Objektdetektion For Dummies Del 3: R-CNN Family
I Del 3 ville vi undersøge fire objektdetekteringsmodeller: R-CNN, hurtig R-CNN, hurtigere R-CNN og maske R-CNN. Disse modeller er meget relaterede, og de nye versioner viser stor hastighedsforbedring sammenlignet med de ældre.
i serien “Object Detection for Dummies” startede vi med grundlæggende begreber i billedbehandling, såsom gradientvektorer og HOG, i Del 1. Derefter introducerede vi klassiske indviklede neurale netværksarkitekturdesign til klassificering og pionermodeller til genkendelse af objekter, Overfeat og DPM, i Del 2. I det tredje indlæg i denne serie er vi ved at gennemgå et sæt modeller i familien R-CNN (“Regionbaseret CNN”).
Links til alle indlæg i serien: .
Her er en liste over papirer, der er omfattet af dette indlæg 😉
| Model | Goal | Resources |
| R-CNN | Object recognition | |
| Fast R-CNN | Object recognition | |
| Faster R-CNN | Object recognition | |
| Mask R-CNN | Image segmentation |
R-CNN
R-CNN (Girshick et al., 2014) is short for “Region-based Convolutional Neural Networks”. The main idea is composed of two steps. Først ved hjælp af selektiv søgning identificerer den et håndterbart antal kandidater til afgrænsningsobjektregion (“region af interesse” eller “RoI”). Og så udtrækker det CNN-funktioner fra hver region uafhængigt til klassificering.
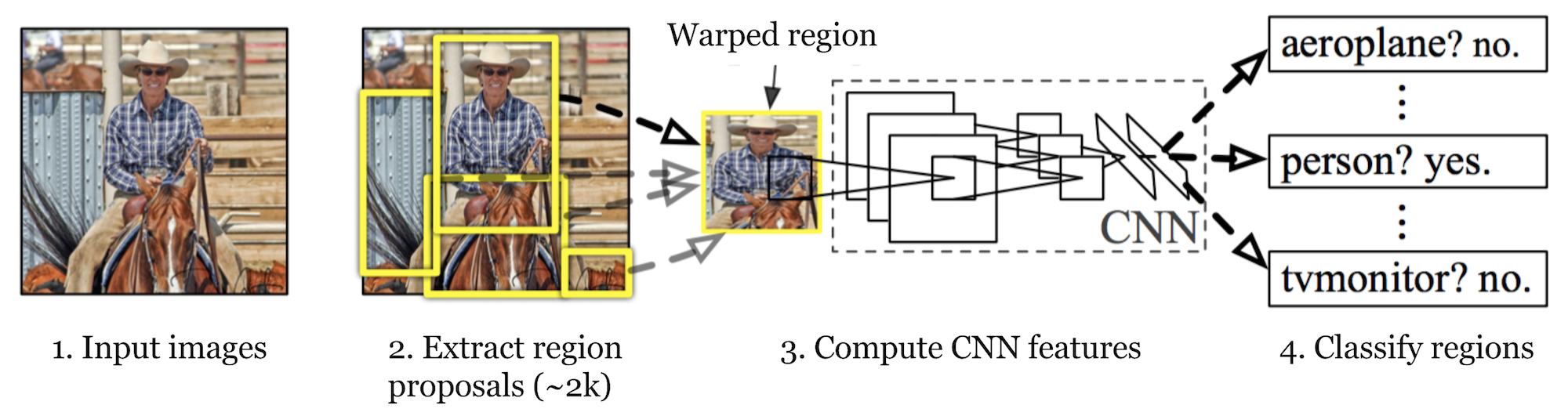
Fig. 1. Arkitekturen af R-CNN. (Billedkilde: Girshick et al., 2014)
Modelarbejdsgang
Sådan fungerer R-CNN kan opsummeres som følger:
- træn et CNN-netværk på billedklassificeringsopgaver; for eksempel VGG eller ResNet trænet i ImageNet datasæt. Klassificeringsopgaven involverer n klasser.
Bemærk: Du kan finde en præ-uddannet Aleksnet i Caffe Model Dyrepark. Jeg tror ikke, du kan finde det i Tensorstrøm, men Tensorstrøm-slim modelbibliotek giver forududdannet ResNet, VGG og andre.
- foreslå kategori-uafhængige regioner af interesse ved selektiv søgning (~2K kandidater pr billede). Disse regioner kan indeholde målobjekter, og de har forskellige størrelser.
- regionskandidater er skæv for at have en fast størrelse som krævet af CNN.
- Fortsæt finjustering af CNN på skæve forslagsregioner for K + 1-klasser; den ekstra klasse henviser til baggrunden (intet objekt af interesse). I finjusteringsfasen skal vi bruge en meget mindre læringshastighed, og mini-batch overprøver de positive sager, fordi de fleste foreslåede regioner kun er baggrund.
