Wykrywanie obiektów dla manekinów Część 3: Rodzina R-CNN
w części 3 zbadamy cztery modele wykrywania obiektów: R-CNN, Fast R-CNN, Faster R-CNN i Mask R-CNN. Modele te są bardzo powiązane, a nowe wersje wykazują dużą poprawę prędkości w porównaniu do starszych.
w serii „detekcja obiektów dla manekinów” zaczęliśmy od podstawowych pojęć w przetwarzaniu obrazów, takich jak wektory gradientowe i wieprz, w części 1. Następnie w części 2 wprowadziliśmy Klasyczne konwolucyjne projekty architektury sieci neuronowych do klasyfikacji oraz pionierskie modele do rozpoznawania obiektów, Overfeat i DPM. W trzecim poście z tej serii, mamy zamiar przejrzeć zestaw modeli z rodziny R-CNN („region-based CNN”).
linki do wszystkich postów z serii: .
oto lista artykułów objętych tym postem 😉
| Model | Goal | Resources |
| R-CNN | Object recognition | |
| Fast R-CNN | Object recognition | |
| Faster R-CNN | Object recognition | |
| Mask R-CNN | Image segmentation |
- R-CNN
- Model Workflow
- regresja obwiedni
- wspólne triki
- wąskie gardło prędkości
- Fast R-CNN
- Roi Pooling
- Model Workflow
- funkcja utraty
- szybkie wąskie gardło
- Faster R-CNN
- Model Workflow
- funkcja utraty
- Maska R-CNN
- RoIAlign
- funkcja utraty wielu zadań Maski R-CNN łączy utratę klasyfikacji, lokalizacji i maski segmentacji: \(\mathcal{L} = \mathcal{L}_\text{cls} + \mathcal{L}_\text{box} + \mathcal{L}_\text{mask}\), gdzie \(\mathcal{L}_\text{cls}\) i \(\mathcal{L}_\text{box}\) są takie same jak w faster R-CNN.
- podsumowanie modeli z rodziny R-CNN
- odniesienie
R-CNN
R-CNN (Girshick et al., 2014) is short for „Region-based Convolutional Neural Networks”. The main idea is composed of two steps. Po pierwsze, korzystając z wyszukiwania selektywnego, identyfikuje łatwą do opanowania liczbę kandydatów na Region obiektu obwiedni („region zainteresowania” lub „zwrot z inwestycji”). Następnie wyodrębnia cechy CNN z każdego regionu niezależnie w celu klasyfikacji.
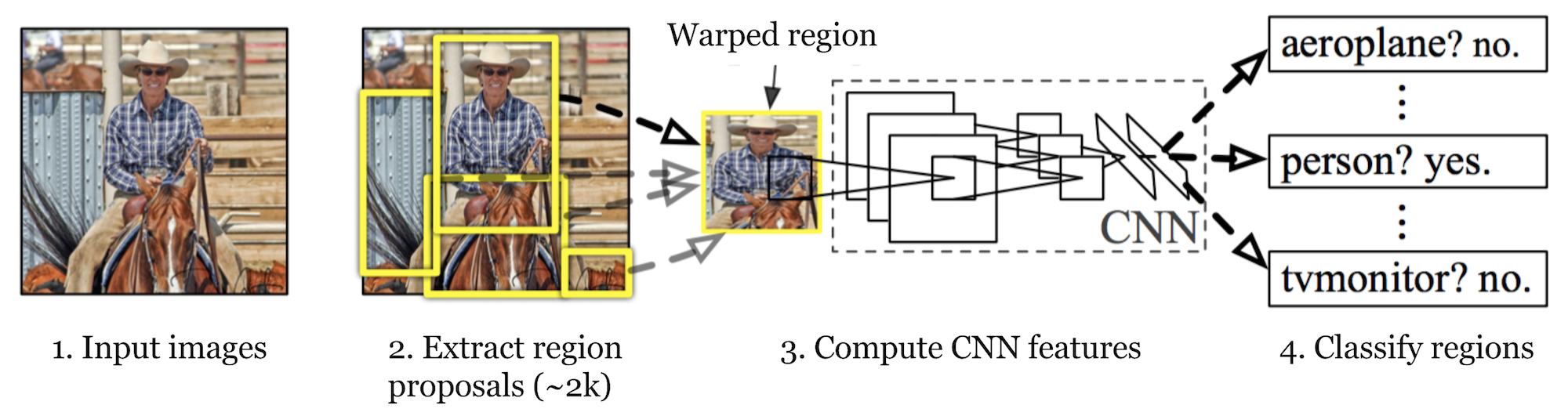
rys. 1. Architektura R-CNN. (Źródło obrazu: Girshick et al., 2014)
Model Workflow
sposób działania R-CNN można podsumować w następujący sposób:
- Pre-train a CNN network on image classification tasks; na przykład VGG lub ResNet przeszkolony na zestawie danych ImageNet. Zadanie klasyfikacyjne obejmuje N klas.
uwaga: w Caffe Model Zoo można znaleźć przygotowaną AlexNet. Nie sądzę, że można go znaleźć w Tensorflow, ale biblioteka modeli TensorFlow-slim zapewnia wstępnie wyszkolony ResNet, VGG i inne.
