ダミーのオブジェクト検出パート3:R-CNNファミリ
パート3では、R-CNN、Fast R-CNN、Faster R-CNN、Mask R-CNNの四つのオブジェクト検出モデルを調べます。 これらのモデルは非常に関連しており、新しいバージョンは古いものと比較して大きな速度向上を示しています。
“ダミーのオブジェクト検出”のシリーズでは、第1部でグラデーションベクトルやHOGなどの画像処理の基本的な概念から始めました。 次に、第2部では、分類のための古典的な畳み込みニューラルネットワークアーキテクチャ設計と、物体認識、OverfeatおよびDPMのための先駆的モデルを紹介しました。 このシリーズの3番目の投稿では、R-CNN(「地域ベースのCNN」)ファミリの一連のモデルを検討します。シリーズ内のすべての投稿へのリンク:。この記事で取り上げられている論文のリストは次のとおりです。
😉
| Model | Goal | Resources |
| R-CNN | Object recognition | |
| Fast R-CNN | Object recognition | |
| Faster R-CNN | Object recognition | |
| Mask R-CNN | Image segmentation |
R-CNN
R-CNN (Girshick et al., 2014) is short for “Region-based Convolutional Neural Networks”. The main idea is composed of two steps. まず、選択的検索を使用して、管理可能な数の境界ボックスオブジェクト領域候補(「関心領域」または「Roi」)を識別する。 そして、それは分類のために各地域から独立してCNNの特徴を抽出します。
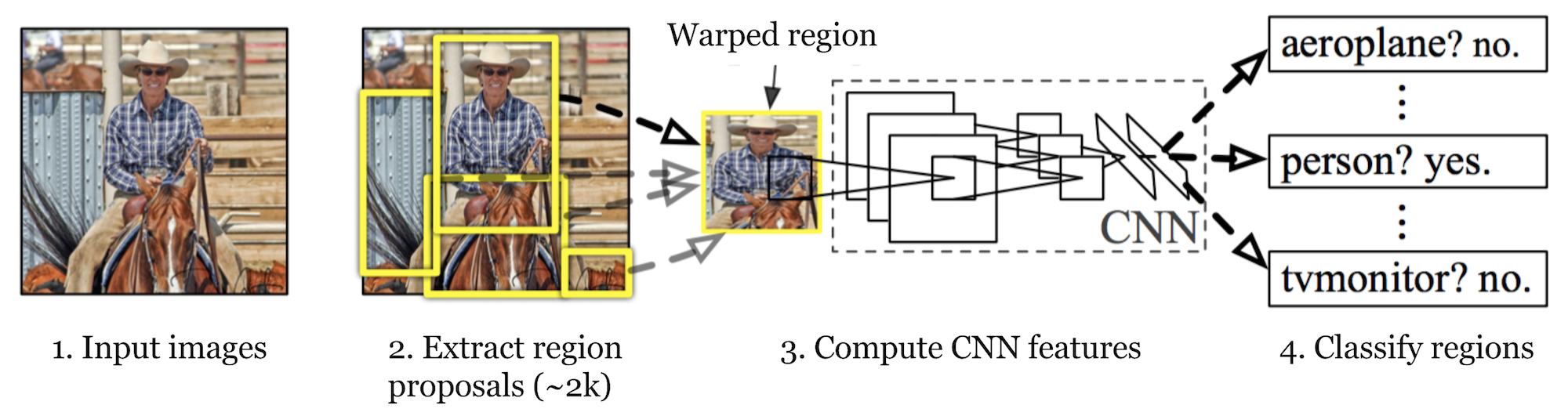
図。 1. R-CNNのアーキテクチャ。 (画像ソース:Girshick et al.,2014)
モデルワークフロー
R-CNNの仕組みは、次のように要約することができます。
- 画像分類タスクについてCNNネットワークを事前に訓練します。 分類タスクにはN個のクラスが含まれます。
注:Caffe Model Zooで事前に訓練されたAlexNetを見つけることができます。 私はあなたがTensorflowでそれを見つけることができるとは思わないが、Tensorflow-slimモデルライブラリは事前に訓練されたResNet、VGGなどを提供する。
- 選択的検索(画像ごとに-2k候補)によって関心のカテゴリに依存しない領域を提案します。 これらの領域にはターゲットオブジェクトが含まれている場合があり、サイズは異なります。
