Rilevamento di oggetti per manichini Parte 3: Famiglia R-CNN
Nella Parte 3, esamineremo quattro modelli di rilevamento di oggetti: R-CNN, Fast R-CNN, Faster R-CNN e Mask R-CNN. Questi modelli sono altamente correlati e le nuove versioni mostrano un grande miglioramento della velocità rispetto a quelli più vecchi.
Nella serie di “Object Detection for Dummies”, abbiamo iniziato con concetti di base nell’elaborazione delle immagini, come i vettori di gradiente e HOG, nella Parte 1. Poi abbiamo introdotto classici progetti di architettura di rete neurale convoluzionale per la classificazione e modelli pionieristici per il riconoscimento di oggetti, Overfeat e DPM, nella parte 2. Nel terzo post di questa serie, stiamo per rivedere una serie di modelli della famiglia R-CNN (“CNN regionale”).
Link a tutti i post della serie: .
Ecco un elenco di articoli trattati in questo post 😉
| Model | Goal | Resources |
| R-CNN | Object recognition | |
| Fast R-CNN | Object recognition | |
| Faster R-CNN | Object recognition | |
| Mask R-CNN | Image segmentation |
- R-CNN
- Flusso di lavoro del modello
- Regressione Bounding Box
- Trucchi comuni
- Velocità collo di bottiglia
- Fast R-CNN
- Roi Pooling
- Flusso di lavoro del modello
- la Perdita di Funzione
- Collo di bottiglia di velocità
- Più veloce R-CNN
- Flusso di lavoro del modello
- Funzione di perdita
- Maschera R-CNN
- RoIAlign
- la Perdita di Funzione
- Riepilogo dei modelli della famiglia R-CNN
- Riferimento
R-CNN
R-CNN (Girshick et al., 2014) is short for “Region-based Convolutional Neural Networks”. The main idea is composed of two steps. Innanzitutto, utilizzando la ricerca selettiva, identifica un numero gestibile di candidati della regione oggetto bounding-box (“regione di interesse “o”RoI”). E poi estrae le funzionalità CNN da ogni regione in modo indipendente per la classificazione.
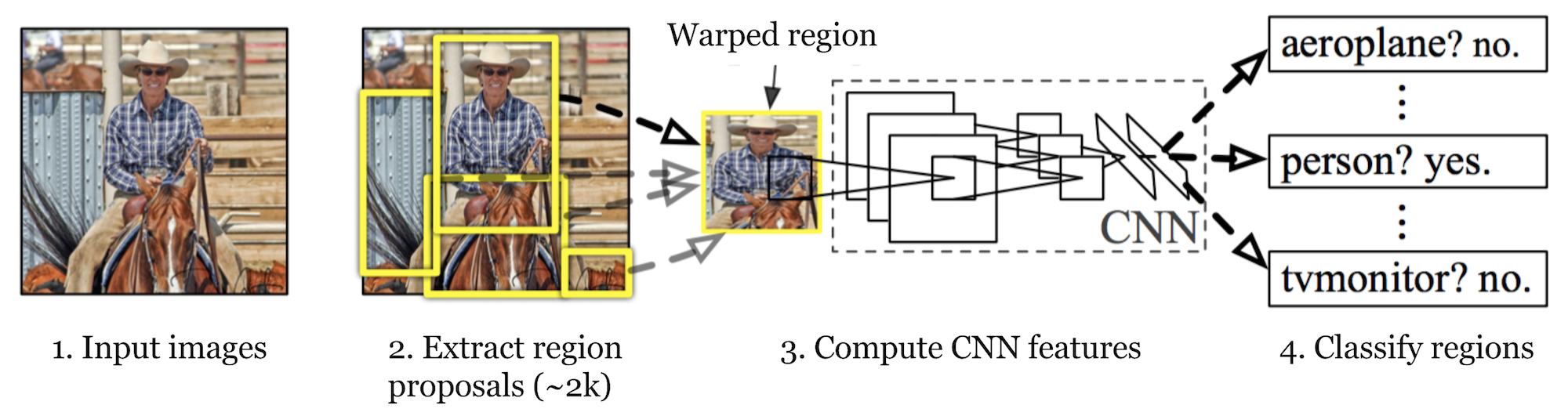
Fig. 1. L’architettura di R-CNN. (Fonte immagine: Girshick et al., 2014)
Flusso di lavoro del modello
Come funziona R-CNN può essere riassunto come segue:
- Pre-addestrare una rete CNN sulle attività di classificazione delle immagini; ad esempio, VGG o ResNet addestrati sul set di dati ImageNet. L’attività di classificazione coinvolge N classi.
NOTA: puoi trovare un AlexNet pre-addestrato in Caffe Model Zoo. Non penso che tu possa trovarlo in Tensorflow, ma Tensorflow-slim model library fornisce ResNet, VGG e altri pre-addestrati.
- Proporre regioni di interesse indipendenti dalla categoria mediante ricerca selettiva (~2k candidati per immagine). Queste regioni possono contenere oggetti di destinazione e sono di dimensioni diverse.
