Objekt Deteksjon For Dummies Del 3 :R-CNN Familie
I Del 3, ville vi undersøke fire objekt deteksjon modeller: R-CNN, Rask R-CNN, Raskere R-CNN, Og Maske R-CNN. Disse modellene er svært relatert og de nye versjonene viser stor hastighet forbedring i forhold til de eldre.
i serien «Object Detection For Dummies», vi startet med grunnleggende begreper i bildebehandling, for eksempel gradient vektorer og HOG, I Del 1. Deretter introduserte vi klassiske convolutional neural network architecture design for klassifisering og pionermodeller for objektgjenkjenning, Overfeat og DPM, I Del 2. I det tredje innlegget i denne serien skal vi gjennomgå et sett med modeller i FAMILIEN R-CNN («Regionbasert CNN»).
Lenker til alle innleggene i serien: .
Her er en liste over papirer dekket i dette innlegget 😉
| Model | Goal | Resources |
| R-CNN | Object recognition | |
| Fast R-CNN | Object recognition | |
| Faster R-CNN | Object recognition | |
| Mask R-CNN | Image segmentation |
R-CNN
R-CNN (Girshick et al., 2014) is short for «Region-based Convolutional Neural Networks». The main idea is composed of two steps. Først, ved hjelp av selektivt søk, identifiserer det et håndterbart antall grenseboksobjektområdekandidater («interesseområde» eller «RoI»). OG så trekker DET UT cnn-funksjoner fra hver region uavhengig av klassifisering.
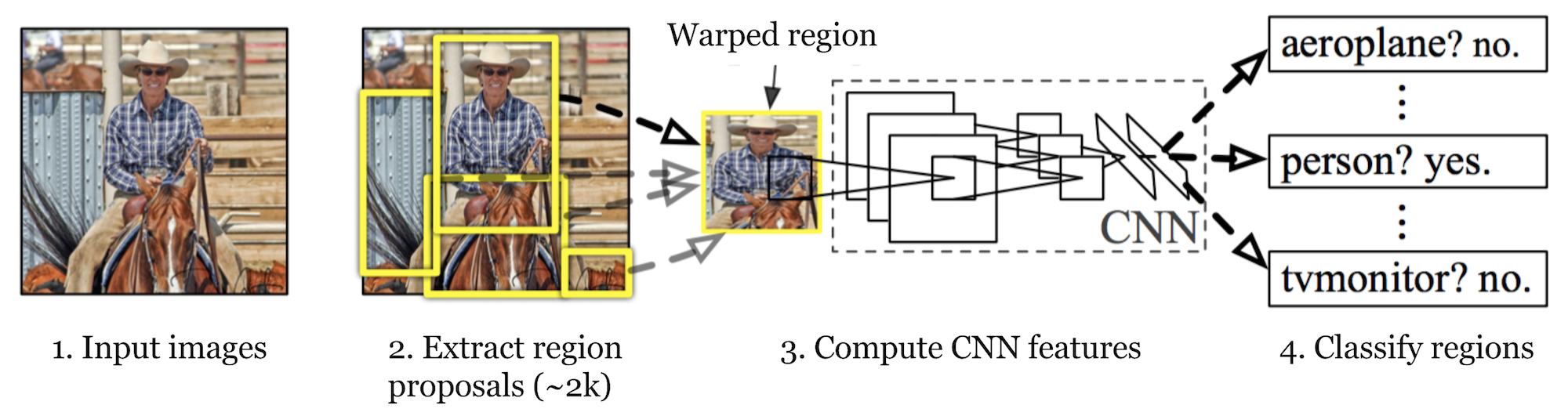
Fig. 1. Arkitekturen TIL R-CNN. (Kilde: Girshick et al., 2014)
Modell Arbeidsflyt
HVORDAN R-cnn fungerer kan oppsummeres som følger:
- pre-trene EN CNN nettverk på bilde klassifisering oppgaver; FOR EKSEMPEL vgg Eller ResNet trent På ImageNet datasett. Klassifiseringsoppgaven innebærer N-klasser.
MERK: Du kan finne en pre-trent AlexNet I Caffe Modell Zoo. Jeg tror ikke du kan finne Den I Tensorflow, Men Tensorflow-slim model library gir pre-trent ResNet, VGG og andre.
- Foreslå kategori-uavhengige regioner av interesse ved selektiv søk (~2k kandidater per bilde). Disse områdene kan inneholde målobjekter og de er av forskjellige størrelser.
- Region kandidater er vridd til å ha en fast størrelse som kreves AV CNN.
- Fortsett å finjustere CNN på forvrengte forslag regioner For K + 1 klasser; den ekstra en klasse refererer til bakgrunnen (ingen objekt av interesse). I finjusteringsfasen bør vi bruke en mye mindre læringsrate, og mini-batchen oversampler de positive tilfellene fordi de fleste foreslåtte regioner bare er bakgrunn.
