seaborn.histplot¶
seaborn.histplot(dados=Nenhum, *, x=Nenhum, y=Nenhum, hue=Nenhum, pesos=Nenhum, stat=’contagem’, bandejas=’auto’, binwidth=Nenhum, binrange=Nenhum, discreto=Nenhum, cumulativa=False, common_bins=True, common_norm=True, vários=’camada’, elemento= “barras”, fill=True, psiquiatra=1, kde=False, kde_kws=Nenhum, line_kws=Nenhum, thresh=0, pthresh=Nenhum, pmax=Nenhum, cbar=False, cbar_ax=Nenhum, cbar_kws=Nenhum, paleta=Nenhum, hue_order=Nenhum, hue_norm=Nenhum, color=None, log_scale=Nenhum, legend=True, ax=Nenhum, **kwargs)¶
Plot univariada ou bivariadas histogramas para mostrar distribuições de conjunto.
um histograma é uma ferramenta de visualização clássica que representa a distribuição de uma ou mais variáveis, contando o número de observações que caem com silos indisretos.
Esta função pode normalizar a estatística calculada dentro de cada bin para estimatefrequency, densidade ou de probabilidade de massa, e pode adicionar uma curva suave obtainedusing uma estimativa de densidade de kernel, semelhante ao kdeplot().
Mais informação é fornecida no Guia do utilizador.
Parameters datapandas.DataFramenumpy.ndarray, mapping, or sequence
Input data structure. Ou uma coleção de vetores de forma longa que pode ser atribuída a variáveis nomeadas ou um conjunto de dados de forma ampla que será incorporado internamente.
x, yvectores ou chaves emdata
variáveis que especificam posições nos eixos x e Y.
huevector ou chave emdata
variável semântica que é mapeada para determinar a cor dos elementos do gráfico.
weightsvector ou key indata
Se fornecido, pondere a contribuição dos pontos de dados correspondentes para a contagem em cada cesto por estes factores.
stat{“count”, “frequency”, “density”, “probability”}
estatística agregada para computar em cada caixa.
-
countmostra o número de observações -
frequencymostra o número de observações dividida pelo bin largura -
densitynormaliza as contagens de modo que a área do histograma é 1 -
probabilitynormaliza as contagens de modo que a soma das alturas das barras 1
binsstr, número, vetor, ou um par de tais valores
Genérico bin parâmetro que pode ser o nome de uma referência de regra,o número de contentores, ou a quebra dos bins.Passada para numpy.histogram_bin_edges().
binwidthnumber ou um par de números
Largura de cada bin, substitui bins mas pode ser usado combinrange.
binrangepair of numbers or a pair of pairs
Lowest and highest value for bin edges; can be used eitherwith bins or binwidth. Por omissão, os extremos dos dados.
discretebool
If True, default to binwidth=1 and draw the bars so that they arecentered on their corresponding data points. Isto evita “lacunas” que podem aparecer de outra forma ao usar dados discretos (inteiros).se for verdadeiro, plotar as contagens cumulativas como aumento de células.
common_binsbool
If True, use the same bins when semantic variables produce multipleplots. If using a reference rule to determine the bins, it will be computed with the full dataset.
common_normbool
If True and using a normalized statistic, the normalization will apply over the full dataset. Caso contrário, normalize cada histograma de forma independente.
multiple{“layer”,” dodge”,” stack”,” fill”}
Approach to resolving multiple elements when semantic mapping creates subsets.Apenas relevante com dados univariados.
elemento {“barras”, “passo”, “Poli”}
representação Visual da Estatística do histograma.Apenas relevante com dados univariados.
fillbool
Se for verdadeiro, preencha o espaço sob o histograma.Apenas relevante com dados univariados.
shrinknumber
Escale a largura de cada barra em relação à largura do binwidth por este fator.Apenas relevante com dados univariados.
kdebool
Se for verdadeiro, calcula uma estimativa da densidade do kernel para suavizar a distribuição e mostrar no gráfico como (uma ou mais) Linha(s).Apenas relevante com dados univariados.
