Um pap smear ferramenta de análise (PAT) para a detecção de câncer de colo de útero a partir do pap smear imagens
de análise de Imagem
A análise de imagens de pipeline para o desenvolvimento de um pap smear ferramenta de análise para a detecção de câncer de colo do pap-manchas apresentadas neste documento está apresentada na Fig. 1.

A abordagem para obtenção de câncer de colo de detecção de pap smear imagens
aquisição de Imagem
A abordagem foi avaliada através de três conjuntos de dados. O conjunto de dados 1 consiste em 917 células individuais de imagens de cravo de Harlev preparadas por Jantzen et al. . O conjunto de dados contém imagens de pap-esfregaço tiradas com uma resolução de 0,201 µm / pixel por citopatologistas habilidosos usando um microscópio ligado a um grabber de moldura. As imagens foram segmentadas usando software comercial CHAMP e, em seguida, classificadas em sete classes com características distintas, como mostrado na Tabela 2. Destas 200 imagens foram usadas para treinamento e 717 para testes.
conjunto de dados 2 consiste de 497 slide completo pap smear imagens preparadas pela Norup et al. . Destas 200 imagens foram usadas para treinamento e 297 para testes. Além disso, o desempenho do Classificador foi avaliado no conjunto de dados 3 de amostras de 60 esfregaços de pap (30 normais e 30 anormais) obtidas do Mbarara Regional Referral Hospital (MRRH). As amostras foram fotografadas usando um microscópio de campo brilhante Olympus BX51 equipado com uma lente de 40×, 0.95 NA e uma câmera monocromática Hamamatsu ORCA-05G 1.4 Mpx, dando um tamanho de pixels de 0,25 µm com profundidade cinzenta de 8 bits. Cada imagem foi então dividida em 300 áreas com cada área contendo entre 200 e 400 células. Com base nas opiniões dos cytopathologists, 10.000 objetos em imagens derivadas de 60 diferentes pap-esfregaços foram selecionados, dos quais 8000 eram livres deitado cervical células epiteliais (3000 células normais do normal sujeiras e 5000 anormal de células anormais em esfregaços) e o restante 2000 foram detritos objetos. Esta segmentação pap-smear foi conseguida usando toolkit de segmentação Weka treinável para construir um classifier de segmentação de nível pixel.
melhoria de imagem
uma equalização do histograma adaptativo local de contraste (CLAHE) foi aplicada à imagem em tons de cinzento para a melhoria de imagem . Em CLAHE, a seleção de clip-limit que especifica a forma desejada do histograma da imagem é fundamental, já que influencia criticamente a qualidade da imagem melhorada. O valor ideal do clip-limit foi selecionado empiricamente usando o método definido por Joseph et al. . Um valor máximo de clip de 2.0 foi determinado como adequado para proporcionar uma melhoria adequada da imagem, preservando as características escuras para os conjuntos de dados utilizados. A conversão para tons de cinza foi conseguida usando uma técnica de tons de cinza implementada usando Eq. 1 tal como definido em .
, onde R = Vermelho, G = Verde, B = Azul cor contribuições para a nova imagem.
A aplicação de CLAHE para a melhoria da imagem resultou em mudanças notáveis nas imagens, ajustando intensidades de imagem onde o escurecimento do núcleo, bem como os limites do citoplasma, tornou-se facilmente identificável usando um limite de clip de 2.0.
segmentação de cena
para atingir segmentação de cena, um classificador de nível de pixels foi desenvolvido usando segmentação treinável Weka (TWS) toolkit. A maioria das células observadas num esfregaço papal não são surpreendentemente células epiteliais cervicais . Além disso, vários números de leucócitos, eritrócitos e bactérias são geralmente evidentes, enquanto pequenos números de outras células contaminantes e microorganismos são por vezes observados. No entanto, o pap-smear contém quatro tipos principais de células escamosas do colo do útero—superficiais, intermédias, parabasais e basais—das quais as células superficiais e intermédias representam a esmagadora maioria num esfregaço convencional; daí que estes dois tipos são geralmente utilizados para uma análise pap-smear convencional . Uma segmentação treinável do Weka foi usada para identificar e segmentar os diferentes objetos no slide. Nesta fase, um classificador de nível pixel foi treinado em núcleos celulares, citoplasma, identificação de fundo e escombros com a ajuda de um citopatologista qualificado usando segmentação treinável Weka (TWS) toolkit . Isto foi conseguido desenhando linhas / seleção através das áreas de interesse e atribuindo-as a uma classe particular. Os pixels sob as linhas/seleção foram levados para ser o representante dos núcleos, citoplasma, fundo e detritos.
