Objektdetektering för Dummies del 3: R-CNN-familjen
i del 3 skulle vi undersöka fyra objektdetekteringsmodeller: R-CNN, snabb R-CNN, snabbare R-CNN och Mask R-CNN. Dessa modeller är mycket relaterade och de nya versionerna visar stor hastighetsförbättring jämfört med de äldre.
i serien” Object Detection for Dummies ” började vi med grundläggande begrepp inom bildbehandling, såsom gradientvektorer och HOG, i Del 1. Sedan introducerade vi klassiska konvolutionella neurala nätverksarkitekturdesigner för klassificering och pionjärmodeller för objektigenkänning, Overfeat och DPM, i del 2. I det tredje inlägget i denna serie håller vi på att granska en uppsättning modeller i familjen R-CNN (”Regionbaserad CNN”).
länkar till alla inlägg i serien:.
Här är en lista över papper som omfattas av detta inlägg 😉
| Model | Goal | Resources |
| R-CNN | Object recognition | |
| Fast R-CNN | Object recognition | |
| Faster R-CNN | Object recognition | |
| Mask R-CNN | Image segmentation |
R-CNN
R-CNN (Girshick et al., 2014) is short for ”Region-based Convolutional Neural Networks”. The main idea is composed of two steps. Först, med hjälp av selektiv sökning, identifierar den ett hanterbart antal avgränsande objektregionskandidater (”region av intresse ”eller”RoI”). Och sedan extraherar det CNN-funktioner från varje region oberoende för klassificering.
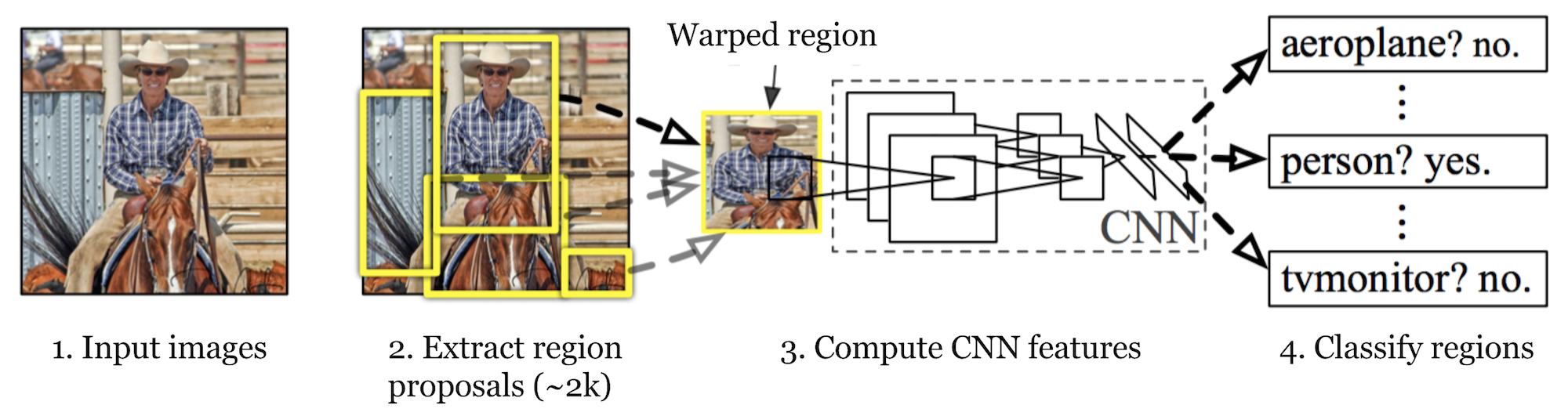
Fig. 1. Arkitekturen av R-CNN. (Bildkälla: Girshick et al., 2014)
Modellarbetsflöde
hur r-CNN fungerar kan sammanfattas enligt följande:
- Pre-train ett CNN-nätverk på bildklassificeringsuppgifter; till exempel vgg eller ResNet utbildad på ImageNet dataset. Klassificeringsuppgiften omfattar n-klasser.
OBS: Du kan hitta ett förutbildat AlexNet i Caffe Model Zoo. Jag tror inte att du kan hitta den i Tensorflow, men Tensorflow-slim model library ger förutbildad ResNet, VGG och andra.
- föreslå kategorioberoende regioner av intresse genom selektiv sökning (~2K kandidater per bild). Dessa regioner kan innehålla målobjekt och de har olika storlekar.
- regionkandidater är förvrängda för att ha en fast storlek som krävs av CNN.
- fortsätt finjustera CNN på förvrängda förslagsregioner för K + 1-klasser; den ytterligare klassen hänvisar till bakgrunden (inget objekt av intresse). I finjusteringsfasen bör vi använda en mycket mindre inlärningsfrekvens och mini-batch överprover de positiva fallen eftersom de flesta föreslagna regionerna bara är Bakgrund.
