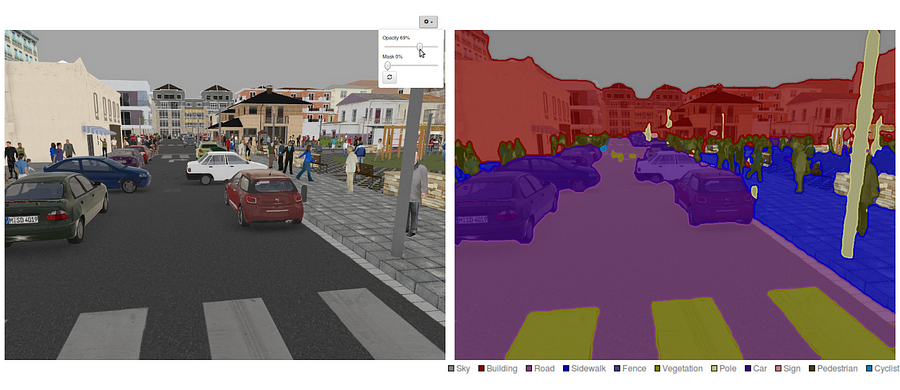
Como fazer a segmentação semântica usando a aprendizagem profunda
este artigo é uma visão geral abrangente, incluindo um guia passo a passo para implementar um modelo de segmentação de imagem de aprendizagem profunda.
compartilhamos um novo blog atualizado sobre segmentação semântica aqui: a 2021 guide to Semantic Segmentation
hoje em dia, segmentação semântica é um dos principais problemas no campo da visão computacional. Olhando para o quadro geral, a segmentação semântica é uma das tarefas de alto nível que abre o caminho para a compreensão completa da cena. A importância da compreensão de cena como um problema central de visão de computador é destacada pelo fato de que um número crescente de aplicações nutrem a partir de inferring conhecimento a partir de imagens. Algumas dessas aplicações incluem veículos de auto-condução, interação humano-computador, Realidade virtual, etc. Com a popularidade da aprendizagem profunda nos últimos anos, muitos problemas de segmentação semântica estão sendo abordados usando arquiteturas profundas, na maioria das vezes redes neurais convolucionais, que superam outras abordagens por uma grande margem em termos de precisão e eficiência.o que é segmentação semântica?
segmentação semântica é um passo natural na progressão de inferência grosseira a fina:a origem pode estar localizada na classificação, que consiste em fazer uma previsão para uma entrada inteira.O próximo passo é a localização / detecção, que fornecem não só as classes, mas também informações adicionais sobre a localização espacial dessas classes.Finalmente, a segmentação semântica alcança a inferência de grão fino, fazendo previsões densas inferindo etiquetas para cada pixel, de modo que cada pixel é rotulado com a classe de sua região de minério objeto envolvente.
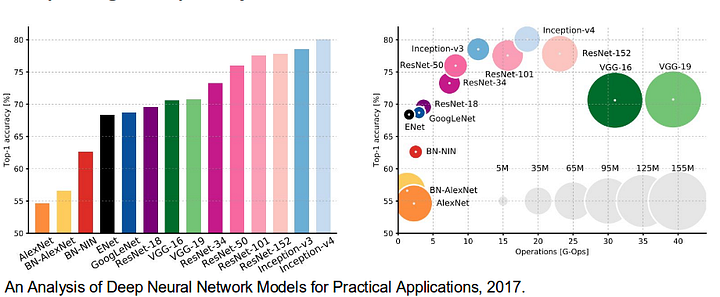
também é digno de rever algumas padrão profunda redes que fizeram contribuições significativas para o campo da visão de computador, como eles são normalmente usados como base para a semântica de segmentação de sistemas:
- AlexNet: Toronto pioneiro profunda da CNN, que não as de 2012 ImageNet concorrência com um teste de precisão de 84.6%. Consiste em 5 camadas convolucionais, pooling máximo, ReLUs como não linearidade, 3 camadas totalmente convolucionais, e desistência.
- VGG-16: Este modelo de Oxford ganhou a competição ImageNet 2013 com 92,7% de precisão. Ele usa uma pilha de camadas de convolução com pequenos campos receptivos nas primeiras camadas em vez de algumas camadas com grandes campos receptivos.GoogLeNet: esta rede do Google venceu a competição ImageNet de 2014 com uma precisão de 93,3%. Ele é composto por 22 camadas e um bloco de construção recém-introduzido chamado módulo inception. O módulo consiste de uma camada de rede em rede, uma operação de agrupamento, uma camada de convolução de grande porte e uma camada de convolução de pequeno porte.ResNet: este modelo da Microsoft ganhou a competição ImageNet 2016 com 96,4% de precisão. É bem conhecido devido à sua profundidade (152 camadas) e a introdução de blocos residuais. Os blocos residuais abordam o problema de treinar uma arquitetura realmente profunda, introduzindo conexões de skip identidade para que as camadas possam copiar suas entradas para a próxima camada.