- 領域候補は、CNNの要求に応じて固定サイズに歪んでいます。
- K+1クラスの歪んだプロポーザル領域でCNNを微調整し続けます。 微調整段階では、はるかに小さい学習率を使用する必要があり、ほとんどの提案された領域は単なる背景であるため、ミニバッチは正のケースをオーバーサ
- すべての画像領域が与えられると、CNNを通る1つの前方伝播は特徴ベクトルを生成する。 この特徴ベクトルは、各クラスに対して個別に学習されたバイナリSVMによって消費されます。
正のサンプルは、IoU(union over intersection)overlap threshold>=0.3を持つ提案された領域であり、負のサンプルは無関係な他のものです。 - 局在誤差を低減するために、回帰モデルは、CNN特徴を使用して境界ボックス補正オフセット上の予測検出ウィンドウを補正するように訓練され
境界ボックス回帰
予測された境界ボックス座標\(\mathbf{p}=(p_x,p_y,p_w,p_h)\)(中心座標,幅,高さ)とそれに対応する地上真理ボックス座標\(\mathbf{g}=(g_x,g_y,g_w,g_h)\)を考えると、リグレッサは二つの中心間のスケール不変変換と幅と高さの間の対数スケール変換を学習するように構成されている。….. すべての変換関数は、入力として\(\mathbf{p}\)を取ります。
\
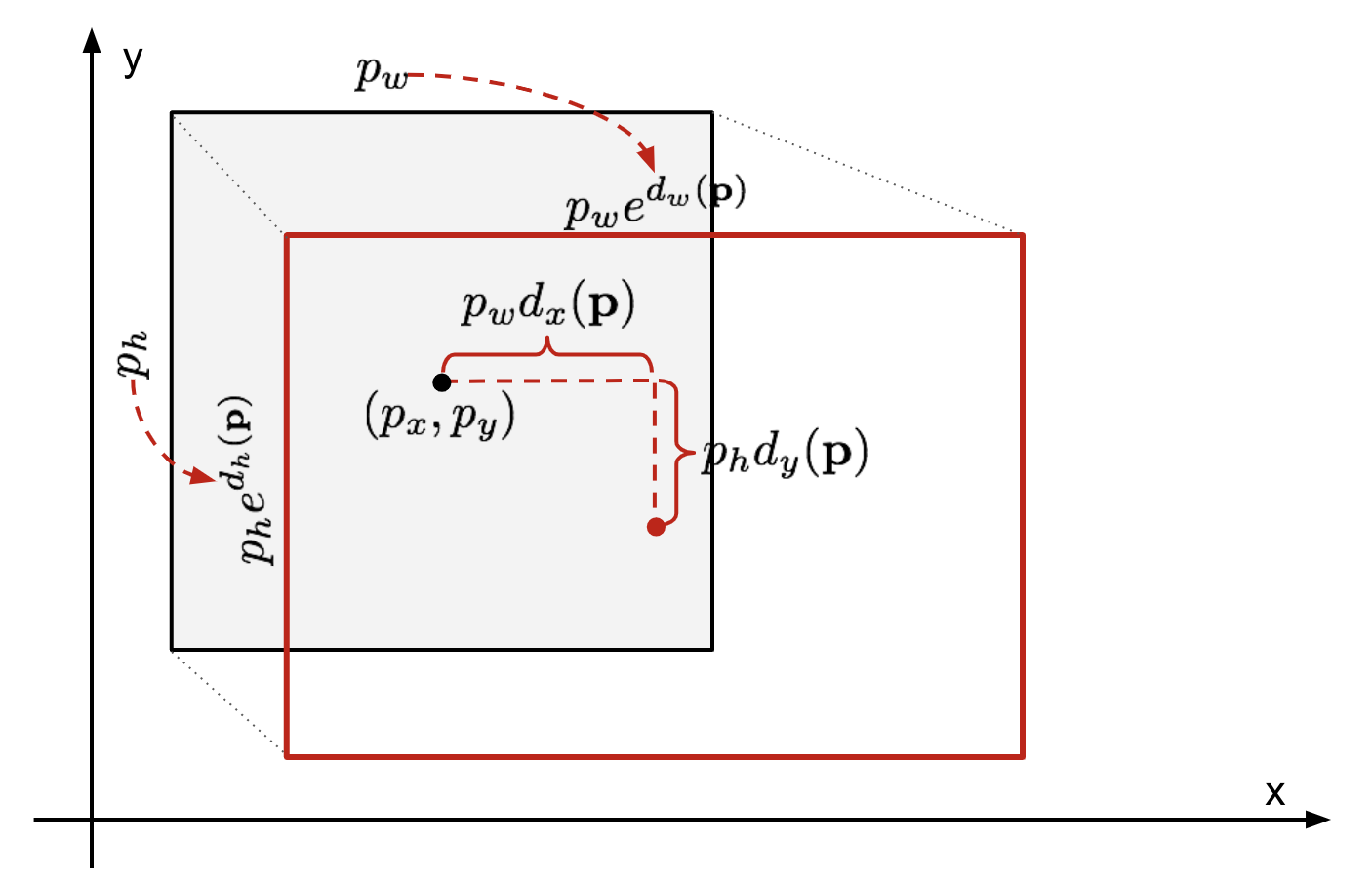
図。 2. 予測と地上の真実の境界ボックス間の変換のイラスト。このような変換を適用することの明らかな利点は、すべての境界ボックス補正関数\(d_i(\mathbf{p})\)ここで、\(i\in\{x,y,w,h\}\)は、間の任意の値を取ることがで 標準回帰モデルは、正則化によるSSE損失を最小化することによって問題を解決することができます。
\
ここでは正則化項が重要であり、rcnnの論文は交差検証によって最良のσを選択しました。 また、すべての予測された境界ボックスが対応する地上真理ボックスを持っているわけではないことも注目に値する。 たとえば、重複がない場合、bbox回帰を実行することは意味がありません。 ここでは、bbox回帰モデルを学習するために、少なくとも0.6IoUを持つ近くの地上真理値ボックスを持つ予測ボックスのみが保持されます。
Common Tricks
RCNNやその他の検出モデルでは、いくつかのトリックが一般的に使用されています。
非最大抑制