- med tanke på varje bildregion genererar en framåtutbredning genom CNN en funktionsvektor. Denna funktionsvektor konsumeras sedan av en binär SVM utbildad för varje klass oberoende.
de positiva proverna är föreslagna regioner med IoU (intersection over union) överlappningströskel >= 0.3, och negativa prover är irrelevanta andra. - för att minska lokaliseringsfelen tränas en regressionsmodell för att korrigera det förutsagda detekteringsfönstret på korrigeringsförskjutning med hjälp av CNN-funktioner.
Avgränsningsboxregression
givet en förutsagd avgränsningsboxkoordinat \(\mathbf{p} = (p_x, p_y, p_w, p_h)\) (mittkoordinat, bredd, höjd) och dess motsvarande marksanningsboxkoordinater \(\mathbf{g} = (g_x, g_y, g_w, g_h)\) , är regressorn konfigurerad för att lära sig skala-invariant transformation mellan två centra och log-skala transformation mellan två centra och log-skala transformation mellan bredder och höjder. Alla omvandlingsfunktioner tar \(\mathbf{p}\) som inmatning.
\
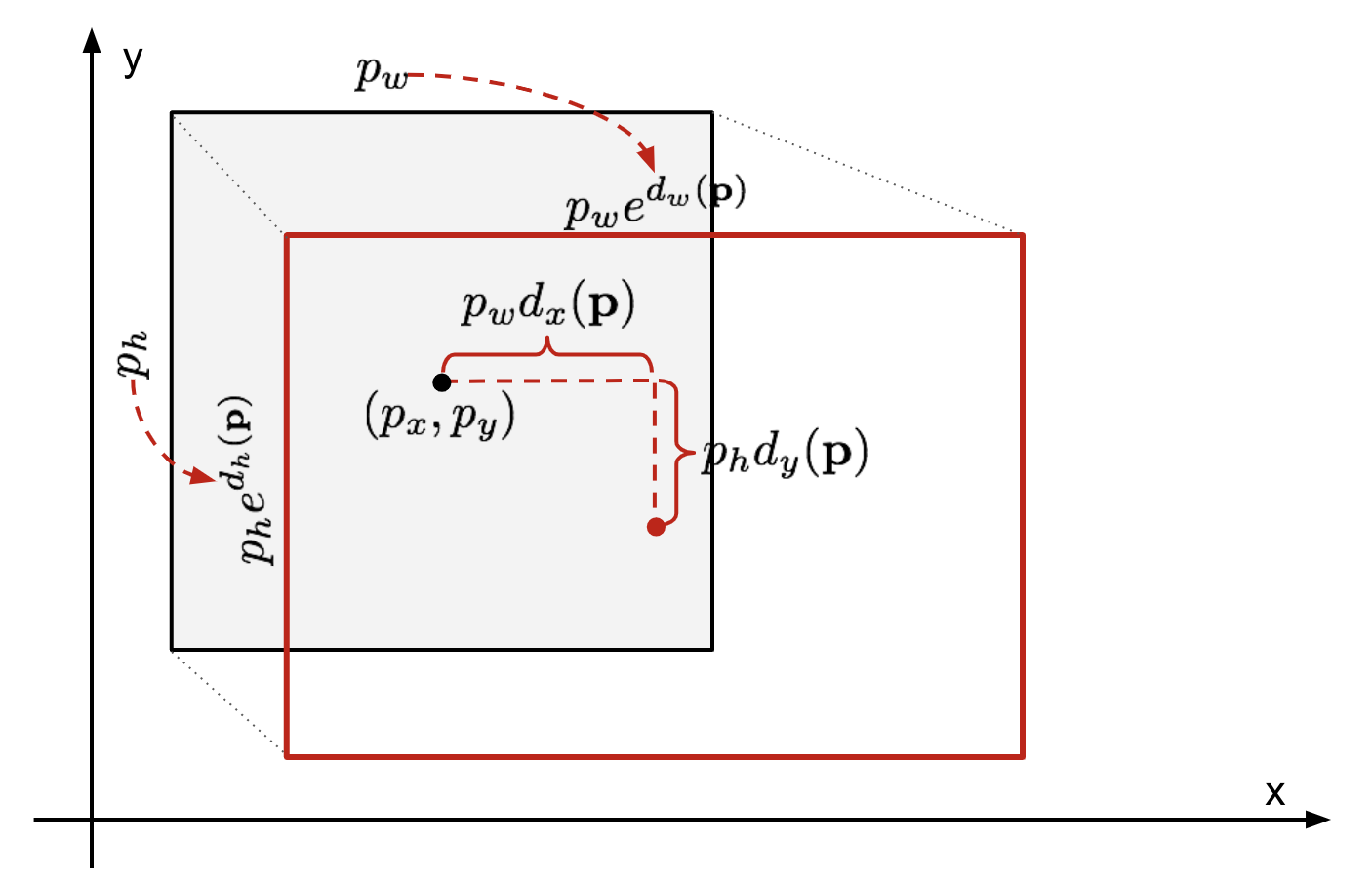
Fig. 2. Illustration av omvandling mellan förutsagda och markerade sanningsbegränsande lådor.