- Zaproponuj niezależne od kategorii regiony zainteresowania poprzez selektywne wyszukiwanie (~2K kandydatów na zdjęcie). Regiony te mogą zawierać obiekty docelowe i mają różne rozmiary.
- kandydaci regionu są wypaczeni, aby mieć stały rozmiar wymagany przez CNN.
- Kontynuuj dostrajanie CNN w zakrzywionych regionach propozycji dla klas K + 1; dodatkowa klasa odnosi się do tła (brak przedmiotu zainteresowania). Na etapie dostrajania powinniśmy stosować znacznie mniejszy wskaźnik uczenia się, a mini-partia oversample pozytywnych przypadków, ponieważ większość proponowanych regionów jest tylko tłem.
- biorąc pod uwagę Każdy region obrazu, jedna propagacja do przodu przez CNN generuje wektor funkcji. Ten wektor funkcji jest następnie zużywany przez binarną maszynę wirtualną szkoloną dla każdej klasy niezależnie.
próbki dodatnie są proponowanymi regionami z progiem nakładania się IoU (intersection over union)>= 0.3, A próbki ujemne są nieistotne inne. - aby zmniejszyć błędy lokalizacji, model regresji jest szkolony w celu skorygowania przewidywanego okna wykrywania na przesunięciu korekcji obwiedni przy użyciu funkcji CNN.
regresja obwiedni
biorąc pod uwagę przewidywaną współrzędną obwiedni \(\mathbf{p} = (p_x, p_y, p_w, p_h)\) (współrzędna Środkowa, szerokość, wysokość) i odpowiadające jej współrzędne pola prawdy ziemi \(\mathbf{g} = (g_x, g_y, g_w, g_h)\) , regresor jest skonfigurowany do nauki transformacji niezmienniczej skali między dwoma centrami i log-skali transformacja między szerokościami i wysokościami. Wszystkie funkcje transformacji przyjmują \(\mathbf{P}\) jako wejście.
\
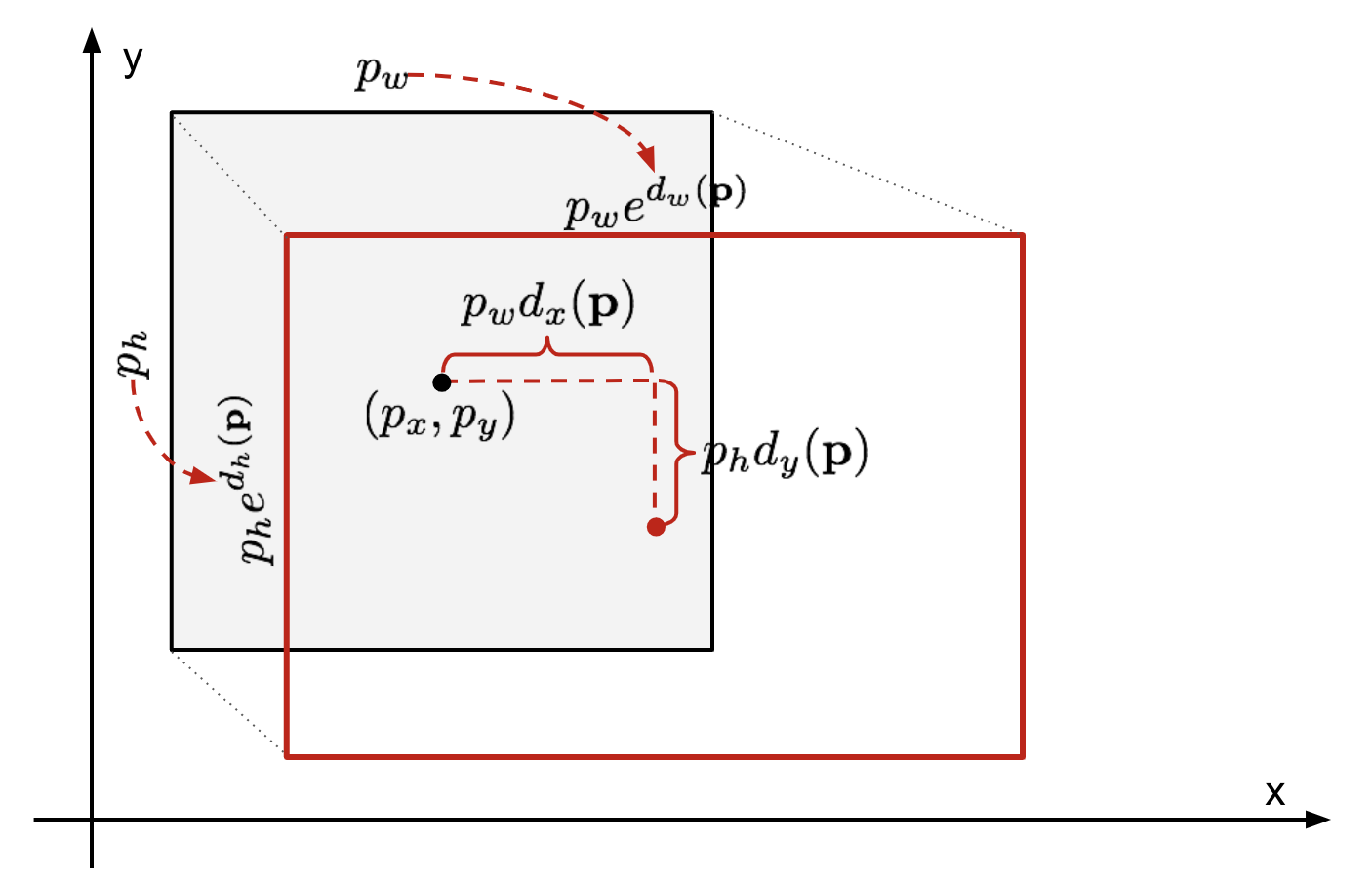
rys. 2. Ilustracja transformacji między przepowiedzianą i gruntową prawdą obwiednią.
