Détection d’objets pour les nuls Partie 3: Famille R-CNN
Dans la partie 3, nous examinerons quatre modèles de détection d’objets: R-CNN, R-CNN rapide, R-CNN plus rapide et Masque R-CNN. Ces modèles sont très liés et les nouvelles versions montrent une grande amélioration de la vitesse par rapport aux anciennes.
Dans la série « Détection d’objets pour les nuls », nous avons commencé avec des concepts de base en traitement d’image, tels que les vecteurs de gradient et HOG, dans la partie 1. Ensuite, nous avons introduit des conceptions classiques d’architecture de réseau neuronal convolutif pour la classification et des modèles pionniers pour la reconnaissance d’objets, la surcharge et le DPM, dans la partie 2. Dans le troisième article de cette série, nous sommes sur le point de passer en revue un ensemble de modèles de la famille R-CNN (« CNN basée sur la région »).
Liens vers tous les articles de la série : .
Voici une liste des articles couverts dans cet article 😉
| Model | Goal | Resources |
| R-CNN | Object recognition | |
| Fast R-CNN | Object recognition | |
| Faster R-CNN | Object recognition | |
| Mask R-CNN | Image segmentation |
- R-CNN
- Workflow du modèle
- Régression de la boîte englobante
- Astuces courantes
- Goulot d’étranglement de vitesse
- Fast R-CNN
- Mise en commun du RoI
- Workflow du modèle
- Fonction de perte
- Goulot d’étranglement de vitesse
- R-CNN plus rapide
- Workflow modèle
- Fonction de perte
- Masque R-CNN
- RoIAlign
- Fonction de perte
- Résumé des modèles de la famille R-CNN
- Référence
R-CNN
R-CNN (Girshick et al., 2014) is short for « Region-based Convolutional Neural Networks ». The main idea is composed of two steps. Tout d’abord, à l’aide d’une recherche sélective, il identifie un nombre gérable de candidats de région d’objet de la boîte englobante (« région d’intérêt » ou « RoI »). Et puis il extrait les fonctionnalités CNN de chaque région indépendamment pour la classification.
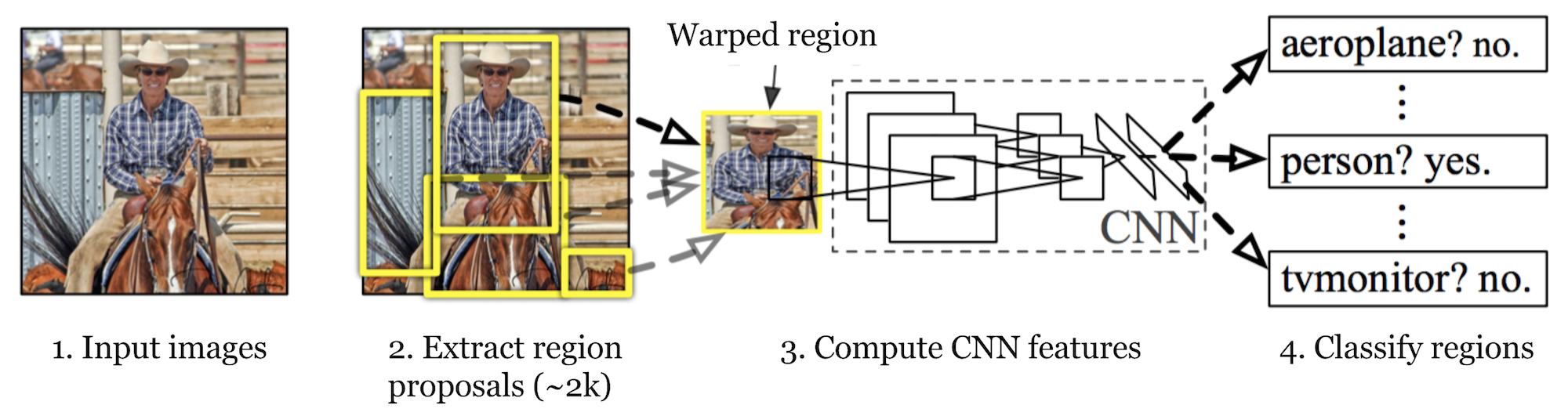
Fig. 1. L’architecture de R-CNN. (Source de l’image: Girshick et coll., 2014)
Workflow du modèle
Le fonctionnement de R-CNN peut être résumé comme suit :
- Pré-former un réseau CNN aux tâches de classification d’images ; par exemple, VGG ou ResNet formés sur l’ensemble de données ImageNet. La tâche de classification implique N classes.
REMARQUE: Vous pouvez trouver un AlexNet pré-formé dans le zoo modèle Caffe. Je ne pense pas que vous puissiez le trouver dans Tensorflow, mais la bibliothèque de modèles Tensorflow-slim fournit ResNet, VGG et autres pré-formés.
- Propose des régions d’intérêt indépendantes de la catégorie par recherche sélective (~2k candidats par image). Ces régions peuvent contenir des objets cibles et elles sont de tailles différentes.