- Gitt hvert bildeområde, genererer en fremoverutbredelse gjennom CNN en funksjonsvektor. Denne funksjonsvektoren forbrukes deretter av en binær SVM trent for hver klasse uavhengig.
de positive prøvene er foreslått regioner med IoU (kryss over union) overlapping terskel > = 0,3, og negative prøver er irrelevante andre. - for å redusere lokaliseringsfeil, er en regresjonsmodell opplært til å korrigere spådd deteksjon vinduet på markeringsrammen korreksjon offset ved HJELP AV CNN funksjoner.
Markeringsboksregresjon
gitt en spådd markeringsbokskoordinat \(\mathbf{p} = (p_x, p_y, p_w, p_h)\) (senterkoordinat, bredde, høyde) og tilhørende bakkekoordinater \(\mathbf{g} = (g_x, g_y, g_w, g_h)\) , er regressoren konfigurert til å lære skala-invariant transformasjon mellom to sentre og log-skala transformasjon mellom bredder og høyder. Alle transformasjonsfunksjonene tar \(\mathbf{p}\) som input.
\
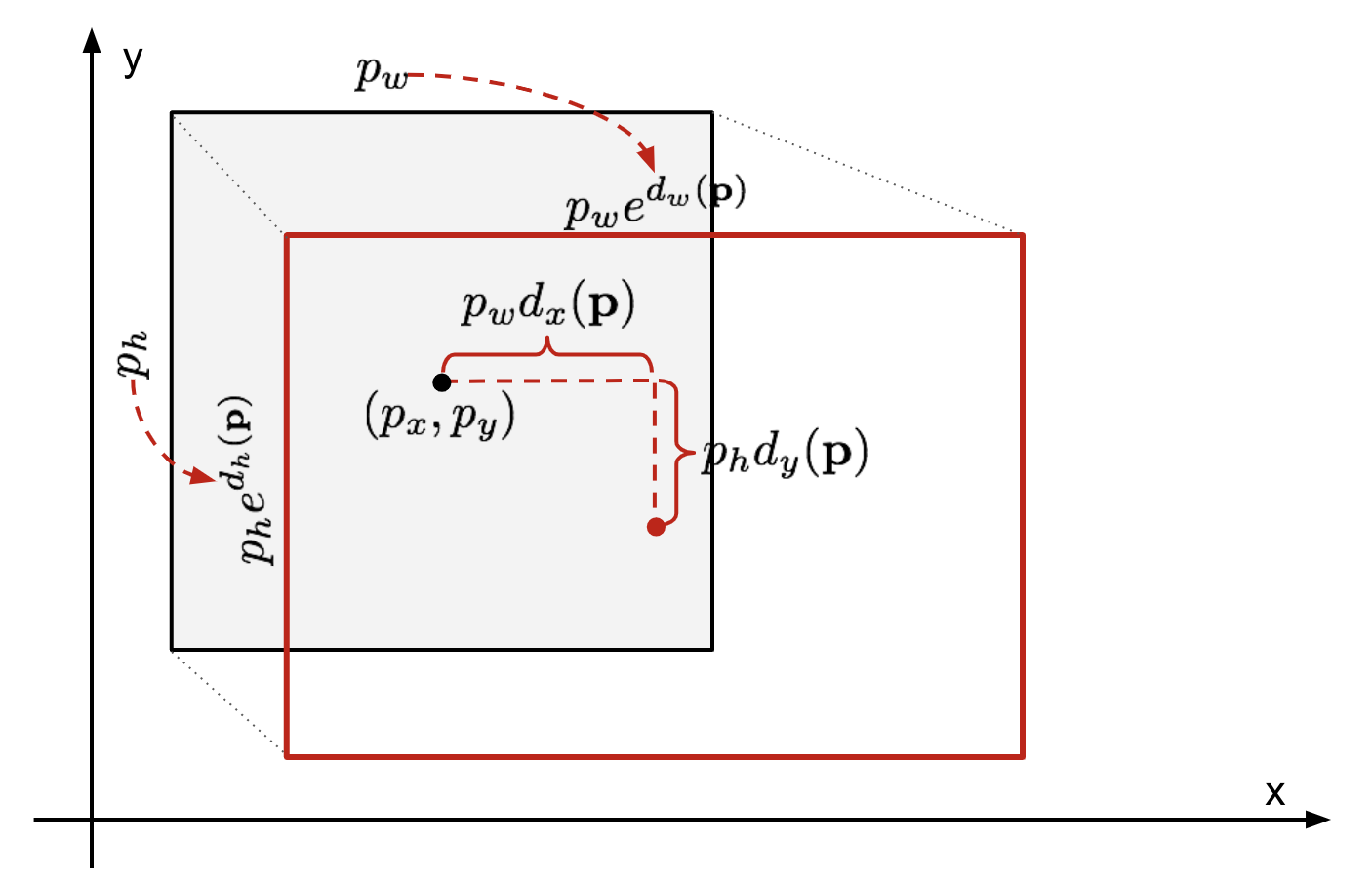
Fig. 2. Illustrasjon av transformasjon mellom spådd og bakken sannhetsbegrensende bokser.en åpenbar fordel ved å anvende en slik transformasjon er at alle grensebokskorrigeringsfunksjonene, \(d_i (\mathbf{p})\) hvor \ (i \ i \ { x, y, w, h\}\), kan ta noen verdi mellom . Målene for dem å lære er:
\
en standard regresjonsmodell kan løse problemet ved å minimere SSE-tapet med regularisering:
\
regulariseringsbegrepet er kritisk her og RCNN-papiret plukket den beste λ ved kryssvalidering. Det er også bemerkelsesverdig at ikke alle de forutsagte grenseboksene har tilsvarende bakken sannhetsbokser. For eksempel, hvis det ikke er overlapping, er det ikke fornuftig å kjøre bbox-regresjon. Her holdes bare en spådd boks med en nærliggende ground truth box med minst 0.6 IoU for å trene bbox regresjonsmodellen.