oczywistą zaletą zastosowania takiej transformacji jest to, że wszystkie funkcje korekcji obwiedni, \(d_i(\mathbf{P})\), Gdzie \(i \in \{ X, y, W, h\}\), mogą przyjmować dowolną wartość pomiędzy . Cele dla nich do nauki są:
\
standardowy model regresji może rozwiązać problem, minimalizując straty SSE z regularyzacją:
\
termin regularyzacji jest tutaj krytyczny i rcnn paper wybrał najlepsze λ przez krzyżową walidację. Warto również zauważyć, że nie wszystkie przewidywane pola obwiedniowe mają odpowiednie pola prawdy gruntowej. Na przykład, jeśli nie ma nakładania się, nie ma sensu uruchamiać regresji bbox. Tutaj, tylko przewidywane pole z pobliskim polu prawdy ziemi z co najmniej 0.6 IoU jest przechowywany do szkolenia modelu regresji bbox.
wspólne triki
kilka trików jest powszechnie używanych w rcnn i innych modelach wykrywania.
brak maksymalnego tłumienia
prawdopodobnie model jest w stanie znaleźć wiele obwiedni dla tego samego obiektu. Tłumienie Non-max pomaga uniknąć wielokrotnego wykrywania tej samej instancji. Po otrzymaniu zestawu dopasowanych obwiedni dla tej samej kategorii obiektów: Sortuj wszystkie obwiedni według wyniku zaufania.Odrzucaj pudełka z niskim poziomem zaufania.Podczas gdy nie ma żadnych pozostałych obwiedni, powtórz następujące czynności: chciwie wybierz ten, który ma najwyższy wynik.Pomiń pozostałe pola z wysokim IoU (tj. > 0.5) z wcześniej wybranym.

rys. 3. Wiele obwiedni wykrywa samochód na obrazie. Po nie-maksymalnym tłumieniu pozostaje tylko najlepsze, a reszta jest ignorowana, ponieważ mają duże nakładanie się z wybranym. (Źródło obrazu: DPM paper)
Hard Negative Mining
jako przykłady ujemne uważamy obwiedniowe pola bez obiektów. Nie wszystkie negatywne przykłady są równie trudne do zidentyfikowania. Na przykład, jeśli zawiera czyste puste tło, prawdopodobnie jest to „łatwy negatyw”; ale jeśli pudełko zawiera dziwną, hałaśliwą teksturę lub częściowy obiekt, może być trudne do rozpoznania, a te są”twardymi negatywami”.
twarde negatywne przykłady łatwo błędnie zaklasyfikować. Możemy wyraźnie znaleźć te fałszywie pozytywne próbki podczas pętli treningowych i uwzględnić je w danych treningowych, aby poprawić klasyfikator.
wąskie gardło prędkości
przeglądając etapy uczenia się R-CNN, można łatwo dowiedzieć się, że szkolenie modelu R-CNN jest kosztowne i powolne, ponieważ następujące kroki wymagają wiele pracy:
- uruchamianie selektywnego wyszukiwania w celu zaproponowania 2000 kandydatów na regiony dla każdego obrazu;
- generowanie wektora funkcji CNN dla każdego regionu obrazu (N images * 2000).
- cały proces obejmuje trzy modele oddzielnie bez wielu wspólnych obliczeń: konwolucyjną sieć neuronową do klasyfikacji obrazu i ekstrakcji funkcji; górny klasyfikator SVM do identyfikacji obiektów docelowych; i model regresji do dokręcania obwiedni regionów.
Fast R-CNN
aby przyspieszyć R-CNN, Girshick (2015) ulepszył procedurę szkolenia, łącząc trzy niezależne modele w jedną wspólnie przeszkoloną ramę i zwiększając wspólne wyniki obliczeń, nazwane Fast R-CNN. Zamiast wyodrębniać wektory funkcji CNN niezależnie dla każdej propozycji regionu, model ten agreguje je w jedno przejście CNN do przodu na całym obrazie, a propozycje regionów udostępniają tę matrycę funkcji. Następnie ta sama macierz funkcji jest rozgałęziona do wykorzystania do nauki klasyfikatora obiektów i regresora bounding-box. Podsumowując, dzielenie obliczeń przyspiesza R-CNN.
