Reading Code Right, With Some Help From The Lexer
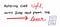
Software is all about logic. A programação ganhou a reputação de ser um campo pesado na matemática e nas equações malucas. E a Ciência da computação parece estar no cerne deste equívoco.
claro, há alguma matemática e há algumas fórmulas — mas nenhum de nós realmente precisa ter PhDs em cálculo, a fim de que possamos entender como nossas máquinas funcionam! De fato, muitas das regras e paradigmas que aprendemos no processo de escrever código são as mesmas regras e paradigmas que se aplicam a conceitos complexos de ciência da computação. E às vezes, essas idéias na verdade derivam da ciência da computação, e nós simplesmente nunca soubemos disso.
independentemente da linguagem de programação que usamos, quando a maioria de nós escreve o nosso código, pretendemos encapsular coisas distintas em classes, objetos ou métodos, separando intencionalmente o que diferentes partes do nosso Código estão preocupados. Em outras palavras, sabemos que é geralmente bom dividir nosso código para que uma classe, objeto ou método só esteja preocupado e responsável por uma única coisa. Se não fizéssemos isso, as coisas poderiam ficar super bagunçadas e entrelaçadas em uma bagunça de uma teia. Às vezes isso ainda acontece, mesmo com separação de preocupações.ao que parece, até o funcionamento interno dos nossos computadores segue paradigmas de design muito semelhantes. Nosso compilador, por exemplo, tem diferentes partes para ele, e cada parte é responsável por lidar com uma parte específica do processo de compilação. Nós encontramos um pouco disso na semana passada, quando aprendemos sobre o analisador, que é responsável pela criação de árvores de processamento. Mas o analisador não pode ser encarregado de tudo.
O analisador precisa de alguma ajuda de seus amigos, e é finalmente hora de aprender quem eles são!
Quando aprendemos sobre análise recentemente, mergulhamos nossos dedos do pé para a gramática, a sintaxe, e como o compilador reage e responde a essas coisas dentro de uma linguagem de programação. Mas nós nunca realçamos o que é exatamente um compilador! À medida que entramos no funcionamento interno do processo de compilação, vamos aprender muito sobre o design do compilador, então é vital para nós entendermos exatamente do que estamos falando aqui.
compiladores podem parecer meio assustadores, mas seus trabalhos não são realmente muito complexos para entender — particularmente quando dividimos as diferentes partes de um compilador em partes do tamanho de mordida.
mas primeiro, vamos começar com a definição mais simples possível. Um compilador é um programa que lê o nosso código (ou qualquer código, em qualquer linguagem de programação), e o traduz em outra linguagem.

Geralmente falando, um compilador só vai realmente traduzir o código de uma linguagem de alto nível para uma linguagem de baixo nível. As linguagens de nível inferior em que um compilador traduz o código é muitas vezes referido como código de montagem, código de máquina ou código objeto. Vale a pena mencionar que a maioria dos programadores não estão realmente lidando com ou escrevendo qualquer código de máquina; em vez disso, dependemos do compilador para pegar nossos programas e traduzi-los em código de máquina, que é o que nosso computador vai executar como um programa executável.
podemos pensar em compiladores como o intermediário entre nós, os programadores, e nossos computadores, que só podem executar programas executáveis em linguagens de nível inferior.
O compilador faz o trabalho de traduzir o que queremos que aconteça de uma forma que seja compreensível e executável por nossas máquinas.
sem o compilador, seríamos forçados a comunicar com nossos computadores escrevendo código de máquina, o que é incrivelmente ilegível e difícil de decifrar. O código da máquina pode muitas vezes parecer um monte de 0’s e 1’s para o olho humano — é tudo binário, lembras-te? – o que torna muito difícil ler, escrever e depurar. O compilador abstraído código de máquina para nós como programadores, porque tornou muito fácil para nós não pensar em código de máquina e escrever programas usando linguagens muito mais elegantes, claras e fáceis de ler.
continuaremos a desempacotar mais e mais sobre o misterioso compilador ao longo das próximas semanas, o que esperamos torná-lo menos um enigma no processo. Mas por agora, vamos voltar à questão em questão: Quais são as partes mais simples possíveis de um compilador?
cada compilador, não importa como ele pode ser projetado, tem fases distintas. Estas fases são como podemos distinguir as partes únicas do compilador.

