Object Detection for Dummies Part 3: R-CNN család
a 3.részben négy objektum detektálási modellt vizsgálnánk meg: R-CNN, gyors R-CNN, gyorsabb R-CNN és maszk R-CNN. Ezek a modellek szorosan kapcsolódnak egymáshoz, és az új verziók nagy sebességnövekedést mutatnak a régebbiekhez képest.
az “Object Detection for Dummies” sorozatban a képfeldolgozás alapfogalmaival kezdtük, mint például a gradiens vektorok és a HOG, az 1.részben. Ezután a 2.részben bemutattuk a klasszikus konvolúciós neurális hálózati architektúra-terveket osztályozáshoz, valamint úttörő modelleket az objektumfelismeréshez, a Túltápláláshoz és a DPM-hez. A sorozat harmadik bejegyzésében az R-CNN (“Régióalapú CNN”) család modellkészletét fogjuk áttekinteni.
linkek a sorozat összes bejegyzéséhez:.
itt van egy lista az ebben a bejegyzésben szereplő cikkekről 😉
| Model | Goal | Resources |
| R-CNN | Object recognition | |
| Fast R-CNN | Object recognition | |
| Faster R-CNN | Object recognition | |
| Mask R-CNN | Image segmentation |
- R-CNN
- modell munkafolyamat
- Bounding Box regresszió
- gyakori trükkök
- sebesség szűk keresztmetszet
- gyors R-CNN
- RoI Pooling
- modell munkafolyamat
- veszteség funkció
- sebesség szűk keresztmetszet
- gyorsabb R-CNN
- modell munkafolyamat
- veszteség funkció
- maszk R-CNN
- RoIAlign
- veszteség funkció
- az R-CNN család modelljeinek összefoglalása
R-CNN
R-CNN (Girshick et al., 2014) is short for “Region-based Convolutional Neural Networks”. The main idea is composed of two steps. Először is, a szelektív keresés, azonosítja kezelhető számú határoló-box objektum régió jelöltek (“régió érdekes “vagy”RoI”). Ezután kivonja a CNN jellemzőit az egyes régiókból függetlenül osztályozás céljából.
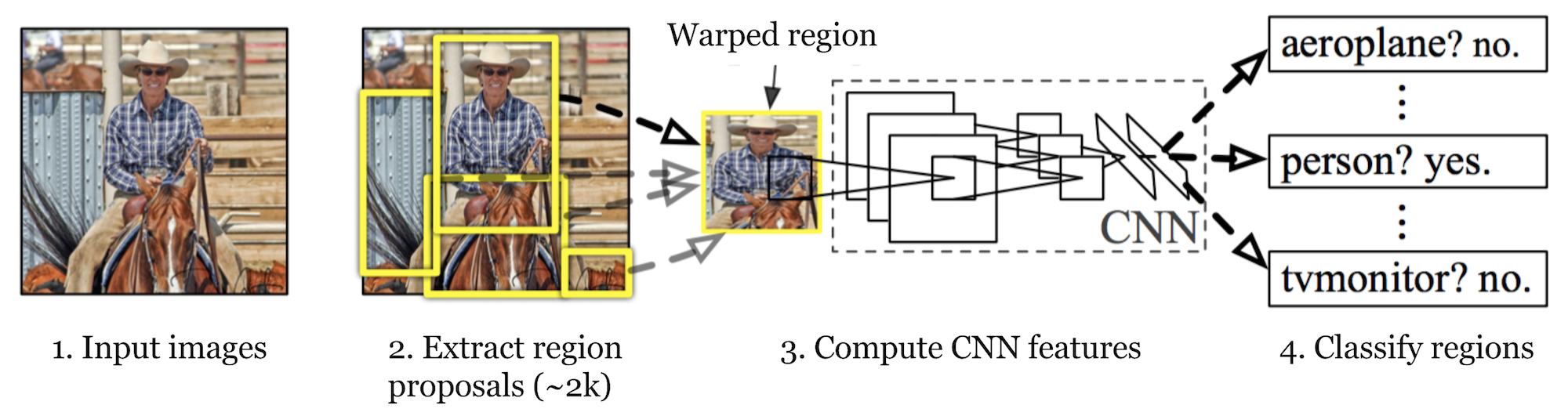
ábra. 1. Az R-CNN architektúrája. (Kép forrása: Girshick et al., 2014)
modell munkafolyamat
az R-CNN működése a következőképpen foglalható össze:
- a CNN hálózat előzetes képzése a képosztályozási feladatokról; például a VGG vagy a ResNet képzett az ImageNet adatkészleten. Az osztályozási feladat magában foglalja N osztályok.
megjegyzés: a Caffe Model Zoo-ban megtalálható egy előre kiképzett AlexNet. Nem hiszem, hogy megtalálja a Tensorflow-ban, de a TensorFlow-slim modellkönyvtár előre képzett ResNet, VGG és mások.
- javasoljon kategóriafüggetlen érdekes régiókat szelektív kereséssel (~2K jelölt képenként). Ezek a régiók célobjektumokat tartalmazhatnak, és különböző méretűek.
- Régió jelöltek elvetemült, hogy egy fix méretű által előírt CNN.
