Objectdetectie voor Dummies deel 3: R-CNN familie
in Deel 3 zouden we vier objectdetectiemodellen onderzoeken: R-CNN, Fast R-CNN, Faster R-CNN en Mask R-CNN. Deze modellen zijn zeer verwant en de nieuwe versies vertonen grote snelheidsverbetering in vergelijking met de oudere.
In de serie” Object Detection for Dummies ” zijn we begonnen met basisconcepten in beeldverwerking, zoals gradiëntvectoren en HOG, in Deel 1. Vervolgens introduceerden we klassieke convolutionele neurale netwerkarchitectuurontwerpen voor classificatie en pioniermodellen voor objectherkenning, overeat en DPM, in Deel 2. In de derde post van deze serie, staan we op het punt om een set van modellen in de R-CNN (“Region-based CNN”) familie te bekijken.
Links naar alle berichten in de serie: .
Hier is een lijst van documenten die in dit bericht worden behandeld 😉
| Model | Goal | Resources |
| R-CNN | Object recognition | |
| Fast R-CNN | Object recognition | |
| Faster R-CNN | Object recognition | |
| Mask R-CNN | Image segmentation |
R-CNN
R-CNN (Girshick et al., 2014) is short for “Region-based Convolutional Neural Networks”. The main idea is composed of two steps. Ten eerste, met behulp van selectief zoeken, identificeert het een beheersbaar aantal bounding-box object regio kandidaten (“regio van belang” of “RoI”). En dan haalt het CNN-functies uit elke regio onafhankelijk voor classificatie.
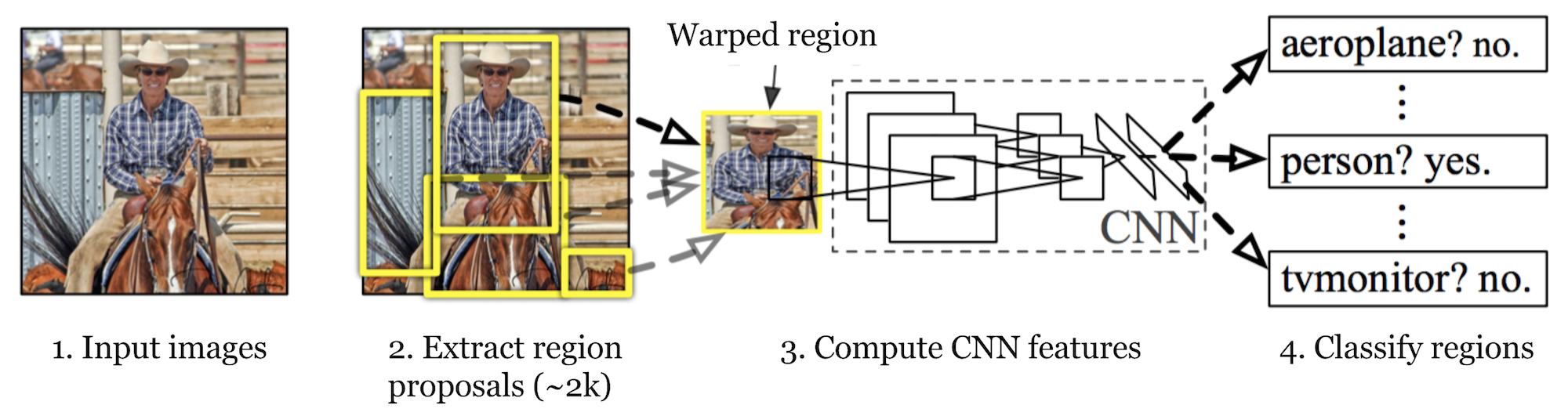
Fig. 1. De architectuur van R-CNN. (Bron afbeelding: Girshick et al., 2014)
Model Workflow
hoe R-CNN werkt kan als volgt worden samengevat:
- Pre-train een CNN-netwerk op afbeeldingsclassificatietaken; bijvoorbeeld, VGG of ResNet getraind op ImageNet-dataset. De classificatietaak omvat N-klassen.
Opmerking: U kunt een Voorgetrainde AlexNet vinden in Caffe Model Zoo. Ik denk niet dat je het kunt vinden in Tensorflow, maar Tensorflow-slim model bibliotheek biedt pre-getrainde ResNet, VGG, en anderen.
- voorstellen categorie-Onafhankelijke regio ‘ s van belang door selectief zoeken (~2k kandidaten per afbeelding). Deze regio ‘ s kunnen doelobjecten bevatten en ze zijn van verschillende grootte.
- Regiokandidaten worden kromgetrokken tot een vaste grootte zoals vereist door CNN.
- doorgaan met het verfijnen van de CNN op verwrongen voorstel regio ‘ s voor K + 1 klassen; de extra één klasse verwijst naar de achtergrond (geen voorwerp van belang). In de fine-tuning fase, moeten we een veel kleinere Leersnelheid gebruiken en de mini-batch oversamples de positieve gevallen, omdat de meeste voorgestelde regio ‘ s zijn gewoon achtergrond.