Kde_ kwsdict
parâmetros que controlam o cálculo do KDE, como em kdeplot().
line_kwsdict
parâmetros que controlam a visualização do KDE, passados paramatplotlib.axes.Axes.plot().as células com uma estatística inferior ou igual a este valor serão transparentes.Apenas relevante com dados bivariados.
pthreshnumber ou Nenhum
Como thresh, mas um valor tal que as células com agregação de contagens(ou outras estatísticas, quando utilizados) até esta proporção do total betransparent.
pmaxnumber ou Nenhum
Um valor que define que ponto de saturação para a colormap em um valuesuch que as células abaixo constistute esta proporção do total count (orother estatística, quando usado).
cbarbool
Se for verdadeiro, adicione uma barra de cores para anotar o mapeamento de cores num gráfico bivariado.Nota: não suporta actualmente parcelas com um hue bem variável.
cbar_axmatplotlib.axes.Axes
eixos pré-existentes para a barra de cores.
cbar_ kwsdict
parâmetros adicionais passaram para matplotlib.figure.Figure.colorbar().
palettestring, list, dict, ormatplotlib.colors.Colormap
método para escolher as cores a usar ao mapear ohue semântica.Os valores das cadeias são passados para color_palette(). List ou dict apenas mapeamento categórico, enquanto um objeto de colormap implica mapeamento numérico.
hue_ordervector of strings
especifique a ordem de processamento e plotagem para níveis categóricos dohue semântico.
hue_normtuple oumatplotlib.colors.Normalize
ou um par de valores que configuram o intervalo de normalização em unidades de dados ou um objecto que irá mapear a partir de unidades de dados para um intervalo. O usagimplies o mapeamento numérico.
cor
especificação de cor única para quando o mapeamento de matiz não é usado. Caso contrário, theplot vai tentar ligar-se ao ciclo de propriedade matplotlib.
log_ scalebool ou number, ou par de bools ou números
defina uma escala de log no eixo de dados (ou eixos, com dados bivariados) com a base given (por omissão 10), e avalie o KDE no espaço de log.
legendbool
Se falso, suprimir a legenda para variáveis semânticas.
axmatplotlib.axes.Axes
eixos pré-existentes para a parcela. Caso contrário, chamar matplotlib.pyplot.gca()internamente.
kwargs
outros argumentos da palavra-chave são passados para um dos seguintes matplotlibfunctions:
-
matplotlib.axes.Axes.bar()(univariate, element=”bars”) -
matplotlib.axes.Axes.fill_between()(univariate, other element, fill=True) -
matplotlib.axes.Axes.plot()(univariate, other element, fill=False) -
matplotlib.axes.Axes.pcolormesh()(bivariate)
Returnsmatplotlib.axes.Axes
The matplotlib axes containing the plot.
See also
displot
Figure-level interface to distribution plot functions.
kdeplot
plotar distribuições univariadas ou bivariadas utilizando a estimativa da densidade do núcleo.
rugplot
desenhar uma carraça em cada valor de observação ao longo dos eixos x e/ou Y.
ecdfplot
Plot empirical cumulative distribution functions.
jointplot
desenhar uma parcela variável com distribuições marginais univariadas.
Notes
The choice of bins for computing and plotting a histogram can exertsubstantial influence on the insights that one is able to draw from thevisualization. Se os caixotes são muito grandes, eles podem apagar características importantes.Por outro lado, os caixotes que são muito pequenos podem ser dominados pela variabilidade aleatória, obscurecendo a forma da verdadeira distribuição subjacente. O tamanho do bindefault é determinado usando uma regra de referência que depende do tamanho e variância do exemplo. Isto funciona bem em muitos casos, (i.e., com dados”bem comportados”), mas falha em outros. É sempre bom experimentar diferentes tamanhos de BINs para ter a certeza de que não lhe falta algo importante.Esta função permite que você especifique caixas de várias maneiras diferentes, como por definir o número total de caixas a usar, a largura de cada caixa, ou locais específicos onde as caixas devem quebrar.