- folytassa a CNN finomhangolását a K + 1 osztályok elvetemült javaslatterületein; a további egy osztály a háttérre utal (nincs érdekes tárgy). A finomhangolási szakaszban sokkal kisebb tanulási arányt kell alkalmaznunk, és a mini-batch túlmutat a pozitív eseteken, mivel a legtöbb javasolt régió csak háttér.
- minden képrégiót figyelembe véve egy előre terjedés a CNN-en keresztül létrehoz egy jellemzővektort. Ezt a tulajdonságvektort ezután egy bináris SVM fogyasztja, amelyet az egyes osztályokhoz függetlenül kiképeznek.
a pozitív minták javasolt régiók IoU (metszéspont felett Unió) átfedési küszöb > = 0,3, a negatív minták irrelevánsak mások. - a lokalizációs hibák csökkentése érdekében egy regressziós modellt képeztek ki, hogy korrigálja az előrejelzett észlelési ablakot a határoló doboz korrekciós eltolásán a CNN funkciók segítségével.
Bounding Box regresszió
adott egy előre jelzett bounding box koordináta \(\mathbf{p} = (p_x, p_y, p_w, p_h)\) (középkoordináta, szélesség, magasság) és a megfelelő ground truth box koordináták \(\mathbf{g} = (g_x, g_y, g_w, g_h)\) , a regresszor úgy van beállítva, hogy megtanulja a skála-invariáns transzformációt két központ között és a log-scale transzformációt két központ között szélesség és magasság. Az összes transzformációs függvény a \(\mathbf{p}\) bemenetet veszi fel.
\
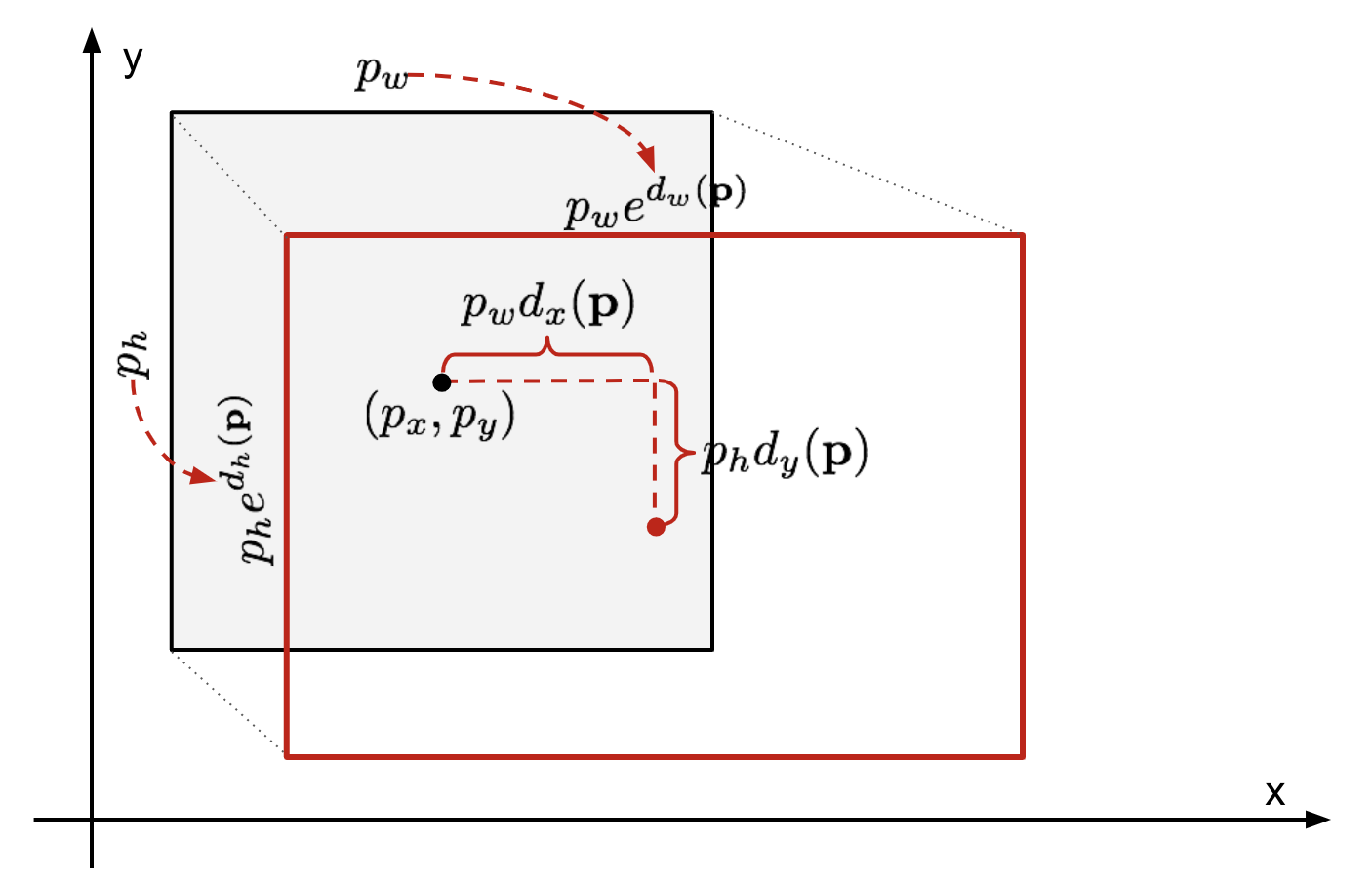
ábra. 2. Az előrejelzett és a földi igazság határoló dobozok közötti átalakulás illusztrációja.