- I candidati della regione sono deformati per avere una dimensione fissa come richiesto dalla CNN.
- Continua a mettere a punto la CNN sulle regioni delle proposte deformate per le classi K + 1; La classe aggiuntiva si riferisce allo sfondo (nessun oggetto di interesse). Nella fase di fine-tuning, dovremmo usare un tasso di apprendimento molto più piccolo e il mini-batch sovracampiona i casi positivi perché la maggior parte delle regioni proposte sono solo background.
- Data ogni regione dell’immagine, una propagazione in avanti attraverso la CNN genera un vettore di funzionalità. Questo vettore di funzionalità viene quindi utilizzato da un SVM binario addestrato per ogni classe in modo indipendente.
I campioni positivi sono regioni proposte con soglia di sovrapposizione IoU (intersection over union) > = 0.3, e campioni negativi sono irrilevanti altri. - Per ridurre gli errori di localizzazione, viene addestrato un modello di regressione per correggere la finestra di rilevamento prevista sull’offset di correzione del riquadro di delimitazione utilizzando le funzionalità CNN.
Regressione Bounding Box
Data una coordinata bounding box prevista \(\mathbf{p} = (p_x, p_y, p_w, p_h)\) (coordinata centrale, larghezza, altezza) e le corrispondenti coordinate ground truth box \(\mathbf{g} = (g_x, g_y, g_w, g_h)\) , il regressore è configurato per imparare la trasformazione scala-invariante tra due centri e la trasformazione log-scala tra larghezze e altezze. Tutte le funzioni di trasformazione prendono \(\mathbf{p}\) come input.
\
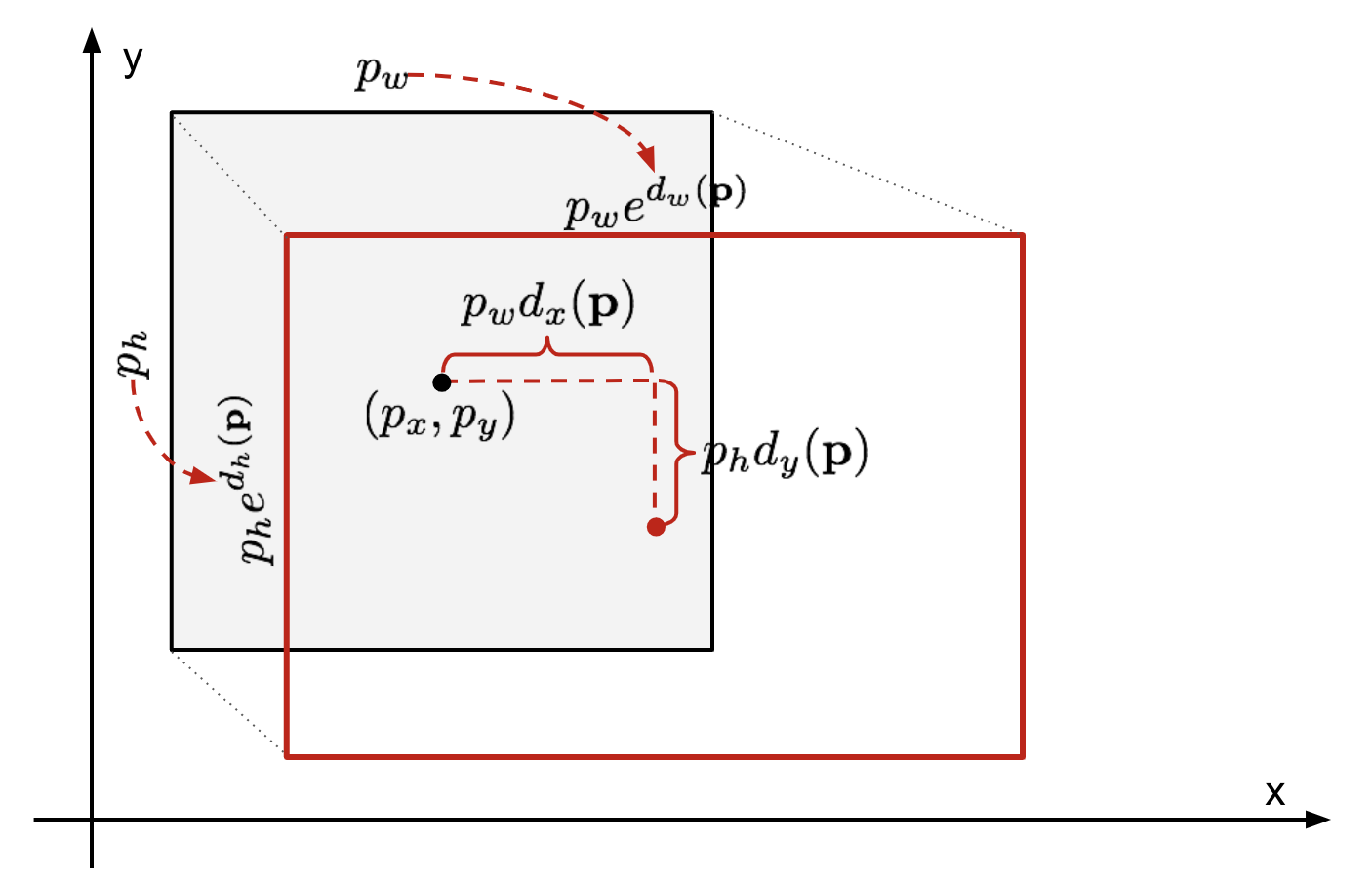
Fig. 2. Illustrazione di trasformazione tra predetto e terra verità bounding box.