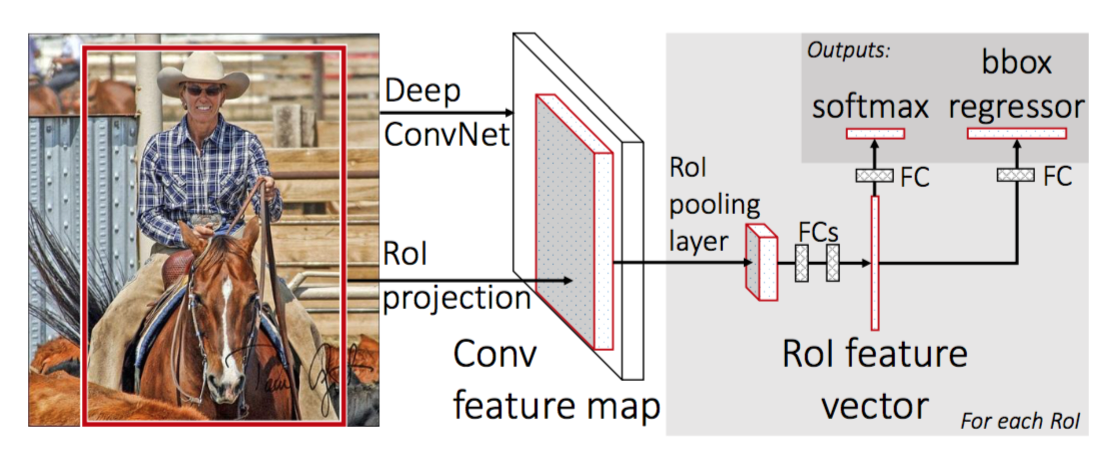
rys. 4. Architektura Fast R-CNN. (Źródło obrazu: Girshick, 2015)
Roi Pooling
jest to rodzaj max poolingu w celu konwersji funkcji w wyświetlanym obszarze obrazu o dowolnym rozmiarze, h x w, w małe stałe okno, H x W. obszar wejściowy jest podzielony na Siatki H x W, w przybliżeniu każde subwindown o rozmiarze h/H x w/W. następnie zastosuj Max pooling w każdej siatce.
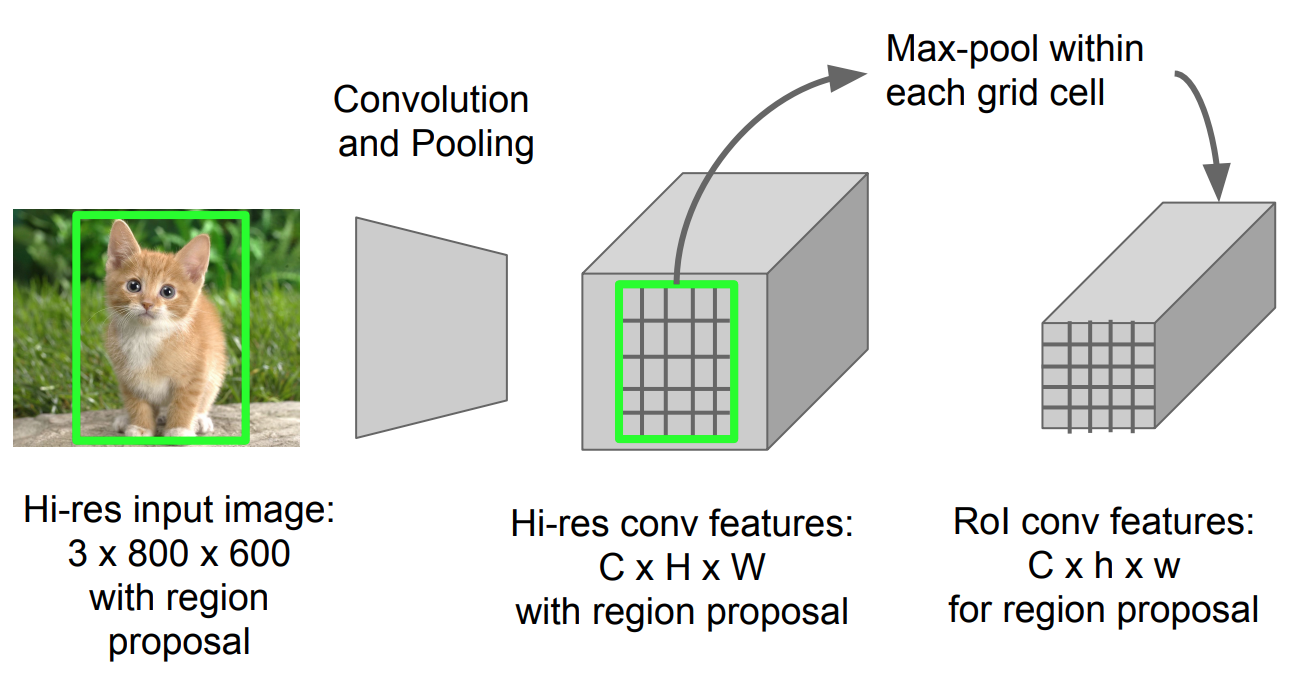
rys. 5. Roi pooling (Źródło zdjęcia: slajdy Stanford CS231n.)
Model Workflow
Jak szybko działa R-CNN jest podsumowany w następujący sposób; wiele kroków jest takich samych jak w R-CNN:
- po pierwsze, pre-train convolutional neural network on image classification tasks.