az ilyen transzformáció alkalmazásának nyilvánvaló előnye, hogy az összes határoló doboz korrekciós függvény, \(d_i(\mathbf{p})\) ahol \(I \in \{ x, y, w, h\}\), bármilyen értéket felvehet . A tanulandó célok a következők:
\
egy standard regressziós modell megoldhatja a problémát az SSE veszteség minimalizálásával a regularizációval:
\
a regularizációs kifejezés itt kritikus, és az RCNN papír a keresztellenőrzéssel választotta ki a legjobb xhamstereket. Figyelemre méltó az is, hogy nem minden előre jelzett határoló doboz rendelkezik megfelelő földi igazságdobozokkal. Például, ha nincs átfedés, akkor nincs értelme futtatni a bbox regressziót. A bbox regressziós modell kiképzéséhez itt csak egy előre jelzett dobozt tárolnak egy közeli földi igazságdobozzal, legalább 0,6 IoU-val.
gyakori trükkök
számos trükköt használnak általában az RCNN-ben és más detektálási modellekben.
Nem Maximális elnyomás
valószínűleg a modell képes több határoló négyzetet találni ugyanarra az objektumra. A nem maximális elnyomás segít elkerülni ugyanazon példány ismételt észlelését. Miután megkaptuk az egyező határoló dobozok készletét ugyanarra az objektumkategóriára: rendezze az összes határoló mezőt bizalmi pontszám szerint.Dobja dobozok alacsony megbízhatósági pontszámok.Amíg van még határoló doboz, ismételje meg a következőket:mohón válassza ki a legmagasabb pontszámot.Hagyja ki a fennmaradó mezőket magas IoU-val (azaz > 0.5) az előzőleg kiválasztott mezővel.

ábra. 3. Több határoló doboz észleli az autót a képen. A nem maximális elnyomás után csak a legjobbak maradnak, a többit pedig figyelmen kívül hagyják, mivel nagy átfedések vannak a kiválasztottal. (Képforrás: DPM paper)
kemény negatív bányászat
negatív példaként tekintjük az objektumok nélküli határoló dobozokat. Nem minden negatív példát lehet egyformán nehéz azonosítani. Például, ha tiszta üres háttérrel rendelkezik, akkor valószínűleg “könnyű negatív”; de ha a doboz furcsa zajos textúrát vagy részleges tárgyat tartalmaz, nehéz lehet felismerni, és ezek “kemény negatívok”.
a kemény negatív példák könnyen rosszul osztályozhatók. Kifejezetten megtalálhatjuk ezeket a hamis pozitív mintákat a képzési ciklusok során, és beilleszthetjük őket a képzési adatokba az osztályozó javítása érdekében.
sebesség szűk keresztmetszet
az R-CNN tanulási lépéseit áttekintve könnyen megtudhatja, hogy az R-CNN modell betanítása drága és lassú, mivel a következő lépések sok munkát igényelnek:
- szelektív keresés futtatása, hogy minden képhez 2000 régiójelöltet javasoljon;
- a CNN funkcióvektor generálása minden képrégióhoz (N kép * 2000).
- az egész folyamat három modellt foglal magában, külön-külön, sok megosztott számítás nélkül: a konvolúciós neurális hálózat a képosztályozáshoz és a jellemzők kivonásához; a felső SVM osztályozó a célobjektumok azonosításához; és a regressziós modell a régióhatároló dobozok meghúzásához.
gyors R-CNN
az R-CNN gyorsabbá tétele érdekében Girshick (2015) javította a képzési eljárást három független modell egyesítésével egy közösen képzett keretrendszerbe, és növelte a megosztott számítási eredményeket, Fast R-CNN néven. Ahelyett, hogy a CNN funkcióvektorokat egymástól függetlenül kivonná az egyes régiókra vonatkozó javaslatokhoz, ez a modell összesíti őket egy CNN előre lépés az egész képen, és a régiójavaslatok megosztják ezt a jellemző mátrixot. Ezután ugyanaz a tulajdonságmátrix elágazik, hogy az objektum osztályozó és a bounding-box regresszor tanulására használható legyen. Összefoglalva, a számítási megosztás felgyorsítja az R-CNN-t.
