Detecção de objectos para manequins Parte 3: Família R-CNN
na Parte 3, examinaríamos quatro modelos de detecção de objectos: R-CNN, R-CNN rápido, R-CNN mais rápido e R-CNN Mascarado. Estes modelos são altamente relacionados e as novas versões mostram uma grande melhoria de Velocidade em comparação com os mais antigos.
na série de “detecção de objectos para manequins”, começamos com conceitos básicos no processamento de imagens, tais como vetores gradientes e porcos, na Parte 1. Então introduzimos projetos clássicos de arquitetura convolucional de rede neural para classificação e modelos pioneiros para reconhecimento de objetos, sobreaquecimento e DPM, na Parte 2. No terceiro post desta série, estamos prestes a rever um conjunto de modelos na família R-CNN (“Regional-based CNN”).
Links para todos os posts da série:.esta é uma lista de artigos abrangidos por esta publicação. 😉
| Model | Goal | Resources |
| R-CNN | Object recognition | |
| Fast R-CNN | Object recognition | |
| Faster R-CNN | Object recognition | |
| Mask R-CNN | Image segmentation |
R-CNN
R-CNN (Girshick et al., 2014) is short for “Region-based Convolutional Neural Networks”. The main idea is composed of two steps. Em primeiro lugar, utilizando a pesquisa seletiva, identifica um número gerenciável de candidatos de regiões objeto delimitadoras (“região de interesse” ou “RoI”). E então extrai características CNN de cada região independentemente para classificação.
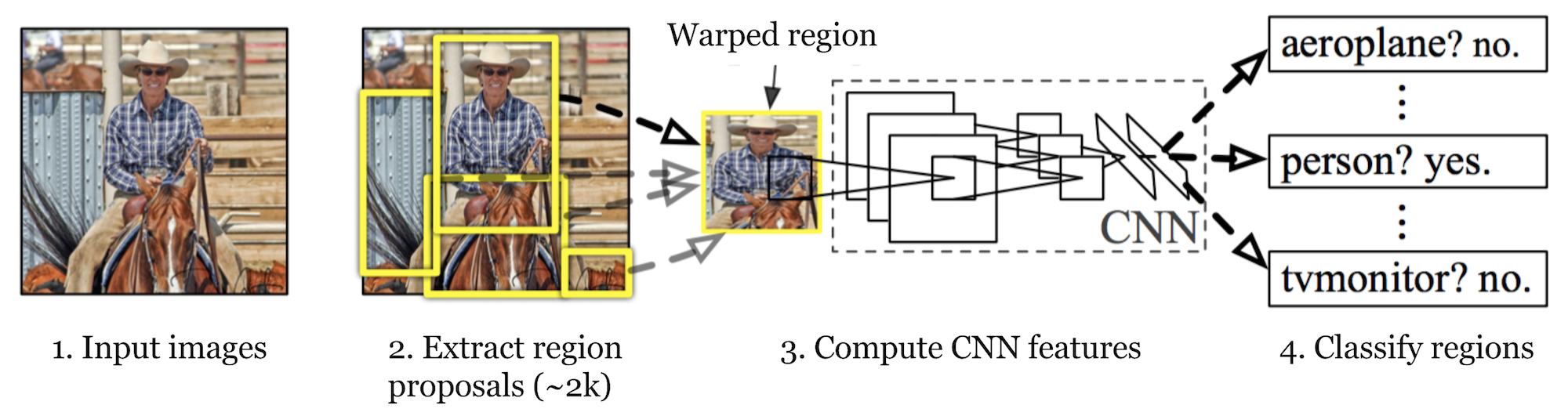
Fig. 1. The architecture of R-CNN. (Image source: Girshick et al., 2014)
Model Workflow
How R-CNN works can be resumed as follows:
- Pre-train a CNN network on image classification tasks; for example, VGG or ResNet trained on ImageNet dataset. A tarefa de classificação envolve N classes.
nota: você pode encontrar uma AlexNet pré-treinada no zoológico modelo Caffe. Eu não acho que você pode encontrá-lo em Tensorflow, mas Tensorflow-slim model library fornece ResNet pré-treinado, VGG, e outros.
- propõe regiões independentes de interesse por Pesquisa seletiva (~2K candidatos por imagem). Essas regiões podem conter objetos-alvo e são de tamanhos diferentes.
- os candidatos da região são distorcidos para ter um tamanho fixo conforme exigido pela CNN.
- Continue fine-tuning the CNN on warped proposal regions for K + 1 classes; The additional one class refers to the background (no object of interest). Na fase de afinação, devemos utilizar uma taxa de aprendizagem muito menor e o mini-lote sobrepõe os casos positivos, porque a maioria das regiões propostas são apenas um pano de fundo.