en uppenbar fördel med att tillämpa en sådan omvandling är att alla korrigeringsfunktioner för avgränsningsrutan, \(d_i (\mathbf{p})\) där \(i \in \{ x, y, w, h \}\), kan ta vilket värde som helst mellan . Målen för dem att lära sig är:
\
en standardregressionsmodell kan lösa problemet genom att minimera SSE-förlusten med regularisering:
\
regulariseringstermen är kritisk här och RCNN-papper valde det bästa coronaviruset genom korsvalidering. Det är också anmärkningsvärt att inte alla förutsagda avgränsningslådor har motsvarande marksanningslådor. Till exempel, om det inte finns någon överlappning, är det inte meningsfullt att köra bbox regression. Här hålls bara en förutsagd låda med en närliggande marksanningslåda med minst 0,6 IoU för att träna bbox-regressionsmodellen.
vanliga Tricks
flera knep används ofta i RCNN och andra detekteringsmodeller.
Icke-maximal undertryckning
sannolikt kan modellen hitta flera avgränsningsrutor för samma objekt. Icke-max dämpning hjälper till att undvika upprepad detektering av samma instans. Efter att vi har fått en uppsättning matchade avgränsningsrutor för samma objektkategori:sortera alla avgränsningsrutor efter konfidenspoäng.Kassera lådor med låga förtroendepoäng.Medan det finns någon återstående begränsningsruta, upprepa följande: Välj girigt den med högsta poäng.Hoppa över de återstående rutorna med hög IoU (dvs. > 0.5) med tidigare vald.

Fig. 3. Flera avgränsningsboxar upptäcker bilen i bilden. Efter icke-maximal undertryckning återstår bara de bästa och resten ignoreras eftersom de har stora överlappningar med den valda. (Bildkälla: DPM-papper)
hård negativ gruvdrift
vi betraktar avgränsningslådor utan objekt som negativa exempel. Inte alla negativa exempel är lika svåra att identifiera. Till exempel, om den har ren tom bakgrund, är det sannolikt en ”lätt negativ”; men om rutan innehåller konstig högljudd konsistens eller partiellt objekt, kan det vara svårt att känna igen och dessa är ”hårda negativa”.
de hårda negativa exemplen är lätt felklassificerade. Vi kan uttryckligen hitta de falska positiva proverna under träningslingorna och inkludera dem i träningsdata för att förbättra klassificeringen.
Hastighetsflaskhals
Om du tittar igenom r-CNN-inlärningsstegen kan du enkelt ta reda på att träning av en R-CNN-modell är dyr och långsam, eftersom följande steg innebär mycket arbete:
- kör selektiv sökning för att föreslå 2000 regionskandidater för varje bild;
- generera CNN-funktionsvektorn för varje bildregion (n images * 2000).
- hela processen involverar tre modeller separat utan mycket delad beräkning: det konvolutionella neurala nätverket för bildklassificering och extraktion av funktioner; den översta SVM-klassificeraren för att identifiera målobjekt; och regressionsmodellen för åtdragning av regionbegränsande lådor.
Fast R-CNN
För att göra R-CNN snabbare förbättrade Girshick (2015) träningsproceduren genom att förena tre oberoende modeller i en gemensamt utbildad ram och öka delade beräkningsresultat, med namnet Fast R-CNN. Istället för att extrahera CNN-funktionsvektorer oberoende för varje regionförslag, samlar denna modell dem i ett CNN-framåtpass över hela bilden och regionförslagen delar denna funktionsmatris. Sedan förgrenas samma funktionsmatris för att användas för att lära sig objektklassificeraren och begränsningsboxregressorn. Sammanfattningsvis påskyndar beräkningsdelning R-CNN.