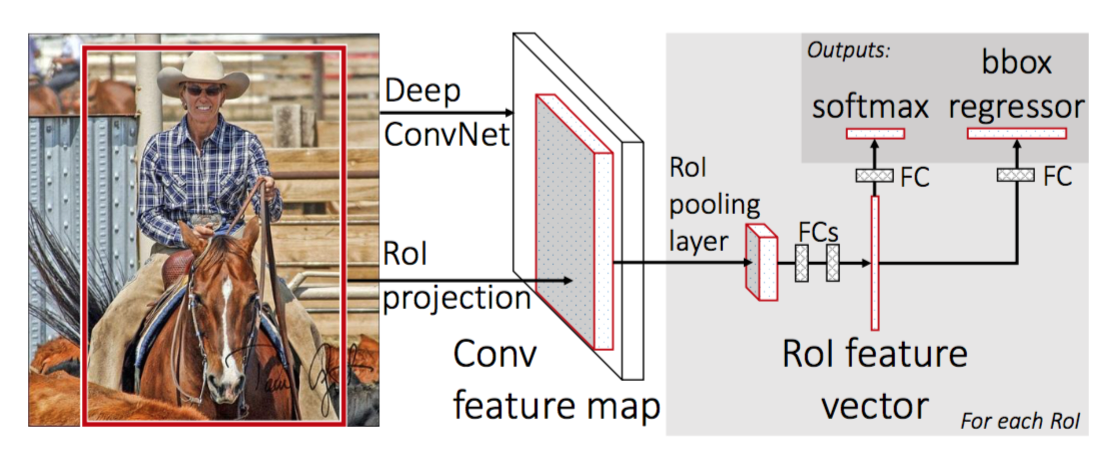
ábra. 4. A gyors R-CNN architektúrája. (Kép forrása: Girshick, 2015)
RoI Pooling
Ez egy olyan típusú max pooling konvertálni funkciók a vetített régióban a kép bármilyen méretű, h x w, egy kis fix ablak, H x W. A bemeneti régió van osztva H x W rácsok, körülbelül minden alablakot mérete h/H x w/W. ezután alkalmazza max-pooling minden rács.
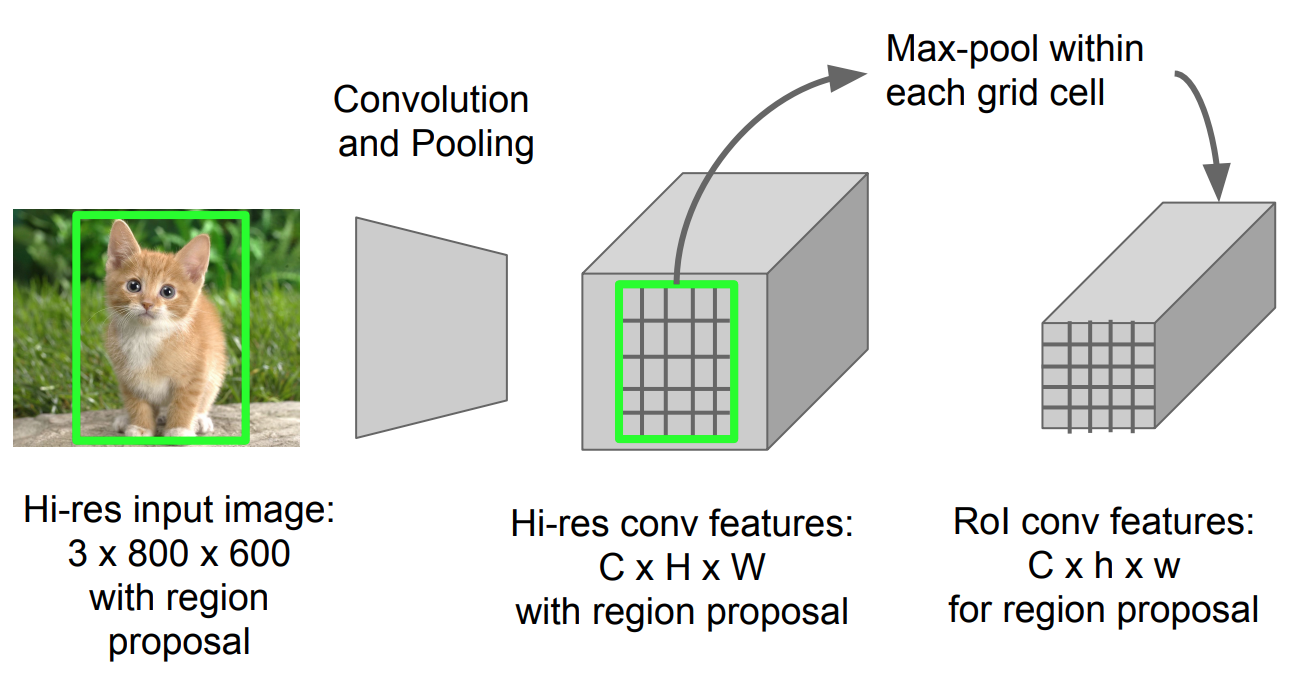
ábra. 5. RoI pooling (kép forrása: Stanford CS231n diák.)
modell munkafolyamat
az R-CNN működésének gyorsaságát a következőképpen foglaljuk össze; sok lépés ugyanaz, mint az R-CNN-ben:
- először előzetesen képezzen egy konvolúciós neurális hálózatot a képosztályozási feladatokra.
- javasoljon régiókat szelektív kereséssel (~2K jelölt képenként).
