liczbą pojemników lub przerwami pojemników.Przekazane do numpy.histogram_bin_edges().
binwidthnumber lub Para liczb
szerokość każdego bin, nadpisujebins, ale może być używana zbinrange.
binrangepair liczb lub pary par
Najniższa i najwyższa wartość dla krawędzi bin; może być stosowany eitherwith binslub binwidth. Domyślnie ekstrema danych.
discretebool
Jeśli to prawda, domyślniebinwidth=1 I narysuj paski tak, aby były ustawione na odpowiednich punktach danych. Dzięki temu unika się” luk”, które mogą pojawiać się podczas korzystania z dyskretnych (całkowitych) danych.
cumulativebool
Jeśli to prawda, wykreśl skumulowane liczniki w miarę wzrostu pojemników.
common_binsbool
jeśli prawda, użyj tych samych pojemników, gdy zmienne semantyczne wytwarzają multiploty. W przypadku użycia reguły odniesienia do określenia pojemników, zostanie ona obliczona z pełnym zestawem danych.
common_normbool
jeśli prawda i użycie znormalizowanej statystyki, normalizacja będzie miała zastosowanie nad pełnym zestawem danych. W przeciwnym razie normalizuj każdy histogram niezależnie.
multiple{„layer”, „dodge”, „stack”, „fill”}
podejście do rozwiązywania wielu elementów, gdy mapowanie semantyczne tworzy podzbiory.Dotyczy tylko danych jednostkowych.
element{„bars”, „step”, „poly”}
wizualna reprezentacja statystyki histogramu.Dotyczy tylko danych jednostkowych.
fillbool
jeśli prawda, wypełnij spację pod histogramem.Dotyczy tylko danych jednostkowych.
shrinknumber
Skaluj szerokość każdego paska względem szerokości bin o ten współczynnik.Dotyczy tylko danych jednostkowych.
kdebool
jeśli prawda, Oblicz oszacowanie gęstości jądra, aby wygładzić dystrybucję i pokazać na wykresie jako (jedną lub więcej) linię(y).Dotyczy tylko danych jednostkowych.
Kde_kwsdict
parametry sterujące obliczeniami KDE, jak wkdeplot().
line_kwsdict
parametry sterujące wizualizacją KDE, przekazane domatplotlib.axes.Axes.plot().
komórki
ze statystyką mniejszą lub równą tej wartości będą przezroczyste.Dotyczy tylko danych dwuwymiarowych.
pthreshnumber lub None
Jak thresh, ale wartość w taki sposób, że komórki o łącznej liczbie(lub innych statystykach, gdy są używane) do tej proporcji całkowitej będą przezroczyste.
pmaxnumber or None
wartość, która ustawia ten punkt nasycenia dla colormapy o wartości takiej, że komórki poniżej stanowią tę część całkowitej liczby (lub inną statystykę, gdy są używane).
cbarbool
jeśli prawda, dodaj pasek kolorów, aby opisać odwzorowanie kolorów na wykresie dwuwymiarowym.Uwaga: obecnie nie obsługuje wykresów ze zmiennąhue.
cbar_axmatplotlib.axes.Axes
wstępnie istniejące osie dla paska kolorów.
Cbar_kwsdict
dodatkowe parametry przekazane domatplotlib.figure.Figure.colorbar().
palettestring, list, dict lubmatplotlib.colors.Colormap
metoda wyboru kolorów do użycia podczas mapowania semantycznegohue.Wartości łańcuchów są przekazywane do color_palette(). Wartości List lub dictmapowanie kategoryczne, podczas gdy obiekt colormap implikuje mapowanie numeryczne.
hue_ordervector ciągów
określa kolejność przetwarzania i wykreślania dla kategorycznych poziomów semantycznychhue.
hue_normtuple lubmatplotlib.colors.Normalize
albo para wartości, które ustawiają zakres normalizacji w jednostkach danych lub obiekt, który będzie mapował z jednostek danych na interwał. Usageimplies numeric mapping.
kolormatplotlib color
Specyfikacja pojedynczego koloru, gdy mapowanie barwy nie jest używane. W przeciwnym razie theplot spróbuje podłączyć się do cyklu właściwości matplotlib.