- i betragtning af hvert billedregion genererer en fremadrettet udbredelse gennem CNN en funktionsvektor. Denne funktionsvektor forbruges derefter af en binær SVM, der er trænet for hver klasse uafhængigt.
de positive prøver er foreslåede regioner med IOU (kryds over union) overlapningstærskel > = 0.3, og negative prøver er irrelevante andre. - for at reducere lokaliseringsfejlene trænes en regressionsmodel til at korrigere det forudsagte detektionsvindue på afgrænsningskorrektion offset ved hjælp af CNN-funktioner.
afgrænsningsboks Regression
givet en forudsagt afgrænsningsbokskoordinat \(\mathbf{p} = (p_h, p_y, p_h, p_h)\) (centerkoordinat, bredde, højde) og dens tilsvarende jord sandhedsbokskoordinater \(\mathbf{g} = (g_h, g_y, g_h, g_h)\) , er regressoren konfigureret til at lære skala-invariant transformation mellem to centre og log-skala transformation mellem bredder og højder. Alle transformationsfunktionerne tager \(\mathbf{p}\) som input.
\
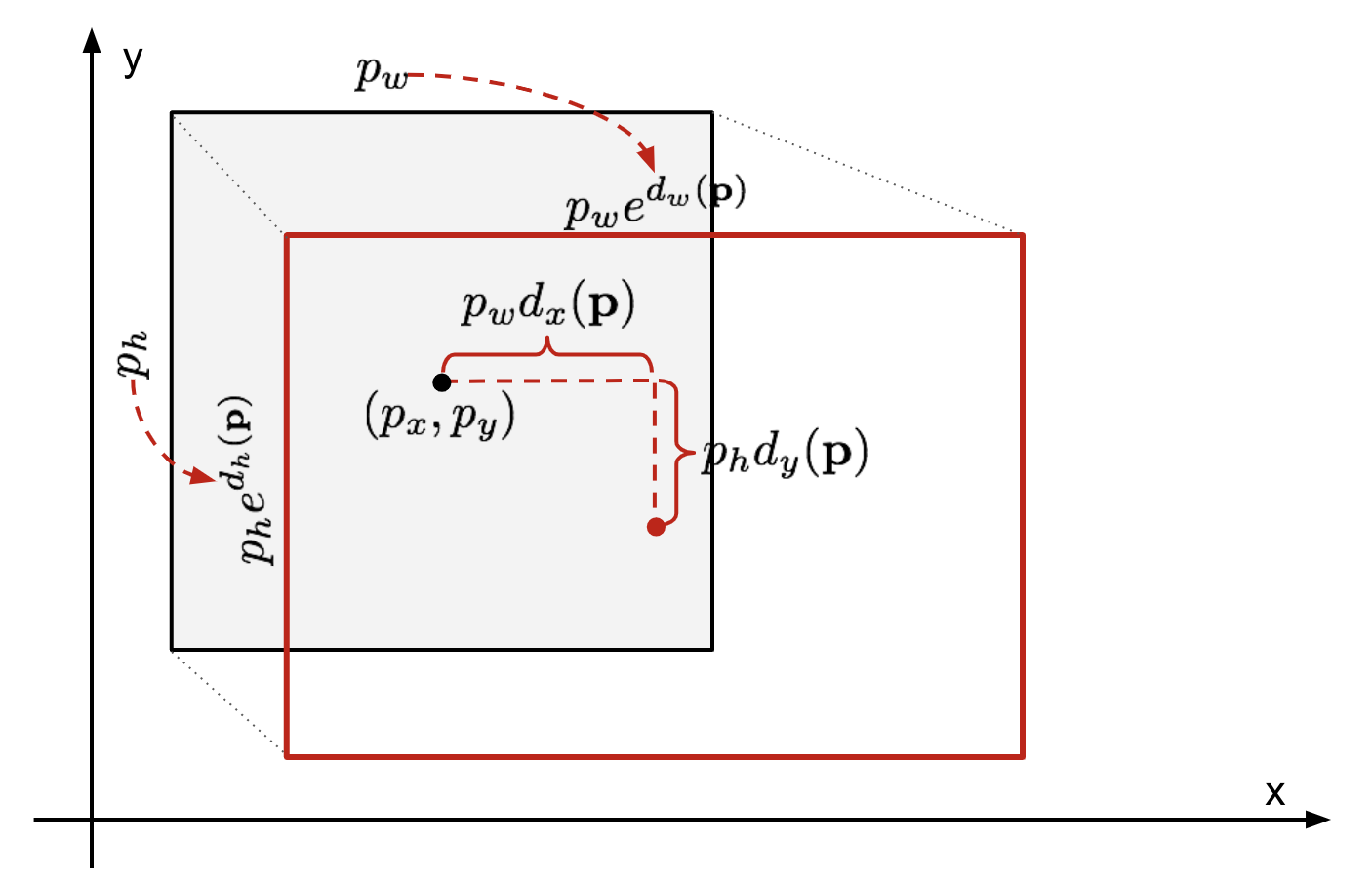
Fig. 2. Illustration af transformation mellem forudsagte og jorden sandhed afgrænsende kasser.