os contornos desenhados dentro de cada classe foram usados para gerar um vector de funcionalidades, \(\mathop F \ limits^{ \to }\) que foi derivado do número de pixels pertencentes a cada contorno. O vector de característica de cada imagem (200 do Dataset 1 e 200 do Dataset 2) foi definido pelo Eq. 2.
onde Ni, Ci, Bi e Di são o número de pixels do núcleo, citoplasma, fundo e escombros da imagem \(i\), como mostrado na Fig. 2.

a Geração do vetor característico da formação de imagens
Cada pixel extraídos da imagem representa não apenas a sua intensidade, mas também um conjunto de recursos de imagens que contêm uma grande quantidade de informações, incluindo textura, bordas e cores dentro de uma área de pixel de 0.201 µm2. Escolher um vetor de recursos apropriado para treinar o classificador foi um grande desafio e uma tarefa nova na abordagem proposta. O classifier de nível pixel foi treinado usando um total de 226 características de treinamento de TWS. O classificador foi treinado usando um conjunto de recursos de treinamento TWS que incluiu: (I) redução de Ruído: os filtros Kuwahara e bilaterais no toolkit TWS foram usados para treinar o classificador em remoção de ruído. Estes têm sido relatados como excelentes filtros para remover o ruído, preservando as bordas, (ii) detecção de bordas: um filtro Sobel, matriz hessiana e filtro Gabor foram usados para treinar o classificador na detecção de limites em uma imagem, e (iii) filtragem de texturas: Os filtros de média, variância, mediana, máximo, mínimo e entropia foram usados para filtragem de textura.
remoção de detritos
a principal razão para as limitações atuais de muitos dos sistemas automatizados de análise pap-smear existentes é que eles lutam para superar a complexidade das estruturas pap-smear, tentando analisar o slide como um todo, que muitas vezes contêm múltiplas células e detritos. Isto tem o potencial de causar a falha do algoritmo e requer maior poder computacional . As amostras estão cobertas de artefatos—como células sanguíneas, células sobrepostas e dobradas, e bactérias—que dificultam os processos de segmentação e geram um grande número de objetos suspeitos. Tem sido demonstrado que classificadores projetados para diferenciar entre células normais e células pré-cancerosas geralmente produzem resultados imprevisíveis quando artefatos existem no pap-smear . Nesta ferramenta, uma técnica para identificar as células do colo do útero usando um esquema de eliminação sequencial de três fases (representado na Fig. 3) é utilizado.

Três fases sequenciais eliminação abordagem para detritos rejeição
A proposta de três-fase esquema de eliminação sequencialmente remove os detritos da pap smear se considera pouco provável que seja um colo célula. Esta abordagem é benéfica, pois permite que uma decisão de dimensão inferior seja tomada em cada fase.
Análise de tamanho
análise de tamanho é um conjunto de procedimentos para determinar uma gama de medições de tamanho de partículas . A área é uma das características mais básicas usadas no campo da citologia automatizada para separar as células dos detritos. A análise pap-smear é um campo bem estudado com muito conhecimento prévio sobre propriedades celulares . No entanto, uma das principais mudanças com a avaliação da área do núcleo é que as células cancerosas sofrem um aumento substancial no tamanho nuclear . Portanto, determinar um limiar de tamanho superior que Não exclua sistematicamente as células diagnósticas é muito mais difícil, mas tem a vantagem de reduzir o espaço de busca. O método apresentado neste artigo baseia-se num tamanho inferior e no limiar superior das células cervicais. O pseudo-código para a abordagem é mostrado em Eq. 3.