- o Que são as existentes Semântica Segmentação abordagens?
- 1-segmentação semântica baseada em regiões
- 2-segmentação semântica baseada na rede totalmente convolucional
- 3 — fracamente supervisionada segmentação semântica
- fazendo segmentação semântica com rede totalmente convolucional
- Passo 1
- Passo 2
- Step 3
- Passo 4
- Passo 5
- você pode estar interessado em nossas últimas postagens em:
o Que são as existentes Semântica Segmentação abordagens?
uma arquitetura de segmentação semântica geral pode ser considerada como uma rede de codificadores seguida por uma rede de decodificadores:
- O codificador é geralmente uma rede de classificação pré-treinada como VGG/ResNet seguida por uma rede de decodificadores.
- a tarefa do decodificador é projetar semanticamente as características discriminatórias (resolução mais baixa) aprendidas pelo codificador no espaço de pixels (resolução mais alta) para obter uma classificação densa.
diferente da classificação onde o resultado final da rede muito profunda é a única coisa importante, a segmentação semântica não só requer discriminação ao nível de pixels, mas também um mecanismo para projetar as características discriminatórias aprendidas em diferentes estágios do codificador no espaço de pixels. Diferentes abordagens utilizam mecanismos diferentes como parte do mecanismo de descodificação. Vamos explorar as 3 principais abordagens:
1-segmentação semântica baseada em regiões
os métodos baseados em regiões geralmente seguem a” segmentação usando reconhecimento ” pipeline, que primeiro extrai regiões de forma livre de uma imagem e descreve-os, seguido de classificação baseada em regiões. No momento do teste, as previsões baseadas na região são transformadas em previsões de pixels, geralmente rotulando um pixel de acordo com a região de pontuação mais alta que o contém.
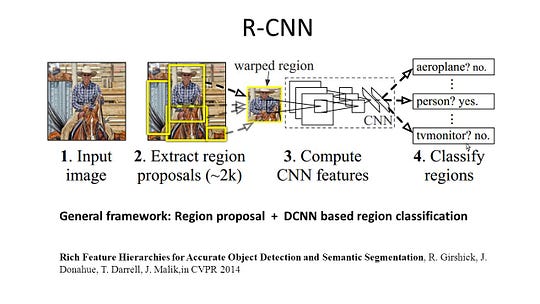
I-a CNN (Regiões com a CNN recurso) é um representante de trabalho para a região, com base em métodos. Ele realiza a segmentação semântica com base nos resultados de detecção de objetos. Para ser específico, R-CNN primeiro utiliza a pesquisa seletiva para extrair uma grande quantidade de propostas de objetos e, em seguida, calcula características CNN para cada um deles. Finalmente, classifica cada região usando a classe específica de SVMs lineares. Em comparação com as estruturas CNN tradicionais, que são principalmente destinadas à classificação de imagens, R-CNN pode abordar tarefas mais complicadas, como detecção de objetos e segmentação de imagens, e até se torna uma base importante para ambos os campos. Além disso, a R-CNN pode ser construída em cima de qualquer estrutura de referência da CNN, como AlexNet, VGG, GoogLeNet e ResNet.
para a tarefa de segmentação da imagem, R-CNN extraíu 2 tipos de recursos para cada região: recurso de região completa e recurso de primeiro plano, e descobriu que poderia levar a um melhor desempenho ao concatená-los juntos como o recurso de região. A R-CNN alcançou melhorias significativas de desempenho devido à utilização das características da CNN altamente discriminatórias. No entanto, ele também sofre de alguns inconvenientes para a tarefa de segmentação:
- o recurso não é compatível com a tarefa de segmentação.
- A característica não contém informação espacial suficiente para a produção precisa de limites.gerar propostas baseadas em segmentos leva tempo e afetaria muito o desempenho final.
devido a estes estrangulamentos, pesquisas recentes foram propostas para resolver os problemas, incluindo SDS, Hipercolumns, Máscara R-CNN.