Vanlige Triks
Flere triks brukes ofte I RCNN og andre deteksjonsmodeller.
Ikke-Maksimal Undertrykkelse
Sannsynligvis er modellen i stand til å finne flere grensebokser for samme objekt. Ikke-maks undertrykkelse bidrar til å unngå gjentatt påvisning av samme forekomst. Etter at vi får et sett med matchede markeringsbokser for samme objektkategori:Sorter alle markeringsboksene etter konfidenspoeng.Kast bokser med lav tillit score.Mens det er noen gjenværende markeringsrammen, gjenta følgende: Grådig velge den med høyest poengsum.Hopp over de resterende boksene med høy IoU (dvs. > 0.5) med tidligere valgt en.

Fig. 3. Flere grensebokser oppdager bilen i bildet. Etter ikke-maksimal undertrykkelse blir bare de beste igjen og resten ignorert da de har store overlapper med den valgte. (Bildekilde: DPM papir)
Hard Negativ Mining
vi anser grensebokser uten objekter som negative eksempler. Ikke alle de negative eksemplene er like vanskelig å identifisere. For eksempel, hvis den har ren tom bakgrunn, er det sannsynligvis en «lett negativ»; men hvis boksen inneholder merkelig støyende tekstur eller delvis objekt, kan det være vanskelig å bli gjenkjent og disse er «harde negative».
de harde negative eksemplene er lett feilklassifisert. Vi kan eksplisitt finne de falske positive prøvene under treningsløkkene og inkludere dem i treningsdataene for å forbedre klassifikatoren.
Speed Bottleneck
Ser du GJENNOM r-CNN læringstrinnene, kan du lett finne ut at trening AV EN R-CNN-modell er dyr og langsom, da følgende trinn innebærer mye arbeid:
- Kjører selektivt søk for å foreslå 2000 regionkandidater for hvert bilde;
- Genererer cnn-funksjonsvektoren for hvert bildeområde (n bilder * 2000).hele prosessen involverer tre modeller separat uten mye delt beregning: det innviklede nevrale nettverket for bildeklassifisering og funksjonsutvinning; den øverste SVM-klassifikatoren for å identifisere målobjekter; og regresjonsmodellen for å stramme regionbegrenser.
Fast R-CNN
For å gjøre R-CNN raskere, Forbedret Girshick (2015) treningsprosedyren ved å forene tre uavhengige modeller i ett felles trent rammeverk og øke delte beregningsresultater, Kalt Fast R-CNN. I stedet for å trekke ut cnn-funksjonsvektorer uavhengig for hvert regionforslag, samler denne modellen dem inn i EN CNN forward pass over hele bildet, og regionforslagene deler denne funksjonsmatrisen. Da er den samme funksjonsmatrisen forgrenet for å bli brukt til å lære objektklassifiseringen og markeringsboksen regressoren. I konklusjonen, beregning deling hastigheter OPP R-CNN.