já encontrámos uma das fases das nossas aventuras de compilação quando soubemos recentemente sobre o analisador e as árvores de processamento. Nós sabemos que o processamento é o processo de tomar alguma entrada e construir uma árvore de análise, que às vezes é referido como o ato de análise. Como acontece, o trabalho de análise de sintaxe é específico para uma fase no processo de compilação chamada análise de sintaxe.
no entanto,o analisador não constrói apenas uma árvore de análise do ar. Tem alguma ajuda! Recordaremos que o analisador recebe alguns tokens (também chamados terminais), e constrói uma árvore de processamento a partir desses tokens. Mas onde é que vai buscar essas fichas? Felizmente para o analisador, ele não tem que operar no vácuo; em vez disso, ele tem alguma ajuda.
isso nos leva a outra fase do processo de compilação, uma que vem antes da fase de análise de sintaxe: a fase de análise lexical.

O termo “lexical” refere-se ao significado de uma palavra isolada a partir da frase que o contém, e independentemente do seu gramaticais no contexto. Se tentarmos adivinhar o nosso próprio significado baseado apenas nesta definição, podemos afirmar que a fase de análise lexical tem a ver com as palavras/termos individuais no próprio programa, e nada a ver com a gramática ou o significado da frase que contém as palavras.
a fase de análise lexical é o primeiro passo no processo de compilação. Não conhece nem se importa com a gramática de uma frase ou com o Significado de um texto ou programa; tudo o que sabe é sobre o significado das próprias palavras.
Lexical analysis must occur before any code from a source program can be processed. Antes de poder ser lido pelo analisador, um programa deve ser digitalizado, dividido e agrupado de certas formas.
Quando começamos a olhar para a fase de análise da sintaxe na semana passada, aprendemos que a árvore de análise é construída olhando para partes individuais da frase e dividindo expressões em partes mais simples. Mas durante a fase de análise lexical, o compilador não sabe ou tem acesso a essas “partes individuais”. Em vez disso, ele tem que primeiro identificá-los e encontrá-los, e depois fazer o trabalho de dividir o texto em peças individuais.
Por exemplo, quando lemos uma frase de Shakespeare, como To sleep, perchance to dream., sabemos que os espaços e a pontuação são dividindo as “palavras” de uma frase. Isto é, claro, porque fomos treinados para ler uma frase, “lex”, e analisá-la para gramática.
mas, para um compilador, essa mesma frase pode parecer esta a primeira vez que a lê: Tosleepperhachancetodream. Quando lemos esta frase, é um pouco mais difícil para nós determinar quais são as “palavras” reais! Tenho a certeza que o nosso compilador pensa o mesmo.então, como é que a nossa máquina lida com este problema? Bem, durante a fase lexical de análise do processo de compilação, ele sempre faz duas coisas importantes: ele verifica o código, e então ele o avalia.

O trabalho de digitalização e de avaliação podem, por vezes, ser agrupados juntos em um único programa, ou pode ser separada em dois programas que dependem um do outro; é realmente apenas uma questão de como qualquer um compilador passou a ser concebido. O programa compilador, que é responsável por fazer o trabalho de digitalização e avaliação é muitas vezes referido como o lexer ou os lexemas, e toda a fase de análise léxica é às vezes chamado de processo de análise ou simbolização.
para digitalizar, por acaso ler
o primeiro dos dois principais passos da análise lexical é a digitalização. Podemos pensar na digitalização como o trabalho de realmente “ler” algum texto de entrada. Lembre-se que este texto de entrada pode ser uma cadeia, sentença, expressão, ou mesmo um programa inteiro! Não importa, porque, nesta fase do processo, é apenas uma bolha gigante de personagens que não significa nada ainda, e é um pedaço contíguo.
vamos olhar para um exemplo para ver como exatamente isso acontece. Usaremos a nossa frase original, To sleep, perchance to dream., que é o nosso texto de origem ou código-fonte. Para o nosso compilador, este texto-fonte será lido como texto de entrada que se parece com Tosleep,perchancetodream., que é apenas uma cadeia de caracteres que ainda tem de ser decifrada.