Un ovvio vantaggio dell’applicazione di tale trasformazione è che tutte le funzioni di correzione del riquadro di delimitazione, \(d_i(\mathbf{p})\) dove \(i \in \{ x, y, w, h \}\), possono assumere qualsiasi valore tra . Gli obiettivi per loro da imparare sono:
\
Un modello di regressione standard può risolvere il problema riducendo al minimo la perdita SSE con regolarizzazione:
\
Il termine di regolarizzazione è fondamentale qui e RCNN paper ha scelto il miglior λ per validazione incrociata. È anche interessante notare che non tutte le caselle di delimitazione previste hanno corrispondenti caselle di verità di terra. Ad esempio, se non vi è alcuna sovrapposizione, non ha senso eseguire la regressione bbox. Qui, solo una scatola prevista con una scatola di verità di terra vicina con almeno 0.6 IoU viene conservata per addestrare il modello di regressione bbox.
Trucchi comuni
Diversi trucchi sono comunemente usati in RCNN e altri modelli di rilevamento.
Soppressione non massima
Probabilmente il modello è in grado di trovare più caselle di delimitazione per lo stesso oggetto. La soppressione non massima consente di evitare il rilevamento ripetuto della stessa istanza. Dopo aver ottenuto una serie di caselle di delimitazione abbinate per la stessa categoria di oggetti: Ordina tutte le caselle di delimitazione in base al punteggio di confidenza.Scartare scatole con punteggi di fiducia bassi.Mentre c’è un riquadro di delimitazione rimanente, ripeti quanto segue:Seleziona avidamente quello con il punteggio più alto.Salta le caselle rimanenti con IoU alto (cioè > 0.5) con una selezionata in precedenza.

Fig. 3. Più caselle di delimitazione rilevano l’auto nell’immagine. Dopo la soppressione non massima, rimane solo il migliore e il resto viene ignorato in quanto hanno grandi sovrapposizioni con quello selezionato. (Fonte immagine: DPM paper)
Hard Negative Mining
Consideriamo i riquadri di delimitazione senza oggetti come esempi negativi. Non tutti gli esempi negativi sono ugualmente difficili da identificare. Ad esempio, se contiene puro sfondo vuoto, è probabile un “negativo facile”; ma se la casella contiene una strana texture rumorosa o un oggetto parziale, potrebbe essere difficile da riconoscere e questi sono “negativi duri”.
Gli esempi negativi rigidi sono facilmente classificati erroneamente. Possiamo trovare esplicitamente quei campioni falsi positivi durante i cicli di allenamento e includerli nei dati di allenamento in modo da migliorare il classificatore.
Velocità collo di bottiglia
Guardare attraverso il R-CNN apprendimento passaggi, si può facilmente scoprire che la formazione di un R-CNN modello è costoso e lento, come le seguenti operazioni comportano un sacco di lavoro:
- Esecuzione selettiva di ricerca per proporre 2000 regione candidati per ogni immagine;
- Generare la CNN funzione vettoriale per ogni immagine, la regione (N immagini * 2000).
- L’intero processo coinvolge tre modelli separatamente senza calcoli molto condivisi: la rete neurale convoluzionale per la classificazione delle immagini e l’estrazione delle funzionalità; il classificatore SVM superiore per identificare gli oggetti target; e il modello di regressione per il serraggio delle caselle di delimitazione della regione.
Fast R-CNN
Per rendere R-CNN più veloce, Girshick (2015) ha migliorato la procedura di allenamento unificando tre modelli indipendenti in un unico framework addestrato congiuntamente e aumentando i risultati di calcolo condivisi, denominati Fast R-CNN. Invece di estrarre i vettori di funzionalità CNN in modo indipendente per ogni proposta di regione, questo modello li aggrega in un unico passaggio avanti CNN sull’intera immagine e le proposte di regione condividono questa matrice di funzionalità. Quindi la stessa matrice di funzionalità viene ramificata per essere utilizzata per l’apprendimento del classificatore di oggetti e del regressore della casella di delimitazione. In conclusione, la condivisione di calcolo accelera R-CNN.