en indlysende fordel ved at anvende en sådan transformation er, at alle afgrænsningsboksens korrektionsfunktioner, \(d_i(\mathbf{p})\) hvor \(jeg \i \{ H, y, H, H\}\), kan tage enhver værdi mellem . Målene for dem at lære er:
\
en standard regressionsmodel kan løse problemet ved at minimere SSE-tabet med regulering:
\
regulariseringsudtrykket er kritisk her, og rcnn-papir valgte den bedste pri ved krydsvalidering. Det er også bemærkelsesværdigt, at ikke alle de forudsagte afgrænsningskasser har tilsvarende sandhedskasser. For eksempel, hvis der ikke er nogen overlapning, giver det ikke mening at køre bboks regression. Her opbevares kun en forudsagt kasse med en nærliggende sandhedskasse med mindst 0,6 IoU til træning af bkasse-regressionsmodellen.
almindelige Tricks
flere tricks bruges ofte i rcnn og andre detektionsmodeller.
ikke-Maksimal undertrykkelse
sandsynligvis er modellen i stand til at finde flere afgrænsningsbokse til det samme objekt. Ikke-maksimal undertrykkelse hjælper med at undgå gentagen detektion af den samme forekomst. Når vi får et sæt matchede afgrænsningsbokse til den samme objektkategori:Sorter alle afgrænsningsbokse efter tillidsscore.Kasser kasser med lav tillid score.Mens der er nogen resterende afgrænsningsfelt, gentag følgende:Vælg grådigt den med den højeste score.Spring over de resterende kasser med høj IoU (dvs. > 0.5) med tidligere valgt en.

Fig. 3. Flere afgrænsningsbokse registrerer bilen i billedet. Efter ikke-maksimal undertrykkelse forbliver kun det bedste, og resten ignoreres, da de har store overlapninger med den valgte. (Billedkilde: DPM-papir)
Hård negativ minedrift
vi betragter afgrænsningsbokse uden objekter som negative eksempler. Ikke alle de negative eksempler er lige så vanskelige at identificere. For eksempel, hvis den har ren tom baggrund, er det sandsynligvis et “let negativt”; men hvis kassen indeholder underlig støjende struktur eller delvis genstand, kan det være svært at blive genkendt, og disse er “hårde negative”.
de hårde negative eksempler klassificeres let forkert. Vi kan eksplicit finde disse falske positive prøver under træningssløjferne og inkludere dem i træningsdataene for at forbedre klassificeringen.
Hastighedsflaskehals
Når du ser gennem R-CNN-læringstrinnene, kan du nemt finde ud af, at træning af en R-CNN-model er dyr og langsom, da følgende trin involverer en masse arbejde:
- kører selektiv søgning for at foreslå 2000 regionskandidater til hvert billede;
- generering af CNN-funktionsvektoren for hvert billedregion (N billeder * 2000).
- hele processen involverer tre modeller separat uden meget delt beregning: det indviklede neurale netværk til billedklassificering og funktionsekstraktion; den øverste SVM-klassifikator til identifikation af målobjekter; og regressionsmodellen til stramning af afgrænsningsbokse i regionen.
Fast R-CNN
for at gøre R-CNN hurtigere forbedrede Girshick (2015) træningsproceduren ved at forene tre uafhængige modeller i en fælles trænet ramme og øge delte beregningsresultater, der hedder Fast R-CNN. I stedet for at udtrække CNN-funktionsvektorer uafhængigt for hvert regionforslag, aggregerer denne model dem i en CNN fremad passere over hele billedet, og regionforslagene deler denne funktionsmatrice. Derefter forgrenes den samme funktionsmatrice til at blive brugt til at lære objektklassifikatoren og afgrænsningsregressoren. Afslutningsvis fremskynder beregningsdeling r-CNN.
