Objekterkennung für Dummies Teil 3: R-CNN-Familie
In Teil 3 würden wir vier Objekterkennungsmodelle untersuchen: R-CNN, Fast R-CNN, Faster R-CNN und Mask R-CNN. Diese Modelle sind sehr verwandt und die neuen Versionen zeigen eine große Geschwindigkeitsverbesserung im Vergleich zu den älteren.
In der Reihe „Objekterkennung für Dummies“ haben wir in Teil 1 mit grundlegenden Konzepten in der Bildverarbeitung wie Gradientenvektoren und HOG begonnen. Dann haben wir in Teil 2 klassische Faltungsarchitekturdesigns für neuronale Netze zur Klassifizierung und Pioniermodelle für Objekterkennung, Overfeat und DPM vorgestellt. Im dritten Beitrag dieser Serie werden wir eine Reihe von Modellen der R-CNN-Familie („Region-based CNN“) überprüfen.
Links zu allen Beiträgen der Serie: .
Hier ist eine Liste der in diesem Beitrag behandelten Artikel 😉
| Model | Goal | Resources |
| R-CNN | Object recognition | |
| Fast R-CNN | Object recognition | |
| Faster R-CNN | Object recognition | |
| Mask R-CNN | Image segmentation |
R-CNN
R-CNN (Girshick et al., 2014) is short for „Region-based Convolutional Neural Networks“. The main idea is composed of two steps. Zunächst wird mithilfe der selektiven Suche eine überschaubare Anzahl von Bounding-Box-Objektregionskandidaten („Region of Interest“ oder „RoI“) identifiziert. Und dann extrahiert es CNN-Merkmale aus jeder Region unabhängig zur Klassifizierung.
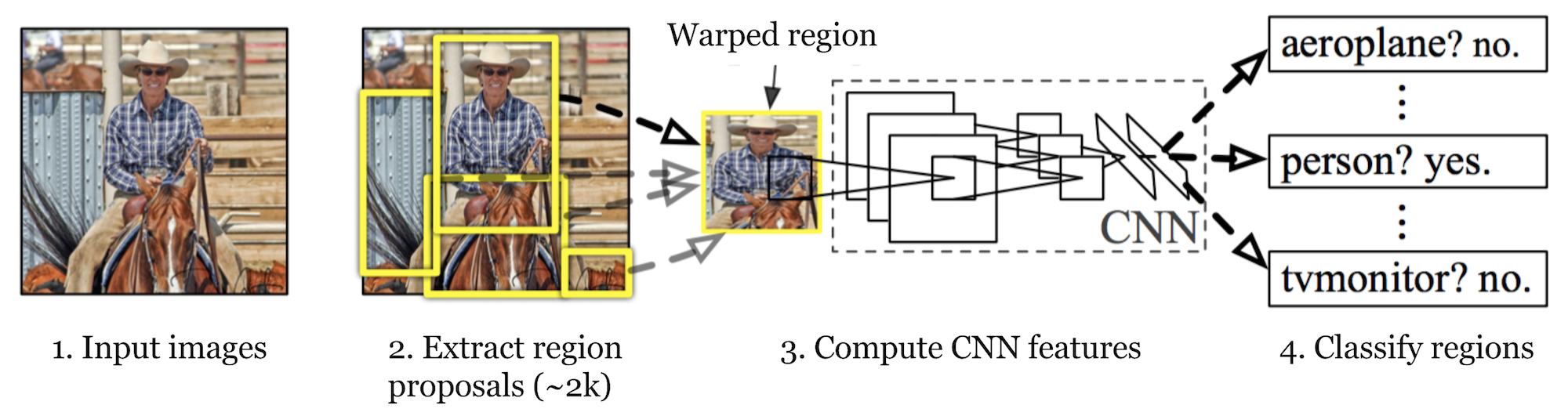
Abb. 1. Die Architektur von R-CNN. (Bildquelle: Girshick et al., 2014)
Modellworkflow
Die Funktionsweise von R-CNN lässt sich wie folgt zusammenfassen:
- Trainieren Sie ein CNN-Netzwerk vorab für Bildklassifizierungsaufgaben. Die Klassifizierungsaufgabe umfasst N Klassen.
HINWEIS: Sie finden ein vortrainiertes AlexNet in Caffe Model Zoo. Ich glaube nicht, dass Sie es in Tensorflow finden können, aber die Tensorflow-Slim-Modellbibliothek bietet vortrainiertes ResNet, VGG und andere.
- Schlagen Sie kategorieunabhängige Regionen von Interesse durch selektive Suche vor (~ 2k Kandidaten pro Bild). Diese Regionen können Zielobjekte enthalten und unterschiedlich groß sein.
- Regionskandidaten werden verzerrt, um eine feste Größe zu haben, wie von CNN gefordert.
- Weiter die Feinabstimmung der CNN auf verzogen Vorschlag Regionen für K + 1 Klassen; Die zusätzliche Klasse bezieht sich auf den Hintergrund (kein Objekt von Interesse). In der Feinabstimmungsphase sollten wir eine viel geringere Lernrate verwenden, und der Mini-Batch überabtastet die positiven Fälle, da die meisten vorgeschlagenen Regionen nur Hintergrund sind.