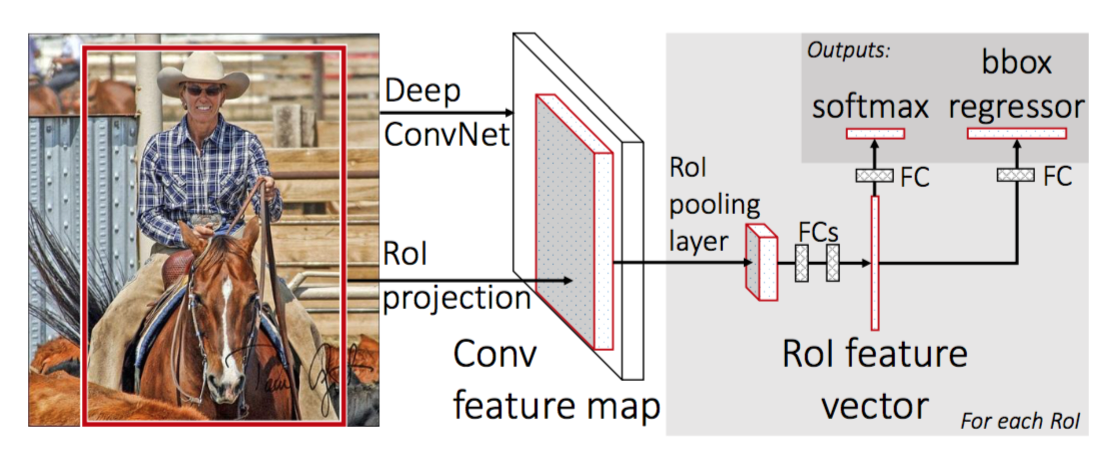
Fig. 4. L’architettura di Fast R-CNN. (Fonte immagine: Girshick, 2015)
Roi Pooling
È un tipo di pool massimo per convertire le funzionalità nella regione proiettata dell’immagine di qualsiasi dimensione, h x w, in una piccola finestra fissa, H x W. La regione di input è divisa in griglie H x W, approssimativamente ogni sottofinestra di dimensioni h/H x w/W. Quindi applica il pool massimo in ogni griglia.
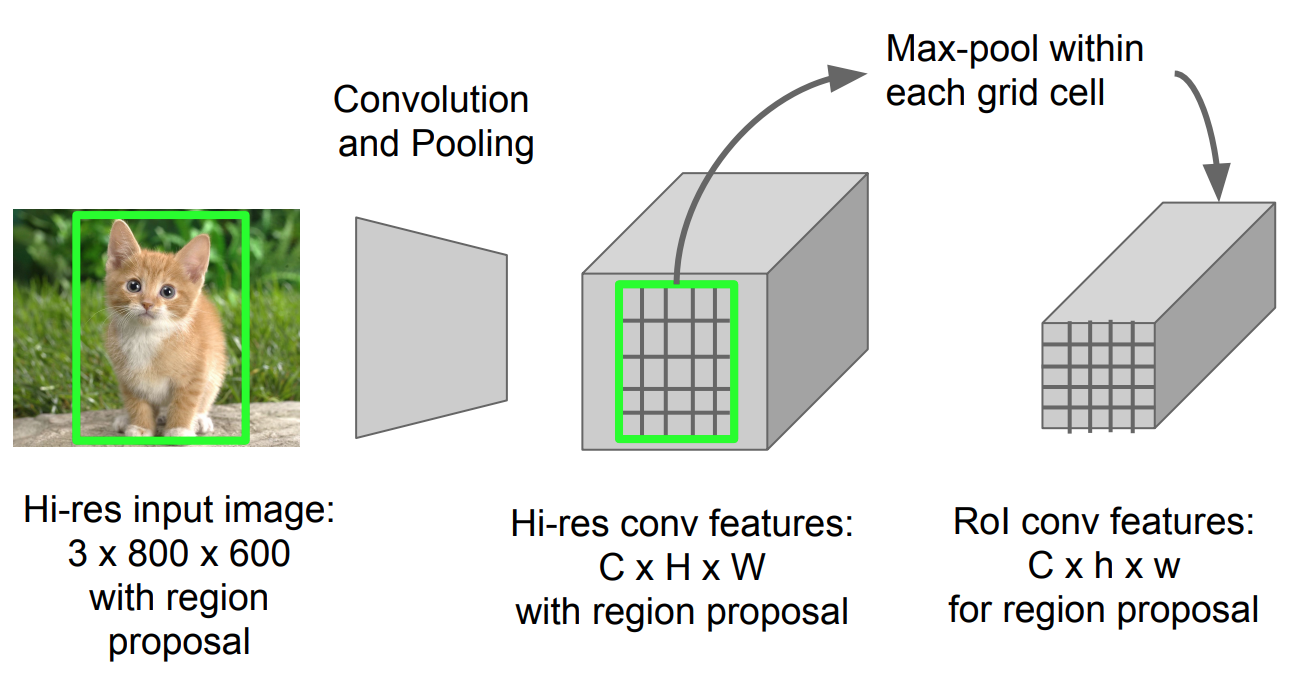
Fig. 5. RoI pooling (Fonte immagine: Stanford CS231n slides.)
Flusso di lavoro del modello
Quanto velocemente funziona R-CNN è riassunto come segue; molti passaggi sono gli stessi di R-CNN:
- In primo luogo, pre-treno una rete neurale convoluzionale sulle attività di classificazione delle immagini.