- Les candidats de région sont déformés pour avoir une taille fixe comme requis par CNN.
- Continuez à affiner le CNN sur les régions de proposition déformées pour K + 1 classes; La classe supplémentaire fait référence à l’arrière-plan (aucun objet d’intérêt). Au stade de la mise au point, nous devrions utiliser un taux d’apprentissage beaucoup plus faible et le mini-lot suréchantillonne les cas positifs car la plupart des régions proposées ne sont que des antécédents.
- Étant donné chaque région d’image, une propagation vers l’avant à travers le CNN génère un vecteur d’entités. Ce vecteur d’entités est ensuite consommé par un SVM binaire entraîné pour chaque classe indépendamment.
Les échantillons positifs sont des régions proposées avec un seuil de chevauchement IoU (intersection sur union) >=0,3, et les échantillons négatifs ne sont pas pertinents pour les autres. - Pour réduire les erreurs de localisation, un modèle de régression est entraîné pour corriger la fenêtre de détection prévue sur le décalage de correction de la boîte englobante à l’aide des fonctionnalités CNN.
Régression de la boîte englobante
Étant donné une coordonnée de boîte englobante prédite \(\mathbf{p}=(p_x, p_y, p_w, p_h)\) (coordonnée centrale, largeur, hauteur) et ses coordonnées de boîte de vérité au sol correspondantes \(\mathbf{g} =(g_x, g_y, g_w, g_h)\), le régresseur est configuré pour apprendre la transformation invariante à l’échelle entre deux centres et la transformation à l’échelle largeurs et hauteurs. Toutes les fonctions de transformation prennent \(\mathbf{p}\) comme entrée.
\
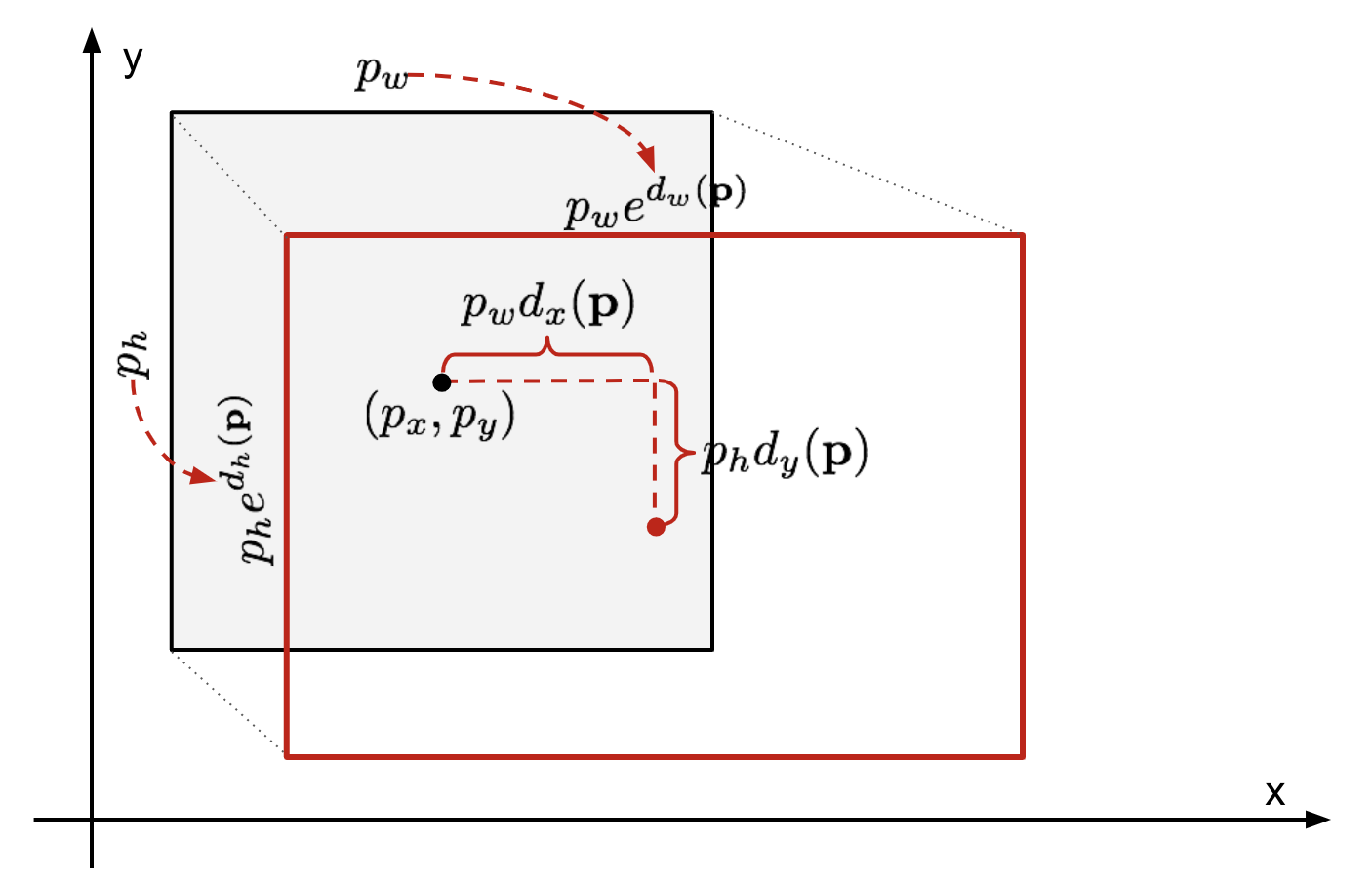
Fig. 2. Illustration de la transformation entre les boîtes englobantes de la vérité prédite et de la vérité au sol.