- dada cada região de imagem, uma propagação para a frente através da CNN gera um vetor de características. Este vetor de recursos é então consumido por um SVM binário treinado para cada classe independentemente.
As amostras positivas são as regiões propostas com limite de sobreposição de IoU (intersecção sobre a União) >= 0,3, e amostras negativas são irrelevantes outras. - Para reduzir os erros de localização, um modelo de regressão é treinado para corrigir a janela de detecção prevista no deslocamento de correção de caixa envolvente usando características CNN.
Caixa Delimitadora de Regressão
Dada uma previsão de caixa delimitadora coordenar \(\mathbf{m} = (p_x, p_y, p_w, p_h)\) (centro de coordenadas, largura, altura) e respectivo terreno verdade caixa de coordenadas \(\mathbf{g} = (g_x, g_y, g_w, g_h)\) , o regressor é configurado para aprender escala invariável de transformação entre os dois centros e log-escala de transformação entre as larguras e alturas. Todas as funções de transformação tomam \(\mathbf{p}\) como entrada.
\
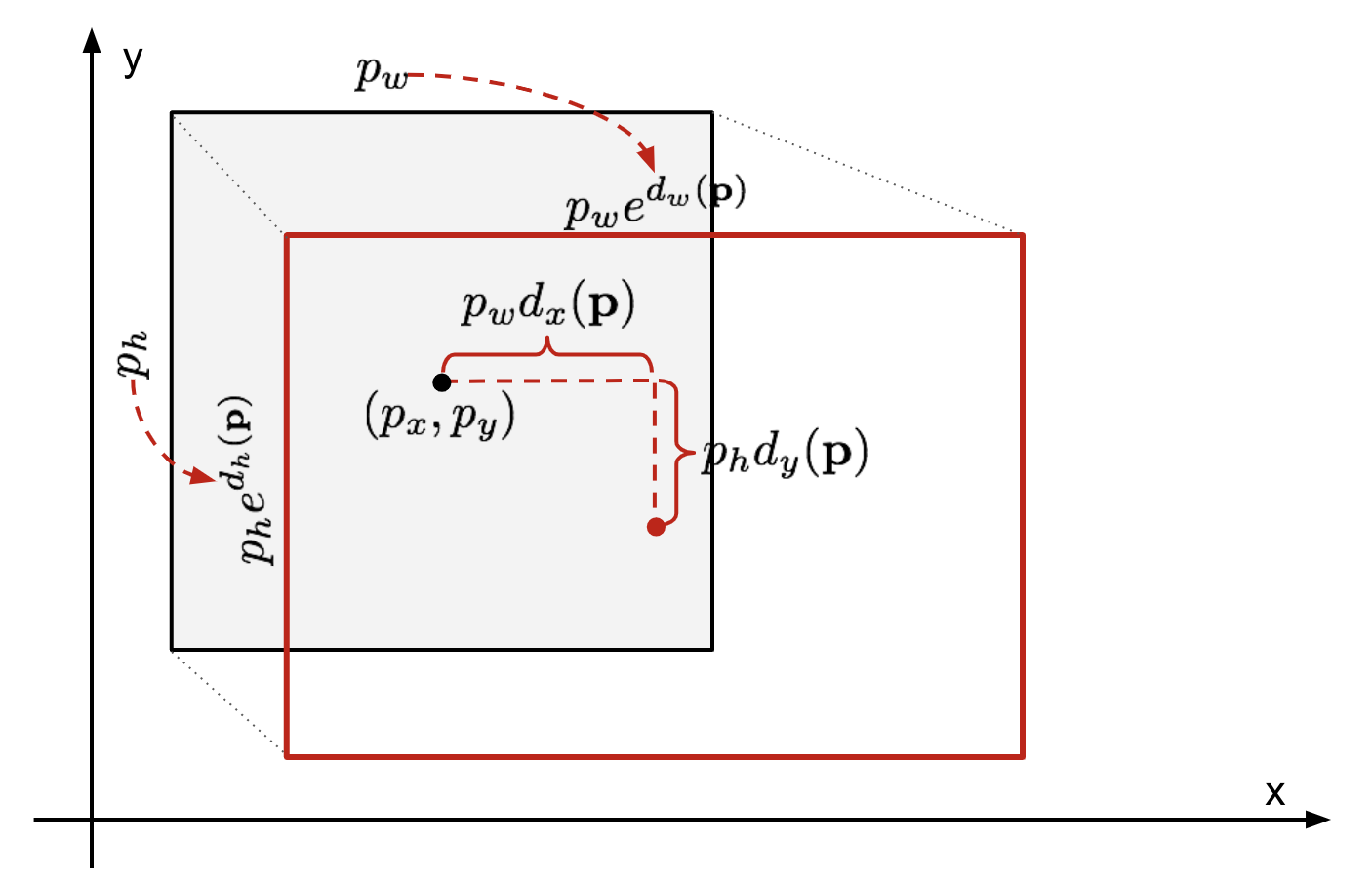
Fig. 2. Ilustração da transformação entre as caixas envolventes da verdade previstas e do solo.