- Bei jeder Bildregion erzeugt eine Vorwärtsausbreitung durch das CNN einen Merkmalsvektor. Dieser Merkmalsvektor wird dann von einer binären SVM verbraucht, die für jede Klasse unabhängig trainiert wird.
Die positiven Proben sind vorgeschlagene Regionen mit IoU (Schnittpunkt über Union) Überlappungsschwelle >= 0.3, und negative Proben sind irrelevant andere. - Um die Lokalisierungsfehler zu reduzieren, wird ein Regressionsmodell trainiert, um das vorhergesagte Erkennungsfenster auf Bounding-Box-Korrekturversatz mit CNN-Features zu korrigieren.
Bounding Box Regression
Bei einer vorhergesagten Bounding Box-Koordinate \(\mathbf{p} = (p_x, p_y, p_w, p_h)\) (Mittelpunktskoordinate, Breite, Höhe) und den entsprechenden Ground Truth Box-Koordinaten \(\mathbf{g} = (g_x, g_y, g_w, g_h)\) ist der Regressor so konfiguriert, dass er die skaleninvariante Transformation zwischen zwei Zentren und die logarithmische Transformation zwischen Breiten lernt und Höhen. Alle Transformationsfunktionen nehmen \(\mathbf{p}\) als Eingabe.
\
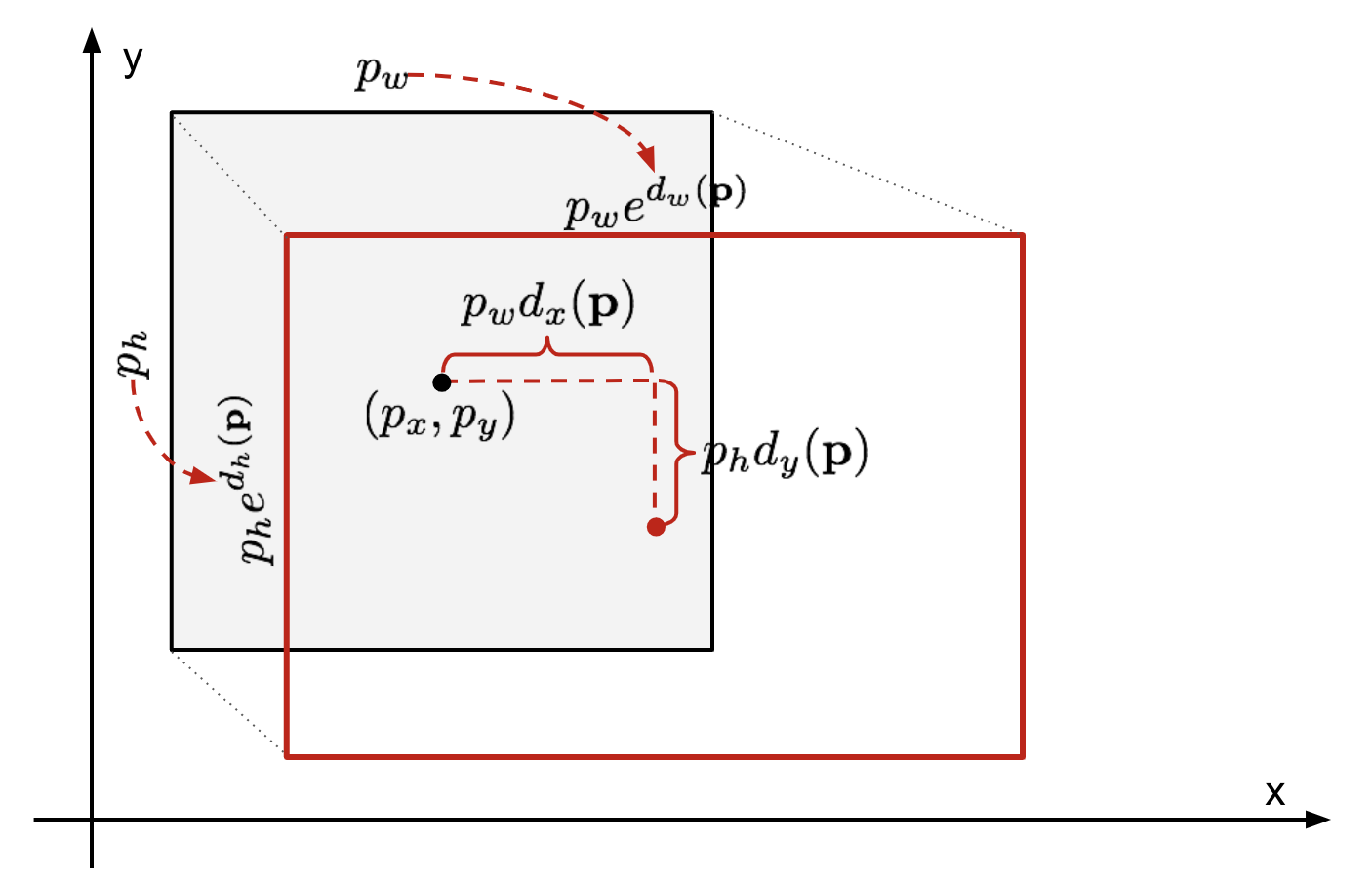
Abb. 2. Abbildung der Transformation zwischen vorhergesagten und Ground Truth Bounding Boxes.Ein offensichtlicher Vorteil der Anwendung einer solchen Transformation besteht darin, dass alle Bounding-Box-Korrekturfunktionen \(d_i(\mathbf{p})\) wobei \(i \in \{ x, y, w, h \}\) einen beliebigen Wert dazwischen annehmen können . Die Ziele, die sie lernen müssen, sind:
\
Ein Standardregressionsmodell kann das Problem lösen, indem es den SSE-Verlust mit Regularisierung minimiert:
\
Der Regularisierungsbegriff ist hier entscheidend, und RCNN hat den besten λ durch Kreuzvalidierung ausgewählt. Es ist auch bemerkenswert, dass nicht alle vorhergesagten Begrenzungsrahmen entsprechende Grundwahrheitsfelder haben. Wenn beispielsweise keine Überlappung vorliegt, ist es nicht sinnvoll, die bbox-Regression auszuführen. Hier wird nur eine vorhergesagte Box mit einer nahe gelegenen Ground Truth Box mit mindestens 0,6 IoU zum Trainieren des bbox-Regressionsmodells aufbewahrt.