- gegeven elk afbeeldingsgebied genereert één voorwaartse voortplanting door de CNN een feature vector. Deze feature vector wordt dan verbruikt door een binaire SVM getraind voor elke klasse onafhankelijk.
de positieve monsters zijn voorgestelde regio ’s met Overlappingsdrempel > = 0,3, en negatieve monsters zijn irrelevant andere. - om de lokalisatiefouten te verminderen, wordt een regressiemodel getraind om het voorspelde detectievenster op de correctie van bounding box te corrigeren met behulp van CNN-functies.
begrenzingsvak regressie
gegeven een voorspelde begrenzingsvakcoördinaat \(\mathbf{p} = (p_x, p_y, p_w, p_h)\) (middencoördinaat, breedte, hoogte) en de bijbehorende grondwaarheidsvakcoördinaten \(\mathbf{g} = (g_x, g_y, g_w, g_h)\) , is de regressor geconfigureerd om Schaal-invariante transformatie tussen twee centra en log-schaal te leren transformatie tussen breedtes en hoogtes. Alle transformatiefuncties nemen \(\mathbf{p}\) als invoer.
\
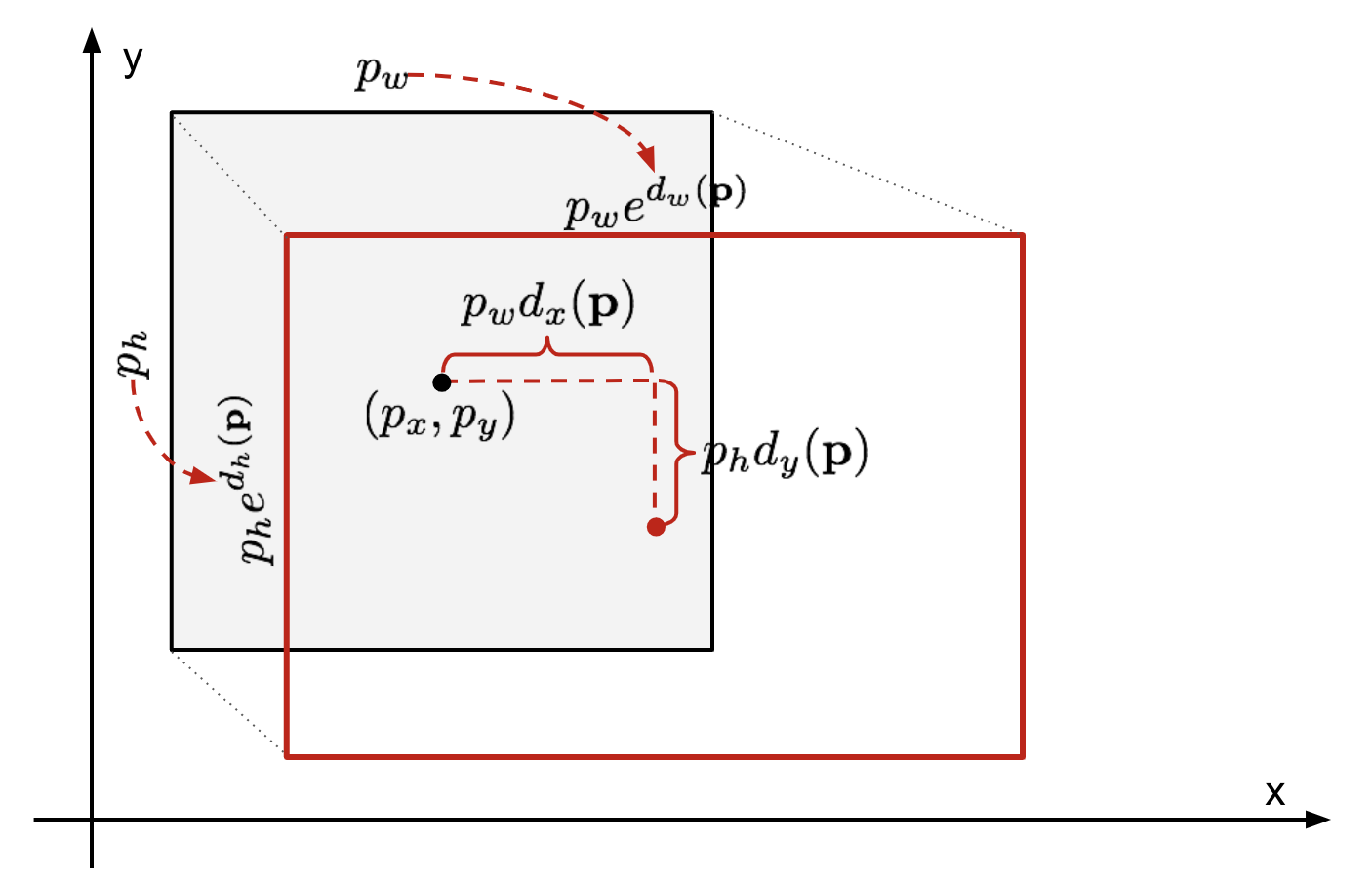
Fig. 2. Illustratie van transformatie tussen voorspelde en grond waarheid bounding dozen.