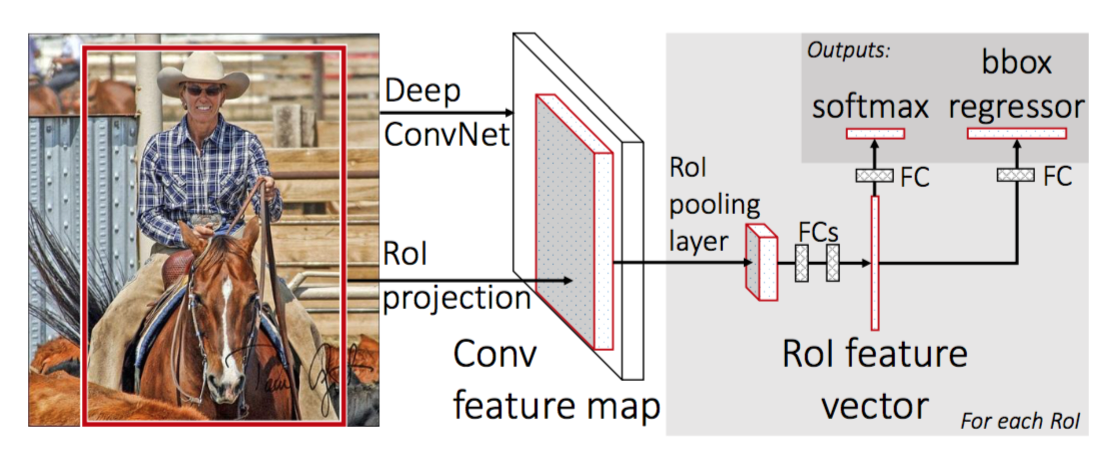
Fig. 4. Arkitekturen för snabb R-CNN. (Bildkälla: Girshick, 2015)
RoI Pooling
det är en typ av max pooling för att konvertera funktioner i den projicerade regionen av bilden av vilken storlek som helst, h x w, till ett litet fast fönster, H x W. ingångsregionen är uppdelad i H x W galler, ungefär varje underfönster av storlek h/H x w/W. använd sedan max-pooling i varje rutnät.
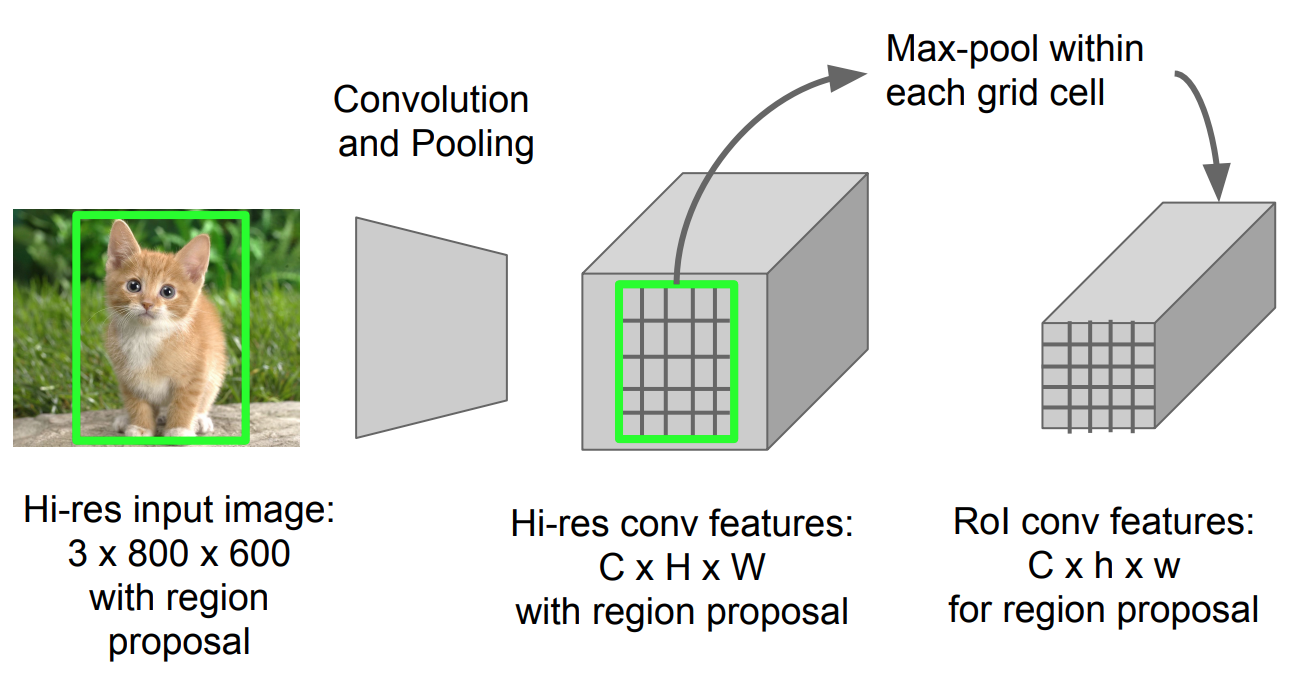
Fig. 5. RoI pooling (Bildkälla: Stanford CS231n slides.)
Modellarbetsflöde
hur snabbt R-CNN fungerar sammanfattas enligt följande; många steg är desamma som i R-CNN:
- Först, träna ett konvolutionellt neuralt nätverk på bildklassificeringsuppgifter.
- föreslå regioner genom selektiv sökning (~2K kandidater per bild).
- ändra det förutbildade CNN:
- Byt ut det sista maxpoolskiktet i det förutbildade CNN med ett RoI-poollager. RoI pooling layer matar ut fasta längdvektorer av regionförslag. Att dela CNN-beräkningen är mycket meningsfullt, eftersom många regionförslag av samma bilder är mycket överlappade.