Häufige Tricks
Mehrere Tricks werden häufig in RCNN und anderen Erkennungsmodellen verwendet.
Nicht maximale Unterdrückung
Wahrscheinlich kann das Modell mehrere Begrenzungsrahmen für dasselbe Objekt finden. Die Nicht-Max-Unterdrückung hilft, die wiederholte Erkennung derselben Instanz zu vermeiden. Nachdem wir eine Reihe übereinstimmender Begrenzungsrahmen für dieselbe Objektkategorie erhalten haben: Sortieren Sie alle Begrenzungsrahmen nach Konfidenzwert.Verwerfen Sie Kisten mit niedrigen Vertrauenswerten.Solange noch ein Begrenzungsrahmen vorhanden ist, wiederholen Sie Folgendes: Wählen Sie gierig den mit der höchsten Punktzahl aus.Überspringen Sie die verbleibenden Felder mit hohem IoU (dh > 0.5) mit dem zuvor ausgewählten.

Abb. 3. Mehrere Begrenzungsrahmen erkennen das Auto im Bild. Nach nicht maximaler Unterdrückung bleibt nur das Beste übrig und der Rest wird ignoriert, da sie große Überlappungen mit dem ausgewählten haben. (Bildquelle: DPM-Papier)
Harte negative Beispiele
Wir betrachten Begrenzungsrahmen ohne Objekte als Negativbeispiele. Nicht alle negativen Beispiele sind gleich schwer zu identifizieren. Wenn die Box jedoch eine seltsame verrauschte Textur oder ein Teilobjekt enthält, kann es schwierig sein, sie zu erkennen, und diese sind „hart negativ“.
Die harten Negativbeispiele werden leicht falsch klassifiziert. Wir können diese falsch positiven Stichproben während der Trainingsschleifen explizit finden und in die Trainingsdaten aufnehmen, um den Klassifikator zu verbessern.
Geschwindigkeitsengpass
Wenn Sie die R-CNN-Lernschritte durchsehen, können Sie leicht feststellen, dass das Trainieren eines R-CNN-Modells teuer und langsam ist, da die folgenden Schritte viel Arbeit erfordern:
- Ausführen einer selektiven Suche, um 2000 Regionskandidaten für jedes Bild vorzuschlagen;
- Generieren des CNN-Merkmalsvektors für jede Bildregion (N Bilder * 2000).
- Der gesamte Prozess umfasst drei separate Modelle ohne viel gemeinsame Berechnung: das Convolutional Neural Network für die Bildklassifizierung und Merkmalsextraktion; der Top-SVM-Klassifikator zur Identifizierung von Zielobjekten; und das Regressionsmodell zum Straffen von Region Bounding Boxes.
Fast R-CNN
Um R-CNN schneller zu machen, verbesserte Girshick (2015) das Trainingsverfahren, indem er drei unabhängige Modelle in einem gemeinsam trainierten Framework vereinheitlichte und die gemeinsamen Berechnungsergebnisse mit dem Namen Fast R-CNN erhöhte. Anstatt CNN-Merkmalsvektoren unabhängig für jeden Regionsvorschlag zu extrahieren, aggregiert dieses Modell sie zu einem CNN-Vorwärtsdurchlauf über das gesamte Bild, und die Regionsvorschläge teilen sich diese Merkmalsmatrix. Dann wird dieselbe Merkmalsmatrix verzweigt, um zum Lernen des Objektklassifikators und des Bounding-Box-Regressors verwendet zu werden. Zusammenfassend lässt sich sagen, dass die gemeinsame Nutzung von Berechnungen R-CNN beschleunigt.