een duidelijk voordeel van het toepassen van een dergelijke transformatie is dat alle bounding box correctie functies, \(d_i(\mathbf{p})\) waar \(i \in \{ x, y, w, h \}\), elke waarde tussen kunnen nemen . De doelen voor hen om te leren zijn:
\
een standaard regressiemodel kan het probleem oplossen door het SSE-verlies te minimaliseren met regularisatie:
\
De term regularisatie is hier cruciaal en RCNN paper koos de beste λ Door kruisvalidatie. Het is ook opmerkelijk dat niet alle voorspelde bounding dozen hebben overeenkomstige grond waarheid dozen. Als er bijvoorbeeld geen overlapping is, heeft het geen zin om Bbox-regressie uit te voeren. Hier wordt alleen een voorspelde doos met een nabijgelegen ground truth box met ten minste 0,6 IoU bewaard voor het trainen van het Bbox regressiemodel.
gemeenschappelijke trucs
verschillende trucs worden vaak gebruikt in RCNN en andere detectiemodellen.
Niet-maximale onderdrukking
waarschijnlijk kan het model meerdere bounding boxes vinden voor hetzelfde object. Non-max onderdrukking voorkomt herhaalde detectie van dezelfde instantie. Nadat we een set overeenkomende bounding boxes voor dezelfde objectcategorie hebben gekregen:Sorteer alle bounding boxes op confidence score.Gooi dozen met een laag vertrouwen scores.Terwijl er een resterende bounding box, herhaal het volgende: gretig selecteer degene met de hoogste score.Sla de resterende vakken met hoge IoU (dwz 0.5) met eerder geselecteerde.

Fig. 3. Meerdere bounding boxes detecteren de auto in de afbeelding. Na Niet-maximale onderdrukking blijft alleen het beste over en de rest wordt genegeerd omdat ze grote overlappingen hebben met de geselecteerde. (Afbeeldingsbron: DPM paper)
Hard Negative Mining
We beschouwen bounding boxes zonder objecten als negatieve voorbeelden. Niet alle negatieve voorbeelden zijn even moeilijk te identificeren. Bijvoorbeeld, als het zuivere lege achtergrond bevat, is het waarschijnlijk een “gemakkelijk negatief”; maar als het vak vreemde lawaaierige textuur of gedeeltelijk object bevat, kan het moeilijk zijn om te worden herkend en deze zijn”hard negatief”.
de harde negatieve voorbeelden worden gemakkelijk verkeerd ingedeeld. We kunnen deze vals-positieve monsters expliciet vinden tijdens de trainingslussen en opnemen in de trainingsgegevens om de classifier te verbeteren.
Speed Bottleneck
kijkend door de R-CNN leerstappen, kunt u gemakkelijk ontdekken dat het trainen van een R-CNN model duur en traag is, omdat de volgende stappen veel werk vergen:
- selectief Zoeken om 2000 regiokandidaten voor elke afbeelding voor te stellen;
- het genereren van de CNN-feature vector voor elk afbeeldingsgebied (n images * 2000).
- het hele proces omvat drie modellen afzonderlijk zonder veel gedeelde berekening: het convolutionele neurale netwerk voor beeldclassificatie en functie-extractie; de bovenste SVM classifier voor het identificeren van doelobjecten; en het regressiemodel voor het aanscherpen van region bounding boxes.
Fast R-CNN
om R-CNN sneller te maken, verbeterde Girshick (2015) de trainingsprocedure door drie onafhankelijke modellen te verenigen in één gezamenlijk opgeleid framework en gedeelde rekenresultaten te verhogen, genaamd Fast R-CNN. In plaats van het extraheren van CNN feature vectoren onafhankelijk voor elke regio voorstel, dit model aggregeert ze in een CNN forward pass over het hele beeld en de regio voorstellen delen deze functie matrix. Vervolgens wordt dezelfde feature matrix vertakt om te worden gebruikt voor het leren van de object classifier en de bounding-box regressor. Concluderend, berekening delen versnelt R-CNN.