- Zaproponuj regiony przez selective search (~2K kandydatów na zdjęcie).
- Zmień wstępnie wytrenowaną CNN:
- Zastąp ostatnią warstwę Max pooling wstępnie wytrenowanej CNN warstwą Roi pooling. Warstwa Roi pooling generuje wektory o stałej długości propozycji regionów. Dzielenie się obliczeniami CNN ma sens, ponieważ wiele propozycji regionów tych samych obrazów jest mocno na siebie nałożonych.
- Zastąp ostatnią w pełni połączoną warstwę i ostatnią warstwę softmax (klasy K) w pełni połączoną warstwą i softmax nad klasami K + 1.
- wreszcie model rozgałęzia się na dwie warstwy wyjściowe:
- Estymator softmax klas K + 1 (taki sam jak w R-CNN, +1 jest klasą „tła”), wyprowadzając dyskretny rozkład prawdopodobieństwa na RoI.
- model regresji bounding-box, który przewiduje przesunięcia względem pierwotnego zwrotu z inwestycji dla każdej z klas K.
funkcja utraty
model jest zoptymalizowany dla straty łączącej dwa zadania (klasyfikacja + lokalizacja):
| Symbol | Wyjaśnienie |
| \(u\) | True Class Label, \(u \in 0, 1, \Dots, K\); zgodnie z konwencją Klasa catch-all background ma \(u = 0\). |
| \(p\) | dyskretny rozkład prawdopodobieństwa (na RoI) w klasach K + 1: \(p = (p_0, \dots, p_K)\), obliczany przez softmax nad wyjściami K + 1 w pełni połączonej warstwy. |
| \(v\) | True bounding box \(v = (v_x, v_y, v_w, v_h)\). |
| \(t^u\) | przewidywana korekta obwiedni, \(t^u = (t^u_x, t^u_y, t^u_w, t^u_h)\). Patrz wyżej. |
funkcja strat podsumowuje koszt klasyfikacji i przewidywania obwiedni: \(\mathcal{L} = \mathcal{L}_\text{cls} + \mathcal{L}_\text{box}\). Dla” background ” RoI, \(\mathcal{L}_ \ text{box}\) jest ignorowany przez funkcję wskaźnika \(\mathbb{1} \), zdefiniowaną jako:
\ = \begin{cases} 1 & \text{if } u \geq 1\\ 0 & \text{otherwise}\end{cases}\]
ogólna funkcja utraty TO:
\ \mathcal{L}_\text{box}(t^U, v) \\\mathcal{l}_\text{cls}(p, u) &= -\log p_u \\\mathcal{l}_\text{box}(T^U, V) &= \sum_{i \in \{x, y, w, h\}} l_1^\text{Smooth} (t^u_i – v_i)\end{align*}\]
obwiedniowy loss \(\mathcal{l}_{box}\) powinien zmierzyć różnicę między \(t^u_i\) i \(v_i\) przy użyciu solidnej funkcji loss. Przyjmuje się tutaj gładką stratę L1 i twierdzi się, że jest mniej wrażliwa na wartości odstające.
\
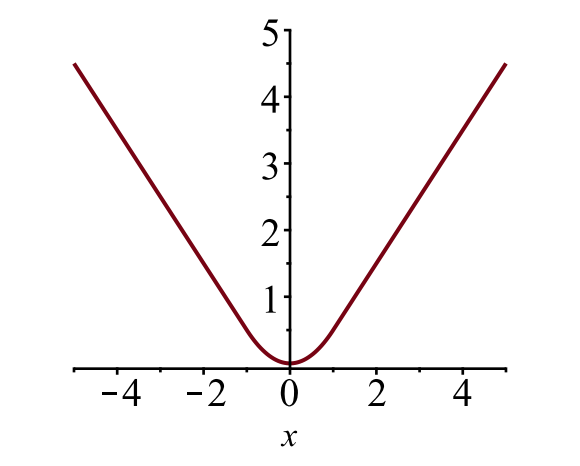
rys. 6. Wykres gładkiej utraty L1, \(y = L_1^ \ text{smooth} (x)\). (Źródło zdjęcia: link)
szybkie wąskie gardło
szybki R-CNN jest znacznie szybszy zarówno w czasie treningu, jak i testów. Poprawa nie jest jednak dramatyczna, ponieważ propozycje regionów są generowane oddzielnie przez inny model, co jest bardzo kosztowne.
Faster R-CNN
intuicyjnym rozwiązaniem speedup jest zintegrowanie algorytmu propozycji regionu z modelem CNN. Faster R-CNN (Ren et al., 2016) robi dokładnie to: zbuduj pojedynczy, zunifikowany model składający się z RPN (region proposal network) i szybkiego R-CNN ze współdzielonymi warstwami funkcji konwolucyjnych.

rys. 7. Ilustracja szybszego modelu R-CNN. (Źródło obrazu: Ren et al., 2016)
Model Workflow
- Pre-train a CNN network on image classification tasks.
- Dostosuj RPN (region proposal network) od końca do końca dla zadania propozycji regionu, które jest inicjowane przez klasyfikator obrazu przed pociągiem. Próbki dodatnie mają IoU (intersection-over-union) > 0,7, podczas gdy próbki ujemne mają IOU < 0,3.