- változtassa meg az előre kiképzett CNN-t:
- cserélje ki az előre kiképzett CNN utolsó max pooling rétegét egy RoI pooling rétegre. A RoI pooling réteg a régiójavaslatok rögzített hosszúságú jellemzővektorait adja ki. A CNN számítás megosztása sok értelme van, mivel ugyanazon képek sok régiójavaslata erősen átfedésben van.
- cserélje ki az utolsó teljesen összekapcsolt réteget és az utolsó softmax réteget (K osztályok) egy teljesen összekapcsolt rétegre és softmax-ot K + 1 osztályok felett.
- végül a modell két kimeneti rétegre oszlik:
- a softmax becslője K + 1 osztályok (ugyanaz, mint az R-CNN-ben, +1 a “háttér” osztály), diszkrét valószínűségi eloszlást adva RoI-nként.
- egy bounding-box regressziós modell, amely előrejelzi az egyes k osztályok eredeti RoI-jához viszonyított eltolódásokat.
veszteség funkció
a modell két feladatot kombináló veszteségre van optimalizálva (osztályozás + lokalizáció):
| szimbólum | magyarázat |
| \(u\) | valódi osztálycímke, \(u \in 0, 1, \Dots, k\); megegyezés szerint az összes háttérosztálynak \(u = 0\) van. |
| \(p\) | diszkrét valószínűségi eloszlás (RoI-nként) K + 1 osztály felett: \(p = (p_0, \dots, p_K)\), amelyet egy softmax számít ki egy teljesen összekapcsolt réteg K + 1 kimenetén. |
| \(v\) | igaz határoló doboz \(v = (v_x, v_y, v_w, v_h)\). |
| \(t^u\) | várható határoló doboz korrekció, \(t^u = (t^u_x, t^u_y, t^u_w, t^u_h)\). Lásd fent. |
a veszteség függvény összegzi az osztályozás és a határoló doboz előrejelzésének költségeit: \(\mathcal{L} = \mathcal{L}_\text{cls} + \mathcal{L}_\text{box}\). A “háttér” RoI, \(\mathcal{L} _ \ text{box}\) figyelmen kívül hagyja a mutató függvény \(\mathbb{1} \), definiálva:
\ = \begin{cases} 1 & \text{if } u \geq 1\\ 0 & \text{egyébként}\end{cases}\]
a teljes veszteség függvény:
\ \mathcal{L}_\text{box}(t^u, v) \\\mathcal{L}_\text{cls}(p, u) &= -\log p_u \\\mathcal{l}_\text{box}(t^u, v) &= \sum_{i \in \{x, y, w, h\}} l_1^\text{Smooth} (t^u_i – v_i)\end{align*}\]
a határoló box loss \(\mathcal{l}_{box}\) méri a különbséget \(t^u_i\) és \(v_i\) között egy robusztus veszteségfüggvény segítségével. A sima L1 veszteséget itt alkalmazzák, és azt állítják, hogy kevésbé érzékeny a kiugró értékekre.
\
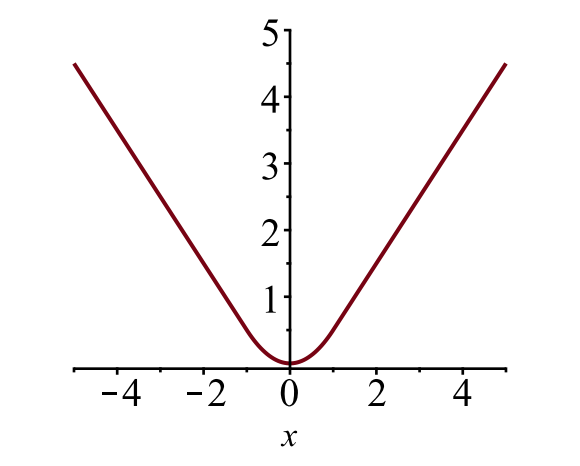
ábra. 6. A sima L1 veszteség diagramja, \(y = L_1^ \ szöveg{sima} (x)\). (Kép forrása: link)
sebesség szűk keresztmetszet
A Fast R-CNN sokkal gyorsabb mind a képzési, mind a tesztelési időben. A javulás azonban nem drámai, mivel a régiókra vonatkozó javaslatokat külön-külön egy másik modell generálja, ami nagyon drága.
gyorsabb R-CNN
Az intuitív gyorsítási megoldás a régiójavaslat algoritmusának integrálása a CNN modellbe. Gyorsabb R-CNN (Ren et al., 2016) pontosan ezt teszi: egyetlen, egységes modellt hoz létre, amely az RPN-ből (region proposal network) és a fast R-CNN-ből áll, megosztott konvolúciós jellemző rétegekkel.

ábra. 7. A gyorsabb R-CNN modell illusztrációja. (Kép forrása: Ren et al., 2016)
modell munkafolyamat
- a CNN hálózat előzetes képzése a képosztályozási feladatokról.
- finomhangolja az RPN (region proposal network) végponttól végpontig a régiójavaslati feladathoz, amelyet a vonat előtti képosztályozó inicializál. A pozitív minták IoU (kereszteződés-Unió felett) > 0,7, míg a negatív minták IoU < 0,3.