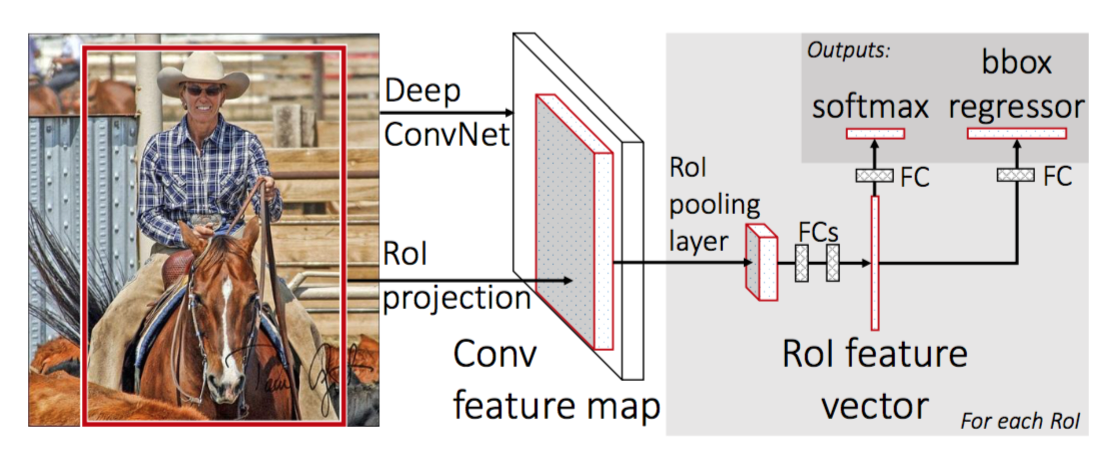
Fig. 4. De architectuur van Fast R-CNN. (Bron van de afbeelding: Girshick, 2015)
RoI-Pooling
Het is een type max-pooling om functies in het geprojecteerde gebied van het beeld van elke grootte, h x w, om te zetten in een klein vast venster, H x W. het invoergebied is verdeeld in H x W-rasters, ongeveer elk subvenster van grootte h/H x w/W. pas dan max-pooling toe in elk raster.
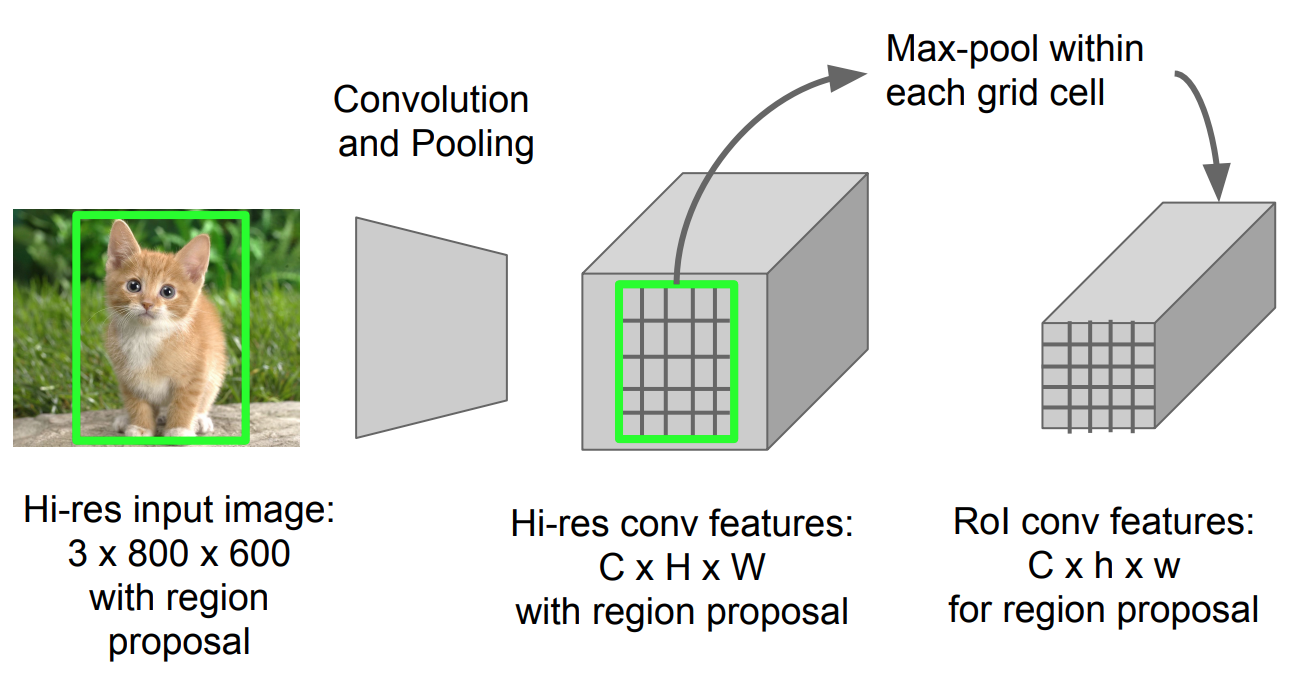
Fig. 5. Roi pooling (bron: Stanford CS231n slides.)
Model Workflow
hoe snel R-CNN werkt wordt als volgt samengevat; veel stappen zijn hetzelfde als in R-CNN:
- eerst een convolutioneel neuraal netwerk voor beeldclassificatietaken vooraf trainen.
- voorstellen van regio ‘ s door selectief zoeken (~2k kandidaten per afbeelding).
- Wijzig de voorgetrainde CNN:
- Vervang de laatste maximale poolingslaag van de voorgetrainde CNN door een ROI-poolingslaag. De ROI pooling laag outputs vaste lengte kenmerken vectoren van regio voorstellen. Het delen van de CNN-berekening heeft veel zin, omdat veel regio-voorstellen van dezelfde beelden sterk overlappen.