onde \(Area_{max} = 85,267\,{\upmu \text{m}}^{2}\) e \(Area_{min} = 625\,{\upmu \text{m}}^{2}\) derivada da Tabela 2.
os objetos no fundo são considerados detritos e, portanto, descartados da imagem. As partículas que se situam entre \(Area_{min}\) e \(Area_{max}\) são analisadas mais aprofundadamente durante as fases seguintes da análise da textura e da forma.
análise da forma
a forma dos objetos em um pap-smear é uma característica fundamental na diferenciação entre células e detritos . Há uma série de métodos para a detecção da descrição da forma e estes incluem abordagens baseadas na região e no contorno . Os métodos baseados nas regiões são menos sensíveis ao ruído, mas mais intensivos em termos computacionais, enquanto os métodos baseados no contorno são relativamente eficientes para calcular, mas mais sensíveis ao ruído . Neste artigo foi utilizado um método baseado na região (perimeter2 / area (P2A)). O descritor P2A foi escolhido pelo mérito de descrever a similaridade de um objeto com um círculo. Isso o torna bem adequado como um descritor do núcleo celular, uma vez que os núcleos são geralmente circulares em sua aparência. O P2A também é referido como compacidade de forma e é definido por Eq. 4.
, onde c é o valor da forma de compacidade, a é a área e p é o perímetro do núcleo. Considera-se que os detritos são objectos com um valor P2A superior a 0,97 ou inferior a 0,15 de acordo com as características de treino (apresentadas na Tabela 2).
A análise da textura
textura é uma característica muito importante que pode diferenciar entre núcleos e detritos. A textura da imagem é um conjunto de métricas projetadas para quantificar a textura percebida de uma imagem . Dentro de um pap-smear, a distribuição da intensidade média de mancha nuclear é muito mais estreita do que a variação da intensidade de mancha entre os objetos de detritos . Este fato foi usado como base para remover detritos com base em suas intensidades de imagem e informações de cor usando momentos Zernike (ZM) . Zernike moments are used for a variety of pattern recognition applications and are known to be robust with regards to noise and to have a good reconstruction power. Neste trabalho, o ZM como apresentado por Malm et al. de ordem n Com repetição I da função \(f\esquerda ({r,\theta } \direita)\), em coordenadas polares dentro de um disco centrado na imagem quadrada \(I\esquerda ({x,y} \direita)\) do tamanho \(m \vezes m\) dado por Eq. 5 foi utilizado.
\(v_{nl }^{*} \left( {r,\theta } \right)\) denota o conjugado complexo do polinômio de Zernike \(v_{nl} \left( {r,\theta } \right)\). Para produzir uma medida de textura, as magnitudes de \(a_{nl}\) centradas em cada pixel da imagem de textura são médias .
extracção de recursos
o sucesso de um algoritmo de classificação depende muito da correcção das características extraídas da imagem. As células do pap-smears no conjunto de dados utilizado são divididas em sete classes com base em características tais como tamanho, Área, forma e brilho do núcleo e citoplasma. As características extraídas das imagens incluíam características morfológicas anteriormente utilizadas por outros . Neste trabalho três características geométricas (solidez, compacidade e excentricidade) e seis textuais características (média, desvio padrão, variância, suavidade, energia e entropia) também foram extraídos a partir do núcleo, resultando em 29 de recursos no total, como mostrado na Tabela 3.
Feature selection is the process of selecting subcets of the extracted features that give the best classification results. Entre essas características extraídas, alguns podem conter ruído, enquanto o classificador escolhido não pode utilizar outros. Assim, um conjunto ideal de recursos tem que ser determinado, possivelmente tentando todas as combinações. No entanto, quando existem muitas características, as combinações possíveis explodem em número e isso aumenta a complexidade computacional do algoritmo. Algoritmos de seleção de recursos são amplamente classificados nos métodos filtro, invólucro e embutido .