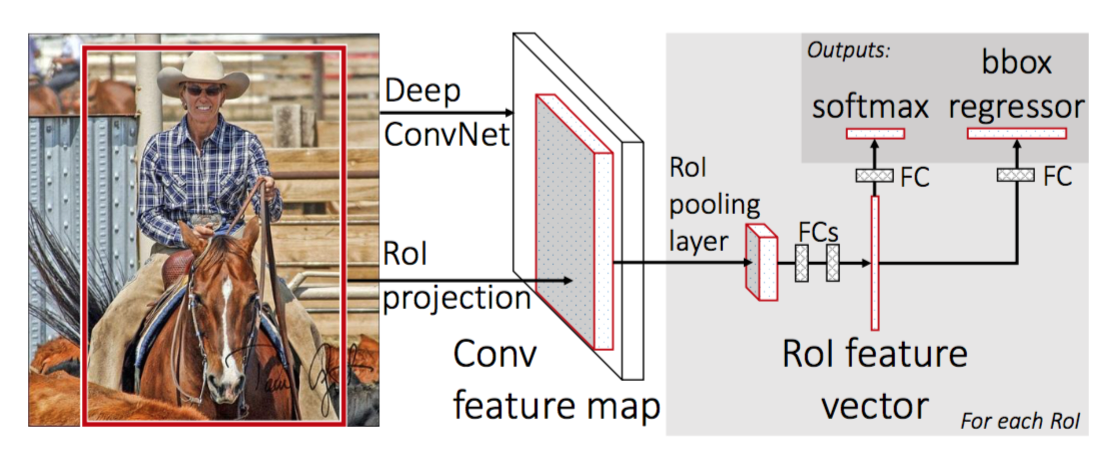
Fig. 4. Arkitekturen Av Fast R-CNN. (Bildekilde: Girshick, 2015)
RoI Pooling
det er en type max pooling for å konvertere funksjoner i det projiserte området av bildet av enhver størrelse, h x w, til et lite fast vindu, h X W. inngangsregionen er delt inn I h X W-rutenett, omtrent hver undervindu av størrelse h / H x w / W. bruk deretter max-pooling i hvert rutenett.
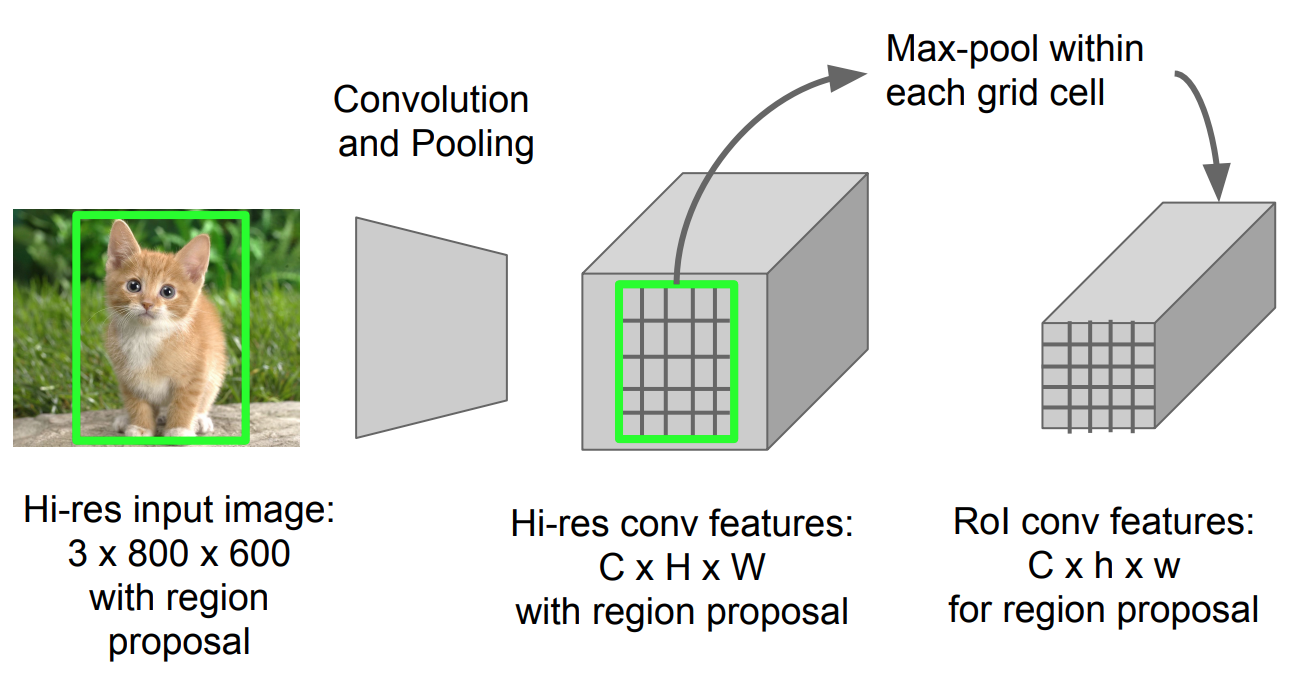
Fig. 5. RoI pooling (Bildekilde: Stanford CS231n lysbilder.)
Modell Arbeidsflyt
Hvor Fort R-CNN fungerer er oppsummert som følger; mange trinn er samme SOM I R-CNN:
- først, pre-tog en convolutional nevrale nettverk på bilde klassifisering oppgaver.
- Foreslå regioner ved selektiv søk (~2k kandidater per bilde).
- Endre pre-trent CNN:
- Erstatte den siste max pooling lag av pre-trent CNN Med En RoI pooling lag. RoI pooling lag utganger fast lengde funksjon vektorer av region forslag. Deling AV CNN-beregningen gir mye mening, da mange regionsforslag av de samme bildene er svært overlappede.