Exemplos
Atribuir uma variável para x para desenhar um univariada distribuição ao longo do eixo x:
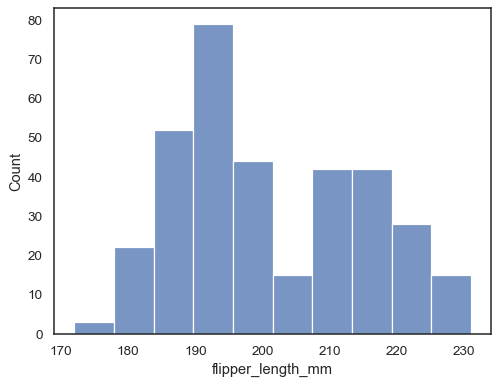
penguins = sns.load_dataset("penguins")sns.histplot(data=penguins, x="flipper_length_mm")
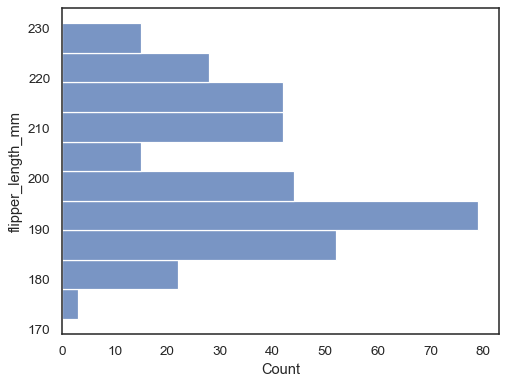
Flip the plot by assigning the data variable to the y axis:
sns.histplot(data=penguins, y="flipper_length_mm")
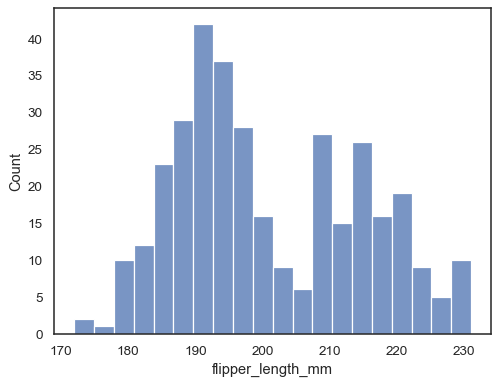
Verificar como o histograma representa os dados especificando adifferent bin largura:
sns.histplot(data=penguins, x="flipper_length_mm", binwidth=3)
Pode também definir o número total de contentores a utilizar:
sns.histplot(data=penguins, x="flipper_length_mm", bins=30)
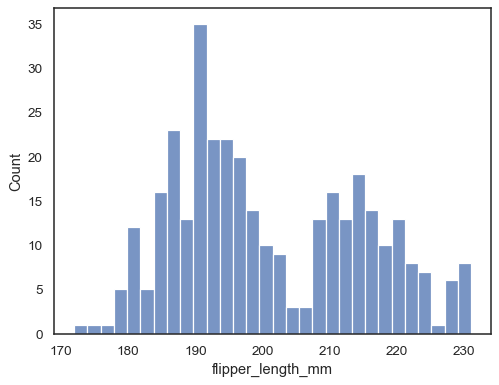
Adicionar um kernel da estimativa de densidade para suavizar o histograma, providingcomplementary informações sobre a forma de distribuição:
sns.histplot(data=penguins, x="flipper_length_mm", kde=True)
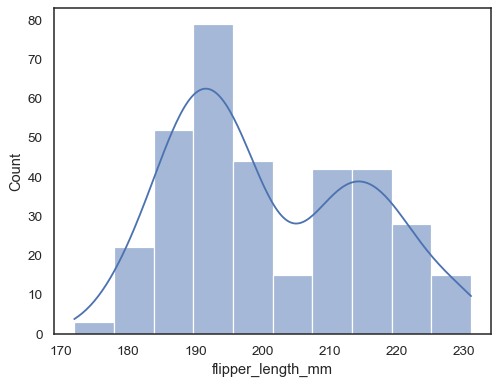
Se nem x nem y é atribuído, o conjunto de dados é tratada aswide-forma, e um histograma é desenhado para cada coluna numérica:
sns.histplot(data=penguins)
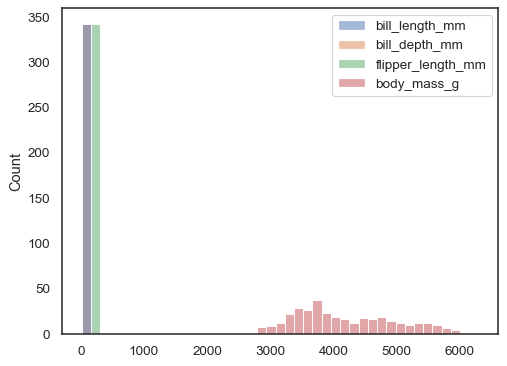
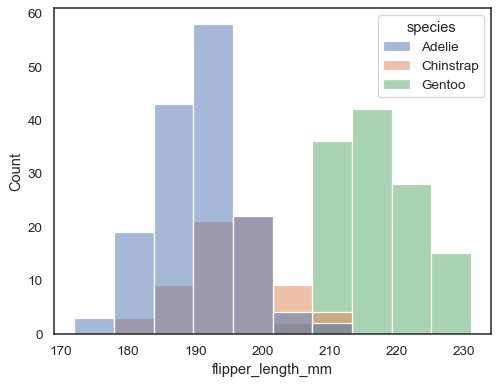