- Przesuń małe okno przestrzenne n x n nad mapą funkcji conv całego obrazu.
- w środku każdego przesuwanego okna przewidujemy wiele regionów o różnych skalach i proporcjach jednocześnie. Kotwica jest kombinacją (przesuwne centrum okna, skala, stosunek). Na przykład 3 skale + 3 współczynniki = > k = 9 kotew w każdej pozycji ślizgowej.
- trenuj szybki model wykrywania obiektów R-CNN, korzystając z propozycji generowanych przez obecny RPN
- , a następnie użyj szybkiej sieci R-CNN, aby zainicjować szkolenie RPN. Zachowując wspólne warstwy splotu, dostosuj tylko warstwy specyficzne dla RPN. Na tym etapie RPN i sieć detekcyjna współdzieliły warstwy splotu!
- wreszcie dostroić unikalne warstwy Fast R-CNN
- krok 4-5 można powtórzyć, aby trenować RPN i Fast R-CNN alternatywnie w razie potrzeby.
funkcja utraty
Faster R-CNN jest zoptymalizowany pod kątem wielozadaniowej funkcji utraty, podobnej do fast R-CNN.
| Symbol | Wyjaśnienie | |
| \(p_i\) | przewidywane prawdopodobieństwo zakotwiczenia i jest obiektem. | |
| \(p^*_i\) | uziemiona Etykieta prawdy (binarna) o tym, czy anchor i jest obiektem. | |
| \(t_i\) | przewiduje cztery parametryzowane współrzędne. | |
| \(t^*_i\) | Współrzędne Ziemi. | |
| \(n_\text{cls}\) | termin normalizacji, ustawiony na rozmiar mini partii (~256) w artykule. | |
| \(n_\text{box}\) | termin normalizacji, ustawiony na liczbę zakotwiczeń (~2400) w dokumencie. | |
| \(\lambda\) | parametr równoważący, ustawiony na ~10 w dokumencie (tak, że oba terminy \(\mathcal{L}_\text{cls}\) i \(\mathcal{L}_\text{box}\) są mniej więcej równo ważone). |
funkcja utraty wielu zadań łączy straty klasyfikacji i regresji obwiedni:
\
gdzie \(\mathcal{L}_\text{cls}\) jest funkcją utraty logów w dwóch klasach, ponieważ możemy łatwo przetłumaczyć klasyfikację wielu klas na klasyfikację binarną poprzez przewidywanie, że próbka jest obiektem docelowym, a nie obiektem docelowym. \(L_1^ \ text{smooth}\) jest gładką stratą L1.
\
Maska R-CNN
Maska R-CNN (He et al., 2017) rozszerza szybciej R-CNN do segmentacji obrazu na poziomie pikseli. Kluczową kwestią jest oddzielenie zadań klasyfikacji i przewidywania maski na poziomie pikseli. W oparciu o Faster R-CNN dodano trzecią gałąź do przewidywania maski obiektu równolegle z istniejącymi gałęziami do klasyfikacji i lokalizacji. Gałąź Maska to mała, w pełni połączona sieć stosowana do każdego zwrotu z inwestycji, przewidująca maskę segmentacji w sposób piksel do piksela.
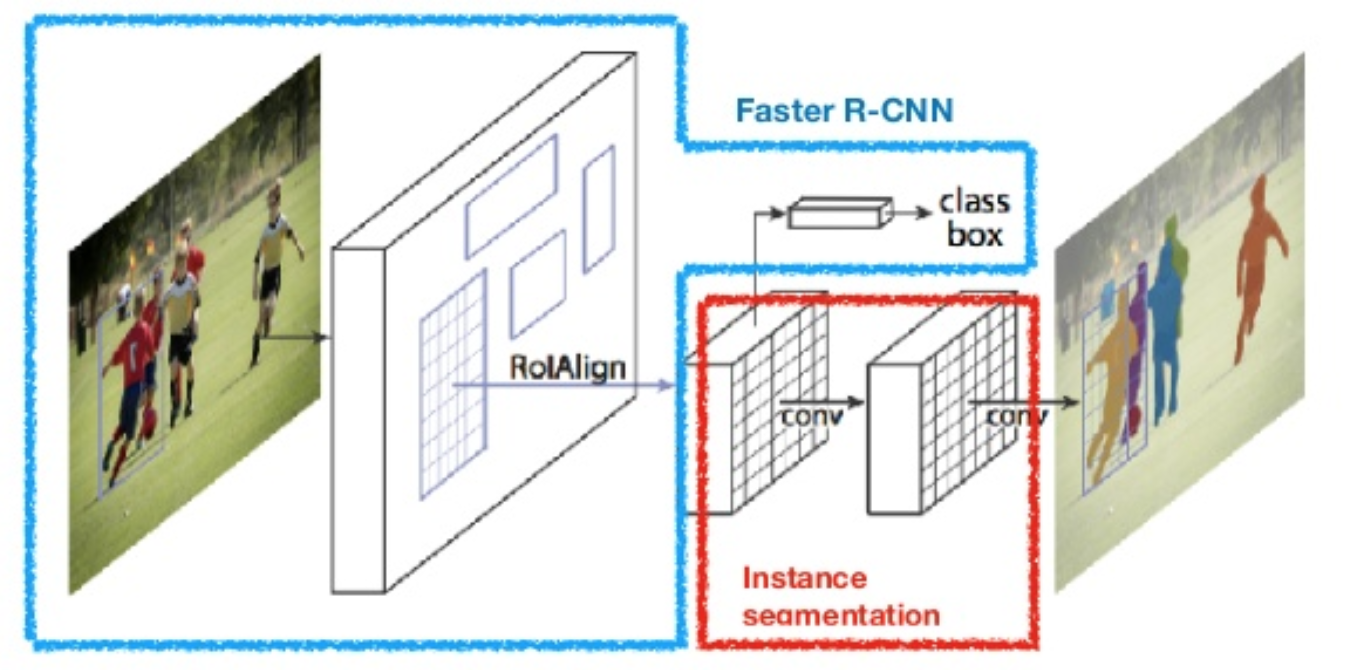
rys. 8. Maska R-CNN jest szybszym modelem R-CNN z segmentacją obrazu. (Źródło obrazu: He et al., 2017)
ponieważ segmentacja na poziomie pikseli wymaga znacznie bardziej drobnoziarnistego wyrównania niż obwiedni, mask R-CNN poprawia warstwę poolingu zwrotu z inwestycji (zwaną „warstwą RoIAlign”), dzięki czemu zwrot z inwestycji może być lepiej i precyzyjniej odwzorowany na regiony oryginalnego obrazu.