- Erstatt det siste fullt tilkoblede laget og det siste softmax-laget (K-klasser) med et fullt tilkoblet lag og softmax over K + 1-klasser.
- endelig modellen grener i to output lag:
- en softmax estimator Av K + 1 klasser (samme som I R-CNN, +1 er «bakgrunn» klasse), sender ut en diskret sannsynlighetsfordeling per RoI.
- en markeringsboks regresjonsmodell som forutsier forskyvninger i forhold til Den opprinnelige Avkastningen for Hver Av K-klassene.
Tap Funksjon
modellen er optimalisert for et tap som kombinerer to oppgaver (klassifisering + lokalisering):
| Symbol | Forklaring | |
| \(u\) | true class label, \(u \i 0, 1, \dots, k\); ved konvensjon har catch-all bakgrunnsklassen \(u = 0\). | |
| \(p\) | Diskret sannsynlighetsfordeling (Per RoI) over K + 1 klasser: \(p = (p_0, \dots, p_K)\), beregnet av en softmax over K + 1 utgangene til et fullt tilkoblet lag. | |
| \(v\) | True markeringsrammen \(v = (v_x, v_y, v_w, v_h)\).dette er en av de mest populære variantene i verden, og du kan også bruke denne funksjonen. Se ovenfor. |
tap-funksjonen oppsummerer kostnaden for klassifisering og prediksjon av markeringsrammen: \(\mathcal{L} = \mathcal{L}_\text{cls} + \mathcal{l}_\text{box}\). For» bakgrunn » RoI ignoreres \(\mathcal{L}_\text{box}\) av indikatorfunksjonen \(\mathbb{1}\), definert som:
\ = \begin{cases} 1 & \text{if } u \geq 1\\ 0 & \text{ellers}\end{cases}\]
den totale tapsfunksjonen er:
\ \mathcal{L}_\text{box}(t^u, v) \\mathcal{L}_\text{cls}(p, u) &=- \logg p_u \\\mathcal{l}_\tekst{box}(t^u, v) &=\sum_{i \i \{x, y, w, h\}} l_1^\ tekst{glatt} (t^u_i – v_i)\end{align*}\]
grenseverdien box tap\(\mathcal{l}_{box}\) skal måle forskjellen mellom\ (t^u_i\) og\ (v_i\) ved hjelp av en robust tap funksjon. Det glatte l1-tapet er vedtatt her, og det hevdes å være mindre følsomt for uteliggere.
\
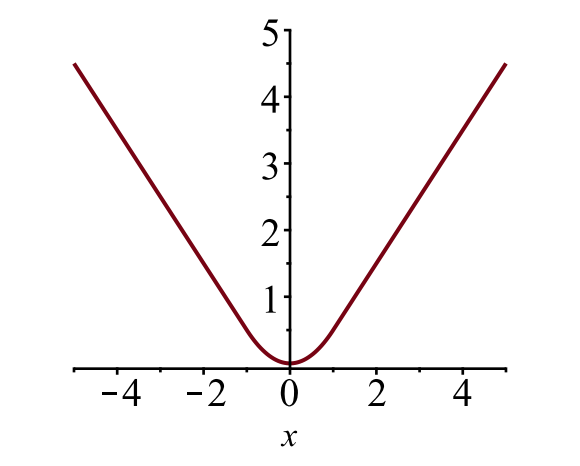
Fig. 6. Plottet av glatt L1 tap, \(y = L_1^ \ text{glatt} (x)\). (Bildekilde: link)
Speed Bottleneck
Fast R-CNN er mye raskere i både trening og testing tid. Forbedringen er imidlertid ikke dramatisk fordi regionforslagene genereres separat av en annen modell, og det er veldig dyrt.
Raskere R-CNN
en intuitiv speedup løsning er å integrere regionen forslaget algoritmen i CNN-modellen. Raskere R-CNN (Ren et al., 2016) gjør akkurat dette: konstruer en enkelt, enhetlig modell bestående AV RPN (region proposal network) og rask R-CNN med delte innviklede funksjonslag.

Fig. 7. En illustrasjon Av Raskere R-CNN modell. (Kilde: Ren et al., 2016)
Modell Arbeidsflyt
- pre-tog EN CNN nettverk på bilde klassifisering oppgaver.
- Finjustere rpn (region proposal network) ende-til-ende for region proposal-oppgaven, som er initialisert av pre-tog bildeklassifisereren. Positive prøver har iou (kryss-over-union) > 0.7, mens negative prøver har iou < 0.3.
- Skyv et lite n x n romlig vindu over conv-funksjonskartet over hele bildet.