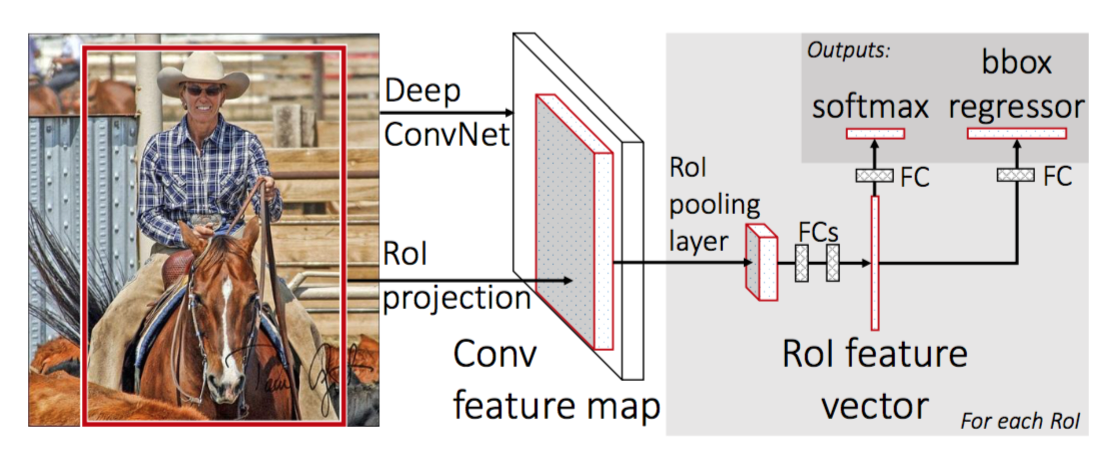
Abb. 4. Die Architektur von Fast R-CNN. (Bildquellen: Girshick, 2015)
RoI-Pooling
Es handelt sich um eine Art maximales Pooling, um Features im projizierten Bereich des Bildes beliebiger Größe (h x b) in ein kleines festes Fenster (H x B) zu konvertieren.
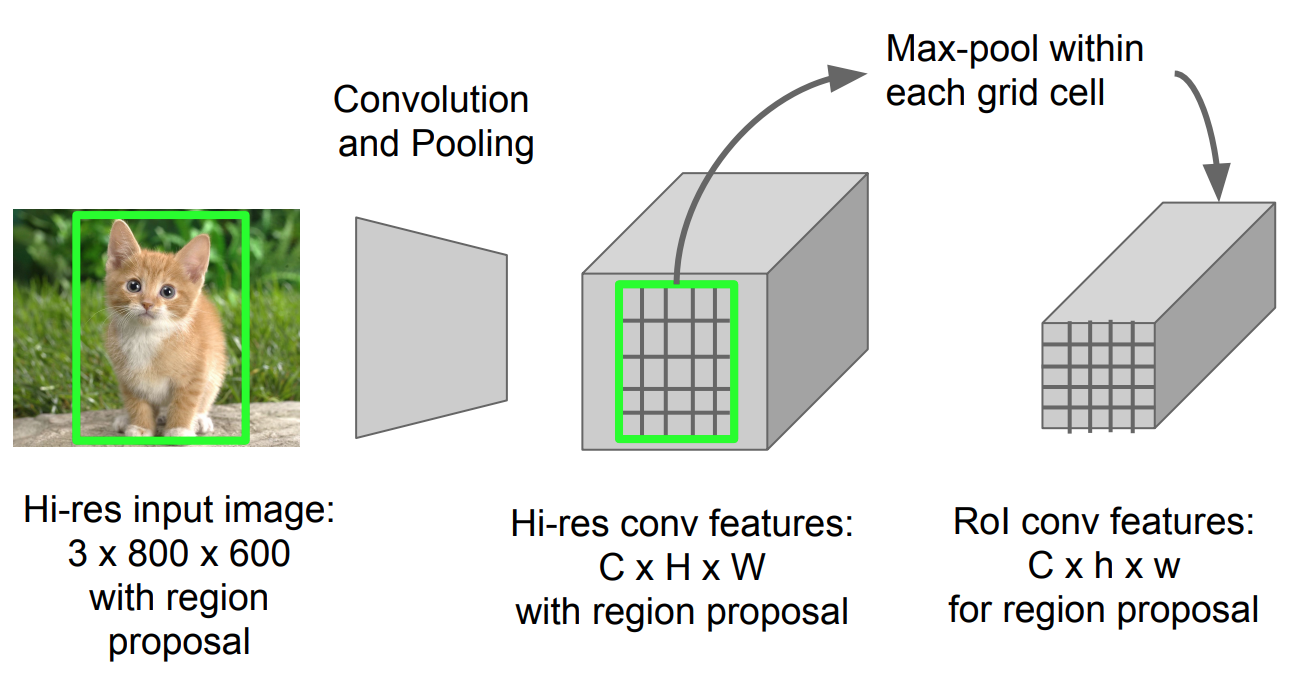
Abb. 5. RoI-Pooling (Bildquelle: Stanford CS231n).)
Modell-Workflow
Wie schnell R-CNN arbeitet, ist wie folgt zusammengefasst; viele Schritte sind die gleichen wie in R-CNN:
- Trainieren Sie zunächst ein konvolutionelles neuronales Netzwerk für Bildklassifizierungsaufgaben.
- Regionen durch selektive Suche vorschlagen (~2k Kandidaten pro Bild).
- vortrainiertes CNN ändern:
- Ersetzen Sie die letzte Max-Pooling-Schicht des vortrainierten CNN durch eine RoI-Pooling-Schicht. Der RoI-Pooling-Layer gibt Feature-Vektoren fester Länge von Regionsvorschlägen aus. Die gemeinsame Nutzung der CNN-Berechnung ist sehr sinnvoll, da sich viele Regionsvorschläge derselben Bilder stark überlappen.
- Ersetzen Sie die letzte vollständig verbundene Ebene und die letzte Softmax-Ebene (K-Klassen) durch eine vollständig verbundene Ebene und Softmax über K + 1-Klassen.