log_scalebool lub liczba, lub para Booli lub liczb
Ustaw skalę logu na osi danych (lub osiach, z danymi dwuwymiarowymi) za pomocą bazy danych (domyślnie 10) i oceń KDE w przestrzeni logów.
legendbool
Jeśli False, pomija legendę dla zmiennych semantycznych.
axmatplotlib.axes.Axes
wstępnie istniejące osie do wykresu. W przeciwnym razie wywołaj wewnętrznie matplotlib.pyplot.gca().
kwargs
inne argumenty słowa kluczowego są przekazywane do jednej z następujących funkcji matplotlibfunctions:
-
matplotlib.axes.Axes.bar()(univariate, element=”bars”) -
matplotlib.axes.Axes.fill_between()(univariate, other element, fill=True) -
matplotlib.axes.Axes.plot()(univariate, other element, fill=False) -
matplotlib.axes.Axes.pcolormesh()(bivariate)
Returnsmatplotlib.axes.Axes
The matplotlib axes containing the plot.
See also
displot
Figure-level interface to distribution plot functions.
kdeplot
Wykreśl jedno-lub dwu -mienne dystrybucje za pomocą estymacji gęstości jądra.
rugplot
narysuj kleszcza na każdej wartości obserwacji wzdłuż osi x i / lub Y.
ecdfplot
wykreślić empiryczne funkcje rozkładu kumulacyjnego.
jointplot
narysuj dwudzielny Wykres z jednodzielnymi rozkładami krańcowymi.
uwagi