- Proporre regioni di ricerca selettiva (~2k candidati per immagine).
- Modificare la CNN pre-addestrata:
- Sostituire l’ultimo livello di pooling massimo della CNN pre-addestrata con uno strato di pooling del RoI. Il livello di pooling del RoI produce vettori di funzionalità a lunghezza fissa di proposte regionali. Condividere il calcolo della CNN ha molto senso, poiché molte proposte regionali delle stesse immagini sono altamente sovrapposte.
- Sostituire l’ultimo livello completamente collegato e l’ultimo livello softmax (classi K) con un livello completamente collegato e softmax su classi K + 1.
- Infine il modello si dirama in due livelli di output:
- Uno stimatore softmax di classi K + 1 (come in R-CNN, +1 è la classe “background”), che emette una distribuzione di probabilità discreta per RoI.
- Un modello di regressione bounding-box che prevede offset rispetto al RoI originale per ciascuna delle classi K.
la Perdita di Funzione
Il modello è ottimizzato per una perdita di combinazione di due attività (classificazione + localizzazione):
| Simbolo | Descrizione |
| \(u\) | True etichetta di classe, \(u \in 0, 1, \dots, K\); per convenzione, il catch-all background di classe ha \(u = 0\). |
| \(p\) | Distribuzione di probabilità discreta (per RoI) su classi K + 1: \(p = (p_0, \dots, p_K)\), calcolata da un softmax sulle uscite K + 1 di un livello completamente connesso. |
| \(v\) | Vero riquadro di delimitazione \(v = (v_x, v_y, v_w, v_h)\). |
| \(t^u\) | Correzione del riquadro di delimitazione prevista, \(t^u = (t^u_x, t^u_y, t^u_w, t^u_h)\). Vedi sopra. |
La funzione di perdita riassume il costo della classificazione e della previsione del riquadro di delimitazione: \(\mathcal{L} = \mathcal{L}_\text{cls} + \mathcal{L}_\text{box}\). Per il RoI” background”, \(\mathcal{L} _ \ text{box}\) viene ignorato dalla funzione indicatore \(\mathbb{1}\), definita come:
\ = \begin{casi} 1 & \text{se } u \geq 1\\ 0 & \text{altrimenti}\end{casi}\]
La perdita di funzione è:
\ \mathcal{L}_\text{casella}(t^u, v) \\\mathcal{L}_\text{cls}(p, u) &= -\log p_u \\\mathcal{L}_\text{casella}(t^u, v) &= \sum_{i \in \{x, y, w, h\}} L_1^\text{liscia} (t^u_i – v_i)\end{align*}\]
Il riquadro di delimitazione di perdita di \(\mathcal{L}_{casella}\) dovrebbe misurare la differenza tra \(t^u_i\) e \(v_i\) utilizzando un robusto perdita di funzione. La perdita L1 liscia è adottata qui e si afferma di essere meno sensibile ai valori anomali.
\
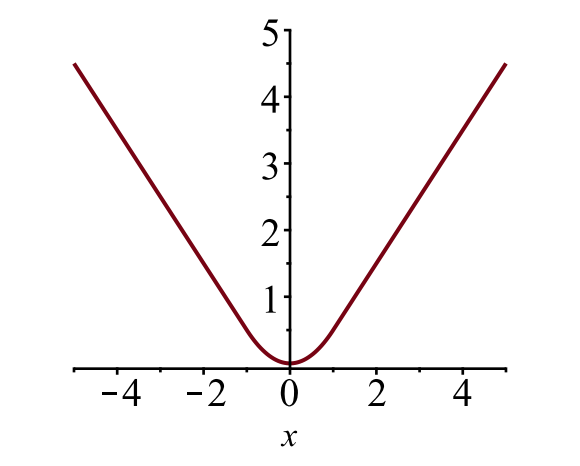
Fig. 6. La trama della perdita L1 liscia, \(y = L_1^ \ text {smooth} (x)\). (Fonte immagine: link)
Collo di bottiglia di velocità
Veloce R-CNN è molto più veloce sia in allenamento che in tempo di test. Tuttavia, il miglioramento non è drammatico perché le proposte regionali sono generate separatamente da un altro modello e questo è molto costoso.
Più veloce R-CNN
Una soluzione intuitiva speedup è quello di integrare l’algoritmo proposta regione nel modello CNN. Più veloce R-CNN (Ren et al., 2016) sta facendo esattamente questo: costruire un singolo modello unificato composto da RPN (region proposal network) e veloce R-CNN con livelli di funzionalità convoluzionali condivisi.

Fig. 7. Un’illustrazione del modello R-CNN più veloce. (Fonte immagine: Ren et al., 2016)
Flusso di lavoro del modello
- Pre-addestrare una rete CNN sulle attività di classificazione delle immagini.
- Ottimizzare l’RPN (region proposal network) end-to-end per l’attività proposta regione, che viene inizializzata dal classificatore di immagini pre-treno. I campioni positivi hanno IoU (intersection-over-union)> 0.7, mentre i campioni negativi hanno IoU< 0.3.