- Schließlich verzweigt sich das Modell in zwei Ausgabeschichten:
- Ein Softmax-Schätzer von K + 1 Klassen (wie in R-CNN, +1 ist die „Hintergrund“ -Klasse), der eine diskrete Wahrscheinlichkeitsverteilung pro RoI ausgibt.
- Ein Bounding-Box-Regressionsmodell, das Offsets relativ zum ursprünglichen RoI für jede von K Klassen vorhersagt.
Verlustfunktion
Das Modell ist für einen Verlust optimiert, der zwei Aufgaben kombiniert (Klassifizierung + Lokalisierung):
| Symbol | Erklärung |
| \(u\) | True class label, \(u \in 0, 1, \dots, K\); Konventionell hat die Catch-all-Hintergrundklasse \(u = 0\) . |
| \(p\) | Diskrete Wahrscheinlichkeitsverteilung (pro RoI) über K + 1-Klassen: \(p = (p_0, \dots, p_K)\), berechnet durch einen Softmax über die K + 1-Ausgänge einer vollständig verbundenen Schicht. |
| \(v\) | Wahre Begrenzungsrahmen \(v = (v_x, v_y, v_w, v_h)\). |
| \(t^u\) | Vorhergesagte Korrektur des Begrenzungsrahmens, \(t^u = (t^u_x, t^u_y, t^u_w, t^u_h)\). Siehe oben. |
Die Verlustfunktion fasst die Kosten für die Klassifizierung und Bounding-Box-Vorhersage zusammen: \(\mathcal{L} = \mathcal{L}_\text{cls} + \mathcal{L}_\text{box}\). Für „Hintergrund“ -RoI wird \(\mathcal{L}_\text{box}\) von der Indikatorfunktion \(\mathbb{1} \) ignoriert, definiert als:
\ = \begin{cases} 1 & \text{if } u \geq 1\\ 0 & \text{otherwise}\end{cases}\]
Die Gesamtverlustfunktion ist:
\ \mathcal{L}_\text{box}(t^u, v) \\\mathcal{L}_\text{cls}(p, u) &= -\log p_u \\\mathcal{L}_\text{box}(t^u, v) &= \sum_{i \in \{x, y, w, h\}} L_1^\text{smooth} (t^u_i – v_i)\end{align*}\]
Der Verlust der Begrenzungsbox \(\mathcal{ L}_{box}\) sollte die Differenz zwischen \(t^ u_i\) und \(v_i\) mit einer robusten Verlustfunktion messen. Der glatte L1-Verlust wird hier übernommen und es wird behauptet, dass er weniger empfindlich auf Ausreißer reagiert.
\
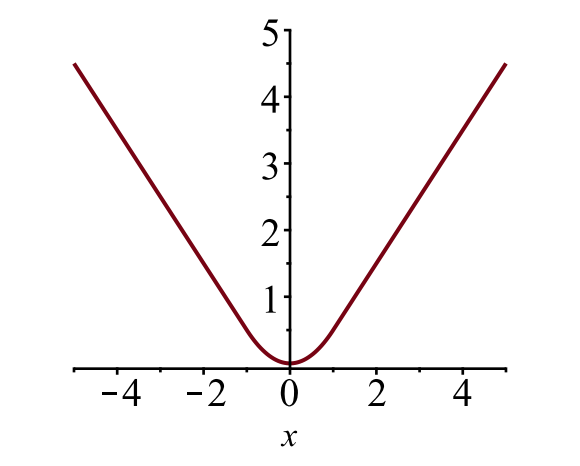
Abb. 6. Das Diagramm des glatten L1-Verlusts, \(y = L_1^\text{smooth}(x)\). (Bildquelle: Link)
Speed Bottleneck
Fast R-CNN ist sowohl in der Trainings- als auch in der Testzeit viel schneller. Die Verbesserung ist jedoch nicht dramatisch, da die Regionsvorschläge separat von einem anderen Modell generiert werden und das sehr teuer ist.
Schnelleres R-CNN
Eine intuitive Beschleunigungslösung besteht darin, den Regionsvorschlagsalgorithmus in das CNN-Modell zu integrieren. Schneller R-CNN (Ren et al., 2016) macht genau das: Konstruieren Sie ein einzelnes, einheitliches Modell, das aus RPN (Region Proposal Network) und Fast R-CNN mit gemeinsamen Faltungsmerkmalsschichten besteht.

Abb. 7. Eine Illustration des R-CNN-Modells. (Bildquelle: Ren et al., 2016)
Model Workflow
- Trainieren Sie ein CNN-Netzwerk für Bildklassifizierungsaufgaben.
- Feinabstimmung des RPN (Region Proposal Network) Ende-zu-Ende für die Aufgabe Region Proposal, die vom Pre-Train Image Classifier initialisiert wird. Positive Proben haben IoU (intersection-over-union) > 0.7, während negative Proben IoU < 0.3 .
- Schieben Sie ein kleines n x n räumliches Fenster über die conv Feature Map des gesamten Bildes.
- In der Mitte jedes Schiebefensters prognostizieren wir mehrere Regionen mit verschiedenen Skalen und Verhältnissen gleichzeitig. Ein Anker ist eine Kombination aus (Schiebefenstermitte, Maßstab, Verhältnis). Zum Beispiel 3 Skalen + 3 Verhältnisse => k=9 Anker an jeder Gleitposition.