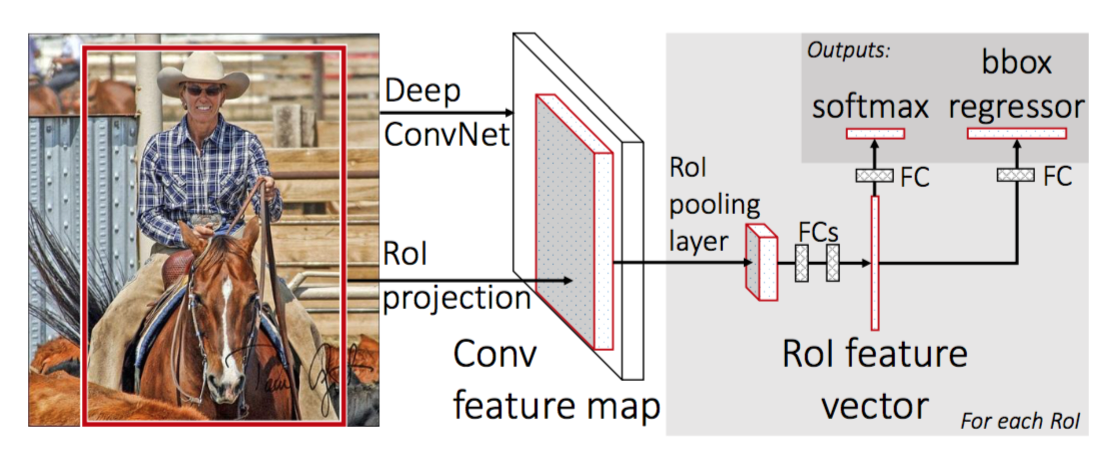
Fig. 4. Arkitekturen i Fast R-CNN. (Billede kilde: Girshick, 2015)
RoI Pooling
det er en type maks pooling til at konvertere funktioner i det projicerede område af billedet af enhver størrelse, hhv, til et lille fast vindue, hhv.
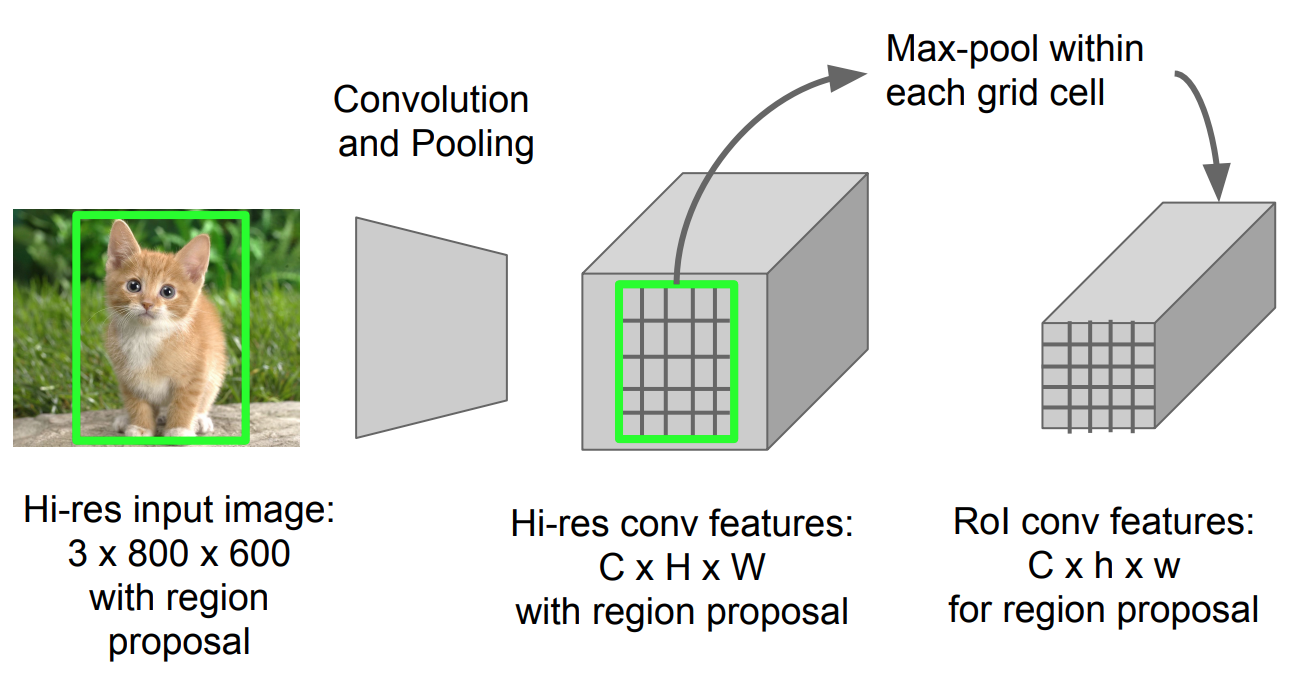
Fig. 5. RoI pooling (Billedkilde: Stanford CS231n dias.)
Modelarbejdsgang
hvor hurtigt r-CNN fungerer opsummeres som følger; mange trin er de samme som i R-CNN:
- først skal du træne et indviklet neuralt netværk på billedklassificeringsopgaver.
- foreslå regioner ved selektiv søgning (~2K kandidater pr billede).
- skift det forududdannede CNN:
- udskift det sidste maks.poolinglag af det forududdannede CNN med et RoI-poolinglag. RoI-poolinglaget udsender faste længdevektorer af regionforslag. Deling af CNN-beregningen giver meget mening, da mange regionforslag af de samme billeder er stærkt overlappede.