- Byt ut det sista helt anslutna lagret och det sista softmax-lagret (k-klasser) med ett helt anslutet lager och softmax över K + 1-klasserna.
- slutligen delas modellen in i två utgångslager:
- en softmax-estimator av K + 1-klasser (samma som i R-CNN, +1 är klassen ”bakgrund”) och matar ut en diskret sannolikhetsfördelning per RoI.
- en begränsande regressionsmodell som förutsäger förskjutningar i förhållande till den ursprungliga avkastningen för var och en av K-klasserna.
förlustfunktion
modellen är optimerad för en förlust som kombinerar två uppgifter (klassificering + lokalisering):
| Symbol | förklaring |
| \(u\) | True class label, \(u \i 0, 1, \Dots, K\); enligt konvention har catch-all bakgrundsklass \(u = 0\). |
| \(p\) | diskret sannolikhetsfördelning (per RoI) över K + 1-klasserna: \(p = (p_0, \dots, p_K)\), beräknad av en softmax över K + 1-utgångarna i ett helt anslutet lager. |
| \(v\) | sann avgränsningsruta \(v = (v_x, v_y, v_w, v_h)\). |
| \(t^u\) | förutspådd begränsningsboxkorrigering, \(t^u = (t^u_x, t^u_y, t^u_w, t^u_h)\). Se ovan. |
förlustfunktionen summerar kostnaden för klassificering och begränsningsboxprediktion: \(\mathcal{L} = \mathcal{L}_\text{cls} + \mathcal{L}_\text{box}\). För” bakgrund ” RoI ignoreras \(\mathcal{L}_\text{box}\) av indikatorfunktionen \(\mathbb{1}\), definierad som:
\ = \begin{cases} 1 & \text{if } u \geq 1\\ 0 & \text{annars}\end{cases}\]
den totala förlustfunktionen är:
\ \mathcal{L}_\text{box}(t^u, v) \\\mathcal{L}_\text{cls}(p, u) &= -\log p_u \\\mathcal{L}_\text{box}(t^u, v) &= \sum_{i \in \{x, y, w, h\}} l_1^\text{Smooth} (t^u_i – v_i)\end{align*}\]
bounding box loss \(\mathcal{L}_{box}\) ska mäta skillnaden mellan \(t^u_i\) och \(v_i\) med hjälp av en robust förlustfunktion. Den smidiga L1-förlusten antas här och det påstås vara mindre känsligt för avvikare.
\
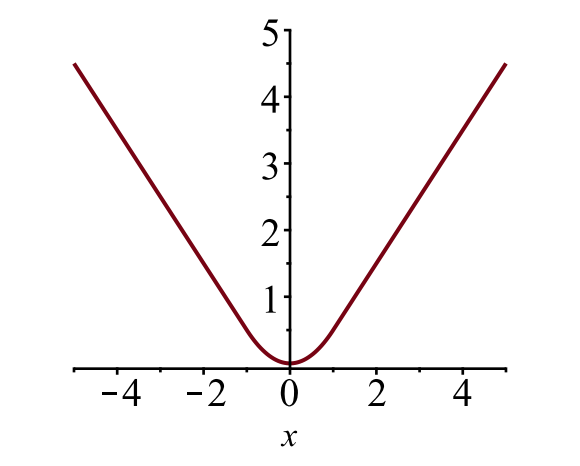
Fig. 6. Diagrammet för smidig L1-förlust, \(y = L_1^\text{smooth} (x)\). (Bildkälla: länk)
Hastighetsflaskhals
snabb R-CNN är mycket snabbare i både träning och testtid. Förbättringen är dock inte dramatisk eftersom regionförslagen genereras separat av en annan modell och det är mycket dyrt.
snabbare r-CNN
en intuitiv speedup-lösning är att integrera regionförslagsalgoritmen i CNN-modellen. Snabbare r-CNN (Ren et al., 2016) gör exakt detta: konstruera en enda, enhetlig modell som består av RPN (region proposal network) och snabb R-CNN med delade faltningsfunktionslager.

Fig. 7. En illustration av snabbare r-CNN modell. (Bildkälla: Ren et al., 2016)
Modellarbetsflöde
- förträna ett CNN-nätverk om bildklassificeringsuppgifter.
- finjustera RPN (region proposal network) end-to-end för region proposal-uppgiften, som initieras av bildklassificeraren före tåget. Positiva prover har IoU (intersection-over-union) > 0.7, medan negativa prover har IoU < 0.3.
- Skjut ett litet n x n rumsligt fönster över Conv-funktionskartan för hela bilden.
- i mitten av varje skjutfönster förutsäger vi flera regioner med olika skalor och förhållanden samtidigt. Ett ankare är en kombination av (glidande fönstercenter, skala, förhållande). Till exempel 3 skalor + 3 förhållanden => k=9 ankare vid varje glidläge.