- Vervang de laatste volledig verbonden laag en de laatste softmax-laag (K-klassen) door een volledig verbonden laag en softmax over K + 1-klassen.
- ten slotte vertakt het model zich in twee outputlagen:
- een softmax-schatter van K + 1-klassen (hetzelfde als in R-CNN, +1 is de “background” – klasse), waarbij een discrete kansverdeling per RoI wordt uitgevoerd.
- een bounding-box regressiemodel dat offsets voorspelt ten opzichte van de oorspronkelijke RoI voor elk van de K-klassen.
verliesfunctie
het model is geoptimaliseerd voor een verlies dat twee taken combineert (classificatie + lokalisatie):
| symbool | uitleg |
| \(u\) | true class label, \(u \in 0, 1, \dots, K\); bij Overeenkomst heeft de catch-all achtergrondklasse \(u = 0\). |
| \(p\) | Discrete kansverdeling (per RoI) over K + 1-klassen: \(p = (p_0, \dots, p_K)\), berekend door een softmax over de K + 1-uitgangen van een volledig verbonden laag. |
| \(v\) | True bounding box \(v = (v_x, v_y, v_w, v_h)\). |
| \(t^u\) | voorspelde bounding box correctie, \(t^u = (t^u_x, t^u_y, t^u_w, t^u_h)\). Zie hierboven. |
De verliesfunctie somt de kosten van classificatie en bounding box voorspelling op: \(\mathcal{L} = \mathcal{L}_\text{cls} + \mathcal{l}_\text{box}\). Voor” background ” RoI wordt \(\mathcal{L}_\text{box}\) genegeerd door de indicatorfunctie \(\mathbb{1} \), gedefinieerd als:
\ = \begin{cases} 1 & \text{als } u \geq 1\\ 0 & \text{anders}\end{cases}\]
Het totale verlies van de functie is:
\ \mathcal{L}_\text{box}(t^u, v) \\\mathcal{L}_\text{cls}(p, u) &= -\log p_u \\\mathcal{L}_\text{box}(t^u, v) &= \sum_{i \in \{x, y, w, h\}} L_1^\text{glad} (t^u_i – v_i)\end{align*}\]
De bounding box verlies \(\mathcal{L}_{box}\) moet meten het verschil tussen \(t^u_i\) en \(v_i\) met behulp van een robuuste verlies van functie. De gladde L1 verlies wordt hier aangenomen en het wordt beweerd dat minder gevoelig voor uitschieters.
\
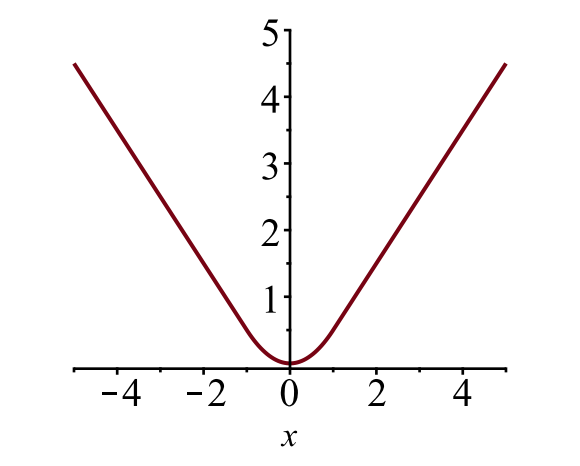
Fig. 6. De plot van glad L1 verlies, \(y = L_1^ \ text{glad} (x)\). (Afbeeldingsbron: link)
Speed Bottleneck
Fast R-CNN is veel sneller in zowel trainings-als testtijd. De verbetering is echter niet dramatisch, omdat de voorstellen voor de regio ‘ s afzonderlijk worden gegenereerd door een ander model en dat is erg duur.
sneller R-CNN
een intuïtieve speedup-oplossing is het integreren van het algoritme voor regio-voorstellen in het CNN-model. Sneller R-CNN (Ren et al., 2016) doet precies dit: construeer een enkel, uniform model dat bestaat uit RPN (region proposal network) en snelle R-CNN met gedeelde convolutionele functielagen.

Fig. 7. Een illustratie van sneller R-CNN model. (Bron afbeelding: Ren et al., 2016)
Modelworkflow
- Pre-train een CNN-netwerk voor beeldclassificatietaken.
- Fine-tunen van de RPN (region proposal network) end-to-end voor de region proposal taak, die wordt geïnitialiseerd door de pre-train image classifier. Positieve monsters hebben IoU (intersection-over-union) 0,7, terwijl negatieve monsters IoU < 0,3 hebben.
- schuif een klein N x n ruimtelijk venster over de Conv feature map van de gehele afbeelding.
- in het midden van elk schuifvenster voorspellen we meerdere regio ‘ s van verschillende schalen en verhoudingen tegelijk. Een anker is een combinatie van (schuifraam centrum, schaal, verhouding). Bijvoorbeeld 3 schalen + 3 ratio ‘s=> k = 9 ankers bij elke schuifpositie.
