Detección de objetos para maniquíes Parte 3: Familia de R-CNN
En la Parte 3, examinaríamos cuatro modelos de detección de objetos: R-CNN, R-CNN Rápida, R-CNN más rápida y R-CNN de máscara. Estos modelos están muy relacionados y las nuevas versiones muestran una gran mejora de velocidad en comparación con las anteriores.
En la serie de «Detección de objetos para Maniquíes», comenzamos con conceptos básicos en el procesamiento de imágenes, como vectores de gradiente y HOG, en la Parte 1. Luego, en la Parte 2, presentamos diseños clásicos de arquitectura convolucional de redes neuronales para clasificación y modelos pioneros para reconocimiento de objetos, Sobrealimentación y DPM. En el tercer post de esta serie, estamos a punto de revisar un conjunto de modelos de la familia R-CNN («CNN basada en la región»).
Enlaces a todas las publicaciones de la serie: .
Aquí hay una lista de artículos cubiertos en este post 😉
| Model | Goal | Resources |
| R-CNN | Object recognition | |
| Fast R-CNN | Object recognition | |
| Faster R-CNN | Object recognition | |
| Mask R-CNN | Image segmentation |
- R-CNN
- Modelo de flujo de trabajo
- Regresión de caja delimitadora
- Trucos comunes
- Cuello de botella de velocidad
- Fast R-CNN
- Pooling de RoI
- Flujo de trabajo del modelo
- Función de pérdida
- Cuello de botella de velocidad
- R-CNN más rápido
- Modelo de flujo de trabajo
- Función de pérdida
- Máscara R-CNN
- RoIAlign
- Función de pérdida
- Resumen de modelos de la familia R-CNN
- Referencia
R-CNN
R-CNN (Girshick et al., 2014) is short for «Region-based Convolutional Neural Networks». The main idea is composed of two steps. En primer lugar, mediante la búsqueda selectiva, identifica un número manejable de candidatos de región de objeto de caja delimitadora («región de interés» o «RoI»). Y luego extrae características de CNN de cada región de forma independiente para su clasificación.
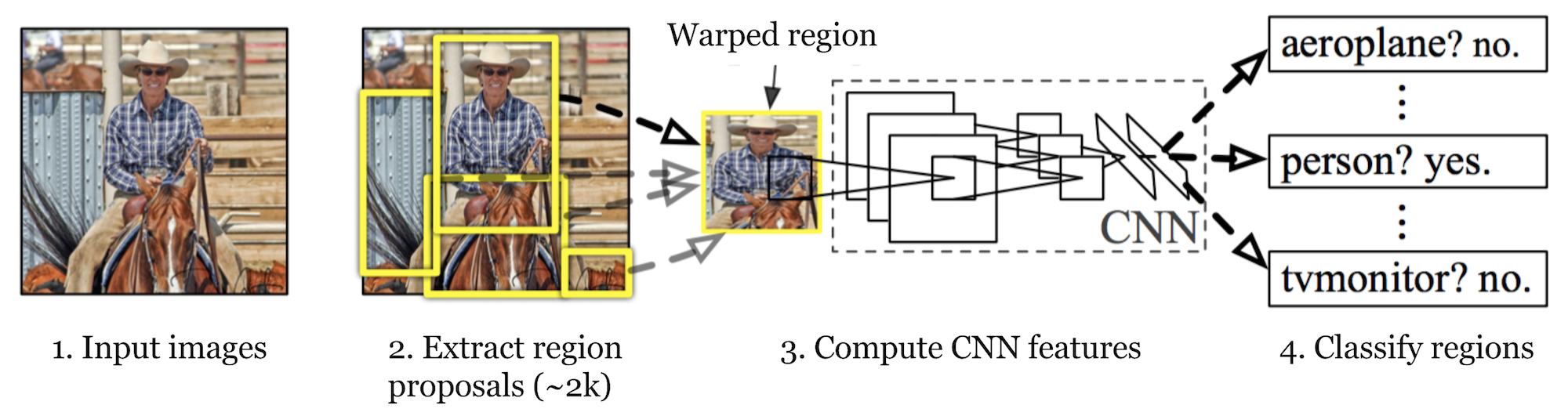
Fig. 1. La arquitectura de R-CNN. (Fuente de la imagen: Girshick et al., 2014)
Modelo de flujo de trabajo
El funcionamiento de R-CNN se puede resumir de la siguiente manera:
- Preentrenar una red CNN en tareas de clasificación de imágenes; por ejemplo, VGG o ResNet entrenados en el conjunto de datos de ImageNet. La tarea de clasificación involucra N clases.
NOTA: Puede encontrar un AlexNet preentrenado en Caffe Model Zoo. No creo que se pueda encontrar en Tensorflow, pero la biblioteca de modelos Tensorflow-slim proporciona ResNet, VGG y otros preentrenados.
- Proponga regiones de interés independientes de la categoría mediante búsqueda selectiva (~2k candidatos por imagen). Esas regiones pueden contener objetos de destino y son de diferentes tamaños.Los candidatos de la región
- están deformados para tener un tamaño fijo según lo requiera CNN.