Un avantage évident de l’application d’une telle transformation est que toutes les fonctions de correction de la boîte englobante, \(d_i(\mathbf{p})\) où \(i\in\{x, y, w, h\}\), peuvent prendre n’importe quelle valeur entre. Les cibles à apprendre sont les suivantes:
\
Un modèle de régression standard peut résoudre le problème en minimisant la perte SSE avec la régularisation:
\
Le terme de régularisation est critique ici et le papier RCNN a choisi le meilleur λ par validation croisée. Il convient également de noter que toutes les boîtes de délimitation prévues n’ont pas de boîtes de vérité au sol correspondantes. Par exemple, s’il n’y a pas de chevauchement, il n’est pas logique d’exécuter une régression bbox. Ici, seule une boîte prédite avec une boîte de vérité au sol voisine d’au moins 0,6 IoU est conservée pour l’entraînement du modèle de régression bbox.
Astuces courantes
Plusieurs astuces sont couramment utilisées dans RCNN et d’autres modèles de détection.
Suppression non maximale
Le modèle est probablement capable de trouver plusieurs boîtes englobantes pour le même objet. La suppression non maximale permet d’éviter la détection répétée de la même instance. Après avoir obtenu un ensemble de boîtes englobantes correspondantes pour la même catégorie d’objet: Triez toutes les boîtes englobantes par score de confiance.Jeter les boîtes avec de faibles scores de confiance.Bien qu’il reste une boîte englobante, répétez les opérations suivantes: Sélectionnez avec gourmandise celle qui a obtenu le score le plus élevé.Ignorez les cases restantes avec une IoU élevée (c’est-à-dire > 0,5) avec une case précédemment sélectionnée.

Fig. 3. Plusieurs boîtes de délimitation détectent la voiture dans l’image. Après une suppression non maximale, seuls les meilleurs restent et les autres sont ignorés car ils ont de grands chevauchements avec celui sélectionné. (Source de l’image: Papier DPM)
Extraction négative dure
Nous considérons les boîtes englobantes sans objets comme des exemples négatifs. Tous les exemples négatifs ne sont pas aussi difficiles à identifier. Par exemple, s’il contient un arrière-plan vide pur, il s’agit probablement d’un « négatif facile »; mais si la boîte contient une texture bruyante étrange ou un objet partiel, il pourrait être difficile à reconnaître et ceux-ci sont « négatifs durs ».
Les exemples négatifs durs sont facilement mal classés. Nous pouvons trouver explicitement ces échantillons faussement positifs lors des boucles d’entraînement et les inclure dans les données d’entraînement afin d’améliorer le classificateur.
Goulot d’étranglement de vitesse
En parcourant les étapes d’apprentissage de R-CNN, vous pouvez facilement découvrir que la formation d’un modèle R-CNN est coûteuse et lente, car les étapes suivantes impliquent beaucoup de travail:
- Lancer une recherche sélective pour proposer 2000 candidats de régions pour chaque image;
- Générer le vecteur de fonction CNN pour chaque région d’image (N images *2000).
- L’ensemble du processus implique trois modèles séparément sans calcul beaucoup partagé: le réseau de neurones convolutifs pour la classification des images et l’extraction des entités; le classificateur SVM supérieur pour identifier les objets cibles; et le modèle de régression pour resserrer les boîtes de délimitation des régions.
Fast R-CNN
Pour accélérer R-CNN, Girshick (2015) a amélioré la procédure de formation en unifiant trois modèles indépendants en un cadre formé conjointement et en augmentant les résultats de calcul partagés, nommés Fast R-CNN. Au lieu d’extraire les vecteurs de caractéristiques CNN indépendamment pour chaque proposition de région, ce modèle les agrège en un seul passage en avant CNN sur l’ensemble de l’image et les propositions de régions partagent cette matrice de caractéristiques. Ensuite, la même matrice d’entités est ramifiée pour être utilisée pour apprendre le classificateur d’objets et le régresseur de la boîte englobante. En conclusion, le partage de calcul accélère R-CNN.