- Train een snel R-CNN-objectdetectiemodel met behulp van de voorstellen die door het huidige RPN
- worden gegenereerd en gebruik vervolgens het Snelle R-CNN-netwerk om RPN-training te initialiseren. Terwijl u de gedeelde convolutionele lagen behoudt, kunt u alleen de RPN-specifieke lagen fine-tunen. In dit stadium hebben RPN en het detectienetwerk convolutionele lagen gedeeld!
- tenslotte kunnen de unieke lagen van Fast R-CNN
- stap 4-5 worden herhaald om RPN en Fast R-CNN te trainen als alternatief indien nodig.
verliesfunctie
snellere R-CNN is geoptimaliseerd voor een multi-task verliesfunctie, vergelijkbaar met fast R-CNN.
| symbool | verklaring | \(p_i\) | voorspelde kans dat anker i Een object is. |
| \(p^ * _i\) | Ground truth label (binair) of anchor i Een object is. |
| \(t_i\) | voorspelde vier geparametreerde coördinaten. |
| \(t^ * _i\) | grondwaarheidscoördinaten. |
| \(N_ \ text{cls}\) | normalisatieterm, ingesteld op mini-batchgrootte (~256) in het papier. |
| \(N_ \ text{box}\) | normalisatieterm, ingesteld op het aantal ankerlocaties (~2400) in het papier. |
| \(\lambda\) | een balanceerparameter, ingesteld op ~10 in het papier (zodat zowel\(\mathcal{L}_\text{cls}\) als\(\mathcal{L}_ \ text{box}\) termen ruwweg gelijk worden gewogen). |
De multi-task loss functie combineert de verliezen van classificatie en bounding box regressie:
\
waarbij \(\mathcal{L}_\text{cls}\) de log loss functie over twee klassen is, omdat we een multi-class classificatie gemakkelijk kunnen vertalen naar een binaire classificatie door een voorbeeld te voorspellen een doel object versus niet. \(L_1^ \ text{smooth}\) is het smooth L1 verlies.
\
masker R-CNN
masker R-CNN (He et al., 2017) breidt sneller R-CNN naar pixel-niveau beeldsegmentatie. Het belangrijkste punt is om de classificatie en de pixel-niveau masker voorspelling taken te ontkoppelen. Gebaseerd op het framework van snellere R-CNN, voegde het een derde branch toe voor het voorspellen van een objectmasker parallel met de bestaande branches voor classificatie en lokalisatie. De mask branch is een klein volledig verbonden netwerk toegepast op elke RoI, het voorspellen van een segmentatiemasker in een pixel-naar-pixel manier.
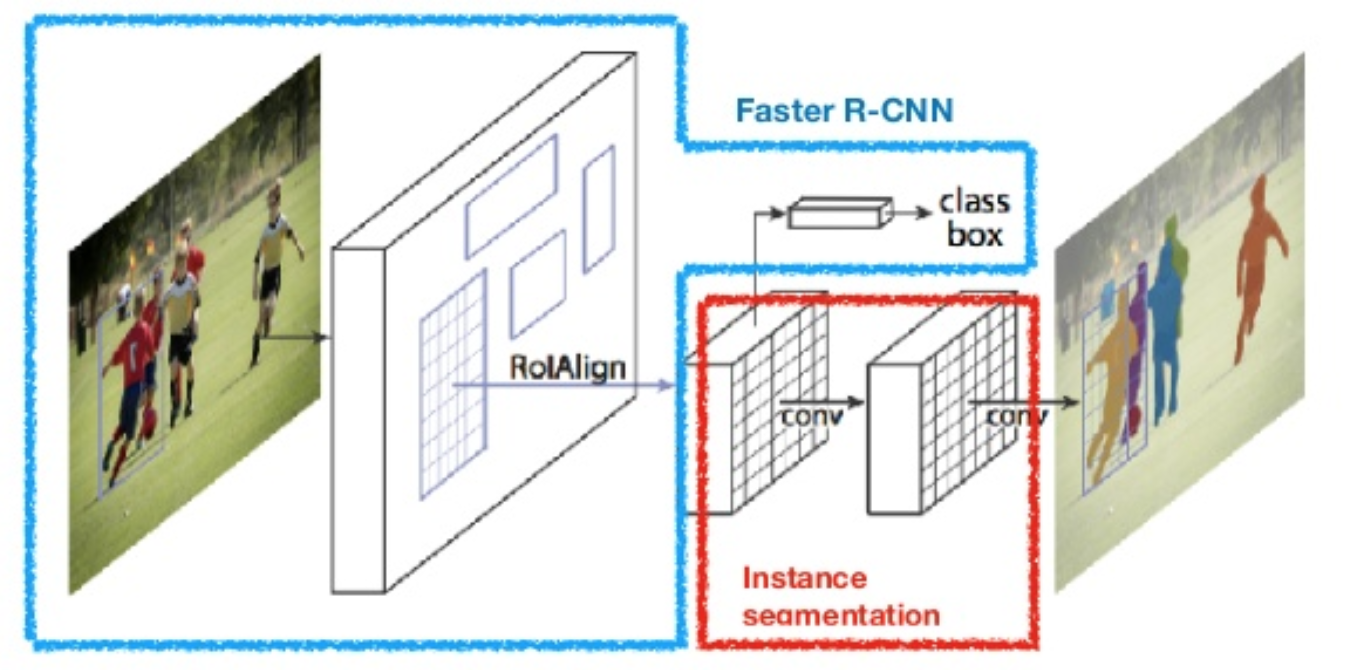
Fig. 8. Masker R-CNN is sneller R-CNN model met beeldsegmentatie. (Bron: He et al., 2017)
omdat segmentatie op pixelniveau veel meer fijnkorrelige uitlijning vereist dan bounding boxes, verbetert mask R-CNN de ROI pooling layer (genaamd “roialign layer”) zodat RoI beter en nauwkeuriger kan worden toegewezen aan de regio ‘ s van de oorspronkelijke afbeelding.