- Continuar afinando la CNN en regiones de propuestas deformadas para las clases K + 1; La clase adicional se refiere al fondo (sin objeto de interés). En la etapa de ajuste fino, deberíamos usar una tasa de aprendizaje mucho más pequeña y el mini-lote muestra en exceso los casos positivos porque la mayoría de las regiones propuestas son solo un fondo.
- Dada cada región de imagen, una propagación hacia adelante a través de la CNN genera un vector de características. Este vector de características es consumido por un SVM binario entrenado para cada clase de forma independiente.
Las muestras positivas son regiones propuestas con umbral de superposición de IoU (intersección sobre unión) >= 0.3, y las muestras negativas son otras irrelevantes. - Para reducir los errores de localización, se entrena un modelo de regresión para corregir la ventana de detección prevista en el desplazamiento de corrección de cuadro delimitador mediante funciones de CNN.
Regresión de caja delimitadora
Dada una coordenada de caja delimitadora predicha \(\mathbf{p} = (p_x, p_y, p_w, p_h)\) (coordenada central, ancho, alto) y sus coordenadas de caja de verdad de tierra correspondientes \(\mathbf{g} = (g_x, g_y, g_w, g_h)\) , el regresor está configurado para aprender la transformación invariante de escala entre dos centros y la transformación de escala logarítmica entre anchos y alturas. Todas las funciones de transformación toman \(\mathbf{p}\) como entrada.
\
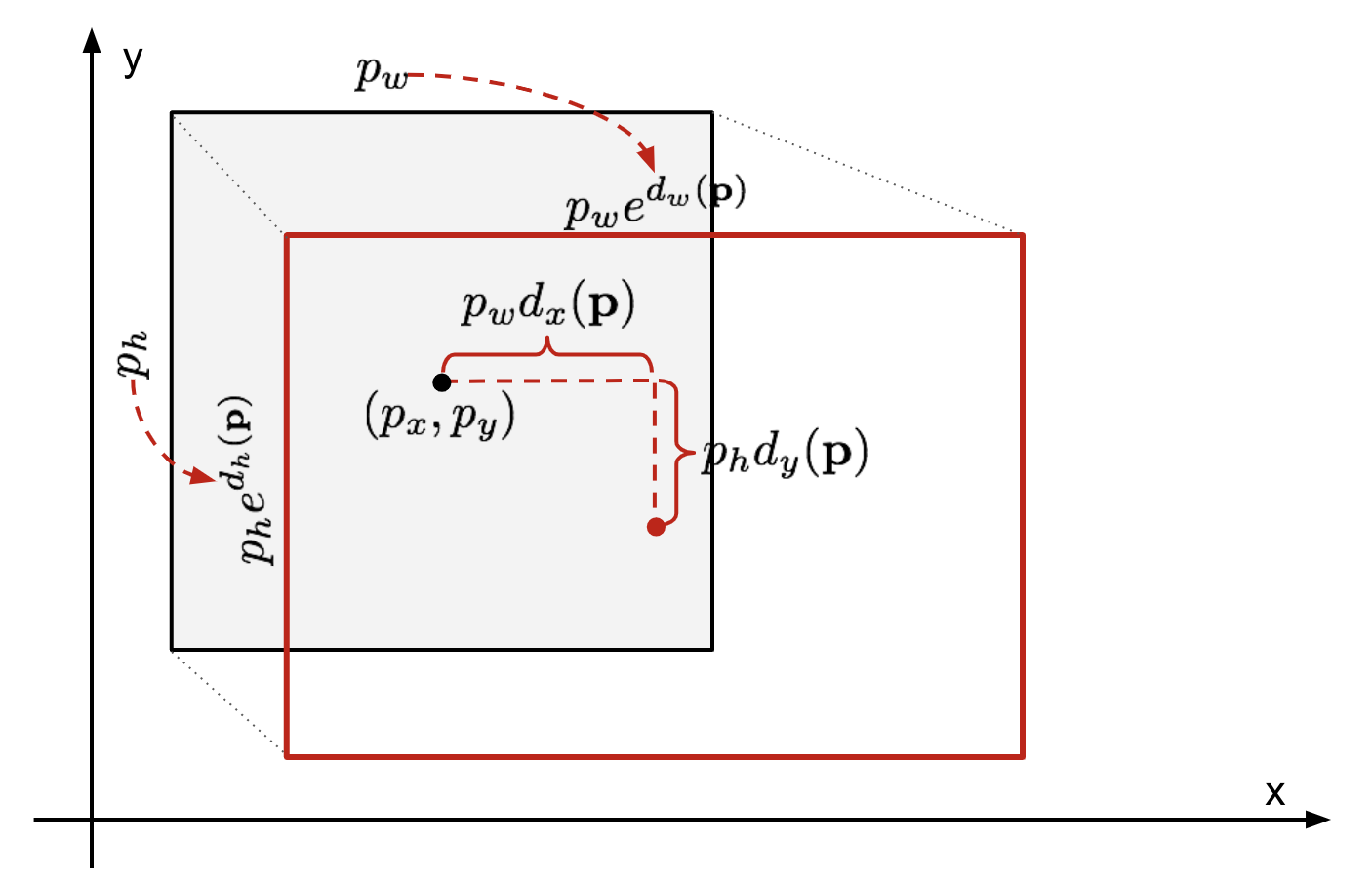
Fig. 2. Ilustración de la transformación entre cajas delimitadoras de verdad predichas y de tierra.