2-segmentação semântica baseada na rede totalmente convolucional
a rede totalmente convolucional original (FCN) aprende um mapeamento de pixels para pixels, sem extrair as propostas da região. O gasoduto de rede FCN é uma extensão da CNN clássica. A ideia principal é fazer com que a CNN clássica tome como entrada imagens de tamanho arbitrário. A restrição do CNN de aceitar e produzir rótulos apenas para insumos de tamanho específico vem das camadas totalmente conectadas que são fixas. Ao contrário deles, os FCNs só têm camadas convolucionais e de agrupamento que lhes dão a capacidade de fazer previsões sobre entradas de tamanho arbitrário.
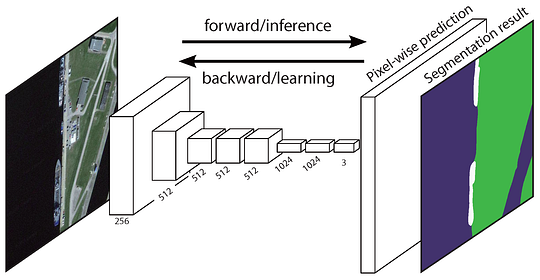
Um problema em específico FCN é que, propagando-se através de várias alternaram convolucionais e agrupamento de camadas, a resolução da saída de recurso de mapas é amostrada. Portanto, as previsões diretas da FCN são tipicamente em baixa resolução, resultando em limites de objetos relativamente difusos. Uma variedade de abordagens mais avançadas baseadas em FCN foram propostas para abordar esta questão, incluindo SegNet, DeepLab-CRF, e convoluções dilatadas.
3 — fracamente supervisionada segmentação semântica
a maioria dos métodos relevantes em Segmentação semântica dependem de um grande número de imagens com máscaras de segmentação em pixels. No entanto, anotar manualmente estas máscaras é bastante demorado, frustrante e comercialmente caro. Portanto, alguns métodos pouco supervisionados foram recentemente propostos, que são dedicados a cumprir a segmentação semântica, utilizando caixas delimitadoras anotadas.

Por exemplo, Boxsup empregados da caixa delimitadora as anotações como uma supervisão para treinar a rede e iterativamente melhorar as estimativas de máscaras para a semântica de segmentação. Simple does it treated the weak supervision limitation as an issue of input label noise and explored recursive training as a de-noising strategy. Pixel-level Labeling interpretou a tarefa de segmentação dentro do framework de aprendizagem de múltiplas instâncias e adicionou uma camada extra para restringir o modelo para atribuir mais peso a pixels importantes para a classificação de nível de imagem.
fazendo segmentação semântica com rede totalmente convolucional
nesta seção, vamos caminhar através de uma implementação passo a passo da arquitetura mais popular para segmentação semântica — a rede totalmente convolucional (FCN). Vamos implementá – lo usando a biblioteca TensorFlow no Python 3, juntamente com outras dependências como Numpy e Scipy.In este exercício vamos rotular os pixels de uma estrada em imagens usando FCN. Vamos trabalhar com o conjunto de dados da estrada Kitti para detecção de estrada/faixa. Este é um exercício simples a partir do Auto-Condução Do Carro nano-grau da Udacity programa, que você pode aprender mais sobre a configuração neste GitHub repo.

Aqui estão as principais características da FCN arquitetura:
- FCN transferências do conhecimento a partir de VGG16 para executar semântica de segmentação.
- as camadas totalmente conectadas de VGG16 é convertida em camadas totalmente convolucionais, usando convolução 1×1. Este processo produz um mapa de calor de presença de classe em baixa resolução.
- a ampliação destes mapas semânticos de baixa resolução é feita usando convoluções transpostas (inicializadas com filtros de interpolação bilineares).
- em cada fase, o processo de upsampling é ainda mais refinado, adicionando recursos a partir de coarser, mas de maior resolução apresentam mapas de camadas mais baixas em VGG16.
- Skip connection is introduced after each convolution block to enable the subsequent block to extract more abstract, class-salient features from the previously pooled features.