- träna en snabb r-CNN-objektdetekteringsmodell med de förslag som genereras av den nuvarande RPN
- använd sedan det snabba r-CNN-nätverket för att initiera RPN-träning. Medan du behåller de delade fällningslagren, finjusterar du bara de RPN-specifika lagren. I detta skede har RPN och detektionsnätverket delat fällningslager!
- slutligen finjustera de unika lagren av Snabb r-CNN
- steg 4-5 kan upprepas för att träna RPN och snabb r-CNN alternativt om det behövs.
förlustfunktion
snabbare R-CNN är optimerad för en förlustfunktion med flera uppgifter, liknande snabb r-CNN.
| Symbol | förklaring |
| \(p_i\) | förutspådd sannolikhetför att ankare är ett objekt. |
| \(p^*_i\) | marksanningsetikett (binär) om anchor i är ett objekt. |
| \(t_i\) | förutspådde fyra parametriserade koordinater. |
| \(t^*_i\) | jord sanningskoordinater. |
| \(n_\text{cls}\) | Normaliseringsperiod, inställd på att vara mini-batchstorlek (~256) i papperet. |
| \(n_\text{box}\) | Normaliseringsperiod, inställd på antalet ankarplatser (~2400) i papperet. |
| \(\lambda\) | en balanseringsparameter, inställd på att vara ~10 i papperet (så att både \(\mathcal{L}_\text{cls}\) och \(\mathcal{L}_\text{box}\) termer är ungefär lika viktade). |
multi-task loss-funktionen kombinerar förlusterna av klassificering och begränsningsregression:
\
där \(\mathcal{L}_\text{cls}\) är loggförlustfunktionen över två klasser, eftersom vi enkelt kan översätta en flerklassklassificering till en binär klassificering genom att förutsäga ett prov är ett målobjekt kontra inte. \(L_1^\text{smooth}\) är den släta L1-förlusten.
\
Mask R-CNN
Mask R-CNN (han et al., 2017) utökar snabbare R-CNN till bildsegmentering på pixelnivå. Nyckelpunkten är att koppla bort klassificeringen och pixelnivåmaskens förutsägelsesuppgifter. Baserat på ramen för snabbare r-CNN lade den till en tredje gren för att förutsäga en objektmask parallellt med befintliga grenar för klassificering och lokalisering. Maskgrenen är ett litet helt anslutet nätverk som appliceras på varje avkastning, vilket förutsäger en segmenteringsmask på ett pixel-Till-pixel-sätt.
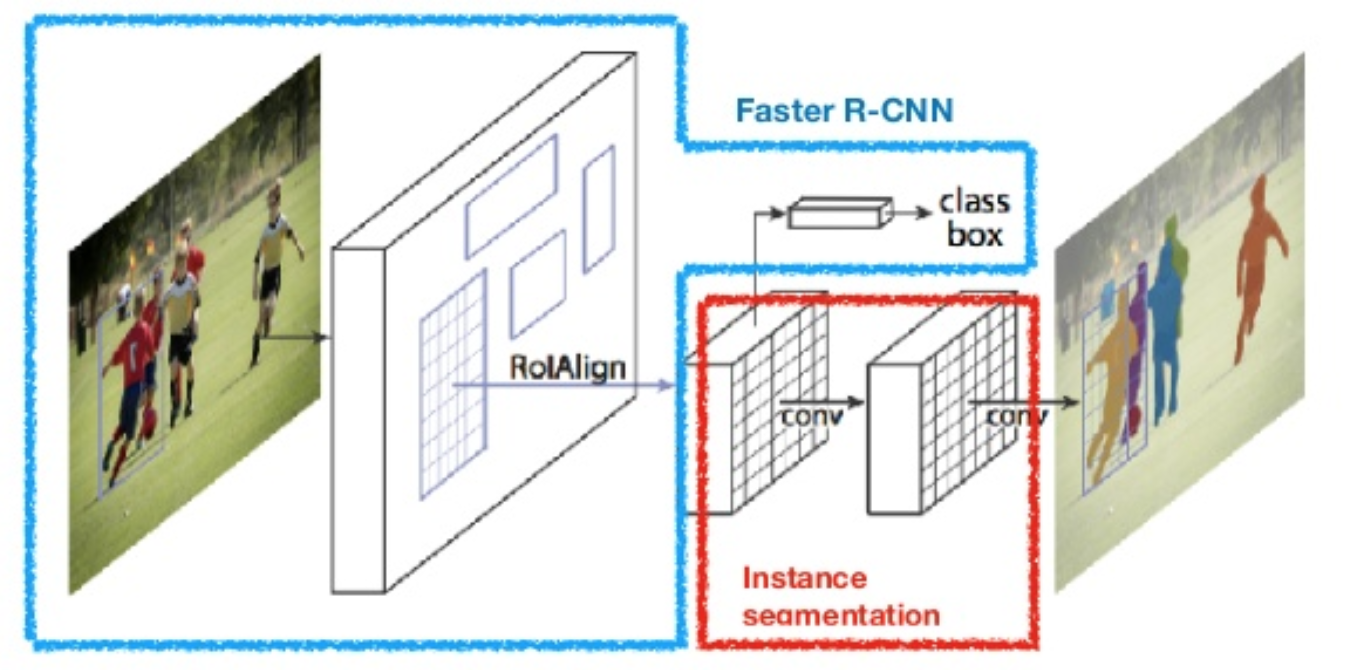
Fig. 8. Mask R-CNN är snabbare R-CNN modell med bildsegmentering. (Bildkälla: han et al., 2017)
eftersom pixelnivåsegmentering kräver mycket mer finkornig inriktning än avgränsningslådor, förbättrar mask R-CNN RoI-poolskiktet (benämnt ”Roilign layer”) så att RoI kan bättre och mer exakt mappas till regionerna i originalbilden.

