Blog
num post anterior, discutimos como os supermercados utilizam os dados para melhor compreender as necessidades dos consumidores e, em última análise, aumentar o seu gasto global. Uma das principais técnicas utilizadas pelos grandes retalhistas é a chamada análise do Cabaz de Mercado (MBA), que descobre associações entre produtos, procurando combinações de produtos que frequentemente co-ocorrem em transacções. Por outras palavras, permite aos supermercados identificar as relações entre os produtos que as pessoas compram. Por exemplo, os clientes que compram um lápis e papel são susceptíveis de comprar uma borracha ou régua.
“a análise do Cabaz de mercado permite aos retalhistas identificar as relações entre os produtos que as pessoas compram.”
Varejistas podem usar os conhecimentos adquiridos a partir de MBA em um número de maneiras, incluindo:
- Agrupamento de produtos que co-ocorrem na estrutura de uma loja de layout para aumentar a chance de cross-selling;
- de Condução online mecanismos de recomendação (“clientes que compraram este produto também visualizaram este produto”); e visando campanhas de marketing, enviando cupões promocionais aos clientes para produtos relacionados com itens que compraram recentemente.tendo em conta o quão popular e valioso é o MBA, pensámos em produzir o seguinte guia passo a passo que descreve como ele funciona e como pode fazer a sua própria análise do Cabaz de mercado.como funciona a análise do Cabaz de mercado?
para realizar um MBA você primeiro precisará de um conjunto de dados de transações. Cada transação representa um grupo de itens ou produtos que foram comprados em conjunto e muitas vezes referidos como um “conjunto de itemset”. Por exemplo, um conjunto pode ser: {lápis, papel, grampos, Borracha} neste caso todos estes itens foram comprados em uma única transação.numa MBA, as transacções são analisadas para identificar as regras de associação. Por exemplo, uma regra poderia ser: {lápis, papel} = > {borracha}. Isso significa que se um cliente tem uma transação que contém um lápis e papel, então eles são susceptíveis de estar interessados em também comprar uma borracha.antes de agir com base numa regra, o retalhista tem de saber se existem provas suficientes que sugiram que resultarão num resultado benéfico. Nós, portanto, medir a força de uma regra de cálculo as seguintes três métricas (observação de outras métricas estão disponíveis, mas estes são os três mais comumente usado):
Suporte: a porcentagem de transações que contêm todos os itens em um conjunto de itens (por exemplo, lápis, papel e borracha). Quanto maior o suporte, mais freqüentemente o conjunto de itemset ocorre. São preferidas regras com um elevado apoio, uma vez que é provável que sejam aplicáveis a um grande número de transacções futuras.
a Confiança: a probabilidade de que uma transação que contém os itens do lado esquerdo da regra (no nosso exemplo, lápis e papel), também contém o item do lado direito (a borracha). Quanto maior a confiança, maior a probabilidade de que o item do lado direito será comprado ou, em outras palavras, maior a taxa de retorno que você pode esperar para uma determinada regra.elevação: a probabilidade de todos os itens em uma regra ocorrer juntos (também conhecido como o suporte) dividido pelo produto das probabilidades dos itens do lado esquerdo e direito ocorrendo como se não houvesse associação entre eles. Por exemplo, se lápis, papel e borracha ocorreram juntos em 2,5% de todas as transações, lápis e papel em 10% das transações e borracha em 8% das transações, então o elevador seria: 0.025/(0.1*0.08) = 3.125. Uma elevação de mais de 1 sugere que a presença de lápis e papel aumenta a probabilidade de uma borracha também ocorrer na transação. Em geral, o elevador resume a força de associação entre os produtos do lado esquerdo e direito da regra; quanto maior o elevador maior a ligação entre os dois produtos.