- udskift det sidste fuldt tilsluttede lag og det sidste softmaks-lag (k-klasser) med et fuldt tilsluttet lag og softmaks over K + 1-klasser.
- endelig forgrener modellen sig i to outputlag:
- en softmaks estimator af K + 1 klasser (samme som i R-CNN, +1 er klassen “baggrund”), der udsender en diskret sandsynlighedsfordeling pr.
- en regressionsmodel med afgrænsningsboks, der forudsiger forskydninger i forhold til den oprindelige RoI for hver af K-klasser.
tabsfunktion
modellen er optimeret til et tab, der kombinerer to opgaver (klassificering + lokalisering):
| Symbol | forklaring |
| \(u\) | true Class label, \(u \i 0, 1, \dots, k\); efter konvention har catch-all baggrundsklassen \(U = 0\). |
| \(p\) | diskret sandsynlighedsfordeling (per RoI) over K + 1 klasser: \(p = (p_0, \dots, p_K)\), beregnet af en softmaks over K + 1 udgange af et fuldt forbundet lag. |
| \(v\) | sand afgrænsningsboks \(v = (v_h, v_y, v_v, v_h)\). |
| \(t^u\) | forudsagt korrektion af afgrænsningsboksen, \(t^u = (t^u_h, t^u_y, t^u_h, t^u_h)\). Se ovenfor. |
tabsfunktionen opsummerer omkostningerne ved klassificering og afgrænsning af boks forudsigelse: \(\mathcal{L} = \mathcal{L}_\tekst{cls} + \mathcal{L}_\tekst{boks}\). For” baggrund ” RoI, \(\mathcal{L}_\tekst{boks}\) ignoreres af indikatorfunktionen \(\mathbb{1} \), defineret som:
\ = \begin{cases} 1 & \tekst{hvis } u \Gk 1\\ 0 & \tekst{ellers}\end{cases}\]
den samlede tabsfunktion er:
\ \mathcal{L}_\tekst{boks}(t^u, v) \\\mathcal{L}_\tekst{cls}(p, u) &= -\log p_u \\\mathcal{l}_\tekst{boks}(t^u, v) &= \sum_{i \In \{h, y, v, h\}} L_1^\tekst{glat} (t^u_i – v_i)\end{juster*}\]
afgrænsningen boks tab \(\mathcal{l}_{boks}\) skal måle forskellen mellem \(T^u_i\) og \(v_i\) ved hjælp af en robust tabsfunktion. Det glatte L1-tab vedtages her, og det hævdes at være mindre følsomt over for outliers.
\
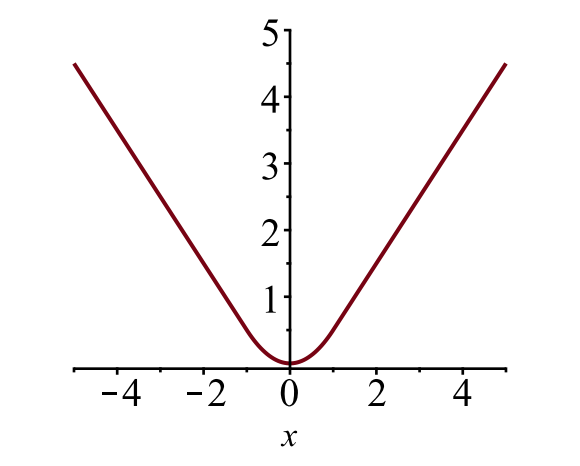
Fig. 6. Plottet af glat L1 tab, \(y = L_1^ \ tekst{glat} (h)\). (Billedkilde: link)
Hastighedsflaskehals
hurtig R-CNN er meget hurtigere i både træning og testtid. Forbedringen er imidlertid ikke dramatisk, fordi regionforslagene genereres separat af en anden model, og det er meget dyrt.
hurtigere R-CNN
en intuitiv speedup-løsning er at integrere regionforslagsalgoritmen i CNN-modellen. Hurtigere R-CNN (Ren et al., 2016) gør netop dette: konstruere en enkelt, samlet model sammensat af RPN (region forslag netværk) og hurtig R-CNN med delte convolutional feature lag.

Fig. 7. En illustration af hurtigere r-CNN model. (Billedkilde: Ren et al., 2016)
Model arbejdsgang
- præ-træne et CNN-netværk på billedklassificeringsopgaver.
- finjustere RPN (region forslag netværk) end-to-end for region forslag opgave, som initialiseres af pre-train billede klassifikator. Positive prøver har IOU (kryds-over-union) > 0.7, mens negative prøver har IOU < 0.3.
- Skub et lille rumligt vindue over conv – funktionskortet over hele billedet.
- i midten af hvert glidende vindue forudsiger vi flere regioner med forskellige skalaer og forhold samtidigt. Et anker er en kombination af (glidende vinduescenter, skala, forhold). For eksempel 3 skalaer + 3 forhold => k=9 ankre ved hver glideposition.