uma vantagem óbvia de aplicar tal transformação é que todas as funções de correção de caixa envolvente, \(d_i (\mathbf{P})\) Onde \(i \in \{ x, y, w, h\}\), podem levar qualquer valor entre . Os alvos para eles aprenderem são:
\
um modelo de regressão padrão pode resolver o problema minimizando a perda de SSE com a regularização:
\
o termo de regularização é crítico aqui e papel RCNN escolheu o melhor λ Por validação cruzada. É também digno de nota que nem todas as caixas envolventes previstas têm as correspondentes caixas de verdade do solo. Por exemplo, se não houver sobreposição, não faz sentido executar regressão bbox. Aqui, apenas uma caixa prevista com uma caixa de verdade terrestre próxima com pelo menos 0,6 IoU é mantida para treinar o modelo de regressão bbox.
Truques comuns
vários truques são comumente usados em RCNN e outros modelos de detecção.
supressão não-Máxima
provavelmente o modelo é capaz de encontrar várias caixas envolventes para o mesmo objeto. Supressão não-max ajuda a evitar a detecção repetida da mesma instância. Depois de obter um conjunto de caixas envolventes para a mesma categoria de objeto: ordenar todas as caixas envolventes pela pontuação de confiança.Rejeitar as caixas com valores de confiança Baixos.Enquanto houver alguma caixa delimitadora restante, repita o seguinte: Greedly selecione o que tiver a pontuação mais alta.Ignorar as restantes caixas com Uai elevada (ou seja, > 0,5) com uma previamente seleccionada.

Fig. 3. Várias caixas envolventes detectam o carro na imagem. Após a supressão não-máxima, apenas os melhores restos e o resto são ignorados, pois eles têm grandes sobreposições com o selecionado. (Image source: DPM paper)
Hard Negative Mining
We consider bounding boxes without objects as negative examples. Nem todos os exemplos negativos são igualmente difíceis de identificar. Por exemplo, se ele contém fundo puro vazio, é provável que seja um “negativo fácil”; mas se a caixa contém Textura barulhenta estranha ou objeto parcial, pode ser difícil de ser reconhecido e estes são “negativos duros”.
os exemplos negativos são facilmente mal classificados. Podemos encontrar explicitamente essas amostras falsas positivas durante os loops de treinamento e incluí-las nos dados de treinamento de modo a melhorar o classificador.
a Velocidade do Gargalo
Olhando através do R-CNN aprendizagem passos, você pode facilmente descobrir que a formação de um R-CNN modelo é caro e lento, como as etapas a seguir envolvem um monte de trabalho:
- Execução seletiva de pesquisa para propor 2000 região de candidatos para cada imagem;
- Gerar a CNN recurso vetor para cada área da imagem (N imagens * 2000).
- Todo o processo envolve três modelos separados sem computação muito compartilhada: a rede neural convolucional para classificação de imagens e extração de recursos; o classificador SVM superior para identificar objetos-alvo; e o modelo de regressão para apertar caixas delimitadoras de regiões.
R-CNN rápido
para tornar R-CNN mais rápido, Gershick (2015) melhorou o procedimento de treinamento unificando três modelos independentes em um quadro de treinamento conjunto e aumentando os resultados de computação compartilhada, chamado Fast R-CNN. Em vez de extrair vetores de características CNN de forma independente para cada proposta de Região, este modelo os agrega em uma transmissão CNN para a frente sobre toda a imagem e as propostas de região compartilham esta matriz de recursos. Então a mesma matriz de recursos é ramificada para ser usada para aprender o classificador de objetos e o regressor de caixa envolvente. Em conclusão, a partilha de cálculos acelera o R-CNN.