Fig. 9. Voorspellingen van Mask R-CNN op COCO test set. (Bron: He et al., 2017)
RoIAlign
De roialign laag is ontworpen om de locatie foutieve uitlijning veroorzaakt door kwantisatie in de ROI pooling te herstellen. RoIAlign verwijdert de hash kwantisatie, bijvoorbeeld door x/16 te gebruiken in plaats van , zodat de geëxtraheerde functies goed kunnen worden uitgelijnd met de invoerpixels. Bilineaire interpolatie wordt gebruikt voor het berekenen van de floating-point locatie waarden in de invoer.
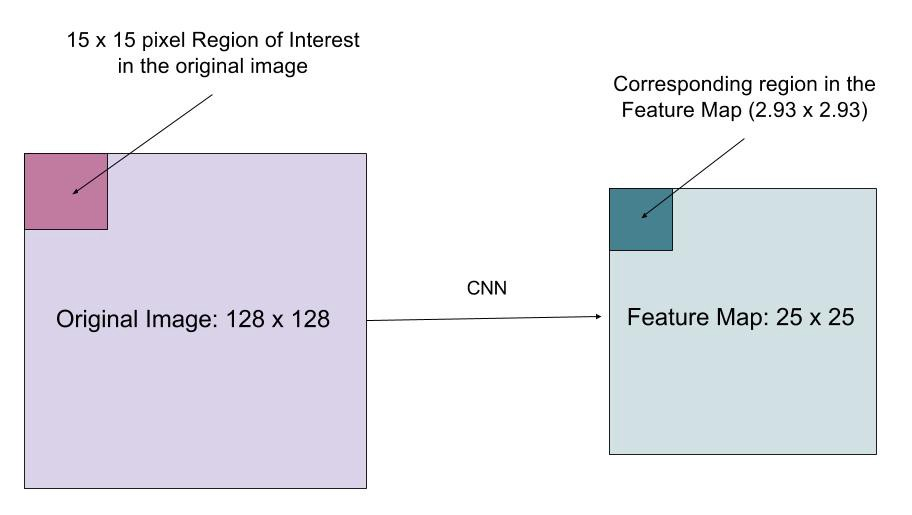
Fig. 10. Een gebied van belang wordt nauwkeurig in kaart gebracht van de oorspronkelijke afbeelding op de functie kaart zonder afronding naar gehele getallen. (Bron van de afbeelding: link)
verliesfunctie
De multi-task verliesfunctie van masker R-CNN combineert het verlies van classificatie, lokalisatie en segmentatiemasker: \(\mathcal{L} = \mathcal{L}_\text{cls} + \mathcal{L}_\text{box} + \mathcal{L}_\text{mask}\), waarbij \(\mathcal{L}_\text{cls}\) en \(\mathcal{L}_\text{box}\) zijn hetzelfde als in snellere R-CNN.
De maskertak genereert een masker van dimensie m x m voor elke RoI en elke klasse; K-klassen in totaal. De totale output is dus van grootte \(K \cdot m^2\). Omdat het model probeert om een masker te leren voor elke klas, is er geen concurrentie tussen de klassen voor het genereren van maskers.
\(\mathcal{L}_\text{mask}\) wordt gedefinieerd als het gemiddelde binaire cross-entropieverlies, alleen met inbegrip van k-het masker als het gebied geassocieerd is met de ground truth class k.
\\]
waarbij \(y_{ij}\) het label is van een cel (i, j) in het ware masker voor het gebied van grootte M x m; \(\hat{y}_{ij}^k\) is de voorspelde waarde van dezelfde cel in het masker geleerd voor de ground-truth klasse k.