wybór pojemników do obliczeń i wykreślenia histogramu może wywrzeć istotny wpływ na spostrzeżenia, które można wyciągnąć z wizualizacji. Jeśli pojemniki są zbyt duże, mogą one usunąć ważne funkcje.Z drugiej strony, pojemniki, które są zbyt małe, mogą być zdominowane przez zmienność losową, zaciemniając kształt rzeczywistego rozkładu podstawowego. Domyślny rozmiar bin określa się za pomocą reguły referencyjnej, która zależy od wielkości próbki i wariancji. Działa to dobrze w wielu przypadkach (np. z”dobrze zachowanymi” danymi), ale w innych zawodzi. Zawsze dobrze jest wypróbowaćróżne rozmiary pojemników, aby mieć pewność, że nie brakuje czegoś ważnego.Ta funkcja pozwala określić pojemniki na kilka różnych sposobów, np. poprzez ustawienie całkowitej liczby pojemników do użycia, szerokości każdego pojemnika lub konkretnych miejsc, w których pojemniki powinny się zepsuć.
przykłady
przypisanie zmiennej dox, aby narysować rozkład jednostkowy wzdłuż osi x:
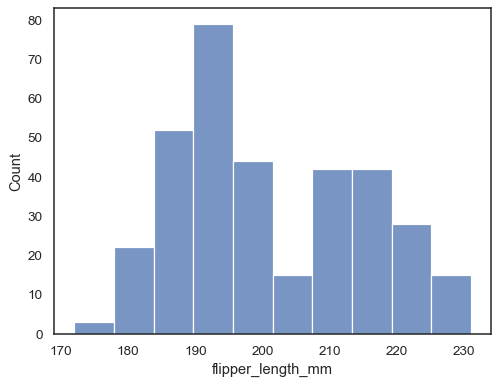
penguins = sns.load_dataset("penguins")sns.histplot(data=penguins, x="flipper_length_mm")
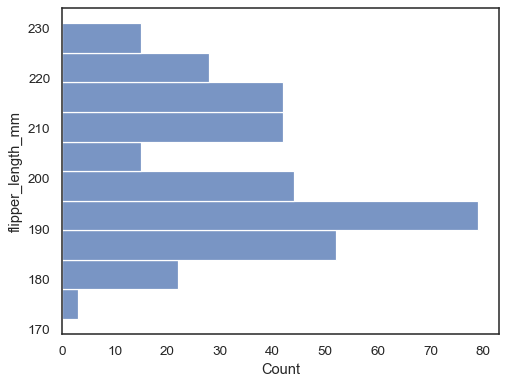
Odwróć Wykres, przypisując zmienną danych do osi y:
sns.histplot(data=penguins, y="flipper_length_mm")
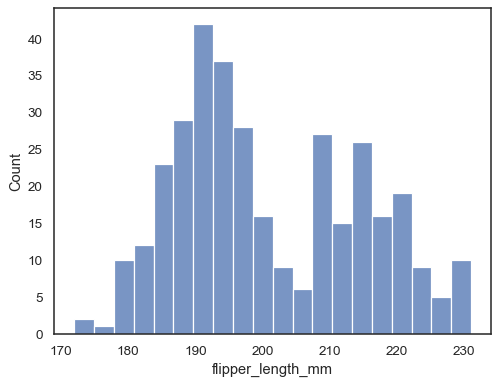
Sprawdź, jak dobrze histogram przedstawia dane, określając inną szerokość bin:
sns.histplot(data=penguins, x="flipper_length_mm", binwidth=3)