モデルは同じオブジェクトの複数の境界ボックスを見つけることができる可能性があります。 非最大抑制は、同じインスタンスの繰り返し検出を回避するのに役立ちます。 同じオブジェクトカテゴリの一致した境界ボックスのセットを取得した後:すべての境界ボックスを信頼スコアで並べ替えます。低信頼スコアとボックスを破棄します。残りの境界ボックスがある間は、次のことを繰り返します。貪欲に最高のスコアを持つものを選択します。高いIoUを持つ残りのボックス(つまり、>0.5)を以前に選択したボックスとスキップします。

図。 3. 複数の境界ボックスは、画像内の車を検出します。 非最大抑制の後、最良のものだけが残り、残りは選択されたものと大きな重複があるため無視されます。 (画像ソース:DPM paper)
Hard Negative Mining
オブジェクトのない境界ボックスを負の例として考えます。 すべての否定的な例が同じように識別するのが難しいわけではありません。 しかし、ボックスに奇妙なノイズの多いテクスチャや部分的なオブジェクトが含まれている場合、認識するのが難しく、これらは”ハードネガ”です。
ハード否定的な例は簡単に誤分類されます。 学習ループ中にこれらの偽陽性サンプルを明示的に見つけ、分類器を改善するためにそれらを学習データに含めることができます。
スピードボトルネック
R-CNN学習ステップを見ると、R-CNNモデルのトレーニングは高価で遅いことが簡単にわかります。
- すべての画像に2000個の領域候補を提案するための選択的検索の実行。
- すべての画像領域(N images*2000)のCNN特徴ベクトルを生成する。
- 全体のプロセスは、画像分類と特徴抽出のための畳み込みニューラルネットワーク、ターゲットオブジェクトを識別するためのトップSVM分類器、および領域R-CNNをより高速にするために、Girshick(2015)は、3つの独立したモデルを1つの共同訓練されたフレームワークに統合し、Fast R-CNNという名前の共有計算結果を増 このモデルは,各領域提案に対してCNN特徴ベクトルを独立に抽出するのではなく,それらを画像全体にわたって一つのCNNフォワードパスに集約し,領域提案はこの特徴行列を共有する。 次に、同じ特徴行列が分岐して、オブジェクト分類器と境界ボックス回帰器の学習に使用されます。 結論として、計算の共有はR-CNNを高速化します。Fast R-CNN
Fig. 4. Fast R-CNNのアーキテクチャ。 (画像ソース: Girshick,2015)
RoI Pooling
任意のサイズの画像の投影領域内のフィーチャを小さな固定ウィンドウH x Wに変換するmax poolingの一種です。h x W入力領域は、サイズh/H x w/WのほぼすべてのサブウィンドウであるH x Wグリッドに分割されます。次に、各グリッドにmax-poolingを適用します。