- csúsztasson egy kis N x n térbeli ablakot a teljes kép conv funkciótérképére.
- az egyes tolóablakok közepén különböző skálák és arányok több régióját jósoljuk meg egyszerre. Egy horgony kombinációja (tolóablak központ, skála, Arány). Például 3 skála + 3 arány => k=9 horgony minden csúszó helyzetben.
- egy gyors R-CNN objektumdetektálási modell kiképzése az aktuális RPN által generált javaslatok felhasználásával
- majd használja a gyors R-CNN hálózatot az RPN képzés inicializálásához. A megosztott konvolúciós rétegek megtartása mellett csak az RPN-specifikus rétegeket finomítsa. Ebben a szakaszban az RPN és az észlelési hálózat konvolúciós rétegeket osztott meg!
- végül finomítsa a Fast r-CNN egyedi rétegeit
- a 4-5 lépés megismételhető az RPN és a Fast R-CNN betanításához, ha szükséges.
veszteség funkció
a gyorsabb R-CNN többfeladatos veszteségfüggvényre van optimalizálva, hasonlóan a gyors R-CNN-hez.
| szimbólum | magyarázat |
| \(p_i\) | az anchor I objektum várható valószínűsége. |
| \(p^*_i\) | földi igazság címke (bináris), hogy horgony i egy objektum. |
| \(t_i\) | négy paraméterezett koordinátát jósolt meg. |
| \(t^*_i\) | földi igazság koordináták. |
| \(N_\text{cls}\) | normalizációs kifejezés, amely a papír mini-kötegméretének (~256) felel meg. |
| \(N_\text{box}\) | normalizációs kifejezés, a papír rögzítési helyeinek (~2400) számára állítva. |
| \(\lambda\) | egy kiegyensúlyozó paraméter, amely ~10-re van állítva a papírban (úgy, hogy mind a \(\mathcal{L}_\text{cls}\), mind a \(\mathcal{L}_\text{box}\) kifejezések nagyjából azonos súlyúak legyenek). |
a multi-task loss függvény kombinálja az osztályozás és a bounding box regresszió veszteségeit:
\
ahol \(\mathcal{L}_\text{cls}\) a log loss függvény két osztály felett, mivel a többosztályos osztályozást könnyen lefordíthatjuk bináris osztályozássá azáltal, hogy előre jelezzük, hogy a többosztályos osztályozás a a minta célobjektum, szemben a nem. \(L_1^ \ text{smooth}\) a sima L1 veszteség.
\
maszk R-CNN
maszk R-CNN (ő et al., 2017) kiterjeszti a gyorsabb R-CNN-t a pixel szintű képszegmentálásra. A legfontosabb pont az osztályozás és a pixelszintű maszk előrejelzési feladatok szétválasztása. A Faster R-CNN keretrendszere alapján egy harmadik ágat adott hozzá az objektummaszk előrejelzéséhez a meglévő ágakkal párhuzamosan az osztályozáshoz és a lokalizációhoz. A maszk ág egy kicsi, teljesen csatlakoztatott hálózat, amelyet minden RoI-ra alkalmaznak, pixelről pixelre előrejelezve a szegmentációs maszkot.
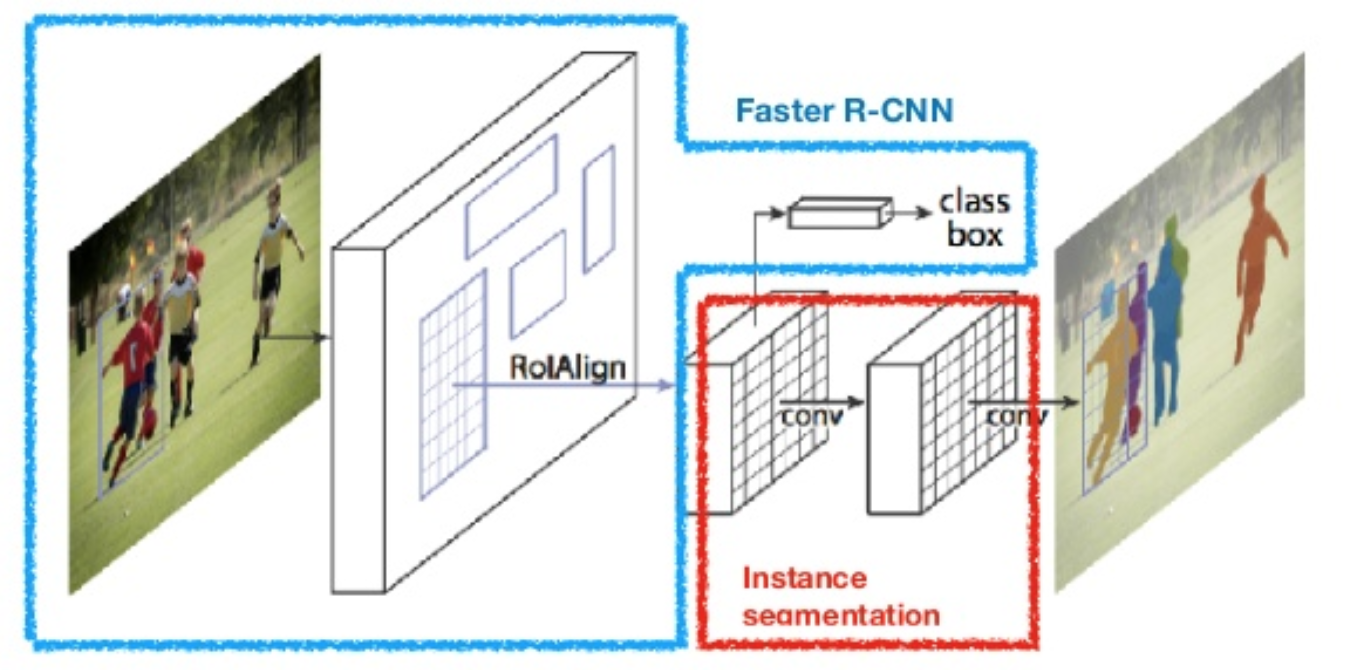
ábra. 8. Maszk R-CNN gyorsabb R-CNN modell kép szegmentálás. (Kép forrása: He et al., 2017)
mivel a pixelszintű szegmentálás sokkal finomszemcsésebb igazítást igényel, mint a határoló dobozok, az R-CNN maszk javítja a RoI pooling réteget (“RoIAlign layer” néven), így a RoI jobban és pontosabban leképezhető az eredeti kép régióihoz.