rys. 9. Przewidywania przez maskę R-CNN na zestawie testowym COCO. (Źródło obrazu: He et al., 2017)
RoIAlign
warstwa RoIAlign ma na celu naprawienie niewspółosiowości lokalizacji spowodowanej kwantyzacją w Puli RoI. RoIAlign usuwa kwantyzację skrótu, na przykład za pomocą x/16 zamiast, dzięki czemu wyodrębnione funkcje mogą być odpowiednio wyrównane z wejściowymi pikselami. Dwuliniowa interpolacja jest używana do obliczania zmiennoprzecinkowych wartości położenia na wejściu.
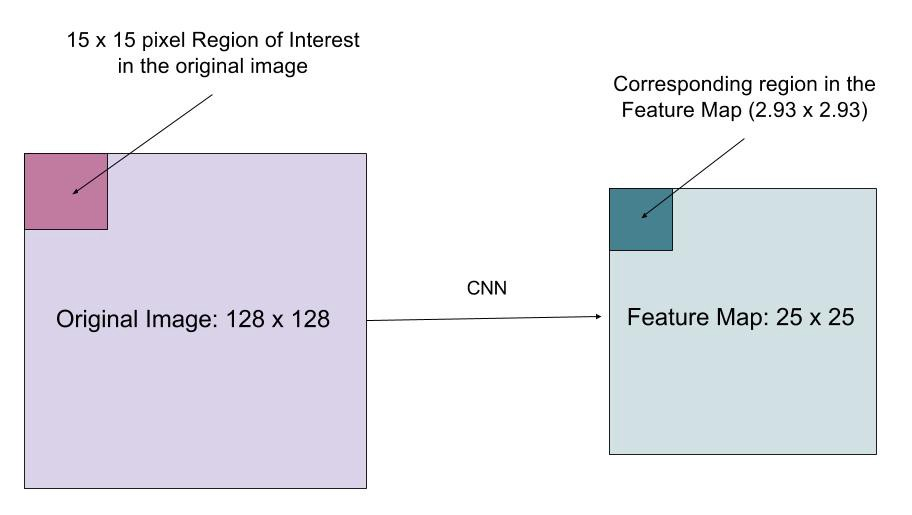
rys. 10. Obszar zainteresowania jest dokładnie odwzorowywany z oryginalnego obrazu na mapie funkcji bez zaokrąglania do liczb całkowitych. (Źródło obrazu: funkcja utraty
funkcja utraty wielu zadań Maski R-CNN łączy utratę klasyfikacji, lokalizacji i maski segmentacji: \(\mathcal{L} = \mathcal{L}_\text{cls} + \mathcal{L}_\text{box} + \mathcal{L}_\text{mask}\), gdzie \(\mathcal{L}_\text{cls}\) i \(\mathcal{L}_\text{box}\) są takie same jak w faster R-CNN.
gałąź Maska generuje maskę o wymiarach m x M dla każdego RoI i każdej klasy; klasy K w sumie. Tak więc, całkowite wyjście jest wielkości \(K \ cdot m^2\). Ponieważ model próbuje nauczyć się maski dla każdej klasy, nie ma konkurencji między klasami w zakresie generowania masek.
\(\mathcal{L}_\text{mask}\) jest zdefiniowana jako średnia binarna utrata entropii krzyżowej, włączając tylko maskę k, jeśli region jest powiązany z klasą prawdy ziemi k.
\\]
gdzie \(y_{ij}\) jest etykietą komórki (i, j) w prawdziwej masce dla obszaru o rozmiarze M x M; \(\hat{y}_{ij}^k\) jest przewidywaną wartością tej samej komórki w masce nauka dla ziemi-prawda Klasa k.