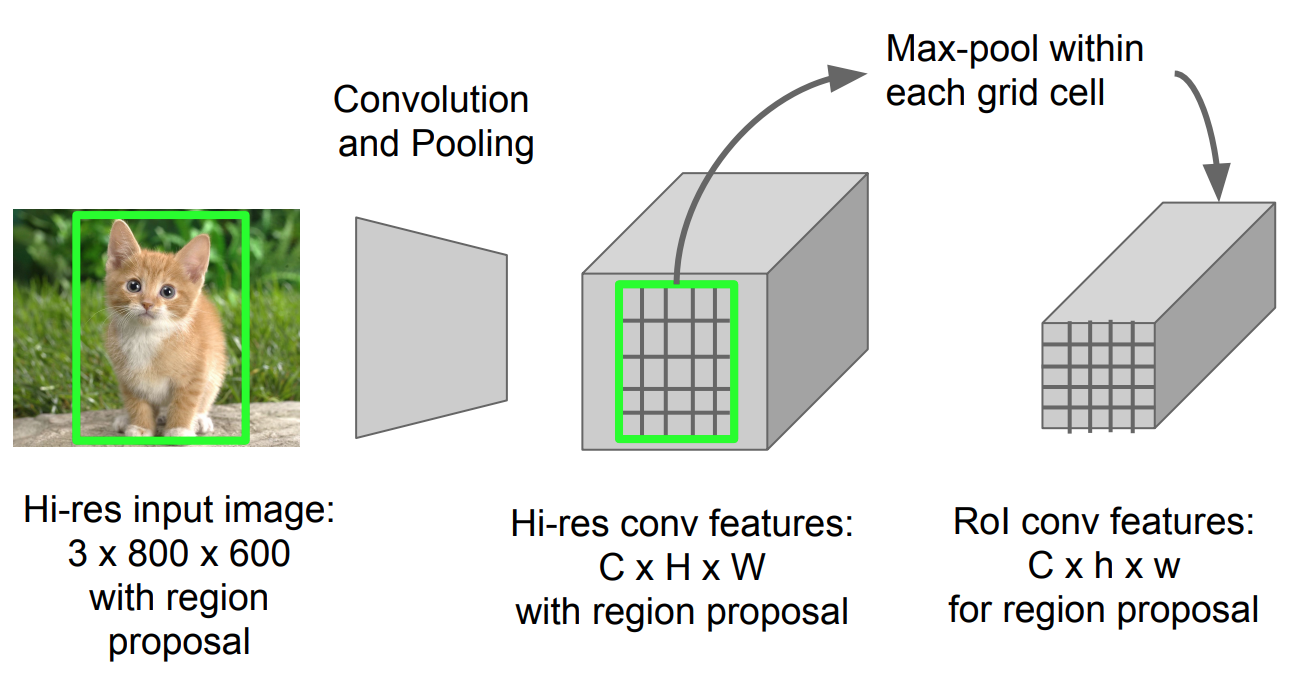
図。 5. RoIプーリング(画像ソース:スタンフォードCs231Nスライド。)
モデルワークフロー
R-CNNの動作の速さは次のように要約されています。:
- まず、画像分類タスクに関する畳み込みニューラルネットワークを事前に訓練します。
- 選択的検索(画像ごとに-2k候補)によって領域を提案します。
- 事前に訓練されたCNNを変更します。
- 事前に訓練されたCNNの最後の最大プーリング層をRoIプーリング層に置き換えます。 RoIプーリング層は、領域提案の固定長の特徴ベクトルを出力します。 CNNの計算を共有することは、同じ画像の多くの地域提案が非常に重複しているため、多くの意味があります。
- 最後の完全に接続された層と最後のsoftmax層(Kクラス)を完全に接続された層とsoftmax over K+1クラスに置き換えます。最後に、モデルは2つの出力層に分岐します:
- K+1クラスのsoftmax推定器(R-CNNと同じ、+1は「背景」クラスです)、RoIごとの離散確率分布を出力します。
- 最後に、モデルは2つの出力層に分岐します。
- K+1クラスのsoftmax推定器(R-CNNと同じ、+1は「背景」クラスです)。
- kクラスごとに元のRoIに対するオフセットを予測する境界ボックス回帰モデル。p>
シンボル 説明 \(u\) シンボル シンボル シンボル シンボル シンボル 真のクラスラベル、\(u\in0,1,\Dots,k\);慣例により、キャッチオールバックグラウンドクラスは\(u=0\)を持ちます。K+1クラス上の離散確率分布(RoIあたり):\(p=(p_0,\dots,p_k)\)、完全に接続された層のK+1出力上のソフトマックスによって計算されます。 真の境界ボックス\(v=(v_x,v_y,v_w,v_h)\)。予測された境界ボックス補正、\(t^u=(t^u_x,t^u_y,t^u_w,t^u_h)\)。 上記を参照してください。損失関数は、分類と境界ボックス予測のコストを合計します。\(\mathcal{L}=\mathcal{L}_\text{cls}+\mathcal{L}_\text{box}\)。 “背景”RoIの場合、\(\mathcal{L}_\text{box}\)は次のように定義された指標関数\(\mathbb{1}\)によって無視されます:=\開始{ケース}1&\テキスト{場合}u\geq1\0&\テキスト{そうでなければ}端\{ケース}\] 全体的な損失関数は次のとおりです。