- i midten av hvert skyvevindu forutsier vi flere regioner av forskjellige skalaer og forhold samtidig. Et anker er en kombinasjon av (glidende vindu senter, skala, forhold). For eksempel, 3 skalaer + 3 forhold = > k=9 ankre i hver skyveposisjon.
- Tren En Rask r-CNN-objektdeteksjonsmodell ved hjelp av forslagene generert av den nåværende RPN
- bruk Deretter Det Raske r-CNN-nettverket for å initialisere rpn-trening. Mens du holder de delte convolutional lagene, må du bare finjustere RPN-spesifikke lagene. PÅ dette stadiet har RPN og deteksjonsnettverket delt innviklede lag!Trinn 4-5 kan gjentas for å trene RPN og Rask R-CNN alternativt om nødvendig.
Tap Funksjon
Raskere R-CNN er optimalisert for en multi-oppgave tap funksjon, lik rask R-CNN.
| Symbol | Forklaring |
| \(p_i\) | Forutsagt sannsynlighet for at anker i er et objekt. |
| \(p^*_i\) | Ground truth label (binær) av om anker i er et objekt. |
| \(t_i\) | Forutslo Fire parameteriserte koordinater. |
| \(t^*_i\) | ground truth koordinater. |
| \(N_\text{cls}\) | Normalisering term, satt til å være mini-batch størrelse (~256) i papiret. |
| \(N_\text{box}\) | Normaliseringsperiode, sett til antall ankerplasser (~2400) i papiret. |
| \(\lambda\) | en balanseparameter, satt til ~10 i papiret (slik at både \(\mathcal{L}_ \ text{cls}\) og \(\mathcal{L}_\text{box}\) termer er omtrent like vektet). |
multi-oppgave tap funksjonen kombinerer tap av klassifisering og markeringsregresjon:
\
hvor \(\mathcal{l}_\text{cls}\) er logg tap funksjon over to klasser, som vi lett kan oversette en multi-klasse klassifisering i en binær klassifisering ved å forutsi en prøve er et målobjekt versus ikke. \(L_1^ \ text{smooth}\) er det glatte l1-tapet.
\
Maske R-CNN
Maske R-CNN (Han et al., 2017) utvider Raskere R-CNN til pikselnivå bildesegmentering. Hovedpoenget er å avkoble klassifisering og pixel-nivå maske prediksjon oppgaver. Basert På Rammen Av Raskere R-CNN, la den til en tredje gren for å forutsi en objektmaske parallelt med eksisterende grener for klassifisering og lokalisering. Maskegrenen er et lite fullt tilkoblet nettverk som brukes på Hver Avkastning, og forutsier en segmenteringsmaske på en piksel-til-piksel måte.
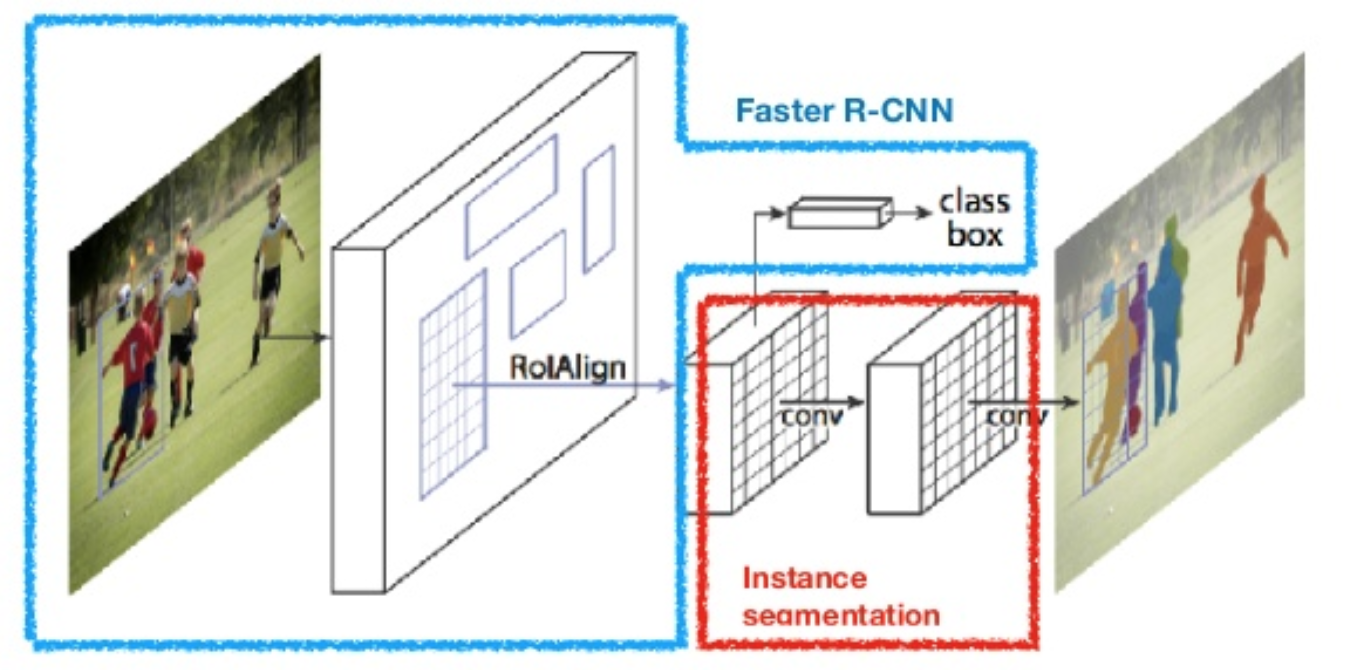
Fig. 8. Mask R-CNN Er Raskere R-CNN modell med bilde segmentering. (Bilde kilde: He et al., 2017)
fordi segmentering på pikselnivå krever mye mer finkornet justering enn markeringsbokser, forbedrer mask R-CNN RoI-pooling-laget (kalt «RoIAlign-lag») slik at RoI kan bli bedre og mer presist kartlagt til regionene i det opprinnelige bildet.