Un beneficio obvio de aplicar tal transformación es que todas las funciones de corrección de caja delimitadora, \(d_i (\mathbf{p})\) donde \(i \ in \ { x, y, w, h\}\), pueden tomar cualquier valor intermedio . Los objetivos para que aprendan son:
\
Un modelo de regresión estándar puede resolver el problema minimizando la pérdida de ESS con regularización:
\
El término de regularización es crítico aquí y el artículo de RCNN eligió el mejor λ mediante validación cruzada. También es de destacar que no todas las cajas delimitadoras predichas tienen cajas de verdad de tierra correspondientes. Por ejemplo, si no hay superposición, no tiene sentido ejecutar regresión bbox. Aquí, solo se guarda una caja predicha con una caja de verdad de tierra cercana con al menos 0,6 pagarés para entrenar el modelo de regresión de bbox.
Trucos comunes
Varios trucos se utilizan comúnmente en RCNN y otros modelos de detección.
Supresión no máxima
Es probable que el modelo pueda encontrar varios cuadros delimitadores para el mismo objeto. La supresión no máxima ayuda a evitar la detección repetida de la misma instancia. Después de obtener un conjunto de cajas delimitadoras coincidentes para la misma categoría de objeto: Ordene todas las cajas delimitadoras por puntuación de confianza.Deseche las cajas con puntuaciones de confianza bajas.Mientras quede algún cuadro delimitador, repita lo siguiente:Seleccione con avidez el que tenga la puntuación más alta.Omita las casillas restantes con pagarés altos (es decir, > 0.5) con una seleccionada previamente.

Fig. 3. Múltiples cajas delimitadoras detectan el coche en la imagen. Después de una supresión no máxima, solo quedan los mejores y el resto se ignoran, ya que tienen grandes superposiciones con el seleccionado. (Fuente de la imagen: DPM paper)
Minería de negativos duros
Consideramos los cuadros delimitadores sin objetos como ejemplos negativos. No todos los ejemplos negativos son igualmente difíciles de identificar. Por ejemplo, si contiene un fondo vacío puro, es probable que sea un «negativo fácil»; pero si la caja contiene una textura ruidosa extraña u objeto parcial, podría ser difícil de reconocer y estos son «negativos duros».
Los ejemplos negativos duros se clasifican mal fácilmente. Podemos encontrar explícitamente esas muestras de falsos positivos durante los bucles de entrenamiento e incluirlas en los datos de entrenamiento para mejorar el clasificador.
Cuello de botella de velocidad
Mirando a través de los pasos de aprendizaje de R-CNN, puede descubrir fácilmente que entrenar un modelo de R-CNN es costoso y lento, ya que los siguientes pasos implican mucho trabajo:
- Realizar una búsqueda selectiva para proponer candidatos de 2000 regiones para cada imagen;
- Generar el vector de características de CNN para cada región de imagen (N imágenes * 2000).
- Todo el proceso involucra tres modelos por separado sin mucha computación compartida: la red neuronal convolucional para la clasificación de imágenes y extracción de características; el clasificador SVM superior para identificar objetos objetivo; y el modelo de regresión para apretar cajas delimitadoras de regiones.
Fast R-CNN
Para hacer que R-CNN sea más rápido, Girshick (2015) mejoró el procedimiento de entrenamiento unificando tres modelos independientes en un marco de trabajo entrenado conjuntamente y aumentando los resultados de cómputo compartidos, denominados Fast R-CNN. En lugar de extraer vectores de características de CNN de forma independiente para cada propuesta de región, este modelo los agrega en un pase de avance de CNN sobre toda la imagen y las propuestas de regiones comparten esta matriz de características. Luego, la misma matriz de características se ramifica para usarse para aprender el clasificador de objetos y el regresor de caja delimitadora. En conclusión, el uso compartido de computación acelera R-CNN.