a primeira coisa que o nosso compilador tem que fazer é realmente dividir essa bolha de texto em suas menores peças possíveis, o que tornará muito mais fácil identificar onde as palavras na bolha de texto realmente estão.
a maneira mais simples de mergulhar em um pedaço gigante de texto é lendo-o lenta e sistematicamente, um personagem de cada vez. E isso é exatamente o que o compilador faz.
muitas vezes, o processo de digitalização é tratado por um programa separado chamado scanner, cuja única tarefa é fazer o trabalho de ler um arquivo de fonte / texto, um personagem de cada vez. Para o nosso scanner, não importa quão grande é o nosso texto; tudo o que ele vai ver quando “lê” nosso arquivo é um personagem de cada vez.
Aqui está o que nossa sentença shakespeariana seria lida como pelo nosso scanner:

vamos notar que To sleep, perchance to dream. foi dividido em caracteres individuais por nosso scanner. Além disso, mesmo os espaços entre as palavras estão sendo tratados como caracteres, como é a pontuação em nossa frase. Há também um personagem no final desta sequência que é particularmente interessante: eof. Este é o caráter “end of file”, e é semelhante a tabspace e newline. Uma vez que o nosso texto fonte é apenas uma única frase, quando o nosso scanner chega ao fim do ficheiro (neste caso, o fim da frase), lê o fim do ficheiro e trata-o como um carácter.
So, in actuality, when our scanner read our input text, it interpreted it as individual characters which resulted in this: .

Agora que o nosso scanner leu e dividiu o nosso texto fonte em suas menores partes possíveis, ele terá um tempo muito mais fácil de descobrir as” palavras ” em nossa sentença.
em seguida, o scanner precisa olhar para seus caracteres divididos em ordem, e determinar quais caracteres são partes de uma palavra, e quais não são. Para cada caractere que o scanner lê, ele marca a linha e a posição de onde esse caractere foi encontrado no texto fonte.
A imagem mostrada aqui ilustra este processo para a nossa sentença shakespeariana. Podemos ver que nosso scanner está marcando a linha e a coluna para cada personagem em nossa sentença. Podemos pensar na representação de linha e coluna como uma matriz ou matriz de caracteres.
Recall that, since our file has only one single line in it, everything lives at line 0. No entanto, à medida que trabalhamos nosso caminho através da frase, a coluna de cada personagem aumenta. Vale ressaltar também que, desde o nosso scanner lê spacesnewlineseof, e todos os sinais de pontuação como personagens, aqueles que aparecem em nossa tabela de caracteres, também!

Uma vez que o texto de origem foi digitalizado e marcado, o nosso compilador está pronto para transformar estes caracteres em palavras. Desde que o scanner não sabe exatamente onde o spacesnewlines e eof no arquivo, mas também de onde eles moram em relação a outras personagens ao seu redor, ele pode verificar através de personagens, e dividi-os em seqüências de caracteres individuais conforme necessário.
No nosso exemplo, o scanner irá olhar para os caracteres T, então o e, em seguida, uma space. Quando ele encontra um espaço, ele vai dividir To em sua própria palavra — a combinação mais simples de caracteres possíveis antes do scanner encontrar um espaço.
é uma história similar para a próxima palavra que encontra, que é sleep. No entanto, neste cenário, lê-se s-l-e-e-p, e então lê-se um ,, uma marca de pontuação. Uma vez que esta vírgula é flanqueada por um personagem (p) e um space de ambos os lados, a vírgula É, por si só, considerada uma “palavra”.
a palavra sleep e o símbolo de pontuação , são chamados lexèmes, que são subseqüências o texto-fonte. Um lexeme é um agrupamento das menores sequências possíveis de caracteres no nosso código-fonte. Os lexemas de um arquivo fonte são considerados as “palavras” individuais do próprio arquivo. Assim que o nosso scanner terminar de ler os caracteres únicos do nosso Ficheiro, irá devolver um conjunto de lexemas que se parecem com este: .