\\mathcal{L}_\text{box}(t^u、v)\\\mathcal{L}_\text{cls}(p、u)&\text{if}u\geq1\\0&\text{if}u\geq1\\0&\text{さもなければ}\end{cases}\]
全体的な損失関数は次のとおりです。
L_1^\text{smooth}(T^u_i-V_i)\end{align*}\]境界ボックスの損失\(\mathcal{l}_{ボックス}(T^u、V)&=\sum_{i\in\{x、y、w、h\}}L_1^\text{smooth}(T^u_i-V_i)\end{align*}\]
境界ボックスの損失\(\mathcal{l}_{ボ}\)は、ロバスト損失関数を使用して、\(t^u_i\)と\(v_i\)の差を測定する必要があります。 ここでは滑らかなL1損失が採用されており、外れ値に敏感ではないと主張されています。
\
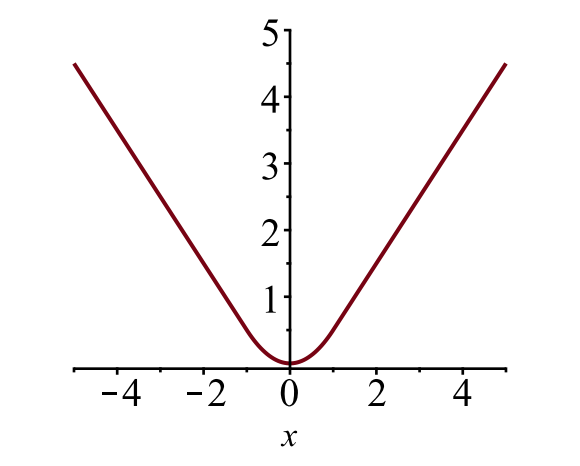
図。 6. 滑らかなL1損失のプロット、\(y=L_1^\text{smooth}(x)\)。 (画像ソース:リンク)
スピードボトルネック
高速R-CNNは、トレーニングとテストの両方の時間ではるかに高速です。 しかし、地域の提案は別のモデルによって別々に生成され、それは非常に高価であるため、改善は劇的ではありません。
Faster R-CNN
直感的な高速化ソリューションは、地域提案アルゴリズムをCNNモデルに統合することです。 Faster R-CNN(Ren et al. Rpn(region proposal network)とfast R-CNNで構成される単一の統一モデルを構築し、畳み込みフィーチャレイヤーを共有しています。

図。 7. より高速なR-CNNモデルの図。 (画像ソース:Ren et al. 2016)
モデルワークフロー
- 画像分類タスクについてCNNネットワークを事前に訓練します。
- プレトレイン画像分類器によって初期化される領域提案タスクのRPN(region proposal network)をエンドツーエンドで微調整します。 正のサンプルはIoU(intersection-over-union)>0.7を持ち、負のサンプルはIoU<0.3を持っています。
- 画像全体のconvフィーチャマップの上に小さなn x n空間ウィンドウをスライドさせます。
- 各スライディングウィンドウの中心で、さまざまなスケールと比率の複数の領域を同時に予測します。 アンカーは、(スライド窓の中心、スケール、比)の組み合わせです。 たとえば、3つのスケール+3つの比率=>k=各スライド位置に9つのアンカーがあります。