- Far scorrere una piccola finestra spaziale n x n sulla mappa delle funzioni conv dell’intera immagine.
- Al centro di ogni finestra scorrevole, prevediamo più regioni di varie scale e rapporti contemporaneamente. Un’ancora è una combinazione di (centro finestra scorrevole, scala, rapporto). Ad esempio, 3 scale + 3 rapporti => k=9 ancore in ogni posizione di scorrimento.
- Addestrare un modello di rilevamento di oggetti veloce R-CNN utilizzando le proposte generate dalla corrente RPN
- Quindi utilizzare la rete veloce R-CNN per inizializzare formazione RPN. Pur mantenendo i livelli convoluzionali condivisi, solo mettere a punto i livelli specifici RPN. In questa fase, RPN e la rete di rilevamento hanno condiviso i livelli convoluzionali!
- Infine mettere a punto gli strati unici di veloce R-CNN
- Passo 4-5 può essere ripetuto per addestrare RPN e veloce R-CNN in alternativa, se necessario.
Funzione di perdita
Più veloce R-CNN è ottimizzato per una funzione di perdita multi-task, simile a veloce R-CNN.
| Simbolo | Spiegazione |
| \(p_i\) | Probabilità prevista che anchor i sia un oggetto. |
| \(p^*_i\) | Ground truth label (binary) del fatto che anchor i sia un oggetto. |
| \(t_i\) | Ha predetto quattro coordinate parametrizzate. |
| \(t^*_i\) | Coordinate di verità di terra. |
| \(N_\text{cls}\) | Termine di normalizzazione, impostato come dimensione mini-batch (~256) nel documento. |
| \(N_\text{box}\) | Termine di normalizzazione, impostato sul numero di posizioni di ancoraggio (~2400) nel documento. |
| \(\lambda\) | Un parametro di bilanciamento, impostato per essere ~10 nel documento (in modo che entrambi i termini \(\mathcal{L}_\text{cls}\) e \(\mathcal{L}_\text{box}\) siano approssimativamente ugualmente ponderati). |
Il multi-task perdita di funzione combina le perdite di classificazione e di delimitazione e di regressione:
\
dove \(\mathcal{L}_\text{cls}\) è il registro di perdita di funzione di due classi, come si può facilmente tradurre multi-classificazione di classe in una classificazione binaria attraverso la previsione di un campione di un oggetto di destinazione rispetto a non. \(L_1^\text {smooth}\) è la perdita L1 liscia.
\
Maschera R-CNN
Maschera R-CNN (He et al., 2017) estende più velocemente R-CNN alla segmentazione dell’immagine a livello di pixel. Il punto chiave è quello di disaccoppiare la classificazione e le attività di previsione maschera a livello di pixel. Basato sul framework di Faster R-CNN, ha aggiunto un terzo ramo per prevedere una maschera di oggetto in parallelo con i rami esistenti per la classificazione e la localizzazione. Il ramo mask è una piccola rete completamente connessa applicata a ciascun RoI, che prevede una maschera di segmentazione in modo pixel-to-pixel.
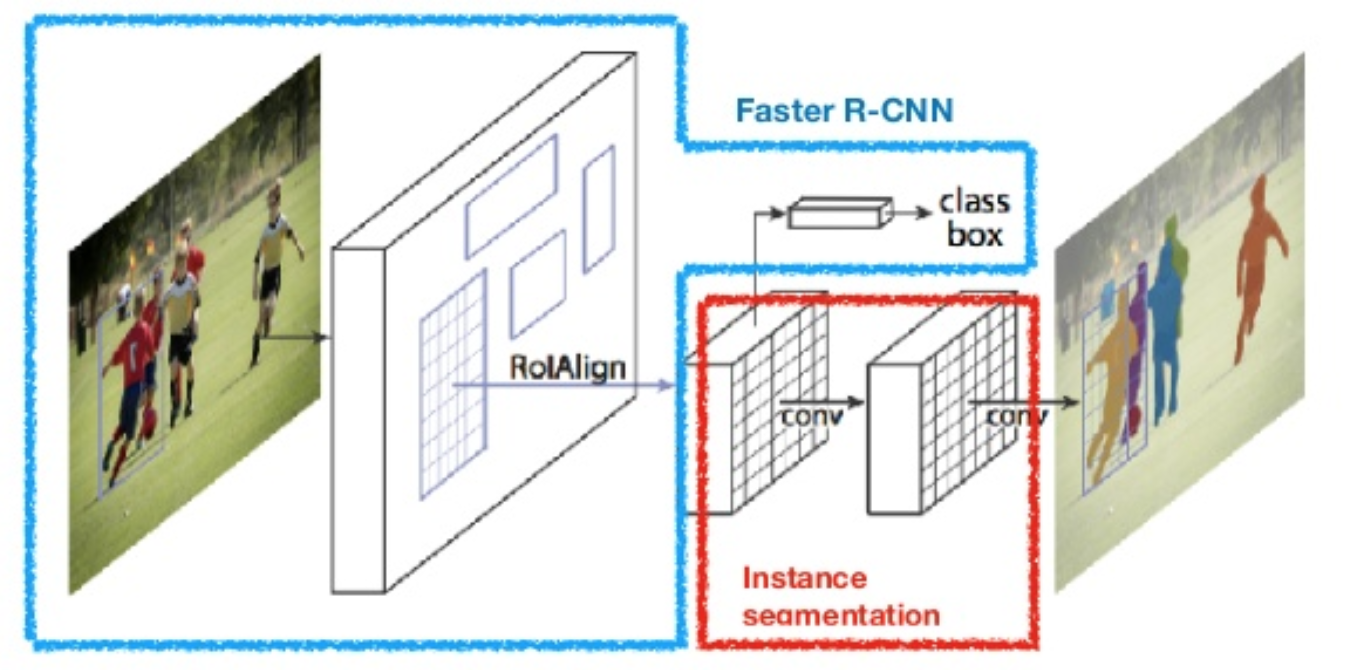
Fig. 8. Maschera R-CNN è più veloce modello R-CNN con segmentazione delle immagini. (Fonte immagine: He et al., 2017)
Poiché la segmentazione a livello di pixel richiede un allineamento molto più fine rispetto ai riquadri di delimitazione, mask R-CNN migliora il livello di pool del RoI (denominato “RoIAlign layer”) in modo che il RoI possa essere mappato in modo migliore e più preciso alle regioni dell’immagine originale.