Repare como o nosso scanner levou um bocado de texto como entrada, o que não poderia, inicialmente, ler, e começou a examiná-lo uma vez carácter de cada vez e, simultaneamente, a leitura e marcação de conteúdo. Em seguida, passou a dividir a cadeia em seus lexemas menores possíveis, usando os espaços e pontuação entre os caracteres como delimitadores.
no entanto, apesar de todo este trabalho, neste ponto na fase de análise lexical, nosso scanner não sabe nada sobre estas palavras. Claro, ele dividiu o texto em palavras de diferentes formas e tamanhos, mas na medida em que essas palavras são o scanner não tem idéia! As palavras podem ser uma corda literal, ou podem ser uma marca de pontuação, ou podem ser algo completamente diferente!
o scanner não sabe nada sobre as próprias palavras, ou que” tipo ” de palavra são. Só sabe onde terminam as palavras e começa no próprio texto.
isto indica-nos para a segunda fase da análise lexical: avaliação. Uma vez que digitalizamos nosso texto e dividimos o código fonte em unidades lexeme individuais, devemos avaliar as palavras que o scanner nos devolveu e descobrir com que tipos de palavras estamos lidando — em particular, devemos procurar palavras importantes que significam algo especial na linguagem que estamos tentando compilar.
avaliando as partes importantes
Depois de terminarmos a digitalização do nosso texto de origem e identificarmos os nossos lexemas, teremos de fazer alguma coisa com o nosso lexeme “palavras”. Este é o passo de avaliação da análise lexical, que é muitas vezes referido em complier design como o processo de laxing ou tokenizing nossa entrada.

quando avaliamos o nosso código digitalizado, tudo o que estamos a fazer é olhar mais de perto para cada um dos lexemas que o nosso scanner gerou. O nosso compilador vai precisar de olhar para cada palavra lexeme e decidir que tipo de palavra é. O processo de determinar que tipo de lexeme cada “palavra” em nosso texto é como nosso compilador transforma cada lexeme individual em um token, assim tokenizando nossa cadeia de entrada.
encontrámos pela primeira vez fichas quando estávamos a aprender sobre árvores de processamento. Tokens são símbolos especiais que estão no cerne de cada linguagem de programação. Tokens, tais como (, ), +, -, if, else, then, todos ajudam um compilador a entender como diferentes partes de uma expressão e vários elementos se relacionam entre si. O analisador, que é central para a fase de análise de sintaxe, depende de receber tokens de algum lugar e, em seguida, transforma esses tokens em uma árvore de processamento.

Well, guess what? Finalmente descobrimos o “algures”! Como acontece, os tokens que são enviados para o analisador são gerados na fase de análise lexical pelo tokenizer, também chamado de lexer.

então o que exatamente um token se parece? Um token é bastante simples, e é geralmente representado como um par, consistindo de um nome token, e algum valor (que é opcional).
Por exemplo, se nós tokenize nossa string shakespeariana, nós terminaríamos com tokens que seriam principalmente literais de string e separadores. Poderíamos representar o lexeme "dream” como um token assim: <string literal, "dream">. Em uma veia semelhante, poderíamos representar o lexeme . como o token, <separator, .>.
vamos notar que cada um destes tokens não estão modificando o lexeme em tudo-eles estão simplesmente adicionando informações adicionais a eles. Um token é lexeme ou unidade lexical com mais detalhes; especificamente, o detalhe adicionado nos diz que categoria de token (que tipo de “palavra”) estamos lidando com.
Agora que nós temos tokenized nossa sentença shakespeariana, nós podemos ver que não há toda essa variedade nos tipos de tokens em nosso arquivo fonte. A nossa frase só tinha cordas e pontuação, mas isso é só a ponta do iceberg simbólico! Há muitos outros tipos de” Palavras ” em que um lexeme pode ser categorizado.