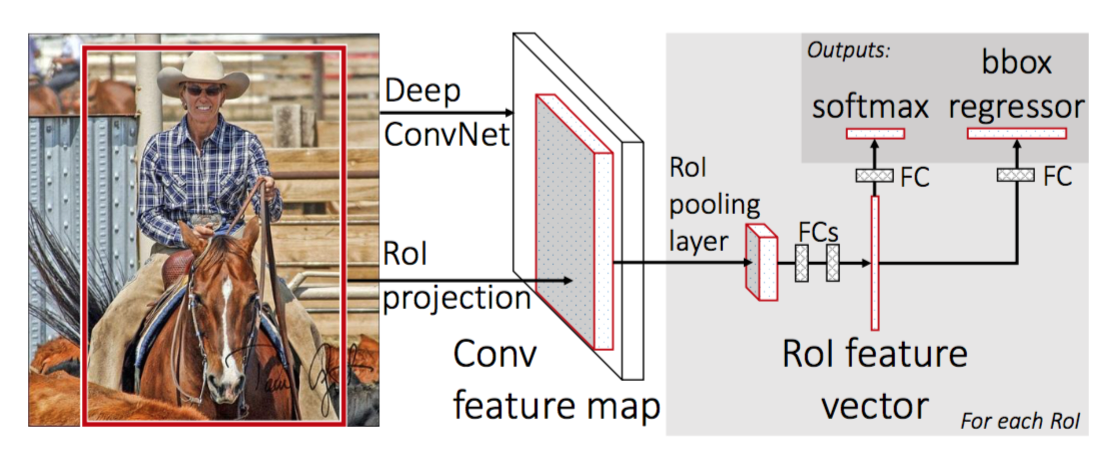
Fig. 4. La arquitectura de Fast R-CNN. (Fuente de la imagen: Girshick, 2015)
Pooling de RoI
Es un tipo de pooling máximo para convertir entidades en la región proyectada de la imagen de cualquier tamaño, h x w, en una pequeña ventana fija, H x W. La región de entrada se divide en cuadrículas H x W, aproximadamente cada subventana de tamaño h/H x w/W. A continuación, aplique el pooling máximo en cada cuadrícula.
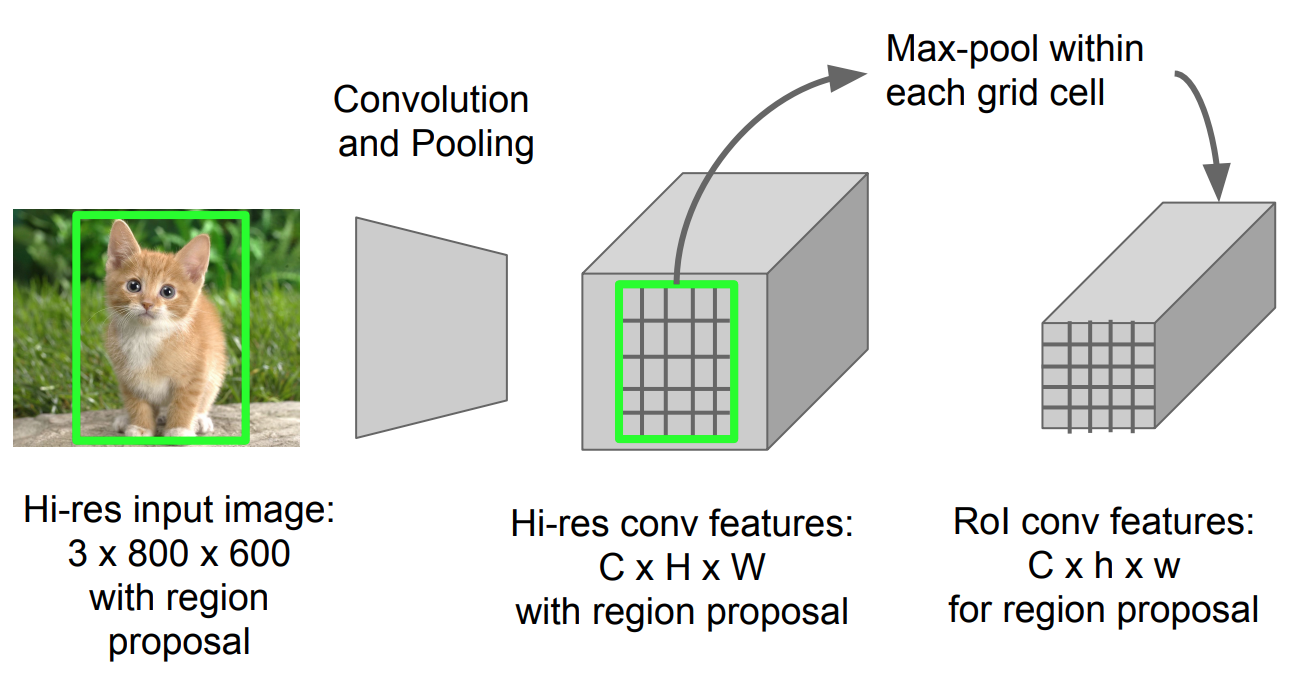
Fig. 5. Roi pooling (Fuente de la imagen: diapositivas de Stanford CS231n.)
Flujo de trabajo del modelo
La rapidez con que funciona R-CNN se resume de la siguiente manera; muchos pasos son los mismos que en R-CNN:
- Primero, entrenar previamente una red neuronal convolucional en tareas de clasificación de imágenes.
- Proponer regiones mediante búsqueda selectiva (~2k candidatos por imagen).