Fig. 9. Previsioni di Mask R-CNN sul set di test COCO. (Fonte immagine: He et al., 2017)
RoIAlign
Il livello RoIAlign è progettato per correggere il disallineamento della posizione causato dalla quantizzazione nel pool del RoI. RoIAlign rimuove la quantizzazione hash , ad esempio, utilizzando x/16 invece di, in modo che le funzionalità estratte possano essere allineate correttamente con i pixel di input. L’interpolazione bilineare viene utilizzata per calcolare i valori di posizione in virgola mobile nell’input.
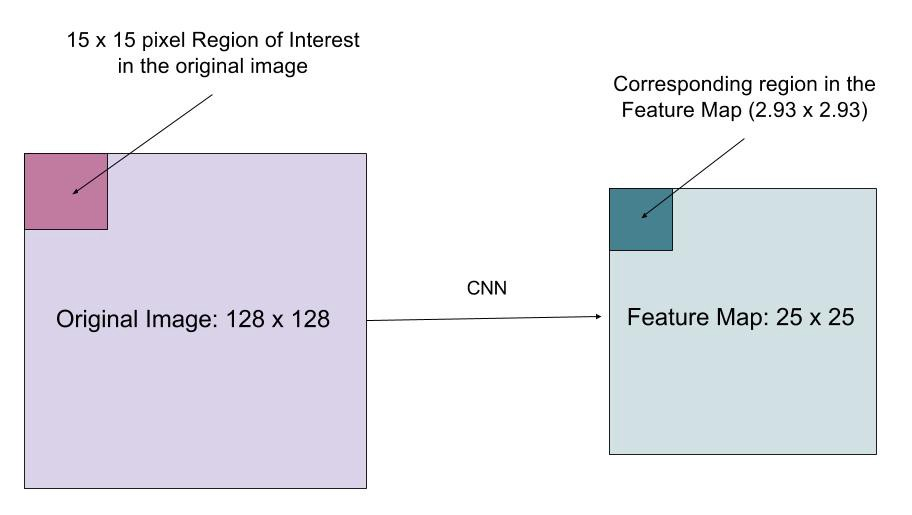
Fig. 10. Una regione di interesse viene mappata accuratamente dall’immagine originale sulla mappa delle funzionalità senza arrotondare a numeri interi. (Fonte immagine: link)
la Perdita di Funzione
Il multi-task perdita di funzione di Maschera di R-CNN combina la perdita di classificazione, localizzazione e la segmentazione maschera: \(\mathcal{L} = \mathcal{L}_\text{cls} + \mathcal{L}_\text{casella} + \mathcal{L}_\text{mask}\), dove \(\mathcal{L}_\text{cls}\) e \(\mathcal{L}_\text{casella}\) sono le stesse della più Veloce R-CNN.
Il ramo mask genera una maschera di dimensione m x m per ogni RoI e ogni classe; K classi in totale. Pertanto, l’output totale è di dimensione \(K \ cdot m^2\). Poiché il modello sta cercando di imparare una maschera per ogni classe, non c’è competizione tra le classi per la generazione di maschere.
\(\mathcal{L}_\text{mask}\) è definito come la media binario cross-entropia perdita, solo k-esimo maschera, se la regione è associato con la verità di terra classe k.
\\]
dove \(y_{ij}\) è l’etichetta di una cella (i, j) in vera maschera per la regione di dimensione m x m; \(\hat{y}_{ij}^k\) è il valore stimato di una stessa cella in maschera imparato per la terra-la verità di classe k.