Możesz również zdefiniować całkowitą liczbę pojemników do użycia:
sns.histplot(data=penguins, x="flipper_length_mm", bins=30)
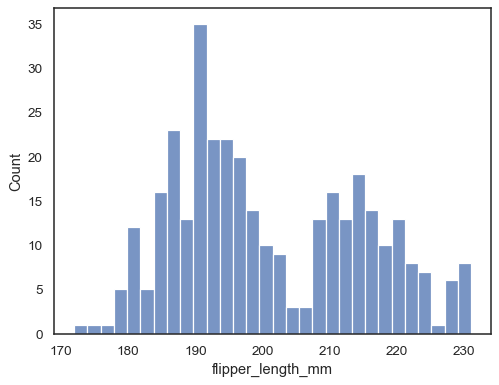
Dodaj oszacowanie gęstości jądra, aby wygładzić histogram, dostarczając uzupełniającą informację o kształcie dystrybucji:
sns.histplot(data=penguins, x="flipper_length_mm", kde=True)
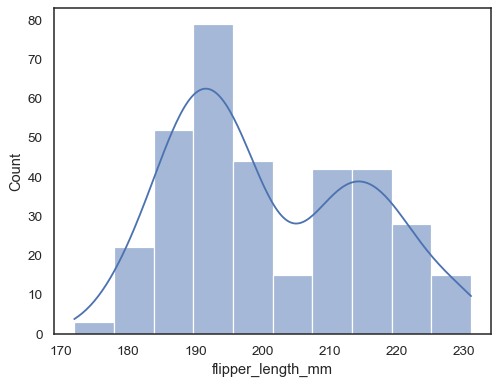
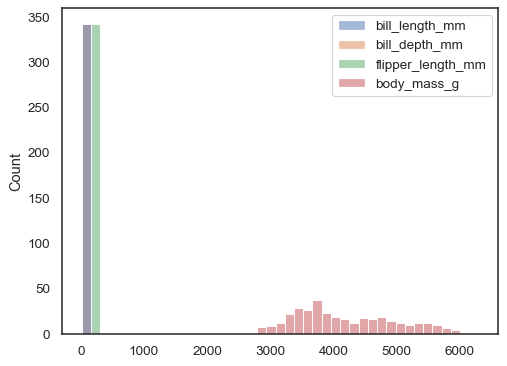
Jeśli nie jest przypisany x ani y, zbiór danych jest traktowany jako szerokokątny, a dla każdej kolumny numerycznej rysowany jest histogram:
sns.histplot(data=penguins)
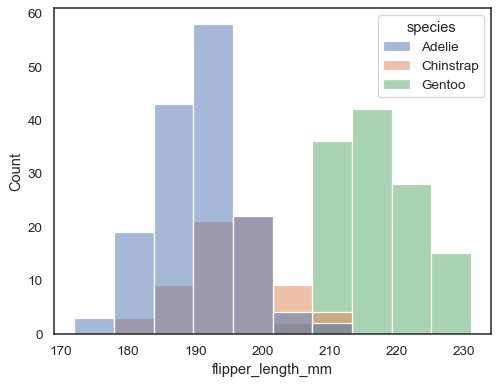
możesz w przeciwnym razie narysować wiele histogramów z długiego zbioru danych za pomocą mapowania:
sns.histplot(data=penguins, x="flipper_length_mm", hue="species")
domyślnym podejściem do kreślenia wielu dystrybucji jest „układanie” ich, ale można je również” układać ” w stos:
sns.histplot(data=penguins, x="flipper_length_mm", hue="species", multiple="stack")
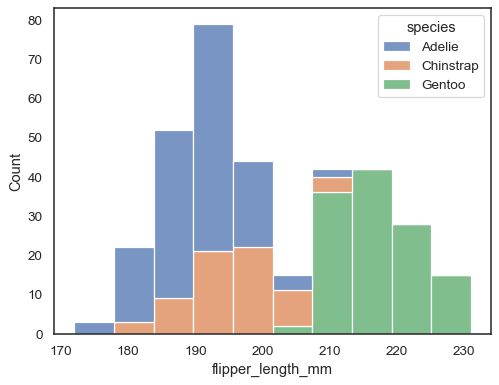
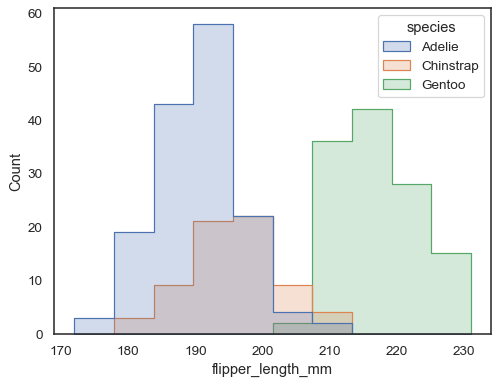
nakładające się paski mogą być trudne do wizualnego rozwiązania. Innym podejściem byłoby narysowanie funkcji krokowej:
sns.histplot(penguins, x="flipper_length_mm", hue="species", element="step")
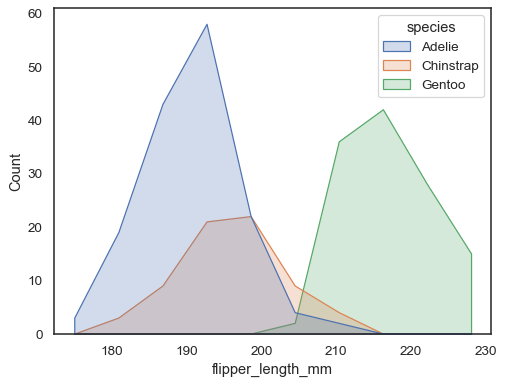