ábra. 9. Az R-CNN maszk előrejelzései a COCO tesztkészleten. (Kép forrása: He et al., 2017)
RoIAlign
a RoIAlign réteg célja A RoI pooling kvantálása által okozott helyeltérés kijavítása. RoIAlign eltávolítja a hash kvantálás, például, segítségével x/16 helyett, úgy, hogy a kibontott funkciók megfelelően igazodik a bemeneti Pixel. A bilineáris interpoláció a lebegőpontos helyértékek kiszámítására szolgál a bemenetben.
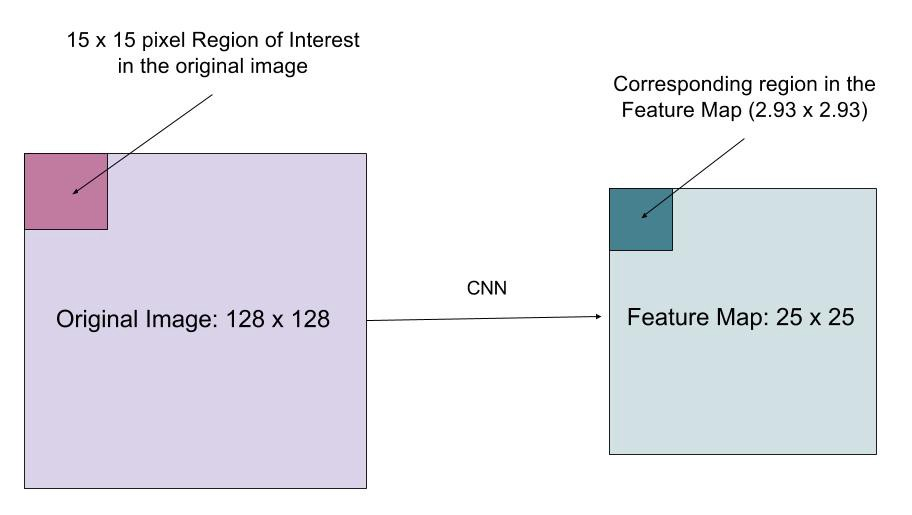
ábra. 10. Az érdeklődésre számot tartó régiót az eredeti képről pontosan leképezik a funkciótérképre anélkül, hogy egész számokra kerekítenék. (Kép forrása:
veszteség funkció
az R-CNN maszk többfeladatos veszteségfüggvénye egyesíti az osztályozás, a lokalizáció és a szegmentálás maszk elvesztését: \(\mathcal{L} = \mathcal{L}_\text{cls} + \mathcal{L}_\text{box} + \mathcal{L}_\text{mask}\), ahol \(\mathcal{L}_\text{cls}\) és \(\mathcal{L}_\text{box}}\) ugyanazok, mint a gyorsabb R-CNN-ben.
a maszk ág m x m dimenziós maszkot hoz létre minden RoI-hoz és minden osztályhoz; K osztályok összesen. Így a teljes kimenet \(k \cdot m^2\) méretű. Mivel a modell megpróbál megtanulni egy maszkot minden osztály számára, az osztályok között nincs verseny a maszkok előállításáért.
\(\mathcal{L}_\text{mask}\) az átlagos bináris kereszt-entrópia veszteség, csak a k-TH maszkot tartalmazza, ha a régió a földi igazság osztályhoz van társítva k.
\\]
ahol \(y_{IJ}\) egy cella címkéje (i, j) a valódi maszkban az M X M méretű régióhoz; \(\hat{y}_{IJ}^k\) a maszkban lévő ugyanazon cella becsült értéke tanult a földi igazság k osztály.