- 現在のRPNで生成された提案を使用してFast R-CNNオブジェクト検出モデルを学習し、Fast R-CNNネットワークを使用してrpn学習を初期化します。 共有された畳み込み層を維持しながら、RPN固有の層のみを微調整します。 この段階では、rpnと検出ネットワークは畳み込み層を共有しています。ステップ4-5は、必要に応じてRpnとFast R-CNNを別の方法で訓練するために繰り返すことができます。
- 最後に、Fast R-CNNのユニークな層を微調整します。
損失関数
Faster R-CNNは、fast R-CNNと同様に、マルチタスク損失関数用に最適化されています。
シンボル 説明 \(p_i\) アンカー iがオブジェクトである確率を予測しました。アンカー iがオブジェクトであるかどうかの地上真理ラベル(バイナリ)。 \(t_i\) 4つのパラメータ化された座標を予測しました。 \(t^*_i\) 地上真理座標。正規化項は、紙のミニバッチサイズ(〜256)に設定されます。 \(N_\text{cls}\) 正規化項は、紙のミニバッチサイズ(〜256)に設定されています。 正規化項は、紙のミニバッチサイズ(〜256)に設定され正規化項は、紙のアンカー位置の数(〜2400)に設定されます。 \(N_\text{box}\) 正規化項は、紙のアンカー位置の数(〜2400)に設定されます。\(\lambda\) \(\mathcal{L}_\text{cls}\)と\(\mathcal{L}_\text{box}\)の両方の項がほぼ均等に重み付けされるように、紙の中で〜10に設定されたバランシングパラメータです。 マルチタスク損失関数は、分類とバウンディングボックス回帰の損失を組み合わせたものです。
\
ここで、\(\mathcal{L}_\text{cls}\)は、サンプルがターゲットオブジェクトであることを予測することによって、マルチクラス分類をバイナリ分類に簡単に変換できるため、二つのクラスに対する対数損失関数です。対ではありません。 \(L_1^\text{smooth}\)は滑らかなL1損失です。
\
マスクR-CNN
マスクR-CNN(He et al.,2017)は、より高速なR-CNNをピクセルレベルの画像セグメンテーションに拡張します。 重要な点は、分類タスクとピクセルレベルのマスク予測タスクを分離することです。 Faster R-CNNの枠組みに基づいて、分類と局在化のための既存の分岐と並行してオブジェクトマスクを予測するための第三の分岐を追加しました。 マスク分岐は、各RoIに適用される小さな完全に接続されたネットワークであり、ピクセル間の方法でセグメンテーションマスクを予測します。
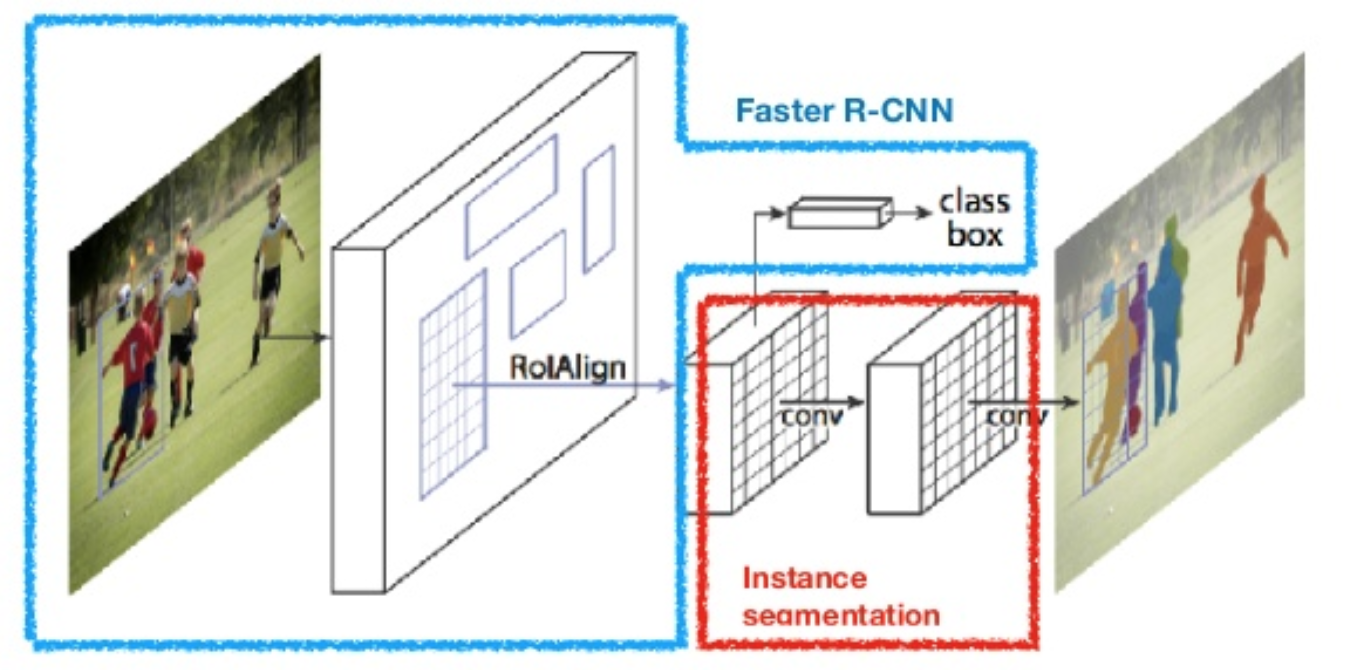