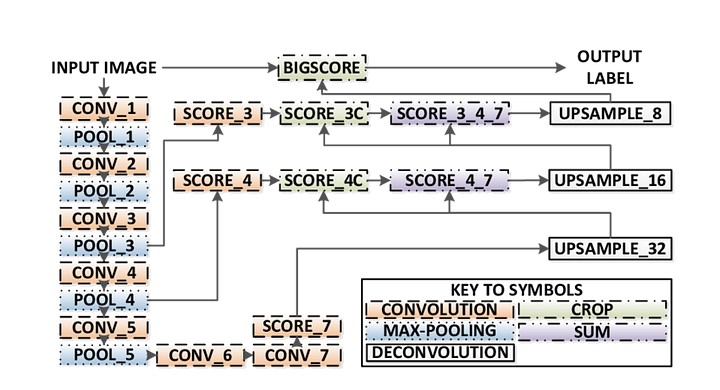
Existem 3 versões de FCN (FCN-32, FCN-16, FCN-8). Vamos implementar FCN-8, como detalhado passo a passo abaixo:
- codificador: um VGG16 pré-treinado é usado como um codificador. O decodificador começa a partir da camada 7 de VGG16.
- FCN Layer-8: a última camada totalmente conectada de VGG16 é substituída por uma convolução 1×1.
- FCN Layer-9: FCN Layer-8 é ampliado 2 vezes para combinar dimensões com a camada 4 de VGG 16, usando convolução transposta com parâmetros: (kernel=(4,4), stride=(2,2), paddding=’same’). Depois disso, uma conexão skip foi adicionada entre a camada 4 de VGG16 e a camada FCN-9.
- FCN Layer-10: FCN Layer-9 is upsampled 2 vezes to match dimensions with Layer 3 of VGG16, using transposed convolution with parameters: (kernel=(4,4), stride=(2,2), paddding=’same’). Depois disso, uma conexão skip foi adicionada entre a camada 3 de VGG 16 e a camada FCN-10.
- FCN Layer-11: FCN Layer-10 é ampliado 4 vezes para corresponder dimensões com o tamanho da imagem de entrada para que obtenhamos a imagem real de volta e profundidade é igual ao número de classes, usando convolução transposta com parâmetros:(kernel=(16,16), stride=(8,8), paddding=’same’).
Passo 1
primeiro carregar o pré-formados VGG-16 modelo em TensorFlow. Tendo em conta a sessão de TensorFlow e o caminho para a pasta VGG (que é transferível aqui), devolvemos a tupla de tensores do modelo VGG, incluindo a entrada de imagem, keep_prob (para controlar a taxa de desistência), camada 3, Camada 4 e camada 7.
def load_vgg(sess, vgg_path): # load the model and weights model = tf.saved_model.loader.load(sess, , vgg_path) # Get Tensors to be returned from graph graph = tf.get_default_graph() image_input = graph.get_tensor_by_name('image_input:0') keep_prob = graph.get_tensor_by_name('keep_prob:0') layer3 = graph.get_tensor_by_name('layer3_out:0') layer4 = graph.get_tensor_by_name('layer4_out:0') layer7 = graph.get_tensor_by_name('layer7_out:0') return image_input, keep_prob, layer3, layer4, layer7função VGG16
Passo 2
agora nos concentramos em criar as camadas para uma FCN, usando os tensores do modelo VGG. Tendo em conta os tensores para a saída da camada VGG e o número de classes a classificar, devolvemos o tensor para a última camada dessa saída. Em particular, aplicamos uma convolução 1×1 para as camadas do codificador, e em seguida adicionamos camadas de descodificador para a rede com conexões de salto e upsampling.
def layers(vgg_layer3_out, vgg_layer4_out, vgg_layer7_out, num_classes): # Use a shorter variable name for simplicity layer3, layer4, layer7 = vgg_layer3_out, vgg_layer4_out, vgg_layer7_out # Apply 1x1 convolution in place of fully connected layer fcn8 = tf.layers.conv2d(layer7, filters=num_classes, kernel_size=1, name="fcn8") # Upsample fcn8 with size depth=(4096?) to match size of layer 4 so that we can add skip connection with 4th layer fcn9 = tf.layers.conv2d_transpose(fcn8, filters=layer4.get_shape().as_list(), kernel_size=4, strides=(2, 2), padding='SAME', name="fcn9") # Add a skip connection between current final layer fcn8 and 4th layer fcn9_skip_connected = tf.add(fcn9, layer4, name="fcn9_plus_vgg_layer4") # Upsample again fcn10 = tf.layers.conv2d_transpose(fcn9_skip_connected, filters=layer3.get_shape().as_list(), kernel_size=4, strides=(2, 2), padding='SAME', name="fcn10_conv2d") # Add skip connection fcn10_skip_connected = tf.add(fcn10, layer3, name="fcn10_plus_vgg_layer3") # Upsample again fcn11 = tf.layers.conv2d_transpose(fcn10_skip_connected, filters=num_classes, kernel_size=16, strides=(8, 8), padding='SAME', name="fcn11") return fcn11Layers function
Step 3
o próximo passo é optimizar a nossa rede neural, aka construir funções de perda de fluxo tensorial e operações de optimização. Aqui nós usamos a entropia cruzada como nossa função de perda e Adam como nosso algoritmo de otimização.