- Trainieren Sie ein schnelles R-CNN-Objekterkennungsmodell unter Verwendung der vom aktuellen RPN generierten Vorschläge
- Verwenden Sie dann das schnelle R-CNN-Netzwerk, um das RPN-Training zu initialisieren. Optimieren Sie nur die RPN-spezifischen Ebenen, während Sie die gemeinsam genutzten Faltungsebenen beibehalten. Zu diesem Zeitpunkt haben RPN und das Erkennungsnetzwerk Faltungsschichten gemeinsam!
- Schließlich Feinabstimmung der einzigartigen Schichten von Fast R-CNN
- Schritt 4-5 kann bei Bedarf wiederholt werden, um RPN und Fast R-CNN alternativ zu trainieren.
Verlustfunktion
Faster R-CNN ist für eine Multi-Task-Verlustfunktion optimiert, ähnlich wie fast R-CNN.
| Symbol | Erklärung |
| \(p_i\) | Vorhergesagte Wahrscheinlichkeit, dass Anker i ein Objekt ist. |
| \(p^*_i\) | Ground truth Bezeichnung (binär), ob Anker i ein Objekt ist. |
| \(t_i\) | Vorhergesagte vier parametrisierte Koordinaten. |
| \(t^*_i\) | Grundwahrheitskoordinaten. |
| \(N_\text{cls}\) | Normalisierungsbegriff, im Papier auf Mini-Batch-Größe (~ 256) eingestellt. |
| \(N_\text{box}\) | Normalisierungsbegriff, eingestellt auf die Anzahl der Ankerstellen (~2400) im Papier. |
| \(\lambda\) | Ein Ausgleichsparameter, der in der Arbeit auf ~10 gesetzt ist (so dass beide Terme \(\mathcal{L}_\text{cls}\) und \(\mathcal{L}_\text{box}\) ungefähr gleich gewichtet sind). |
Die Multi-Task-Verlustfunktion kombiniert die Verluste der Klassifikation und der Bounding-Box-Regression:
\
wobei \(\mathcal{L}_\text{cls}\) die Log-Verlustfunktion über zwei Klassen ist, da wir eine Multi-Klassen-Klassifikation leicht in eine binäre Klassifikation übersetzen können, indem wir voraussagen, dass eine Stichprobe eine binäre Klassifikation ist zielobjekt versus nicht. \(L_1^\text{smooth}\) ist der glatte L1-Verlust.
\
Maske R-CNN
Maske R-CNN (Er et al., 2017) erweitert schnelleres R-CNN auf Bildsegmentierung auf Pixelebene. Der entscheidende Punkt besteht darin, die Klassifizierungs- und die Maskenvorhersageaufgaben auf Pixelebene zu entkoppeln. Basierend auf dem Framework von Faster R-CNN wurde parallel zu den vorhandenen Zweigen zur Klassifizierung und Lokalisierung ein dritter Zweig zur Vorhersage einer Objektmaske hinzugefügt. Der Maskenzweig ist ein kleines, vollständig verbundenes Netzwerk, das auf jeden RoI angewendet wird und eine Segmentierungsmaske Pixel für Pixel vorhersagt.
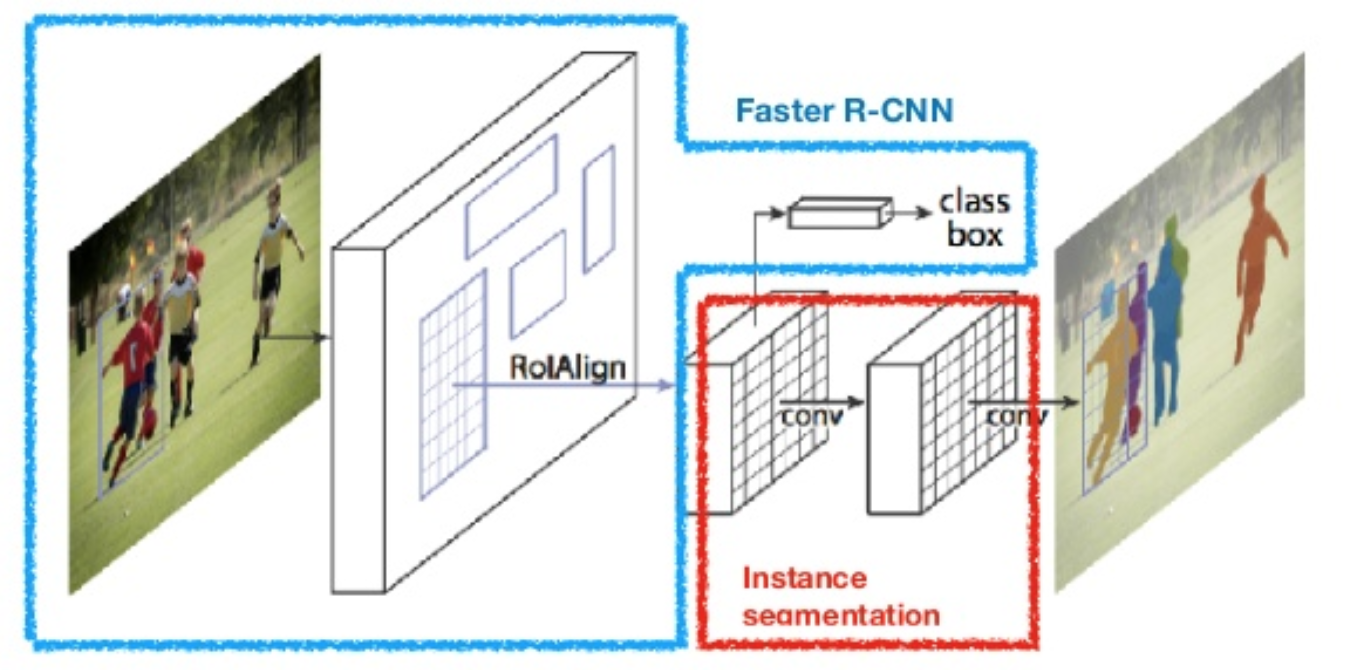
Abb. 8. Maske R-CNN ist schneller R-CNN-Modell mit Bildsegmentierung. (Bildquelle: Er et al., 2017)
Da die Segmentierung auf Pixelebene eine viel feinkörnigere Ausrichtung erfordert als Begrenzungsrahmen, verbessert mask R-CNN die RoI-Pooling-Ebene (mit dem Namen „RoIAlign layer“), sodass die RoI besser und präziser auf die Regionen des Originalbilds abgebildet werden kann.