a tabela mostrada aqui ilustra alguns dos tokens mais comuns que o nosso compilador veria ao ler um ficheiro de código em praticamente qualquer linguagem de programação. Vimos exemplos de literals, que pode ser qualquer cadeia de caracteres, número, ou de lógica/valor booleano, bem como separators, que são qualquer tipo de pontuação, incluindo chaves ({}) e parênteses (()).
However, there are also keywords, which are terms that are reserved in the language (such as ifvarwhilereturn), as well as operators, which operate on arguments and return some value ( +-x/). Podemos também encontrar lexèmes que poderia ser simbolizado como identifiers, que, geralmente, são nomes de variáveis ou coisas escritas pelo usuário/programador para fazer referência a algo mais, como bem como , que pode ser de linha ou bloco de comentários escritos pelo usuário.a nossa frase original só nos mostrou dois exemplos de fichas. Vamos reescrever nossa sentença para ler: var toSleep = "to dream";. Como pode o nosso compilador lex esta versão de Shakespeare?

aqui, veremos que temos uma maior variedade de fichas. Temos uma keyword no var, onde estamos declarando uma variável e uma identifiertoSleep, que é o caminho que estamos a atribuição de nomes a nossa variável, ou referenciar o valor para vir. A seguir está o nosso =, que é um operator token, seguido pelo string literal"to dream". A nossa Declaração termina com um separador;, indicando o fim de uma linha e delimitando espaços em branco.
Uma coisa importante a notar sobre o processo de tokenização é que nós não estamos tokenizing nenhum espaço em branco (espaços, linhas novas, tabs, fim de linha, etc.), nem passá-lo para o analisador. Lembre-se que apenas os tokens são dados ao analisador e vai acabar na árvore de processamento.
também vale a pena mencionar que diferentes línguas terão diferentes caracteres que constituem como espaço em branco. Por exemplo, em algumas situações, a linguagem de programação Python usa indentação — incluindo tabs e espaços — a fim de indicar como o escopo de uma função muda. Assim, o Python compilador de lexemas precisa estar ciente do fato de que, em determinadas situações, uma tab ou space na verdade, não precisa ser simbolizado como uma palavra, porque, na verdade, não precisa ser passado para o parser!

Este aspecto da lexemas é uma boa maneira de contraste como um lexer/lexemas é diferente de um scanner. Enquanto um scanner é ignorante, e só sabe como quebrar um texto em suas partes menores possíveis (suas “palavras”), um lexer/tokenizer é muito mais consciente e mais preciso em comparação.
o tokenizer precisa saber as complexidades e especificações da linguagem que está sendo compilada. Se tabs são importantes, ele precisa saber que; se newlines pode ter certos significados na língua que está sendo compilado, os lexemas precisa estar atenta a esses detalhes. Por outro lado, o scanner nem sequer sabe quais são as palavras que divide, muito menos o que significam.
o scanner de um complier é muito mais agnóstico da linguagem, enquanto um tokenizer deve ser específico da linguagem por definição.
estas duas partes do processo de análise lexical vão lado a lado, e elas são centrais para a primeira fase do processo de compilação. Naturalmente, diferentes compliers são projetados em suas próprias maneiras únicas. Alguns compiladores fazem o passo de digitalização e tokenizing em um único processo e como um ÚNICO programa, enquanto outros irão dividi-los em classes diferentes, em que caso o tokenizer vai chamar para a classe scanner quando ele é executado.

em ambos os casos, o passo da análise lexical é super importante para a compilação, porque a fase de análise de sintaxe depende diretamente dela. E mesmo que cada parte do compilador tenha seus próprios papéis específicos, eles se apoiam uns nos outros e dependem uns dos outros — assim como bons amigos sempre fazem.
recursos
Uma vez que existem muitas maneiras diferentes de escrever e projetar um compilador, também existem muitas maneiras diferentes de ensiná-los. Se você fizer pesquisas suficientes sobre os fundamentos da compilação, torna-se bastante claro que algumas explicações vão em muito mais detalhes do que outras, o que pode ou não ser útil. Se você se encontrar querendo aprender mais, abaixo estão uma variedade de recursos em compiladores — com foco na fase de análise lexical.
- Capítulo 4 — Elaboração de Intérpretes, Robert Nystrom
- Compilador de Construção, o Professor Allan Gottlieb
- Compilador Básico, o Professor James Alan Farrell
- a Escrita de uma linguagem de programação — o Lexer, Andy Balaão
- Notas sobre Como Analisadores e Compiladores de Trabalho, Stephen Raymond Ferg
- Qual é a diferença entre um símbolo e um lexeme?, StackOverflow