- træn en hurtig r-CNN-objektdetekteringsmodel ved hjælp af forslagene genereret af den aktuelle RPN
- brug derefter det hurtige r-CNN-netværk til at initialisere RPN-træning. Mens du holder de delte konvolutlag, skal du kun finjustere de RPN-specifikke lag. På dette tidspunkt har RPN og detektionsnetværket delt konvolutlag!
- Finjuster endelig de unikke lag af Fast R-CNN
- trin 4-5 kan gentages for at træne RPN og Fast R-CNN alternativt, hvis det er nødvendigt.
tabsfunktion
hurtigere R-CNN er optimeret til en multi-task-tabsfunktion, der ligner hurtig R-CNN.
| Symbol | forklaring |
| \(p_i\) | forudsagt Sandsynlighed for, at anker er et objekt. |
| \(p^*_i\) | Ground truth label (Binær) af, om Anker i er et objekt. |
| \(t_i\) | forudsagde fire parameteriserede koordinater. |
| \(t^*_i\) | jord sandhed koordinater. |
| \(n_\tekst{cls}\) | Normaliseringsudtryk, indstillet til at være mini-batchstørrelse (~256) i papiret. |
| \(n_\tekst{boks}\) | Normaliseringsudtryk, indstillet til antallet af ankerplaceringer (~2400) i papiret. |
| \(\lambda\) | en balanceringsparameter, der er indstillet til at være ~10 i papiret (således at både \(\mathcal{L}_\tekst{cls}\) og \(\mathcal{L}_\tekst{boks}\) termer er omtrent lige vægtede). |
multi-task loss-funktionen kombinerer tabene ved klassificering og afgrænsningsregression:
\
hvor \(\mathcal{L}_\tekst{cls}\) er logtabsfunktionen over to klasser, da vi let kan oversætte en klassificering i flere klasser til en binær klassificering ved hjælp af forudsigelse af, at en prøve er et målobjekt versus ikke. \(L_1^ \ tekst{glat}\) er det glatte L1-tab.
\
maske R-CNN
maske R-CNN (He et al., 2017) udvider hurtigere r-CNN til billedsegmentering på billedniveau. Det centrale punkt er at afkoble klassificerings-og forudsigelsesopgaverne på billedniveau. Baseret på rammen af hurtigere R-CNN tilføjede den en tredje gren til forudsigelse af en objektmaske parallelt med de eksisterende grene til klassificering og lokalisering. Maskegrenen er et lille fuldt tilsluttet netværk, der anvendes til hver RoI, og forudsiger en segmenteringsmaske på en punkt-til-punkt-måde.
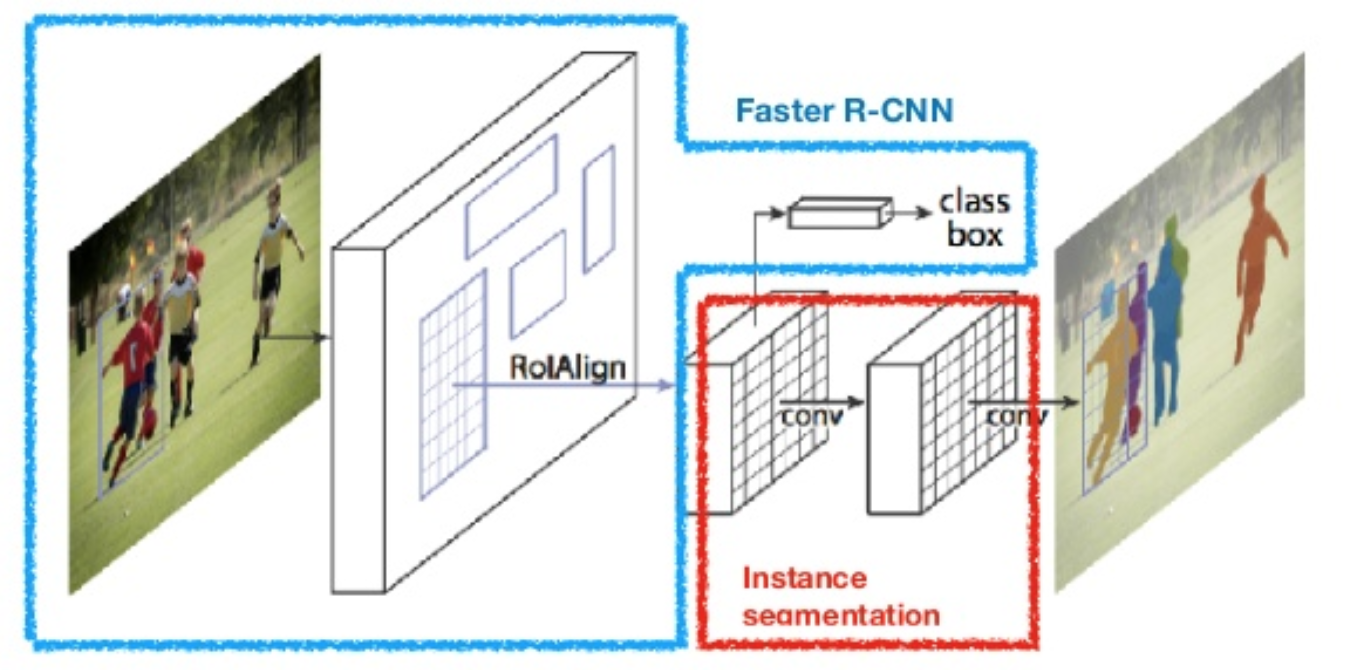
Fig. 8. Maske R-CNN er hurtigere R-CNN model med billede segmentering. (Billedkilde: han et al., 2017)
da segmentering på billedniveau kræver meget mere finkornet justering end afgrænsningsbokse, forbedrer mask R-CNN RoI-poolinglaget (kaldet “Roilign layer”), så RoI kan kortlægges bedre og mere præcist til regionerne i det originale billede.