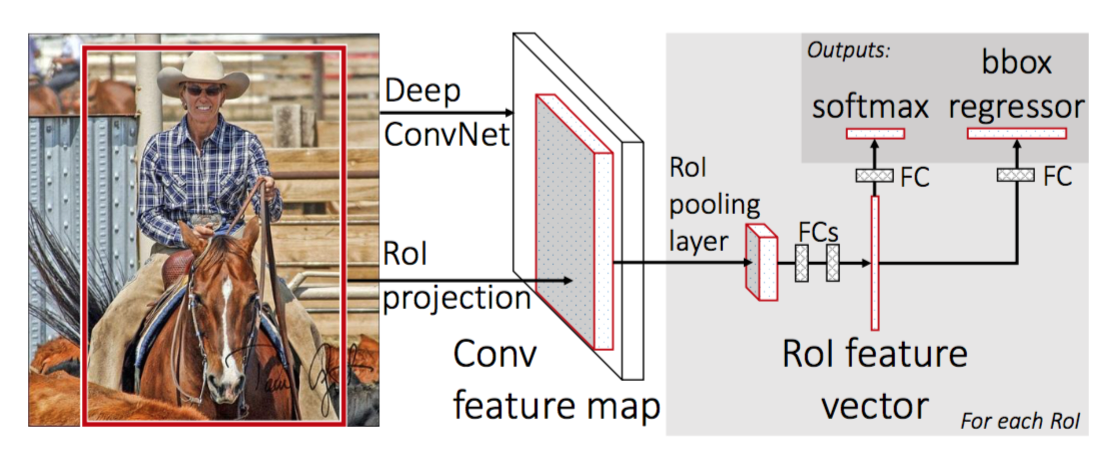
Fig. 4. L’architecture de Fast R-CNN. (Source de l’image: Girshick, 2015)
Mise en commun du RoI
Il s’agit d’un type de mise en commun maximale permettant de convertir des entités de la région projetée de l’image de n’importe quelle taille, h x w, en une petite fenêtre fixe, H x W. La région d’entrée est divisée en grilles H x W, à peu près chaque sous-fenêtre de taille h/ H x w/W. Appliquez ensuite la mise en commun maximale dans chaque grille.
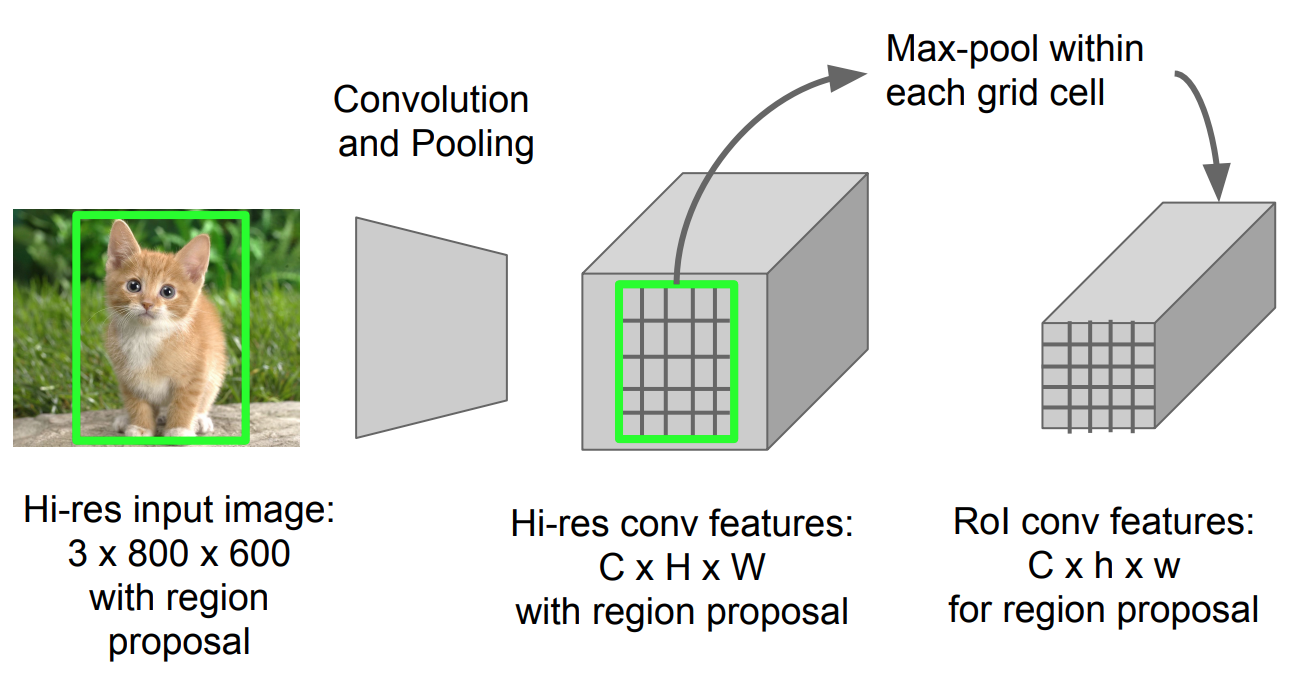
Fig. 5. Mise en commun du ROI (Source de l’image : diapositives Stanford CS231n.)
Workflow du modèle
La vitesse de fonctionnement de R-CNN est résumée comme suit; de nombreuses étapes sont les mêmes que dans R-CNN:
- Tout d’abord, pré-entraînez un réseau neuronal convolutif aux tâches de classification d’images.