def optimize(nn_last_layer, correct_label, learning_rate, num_classes): # Reshape 4D tensors to 2D, each row represents a pixel, each column a class logits = tf.reshape(nn_last_layer, (-1, num_classes), name="fcn_logits") correct_label_reshaped = tf.reshape(correct_label, (-1, num_classes)) # Calculate distance from actual labels using cross entropy cross_entropy = tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=correct_label_reshaped) # Take mean for total loss loss_op = tf.reduce_mean(cross_entropy, name="fcn_loss") # The model implements this operation to find the weights/parameters that would yield correct pixel labels train_op = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(loss_op, name="fcn_train_op") return logits, train_op, loss_opOtimizar a função
Passo 4
Aqui definimos o train_nn função, que leva em parâmetros importantes, incluindo o número de épocas, tamanho do lote, a perda de função, o otimizador de operação, e espaços reservados para imagens de entrada, rótulo de imagens, a velocidade de aprendizagem. Para o processo de treinamento, também definimos keep_probability para 0.5 e learning_rate para 0.001. Para acompanhar o progresso, também imprimimos a perda durante o treinamento.
def train_nn(sess, epochs, batch_size, get_batches_fn, train_op, cross_entropy_loss, input_image, correct_label, keep_prob, learning_rate): keep_prob_value = 0.5 learning_rate_value = 0.001 for epoch in range(epochs): # Create function to get batches total_loss = 0 for X_batch, gt_batch in get_batches_fn(batch_size): loss, _ = sess.run(, feed_dict={input_image: X_batch, correct_label: gt_batch, keep_prob: keep_prob_value, learning_rate:learning_rate_value}) total_loss += loss; print("EPOCH {} ...".format(epoch + 1)) print("Loss = {:.3f}".format(total_loss)) print()Passo 5
Finalmente, é hora de treinar a nossa rede! Nesta função de execução, primeiro construímos nossa rede usando o load_vgg, camadas, e otimizar a função. Então treinamos a rede usando a função train_nn e guardamos os dados de inferência para registros.
def run(): # Download pretrained vgg model helper.maybe_download_pretrained_vgg(data_dir) # A function to get batches get_batches_fn = helper.gen_batch_function(training_dir, image_shape) with tf.Session() as session: # Returns the three layers, keep probability and input layer from the vgg architecture image_input, keep_prob, layer3, layer4, layer7 = load_vgg(session, vgg_path) # The resulting network architecture from adding a decoder on top of the given vgg model model_output = layers(layer3, layer4, layer7, num_classes) # Returns the output logits, training operation and cost operation to be used # - logits: each row represents a pixel, each column a class # - train_op: function used to get the right parameters to the model to correctly label the pixels # - cross_entropy_loss: function outputting the cost which we are minimizing, lower cost should yield higher accuracy logits, train_op, cross_entropy_loss = optimize(model_output, correct_label, learning_rate, num_classes) # Initialize all variables session.run(tf.global_variables_initializer()) session.run(tf.local_variables_initializer()) print("Model build successful, starting training") # Train the neural network train_nn(session, EPOCHS, BATCH_SIZE, get_batches_fn, train_op, cross_entropy_loss, image_input, correct_label, keep_prob, learning_rate) # Run the model with the test images and save each painted output image (roads painted green) helper.save_inference_samples(runs_dir, data_dir, session, image_shape, logits, keep_prob, image_input)a função
Sobre nossos parâmetros, podemos escolher épocas = 40, batch_size = 16, num_classes = 2, e image_shape = (160, 576). Depois de fazer 2 testes passa com dropout = 0.5 e dropout = 0.75, descobrimos que o segundo teste produz melhores resultados com melhores perdas médias.

Para ver o código completo, confira este link: https://gist.github.com/khanhnamle1994/e2ff59ddca93c0205ac4e566d40b5e88
Se você gostou desta peça, Eu adoraria que compartilhar 👏 e difundir o conhecimento.
você pode estar interessado em nossas últimas postagens em:
- AWS Textract
- Data Extraction
comece a usar Nanonets para automação
Experimente o modelo ou solicite uma demonstração hoje!
TENTE AGORA