Fig. 9. Forudsigelser af maske R-CNN på COCO test sæt. (Billedkilde: han et al., 2017)
Roilign
Roilign-laget er designet til at rette placeringsforskydningen forårsaget af kvantisering i RoI-poolingen. Ved at bruge 16 i stedet for, så de ekstraherede funktioner kan justeres korrekt med inputbillederne. Bilinear interpolation bruges til beregning af flydende punkts placeringsværdier i input.
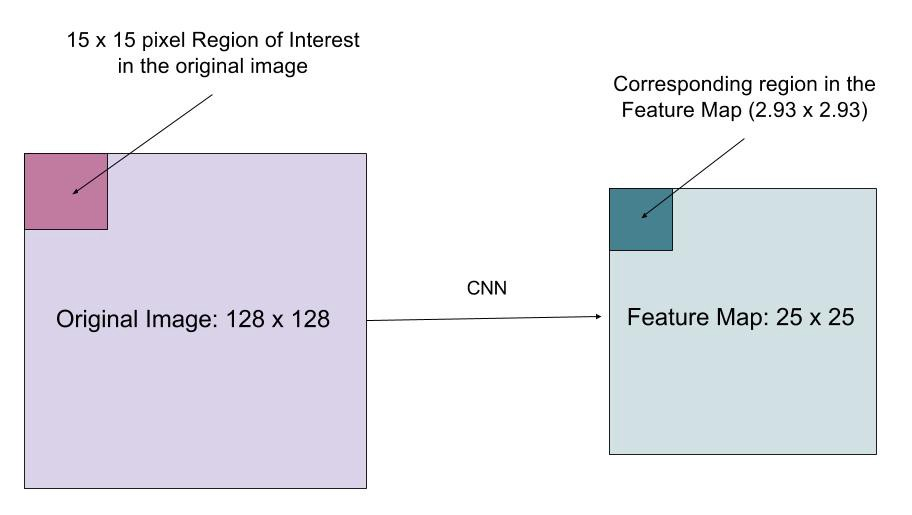
Fig. 10. En region af interesse kortlægges nøjagtigt fra det originale billede på funktionskortet uden at afrunde op til heltal. (Billede kilde: link)
tabsfunktion
multi-task-tabsfunktionen for Mask R-CNN kombinerer tabet af klassificering, lokalisering og segmenteringsmaske: \(\mathcal{L} = \mathcal{l}_\tekst{cls} + \mathcal{l}_\tekst{boks} + \mathcal{l}_\tekst{mask}\), hvor \(\mathcal{L}_\tekst{cls}\) og \(\mathcal{L}_\tekst{boks}\) er de samme som i hurtigere r-CNN.
maskegrenen genererer en maske med dimension m m for hver RoI og hver klasse; K klasser i alt. Således er den samlede produktion af størrelse \(K \ cdot m^2\). Fordi modellen forsøger at lære en maske for hver klasse, er der ingen konkurrence mellem klasser for at generere masker.
\(\mathcal{L}_\tekst{mask}\) er defineret som det gennemsnitlige binære tab på tværs af entropi, kun inklusive k-th-maske, hvis regionen er knyttet til jorden sandhedsklasse k.
\\]
hvor \(y_{IJ}\) er etiketten på en celle (i, j) i den sande maske for området med størrelse m m; \(\hat{y}_{ij}^k\) er den forudsagte værdi af den samme celle i masken lært for jorden-sandhedsklasse k.