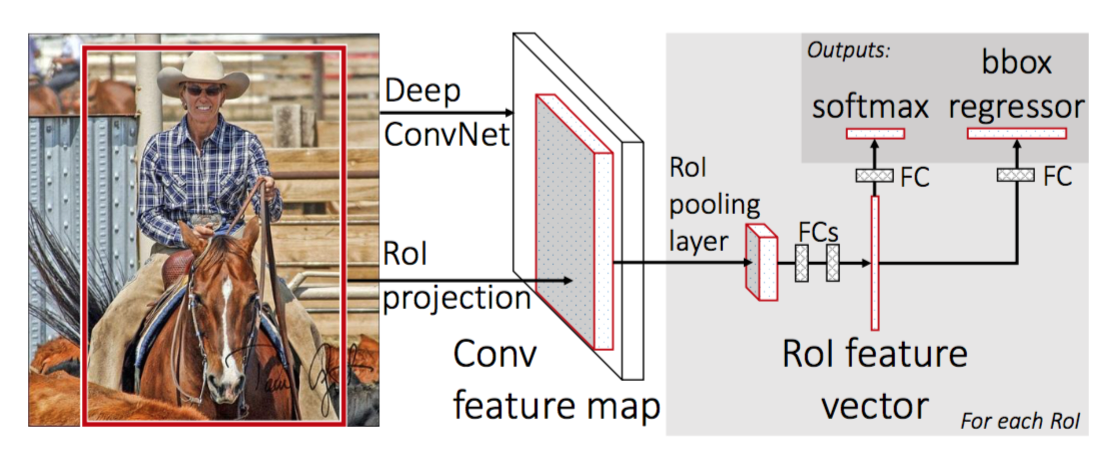
Fig. 4. A arquitetura do Fast R-CNN. (Fonte da imagem: Girshick, 2015)
RoI Agrupamento
é um tipo de max pool para converter recursos em projetada região da imagem de qualquer tamanho, h x w, em uma pequena janela fixa, H x W. A região de entrada é dividido em H x W grades, aproximadamente a cada subjanela do tamanho da h/H x w/W., em Seguida, aplicar max-agrupamento em cada grade.
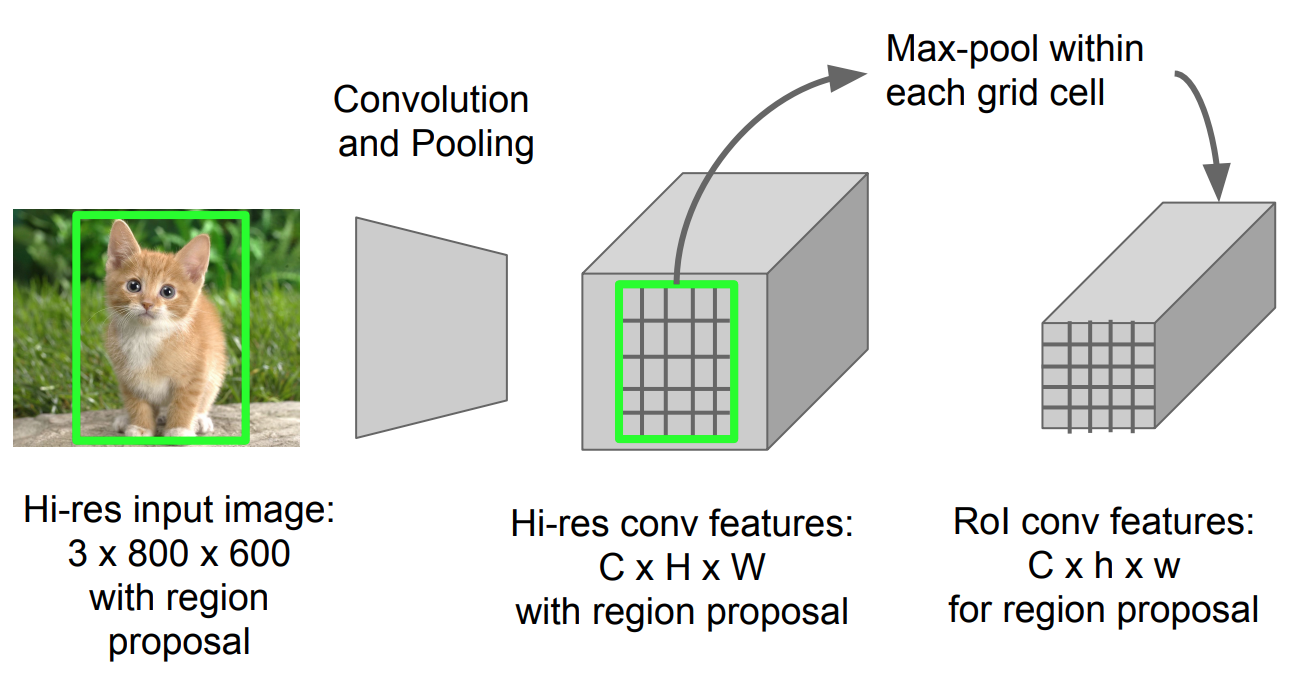
Fig. 5. ROI pooling (fonte da imagem: Stanford CS231n slides.)
Model Workflow
How Fast R-CNN works is resumed as follows; many steps are same as in R-CNN:
- primeiro, pré-treinar uma rede neural convolucional em tarefas de classificação de imagens.
- propõe regiões por Pesquisa seletiva (~2k candidatos por imagem).
- alterar a CNN pré-treinada:
- substituir a última camada de agrupamento máximo da CNN pré-treinada por uma camada de agrupamento de RoI. O ROI pooling layer produz vectores de características de comprimento fixo das propostas das regiões. Compartilhar a computação CNN faz muito sentido, pois muitas propostas de regiões das mesmas imagens são altamente sobrepostas.