Fig. 9. Spådommer Av Mask R-CNN PÅ COCO test sett. (Bilde kilde: He et al., 2017)
RoIAlign
RoIAlign laget er utformet for å fikse plasseringen feiljustering forårsaket av kvantisering I RoI pooling. RoIAlign fjerner hashkvantiseringen, for eksempel ved å bruke x/16 i stedet for, slik at de utpakkede funksjonene kan justeres riktig med inndatapikslene. Bilinær interpolering brukes til å beregne flyttallsplasseringsverdiene i inngangen.
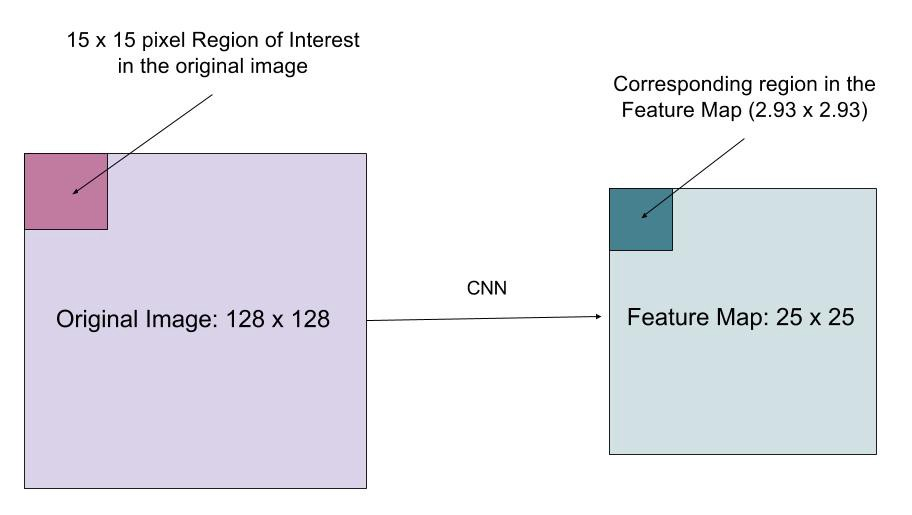
Fig. 10. En region av interesse er kartlagt nøyaktig fra det opprinnelige bildet på funksjonskartet uten å avrunde opp til heltall. (Bildekilde: tap Funksjon
multi-oppgave tap funksjon Av Mask R-CNN kombinerer tap av klassifisering, lokalisering og segmentering maske: \(\mathcal{L} = \mathcal{L}_\text{cls} + \mathcal{L}_\text{box} + \mathcal{l}_\text{mask}\), hvor \(\mathcal{l}_\text{cls}\) og \(\mathcal{l}_\text{box}\) er samme som i raskere r-Cnn.
maskegrenen genererer en maske med dimensjon m x m for Hver RoI og hver klasse; K-klasser totalt. Dermed er den totale utgangen av størrelse \(K \ cdot m^2\). Fordi modellen prøver å lære en maske for hver klasse, er det ingen konkurranse mellom klasser for å generere masker.
\(\mathcal{l}_\text{mask}\) er definert som det gjennomsnittlige binære kryssentropitapet, bare inkludert k-th maske hvis regionen er assosiert med den grunnleggende sannhetsklassen k.
\\]
hvor \(y_{ij}\) er etiketten til en celle (i, j) i den sanne masken for området med størrelse m x m; \(\hat{y}_{ij}^k\) er den forutsagte verdien av den samme cellen i masken.lært for bakken-sannhet klasse k.