pode, de outro modo, desenhar vários histogramas a partir de um conjunto de dados de forma longa com mapeamento de matiz:
sns.histplot(data=penguins, x="flipper_length_mm", hue="species")
a abordagem padrão para plotar várias distribuições é para “camada” elas, mas você também pode “empilhá-las”:
sns.histplot(data=penguins, x="flipper_length_mm", hue="species", multiple="stack")
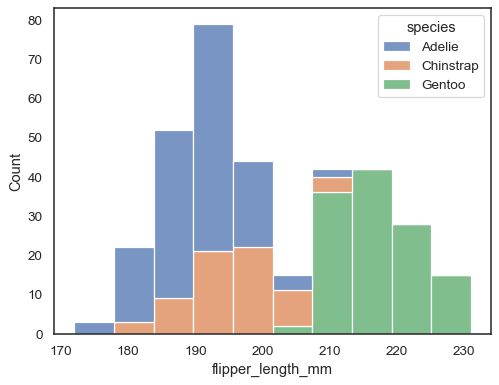
podem ser difíceis de resolver visualmente. Uma abordagem diferente seria desenhar uma função de passo:
sns.histplot(penguins, x="flipper_length_mm", hue="species", element="step")
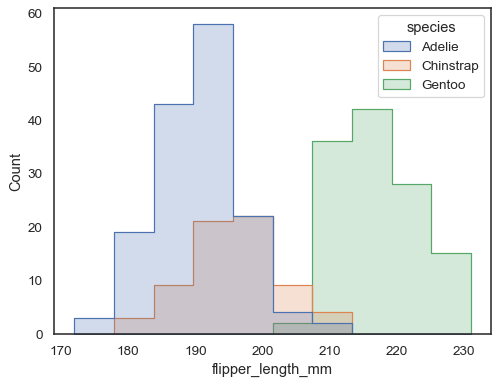
você pode se mover ainda mais longe das barras desenhando um polígono com vértices no centro de cada bin. Isto pode tornar mais fácil ver a paisagem da distribuição, mas use com cuidado: será menos óbvio para o seu público que eles estão olhando para um histograma:
sns.histplot(penguins, x="flipper_length_mm", hue="species", element="poly")
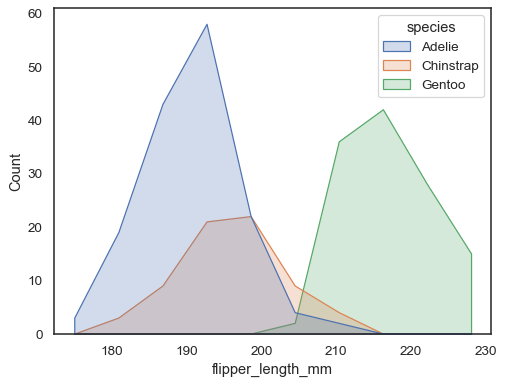
Para comparar a distribuição dos subconjuntos que diferem substancialmente insize, use indepdendent densidade de normalização:
sns.histplot( penguins, x="bill_length_mm", hue="island", element="step", stat="density", common_norm=False,)
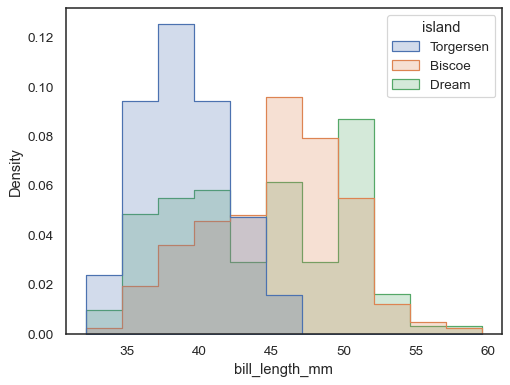
também É possível normalizar, de modo que cada barra de altura mostra aprobability, que fazem mais sentido para variáveis discretas:
tips = sns.load_dataset("tips")sns.histplot(data=tips, x="size", stat="probability", discrete=True)
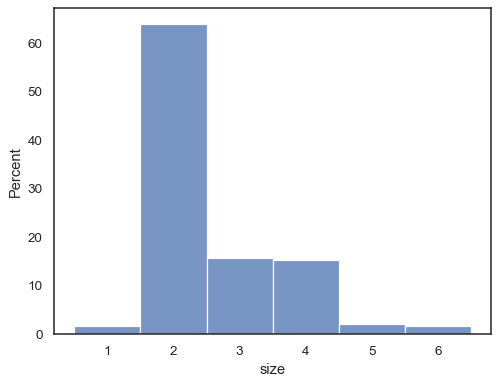
Você pode até mesmo desenhar um histograma mais variáveis categóricas (embora thisis um recurso experimental):
sns.histplot(data=tips, x="day", shrink=.8)
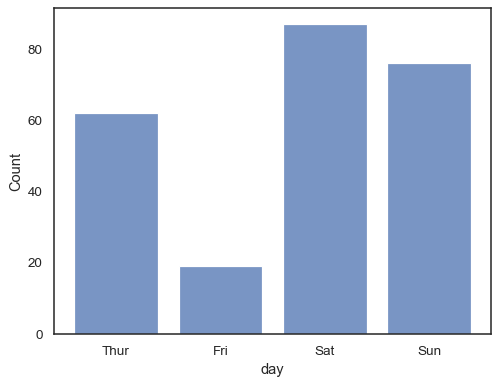
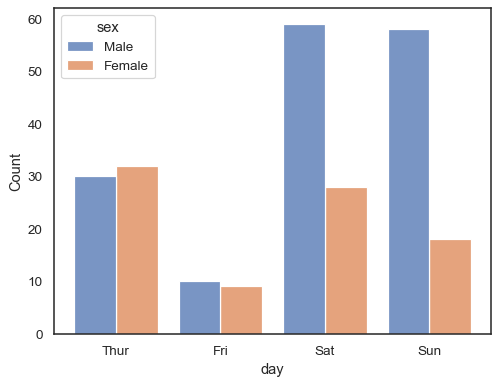
Quando usar um hue semântica com dados discretos, pode fazer sentido para”dodge” os níveis:
sns.histplot(data=tips, x="day", hue="sex", multiple="dodge", shrink=.8)
dados do mundo Real são frequentemente distorcidos. Para distribuições fortemente distorcidas, é melhor definir os contentores no espaço de log. Comparar:
planets = sns.load_dataset("planets")sns.histplot(data=planets, x="distance")
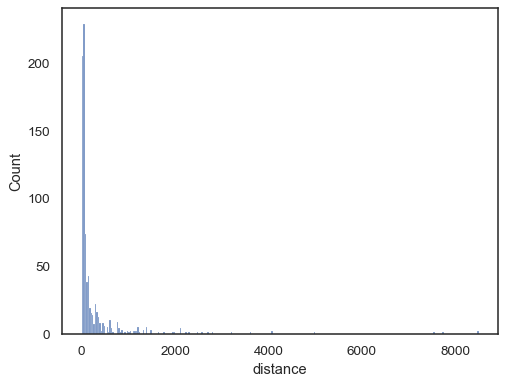
To the log-scale version:
sns.histplot(data=planets, x="distance", log_scale=True)
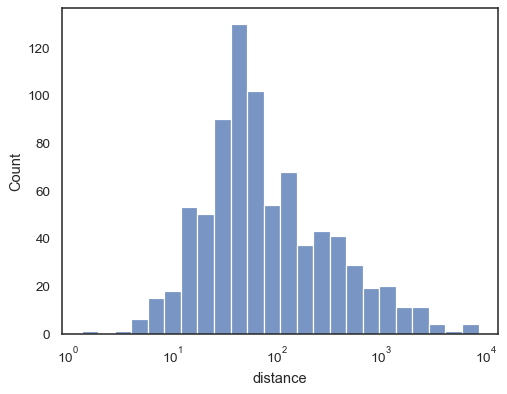