O método utilizado pela ferramenta combina recozimento simulado com uma abordagem Wrap. Esta abordagem foi proposta mas, neste artigo, o desempenho da seleção de recursos é avaliado usando um algoritmo de floresta aleatória de dupla estratégia . Recozimento simulado é uma técnica probabilística para aproximar o ideal global de uma dada função. A abordagem é adequada para garantir que o conjunto ideal de recursos é selecionado. A busca pelo conjunto ideal é guiada por um valor de aptidão. Quando o recozimento simulado é terminado, todos os diferentes subconjuntos de recursos são comparados e o mais apto (ou seja, aquele que executa o melhor) selecionado. A pesquisa do valor de fitness foi obtida com um wrapper onde k-fold cross-validation foi usado para calcular o erro no algoritmo de classificação. Diferentes combinações das características extraídas são preparadas, avaliadas e comparadas com outras combinações. Um modelo preditivo é então usado para avaliar uma combinação de recursos e atribuir uma pontuação baseada na precisão do modelo. The fitness error given by the wrapper is used as the fitness error by the simulated annealing algorithm. Um algoritmo fuzzy C-means foi envolvido em uma caixa preta, a partir da qual um erro estimado foi obtido para as várias combinações de recursos como mostrado na Fig. 4.

O fuzzy C-means é envolto em uma caixa preta do que uma estimativa de erro é obtido
Fuzzy C-significa permite que pontos de dados no conjunto de dados para pertencem a todos os clusters, com associações no intervalo (0-1), como mostrado na Eq. 6.
onde \(m_{ik}\) é a associação para o ponto de dados k ao cluster center i, \(d_{jk}\) é a distância do centro cluster j a ponto de dados k e q € é um expoente que decide o quão forte as associações devem ser. O algoritmo fuzzy C-means foi implementado usando a caixa de ferramentas fuzzy no Matlab.
a desfuzificação
um algoritmo difuso de C-means não nos diz que informação os aglomerados contêm e como essa informação deve ser usada para a classificação. No entanto, ele define como os pontos de dados são atribuídos membros dos diferentes clusters e esta adesão difusa é usada para prever a classe de um ponto de dados . Isto é superado através da defuzificação. Existem vários métodos de defuzificação . No entanto, nesta ferramenta, cada conjunto tem uma associação difusa (0-1) de todas as classes na imagem. Os dados de treino são atribuídos ao grupo mais próximo. A porcentagem de dados de treinamento de cada classe pertencente ao cluster a dá os membros do cluster, cluster A = para as diferentes classes, onde i é a contenção no cluster A E j no outro cluster. A medida de intensidade é adicionada à função de membro para cada cluster usando um algoritmo de defuzificação de clusterização difusa. Uma abordagem popular para a defuzificação da partição fuzzy é a aplicação do princípio do grau máximo de adesão, onde o ponto de dados k é atribuído à classe m se, e somente se, o seu grau de adesão \(m_{ik}\) ao cluster i, é o maior. Chuang et al. propôs ajustar o status de membro de cada ponto de dados usando o status de membro de seus vizinhos.
na abordagem proposta, um método de defuzificação baseado na probabilidade Bayesiana é usado para gerar um modelo probabilístico da função de adesão para cada ponto de dados e aplicar o modelo à imagem para produzir a informação de classificação. O modelo probabilístico é calculado como abaixo:
-
converta as distribuições de possibilidades na matriz de partição (clusters) em distribuições de probabilidade.
-
construir um modelo probabilístico das distribuições de dados como em .
-
aplicar o modelo para produzir a informação de classificação para cada ponto de dados usando Eq. 7.
onde \(P\left( {A_{i} } \right),i = 0 \ldots .c\) é a probabilidade anterior de \(a_{i}\) que pode ser calculada usando o método em que a probabilidade anterior é sempre proporcional à massa de cada classe.