- Alterar la CNN preentrenada:
- Reemplazar la última capa de agrupación max de la CNN preentrenada por una capa de agrupación RoI. La capa de agrupación de RoI genera vectores de entidades de longitud fija de propuestas de regiones. Compartir la computación de CNN tiene mucho sentido, ya que muchas propuestas de regiones de las mismas imágenes están muy superpuestas.
- Reemplace la última capa completamente conectada y la última capa de softmax (clases K) por una capa completamente conectada y softmax sobre clases K + 1.
- Finalmente, el modelo se ramifica en dos capas de salida:
- Un estimador softmax de clases K + 1 (igual que en R-CNN, +1 es la clase «background»), que genera una distribución de probabilidad discreta por RoI.
- Un modelo de regresión de caja delimitadora que predice compensaciones relativas al RoI original para cada una de las clases K.
Función de pérdida
El modelo está optimizado para una pérdida combinando dos tareas (clasificación + localización):
| Símbolo | Explicación |
| \(u\) | Etiqueta de clase verdadera, \(u \in 0, 1, \dots, K\); por convención, la clase de fondo general tiene \(u = 0\). |
| \(p\) | Distribución de probabilidad discreta(por retorno de la inversión) sobre clases K + 1: \(p = (p_0, \dots, p_K)\), calculada por un softmax sobre las salidas K + 1 de una capa completamente conectada. |
| \(v\) | True cuadro delimitador \(v = (v_x, v_y, v_w, v_h)\). |
| \(t^u\) | Predicción del cuadro delimitador de la corrección, \(t^u = (t^u_x, t^u_y, t^u_w, t^u_h)\). Véase supra. |
La función de pérdida resume el costo de la clasificación y la predicción del cuadro delimitador: \(\mathcal{L} = \mathcal{L}_\text{cls} + \mathcal{L}_\text{box}\). Para el RoI de «fondo», \(\mathcal{L}_\text{box}\) es ignorado por la función de indicador \(\mathbb{1} \), definida como:
\ = \begin{cases} 1 & \text{if } u \geq 1\\ 0 & \text{otherwise}\end{cases}\]
La función de pérdida general es:
\ \mathcal{L}_\text{box}(t^u, v) \\\mathcal{L}_\text{cls}(p, u) &= -\log p_u \\\mathcal{L}_\text{box}(t^u, v) &= \sum_{i \in \{x, y, w, h\}} L_1^\text{smooth} (t^u_i – v_i)\end{align*}\]
El límite la pérdida de caja \(\mathcal{L}_{box}\) debe medir la diferencia entre \(t^u_i\) y \(v_i\) utilizando una función de pérdida robusta. La pérdida lisa de L1 se adopta aquí y se afirma que es menos sensible a los valores atípicos.
\
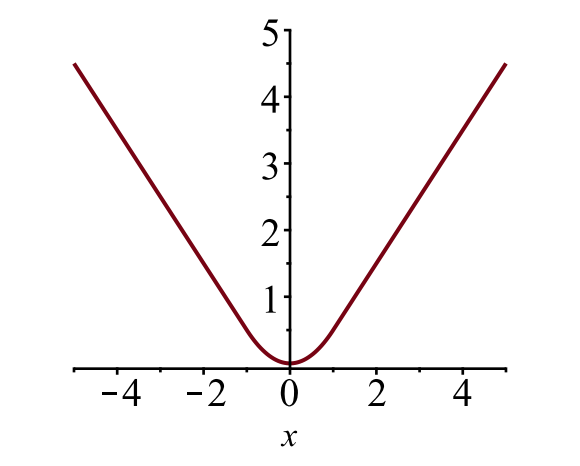
Fig. 6. La gráfica de pérdida L1 suave, \(y = L_1^ \ text{suave} (x)\). (Fuente de la imagen: enlace)
Cuello de botella de velocidad
Fast R-CNN es mucho más rápido tanto en el tiempo de entrenamiento como en el de prueba. Sin embargo, la mejora no es dramática porque las propuestas de la región se generan por separado por otro modelo y eso es muy costoso.
R-CNN más rápido
Una solución de aceleración intuitiva es integrar el algoritmo de propuesta de región en el modelo CNN. R-CNN más rápido (Ren et al., 2016) está haciendo exactamente esto: construir un modelo único y unificado compuesto por RPN (red de propuesta de región) y R-CNN rápido con capas convolucionales de entidades compartidas.

Fig. 7. Una ilustración del modelo R-CNN más rápido. (Fuente de la imagen: Ren et al., 2016)
Modelo de flujo de trabajo
- Preentrene una red CNN en tareas de clasificación de imágenes.
- Ajuste la RPN (red de propuesta de región) de extremo a extremo para la tarea de propuesta de región, que se inicializa con el clasificador de imágenes previo al tren. Las muestras positivas tienen IoU (intersección sobre unión) > 0.7, mientras que las muestras negativas tienen IoU < 0.3.
- Deslice una pequeña ventana espacial n x n sobre el mapa de entidades conv de toda la imagen.