- Proposer des régions par recherche sélective (~2k candidats par image).
- Modifier le CNN pré-formé :
- Remplacer la dernière couche de mise en commun maximale du CNN pré-formé par une couche de mise en commun du RoI. La couche de mise en commun du RoI génère des vecteurs d’entités de longueur fixe de propositions de régions. Le partage du calcul CNN a beaucoup de sens, car de nombreuses propositions de régions des mêmes images se chevauchent fortement.
- Remplacez le dernier calque entièrement connecté et le dernier calque softmax (classes K) par un calque entièrement connecté et softmax sur K+1 classes.
- Enfin, le modèle se branche en deux couches de sortie:
- Un estimateur softmax de K + 1 classes (comme dans R-CNN, +1 est la classe « d’arrière-plan »), produisant une distribution de probabilité discrète par RoI.
- Un modèle de régression englobant qui prédit des décalages par rapport au retour sur investissement d’origine pour chacune des K classes.
Fonction de perte
Le modèle est optimisé pour une perte combinant deux tâches (classification + localisation):
| Symbole | Explication |
| \( u\) | True class label, \(u\ in 0, 1, \dots, K\); par convention, la classe d’arrière-plan fourre-tout a \(u = 0\). |
| \(p\) | Distribution de probabilité discrète (par RoI) sur K + 1 classes : \(p =(p_0, \dots, p_K)\), calculée par un softmax sur les K+1 sorties d’une couche entièrement connectée. |
| \(v\) | Boîte englobante vraie \(v=(v_x, v_y, v_w, v_h)\). |
| \(t^u\) | Correction prédite de la boîte englobante, \(t^u=(t^u_x, t^u_y, t^u_w, t^u_h)\). Voir ci-dessus. |
La fonction de perte résume le coût de la classification et de la prédiction de la boîte englobante: \(\mathcal{L} = \mathcal{L}_\text{cls} + \mathcal{L}_\text{box}\). Pour le RoI « en arrière-plan », \(\mathcal{L}_\text{box}\) est ignoré par la fonction indicateur \(\mathbb{1}\), définie comme:
\=\begin{cases}1 &\text{if}u\geq 1\\0 &\text{sinon}\end{cases}\]
La fonction de perte globale est:
\\mathcal{L}_\text{box}(t^u, v)\\\mathcal{L}_\text{cls }(p, u) &=-\log p_u\\\mathcal {L}_\text{box}(t ^u, v) &= \sum_{i\in\{x, y, w, h\}} L_1 ^\text{smooth}(t^u_i-v_i)\end {align*}\]
La boîte englobante loss\(\mathcal{L}_{box}\) doit mesurer la différence entre \(t^u_i\) et \(v_i\) à l’aide d’une fonction de perte robuste. La perte de L1 lisse est adoptée ici et on prétend qu’elle est moins sensible aux valeurs aberrantes.
\
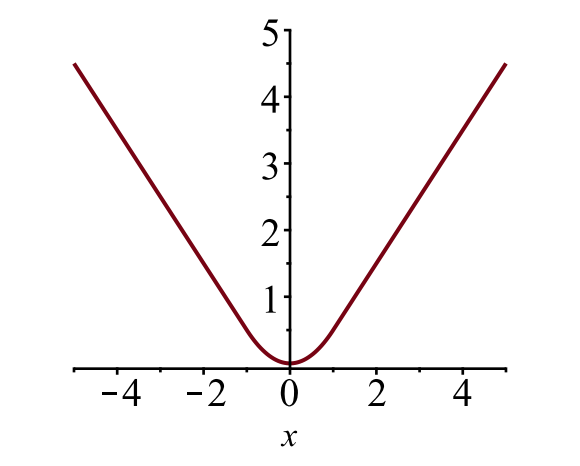
Fig. 6. Le tracé de la perte L1 lisse, \(y = L_1 ^\text {smooth}(x)\). (Source de l’image: lien)
Goulot d’étranglement de vitesse
R-CNN rapide est beaucoup plus rapide en temps d’entraînement et de test. Cependant, l’amélioration n’est pas spectaculaire car les propositions régionales sont générées séparément par un autre modèle et cela coûte très cher.
R-CNN plus rapide
Une solution d’accélération intuitive consiste à intégrer l’algorithme de proposition de région dans le modèle CNN. R-CNN plus rapide (Ren et al., 2016) fait exactement cela: construisez un modèle unique et unifié composé de RPN (region proposal network) et de R-CNN rapide avec des couches d’entités convolutives partagées.

Fig. 7. Une illustration du modèle R-CNN plus rapide. (Source de l’image : Ren et coll., 2016)
Workflow modèle
- Pré-former un réseau CNN sur les tâches de classification d’images.
- Affinez le RPN (region proposal network) de bout en bout pour la tâche de proposition de région, qui est initialisée par le classificateur d’images pré-train. Les échantillons positifs ont IoU (intersection-sur-union) > 0,7, tandis que les échantillons négatifs ont IoU < 0,3.