O número de clusters a usar foi determinado para garantir que o modelo construído pode descrever os dados da melhor maneira possível. Se forem escolhidos demasiados aglomerados, existe o risco de sobrepor o ruído nos dados. Se poucos clusters são escolhidos, então um classificador pobre pode ser o resultado. Por conseguinte, foi realizada uma análise do número de agregados em relação ao erro do teste de validação cruzada. Um número ideal de 25 clusters foi atingido e a overtraining ocorreu acima deste número de clusters. Um expoente de defuzificação de 1.O 0930 foi obtido com 25 clusters, dez vezes mais validação cruzada e 60 reprises e foi usado para calcular o erro de aptidão para a seleção de recursos, onde um total de 18 das 29 características foram selecionadas para a construção do Classificador. Os recursos selecionados foram: núcleo de área; núcleo de níveis de cinza; núcleo de menor diâmetro; núcleo mais longa; núcleo de perímetro; maxima no núcleo; mínimos no núcleo, citoplasma área; citoplasma nível de cinza; citoplasma perímetro; núcleo para o citoplasma relação; núcleo de excentricidade, núcleo desvio padrão, núcleo de níveis de cinza de variância; núcleo cinzento nível de entropia; posição relativa do núcleo; média do nível cinza do núcleo e valores de cinza do núcleo energia.
avaliação da Classificação
neste trabalho, o modelo hierárquico da eficácia dos sistemas de imagem para diagnósticos propostos pelo Fryback e Thornbury foi adotada como um princípio orientador para a avaliação da ferramenta, conforme mostrado na Tabela 4.
a Sensibilidade mede a proporção de reais positivos que são identificados corretamente, como tal, considerando a especificidade mede a proporção de reais negativos, que são corretamente identificados como tal. A sensibilidade e a especificidade são descritas pelo NQA. 8.
onde TP = Verdadeiros positivos, FN = Falsos negativos, TN = Verdadeiros negativos e FP = Falsos positivos.
design e integração GUI
os métodos de processamento de imagem descritos acima foram implementados em Matlab e são executados através de uma interface gráfica de utilizador (GUI) Java mostrada na Fig. 5. A ferramenta tem um painel onde uma imagem pap-smear é carregada e o citotécnico seleciona um método apropriado para segmentação de cena (com base no classificador TWS), remoção de detritos (com base na abordagem de eliminação sequencial) e detecção de limites (se considerado necessário, usando o método de detecção de borda Cany), após o que as características são extraídas usando o botão de recursos de extrato.
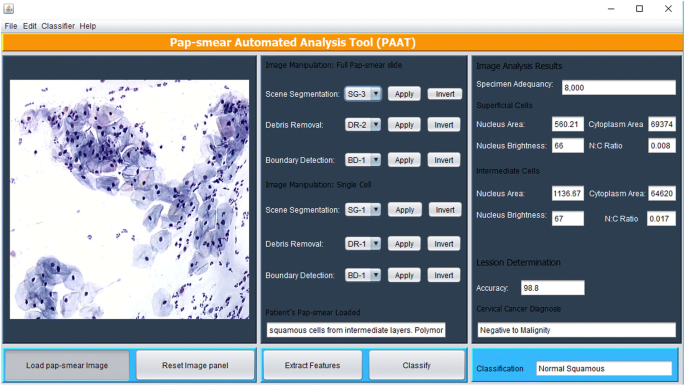
PAT interface gráfica do usuário
A ferramenta verifica através do pap smear para analisar todos os objetos que permaneceram após a remoção de entulho. As 18 características descritas na seleção de recursos são extraídas de cada objeto e usadas para classificar cada célula usando o algoritmo fuzzy C-means descrito no método de classificação. Aleatoriamente, as características extraídas de uma célula superficial e de uma célula intermediária são exibidas no painel de resultados da análise de imagens. Uma vez que as características foram extraídas, o citotécnico (usuário) pressiona o botão classificar e a ferramenta emite um diagnóstico (positivo para a malignidade ou negativo para a malignidade) e classifica o diagnóstico para uma das 7 classes/estágios de câncer cervical como de acordo com o conjunto de dados de treinamento.