- En el centro de cada ventana deslizante, predecimos múltiples regiones de varias escalas y proporciones simultáneamente. Un ancla es una combinación de (centro de ventana deslizante, escala, relación). Por ejemplo, 3 escalas + 3 relaciones = > k = 9 anclajes en cada posición deslizante.
- Entrene un modelo de detección de objetos R-CNN rápido utilizando las propuestas generadas por la RPN actual
- Luego use la red R-CNN Rápida para inicializar el entrenamiento RPN. Manteniendo las capas convolucionales compartidas, solo afine las capas específicas de RPN. En esta etapa, RPN y la red de detección tienen capas convolucionales compartidas.
- Finalmente, ajuste las capas únicas de R-CNN rápida
- El paso 4-5 se puede repetir para entrenar RPN y R-CNN rápida alternativamente si es necesario.
Función de pérdida
La R-CNN más rápida está optimizada para una función de pérdida de tareas múltiples, similar a la R-CNN rápida.
| Símbolos | Explicación |
| \(p_i\) | Predicción de la probabilidad de anclaje yo siendo un objeto. |
| \(p^ * _i\) | Etiqueta de verdad de tierra (binaria) de si el ancla i es un objeto. |
| \(t_i\) | Predicción cuatro con parámetros de coordenadas. |
| \(t^*_i\) | Tierra la verdad coordenadas. |
| \(N_\text{cls}\) | Término de normalización, establecido en tamaño de mini-lote (~256) en el documento. |
| \(N_\text{box}\) | Término de normalización, establecido en el número de ubicaciones de anclaje (~2400) en el documento. |
| \(\lambda\) | Un parámetro de equilibrio, establecido en ~10 en el documento (de modo que los términos \(\mathcal{L}_\text{cls}\) y \(\mathcal{L}_\text{box}\) tienen aproximadamente la misma ponderación). |
La función de pérdida de tareas múltiples combina las pérdidas de clasificación y la regresión de caja delimitadora:
\
donde \(\mathcal{L}_\text{cls}\) es la función de pérdida de registro en dos clases, ya que podemos traducir fácilmente una clasificación de varias clases en una clasificación binaria prediciendo una muestra es un objeto de destino o no. \(L_1^ \ text{smooth}\) es la pérdida L1 suave.
\
Máscara R-CNN
Máscara R-CNN (He et al., 2017) amplía la velocidad de R-CNN a la segmentación de imágenes a nivel de píxel. El punto clave es desacoplar la clasificación y las tareas de predicción de máscara a nivel de píxel. Basado en el marco de R-CNN más rápido, agregó una tercera rama para predecir una máscara de objeto en paralelo con las ramas existentes para la clasificación y localización. La rama de máscara es una pequeña red completamente conectada aplicada a cada RoI, que predice una máscara de segmentación de forma píxel a píxel.
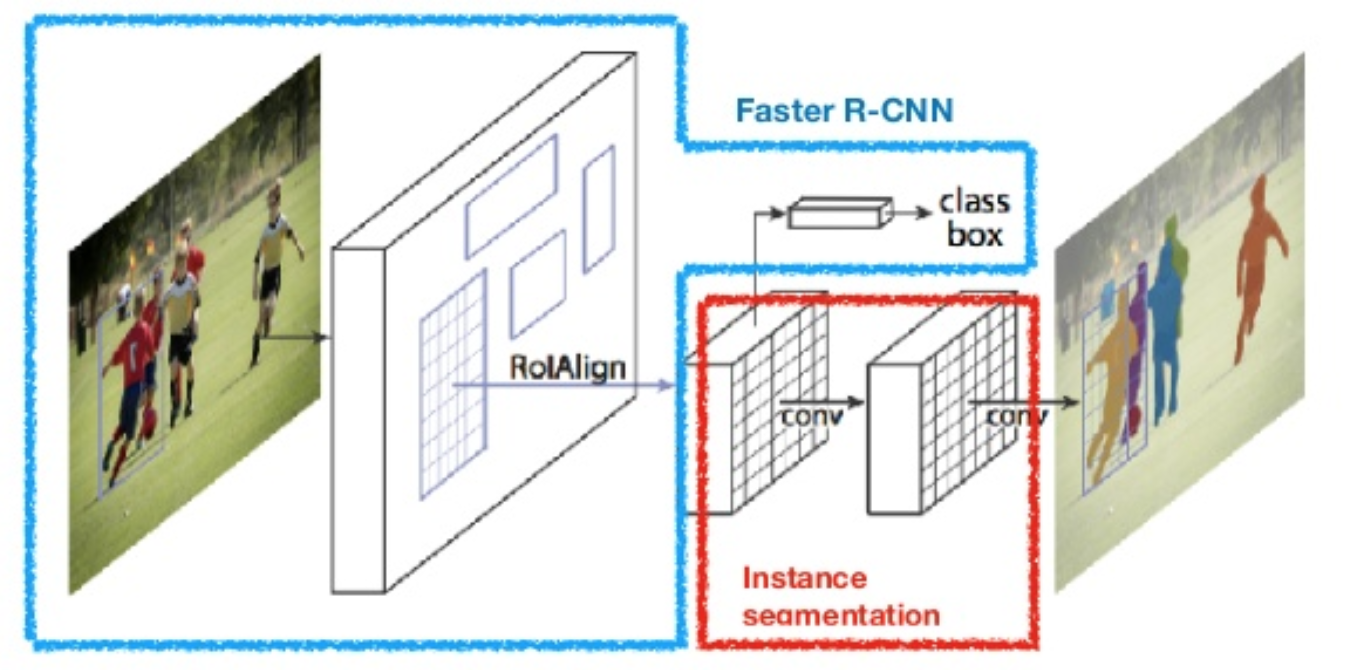
Fig. 8. Máscara R-CNN es un modelo R-CNN más rápido con segmentación de imágenes. (Fuente de la imagen: He et al., 2017)
Debido a que la segmentación a nivel de píxel requiere una alineación mucho más precisa que los cuadros delimitadores, mask R-CNN mejora la capa de agrupación de retorno de la inversión (denominada «capa de alineación de roi») para que el retorno de la inversión se pueda asignar mejor y con mayor precisión a las regiones de la imagen original.