- Substitua a última camada totalmente conectada e a última camada de softmax (classes K) por uma camada totalmente conectada e softmax sobre as classes K + 1.
- finalmente, o modelo se ramifica em duas camadas de saída:
- um estimador de softmax de classes K + 1 (o mesmo que em R-CNN, +1 é a classe “fundo”), obtendo uma distribuição discreta de probabilidade por RoI.
- um modelo de regressão de caixa envolvente que prevê compensações relativas ao RI original para cada uma das classes K.
a Perda de Função
A modelo está optimizado para uma perda da combinação de duas tarefas de classificação (+ localização):
| Símbolo | Explicação |
| \(u\) | True rótulo de classe, \(u \0, 1, \dots, K\); por convenção, o “pega-tudo” de fundo de classe \(u = 0\). |
| \(p\) | Discrete probability distribution (per RoI) over K + 1 classes: \(p = (p_0, \dots, p_K)\), computed by a softmax over the K + 1 outputs of a fully connected layer. |
| \(v\) | trocadilho verdadeiro \(v= (v_x, v_y,v_w, v_h)\). |
| \(t^u\) | Previstos caixa delimitadora de correção, \(t^u = (t^u_x, t^u_y, t^u_w, t^u_h)\). Ver acima. |
A perda de função resume o custo de classificação e a caixa delimitadora de previsão: \(\mathcal{L} = \mathcal{L}_\text{cls} + \mathcal{L}_\text{box}\). Para o RoI de “fundo”, o \(\mathcal{L}_\text{box}\) é ignorado pela função indicador \(\mathbb{1} \), definida como:
\ = \begin{cases} 1 & \text{se } u \geq 1\\ 0 & \text{senão}\end{cases}\]
A perda total da função é:
\ \mathcal{L}_\text{caixa}(t^u, v) \\\mathcal{L}_\text{cls}(p, u) &= -\log p_u \\\mathcal{L}_\text{caixa}(t^u, v) &= \sum_{i \in \{x, y, w, h\}} L_1^\text{suave} (t^u_i – v_i)\end{align*}\]
A caixa delimitadora de perda de \(\mathcal{L}_{box}\) deve medir a diferença entre \(t^u_i\) e \(v_i\), usando um robusto perda de função. A perda suave L1 é adotada aqui e alega-se ser menos sensível a casos anómalos.
\
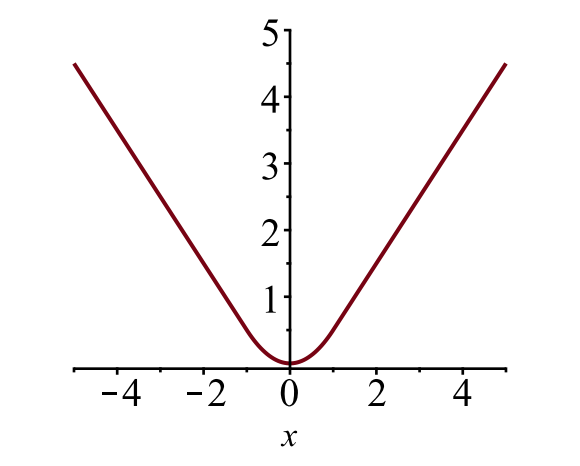
Fig. 6. O gráfico da perda suave do L1, \(y = L_1^\text{smooth} (x)\). (Fonte da imagem: link)
gargalo de Velocidade
r-CNN rápido é muito mais rápido tanto no tempo de treinamento e teste. No entanto, a melhoria não é dramática porque as propostas regionais são geradas separadamente por outro modelo, o que é muito dispendioso.
R-CNN mais rápido
uma solução intuitiva de speedup é integrar o algoritmo de proposta de região no modelo CNN. Faster R-CNN (Ren et al., 2016) está fazendo exatamente isso: construir um único modelo unificado composto de RPN (region proposal network) e R-CNN rápido com camadas de recursos convolucionais compartilhados.

Fig. 7. Uma ilustração do Modelo R-CNN mais rápido. (Fonte da imagem: Ren et al., 2016)
Model Workflow
- Pre-train a CNN network on image classification tasks.Afine a RPN (region proposal network) de ponta a ponta para a tarefa de proposta de região, que é inicializada pelo classificador de imagens pré-train. As amostras positivas têm Ui (intersection-over-union) > 0,7, enquanto as amostras negativas têm Ui < 0,3.
- deslize uma pequena janela espacial n x n Sobre o mapa da funcionalidade conv de toda a imagem.no centro de cada janela deslizante, predizemos várias regiões de várias escalas e rácios simultaneamente. Uma âncora é uma combinação de (centro da janela deslizante, escala, proporção). Por exemplo, 3 escalas + 3 rácios => K=9 âncoras em cada posição móvel.