Abb. 9. Vorhersagen von Maske R-CNN auf COCO Test Set. (Bildquelle: Er et al., 2017)
RoIAlign
Die RoIAlign-Ebene wurde entwickelt, um die durch Quantisierung im RoI-Pooling verursachte Ortsverschiebung zu beheben. RoIAlign entfernt die Hash-Quantisierung, z. B. durch Verwendung von x / 16 anstelle von , damit die extrahierten Features ordnungsgemäß mit den Eingabepixeln ausgerichtet werden können. Die bilineare Interpolation wird zur Berechnung der Gleitkomma-Positionswerte in der Eingabe verwendet.
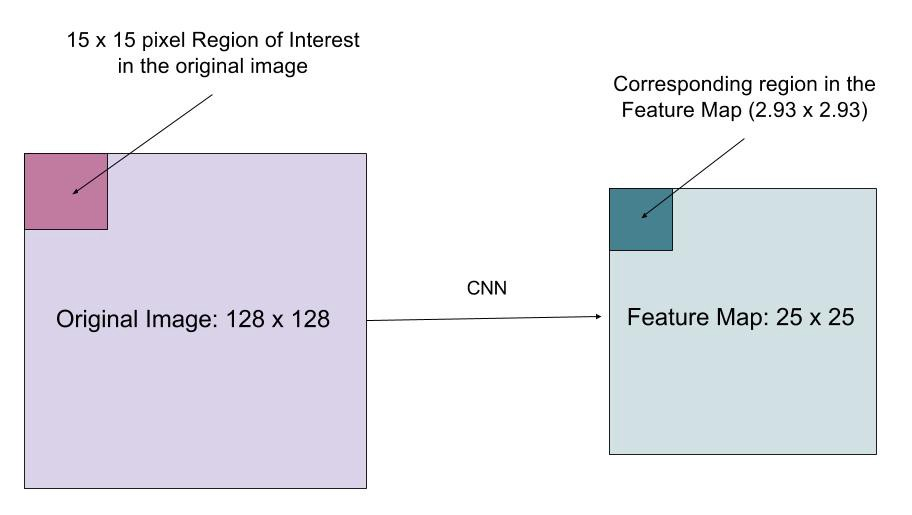
Abb. 10. Eine Region von Interesse wird genau vom Originalbild auf die Merkmalskarte abgebildet, ohne auf Ganzzahlen aufzurunden. (Bildquellen: link)
Verlustfunktion
Die Multi-Task-Verlustfunktion von Mask R-CNN kombiniert den Verlust von Klassifizierungs-, Lokalisierungs- und Segmentierungsmaske: \(\mathcal{L} = \mathcal{L}_\text{cls} + \mathcal{L}_\text{box} + \mathcal{L}_\text{mask}\), wobei \(\mathcal{L}_\text{cls}\) und \(\mathcal{L}_\text{box} }\) sind die gleichen wie in schnelleren R-CNN.
Der Maskenzweig erzeugt eine Maske der Dimension m x m für jeden RoI und jede Klasse; Insgesamt K Klassen. Somit ist die Gesamtausgabe der Größe \(K \ cdot m^ 2\). Da das Modell versucht, für jede Klasse eine Maske zu lernen, gibt es keinen Wettbewerb zwischen den Klassen zum Generieren von Masken.
\(\mathcal{L}_\text{mask}\) ist definiert als der durchschnittliche binäre Kreuzentropieverlust, der nur die k-te Maske einschließt, wenn die Region der Grundwahrheitsklasse k zugeordnet ist.
\\]
wobei \(y_{ij}\) die Bezeichnung einer Zelle (i, j) in der wahren Maske für die Region der Größe m x m ist; \(\hat{y}_{ij}^k\) ist der vorhergesagte Wert derselben Zelle in der Maske gelernt für die Grundwahrheit Klasse k.