Fig. 9. Predicciones de Mask R-CNN en el set de prueba COCO. (Fuente de la imagen: He et al., 2017)
RoIAlign
La capa RoIAlign está diseñada para corregir la desalineación de ubicación causada por la cuantización en la agrupación de RoI. RoIAlign elimina la cuantización de hash, por ejemplo, utilizando x / 16 en lugar de , para que las entidades extraídas se puedan alinear correctamente con los píxeles de entrada. La interpolación bilineal se utiliza para calcular los valores de ubicación de punto flotante en la entrada.
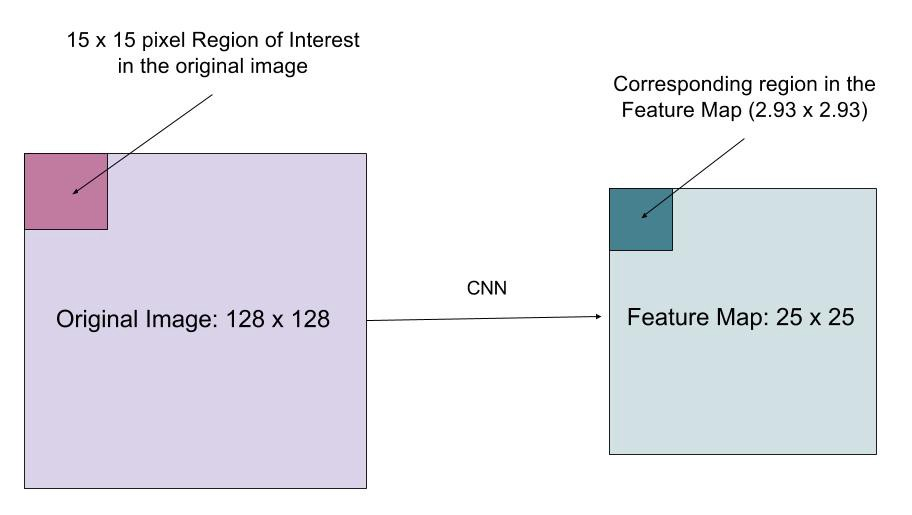
Fig. 10. Una región de interés se asigna con precisión desde la imagen original al mapa de entidades sin redondear a enteros. (Fuente de la imagen: enlace)
Función de pérdida
La función de pérdida de tareas múltiples de Mask R-CNN combina la pérdida de clasificación, localización y máscara de segmentación: \(\mathcal{L} = \mathcal{L}_\text{cls} + \mathcal{L}_\text{box} + \mathcal{L}_\text{mask}\), donde \(\mathcal{L}_\text{cls}\) y \(\mathcal{L}_\text{box}\) son los mismos que en R-CNN más rápido.
La rama de máscara genera una máscara de dimensión m x m para cada RoI y cada clase; clases K en total. Por lo tanto, la salida total es de tamaño \(K \cdot m^2\). Debido a que el modelo está tratando de aprender una máscara para cada clase, no hay competencia entre las clases para generar máscaras.
\(\mathcal{L}_\text{máscara}\) se define como la pérdida binaria media de entropía cruzada, solo incluye la máscara k-ésima si la región está asociada con la clase de verdad de tierra k.
\\]
donde \(y_{ij}\) es la etiqueta de una celda (i, j) en la máscara verdadera para la región de tamaño m x m; \(\hat{y}_{ij}^k\) es el valor predicho de la misma celda en la máscara aprendido para la verdad de la tierra clase k.