図。 8. マスクR-CNNは、画像セグメンテーションと高速R-CNNモデルです。 (画像ソース:He et al. ピクセルレベルのセグメンテーションでは、境界ボックスよりもはるかに細かいアライメントが必要なため、mask R-CNNはRoIプーリングレイヤー(”RoIAlign layer”という名前)を改善し、RoIを元の画像の領域により正確にマッピングできるようにします。

図。 9. COCOテストセット上のマスクR-CNNによる予測。 (画像ソース:He et al.,2017)
RoIAlign
RoIAlignレイヤーは、RoIプーリングの量子化によって引き起こされる位置のずれを修正するように設計されています。 RoIAlignは、抽出されたフィーチャを入力ピクセルと適切に整列させることができるように、たとえば、の代わりにx/16を使用してハッシュ量子化を削除します。 双線形内挿は、入力内の浮動小数点位置の値を計算するために使用されます。
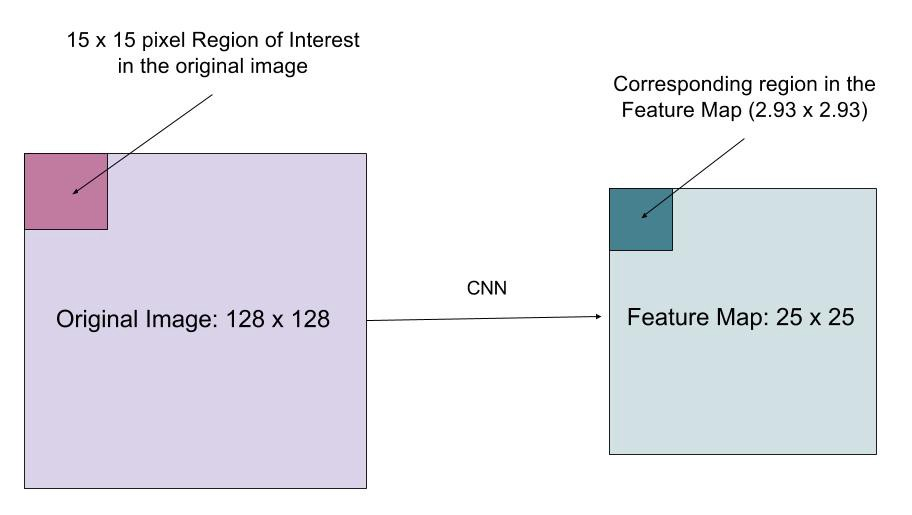
図。 10. 関心領域は、整数に切り上げることなく、元のイメージからフィーチャマップに正確にマッピングされます。 (画像ソース: マスクR-CNNのマルチタスク損失関数は、分類、ローカライズ、セグメンテーションマスクの損失を組み合わせたものです。\(\mathcal{L}=\mathcal{L}_\text{cls}+\mathcal{L}_\text{box}+\mathcal{L}_\text{mask}\)、ここで\(\mathcal{L}_\text{cls}\)と\(\mathcal{L}_\text{box}\)は同じです。\(\mathcal{L}_\text{box}\)は、\(\mathcal{L}_\text{box}\)は、\(\mathcal{L}_\text{box}\)は、\(\mathcal{L}_\text{box}\)と同じです。\(\mathcal{L}_\text{box}\)は、\(\mathcal{L}_\text{box}\)は、\(\mathcal{L}_\text{box}\)は、\(\mathcal{L}_\より高速なr-cnn。
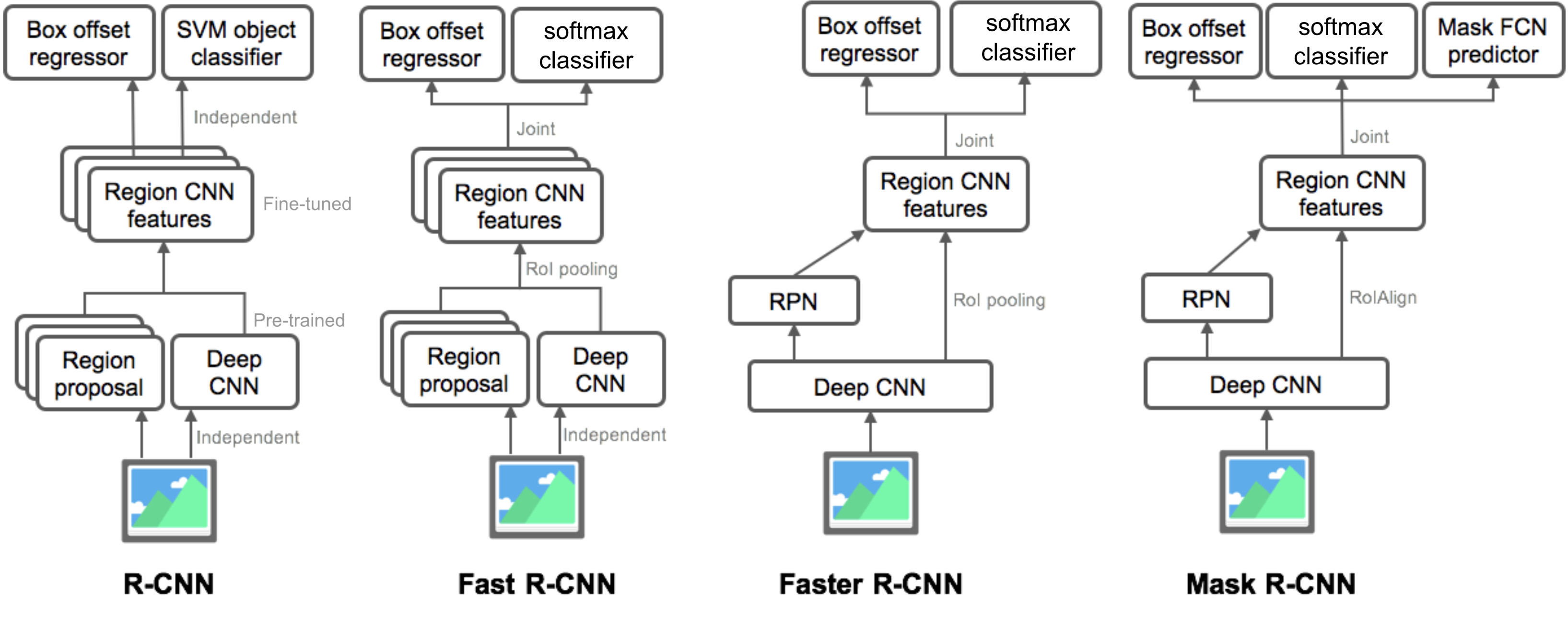
マスクブランチは、各RoIおよび各クラスに対して次元m x mのマスクを生成します。Kクラスの合計。 したがって、合計出力のサイズは\(K\cdot m^2\)です。 モデルはクラスごとにマスクを学習しようとしているため、マスクを生成するためのクラス間の競争はありません。ここで、\(y_{ij}\)はサイズm x mの領域の真のマスク内のセル(i,j)のラベルです。\(\hat{y}_{ij}^k\)は、マスクで学習された同じセルの予測値です。グランド-トゥルークラスk.ここでは、R-CNN、Fast R-CNN、Faster R-CNN、およびMask R-CNNのモデルデザインを説明します。 小さな違いを比較することで、あるモデルが次のバージョンにどのように進化するかを追跡できます。