There are also a number of options for how the histogram appears. Youcan show unfilled bars:
sns.histplot(data=planets, x="distance", log_scale=True, fill=False)
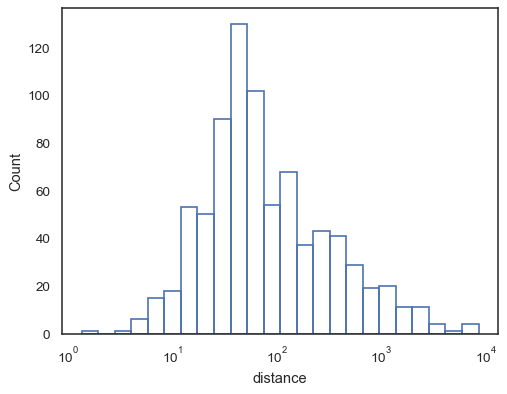
Or an unfilled step function:
sns.histplot(data=planets, x="distance", log_scale=True, element="step", fill=False)
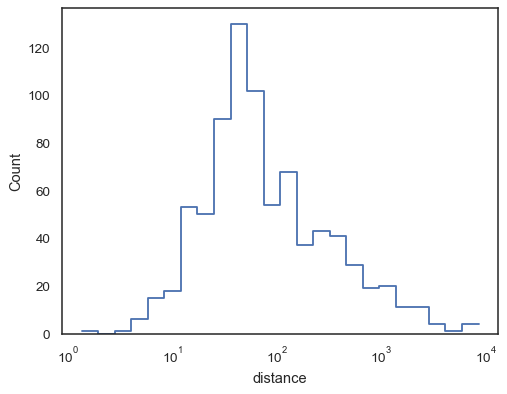
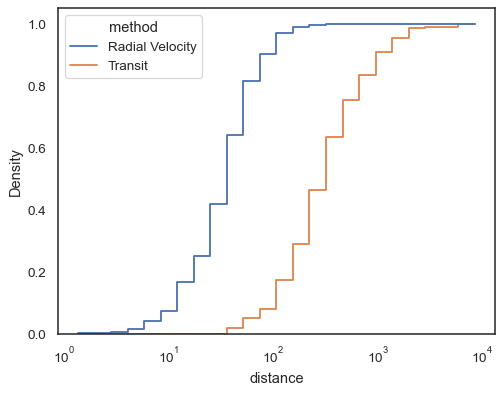
a Etapa funções, esepcially quando não preenchidas, torná-lo fácil para comparecumulative histogramas:
sns.histplot( data=planets, x="distance", hue="method", hue_order=, log_scale=True, element="step", fill=False, cumulative=True, stat="density", common_norm=False,)
Quando x e y são atribuídos, um bivariadas histograma iscomputed e mostrado como um mapa de calor:
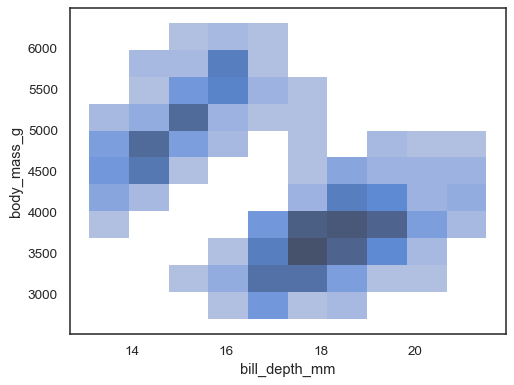
sns.histplot(penguins, x="bill_depth_mm", y="body_mass_g")
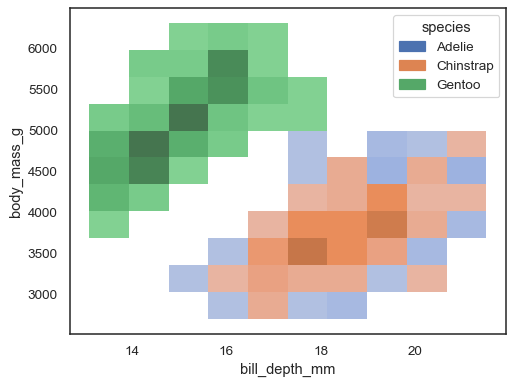
É possível atribuir um hue muito variável, embora isso notwork bem se dados a partir de diferentes níveis de considerável sobreposição:
sns.histplot(penguins, x="bill_depth_mm", y="body_mass_g", hue="species")
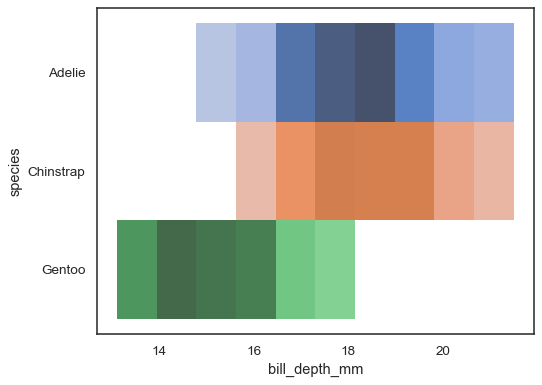
Vários mapas de cor pode fazer sentido quando uma das variáveis isdiscrete:
sns.histplot( penguins, x="bill_depth_mm", y="species", hue="species", legend=False)
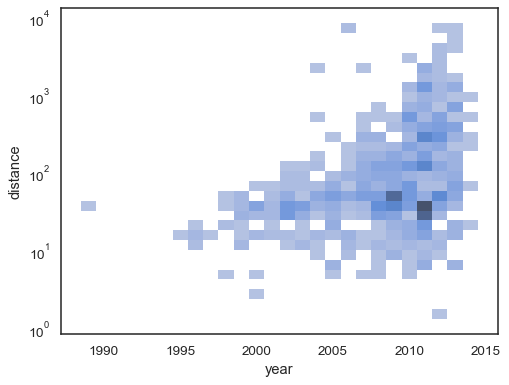
bivariada histograma aceita as mesmas opções para computationas sua univariada contrapartida, usando de tuplas para parametrizar x ey de forma independente:
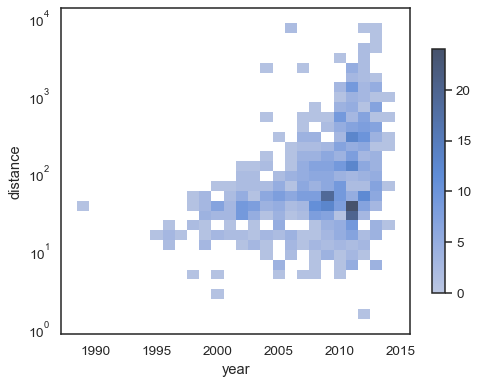
sns.histplot( planets, x="year", y="distance", bins=30, discrete=(True, False), log_scale=(False, True),)
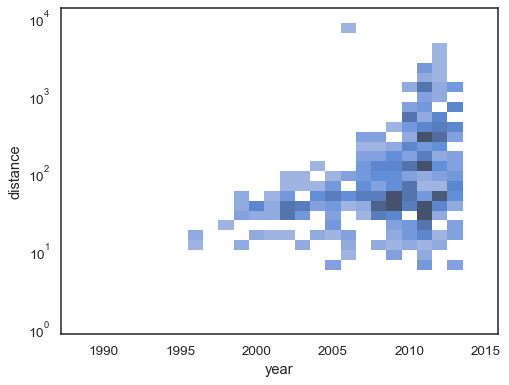
o comportamento por omissão faz com que as células sem observações sejam transparentes, embora isto possa ser desactivado:
sns.histplot( planets, x="year", y="distance", bins=30, discrete=(True, False), log_scale=(False, True), thresh=None,)
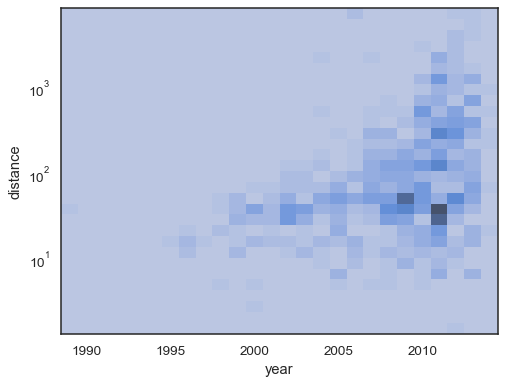
também É possível definir o limite e colormap ponto de saturação interms da proporção de contagens cumulativas:
sns.histplot( planets, x="year", y="distance", bins=30, discrete=(True, False), log_scale=(False, True), pthresh=.05, pmax=.9,)
Para anotar o colormap, adicione um colorbar:
sns.histplot( planets, x="year", y="distance", bins=30, discrete=(True, False), log_scale=(False, True), cbar=True, cbar_kws=dict(shrink=.75),)