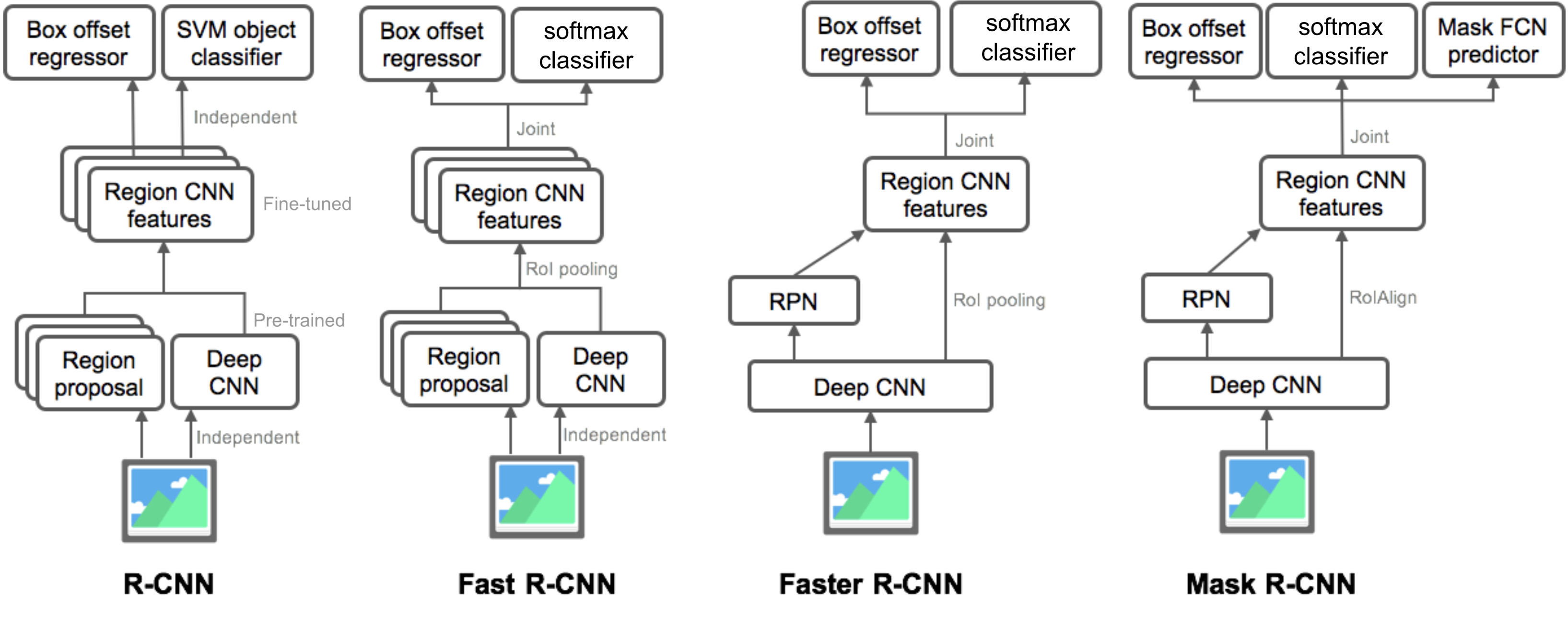
az R-CNN család modelljeinek összefoglalása
itt bemutatom az R-CNN, a Fast R-CNN, a Faster R-CNN és a Mask R-CNN modellterveit. A kis különbségek összehasonlításával nyomon követheti, hogy az egyik modell hogyan fejlődik a következő verzióra.
idézve:
@article{weng2017detection3, title = "Object Detection for Dummies Part 3: R-CNN Family", author = "Weng, Lilian", journal = "lilianweng.github.io/lil-log", year = "2017", url = "http://lilianweng.github.io/lil-log/2017/12/31/object-recognition-for-dummies-part-3.html"}referencia
Ross Girshick, Jeff Donahue, Trevor Darrell és Jitendra Malik. “Gazdag funkcióhierarchiák a pontos objektumfelismeréshez és szemantikai szegmentáláshoz.”A Proc. IEEE Conf. számítógépes látás és mintafelismerés (cvpr), 580-587. 2014.
Ross Girshick. “Gyors R-CNN.”A Proc. IEEE nemzetközi repülőtér. Conf. a számítógépes látásról, 1440-1448. 2015.shaoqing Ren, Kaiming He, Ross Girshick és Jian Sun. “Gyorsabb R-CNN: a valós idejű objektumfelismerés felé a régiójavaslat-hálózatokkal.”A neurális információfeldolgozó rendszerek fejlődésében (NIPS), 91-99. 2015.Kaiming He, Georgia Gkioxari, Piotr Doll és Ross Girshick. “Maszk R-CNN.”arXiv preprint arXiv:1703.06870, 2017.Joseph Redmon, Santosh Divvala, Ross Girshick és Ali Farhadi. “Csak egyszer nézel: egységes, valós idejű objektumfelismerés.”A Proc. IEEE Conf. a számítógépes látásról és mintafelismerésről (cvpr), 779-788. 2016.
“a CNN rövid története a kép Szegmentálásában: az R-CNN-től az R-CNN Maszkolásáig” írta Athelas.
sima L1 veszteség:https://github.com/rbgirshick/py-faster-rcnn/files/764206/SmoothL1Loss.1.pdf