Fig. 9. Förutsägelser av Mask R-CNN på COCO test set. (Bildkälla: han et al., 2017)
RoIAlign
roialign-skiktet är utformat för att fixa platsförskjutningen orsakad av kvantisering i RoI-poolen. RoIAlign tar bort hash-kvantiseringen, till exempel genom att använda x/16 istället för , så att de extraherade funktionerna kan anpassas korrekt med ingångspixlarna. Bilinär interpolering används för att beräkna flyttalsplatsvärdena i ingången.
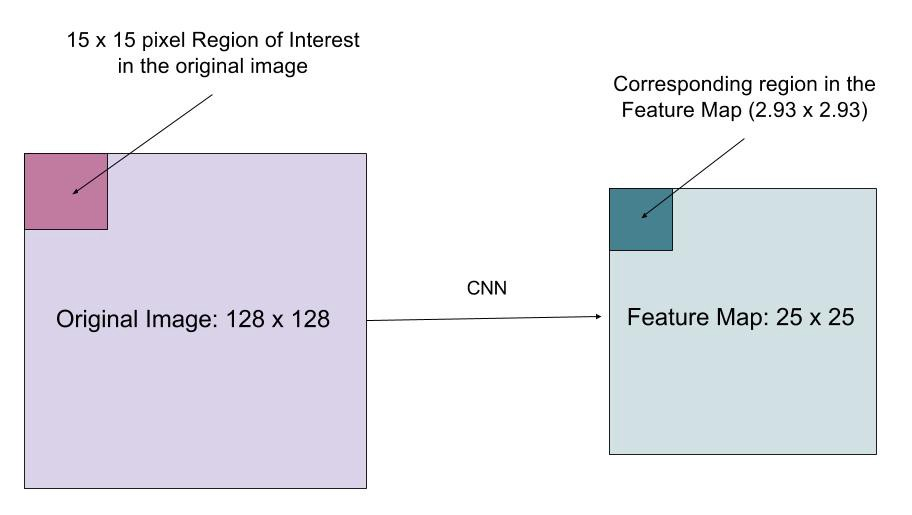
Fig. 10. En region av intresse mappas exakt från den ursprungliga bilden på funktionskartan utan avrundning upp till heltal. (Bildkälla:
förlustfunktion
multi-task-förlustfunktionen för Mask R-CNN kombinerar förlusten av klassificering, lokalisering och segmenteringsmask: \(\mathcal{L} = \mathcal{L}_\text{cls} + \mathcal{L}_\text{box} + \mathcal{L}_\text{mask}\), där \(\mathcal{L}_\text{cls}\) och \(\mathcal{L}_\text{box}\) är samma som i snabbare r-CNN.
maskgrenen genererar en mask med dimension m x m för varje RoI och varje klass; K-klasser totalt. Således är den totala produktionen av storlek \(K \ cdot m^2\). Eftersom modellen försöker lära sig en mask för varje klass finns det ingen konkurrens mellan klasserna för att generera masker.
\(\mathcal{L}_\text{mask}\) definieras som den genomsnittliga binära korsentropiförlusten, endast inklusive k-TH-mask om regionen är associerad med marksanningsklassen k.
\\]
där \(y_{IJ}\) är etiketten för en cell (i, j) i den sanna masken för regionen med storlek m x m; \(\hat{y}_{ij}^k\) är det förutsagda värdet för samma cell i masken lärt sig för marken-sanning klass k.