引用:
@article{weng2017detection3, title = "Object Detection for Dummies Part 3: R-CNN Family", author = "Weng, Lilian", journal = "lilianweng.github.io/lil-log", year = "2017", url = "http://lilianweng.github.io/lil-log/2017/12/31/object-recognition-for-dummies-part-3.html"}リファレンス
Ross Girshick、Jeff Donahue、Trevor Darrell、ジテンドラ-マリクも “正確なオブジェクト検出とセマンティックセグメンテーションのための豊富な機能階層。”である。 IEEE Conf. コンピュータビジョンとパターン認識(CVPR)、pp.580-587。 2014.
ロスGirshick。 “Fast R-CNN.”である。 IEEE国際規格。 コンフ… ^『コンピュータ・ビジョン』、1440-1448頁。 2015.
Shaoqing Ren、Kaiming He、Ross Girshick、およびJian Sun。 “より高速なR-CNN:地域提案ネットワークとリアルタイムのオブジェクト検出に向けて。”神経情報処理システム(NIPS)の進歩、pp.91-99。 2015.
Kaiming He、Georgia Gkioxari、Piotr Dollár、Ross Girshick。 “マスクR-CNN.”arXiv preprint arXiv:1703.06870,2017.Joseph Redmon、Santosh Divvala、Ross Girshick、Ali Farhadi。 “あなたは一度だけ見て:統一された、リアルタイムのオブジェクト検出。”である。 IEEE Conf. コンピュータビジョンとパターン認識(CVPR)、pp.779-788。 2016.Athelasによる「画像セグメンテーションにおけるCnnの簡単な歴史:R-CNNからMask R-CNNへ」。
滑らかなL1損失:https://github.com/rbgirshick/py-faster-rcnn/files/764206/SmoothL1Loss.1.pdf
div