- Faites glisser une petite fenêtre spatiale n x n sur la carte des entités conv de l’image entière.
- Au centre de chaque fenêtre coulissante, nous prédisons simultanément plusieurs régions de différentes échelles et ratios. Une ancre est une combinaison de (centre de fenêtre coulissante, échelle, rapport). Par exemple, 3 échelles + 3 rapports = > k = 9 ancrages à chaque position de glissement.
- Entraînez un modèle de détection d’objet R-CNN rapide en utilisant les propositions générées par le RPN actuel
- Puis utilisez le réseau R-CNN rapide pour initialiser la formation RPN. Tout en conservant les couches convolutives partagées, ajustez uniquement les couches spécifiques au RPN. A ce stade, RPN et le réseau de détection ont partagé des couches convolutives !
- Enfin, affinez les couches uniques de R-CNN rapide
- L’étape 4-5 peut être répétée pour entraîner alternativement RPN et R-CNN rapide si nécessaire.
Fonction de perte
Le R-CNN plus rapide est optimisé pour une fonction de perte multi-tâches, similaire au R-CNN rapide.
| Symbole | Explication |
| \(p_i\) | Probabilité prédite que l’ancre i soit un objet. |
| \(p^*_i\) | Étiquette de vérité au sol (binaire) indiquant si l’ancre i est un objet. |
| \(t_i\) | Prédit quatre coordonnées paramétrées. |
| \(t^*_i\) | Coordonnées de vérité au sol. |
| \(N_\text{cls}\) | Terme de normalisation, défini sur la taille du mini-lot (~ 256) dans le papier. |
| \(N_\text{box}\) | Terme de normalisation, défini sur le nombre d’emplacements d’ancrage (~2400) dans le document. |
| \(\lambda\) | Un paramètre d’équilibrage, défini sur ~10 dans le document (de sorte que les termes \(\mathcal{L}_\text{cls}\) et \(\mathcal{L}_\text{box}\) soient à peu près également pondérés). |
La fonction de perte multi-tâches combine les pertes de la classification et de la régression de la boîte englobante:
\
où \(\mathcal{L}_\text{cls}\) est la fonction de perte de journal sur deux classes, car nous pouvons facilement traduire une classification multi-classes en une classification binaire en prédisant une l’échantillon étant un objet cible plutôt que non. \(L_1^\text {smooth}\) est la perte L1 lisse.
\
Masque R-CNN
Masque R-CNN (He et al., 2017) étend plus rapidement R-CNN à la segmentation d’images au niveau des pixels. Le point clé est de découpler la classification et les tâches de prédiction de masque au niveau des pixels. Basé sur le cadre de Faster R-CNN, il a ajouté une troisième branche pour prédire un masque d’objet en parallèle avec les branches existantes pour la classification et la localisation. La branche de masque est un petit réseau entièrement connecté appliqué à chaque RoI, prédisant un masque de segmentation de manière pixel à pixel.
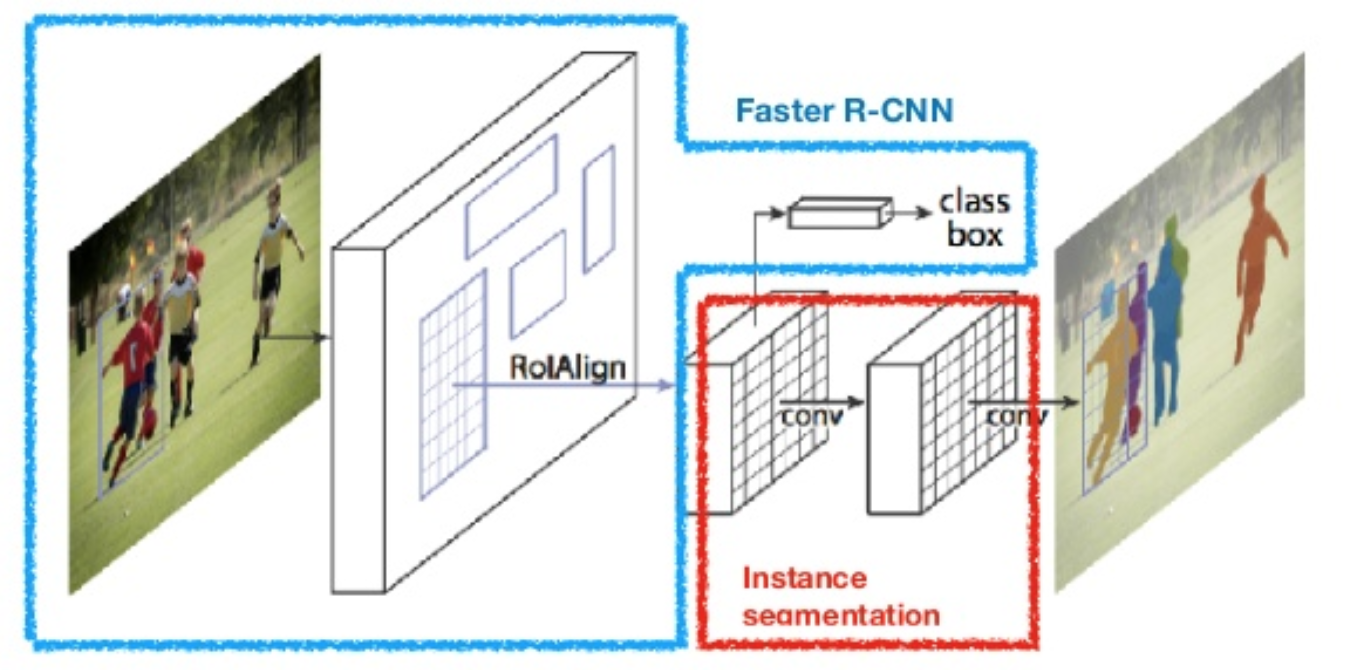
Fig. 8. Le masque R-CNN est un modèle R-CNN plus rapide avec segmentation d’image. (Source de l’image: He et coll., 2017)
Parce que la segmentation au niveau des pixels nécessite un alignement beaucoup plus fin que les boîtes englobantes, mask R-CNN améliore la couche de mise en commun du RoI (nommée « couche RoIAlign ») afin que le RoI puisse être mieux et plus précisément mappé aux régions de l’image d’origine.