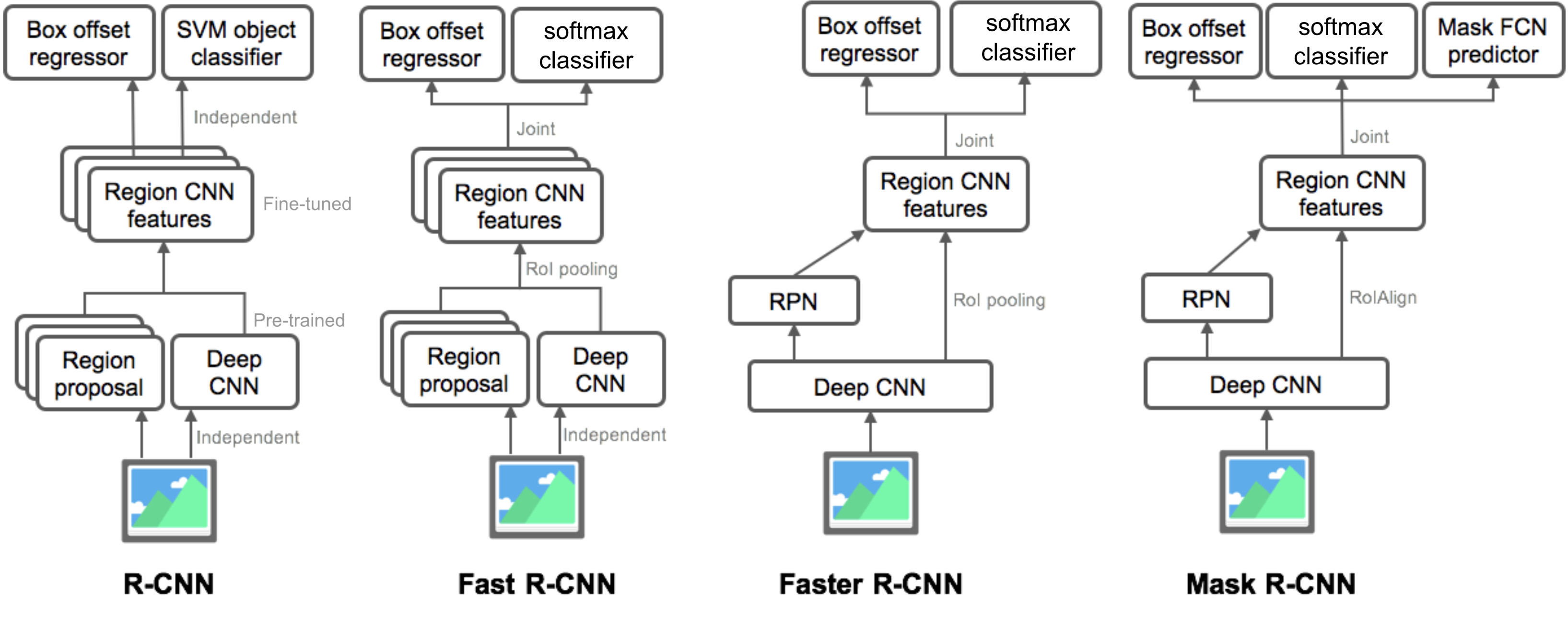
samenvatting van modellen in de R-CNN-familie
hier illustreer ik modelontwerpen van R-CNN, snel R-CNN, sneller R-CNN en masker R-CNN. U kunt volgen hoe een model evolueert naar de volgende versie door het vergelijken van de kleine verschillen.
aangehaald als:
@article{weng2017detection3, title = "Object Detection for Dummies Part 3: R-CNN Family", author = "Weng, Lilian", journal = "lilianweng.github.io/lil-log", year = "2017", url = "http://lilianweng.github.io/lil-log/2017/12/31/object-recognition-for-dummies-part-3.html"}referentie
Ross Girshick, Jeff Donahue, Trevor Darrell, en Jitendra Malik. “Rijke functie hiërarchieën voor nauwkeurige object Detectie en semantische segmentatie.”In Proc. IEEE Conf. on computer vision and pattern recognition (CVPR), PP.580-587. 2014.
Ross Girshick. “Fast R-CNN.”In Proc. IEEE Intl. Conf. over computer vision, PP. 1440-1448. 2015.Shaoqing Ren, Kaiming He, Ross Girshick en Jian Sun. “Snellere R-CNN: naar real-time object detectie met regio voorstel netwerken.”In Advances in neural information processing systems (NIPS), PP.91-99. 2015.Kaiming He, Georgia Gkioxari, Piotr Dollár en Ross Girshick. “Masker R-CNN.”arXiv preprint arXiv: 1703.06870, 2017.Joseph Redmon, Santosh Divvala, Ross Girshick en Ali Farhadi. “Je kijkt maar één keer: uniforme, real-time objectdetectie.”In Proc. IEEE Conf. on computer vision and pattern recognition (CVPR), PP.779-788. 2016.
“A Brief History of CNNs in Image Segmentation: From R-CNN to Mask R-CNN” door Athelas.
Smooth L1 Loss: https://github.com/rbgirshick/py-faster-rcnn/files/764206/SmoothL1Loss.1.pdf