- Train a Fast R-CNN object detection model using the proposals generated by the current RPN
- then use the Fast R-CNN network to initialize RPN training. Enquanto mantém as camadas convolucionais compartilhadas, apenas afina as camadas específicas do RPN. Nesta fase, RPN e a rede de detecção compartilharam camadas convolucionais!finalmente, afinar as camadas únicas de R-CNN rápido
- passo 4-5 pode ser repetido para treinar RPN e R-CNN rápido, em alternativa, se necessário.
A função de perda
r-CNN mais rápido é otimizada para uma função de perda multi-tarefa, semelhante à R-CNN rápida.
| Símbolo | Explicação |
| \(p_i\) | probabilidade Predita de âncora de eu ser um objeto. |
| \(p^*_i\) | Round truth label (binary) of whether anchor I is an object. |
| \(t_i\) | previu quatro coordenadas parametrizadas. |
| \(t^*_i\) | coordenadas da verdade no solo. |
| \(N_\text{cls}\) | termo de normalização, definido como sendo o tamanho do mini-lote (~256) no papel. |
| \(n_\text{box}\) | termo de normalização, definido para o número de pontos de referência (~2400) no papel. |
| \(\lambda\) | Um parâmetro de balanceamento, previsto para ser ~10 no papel (para que tanto \(\mathcal{L}_\text{cls}\) e \(\mathcal{L}_\text{box}\) os termos são aproximadamente o mesmo peso). |
A multi-tarefa perda de função combina as perdas de classificação e a caixa delimitadora de regressão:
\
onde \(\mathcal{L}_\text{cls}\) é o registo de perda de função de mais de duas classes, como podemos facilmente traduzir um multi-classe classificação em um binário de classificação, prevendo um exemplo a ser um objeto de destino versus não. \(L_1^\text{smooth}\) é a perda suave L1.
\
Máscara R-CNN
Máscara R-CNN (He et al., 2017) estende-se mais rápido R-CNN para a segmentação de imagem ao nível de pixels. O ponto-chave é dissociar a classificação e as tarefas de predição da máscara de pixels. Baseado no framework de R-CNN mais rápido, ele adicionou um terceiro ramo para prever uma máscara de objeto em paralelo com os ramos existentes para classificação e localização. O ramo máscara é uma pequena rede totalmente conectada aplicada a cada RoI, prevendo uma máscara de segmentação em uma maneira pixel-a-pixel.
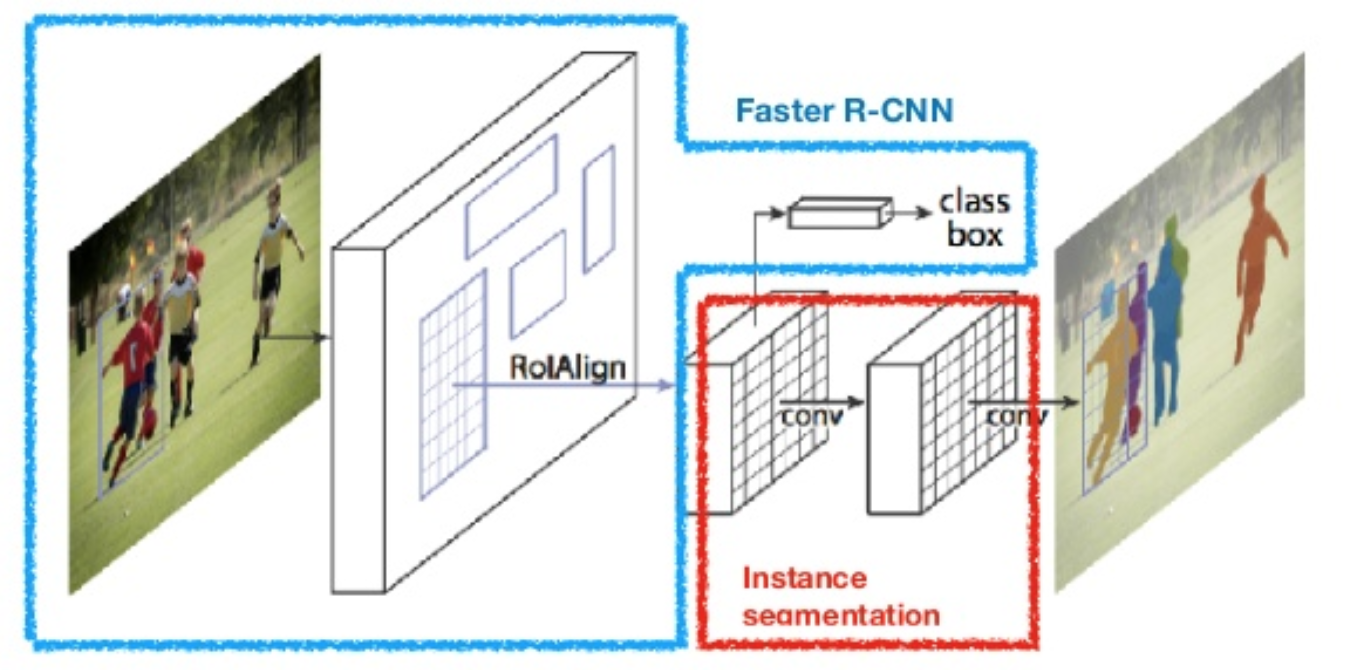
Fig. 8. Mask R-CNN é um modelo R-CNN mais rápido com segmentação de imagem. (Image source: He et al., 2017)
porque a segmentação do nível de pixels requer muito mais alinhamento fino do que Caixas envolventes, mask R-CNN melhora a camada de pooling RoI (chamada “camada RoIAlign”) para que o RoI possa ser melhor e mais precisamente mapeado para as regiões da imagem original.