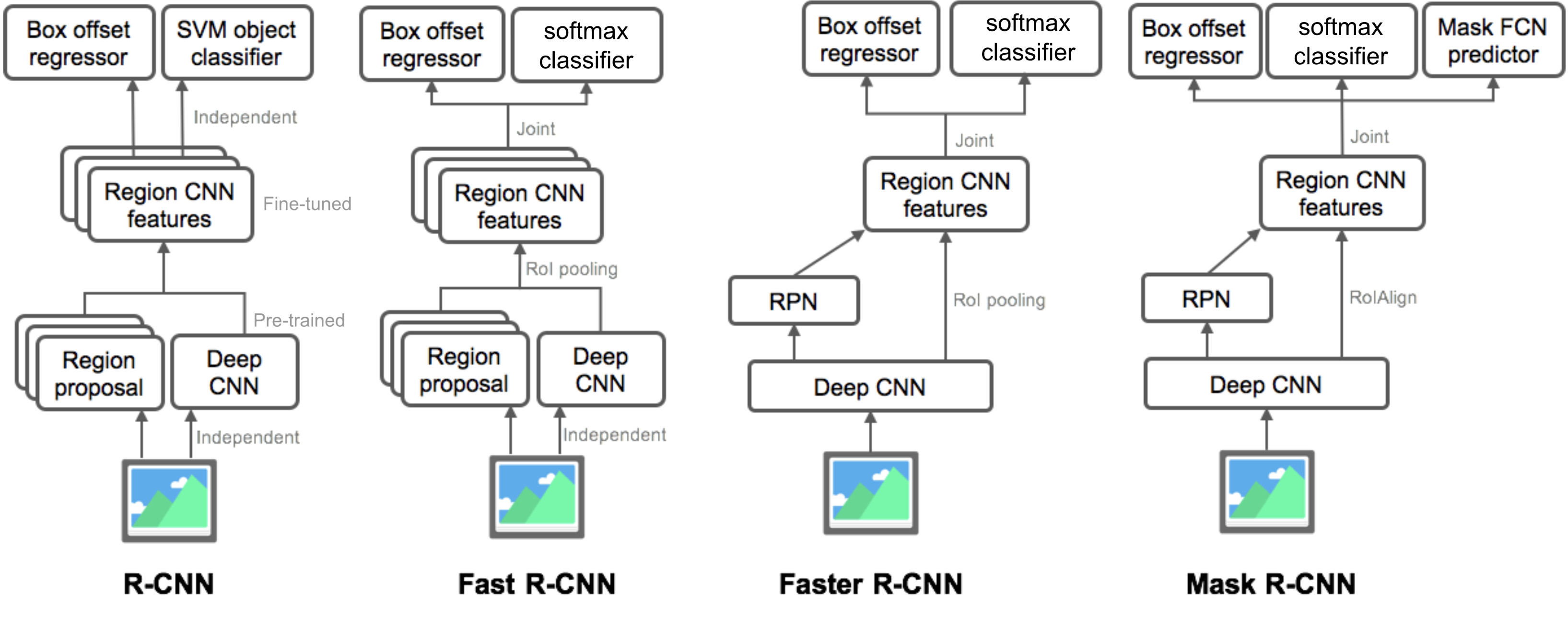
Zusammenfassung der Modelle der R-CNN-Familie
Hier illustriere ich Modellentwürfe von R-CNN, Fast R-CNN, Faster R-CNN und Mask R-CNN. Sie können verfolgen, wie sich ein Modell zur nächsten Version entwickelt, indem Sie die kleinen Unterschiede vergleichen.
Zitiert als:
@article{weng2017detection3, title = "Object Detection for Dummies Part 3: R-CNN Family", author = "Weng, Lilian", journal = "lilianweng.github.io/lil-log", year = "2017", url = "http://lilianweng.github.io/lil-log/2017/12/31/object-recognition-for-dummies-part-3.html"}Referenz
Ross Girshick, Jeff Donahue, Trevor Darrell und Jitendra Malik. „Umfangreiche Funktionshierarchien für genaue Objekterkennung und semantische Segmentierung.“ In Proc. IEEE Conf. über Computer Vision und Mustererkennung (CVPR), S. 580-587. 2014.
Ross Girshick. „Schnelle R-CNN.“ In Proc. In: IEEE Intl. Conf. über Computer Vision, S. 1440-1448. 2015.
Shaoqing Ren, Kaiming He, Ross Girshick und Jian Sun. „Faster R-CNN: Auf dem Weg zur Echtzeit-Objekterkennung mit regionalen Netzwerken.“ In Fortschritte in neuronalen Informationsverarbeitungssystemen (NIPS), S. 91-99. 2015.
Kaiming He, Georgia Gkioxari, Piotr Dollár und Ross Girshick. „Maske R-CNN.“ arXiv preprint arXiv:1703.06870, 2017.
Joseph Redmon, Santosh Divvala, Ross Girshick und Ali Farhadi. „Man schaut nur einmal hin: Einheitliche Objekterkennung in Echtzeit.“ In Proc. IEEE Conf. über Computer Vision und Mustererkennung (CVPR), S. 779-788. 2016.
„Eine kurze Geschichte von CNNs in der Bildsegmentierung: Von R-CNN zu Mask R-CNN“ von Athelas.
Glatter L1-Verlust: https://github.com/rbgirshick/py-faster-rcnn/files/764206/SmoothL1Loss.1.pdf