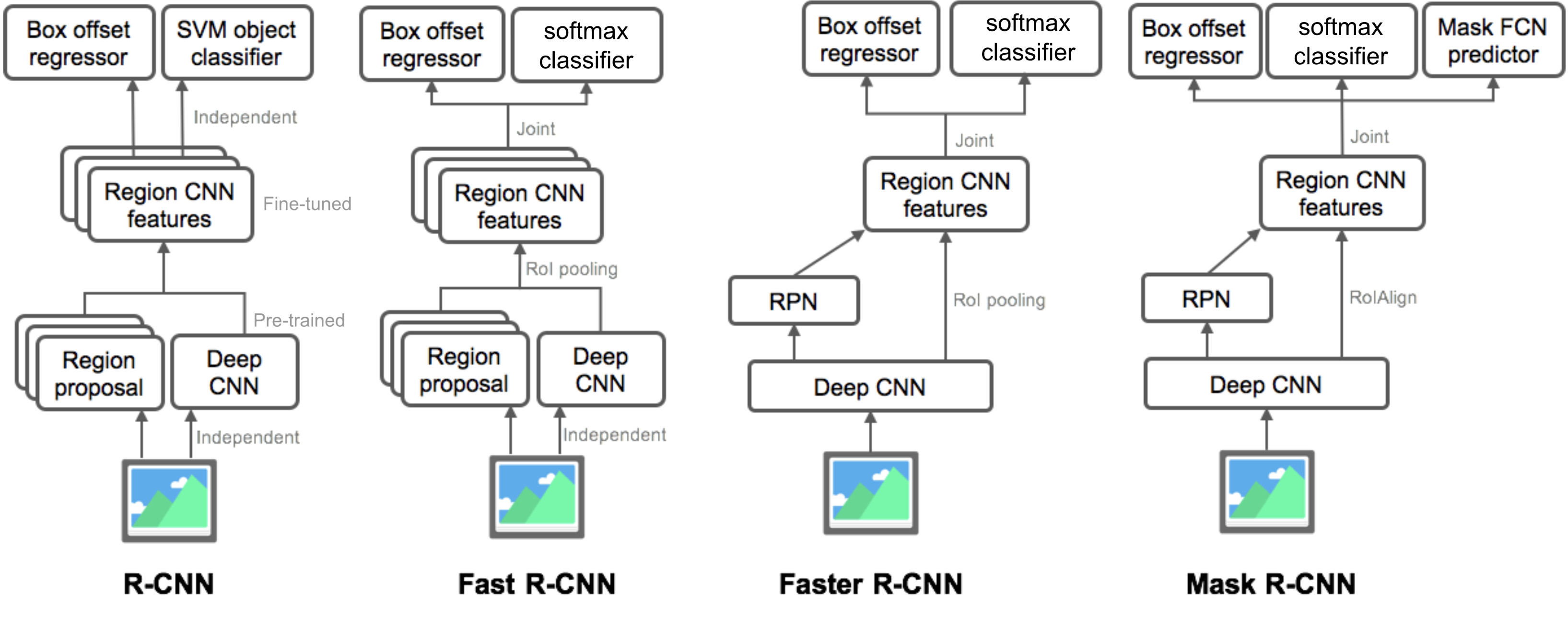
oversigt over modeller i R-CNN-familien
her illustrerer jeg modeldesign af R-CNN, Fast R-CNN, Faster R-CNN og Mask r-CNN. Du kan spore, hvordan en model udvikler sig til den næste version ved at sammenligne de små forskelle.
Citeret som:
@article{weng2017detection3, title = "Object Detection for Dummies Part 3: R-CNN Family", author = "Weng, Lilian", journal = "lilianweng.github.io/lil-log", year = "2017", url = "http://lilianweng.github.io/lil-log/2017/12/31/object-recognition-for-dummies-part-3.html"}Reference
Ross Girshick, Jeff Donahue, Trevor Darrell og Jitendra Malik. “Rige funktionshierarkier til nøjagtig objektdetektering og semantisk segmentering.”I Proc. IEEE Conf. om computersyn og mønstergenkendelse (CVPR), s.580-587. 2014.
Ross Girshick. “Hurtig R-CNN.”I Proc. IEEE Intl. Conf. på computersyn, s.1440-1448. 2015.Jian Sun, Kaiming he, Ross Girshick og Jian Sun. “Hurtigere R-CNN: mod realtids objektdetektering med regionforslagsnetværk.”I fremskridt inden for neurale informationsbehandlingssystemer (NIPS), s.91-99. 2015.Kaiming He, Georgia Gkioksari, Piotr Doll larr og Ross Girshick. “Maske R-CNN.”kronprint kronprint:1703.06870, 2017.Joseph Redmon, Santosh Divvala, Ross Girshick og Ali Farhadi. “Du ser kun en gang ud: samlet objektregistrering i realtid.”I Proc. IEEE Conf. om computersyn og mønstergenkendelse (CVPR), s.779-788. 2016.
“en kort historie om CNNs i Billedsegmentering: fra R-CNN til maske R-CNN” af Athelas.
glat L1 tab: https://github.com/rbgirshick/py-faster-rcnn/files/764206/SmoothL1Loss.1.pdf