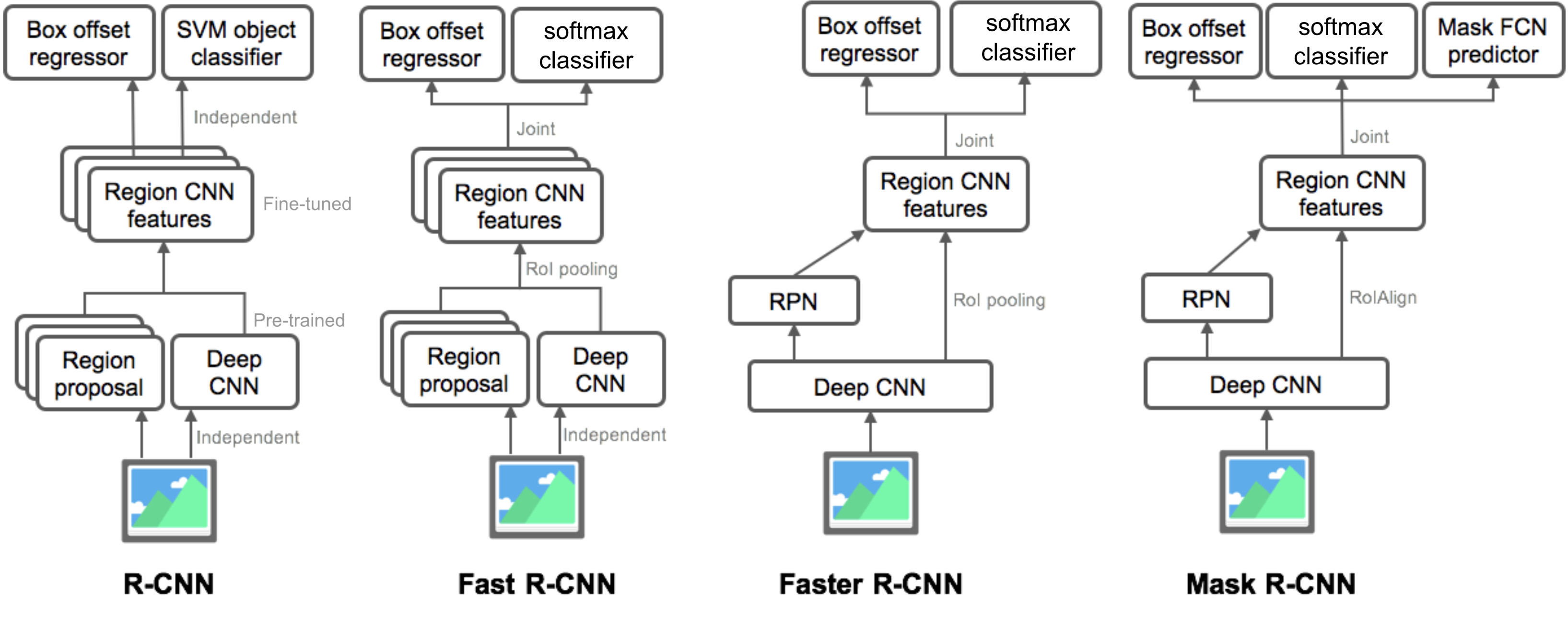
sammanfattning av modeller i r-CNN-familjen
här illustrerar jag modelldesigner av R-CNN, Fast R-CNN, Faster R-CNN och Mask R-CNN. Du kan spåra hur en modell utvecklas till nästa version genom att jämföra de små skillnaderna.
citerad som:
@article{weng2017detection3, title = "Object Detection for Dummies Part 3: R-CNN Family", author = "Weng, Lilian", journal = "lilianweng.github.io/lil-log", year = "2017", url = "http://lilianweng.github.io/lil-log/2017/12/31/object-recognition-for-dummies-part-3.html"}referens
Ross Girshick, Jeff Donahue, Trevor Darrell och Jitendra Malik. ”Rika funktionshierarkier för exakt objektdetektering och semantisk segmentering.”I Proc. IEEE Conf. på datorsyn och mönsterigenkänning (CVPR), s.580-587. 2014.
Ross Girshick. ”Snabb R-CNN.”I Proc. IEEE Intl. Conf. på datorsyn, s. 1440-1448. 2015.Shaoqing Ren, Kaiming He, Ross Girshick och Jian Sun. ”Snabbare R-CNN: mot realtidsobjektdetektering med regionförslag nätverk.”I framsteg inom neural Information processing systems (NIPS), s.91-99. 2015.
Kaiming He, Georgia Gkioxari, Piotr Doll och Ross Girshick. ”Mask R-CNN.”arXiv förtryck arXiv: 1703.06870, 2017.
Joseph Redmon, Santosh Divvala, Ross Girshick och Ali Farhadi. ”Du ser bara en gång: enhetlig objektdetektering i realtid.”I Proc. IEEE Conf. om datorsyn och mönsterigenkänning (CVPR), s.779-788. 2016.
” en kort historia av CNN i Bildsegmentering: från R-CNN till Mask R-CNN ” av Athelas.
smidig L1-förlust: https://github.com/rbgirshick/py-faster-rcnn/files/764206/SmoothL1Loss.1.pdf