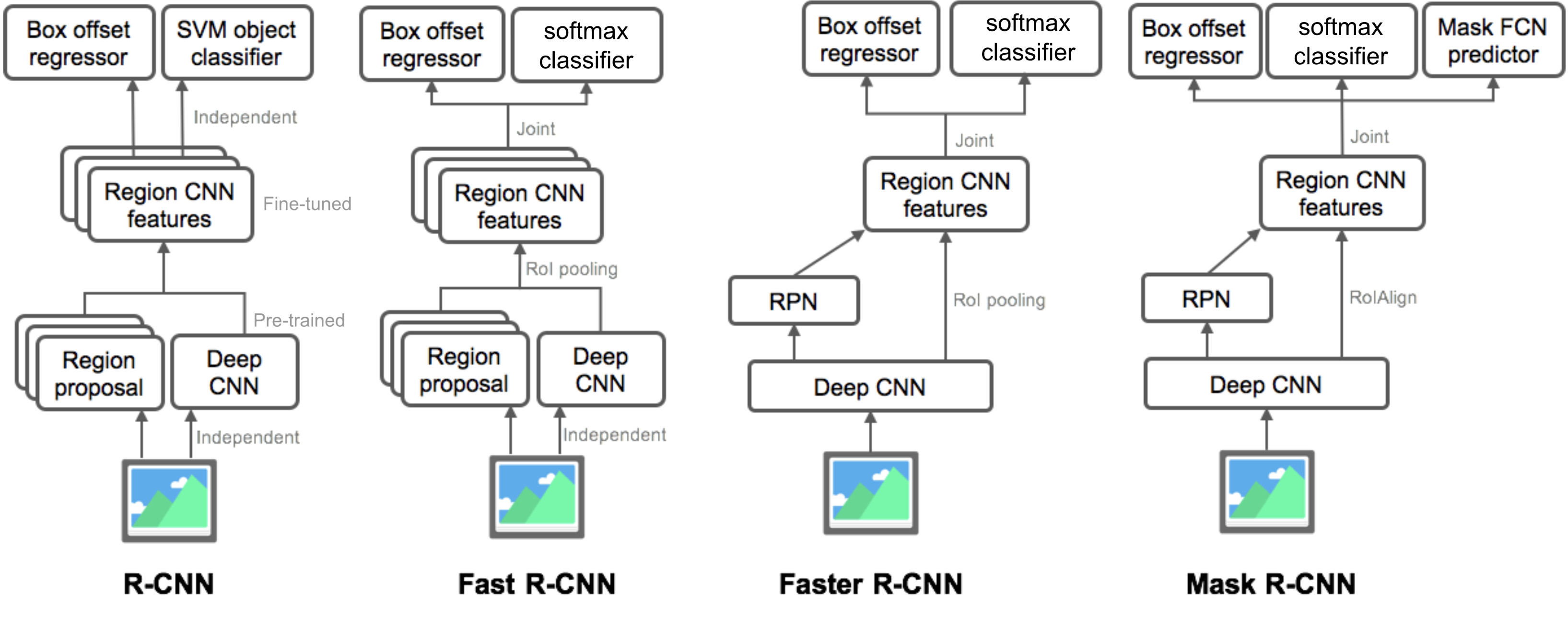
Riepilogo dei modelli della famiglia R-CNN
Qui illustrerò i modelli di R-CNN, Fast R-CNN, Faster R-CNN e Mask R-CNN. È possibile tenere traccia di come un modello si evolve alla versione successiva confrontando le piccole differenze.
Citato come:
@article{weng2017detection3, title = "Object Detection for Dummies Part 3: R-CNN Family", author = "Weng, Lilian", journal = "lilianweng.github.io/lil-log", year = "2017", url = "http://lilianweng.github.io/lil-log/2017/12/31/object-recognition-for-dummies-part-3.html"}Riferimento
Ross Girshick, Jeff Donahue, Trevor Darrell, e Jitendra Malik. “Ricche gerarchie di funzionalità per il rilevamento accurato degli oggetti e la segmentazione semantica.”In Proc. IEEE Conf. su computer vision e pattern recognition (CVPR), pp. 580-587. 2014.- Ross Girshick. “Veloce R-CNN.”In Proc. IEEE Intl. Conf. su computer vision, pp. 1440-1448. 2015.il suo nome è stato tradotto in italiano e tradotto in italiano. “Più veloce R-CNN: Verso il rilevamento di oggetti in tempo reale con le reti proposta regione.”In Advances in neural information processing systems (NIPS), pp. 91-99. 2015.
Kaiming He, Georgia Gkioxari, Piotr Dollár e Ross Girshick. “Maschera R-CNN.”arXiv preprint arXiv: 1703.06870, 2017.
Joseph Redmon, Santosh Divvala, Ross Girshick e Ali Farhadi. “Si guarda solo una volta: unificato, rilevamento di oggetti in tempo reale.”In Proc. IEEE Conf. su computer vision e pattern recognition (CVPR), pp. 779-788. 2016.
” A Brief History of CNNs in Image Segmentation: From R-CNN to Mask R-CNN ” di Athelas.
Perdita L1 liscia: https://github.com/rbgirshick/py-faster-rcnn/files/764206/SmoothL1Loss.1.pdf