Fig. 9. Prédictions par Mask R-CNN sur le jeu de tests COCO. (Source de l’image: He et coll., 2017)
RoIAlign
La couche RoIAlign est conçue pour corriger le désalignement d’emplacement causé par la quantification dans la mise en commun du RoI. RoIAlign supprime la quantification de hachage, par exemple, en utilisant x/16 au lieu de, afin que les entités extraites puissent être correctement alignées avec les pixels d’entrée. L’interpolation bilinéaire est utilisée pour calculer les valeurs d’emplacement en virgule flottante dans l’entrée.
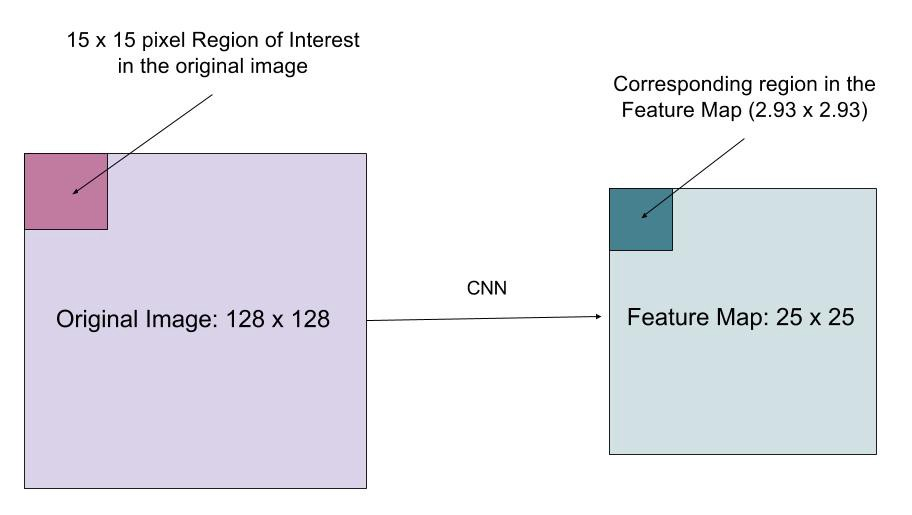
Fig. 10. Une région d’intérêt est mappée avec précision à partir de l’image d’origine sur la carte d’entités sans arrondir aux entiers. (Source de l’image:
Fonction de perte
La fonction de perte multi-tâches du masque R-CNN combine la perte du masque de classification, de localisation et de segmentation: \(\mathcal{L}= \mathcal{L}_\text{cls} + \mathcal{L}_\text{box} + \mathcal{L}_\text{mask}\), où \(\mathcal{L}_\text{cls}\) et \(\mathcal{L}_\text{box }\) sont les mêmes que dans R-CNN plus rapide.
La branche mask génère un masque de dimension m x m pour chaque RoI et chaque classe ; K classes au total. Ainsi, la sortie totale est de taille \(K\cdot m^2\). Parce que le modèle essaie d’apprendre un masque pour chaque classe, il n’y a pas de concurrence entre les classes pour générer des masques.
\(\mathcal{L}_\text{mask}\) est défini comme la perte d’entropie croisée binaire moyenne, n’incluant que le k-th masque si la région est associée à la classe de vérité au sol k.
\\]
où \(y_{ij}\) est l’étiquette d’une cellule (i, j) dans le masque vrai pour la région de taille m x m ; \(\hat{y}_{ij}^k\) est la valeur prédite de la même cellule dans le masque appris pour la classe de vérité au sol k.