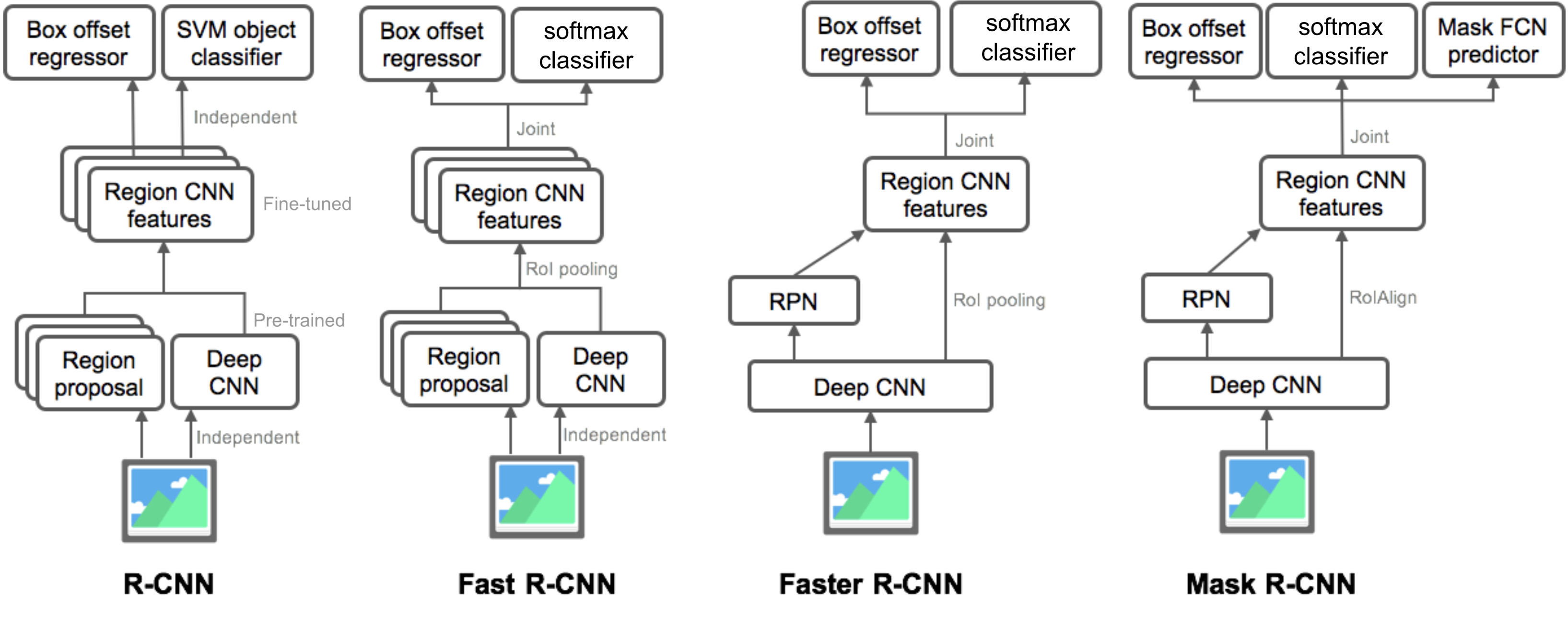
podsumowanie modeli z rodziny R-CNN
tutaj ilustruję modele r-CNN, Fast R-CNN, Faster R-CNN i Mask R-CNN. Możesz śledzić, jak jeden model ewoluuje do następnej wersji, porównując małe różnice.
@article{weng2017detection3, title = "Object Detection for Dummies Part 3: R-CNN Family", author = "Weng, Lilian", journal = "lilianweng.github.io/lil-log", year = "2017", url = "http://lilianweng.github.io/lil-log/2017/12/31/object-recognition-for-dummies-part-3.html"}odniesienie
Jeff Donahue, Trevor Darrell i Jitendra Malik. „Bogate hierarchie funkcji dla dokładnego wykrywania obiektów i segmentacji semantycznej.”W Proc. IEEE Conf. on computer vision and pattern recognition (CVPR), PP.580-587. 2014.
Ross Girshick. „Fast R-CNN.”W Proc. IEEE Intl. Conf. on computer vision, S. 1440-1448. 2015.
Shaoqing Ren, Kaiming He, Ross Girshick i Jian Sun. „Szybsze R-CNN: w kierunku wykrywania obiektów w czasie rzeczywistym za pomocą sieci propozycji regionów.”In Advances in neural information processing systems (NIPS), PP.91-99. 2015.
Kaiming He, Georgia Gkioxari, Piotr Dollár i Ross Girshick. „Maska R-CNN.”arXiv preprint arXiv: 1703.06870, 2017.
Joseph Redmon, Santosh Divvala, Ross Girshick i Ali Farhadi. „Patrzysz tylko raz: ujednolicone wykrywanie obiektów w czasie rzeczywistym.”W Proc. IEEE Conf. on computer vision and pattern recognition (CVPR), PP.779-788. 2016.
„a Brief History of CNNs in Image Segmentation: From R-CNN to Mask R-CNN” by Athelas.
gładka strata L1:https://github.com/rbgirshick/py-faster-rcnn/files/764206/SmoothL1Loss.1.pdf