para realizar uma análise do Cabaz de mercado e identificar regras potenciais, um algoritmo de mineração de dados chamado “algoritmo Apriori” é comumente usado, que funciona em duas etapas:
- sistematicamente identificar itemsets que ocorrem frequentemente no conjunto de dados com um suporte maior que um limiar pré-especificado.calcular a confiança de todas as regras possíveis, tendo em conta os itemsets frequentes, e manter apenas aqueles com uma confiança superior a um limiar pré-especificado.
os limiares para definir o suporte e a confiança são especificados pelo utilizador e são susceptíveis de variar entre conjuntos de dados de transacção. R tem valores padrão, mas recomendamos que você experimente com estes para ver como eles afetam o número de regras retornadas (mais sobre isso abaixo). Finalmente, embora o algoritmo Apriori não use o lift para estabelecer regras, você verá no seguinte que usamos o lift ao explorar as regras que o algoritmo retorna.
realizar a análise do Cabaz de mercado em R
para demonstrar como realizar um MBA que escolhemos usar r e, em particular, o pacote arules. Para aqueles que estão interessados incluímos o código R que usamos no final deste blog.aqui, seguimos o mesmo exemplo usado na vinheta de arulesViz e usamos um conjunto de dados de vendas de mercearias que contém 9.835 transações individuais com 169 itens. A primeira coisa que fazemos é dar uma olhada nos itens nas transações e, em particular, traçar a frequência relativa dos 25 itens mais frequentes na Figura 1. Isto é equivalente ao suporte destes itens onde cada conjunto de itemets contém apenas o único item. Este gráfico de barras ilustra as compras que são frequentemente compradas nesta loja, e é notável que o Suporte de até mesmo os itens mais freqüentes é relativamente baixo (por exemplo, o item mais freqüente ocorre em apenas cerca de 2,5% das transações). Usamos esses insights para informar o limiar mínimo ao executar o algoritmo Apriori; por exemplo, sabemos que para que o algoritmo retorne um número razoável de regras precisamos definir o limiar de suporte em bem abaixo de 0,025.
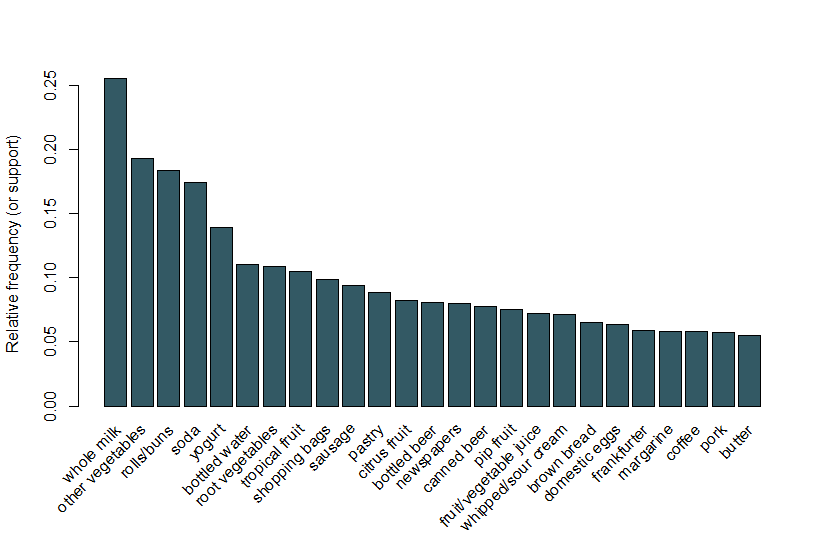
Figure 1 a bar plot of the support of the 25 most frequent items bought.