Fig. 9. Previsões da Mask R-CNN no ensaio do COCO. (Image source: He et al. A camada RoIAlign foi projetada para corrigir o desalinhamento de localização causado pela quantização na poça ROI. RoIAlign remove a quantização de hash, por exemplo, usando x/16 em vez de , de modo que as características extraídas podem ser adequadamente alinhadas com os pixels de entrada. Interpolação Bilinear é usada para calcular os valores de localização de ponto flutuante na entrada.
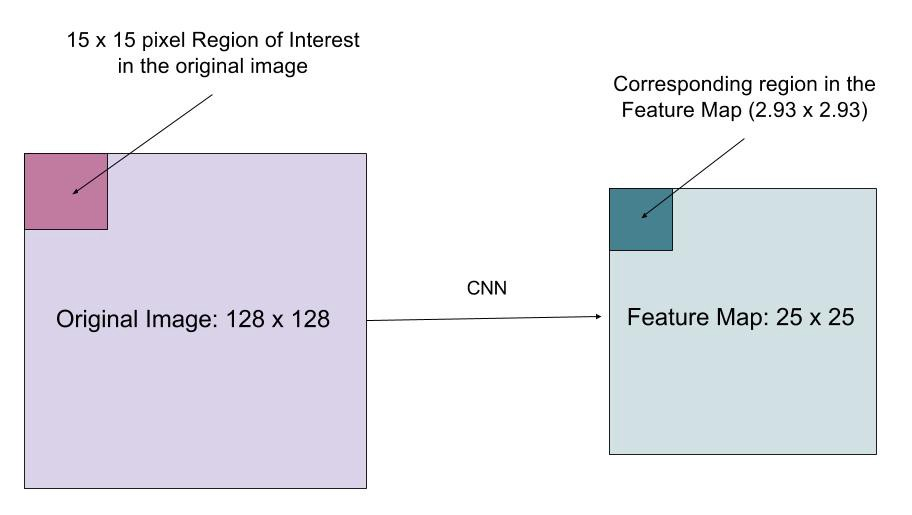
Fig. 10. Uma região de interesse é mapeada com precisão a partir da imagem original para o mapa de recursos sem arredondamento para inteiros. (Fonte da imagem: link)
a Perda de Função
A multi-tarefa perda de função da Máscara de R-CNN combina a perda de classificação, localização e segmentação máscara: \(\mathcal{L} = \mathcal{L}_\text{cls} + \mathcal{L}_\text{caixa} + \mathcal{L}_\text{máscara}\), onde \(\mathcal{L}_\text{cls}\) e \(\mathcal{L}_\text{box}\) são as mesmas que no mais Rápido do R-a CNN.
o ramo máscara gera uma máscara de dimensão m x m para cada RoI e cada classe; K classes no total. Assim, o resultado total é de tamanho \(K \cdot m^2\). Porque o modelo está tentando aprender uma máscara para cada classe, não há competição entre as classes para gerar máscaras.
\(\mathcal{L}_\text{máscara}\) é definido como a média binário cross-entropy perda, inclusive para o k-ésimo máscara, se a região está associada com o solo verdade de classe k.
\\]
onde \(y_{ij}\) é o rótulo de uma célula (i, j) na verdade máscara para a região de tamanho m x m; \(\hat{y}_{ij}^k\) é o valor previsto da mesma célula na máscara aprendeu para o chão-verdade de classe k.