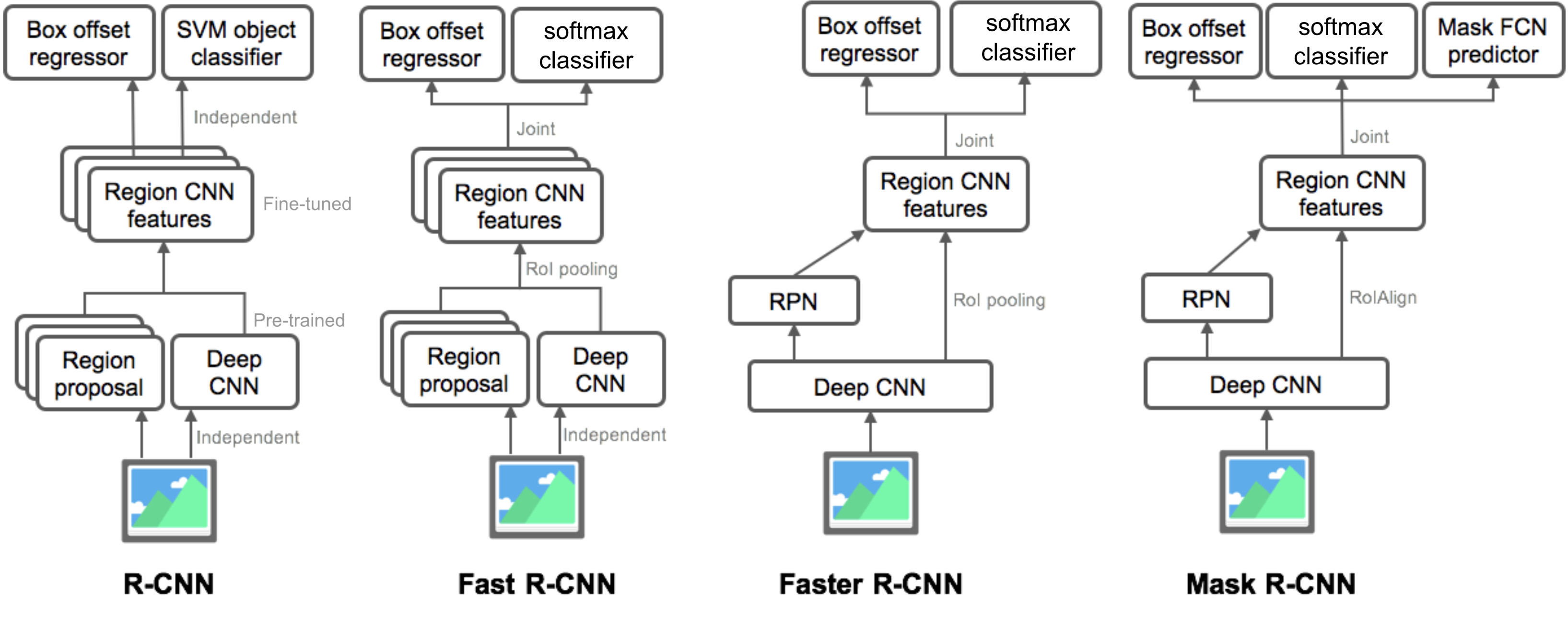
Resumen de modelos de la familia R-CNN
Aquí ilustro los diseños de modelos de R-CNN, Fast R-CNN, Faster R-CNN y Mask R-CNN. Puede realizar un seguimiento de cómo evoluciona un modelo a la siguiente versión comparando las pequeñas diferencias.
cita:
@article{weng2017detection3, title = "Object Detection for Dummies Part 3: R-CNN Family", author = "Weng, Lilian", journal = "lilianweng.github.io/lil-log", year = "2017", url = "http://lilianweng.github.io/lil-log/2017/12/31/object-recognition-for-dummies-part-3.html"}Referencia
Ross Girshick, Jeff Donahue, Trevor Darrell, y Jitendra Malik. «Jerarquías de funciones enriquecidas para la detección precisa de objetos y la segmentación semántica.»In Proc. IEEE Conf. on computer vision and pattern recognition (CVPR), pp.580-587. 2014.Ross Girshick. «Fast R-CNN.»In Proc. IEEE Intl. Conf. on computer vision, pp. 1440-1448. 2015.Shaoqing Ren, Kaiming He, Ross Girshick y Jian Sun. «R-CNN más rápido: Hacia la detección de objetos en tiempo real con redes de propuesta de región.»En Advances in neural information processing systems (NIPS), pp.91-99. 2015.
Kaiming He, Georgia Gkioxari, Piotr Dollár y Ross Girshick. «Máscara R-CNN.»arXiv preprint arXiv: 1703.06870, 2017.
Joseph Redmon, Santosh Divvala, Ross Girshick y Ali Farhadi. «Solo se mira una vez: Detección unificada de objetos en tiempo real.»In Proc. IEEE Conf. on computer vision and pattern recognition (CVPR), pp.779-788. 2016.
«A Brief History of CNNs in Image Segmentation: From R-CNN to Mask R-CNN» por Athelas.
Pérdida L1 suave: https://github.com/rbgirshick/py-faster-rcnn/files/764206/SmoothL1Loss.1.pdf