Através da definição de um suporte de limite de 0,001 e confiança de 0,5, podemos executar o algoritmo Apriori e obter um conjunto de 5,668 resultados. Estes valores-limite são escolhidos de modo a que o número de regras devolvidas seja elevado, mas esse número diminuiria se aumentássemos ambos os limiares. Recomendamos experimentar estes limiares para obter os valores mais adequados. Enquanto há muitas regras para ser capaz de olhar para todos eles individualmente, podemos olhar para as cinco regras com a maior elevação:
Excluir Suporte Confiança Elevador {instantâneas produtos alimentares,refrigerante}=>{hambúrguer de carne} 0.001 0.632 19.00 {refrigerante, pipoca}=>{salgados} 0.001 0.632 16.70 {flour, baking powder}=>{sugar} 0.001 0.556 16.41 {ham, processed cheese}=>{white bread} 0.002 0.633 15.05 {whole milk, instant food products}=>{hamburger meat} 0.002 0.500 15.04 Table 1: The five rules with the largest lift.
These rules seem to make intuitive sense. Por exemplo, a primeira regra pode representar o tipo de itens comprados para um churrasco, o segundo para uma noite de cinema e o terceiro para cozinhar.
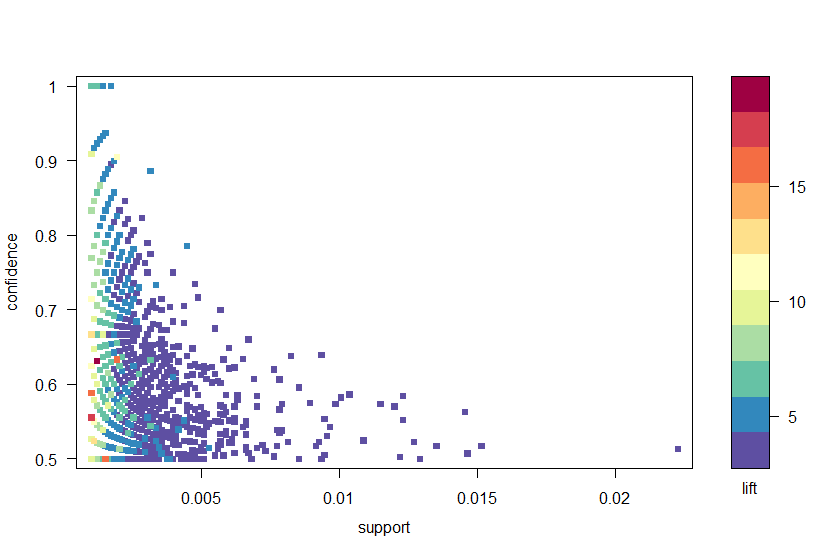
ao invés de usar os limiares para reduzir as regras para um conjunto menor, é normal que um conjunto maior de regras seja devolvido para que haja uma maior chance de gerar regras relevantes. Alternativamente, podemos usar técnicas de visualização para inspecionar o conjunto de regras retornadas e identificar aquelas que são susceptíveis de ser úteis.usando o pacote arulesViz, traçamos as regras pela confiança, suporte e elevação na Figura 2. Este enredo ilustra a relação entre as diferentes métricas. Tem sido demonstrado que as regras ótimas são aquelas que se encontram no que é conhecido como o “limite de suporte-confiança”. Essencialmente, estas são as regras que se encontram à direita do terreno, onde se maximiza o apoio, a confiança ou ambos. A função plot no Pacote arulesViz tem uma função interativa útil que lhe permite selecionar regras individuais (clicando no ponto de dados associado), o que significa que as regras no contorno podem ser facilmente identificadas.
Existem muitos outros lotes disponíveis para visualizar as regras, mas uma outra figura que recomendaria a explorar é o gráfico-base de visualização (ver Figura 3) das dez principais regras em termos de elevador (você pode incluir mais de dez, mas estes tipos de gráficos podem facilmente ficar confuso). Neste gráfico, os itens agrupados em torno de um círculo representam um conjunto de itemets e as setas indicam a relação em regras. Por exemplo, uma regra é que a compra de açúcar está associada a compras de farinha e fermento em pó. O tamanho do círculo representa o nível de confiança associado com a regra e a cor o nível de elevação (quanto maior o círculo e mais escuro o cinzento melhor).