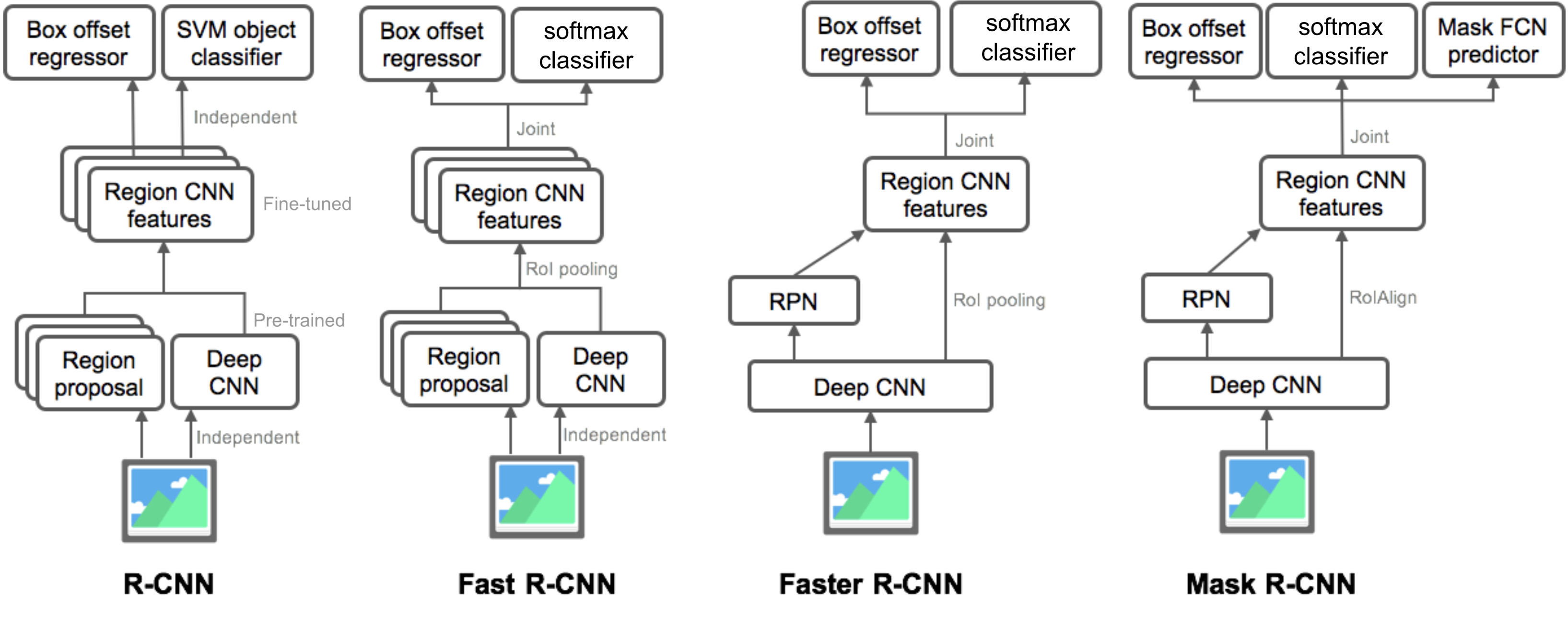
resumo dos modelos da família R-CNN
Aqui ilustro modelos de R-CNN, R-CNN rápido, R-CNN mais rápido e R-CNN Máscara R-CNN. Você pode acompanhar como um modelo evolui para a próxima versão, comparando as pequenas diferenças.
Citada como:
@article{weng2017detection3, title = "Object Detection for Dummies Part 3: R-CNN Family", author = "Weng, Lilian", journal = "lilianweng.github.io/lil-log", year = "2017", url = "http://lilianweng.github.io/lil-log/2017/12/31/object-recognition-for-dummies-part-3.html"}Referência
Ross Girshick, Jeff Donahue, Trevor Darrell, e Jitendra Malik. “Rich feature hierarchies for accurate object detection and semantic segmentation.”In Proc. IEEE Conf. on computer vision and pattern recognition (CVPR), pp. 580-587. 2014.Ross Girshick. “Fast R-CNN.”In Proc. IEEE Intl. Conf. on computer vision, pp. 1440-1448. 2015.Shaoqing Ren, Kaiming He, Ross Girshick e Jian Sun. “Faster R-CNN: Towards real-time object detection with region proposal networks.”In Advances in neural information processing systems (NIPS), pp. 91-99. 2015.Kaiming He, Georgia Gkioxari, Piotr Dollár e Ross Girshick. “Mask R-CNN.”arXiv preprint arXiv: 1703.06870, 2017.Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi. “Você só olha uma vez: unificado, detecção de objetos em tempo real.”In Proc. IEEE Conf. on computer vision and pattern recognition (CVPR), pp. 779-788. 2016.
“A Brief History of CNNs in Image Segmentation: From R-CNN to Mask R-CNN” by Athelas.perda suave L1: https://github.com/rbgirshick/py-faster-rcnn/files/764206/SmoothL1Loss.1.pdf