możesz przesunąć się jeszcze dalej od słupków, rysując wielokąt zzakresami w środku każdego kosza. Może to ułatwić oglądanie obrazu dystrybucji, ale należy zachować ostrożność: będzie to mniej oczywiste dla odbiorców, że patrzą na histogram:
sns.histplot(penguins, x="flipper_length_mm", hue="species", element="poly")
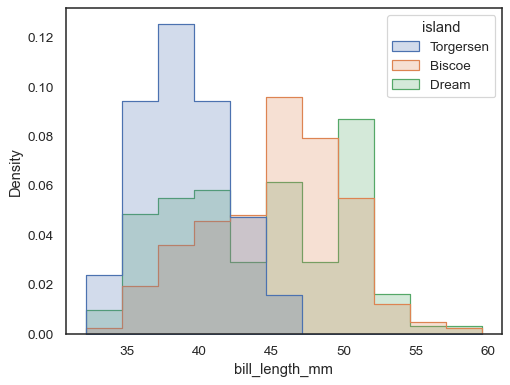
aby porównać rozkład podzbiorów znacznie różniących się rozmiarem, użyj normalizacji gęstości:
sns.histplot( penguins, x="bill_length_mm", hue="island", element="step", stat="density", common_norm=False,)
możliwe jest również znormalizowanie tak, aby wysokość każdego słupka była widoczna, co ma większy sens dla zmiennych dyskretnych:
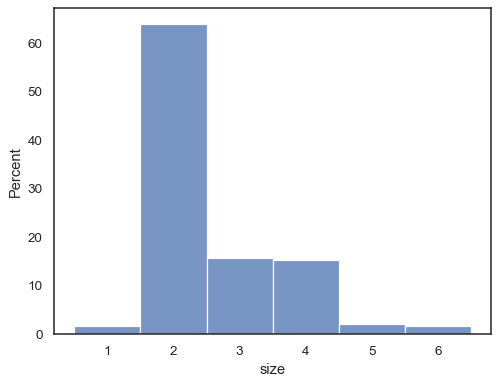
tips = sns.load_dataset("tips")sns.histplot(data=tips, x="size", stat="probability", discrete=True)
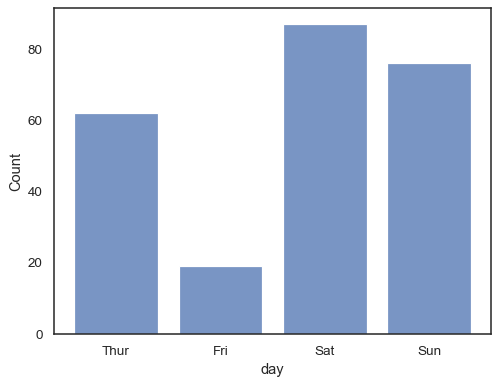
możesz nawet narysować histogram nad zmiennymi kategorycznymi (chociaż jest to funkcja eksperymentalna):
sns.histplot(data=tips, x="day", shrink=.8)
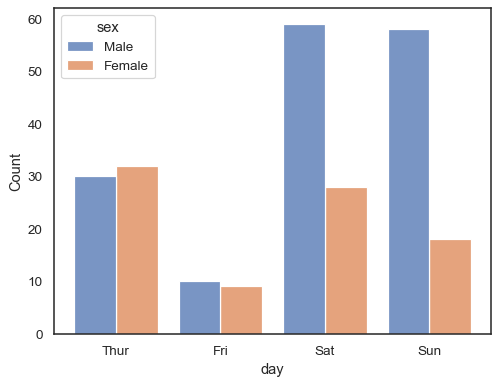
przy użyciuhue semantyczne z dyskretnymi danymi, może mieć sens, aby”dodge” poziomy:
sns.histplot(data=tips, x="day", hue="sex", multiple="dodge", shrink=.8)
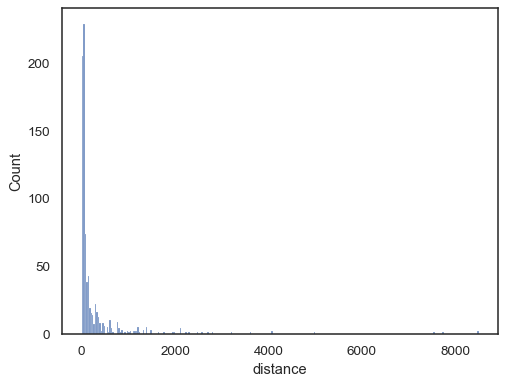
rzeczywiste dane są często wypaczone. W przypadku mocno przekrzywionych rozkładów lepiej jest zdefiniować pojemniki w przestrzeni logów. Porównaj:
planets = sns.load_dataset("planets")sns.histplot(data=planets, x="distance")
To the log-scale version:
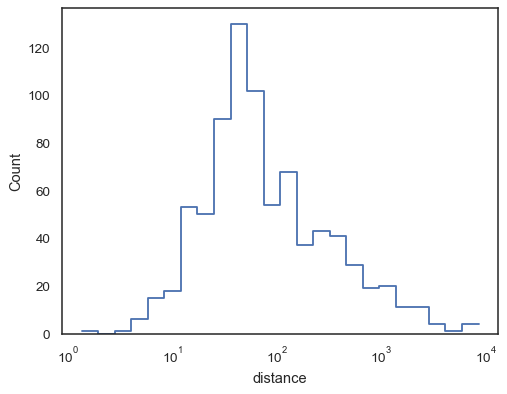
sns.histplot(data=planets, x="distance", log_scale=True)
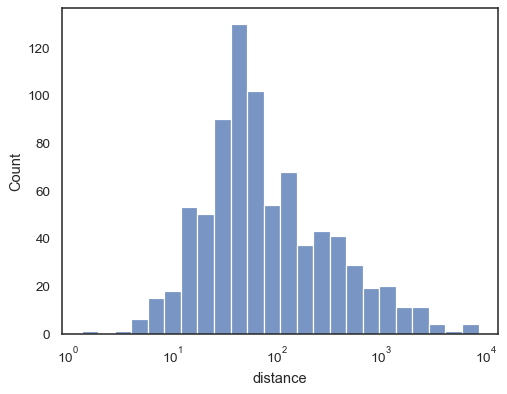
There are also a number of options for how the histogram appears. Youcan show unfilled bars:
sns.histplot(data=planets, x="distance", log_scale=True, fill=False)
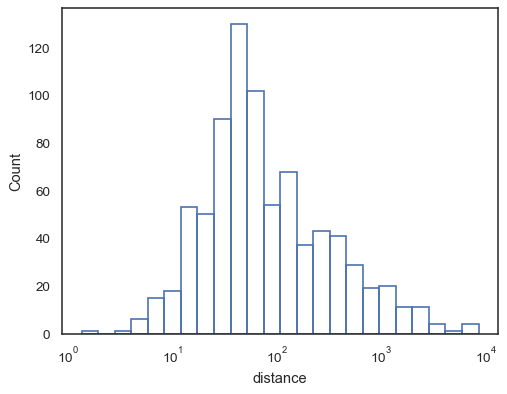
Or an unfilled step function:
sns.histplot(data=planets, x="distance", log_scale=True, element="step", fill=False)
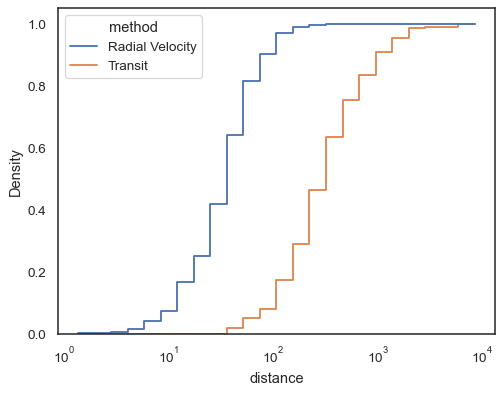
funkcje krokowe, gdy są niewypełnione, ułatwiają porównywanie skumulowanych histogramów:
sns.histplot( data=planets, x="distance", hue="method", hue_order=, log_scale=True, element="step", fill=False, cumulative=True, stat="density", common_norm=False,)
gdy oba x I y są przypisane, dwuwymiarowy histogram jest obliczany i wyświetlany jako heatmapa:
sns.histplot(penguins, x="bill_depth_mm", y="body_mass_g")
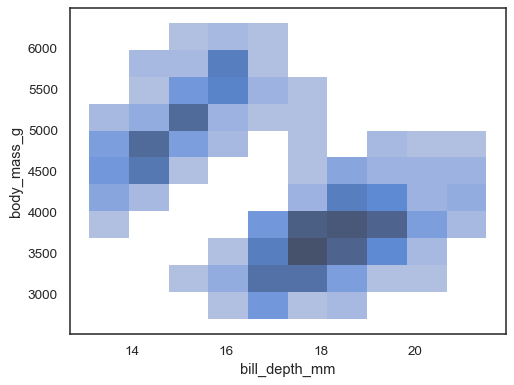
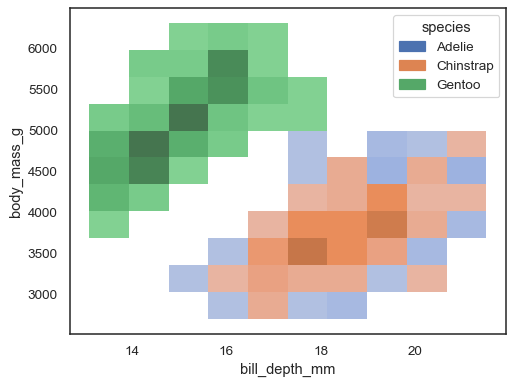
możliwe jest również przypisanie zmiennejhue, chociaż nie będzie to dobrze działać, jeśli dane z różnych poziomów mają znaczące nakładanie się:
sns.histplot(penguins, x="bill_depth_mm", y="body_mass_g", hue="species")
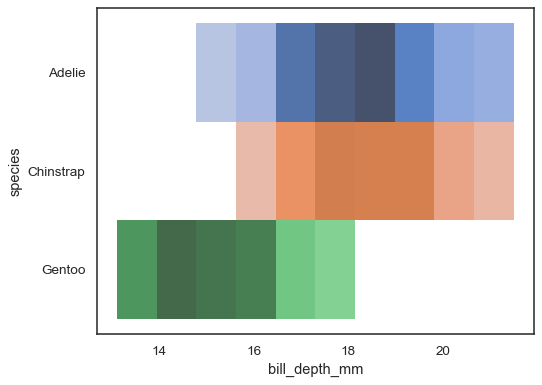
wiele map kolorów może mieć sens, gdy jedna ze zmiennych jest zdefiniowana:
sns.histplot( penguins, x="bill_depth_mm", y="species", hue="species", legend=False)
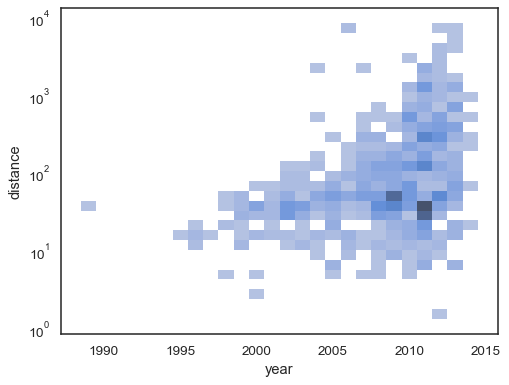
histogram dwuwarstwowy akceptuje wszystkie te same opcje dla obliczeń jak jego uniwariatowy odpowiednik, używając krotek do parametryzacji x Iy niezależnie:
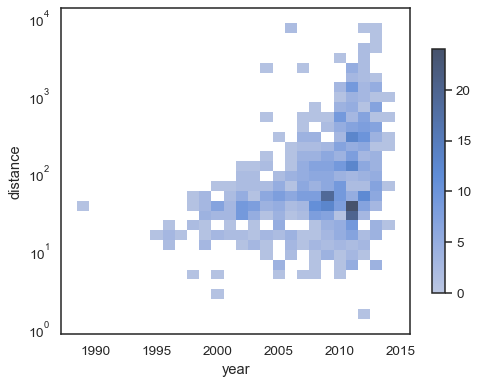
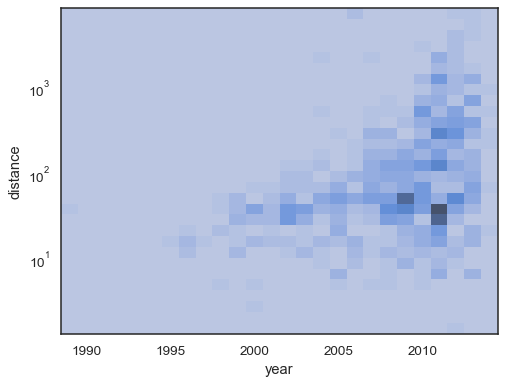
sns.histplot( planets, x="year", y="distance", bins=30, discrete=(True, False), log_scale=(False, True),)
domyślne zachowanie sprawia,że komórki bez obserwacji są przezroczyste, chociaż można to wyłączyć:
sns.histplot( planets, x="year", y="distance", bins=30, discrete=(True, False), log_scale=(False, True), thresh=None,)
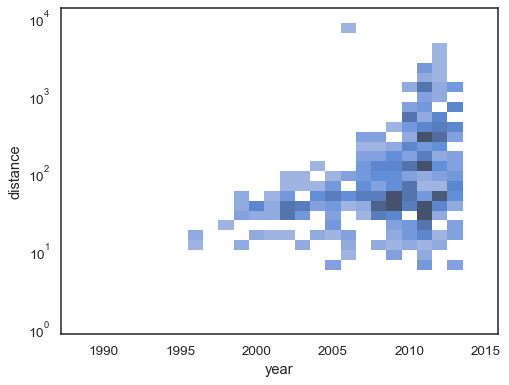
możliwe jest również ustawienie progu i punktu nasycenia colormap proporcji skumulowanych zliczeń:
sns.histplot( planets, x="year", y="distance", bins=30, discrete=(True, False), log_scale=(False, True), pthresh=.05, pmax=.9,)
aby przypisać colormap, dodaj pasek kolorów:
sns.histplot( planets, x="year", y="distance", bins=30, discrete=(True, False), log_scale=(False, True), cbar=True, cbar_kws=dict(shrink=.75),)