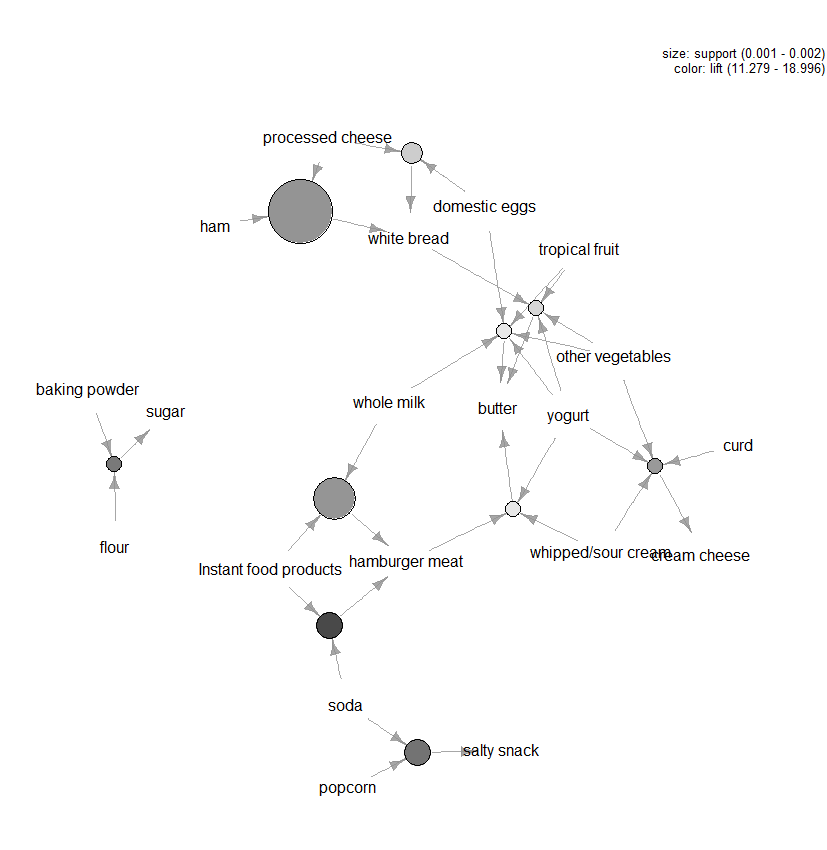
Figura 3: visualização gráfica das dez melhores regras em termos de elevação.
a análise do Cabaz de mercado é uma ferramenta útil para os varejistas que querem entender melhor as relações entre os produtos que as pessoas compram. Existem muitas ferramentas que podem ser aplicadas na realização de MBA e os aspectos mais difíceis da análise estão definindo os limiares de confiança e suporte no algoritmo Apriori e identificando quais regras valem a pena perseguir. Normalmente este último é feito medindo as regras em termos de métricas que resumem o quão interessantes elas são, usando técnicas de visualização e também estatísticas multivariadas mais formais. Em última análise, a chave para o MBA é extrair o valor de seus dados de transação, construindo uma compreensão das necessidades de seus consumidores. Este tipo de informação é inestimável se você estiver interessado em atividades de marketing, tais como vendas cruzadas ou campanhas específicas.se quiser saber mais sobre como analisar os seus dados de transacção, contacte-nos e teremos todo o gosto em ajudar.
R Code
library("arules")library("arulesViz")#Load data set:data("Groceries")summary(Groceries)#Look at data:inspect(Groceries)LIST(Groceries)#Calculate rules using apriori algorithm and specifying support and confidence thresholds:rules = apriori(Groceries, parameter=list(support=0.001, confidence=0.5))#Inspect the top 5 rules in terms of lift:inspect(head(sort(rules, by ="lift"),5))#Plot a frequency plot:itemFrequencyPlot(Groceries, topN = 25)#Scatter plot of rules:library("RColorBrewer")plot(rules,control=list(col=brewer.pal(11,"Spectral")),main="")#Rules with high lift typically have low support.#The most interesting rules reside on the support/confidence border which can be clearly seen in this plot.