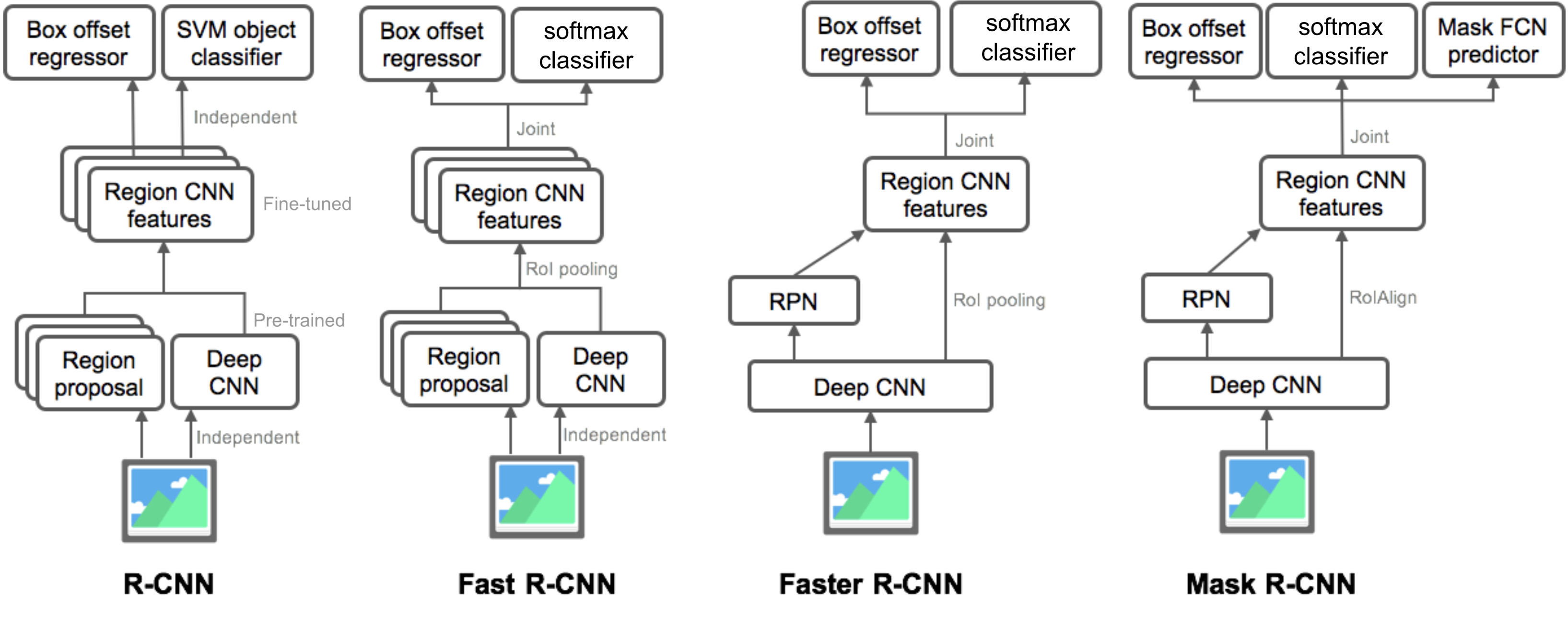
Résumé des modèles de la famille R-CNN
Ici, j’illustre les conceptions de modèles de R-CNN, R-CNN Rapide, R-CNN plus rapide et Masque R-CNN. Vous pouvez suivre l’évolution d’un modèle vers la version suivante en comparant les petites différences.
Cité comme:
@article{weng2017detection3, title = "Object Detection for Dummies Part 3: R-CNN Family", author = "Weng, Lilian", journal = "lilianweng.github.io/lil-log", year = "2017", url = "http://lilianweng.github.io/lil-log/2017/12/31/object-recognition-for-dummies-part-3.html"}Référence
Ross Girshick, Jeff Donahue, Trevor Darrell et Jitendra Malik. » De riches hiérarchies de fonctionnalités pour une détection précise des objets et une segmentation sémantique. » En Proc. IEEE Conf. sur la vision par ordinateur et la reconnaissance de formes (CVPR), pp. 580-587. 2014.
Ross Girshick. « Rapide R- CNN. » En Proc. IEEE Intl. Conf. sur la vision par ordinateur, pp. 1440-1448. 2015.
Shaoqing Ren, Kaiming He, Ross Girshick et Jian Sun. « R-CNN plus rapide: Vers une détection d’objets en temps réel avec des réseaux de propositions de régions. »Dans Advances in neural information processing systems (NIPS), pp. 91-99. 2015.
Kaiming He, Georgia Gkioxari, Piotr Dollár et Ross Girshick. « Masque R – CNN. » Préimpression d’arXiv arXiv: 1703.06870, 2017.
Joseph Redmon, Santosh Divvala, Ross Girshick et Ali Farhadi. « Vous ne regardez qu’une seule fois : Détection d’objets unifiée et en temps réel. » En Proc. IEEE Conf. on computer vision and pattern recognition (CVPR), pp. 779-788. 2016.
« Une brève histoire des CNN dans la segmentation d’images: De R-CNN à Masquer R-CNN » par Athelas.
Perte L1 lisse: https://github.com/rbgirshick/py-faster-rcnn/files/764206/SmoothL1Loss.1.pdf