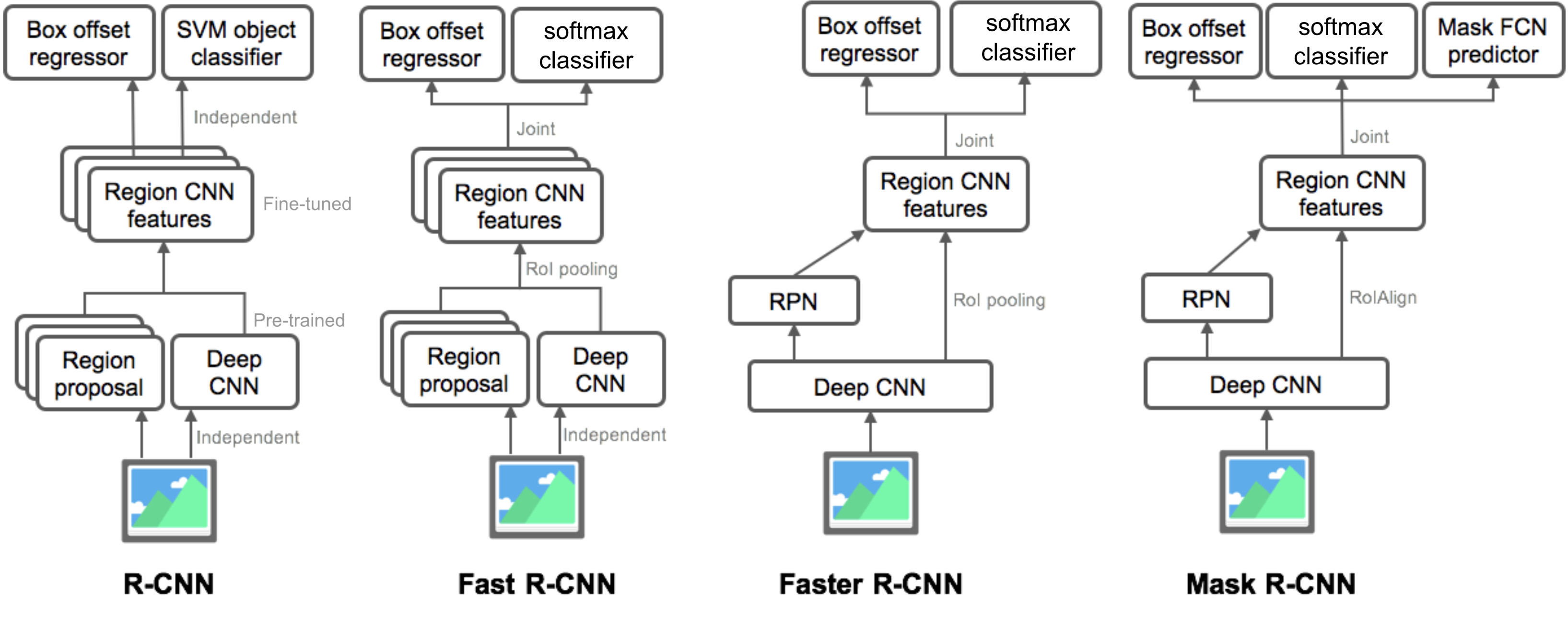
Oppsummering Av Modeller I r-cnn familien
her illustrerer jeg modell design AV R-CNN, Rask R-CNN, Raskere R-CNN og Maske R-CNN. Du kan spore hvordan en modell utvikler seg til neste versjon ved å sammenligne de små forskjellene.
Sitert som:
@article{weng2017detection3, title = "Object Detection for Dummies Part 3: R-CNN Family", author = "Weng, Lilian", journal = "lilianweng.github.io/lil-log", year = "2017", url = "http://lilianweng.github.io/lil-log/2017/12/31/object-recognition-for-dummies-part-3.html"}Referanse
Ross Girshick, Jeff donahue, trevor darrell og jitendra malik. «Rike funksjonshierarkier for nøyaktig objektdeteksjon og semantisk segmentering.»I Proc. IEEE Conf. om datasyn og mønstergjenkjenning (CVPR), s.580-587. 2014.
Ross Girshick. «Rask R-CNN.»I Proc. Ieee Internasjonale flyplass Conf. på computer vision, s.1440-1448. 2015.Shaoqing Ren, Kaiming He, Ross Girshick og Jian Sun. «Raskere R-CNN: Mot real-time objekt deteksjon med region forslaget nettverk.»I Fremskritt i neural information processing systems (NIPS), s.91-99. 2015.Dette er En av De mest populære spillene i verden. «Mask R-CNN.»arXiv preprint arXiv:1703.06870, 2017.Dette er En av De mest kjente av Disse. «Du ser bare en gang: Enhetlig objektdeteksjon i sanntid .»I Proc. IEEE Conf. om datasyn og mønstergjenkjenning (CVPR), s.779-788. 2016.
«En Kort Historie Om CNNs I Bildesegmentering: Fra R-CNN Til Mask R-CNN» Av Athelas.
Glatt L1 Tap: https://github.com/rbgirshick/py-faster-rcnn/files/764206/SmoothL1Loss.1.pdf